 文件传输、UDP
文件传输、UDP
# 文件传输功能
使用TCP套接字程序实现文件的下载功能!! 客户端下载文件都实现了,上传文件的逻辑颠倒过来就行了..
文件传输
├── client
│ ├── download
│ └── 客户端.py
└── server
├── share
│ └── a.txt
└── 服务端.py
2
3
4
5
6
7
8
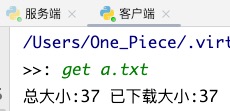
需求: 服务端的资源在share文件夹下,客户端需下载a.txt到download文件夹下!!
Ps - 之所以指定服务端的资源目录,以及客户端下载文件后存放的目录,是避免同时读写同一个文件(做这个实验时,客户端和服务端都运行在同一台机器上的嘛)
# 面向过程版本
哪怕加上了注释可读性依旧很差,不推荐!
# 客户端
import json
import os
import struct
from socket import *
download_dir = os.getcwd() + r'/download' # -- 客户端下载文件的路径 (应写到配置文件中)
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
# -- 1.发命令!!
cmd = input(">>: ").strip()
if not cmd: continue
client.send(cmd.encode('utf-8'))
# -- 2.以写的方式打开一个新文件,接收客户端发来的文件内容并写入新文件
# -- step1:先收4个字节,4个字节中包含了报头的长度
header_len = struct.unpack('i', client.recv(4))[0] # -- 解包后是元祖,取第一个元素
# -- step2:再接收报头并解析,取出我们想要的信息
header_bytes = client.recv(header_len)
header_json = header_bytes.decode('utf-8') # -- 解码
header_dic = json.loads(header_json) # -- 反序列化
total_size = header_dic['file_size'] # -- 取出报头中文件的长度信息
file_name = header_dic['filename'] # -- 取出文件名
# -- step3:再收真实的数据并存入新文件(以写的方式打开)中
with open(f"{download_dir}/{file_name}", 'wb') as f:
recv_size = 0
while recv_size < total_size:
# -- 一边收一边往文件中写
line_data = client.recv(1024)
f.write(line_data)
recv_size += len(line_data)
# -- 若文件很大,应该给用户展示进度条.. 这里就简单处理下.
print("总大小:%s 已下载大小:%s" % (total_size, recv_size))
client.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 服务端
import json
import os
import struct
from socket import *
share_dir = os.getcwd() + r"/share" # -- 服务端资源文件的目录 (应写到配置文件中)
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
while True:
try:
# -- >> 1.接收命令!!
res = conn.recv(1024) # -- b"get 文件名"
if not res: break
# -- subprocess模块是执行系统命令,拿到系统命令的结果
# 而文件传输的命令b"get a.txt"不是系统命令,是我们自己定义的
# 所以不能用subprocess模块
# -- >> 2.解析命令,提取相应命令参数!!
filename = res.decode('utf-8').split()[1]
# -- >> 3.以读的方式打开文件,读取文件内容发送给客户端!!
# -- step1:先制作报头
header_dic = {
'filename': filename,
'file_size': os.path.getsize(f"{share_dir}/{filename}"),
'hash': 'helloHKSD775SOne' # -- 此hash值是瞎写模拟的
}
header_json = json.dumps(header_dic) # -- 序列化
header_bytes = header_json.encode('utf-8') # -- 编码
# -- step2:先发送报头的长度
# "pack将报头长度len(header_bytes)打包成4个bytes,然后发送!!"
conn.send(struct.pack('i', len(header_bytes)))
# -- step3:发送报头的数据
conn.send(header_bytes)
# -- step4:再发真实的数据,即读取文件内容发送
with open(f"{share_dir}/{filename}", 'rb') as f:
# conn.send(f.read()) 若文件内容很大,一下子读出来就会将内存占满!!
for line in f: # -- 同一时刻只有一行内容在内存中
conn.send(line)
except ConnectionResetError:
break
conn.close()
server.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 函数版本
可读性更强, 还便于扩展上传功能.
