 源码分析
源码分析
# drf的体系
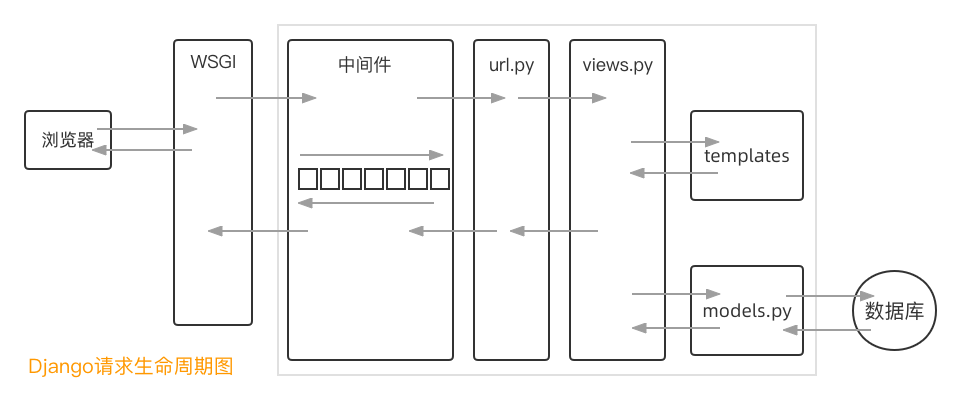
浏览器发出的http请求首先到的不是Django框架..
- http请求它先到web服务器.
1> 该服务器实现了wsgi协议.在开发阶段我们使用wsgiref,项目上线后使用uwsgi来跑Django.
2> 该服务器负责将http请求拆成python的字典.将此字典给Django.
Django将其包装成Django的request对象! (若后面是Flask框架,就包装成Flask的request对象)
- 经过中间件
- 进行路由匹配
- 原来是直接执行对应的视图函数
现在不会啦,因为使用的是drf! drf处于的位置: 路由匹配成功后,进视图类之前
在进入视图函数之前,以及视图里,drf写了很多钩子..帮忙做了很多事.
APIView里dispatch的源码,先后干了这些事
包装了新的request
处理后端能解析的编码 (urlencoded,formdata,json)
三大认证 (认证、权限、频率)
Ps:能进入权限的校验一定登陆成功了.
进入视图类的函数,开始执行
在函数执行过程中,会捕获全局异常
处理了响应,即返回json格式还是浏览器格式的数据
视图是如何执行的?
- 若是GenericAPIView+ListModelMixin 取完所有的数据还会进行了过滤和排序
- 去模型中取数据
- 分页
- 序列化
- 返回
class ListModelMixin:
def list(self, request, *args, **kwargs):
# -- 获取所有并过滤 所有要想实现过滤必须得继承ListModelMixin
queryset = self.filter_queryset(self.get_queryset())
# -- 分页
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
# -- 序列化
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 认证源码
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
class MyAuth(BaseAuthentication):
def authenticate(self, request):
pass
1
2
3
4
5
2
3
4
5
(つД`)ノ
入口:
APIView里dispatch -- self.initial(request, *args, **kwargs) -- self.perform_authentication(request)
def perform_authentication(self, request):
request.user # -- 注意,此request对象是新的request对象!掉用的是新的request对象的user方法.
request.user 其中的user多半是一个被包装成数据属性的方法
from rest_framework.request import Request 去Request类中找user方法!
源码如下:
@property
def user(self):
if not hasattr(self, '_user'):
with wrap_attributeerrors():
self._authenticate() # -- 核心就是这句话!!调用的是Request类的_authenticate方法.
return self._user
Request类的_authenticate方法.
源码如下:
def _authenticate(self):
# -- self.authenticators是一个列表,列表中放的是一个个不同认证类的实例化对象!
# 来就废话,不写认证类就不会认证..Hhh
for authenticator in self.authenticators:
try:
# -- 执行认证类的authenticate方法.
# 这就是为啥我们编写认证类要重写authenticate方法!
# -- 注意,传入的self是Request类的实例对象request.
# So,我们的认证类的authenticate方法有两个参数! authenticate(self,request)
# -- 我们重写的authenticate方法,若认证通过,返回两个值,第一个值约定必须是当前登陆用户
# 这里用user_auth_tuple进行了接收
user_auth_tuple = authenticator.authenticate(self)
# -- 若认证失败,抛出<认证失败AuthenticationFailed>的异常!
# 注意,AuthenticationFailed继承了APIException!
except exceptions.APIException:
self._not_authenticated()
raise
if user_auth_tuple is not None:
self._authenticator = authenticator
# -- 看到了吗?返回的第一个值就给了request.user !!
# 这意味着后续的request对象就有user属性啦!
self.user, self.auth = user_auth_tuple # -- 解压赋值
# -- 认证通过,返回两个值,其它认证类的authenticate方法就不会走啦!!
# 这里直接跳出了for循环!要引起注意哦!
return
self._not_authenticated()
上述源码有个问题还没解决.
for循环那的self.authenticators是怎么一回事呢?
