 供应链开发第三天
供应链开发第三天
# 后端上传文件
我们先用apifox模拟前端上传文件, 完成后端上传文件的代码!!
# 媒体资源配置
静态资源分为 static 和 media
1> static 开发所需的图片、css、js等,常用于前后端不分离时.. eg: 默认头像.
2> medis 用户上传的excel、图片等.. eg: 用户上传头像.media的路径配置、路由配置.. 往后遇到了直接copy即可!!
- 在settings.py中进行媒体资源的配置
MEDIA_URL = '/media/' # 浏览器上访问媒体文件的url前缀
MEDIA_ROOT = os.path.join(BASE_DIR, 'media') # 文件目录
- 在根路由下进行配置
from django.urls import path, re_path, include
from django.conf import settings
from django.views.static import serve
urlpatterns = [
path('api/shipper/', include("apps.shipper.urls")),
re_path(r"^media/(?P<path>.*)$", serve, {'document_root': settings.MEDIA_ROOT}, name="media")
]
# -- ★ 配置media路由 的详细说明
# ○ 写法1: re_path(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
# - 因为媒体文件的访问可能是 /media/banner/1.png 也可能是/media/course/other.png
# banner、course是media目录下的文件夹 所以这里的路由用了有名分组,且命名必须叫做path!
# - serve是视图函数的内存地址
# 可以查看导入的serve,它就是一个视图函数,有名分组中的path分出来需要传给它,作为它的第二个参数!!
# eg: /media/banner/1.png -> '/banner/1.png' 会作为views视图函数的path实参..
# - serve函数还需要传递一个document_root参数.
# 相当于别人写好了一个视图函数,(?P<path>.*)解析出来后,去settings.MEDIA_ROOT路径下找文件.
# url(正则表达式,views视图函数,参数,别名)
# 正则表达式若分组,会分出来传到视图函数中,若视图函数还缺参数,会在后面通过字典形式传递.
#
# ○ 写法2: path('media/<path:path>', serve, {'document_root': settings.MEDIA_ROOT})
# - 使用转换器 转化器叫做path,分出来的key值也叫做path.
- 为了方便测试,在项目根目录下创建名为media的目录,在里面添加一张 img.png 图片
启动后端的Django项目,通过 http://127.0.0.1:8000/media/img.png/ 就能访问到该资源!! (注意是后端的8000而不是前端的8080)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 定义上传路由
后端实现上传,需要先定义路由!!定义的方式有两种. 传统的和非传统的!
此处的示例以非传统的为例!
▲ 传统的.
按照传统的方式,我们可以在shipper这个App的url.py中添加一个路由 path('upload/', account.UploadView.as_view()),
因为上传的逻辑是将上传的图片放到media目录下,并不涉及对数据库做增删改查.
所以此处的视图类UploadView可以像登陆一样继承APIView,在post方法里写自己的业务逻辑.
▲ 非传统的.
使用SimpleRouter是前提,再通过action在视图类中自动扩展路由!!
注意,使用SimpleRouter意味着我们写的视图类必须继承ViewSet类或其子类.
思考: 并不意味着第二种就比第一种好!两种方式有各自的应用场景.
若这个上传是通用的,所有的地方都用该上传,使用方式一; 若只是针对认证功能,只在认证里进行上传,那么使用方式二更好!!
代码实现逻辑如下:
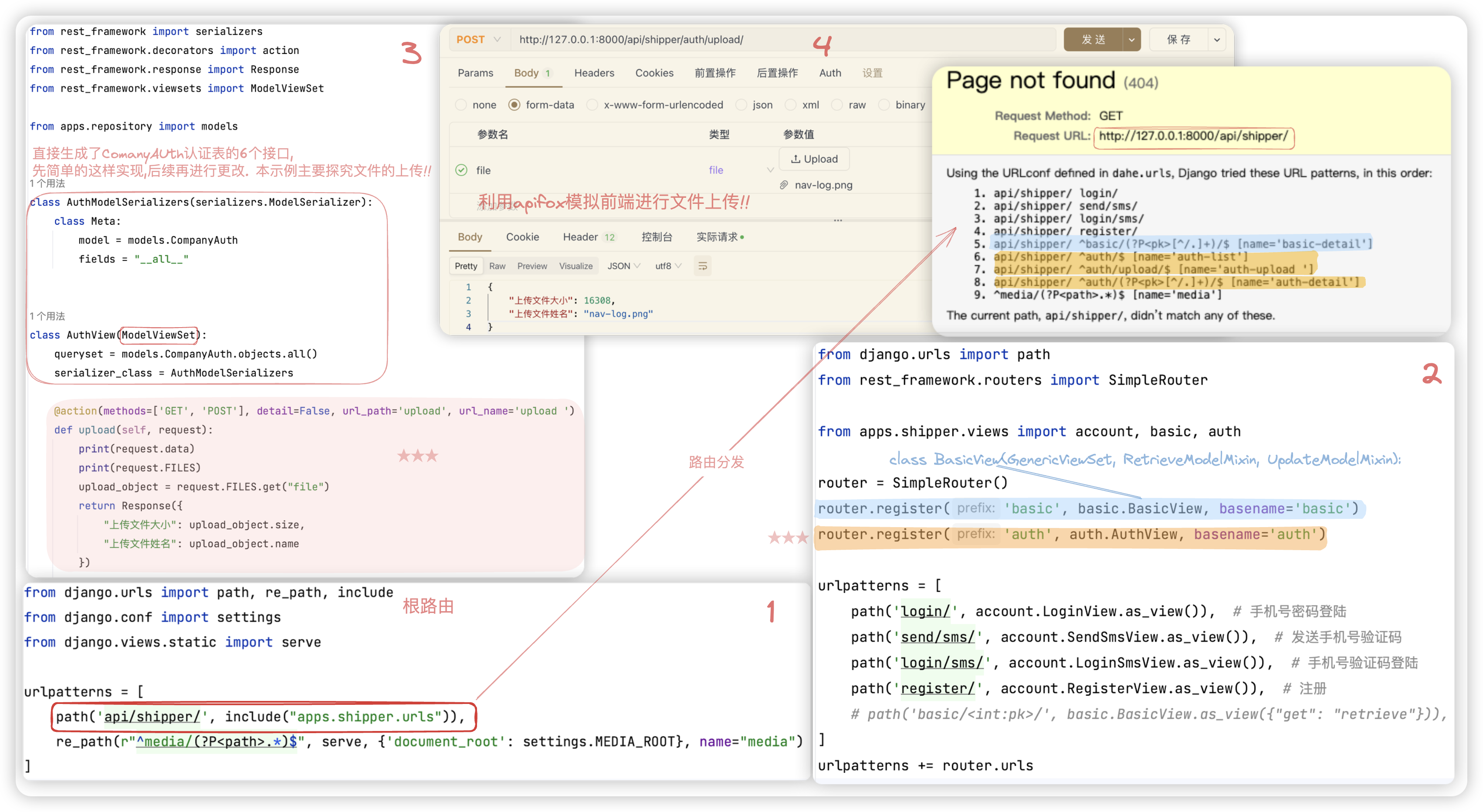
1> 文件上传的后端API地址, 后端服务网址http://127.0.0.1:8000/+根路由的路由分发api/shipper +
SimpleRouter注册视图集里的 auth + 利用action扩展的路由里的url_path的值(示例中detail值为False) upload
2> 截图中利用apifox模拟前端进行文件上传, 选择的是form-data, 其实还可以选择 binary..
详见 第二次学drf中解析器章节里FileUploadParser的使用!!!
# 上传逻辑
在上面定义路由的小节中,我们可以已经可以获取到前端传递过来的文件对象..
接下来,我们需要对action匹配的那个upload函数做一些处理, 返还给前端需要的符合规范的json格式的数据!!
后续有关文件上传,直接copy拿来用即可!!