# 客户端
import json
import os
import struct
from socket import *
download_dir = os.getcwd() + r'/download' # -- 客户端下载文件的路径 (应写到配置文件中)
def get(client):
header_len = struct.unpack('i', client.recv(4))[0]
header_bytes = client.recv(header_len)
header_json = header_bytes.decode('utf-8')
header_dic = json.loads(header_json)
total_size = header_dic['file_size']
file_name = header_dic['filename']
with open(f"{download_dir}/{file_name}", 'wb') as f:
recv_size = 0
while recv_size < total_size:
line_data = client.recv(1024)
f.write(line_data)
recv_size += len(line_data)
print("总大小:%s 已下载大小:%s" % (total_size, recv_size))
def run():
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
inp = input(">>: ").strip()
if not inp: continue
client.send(inp.encode('utf-8'))
cmds = inp.split()
if cmds[0] == "get": # -- 下载
get(client)
elif cmds[1] == "put": # -- 上传
pass
client.close()
if __name__ == '__main__':
run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 服务端
import json
import os
import struct
from socket import *
share_dir = os.getcwd() + r"/share" # -- 服务端资源文件的目录 (应写到配置文件中)
# -- 从服务端下载文件
def data_to_client(conn, cmds):
filename = cmds[1]
header_dic = {
'filename': filename,
'file_size': os.path.getsize(f"{share_dir}/{filename}"),
'hash': 'helloHKSD775SOne' # -- 此hash值是瞎写模拟的
}
header_json = json.dumps(header_dic) # -- 序列化
header_bytes = header_json.encode('utf-8') # -- 编码
conn.send(struct.pack('i', len(header_bytes)))
conn.send(header_bytes)
with open(f"{share_dir}/{filename}", 'rb') as f:
for line in f:
conn.send(line)
def run():
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
while True:
try:
res = conn.recv(1024)
if not res: break
cmds = res.decode('utf-8').split()
if cmds[0] == "get":
data_to_client(conn, cmds)
elif cmds[0] == "put": # -- 客户端上传文件到服务端
pass
except ConnectionResetError:
break
conn.close()
server.close()
if __name__ == '__main__':
run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 面向对象版本
将数据和操作数据的方法整合到一起! 推荐!
... ...
# UDP套接字程序
UDP套接字程序,通常用在 查询 方面,QQ通信也用的UDP..
要特别注意的是! UDP稳定传输的数据量为512字节!不能用它来传大数据!!假设文件有一个T,会分多次发送,使用UDP的话,但凡中间丢一次,整个文件报废.
网上购物,转账等交易都不能用UDP协议!!
# 实现代码
# 服务端
import socket
# -- 无listen、accept 因为UDP无需建立连接 <UDP[无]半连接池的概念>
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server.bind(("127.0.0.1", 8080))
while True:
data, client_addr = server.recvfrom(1024) # -- (b'hello', ('127.0.0.1', 51650))
print(data)
server.sendto(data.upper(), client_addr)
server.close()
2
3
4
5
6
7
8
9
10
11
# 客户端
import socket
# -- 无connect 因为UDP无需建立连接
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
while True:
msg = input(">>:").strip()
client.sendto(msg.encode('utf-8'), ("127.0.0.1", 8080))
# -- 此处的server_addr没有用 可以用_代替说明
data, server_addr = client.recvfrom(1024) # -- (b'HELLO', ('127.0.0.1', 8080))
print(data)
client.close()
2
3
4
5
6
7
8
9
10
11
12
# 代码分析
对UDP套接字的代码进行一通分析, 与TCP的实现作一作比较!!!
# 启动顺序
基于TCP协议的通信, 必须先启动服务端再启动客户端.
基于UDP协议,随便先启动哪端都可以.. 客户端启动后,直接发,它可不管服务端启动与否,数据是否成功到达..
# 客户端回空
TCP客户端直接回车输空,客户端直接卡住..
是因为客户端send给自个儿的OS缓存的是空字节..OS不会有任何反应,不会有任何网络传输的行为..
服务端在等客户端发,客户端在等服务端发,尬住了..
UDP客户端 client.sendto(b"") 看似是给客户端OS缓存一个空字节, 实则还给了个报头!!
是有数据的!! UDP数据报协议,每个数据报都有一个报头!