- 查看源码,得知 self.authenticators是在Request类__init__初始化的时候传入的!!
- 那Request类在什么时候初始化的呢? APIView的dispatch中刚开始的位置!
就这这句话(二次封装request对象): request = self.initialize_request(request, *args, **kwargs)
APIView类的initialize_request方法源码如下:
def initialize_request(self, request, *args, **kwargs):
parser_context = self.get_parser_context(request)
# -- 初始化.
return Request(
request,
parsers=self.get_parsers(),
# -- !!执行了APIView类的get_authenticators方法
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
APIView类的get_authenticators方法源码如下:
def get_authenticators(self):
# -- 列表中放了一个个认证类的对象
# 所以在视图类中配置的 authentication_classes = ['认证类','认证类'] 会执行!
return [auth() for auth in self.authentication_classes]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# 权限源码
from rest_framework.permissions import BasePermission
class MyPermission(BasePermission):
def has_permission(self, request, view):
# -- 比如说,在视图类里定义一个类变量name='lqz' 这里通过view.name就可以取到!
pass
# -- 权限认证失败,返回中文: 在权限类中配置 message即可!
1
2
3
4
5
6
7
2
3
4
5
6
7
(つД`)ノ
入口:
APIView里dispatch -- self.initial(request, *args, **kwargs) -- self.check_permissions(request)
def check_permissions(self, request):
# -- self.get_permissions()返回的是一个列表,列表里放的是一个个视图类中配置的
for permission in self.get_permissions():
# -- 这就是为啥在编写权限类时要重写has_permission方法!!并且重写的该方法要返回bool值!
# -- 传入的self是当前的视图类的实例对象!
if not permission.has_permission(request, self):
# -- 权限验证失败,执行
self.permission_denied(
request,
# -- 用到了反射,So,可以在权限类里 定义类变量message 或者 在has_permission定义self.message
# 这样的话,权限验证失败显示的就是我们设置的中文信息啦!
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)
def get_permissions(self):
return [permission() for permission in self.permission_classes]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 过滤源码
# -- 这是伪代码
class BookView(ListAPIView):
queryset = None
serializer_class = None
filter_backends = ['过滤类']
1
2
3
4
5
2
3
4
5
(⁎⁍̴̛ᴗ⁍̴̛⁎)
1> 查询所有才涉及到过滤
2> 在视图类中配置: filter_backends = [过滤类]
3> 执行过滤类中的filter_queryset方法,在方法中完成过滤、排序
4> 视图类查询所有执行的是 get -- list
注意!!要想实现过滤功能. 视图类必须继承GenericAPIView+ListModelMixin,即ListAPIView.
因为GenericAPIView中才有filter_backends类变量;ListModelMixin中才有list方法获取所有!!
若想自动生成路由,视图类可以再继承ViewSetMixin.这不是必须的.
ListModelMixin类的源码如下:
class ListModelMixin:
def list(self, request, *args, **kwargs):
# -- 视图类继承了ListAPIView,查询所有时就会执行该list方法!
# 此处的self是视图类的实例
# 按照查找顺序,此行代码的get_queryset和filter_queryset方法都是GenericAPIView的方法!!
# self.get_queryset()拿到的是所有要序列化的数据
queryset = self.filter_queryset(self.get_queryset()) # -- 执行过滤
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
GenericAPIView类中filter_queryset方法的源码:
def filter_queryset(self, queryset):
# -- 视图类中可以只设置一个过滤类,不加中括号
for backend in list(self.filter_backends):
# -- backend() 类名+括号 得到视图类中配置的filter_backends列表中过滤类的实例
# 然后调用过滤类实例的filter_queryset方法返回!
# -- 所以在视图类中配置的一个个过滤类都会执行!! 注意观察,queryset作为参数传到下一个!
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 分页源码
# -- 这是伪代码
class BookView(ListAPIView):
queryset = None
serializer_class = None
pagination_class = '分页类'
1
2
3
4
5
2
3
4
5
╮( ̄▽ ̄"")╭
1> 查询所有才涉及到分页
2> 在视图类中配置: pagination_class = 分页类
3> 视图类查询所有执行的是 get -- list
注意!!要想实现分页功能. 视图类必须继承GenericAPIView+ListModelMixin,即ListAPIView.
因为GenericAPIView中才有pagination_class类变量;ListModelMixin中才有list方法获取所有!!
若想自动生成路由,视图类可以再继承ViewSetMixin.这不是必须的.