关于文件 Django --> request.FILES ; DRF --> request.data 、request.FILES
request.data # <QueryDict: {'file': [<InMemoryUploadedFile: 存储器.png (image/png)>]}>
request.FILES # <MultiValueDict: {'file': [<InMemoryUploadedFile: 存储器.png (image/png)>]}>
upload_object = request.FILES.get("file") # 获取文件对象,相当于open打开了该文件
upload_object.size # 文件大小
upload_object.name # 文件名字
upload_object.read() # 一次性获取文件内容
upload_object.chunks(1024) # 一点一点的读取,此处一次取1024字节 是生成器
# 你可以打印type(upload_object)看里面有什么方法!
- 读取前端传递过来的文件,并保存到服务器中 若自己写的话(像下面这样):
import os
upload_object = request.FILES.get("file")
file_path = os.path.join("media", upload_object.name)
with open(file_path, 'wb') as f:
for chunk in upload_object.chunks(1024):
f.write(chunk)
- 自己写的保存,需要考虑几个问题
1> 若上传的图片重名,会导致图片覆盖
2> 我们想根据日期分类在服务器存储前端上传的图片
3> 我们最后需要返回给前端上传的文件在后端存储的路径
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
关键代码如下:

后端上传的图片路径像是这样:
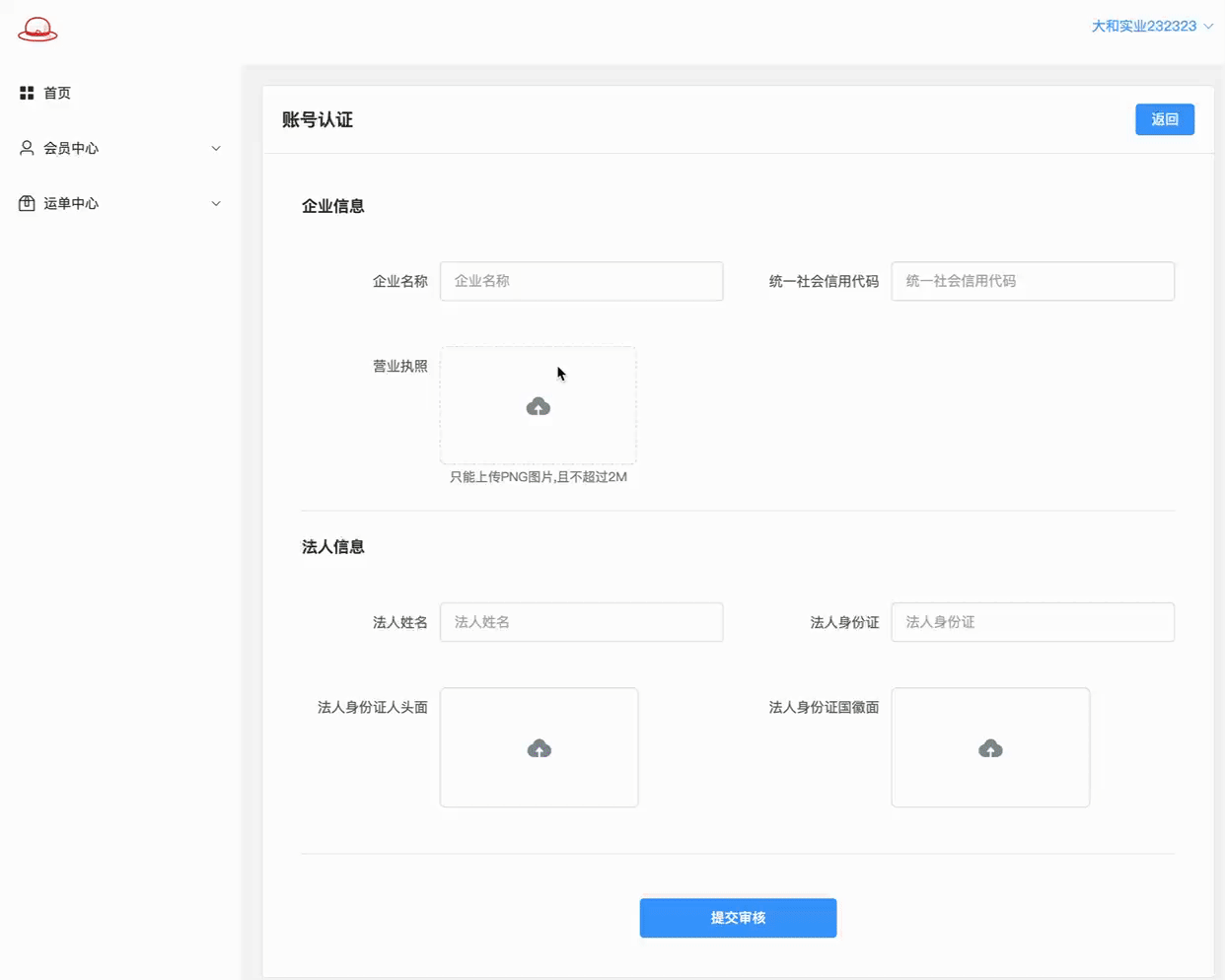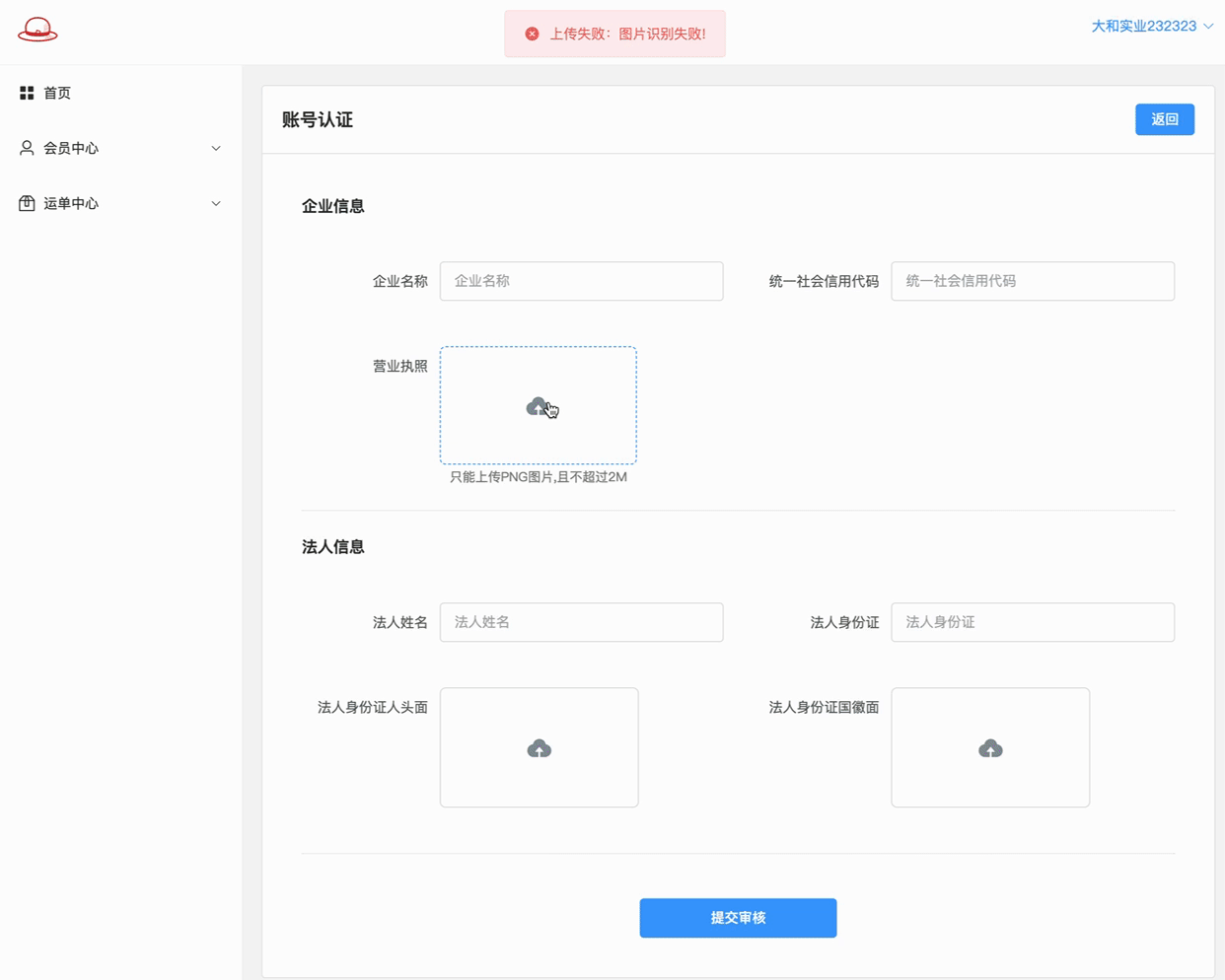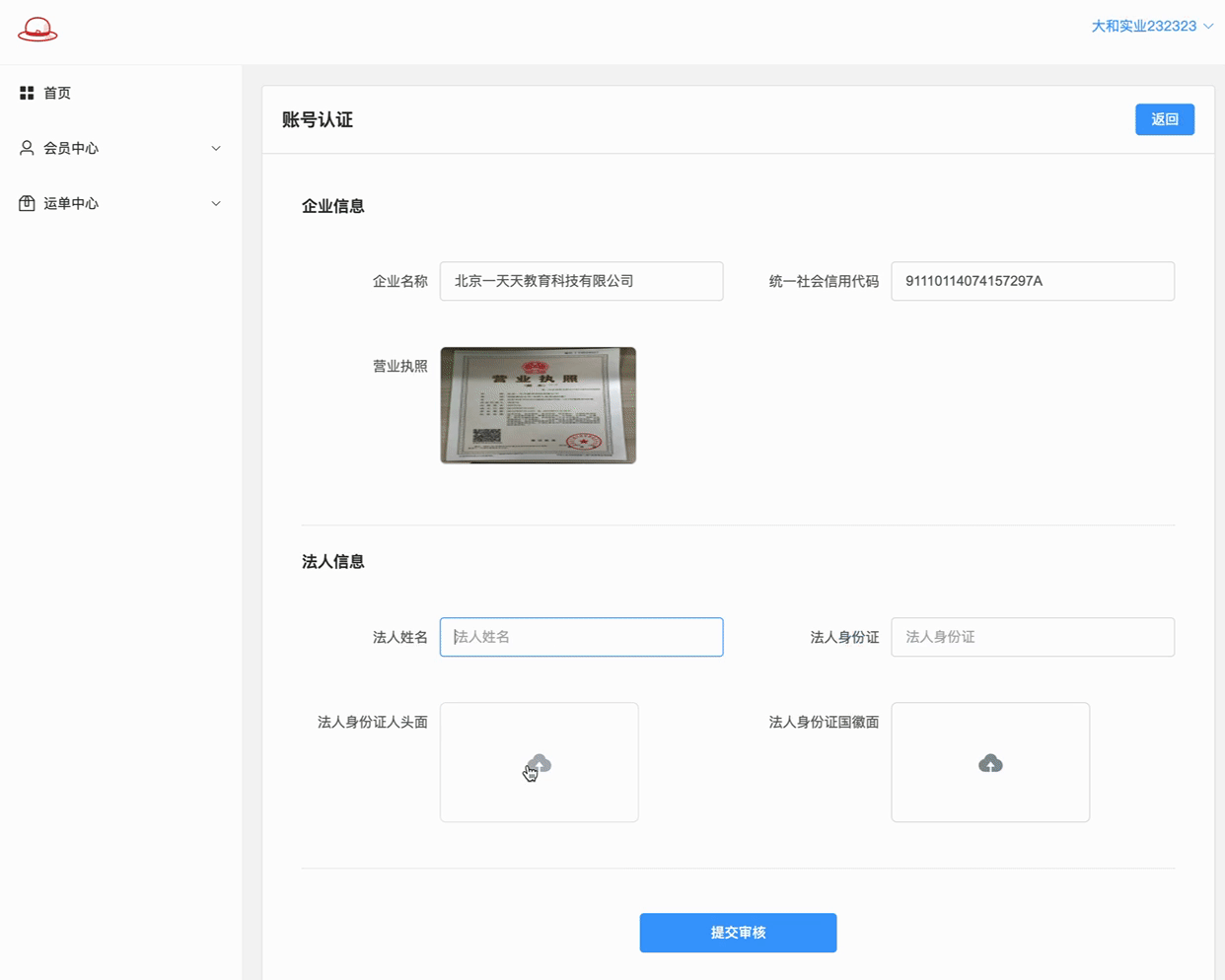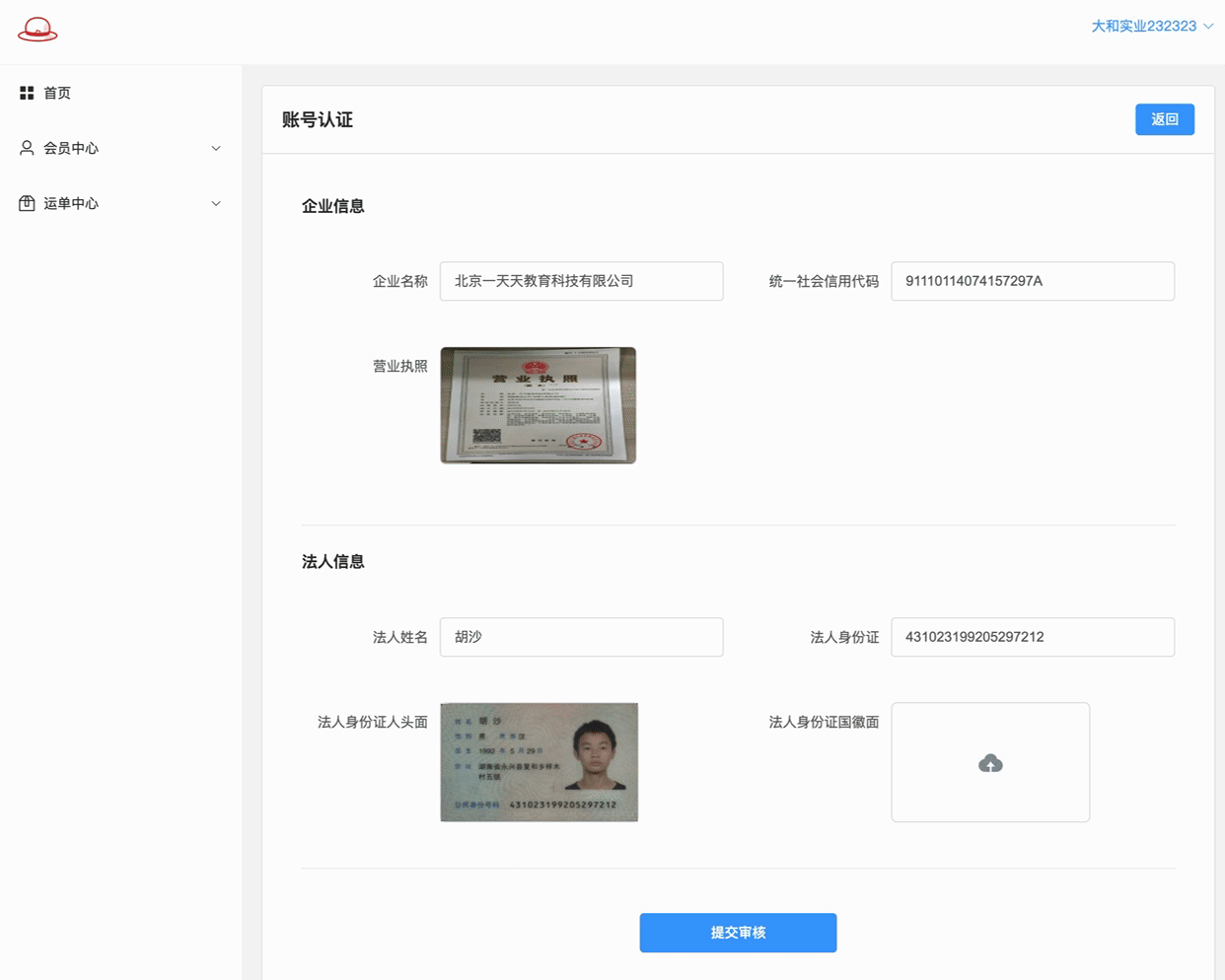
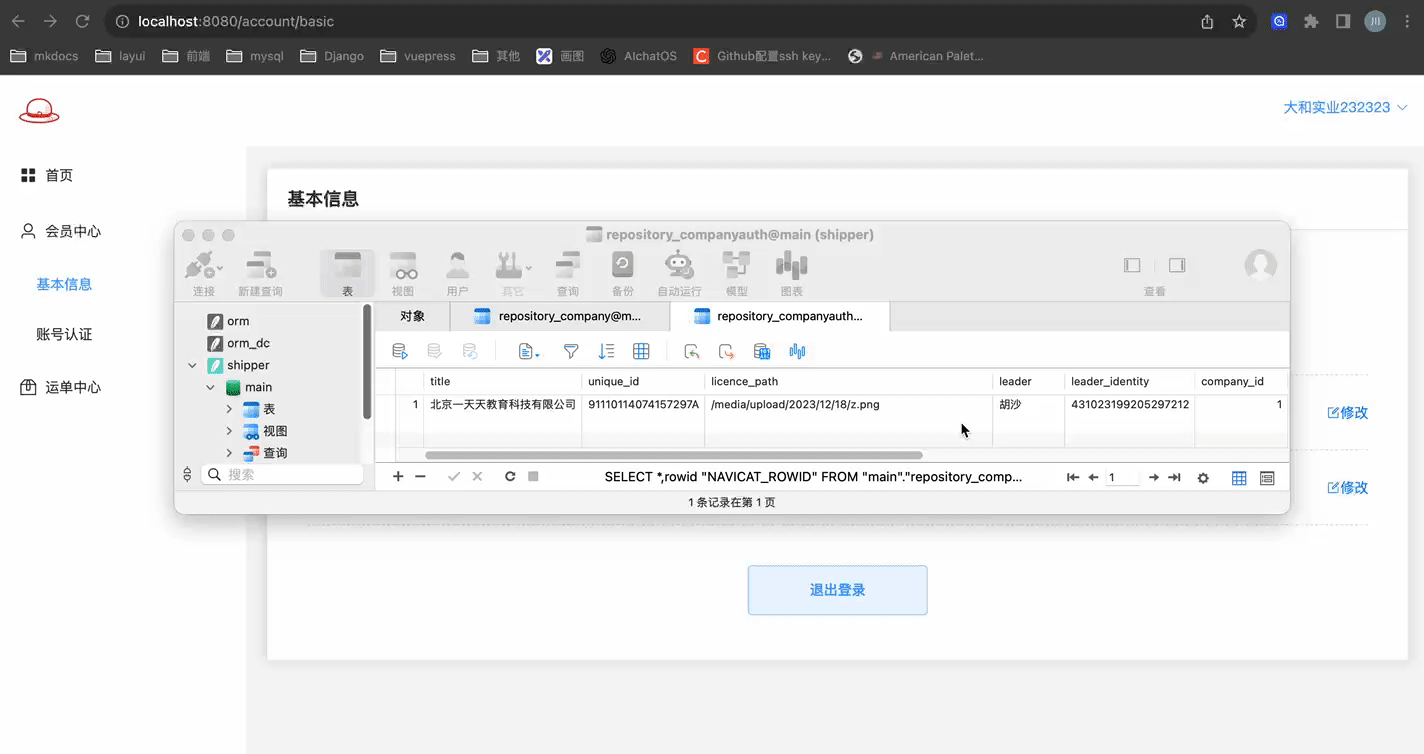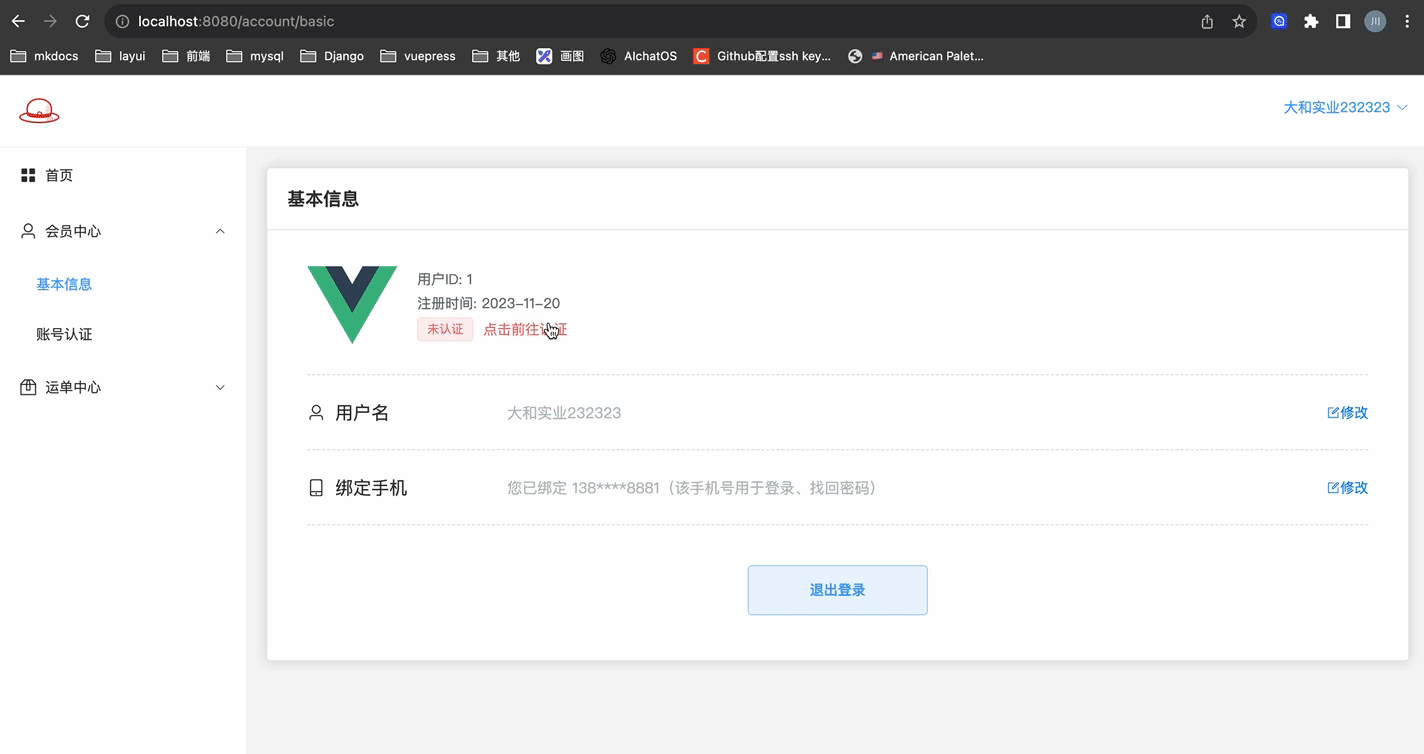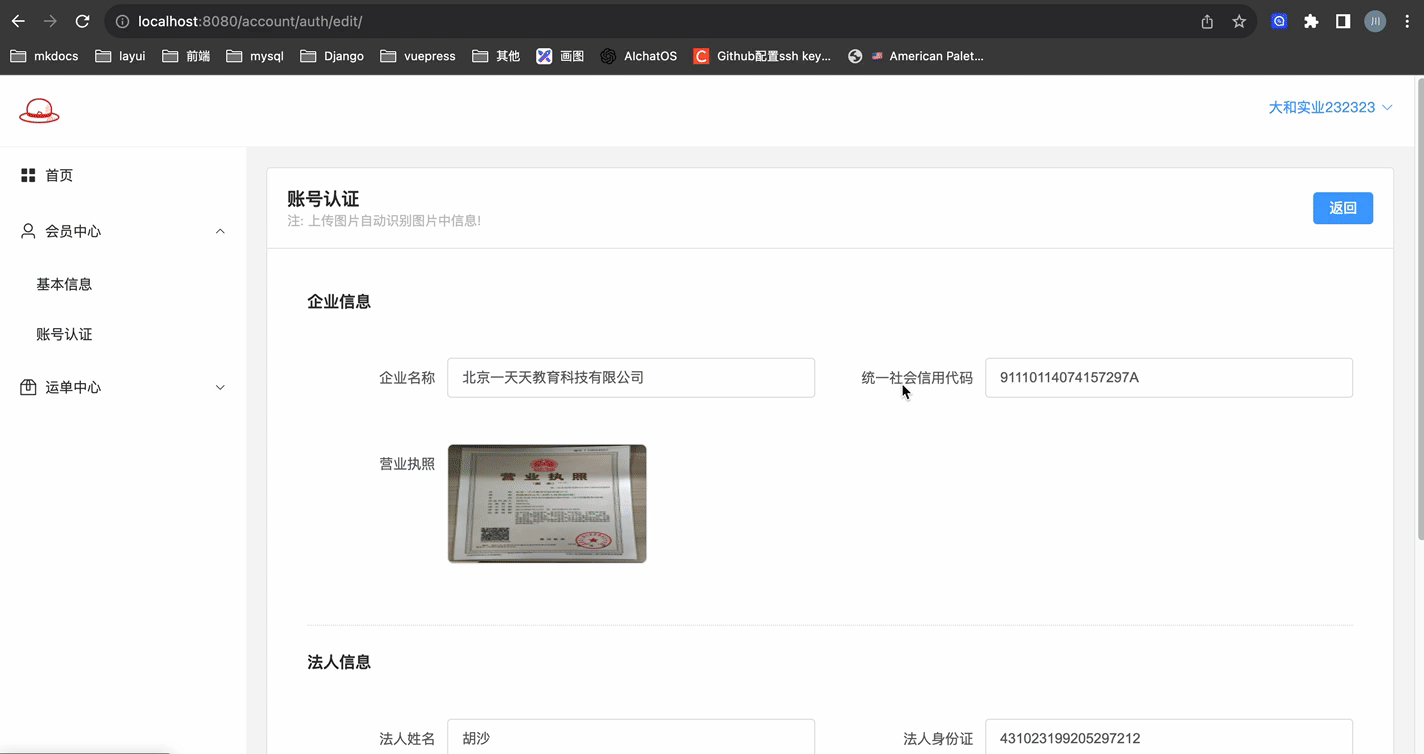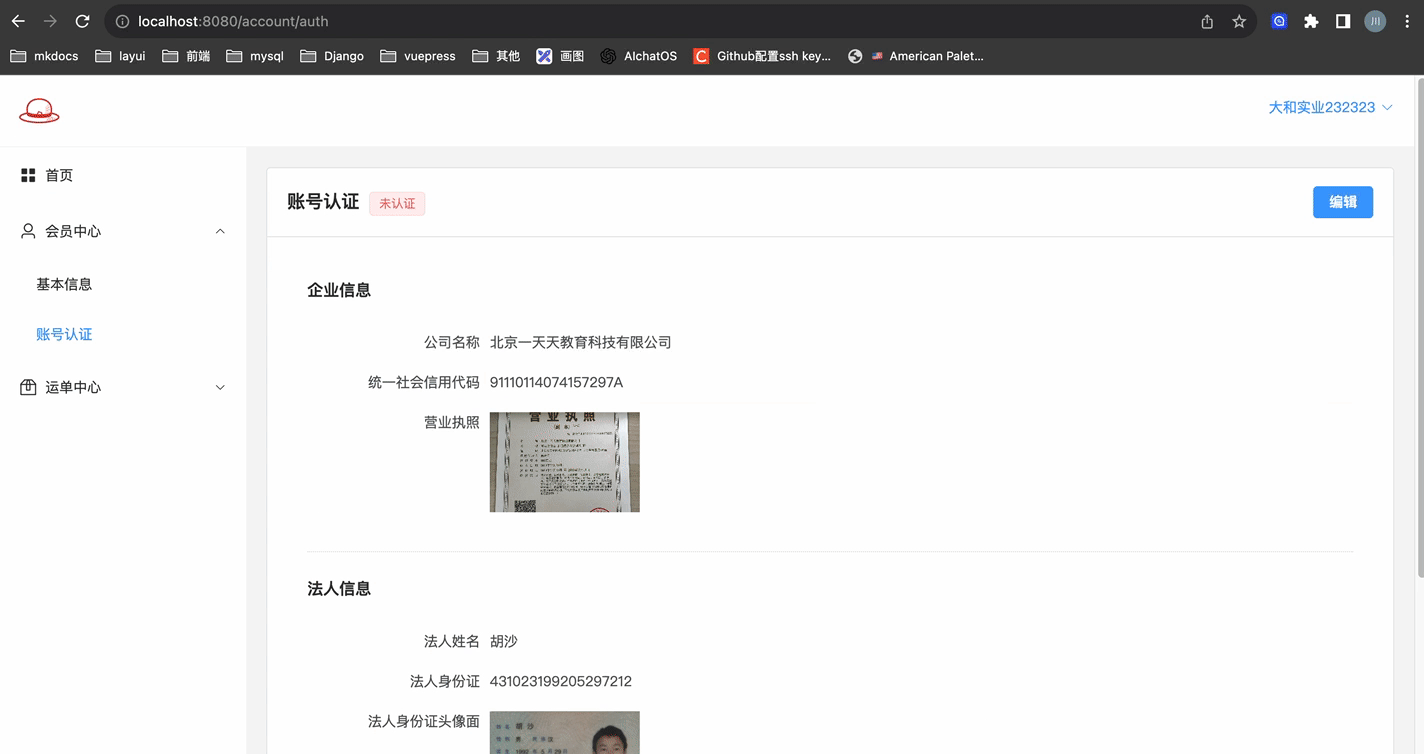
# 账号认证 - 页面A
实现账号认证,相关信息的展示页面
页面展示效果如下:
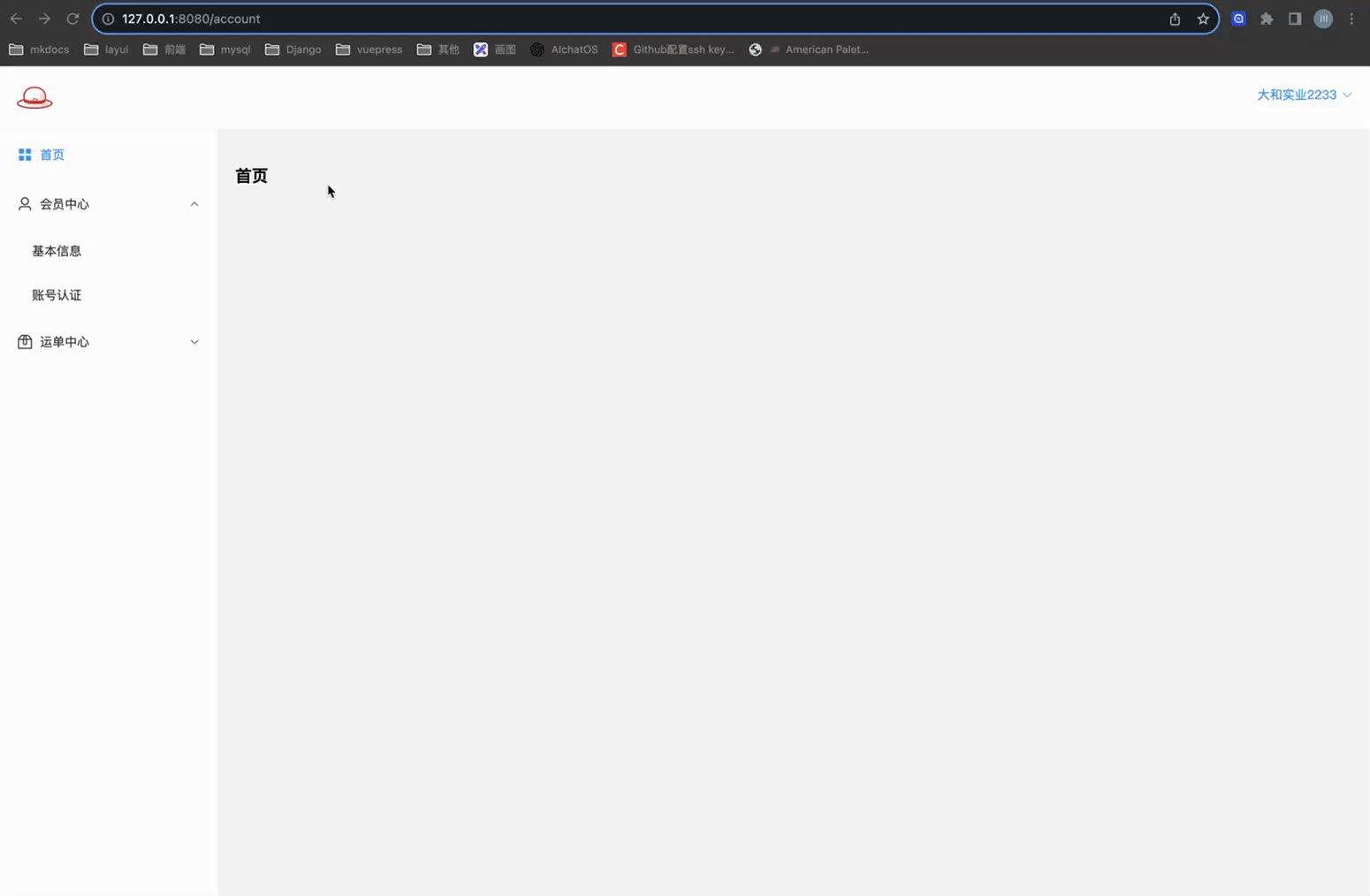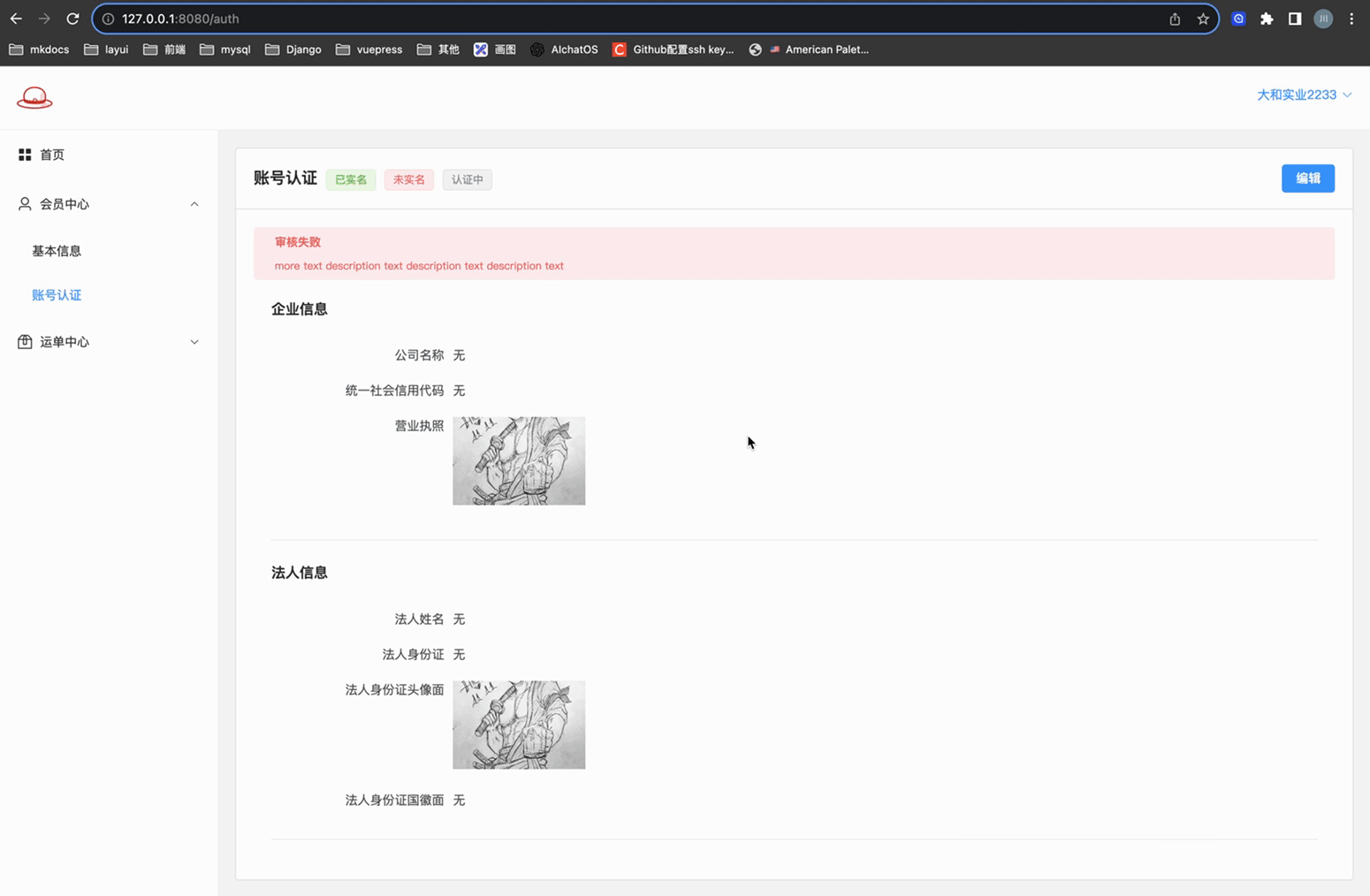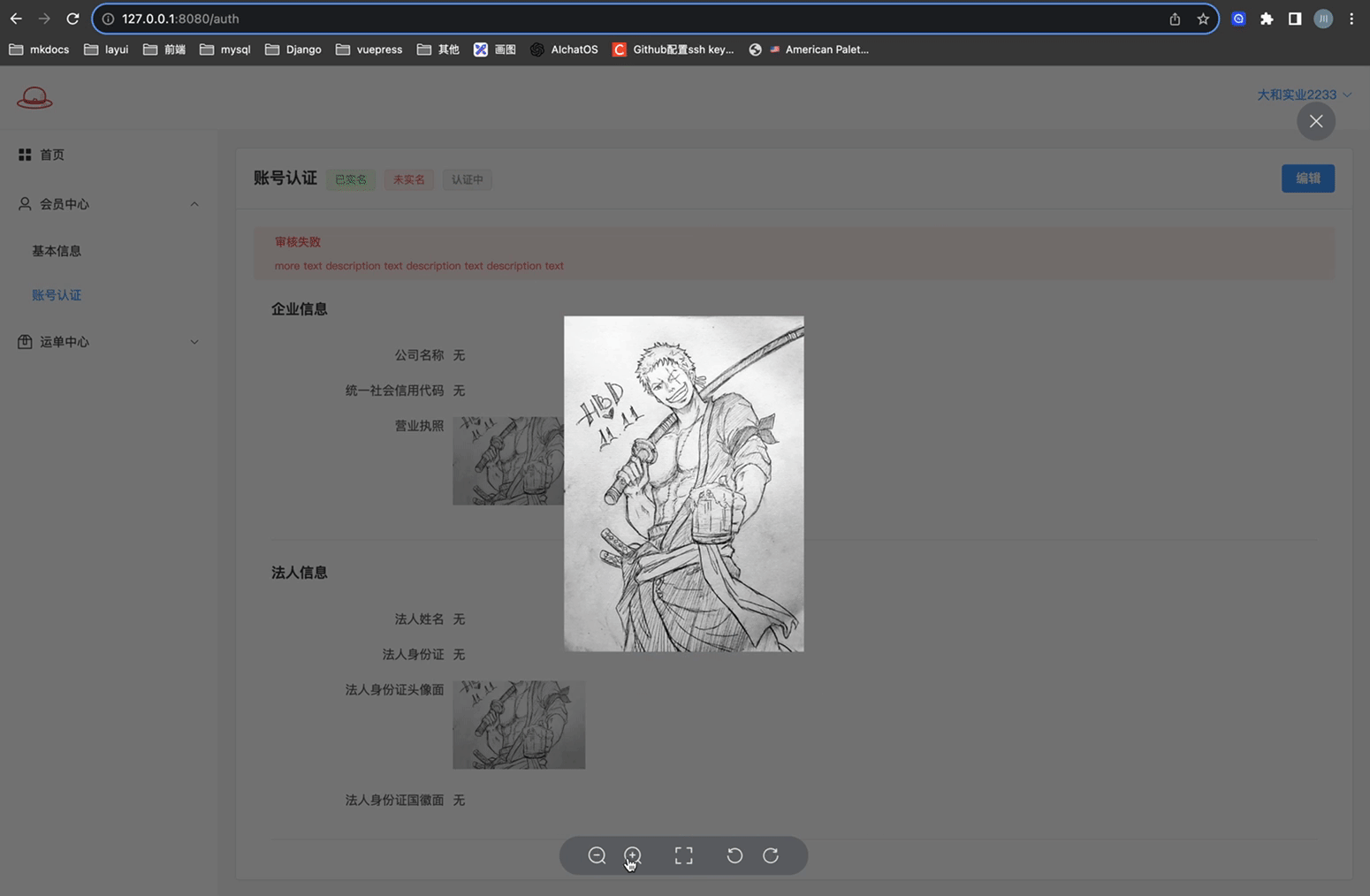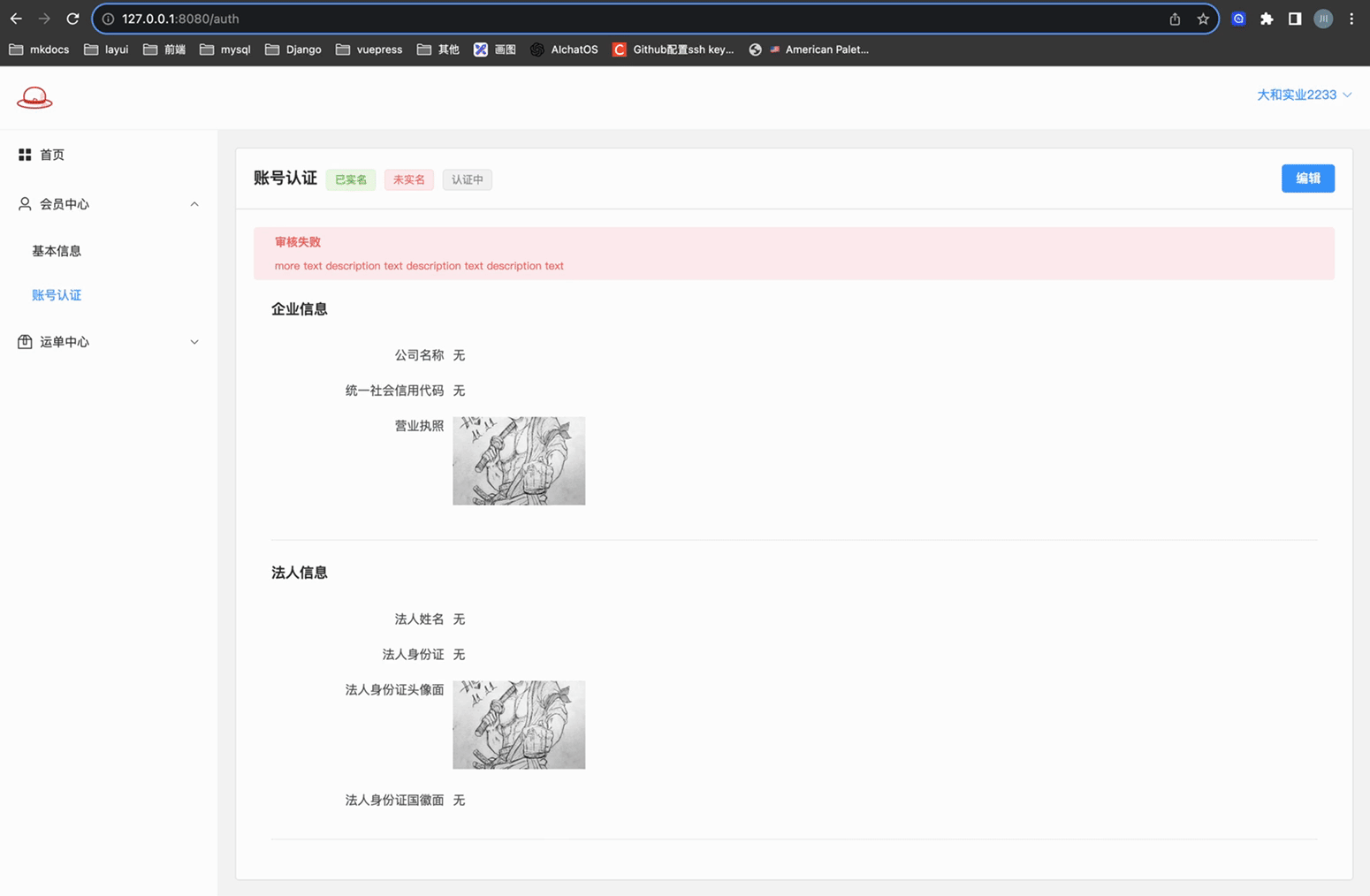
关键代码如下:
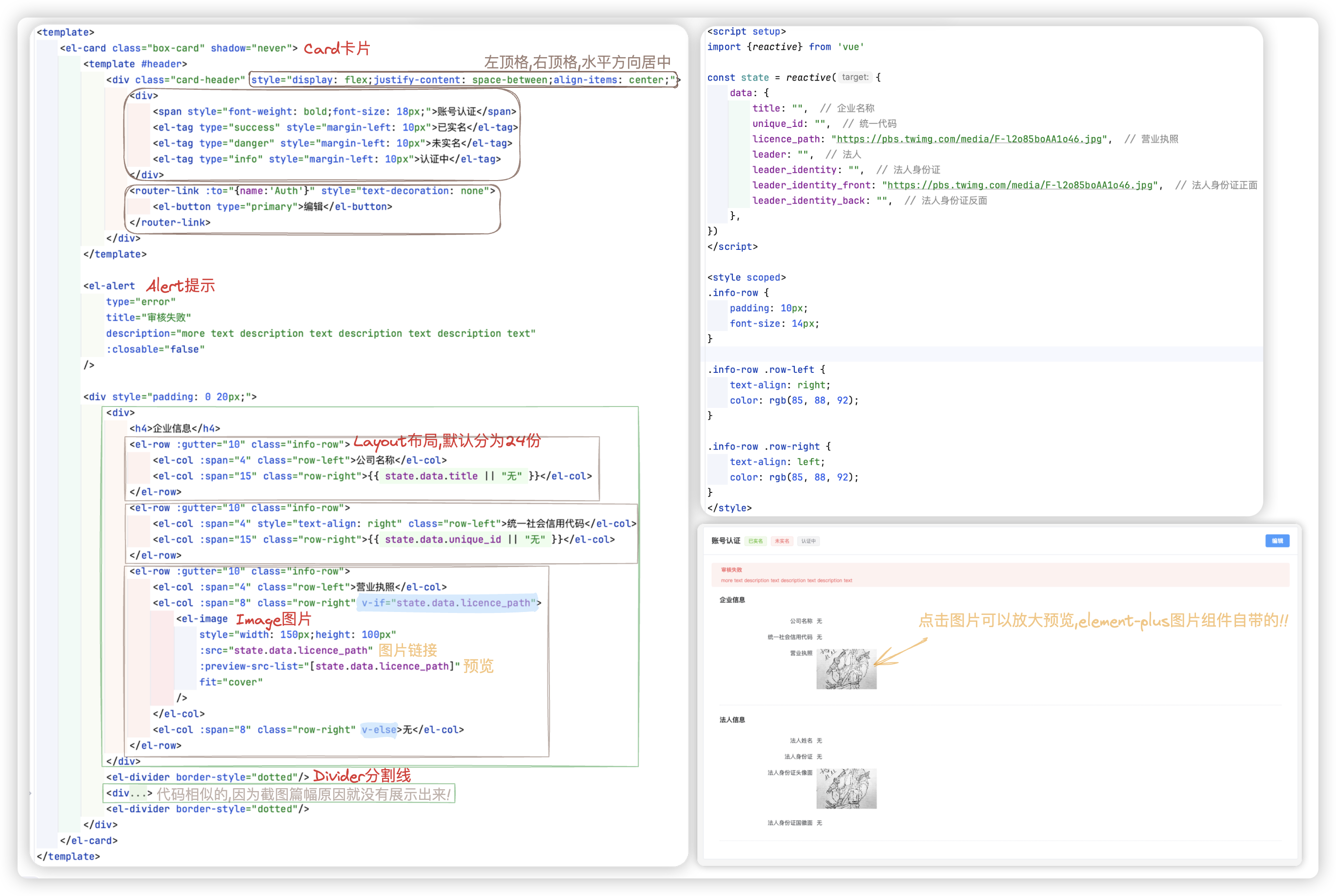
# 账号认证 - 页面B+上传
点击编辑按钮, 跳转认证信息的编辑界面! + 实现上传(elmentPlus 组件会自动发送POST请求进行上传)
该页面的html太多了,不好截图.. 此小节重点展示两种上传是如何实现的!!
说在前面:
- upload组件中:data属性,是用于后面图像识别时区分正反面用的
- licence_path 为了提交审核到数据库中,存储到数据库中的图片路径不应该携带前面的域名信息
licence_path_url 为了预览,用作预览肯定得是全部路径
leader_identity_front、leader_identity_front_url 同理
leader_identity_back、leader_identity_back_url 同理
2
3
4
5
6
先来看看最终效果
# 预览图片可放大
营业执照可以上传并预览放大..
应用的是elementplues Upload上传组件上 自定义缩略图+拖拽上传 这两种方式的结合..
上传了图片展示预览并可以放大; 没有上传图片展示上传框!

# 只简单预览
身份证正面和身份证反面就简单的上传并预览
应用的是elementplues Upload上传组件上 用户头像 这种方式!
# 账号认证 - AI识别
基于百度AI接口对上传图片内容进行识别
领取身份证识别的免费额度 https://cloud.baidu.com/doc/OCR/s/fk3h7xu7h 卡证OCR
创建应用
- AppID 45048380
- API Key zE9gQFGOkXKiDO5TSqyAb6o5
- Secret Key By0BjaPWp1ydPIx7ReDuhpuBoWGvM8Wm
参考官方API文档进行调用
2
3
4
5
6
先来看看是咋样的!!
# 调用官方接口
调用官方识别接口
1> 因为身份证识别和营业执照识别的接口代码基本一致,我根据前端传递的图片类型(front、back、licence)进行了一下封装.