# 是否并发
扫盲(了解):
由于UDP支持的是一对多的模式
所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包
在每个UDP包中就有了消息头(消息来源地址,端口等信息)
这样,对于接收端来说,就容易进行区分处理了!!
前面的TCP套接字程序因为没有实现多进程多线程,所以是不具备并发的效果的!!
这里的UDP套接字程序,开启多个客户端.. 实验下是有并发的效果的.
首先要察觉到, UDP的C端和S端收消息时都会收到对方的信息(包含对方的IP和port);
UDP服务端,recvfrom一下,再sendto一下.. 本质上是一个回合一个回合的响应多个客户端的一条条消息的.
但响应的速度太快了,给操作客户端的人们的感觉就是同时响应的!!
这种并发是有局限性的, 假如有一万个客户端同时在与服务端进行UDP通信呢?
给人的感觉就不是同时响应的啦. 服务端循环一万次多少都需要点时间的吧!!一万个客户端就能感受到先后.
(若考虑客户端发送的消息数据量比较大的话,客户等待的感觉更明显..) So, UDP并没有实现并发!!!
# 无粘包问题
# 接收大于发送
在TCP里,客户端send三个数据包到客户端OS缓存,会依照nagle算法组织数据合成一个b"helloworld" (第三个send的是b"",OS压根不会叼它) 发送给服务端.. 服务端recv(1024)一次就能接收完..
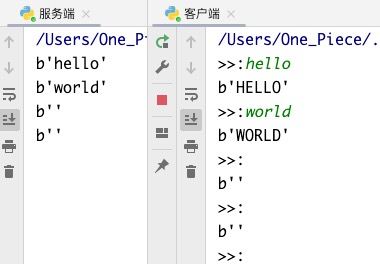
在UDP里,该程序里,客户端的每一个sendto都会依次对应服务端的recvfrom!! 收发一一对应!!
1> 客户端只发三次,服务端就只收三次,服务端第四次的recvfrom苦苦等待ing..
2> 哪怕第三次C端发空字节数据,S端也能收到!!!
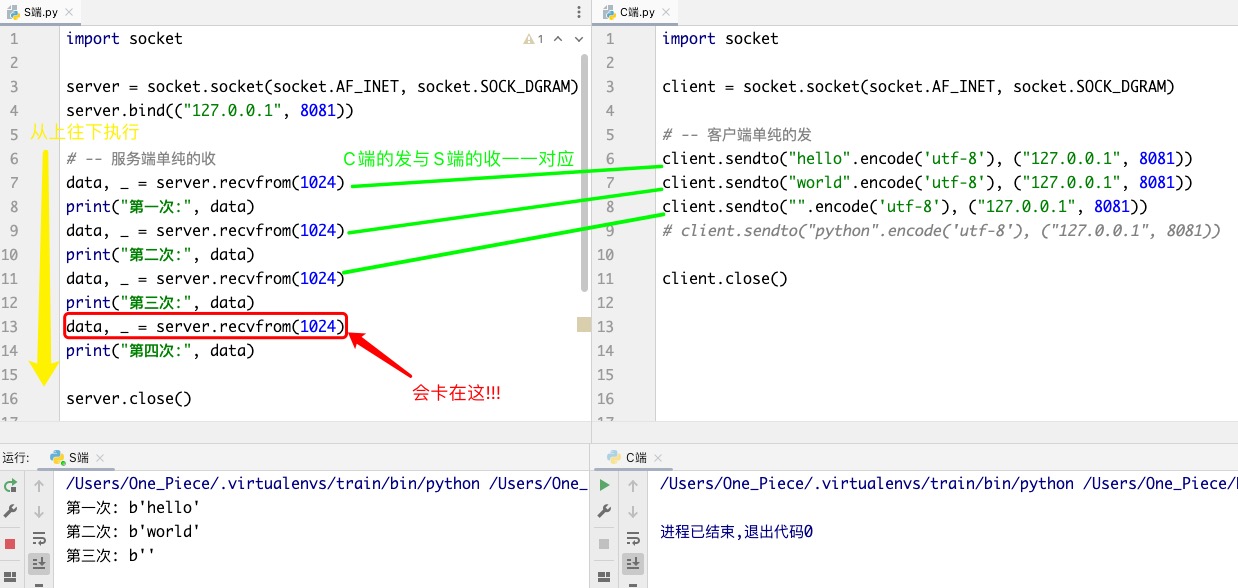
提醒一下!! UDP收发跟TCP一样,都是发送端先给自己的OS缓存,接收端再从自己的OS缓存里取..