ListModelMixin类的源码如下:
class ListModelMixin:
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset()) # -- 执行过滤
page = self.paginate_queryset(queryset) # -- 执行分页,page是当前分页的数据
if page is not None: # -- 如果使用了分页
serializer = self.get_serializer(page, many=True) # -- 只序列化当前分页的数据
return self.get_paginated_response(serializer.data) # -- 返回了上一页和下一页和总条数
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
GenericAPIView类中paginate_queryset方法的源码:
def paginate_queryset(self, queryset):
if self.paginator is None:
return None
# -- self.paginator就是分页类的实例,调用分页类的paginate_queryset方法!
# 分页类的paginate_queryset方法的源码就不看啦,简单说下逻辑.
# ★该方法实现了分页功能,取出从前端地址中传入的第几页,取多少条,在该方法中自动实现分页,返回当前页码的数据!
return self.paginator.paginate_queryset(queryset, self.request, view=self)
GenericAPIView类中paginator方法的源码:
@property
def paginator(self):
if not hasattr(self, '_paginator'):
# -- 视图类中的pagination_class为空就不管,有值就将分页类实例化!
if self.pagination_class is None:
self._paginator = None
else:
self._paginator = self.pagination_class()
return self._paginator
GenericAPIView类中get_paginated_response方法的源码:
def get_paginated_response(self, data):
# -- self.paginator就是分页类的实例
assert self.paginator is not None
# -- 调用了分页类的get_paginated_response方法
return self.paginator.get_paginated_response(data)
以PageNumberPagination分页类的get_paginated_response方法为例,其源码如下:
def get_paginated_response(self, data):
# -- ★返回给前端分页数据
return Response(OrderedDict([
('count', self.page.paginator.count),
('next', self.get_next_link()),
('previous', self.get_previous_link()),
('results', data)
]))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 频率源码
from rest_framework.throttling import SimpleRateThrottle
# -- 频率类
class MyThrottle(SimpleRateThrottle):
scope = 'ip_m_3'
def get_cache_key(self, request, view):
return request.META.get('REMOTE_ADDR')
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
(つД`)ノ
from rest_framework.throttling import SimpleRateThrottle
查看SimpleRateThrottle类的源码 --> 重点关注重写的allow_request方法
class SimpleRateThrottle(BaseThrottle):
cache = default_cache
timer = time.time
cache_format = 'throttle_%(scope)s_%(ident)s'
scope = None
THROTTLE_RATES = api_settings.DEFAULT_THROTTLE_RATES
def __init__(self):
if not getattr(self, 'rate', None):
# 2.
# -- self.rate就是配置文件中的 '3/m'
self.rate = self.get_rate()
self.num_requests, self.duration = self.parse_rate(self.rate) # 3,60
def get_cache_key(self, request, view):
raise NotImplementedError('.get_cache_key() must be overridden')
def get_rate(self):
# 3.
# -- 所以频率类中得配置一个类变量scope
if not getattr(self, 'scope', None):
msg = ("You must set either `.scope` or `.rate` for '%s' throttle" %
self.__class__.__name__)
raise ImproperlyConfigured(msg)
try:
# 4.
# -- 会去项目配置文件中找 'DEFAULT_THROTTLE_RATES': {'ip_m_3': '3/m',}
# -- SO,get_rate方法返回的就是 '3/m'
return self.THROTTLE_RATES[self.scope]
except KeyError:
msg = "No default throttle rate set for '%s' scope" % self.scope
raise ImproperlyConfigured(msg)
def parse_rate(self, rate):
# -- rate是'3/m'
if rate is None:
return (None, None)
num, period = rate.split('/')
num_requests = int(num) # 3
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]] # 60
return (num_requests, duration)
def allow_request(self, request, view):
# 1.
# -- 经过推敲 self.rate就是 '3/m'
if self.rate is None:
return True
# -- get_cache_key返回谁,就以谁做限制!所以我们的频率类里重写了它.
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
# -- self.history是当次访问者ip对应的时间列表
# -- 从缓存中通过key(ip)值,取出时间列表
self.history = self.cache.get(self.key, [])
self.now = self.timer() # -- 获取当前时间
# -- 跟我们自定义的频率类的逻辑没有区别
# -- 列表中只存放咋们规定时间内的时间
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
# -- 时间列表的长度,若大于咋们配置的,就不允许访问了.
if len(self.history) >= self.num_requests:
return self.throttle_failure()
# -- 把当前时间插入到时间列表,返回True
return self.throttle_success()
def throttle_success(self):
# -- 放到第一个位置
self.history.insert(0, self.now)
# -- 放到缓存中
self.cache.set(self.key, self.history, self.duration)
return True
def throttle_failure(self):
return False
def wait(self):
if self.history:
remaining_duration = self.duration - (self.now - self.history[-1])
else:
remaining_duration = self.duration
available_requests = self.num_requests - len(self.history) + 1
if available_requests <= 0:
return None
return remaining_duration / float(available_requests)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94