2> 为了避免调用官方接口获取access_token,我们会将access_token放到redis中进行缓存.
access_token有过期时间,默认为30天,到期后可重新调用官方接口获取新的access_token进行缓存.
server/utils/baidu_ai.py
import requests
from django_redis import get_redis_connection
import base64
def get_token():
"""获取access_token"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": "zE9gQFGOkXKiDO5TSqyAb6o5",
"client_secret": "By0BjaPWp1ydPIx7ReDuhpuBoWGvM8Wm",
}
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload, params=params)
if response:
data_dict = response.json()
return data_dict["access_token"]
def save_token_to_redis(access_token):
"""将access_token缓存到redis数据库中,避免频繁调用官方的对应API引发异常"""
conn = get_redis_connection("default")
conn.set("access_token", access_token, ex=2592000)
def get_token_from_redis():
"""第一次调用时,会进行redis缓存操作,往后的调用就直接从缓存中取了;过期导致不存在,直接重新调用API获取并进行缓存;"""
conn = get_redis_connection("default")
access_token = conn.get("access_token") # 取出来的是bytes数据
if not access_token:
access_token = get_token()
save_token_to_redis(access_token)
return access_token
return access_token.decode("utf-8")
def recognize(img_type, img_content):
"""根据图片的类型(身份证正面、反面、营业执照) 来调用官方API进行识别"""
request_url = ""
if img_type == "front" or img_type == "back":
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/idcard"
elif img_type == "licence":
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/business_license"
# - 基于本地文件的识别
# f = open('x.jpeg', 'rb')
# img = base64.b64encode(f.read())
# - 基于上传文件的识别
img = base64.b64encode(img_content)
params = {"id_card_side": img_type, "image": img} # front正面/back反面
# access_token是从redis中获取的.
access_token = get_token_from_redis()
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
return response.json()
if __name__ == '__main__':
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'dahe.settings')
django.setup()
f = open('x.jpeg', 'rb')
res_dict = recognize(img_type="front", img_content=f.read())
for k, v in res_dict["words_result"].items():
print(k, v)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
apps/shipper/views/auth.py 其实跟前面的上传逻辑的代码相比,增加了 ★▲● 标记地方的代码.
import os
from datetime import datetime
from django.conf import settings
from django.core.files.storage import default_storage
from rest_framework import serializers
from rest_framework.decorators import action
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from apps.repository import models