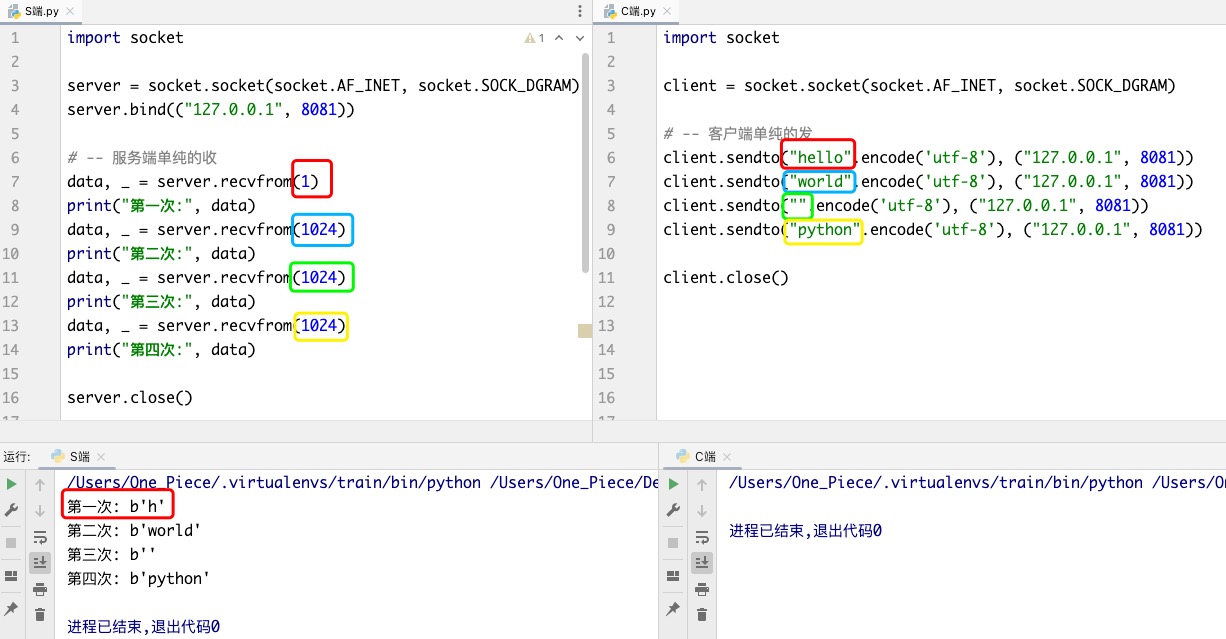
# 接收小于发送
在TCP中,第一次给了你5字节,但你只收了1个字节,还有4个在你自己的OS缓存里放着,下次取时会先拿!
在UDP中,分系统: 无需关注window的情况,了解即可,我们都是用linux
linux -- 给你4个,你只收1个,那么剩下4个直接丢了.不会有残留!
windows -- 直接报错! OSError: 该用户用于接收数据报的缓冲区比数据报小..
So,UDP的发送数据量要小于接收数据量的大小!!
但每次发送的数据量不要超过512bytes..(超过了丢包严重)
# TCP与UDP的异同
TCP是面向连接的,面向流的,提供高可靠性服务.
UDP是无连接的,面向消息的,提供高效率服务.
1> TCP面向流的通信是无消息保护边界的; -- 粘包问题
UDP面向消息的通信是有消息保护边界的. -- UDP数据报协议自带报头!
2> tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住
而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头
3> -- udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成;
即UDP收发是一一对应的!!
若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠.
-- tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容.
TCP收发不是一一对应的,比如可5次send,2次recv.但TCP有一一对应的socket.
数据是可靠的,但是会粘包.
2
3
4
5
6
7
8
9
10
11
12
13