from server.ext import ret
from server.utils import baidu_ai
class AuthModelSerializers(serializers.ModelSerializer):
class Meta:
model = models.CompanyAuth
fields = "__all__"
class AuthView(ModelViewSet):
queryset = models.CompanyAuth.objects.all()
serializer_class = AuthModelSerializers
@staticmethod
def get_upload_filename(file_name):
"""
自己写了一个静态方法用于获取上传的文件在media目录下存储的路径!
若上传的图片重名了,会自动处理
"""
date_path = datetime.now().strftime('%Y/%m/%d') # date_path --> '2023/12/14'
upload_path = os.path.join(settings.UPLOAD_PATH, date_path) # upload_path --> 'upload/2023/12/14'
file_path = os.path.join(upload_path, file_name) # file_path --> upload/2023/12/14/存储器.png
# 图片重名了,会自动处理 upload_url --> upload/2023/12/14/存储器_E9M9jvo.png
upload_url = default_storage.get_available_name(file_path)
return upload_url
@action(methods=['GET', 'POST'], detail=False, url_path='upload', url_name='upload ')
def upload(self, request):
try:
upload_object = request.FILES.get("file")
if upload_object.size > 10 * 1024 * 1024:
return Response({
"code": ret.UPLOAD_ERROR,
"msg": "文件太大!"
})
# ★▲● 识别图片
img_type = request.data.get("type")
img_content = upload_object.read()
img_info = baidu_ai.recognize(img_type, img_content) # 调用官方识别接口.
# 你别问我为何要这么判断,测试一步步实践出来的..
if not img_info.get("words_result", ""):
return Response({
"code": ret.Baidu_AI,
"msg": "图片识别失败!"
})
upload_url = self.get_upload_filename(upload_object.name) # 获取上传的文件在media目录下存储的路径!
# ★ 注意,上面识别图片时,图片的指针已经到最后了,再执行upload_object.read()是没东西的.需要将文件的指针先移到开头!!
upload_object.seek(0) # ★▲●
default_storage.save(upload_url, upload_object) # 自动在media下创建目录并保存上传的文件
# local_url --> /media/upload/2023/12/14/%E5%AD%98%E5%82%A8%E5%99%A8_E9M9jvo.png
local_url = default_storage.url(upload_url)
# asb_url --> http://127.0.0.1:8000/media/upload/2023/12/14/%E5%AD%98%E5%82%A8%E5%99%A8_LzKBcwY.png
asb_url = request.build_absolute_uri(local_url)
# 注意,请务必查看前端引用的第三方上传组件是否规定了后端返回的数据结构是怎么样的.比如{status:0}
context = {
"code": ret.SUCCESS,
"data": {
'url': local_url, # 图片在后端服务器上存储的路径
'abs_url': asb_url, # 图片在后端服务器访问的路径
'img_info': img_info, # 前端上传图片的结果 ★▲●
'img_type': img_type # 图片的类型 ★▲●
}
}
return Response(context)
except Exception as e:
return Response({"code": ret.SUMMARY_ERROR, 'msg': '上传图片失败,请联系管理员!'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
# 前端绑定渲染
前端获取到数据后,进行数据绑定,将图片识别结果渲染到表单中.
PS: 因为上传图片是需要时间的,所以还加入了loading组件,给用户更好的体验..
<template>
<el-card class="box-card" shadow="never" v-loading="state.loading" element-loading-text="上传图片中!">
...
</el-card>
...
</template>
<script setup>
...
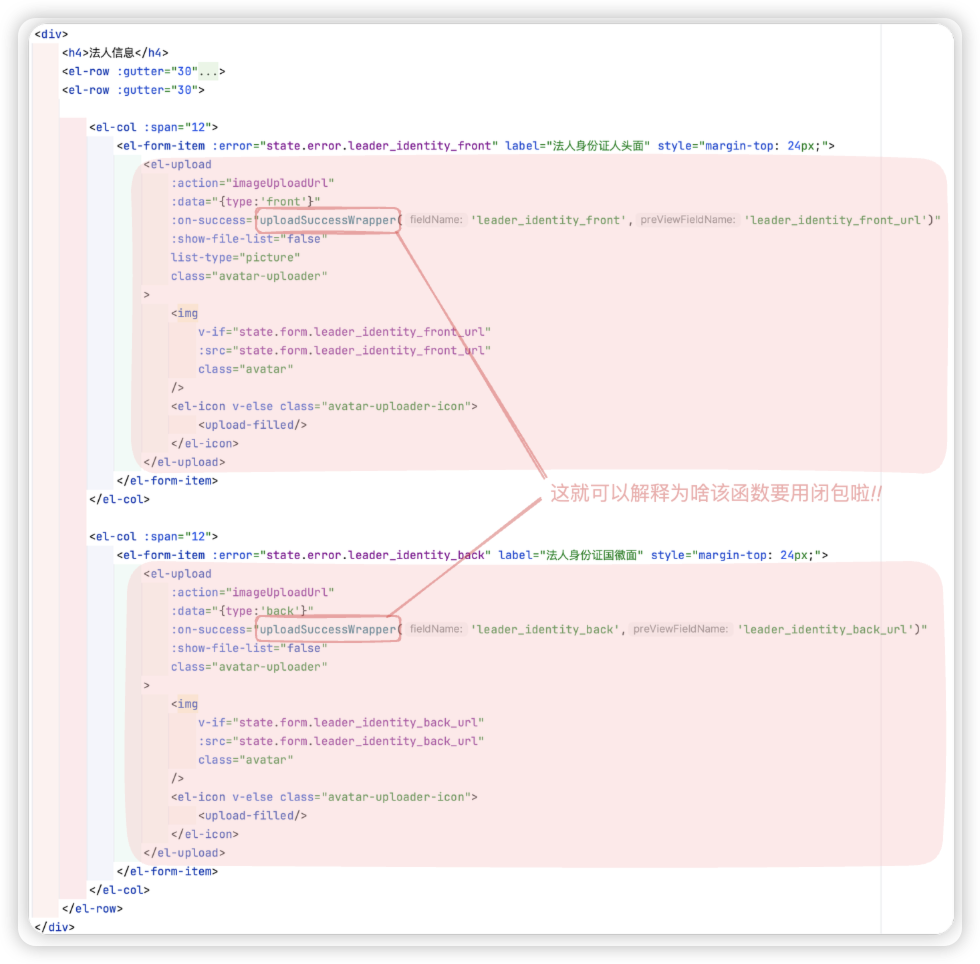
// 该组件中的三个上传都加了 :before-upload="beforeImageUpload" , 其实可以将其进一步优化成闭包!!
function beforeImageUpload(file) {
const isPNG = file.type === 'image/png' || file.type === 'image/jpeg';
const isLt2M = file.size / 1024 / 1024 < 20;
if (!isPNG) {
ElMessage.error("上传图片的格式 png 或 jpeg!");
}
if (!isLt2M) {
ElMessage.error("上传图片大小不能超过 20MB!");
}
if (isPNG && isLt2M) {
state.loading = true; // ●△
return true
} else {
return false
}
}
function uploadSuccessWrapper(fieldName, preViewFieldName) {
return function imageUploadSuccess(res) {
state.loading = false; // ●△
if (res.code === 0) {
state.form[fieldName] = res.data.url;
state.form[preViewFieldName] = res.data.abs_url;
// ●△
if (res.data.img_type === "licence") {
state.form["title"] = res.data.img_info["words_result"]["单位名称"]["words"];
state.form["unique_id"] = res.data.img_info["words_result"]["社会信用代码"]["words"];
} else if (res.data.img_type === "front") {
state.form["leader"] = res.data.img_info["words_result"]["姓名"]["words"];
state.form["leader_identity"] = res.data.img_info["words_result"]["公民身份号码"]["words"];
}
} else {
ElMessage.error('上传失败:' + res.msg);
}
}
}
...
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 账号认证 - 页面A初始化
进入账号认证-页面A时,应获取当前登陆用户所对应的认证信息.
# 无数据
前端访问http://192.168.2.106:8080/account/auth
该页面加载时向后端APIhttp://127.0.0.1:8000/api/shipper/auth/1/ 发送请求. 账号认证页面A最开始的样子如下:
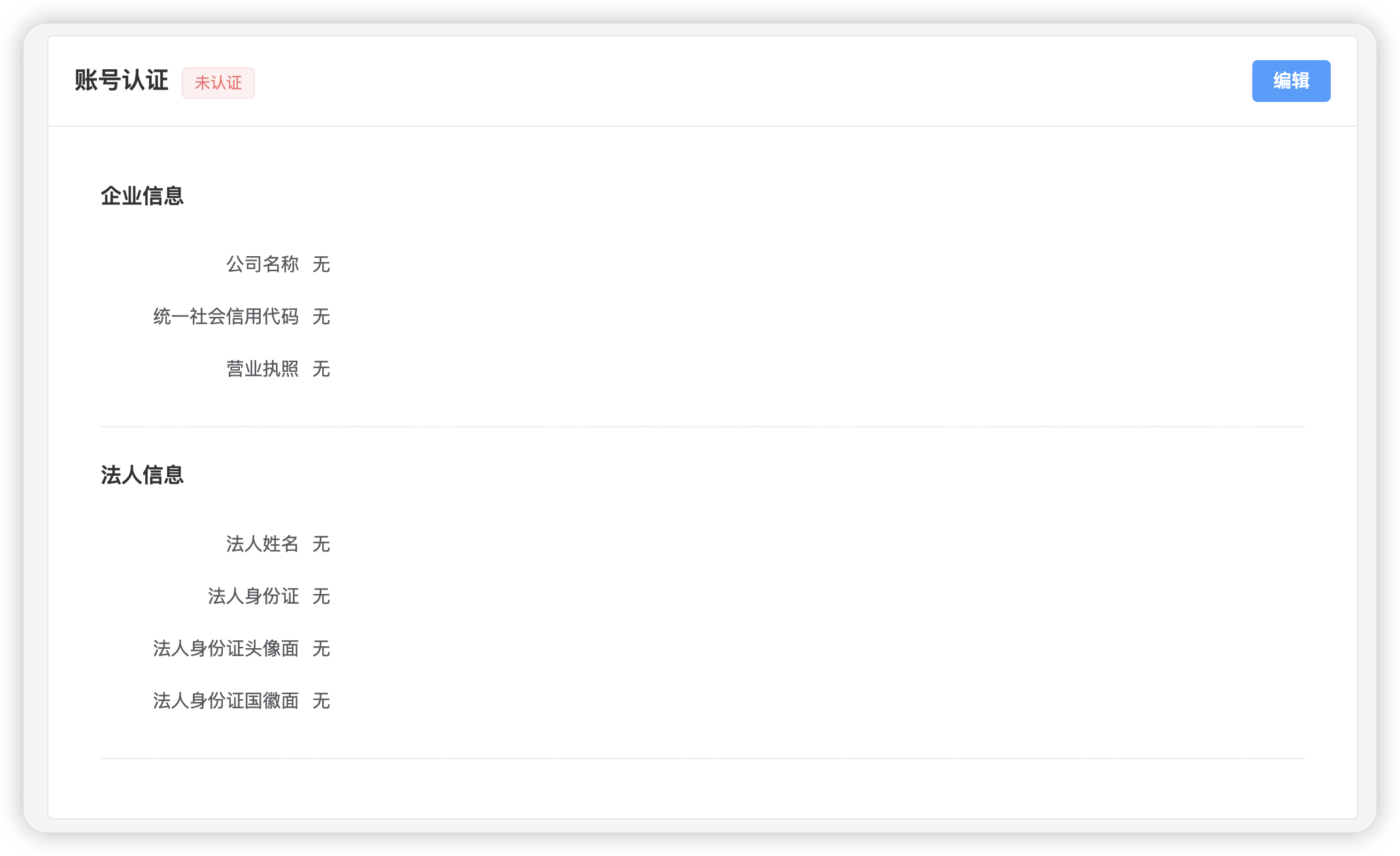
在前面基本信息页面,我们编写过加载初始信息的代码!
我们照猫画虎,大体上是没有啥问题的,实践下来确实如此.但针对账号认证-页面A的初始信息加载,需额外注意两点:
# 注意点1
后端需把"没有找到对象的错误"进行捕获,返回给前端时,前端对code值为-5的情况不做任何处理.
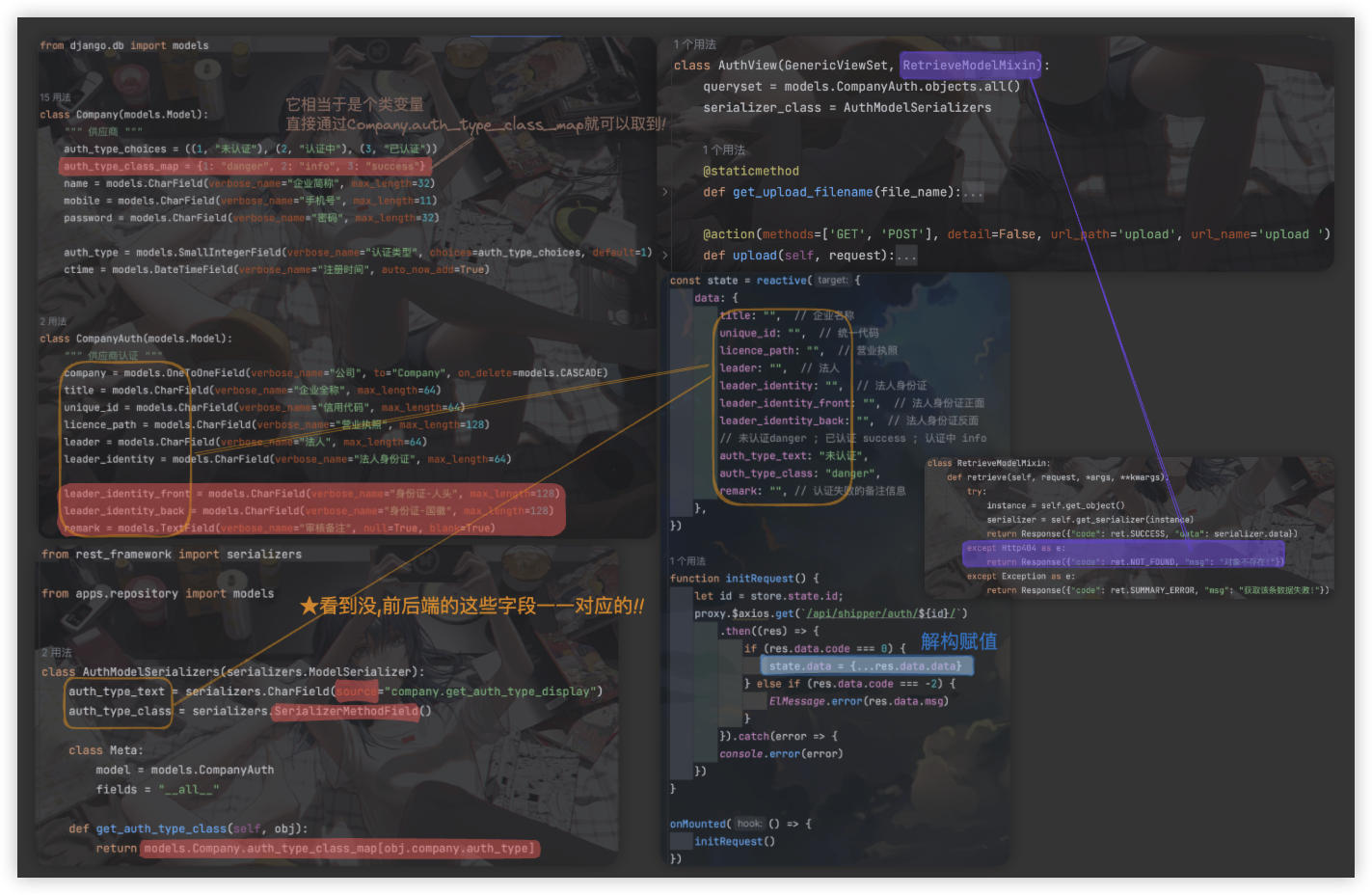
前面已经快速根据SimpleRouter、class AuthView(ModelViewSet) 快速编写了6个接口..
账号认证页面A的初始数据加载属于获取单条数据, 所以 class AuthView(GenericViewSet, RetrieveModelMixin)
一开始,当前登陆用户对应的账号认证相关数据是没有的,即一开始 供应商认证表CompanyAuth是为空的!
这种情况是合理的,允许存在的.
但按照原先获取初始数据的前后端代码.当我们执行 instance = self.get_object() 时,肯定会报错.
报啥错? 没有找到对象! “看get_object对应的源码就明白啦!”
class RetrieveModelMixin:
def retrieve(self, request, *args, **kwargs):
try:
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response({"code": ret.SUCCESS, "data": serializer.data})
except Exception as e:
return Response({"code": ret.SUMMARY_ERROR, "msg": "获取该条数据失败!"})
前端会弹出一个弹出框,说,“获取该条数据失败!”
No! 按照我们的想法,账号认证-页面A的初始化信息时,没找到对象没关系,页面上不弹出这个弹出框即可!
★★★ 如何是好呢?
把没有找到对象的错误进行捕获,返回给前端时,前端对code值为-5的情况不做任何处理.(也不影响前端对code值为-2的情况抛出弹出框.)
把没有找到对象的错误进行捕获具体怎么操作,需要看get_object的源码!!里面有行代码 raise Http404.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
后端关键代码
from rest_framework.response import Response
from django.http.response import Http404
from server.ext import ret
class RetrieveModelMixin:
def retrieve(self, request, *args, **kwargs):
try:
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response({"code": ret.SUCCESS, "data": serializer.data}) # 0
except Http404 as e:
return Response({"code": ret.NOT_FOUND, "msg": "对象不存在!"}) # -5
except Exception as e:
return Response({"code": ret.SUMMARY_ERROR, "msg": "获取该条数据失败!"}) # -2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
前端关键代码
function initRequest() {
let id = store.state.id;
proxy.$axios.get(`/api/shipper/auth/${id}/`).then((res) => {
if (res.data.code === 0) {
// TO Do
} else if (res.data.code === -2) {
ElMessage.error(res.data.msg)
}
}).catch(error => {
console.error(error)
})
}
onMounted(() => {
initRequest()
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 注意点2
账号认证展示什么(未认证/已认证/认证中)、账号认证失败的消息提示, 这些都应由后端返回的数据进行决定.
前端关键代码 截取的片段.
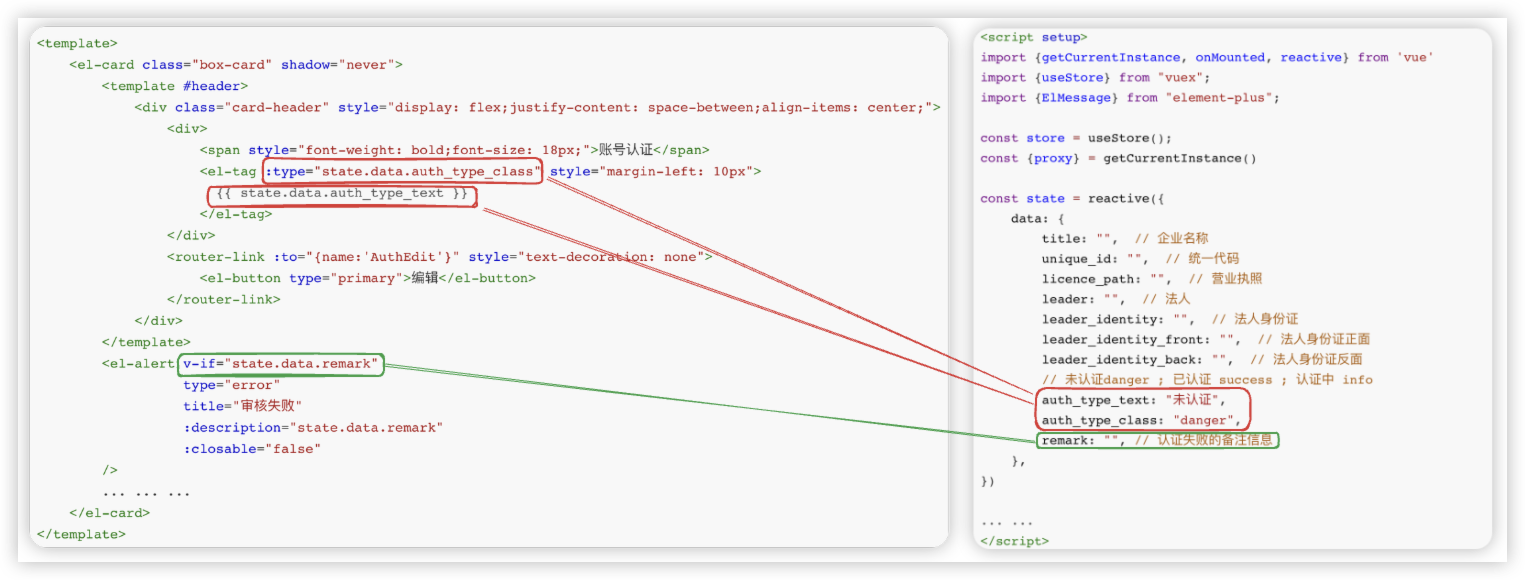
# 有数据
上面的注意点1注意点2, 解决的是新用户第一次打开账号认证页面, 对应的数据表为空的情况!!
我们还需编写对应数据表不为空的时候的业务逻辑代码.. 可参考基本信息页面加载初始信息的笔记.
先来看看效果!

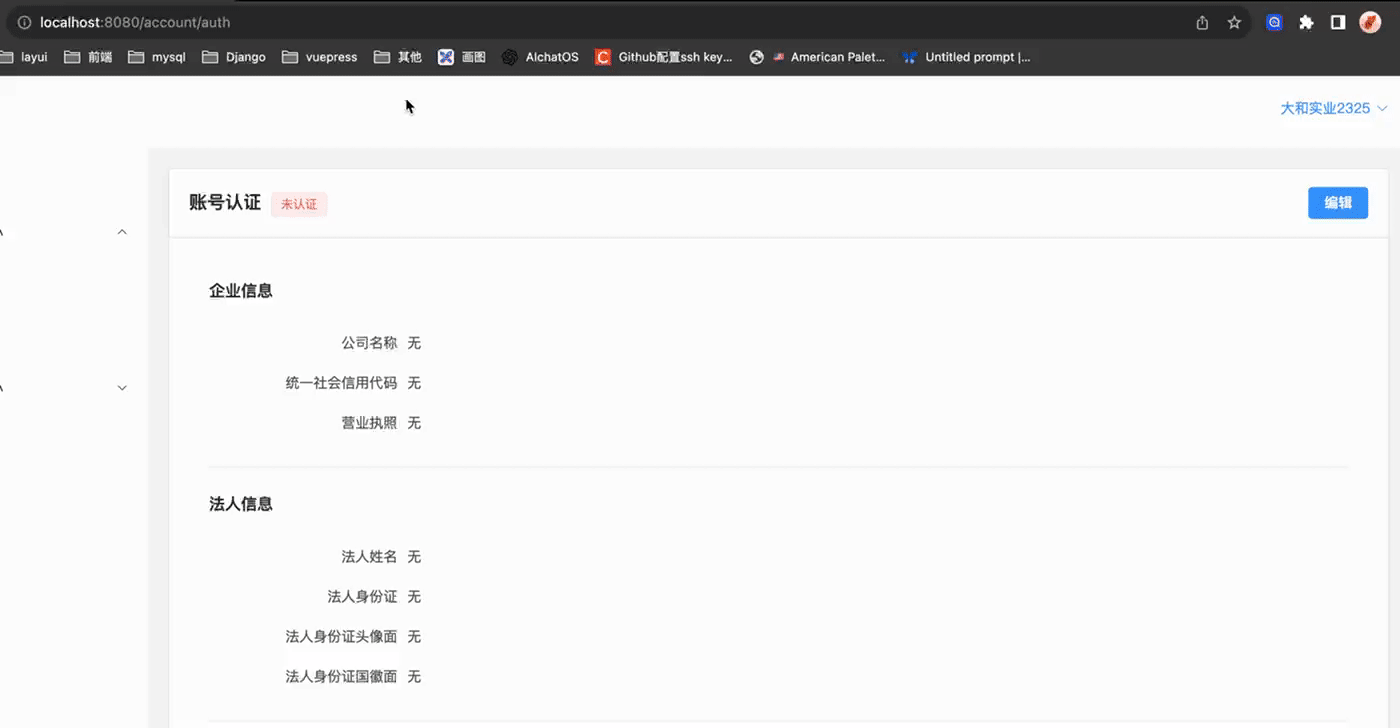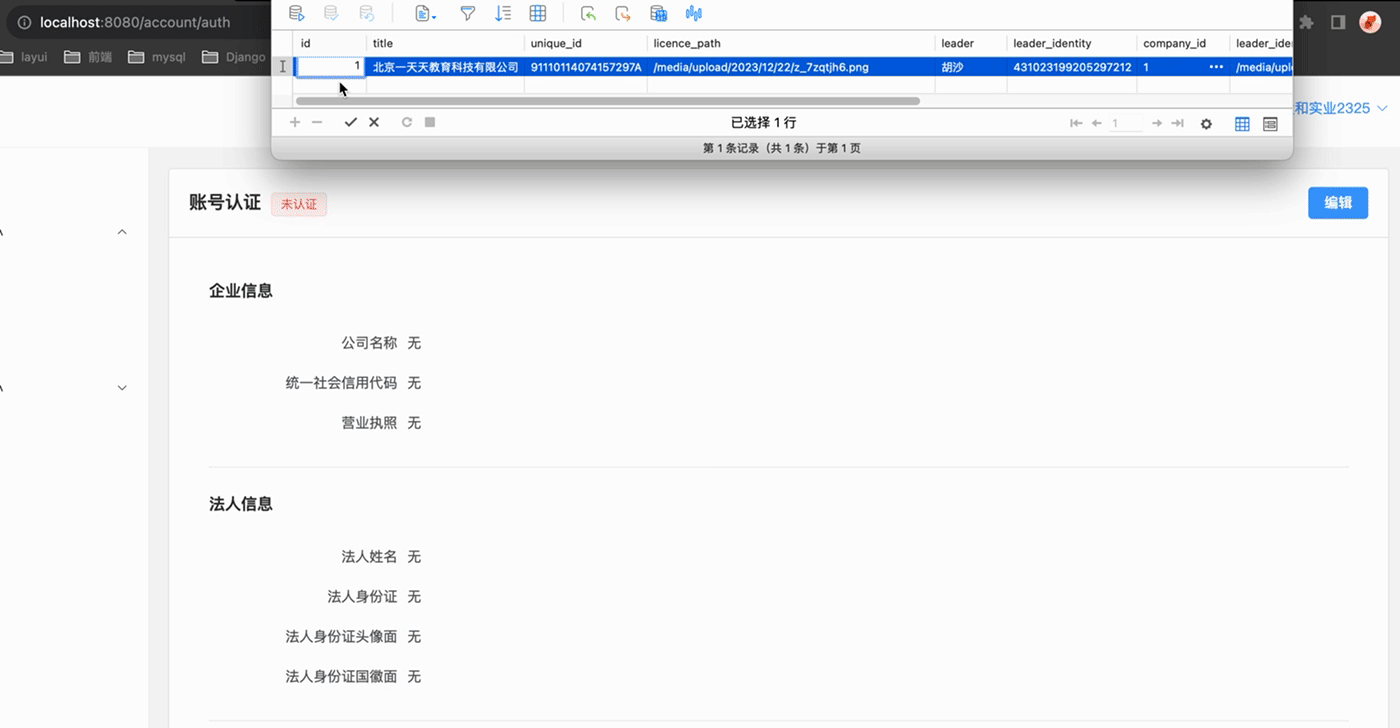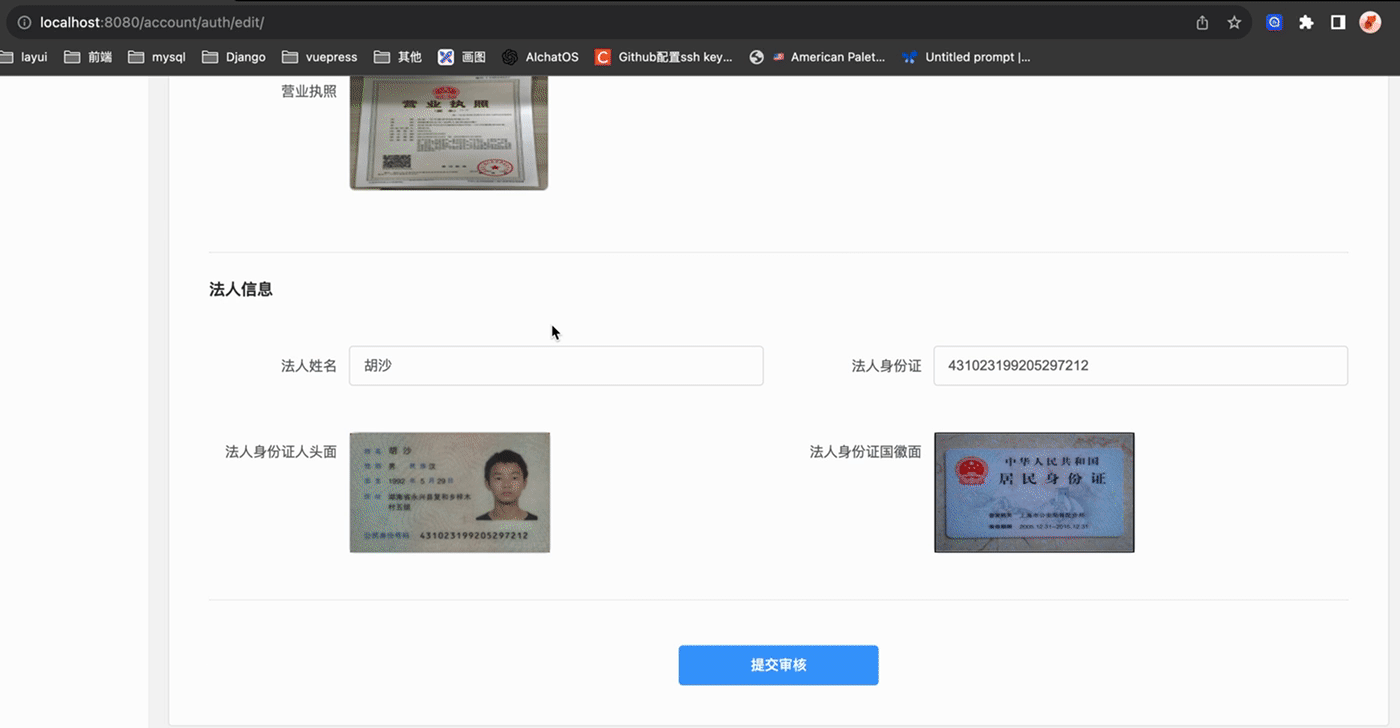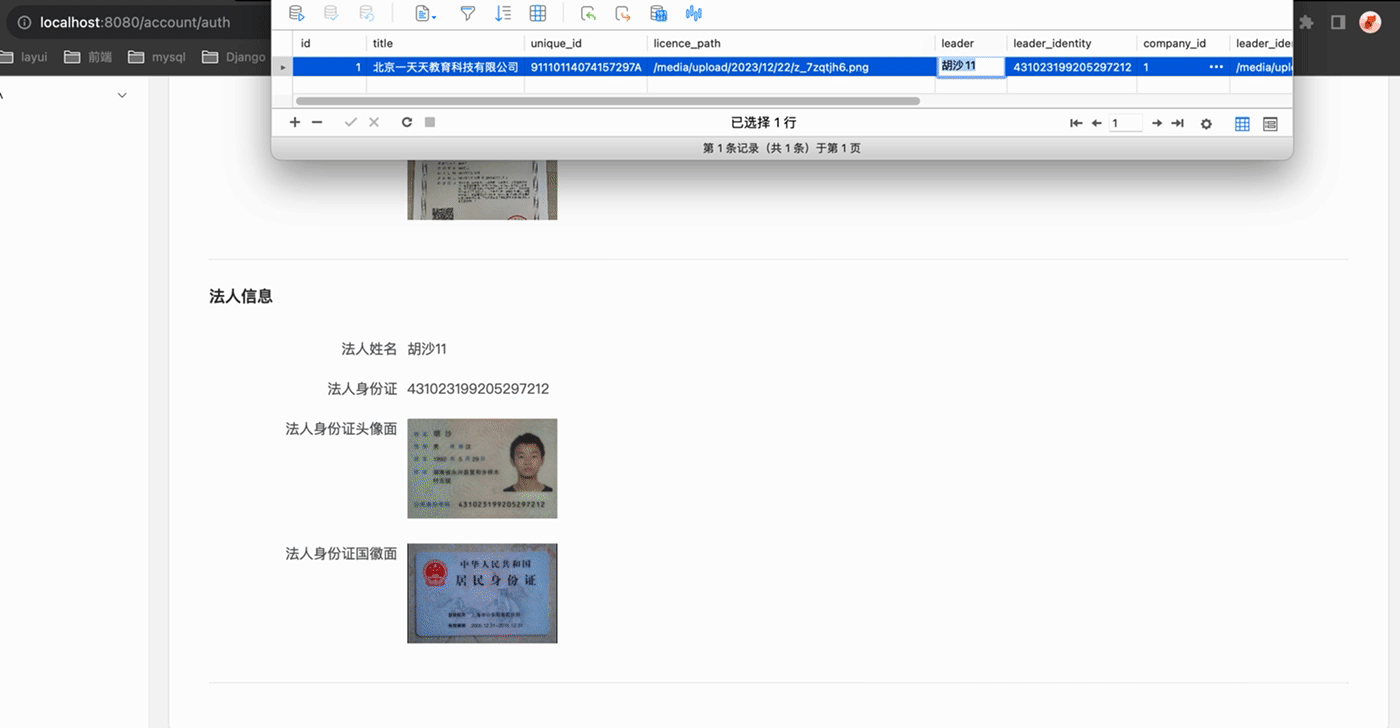
我们先上传了几张图片作为服务端的媒体资源, 然后在供应商认证表CompanyAuth表中手动添加一条记录用作实验!!
◆ 我们先来分析
我们写的视图类继承了重写的RetrieveModelMixin类 “Company:CompanyAuth=1:1”
也就意味着,当供应商认证表CompanyAuth表中有 当前登陆用户/供应商 对应的记录时,会返回该表中的这条记录.
那么返回的那条记录的字段能否满足账号认证-页面A上想要渲染的数据呢?
答案是不能. 还需在已有的基础上增加几个字段 (记得进行数据库数据迁移,迁移时会让你选设置默认值还是设置允许为空)
CompanyAuth表
- leader_identity_front = models.CharField(verbose_name="身份证-人头", max_length=128)
- leader_identity_back = models.CharField(verbose_name="身份证-国徽", max_length=128)
- remark = models.TextField(verbose_name="审核备注", null=True, blank=True)
Company表
- auth_type_class_map = {1: "danger", 2: "info", 3: "success"}
◆ 再继续分析,够了吗?还是不够. 我们需要在获取单条供应商认证信息接口所对应的序列化器类中添加两个额外的字段!!
- 后端还需返回前端认证状态
认证状态在哪?在CompanyAuth表的外键所在的关联表中,额外字段auth_type_text通过source属性跨表来实现!
auth_type_text = serializers.CharField(source="company.get_auth_type_display")
- 后端还需返回前端认证状态的样式,额外字段auth_type_class通过自定义方法来实现!
auth_type_class = serializers.SerializerMethodField()
def get_auth_type_class(self, obj):
# obj是CompanyAuth表中的一条记录, 点语法obj.company通过company外键跨到了Company表,拿到对应的auth_type的值
# models.Company.auth_type_class_map 是一个字典
return models.Company.auth_type_class_map[obj.company.auth_type]
注意:当前登陆用户的ID为1,手动添加的供应商认证的数据ID也为1,不严谨的对应了起来.
“严谨的来说用户(即供应商)应该跟供应商认证表中的那个外键字段值对应,以便于实现当前登陆用户应该只能得到自己的关联的那一条供应商记录”
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
关键代码如下:
Ps: 此示例中在数据库中存储的媒体资源路径是带http前缀的, 像这样 http://127.0.0.1:8000/media/upload/2023/12/18/z.png
其实在数据库中的媒体资源不应该带http前缀,暂且先这样,后续再进行处理!!
# 账号认证 - 页面B初始化
读取认证信息,在页面B上做默认的展示!!
先来看看样子
需要思考的地方:
我们在很早以前就说过,licence_path、licence_path_url的区别,前者是存储数据库中的,不带http前缀;后者用于前端预览,需要带http
So,这里先我们对上一小节 账号认证-页面A初始化 进行完善!
- 将我们在供应商认证表CompanyAuth表中新增的那条记录的licence_path、leader_identity_front、leader_identity_back
去除前面的http,最终样子像这样:/media/upload/2023/12/18/z.png
- 账号认证-页面A 的前端,图片渲染不再使用字段licence_path、leader_identity_front、leader_identity_back
而是使用字段licence_path_url、leader_identity_front_url、leader_identity_back_url
- licence_path_url、leader_identity_front_url、leader_identity_back_url这些前端用作预览的字段
需要后端通过licence_path、leader_identity_front、leader_identity_back拼接http然后返回
到这一步
你仔细观察AuthView.vue和AuthEditView.vue中需要渲染到页面上的那些字段.
它两的初始化可以共用同一个序列化器类!!连发送axios请求的API接口都可以是一样的!!也就是前端组件中初始化的代码基本一致!
这两个组件初始化获得的API数据是一样的:
{
"code": 0,
"data": {
"id": 1,
"auth_type_text": "未认证",
"auth_type_class": "danger",
"licence_path_url": "http://127.0.0.1:8000/media/upload/2023/12/18/z.png%0A",
"leader_identity_front_url": "http://127.0.0.1:8000/media/upload/2023/12/18/x.jpeg",
"leader_identity_back_url": "http://127.0.0.1:8000/media/upload/2023/12/18/y.png",
"title": "北京一天天教育科技有限公司",
"unique_id": "91110114074157297A",
"licence_path": "/media/upload/2023/12/18/z.png\n",
"leader": "胡沙",
"leader_identity": "431023199205297212",
"leader_identity_front": "/media/upload/2023/12/18/x.jpeg",
"leader_identity_back": "/media/upload/2023/12/18/y.png",
"remark": null,
"company": 1
}
}
▲ 若你非要用两个序列化器类,那么可以借鉴 基本信息页面的手机号更改和名称更改!
前端在发送axios请求时加了个type参数,?type=xxx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
最关键的代码如下:
from rest_framework import serializers
from apps.repository import models
class MySerializerMethodField(serializers.SerializerMethodField):
def to_representation(self, value):
"""用于在前面拼接http"""
# ★ 你细品源码可知!
# value 是instance一条记录
# self字段对象; self.parent该字段对象所在序列化器类的实例对象; self.field_name该字段对象的字段名
name = self.field_name.replace("_url", "")
return self.parent.context['request'].build_absolute_uri(getattr(value, name))
class AuthModelSerializers(serializers.ModelSerializer):
auth_type_text = serializers.CharField(source="company.get_auth_type_display")
auth_type_class = serializers.SerializerMethodField()
# licence_path_url = serializers.SerializerMethodField()
licence_path_url = MySerializerMethodField()
leader_identity_front_url = MySerializerMethodField()
leader_identity_back_url = MySerializerMethodField()
class Meta:
model = models.CompanyAuth
fields = "__all__"
def get_auth_type_class(self, obj):
return models.Company.auth_type_class_map[obj.company.auth_type]
# -- ▲ 这个是最容易想到的办法,有三个预览图片地址就要写三个,但通过重写可以不写这些代码!
# def get_licence_path_url(self, obj):
# return self.context['request'].build_absolute_uri(obj.licence_path)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 账号认证 - 页面B提交
细节还是蛮多的!
# ★回顾drf知识
回顾的知识点很重要!!
Django ORM的语法
- 更新时,传了不相干的字段进去也没事;
!!!! 注:若是局部更新哪怕只传一个字段进去即可!
★ 序列化器类中的字段对象摆在那, 前端需要传哪些呢?
"前端必须传的字段需要同时满足三者 可验证的、不为空/必填、没有默认值.."
- 新增的话,必须一个不多一个不少,当然ORM表中允许为空和有默认值的字段可不传.
验证-存储-序列化大体逻辑
- 验证会从request.data中取值!
注: 一般情况下,字段对象自身验证规则是必填,但允许为空和设置了默认值的字段对象自身验证规则是不必填!
★ 意思是, 该字段是需要验证的字段,但该字段不是必填的(允许为空或有默认值), 那么前端也可以不用传!!
- 验证成功后的数据关乎save操作,也就是说,验证成功的数据ser.validated_data与数据库相关
注: save时, **validated_data解包后的键名是字段对象的source_attr
★ 换个角度,read_only=True的字段不验证,也就跟save无关,也就不涉及新增更新. Hhh
但序列化跟save后的返回值instance有关!
- 无论save执行的是新增还是更新操作,都有一个返回值instance,是当前数据库中新增或更新的那条记录.
注: 进行序列化返回时,执行的是 "instance.字段对象的source_attr" 的操作!!
若验证后没有save直接序列化,序列化的数据是ser.validated_data
- 额外说一点,关于save时的源码 当验证成功的数据中b的值是2,我可以在save是传b=3,就可以覆盖前面那个b的值!!
def func1(*args, **kwargs):
print(kwargs) # {'b': 3}
my_dict = {"a": 1, "b": 2}
print({**my_dict, **kwargs}) # {'a': 1, 'b': 3}
func1(b=3)
源码的dispatch方法中
def dispatch(self, request, *args, **kwargs): # self是视图类实例; *args,**kwargs是路由上传递的参数
self.args = args
self.kwargs = kwargs # 看到没,视图类实例是可以直接取到动态路由上传递的参数的!
request = self.initialize_request(request, *args, **kwargs)
self.request = request # 看到没,视图类实例是可以直接取到封装好的request的!
GenericAPIView中的过滤
你看源码就可以知道,我们自定义的过滤类中filter_queryset方法的view形参就是视图类实例!!
进行反向查询时,没有查到会报错
try:
auth_id = instance.companyauth.pk
except models.CompanyAuth.DoesNotExist:
auth_id = 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 思考问题:
关于账号认证-页面B的提交, 先来思考几个问题
# 请求类型
Q1: 点击"提交审核"按钮, 是向后端API发送 POST 请求还是 PUT 请求呢?
当我们点击“提交审核”按钮时,是有两种可能的,一种是新增、一种是新建
在我们已有的认知里,根据RESTful API规范
往http://127.0.0.1:8000/api/shipper/auth/ 发送POST请求 是新增
往http://127.0.0.1:8000/api/shipper/auth/1/ 发送PUT请求 是更新
那么问题来了,点击“提交审核”按钮时,应该往哪个地址发数据axios请求呢?
- 前端在vue组件里判断,没数据就往新增地址提交,否则就往更新地址提交 具体实现起来比较费劲
- ★ 我们采取扩展方案,不必一味的遵循RESTful API规范
前端就往http://127.0.0.1:8000/api/shipper/auth/发送POST请求
后端进行判断,数据不存在就执行新增逻辑,存在就执行更新逻辑!! ==> 在我们重写的CreateUpdateModelMixin的create方法里实现!
- 我们自己写的视图类是这样写的,class AuthView(GenericViewSet, RetrieveModelMixin, CreateUpdateModelMixin):..
注:GenericViewSet = ViewSetMixin + GenericAPIView
按照运行逻辑,向后端地址/api/shipper/auth/发送POST请求,后端会执行create这个视图函数.
2
3
4
5
6
7
8
9
10
11
12
# 请求体数据
Q2: OK,我们确定了点击"提交审核"按钮向后端发送POST请求, 那么请求体中应该包含哪些字段?
- 在AuthEditView.vue组件中,向后端API发送的请求的请求体中理应不包含预览图片相关的字段
即理应不包含licence_path_url、leader_identity_front_url、leader_identity_back_url字段
(预览图片相关字段的值都带有http前缀,后端拿来没用,存储到数据库中的值是不带http前缀的)
1> 此处我们将其从state.form中提取出来放到了state.preview中
const state = reactive({
dialogLicenceVisible: false,
loading: false,
// 需提交到后端的字段
form: {
tile: "",
unique_id: "",
licence_path: "",
leader: "",
leader_identity: "",
leader_identity_front: "",
leader_identity_back: "",
},
// 我们没有做前端校验,但后端返回code=-1时还是需要在相应表单字段下展示错误信息
error: {
title: "", unique_id: "", licence_path: "", leader: "",
leader_identity: "", leader_identity_front: "", leader_identity_back: "",
},
// 预览图片相关字段无需提交到后端
preview: {
licence_path_url: "",
leader_identity_front_url: "",
leader_identity_back_url: "",
}
})
2> vue组件<template>模版中对应预览图片字段值的渲染要相应进行改变下
3> 在uploadSuccessWrapper(fieldName, preViewFieldName)这个闭包函数中,当成功上传图片后,需要这样做
state.form[fieldName] = res.data.url;
state.preview[preViewFieldName] = res.data.abs_url;
- 对AuthEditView.vue组件中的数据进行划分后,晃眼看去,对于点击"提交审核"按钮触发的doSubmit方法发送的axios请求里
其请求体操作写上state.form即可!!
function doSubmit() {
clearFormError(state.error)
proxy.$axios.post("/api/shipper/auth/", state.form).then((res) => {
console.log(res)
}).catch(error => {
console.error(error)
})
}
- 理论上没有任何问题,实则页面B的初始化数据加载的代码埋下的大坑在这里触发了!!
你点击"提交审核"的按钮,右键检查查看网络请求,可以发现请求体里的字段是页面初始化请求后端返回的那些字段..
问题的根源就是 initRequest 方法里的这两行代码,进行了覆盖!! (当时图方便的埋下的坑啊)
state.form = {...res.data.data}
state.preview = {...res.data.data}
- 如何解决? 将那两行代码替换成下面的代码!
for (let key in res.data.data) {
if (key in state.form) {
state.form[key] = res.data.data[key];
}
if (key in state.preview) {
state.preview[key] = res.data.data[key];
}
}
// state.form = {...res.data.data}
// state.preview = {...res.data.data}
- 其实不管这个坑,请求体的数据提交多了也没事!! (你站在通过Apifox发送请求的角度思考,后端肯定不能说传过来了啥就要啥)
licence_path_url、leader_identity_front_url、leader_identity_back_url这些字段前端提交到后端也无大碍
后端的序列化器类里会将这三个字段设置为 read_only=True 的!!
意味着,哪怕你前端给了后端,后端也不会对其进行校验!!不校验也就意味着read_only=True的字段跟save无关,也就不涉及新增更新.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# Upload组件后端认证
这个是前面小节 "后端上传文件" 中遗留的问题. 这里单独用一小节提出来解决下!
后续认证的逻辑代码必定会在AuthView视图类中添加认证类, 保证登陆后才能访问AuthView类中的这些接口..
(包括 图片上传的 http://127.0.0.1:8000/api/shipper/auth/upload/ 这个接口!)
一般, 前端发送的axios请求会通过axios拦截器在发送前添加包含token信息的请求头, 后端的认证组件对token信息进行验证!
但前端的upload上传组件的请求是自动完成的!! 请求到了后端, 就存在认证失败的问题.
如何解决呢?
前端需进行的操作
方案一: 查看elementplus的官方文档,在upload组件上添加个headers属性是可以解决的.
方案二: 在图片上传的 http://127.0.0.1:8000/api/shipper/auth/upload/ 这个接口后面拼接token信息!
方案一页面上每个上传的地方都要加,我们嫌麻烦,此处我们采取方案二!!
const imageUploadUrl = `http://127.0.0.1:8000/api/shipper/auth/upload/?token=${store.state.token}`
后端需进行的操作
编写认证类并在AuthView视图类中进行应用.
authentication_classes = [JwtAuthentication, JwtParamAuthentication, NoAuthentication]
PS: 若没有NoAuthentication,编写时JwtParamAuthentication认证失败返回None,JwtAuthentication认证失败raise
那么JwtParamAuthentication需要在前;JwtAuthentication需要在后!! 需要注意先后顺序!!
why? 复习下def的认证类就很容易理解了!! 注:AuthView视图类中的接口都会经历authentication_classes里的认证类的!!
2
3
4
5
6
7
8
9
10
11
12
后端关键代码如下:
from rest_framework import exceptions
from rest_framework.authentication import BaseAuthentication
from server.utils.jwt_auth import parse_payload
class JwtAuthentication(BaseAuthentication):
"""从请求头中获取token进行校验"""
def authenticate(self, request):
authorization = request.META.get('HTTP_AUTHORIZATION', '')
status, info_or_error = parse_payload(authorization)
# if not status:
# raise exceptions.AuthenticationFailed({"code": 8888, 'msg': info_or_error})
if not status:
# request.info_or_error = info_or_error
return
return info_or_error, authorization
def authenticate_header(self, request):
return 'API'
class JwtParamAuthentication(BaseAuthentication):
"""从请求url中获取token进行校验"""
def authenticate(self, request):
authorization = request.query_params.get('token')
status, info_or_error = parse_payload(authorization)
if not status:
return
return info_or_error, authorization
def authenticate_header(self, request):
return 'API'
class NoAuthentication(BaseAuthentication):
"""从请求url中获取token进行校验"""
def authenticate(self, request):
raise exceptions.AuthenticationFailed({"code": 8888, 'msg': "认证失败,请重新登陆"})
def authenticate_header(self, request):
return 'API'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# CreateUpdateModelMixin
CreateUpdateModelMix 中 包含新增以及更新!!
# 测试新增
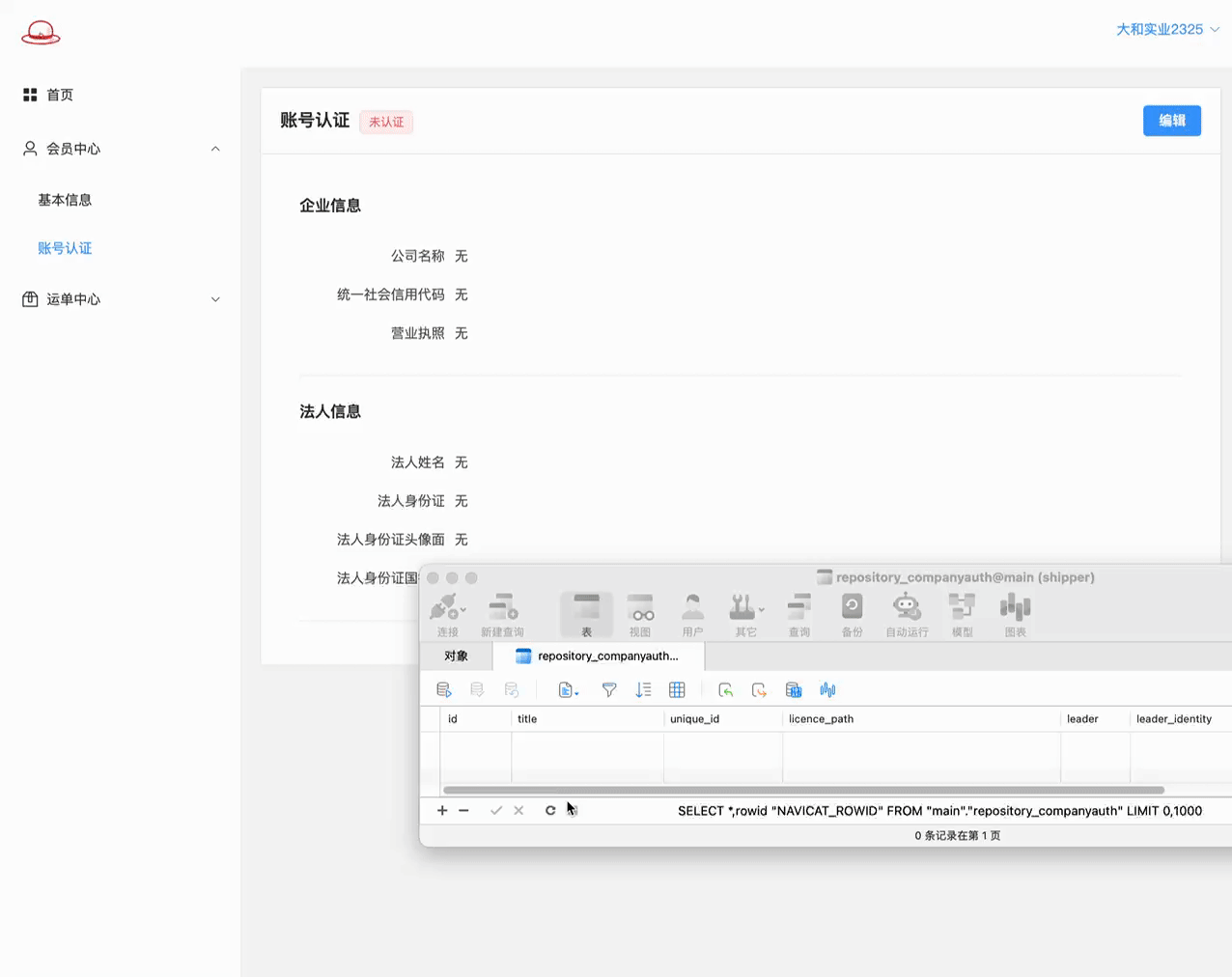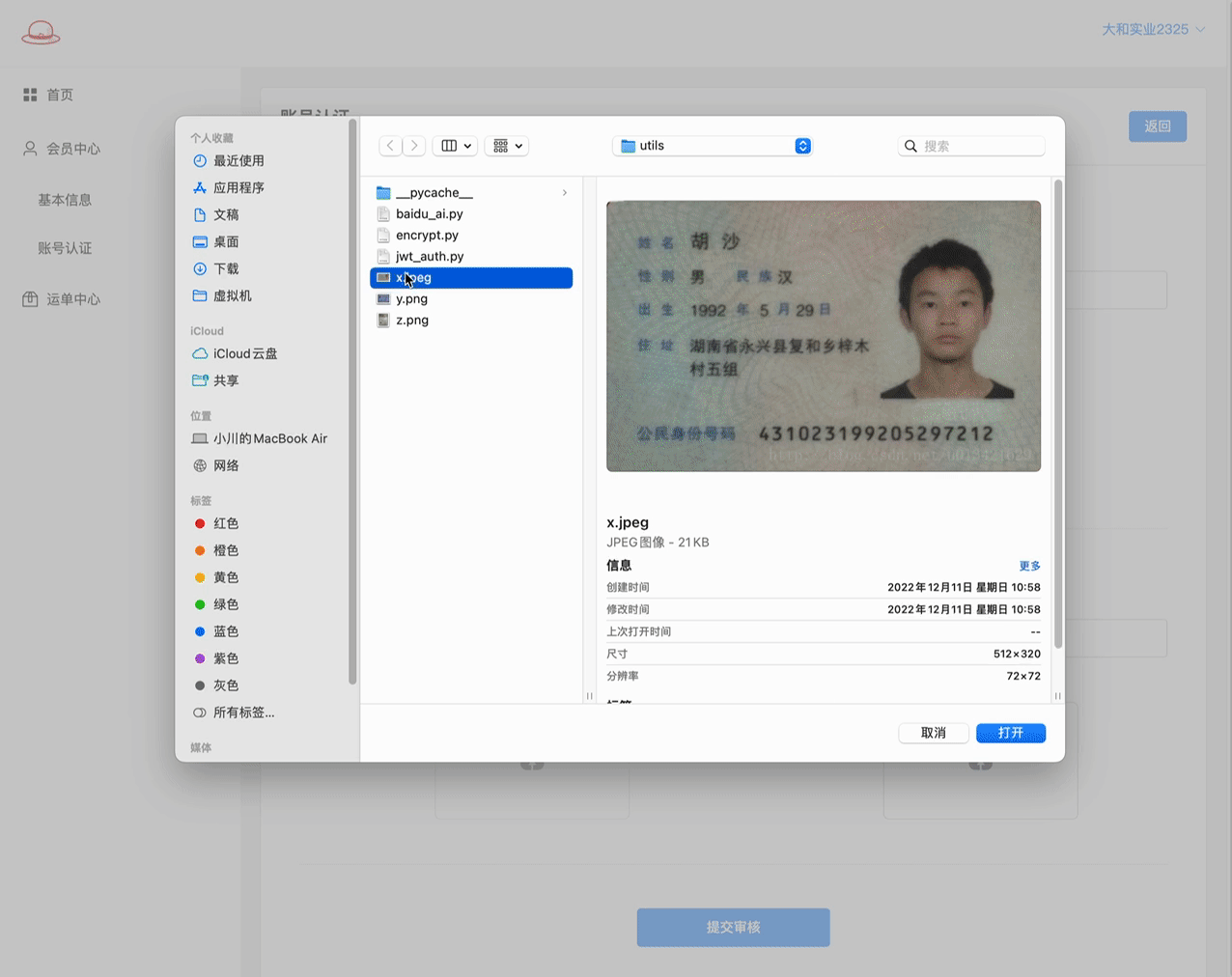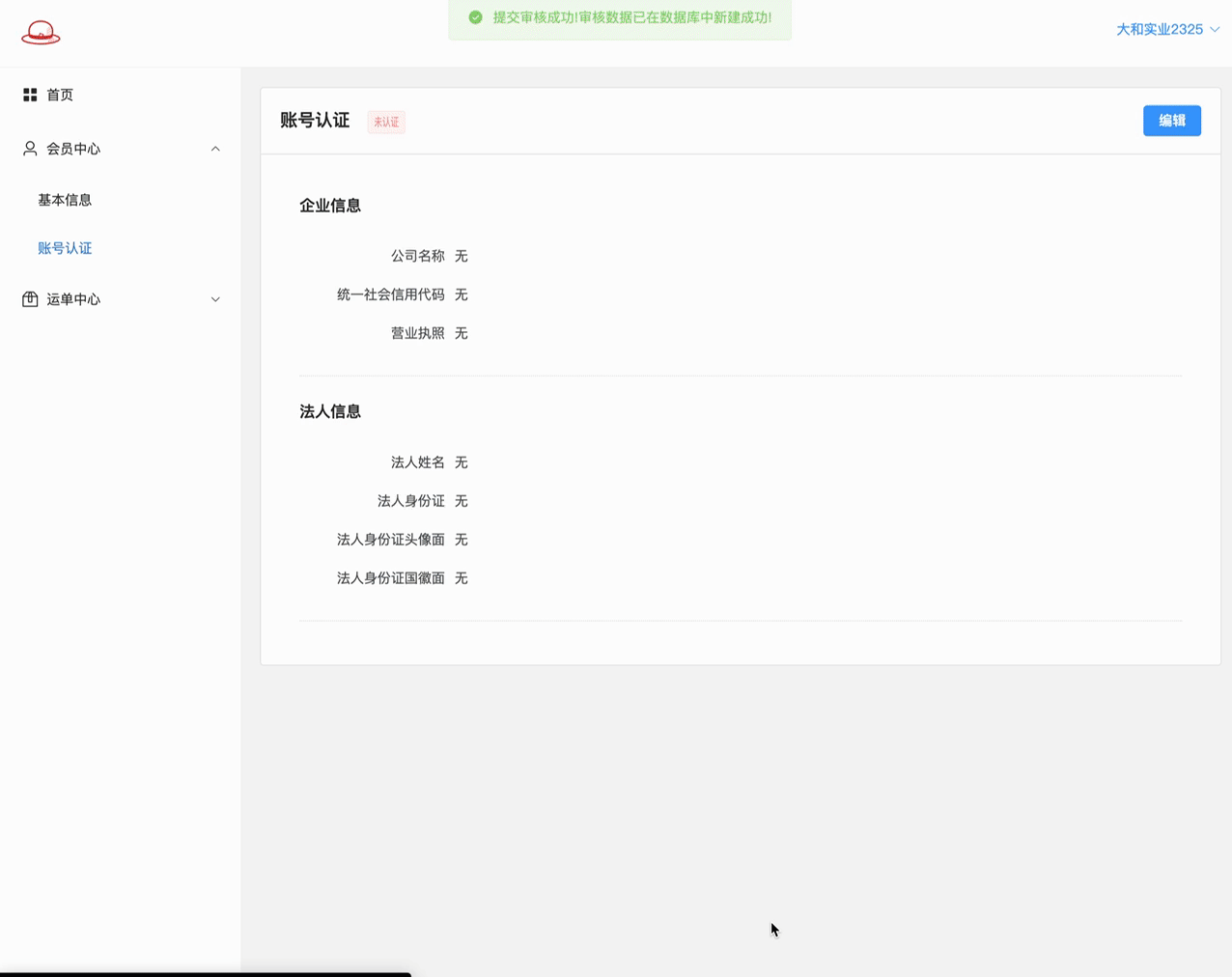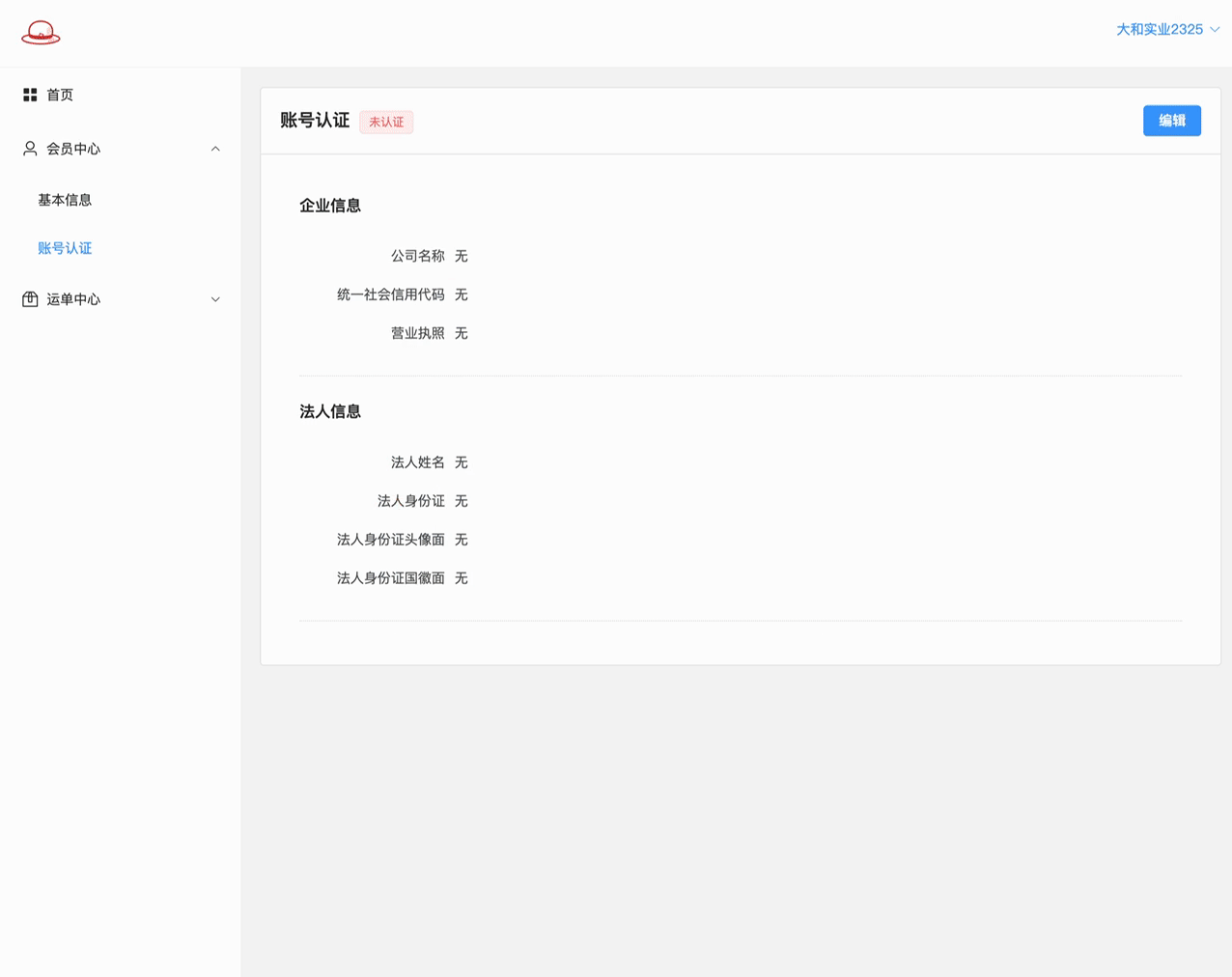
至此, 提交的逻辑基本打通, 但看到没, 测试结果中还有两个问题:
1> 新增数据成功后, AB页面的数据初始化在页面上是没有数据的!
2> 再次到进行认证编辑的B页面, 因为数据库中有数据了,此次 提交审核是更新数据. 因为这些字段是必填的,所以更新失败!!
# 测试更新
喵的,我想测试 更新功能啊!! 如何是好?
我们做一点点小操作, 当前登陆用户的id是1, 我们将CompanyAuth表中新增的那条记录的id从11手动改成1
再刷新页面A、页面B, 可以惊奇的发现, 初始化数据成功渲染出来了, 再进行更改数据的测试!也成功啦!!
2
# 关键代码

# 页面AB初始化遗留问题
哎, 前面留的坑啊! 听我细细道来!
# ★传的ID应是谁?
应是CompanyAuth表中的某条记录的ID,该条记录得满足外键字段company的值等于当前登陆用户的ID!
页面AB初始化数据时, 传递的ID不应该是当前登陆用户的ID
而应该是CompanyAuth表中的某条记录的ID,该条记录得满足外键字段company的值等于当前登陆用户的ID!!
在对于提交认证进行更新的测试中
我们是先手动将新增的那条记录的id改为跟当前登陆用户的id一致,才使得页面AB初始化数据成功的!!进而,很顺利的进行了更新的测试.
不难想到,问题出在,页面AB在进行数据初始化时,向后端传递的那个ID值有问题?!!
我们咋写的呢?
let id = store.state.id; // 当前登陆用户的ID
前端向 `/api/shipper/auth/${auth_id}/` 发送get请求,该API对应的视图函数是RetrieveModelMixin,使用的是数据表CompanyAuth
RetrieveModelMixin函数中执行self.get_object()会根据动态路由传递过来的ID查询CompanyAuth表中的某条记录.
在上面的账号认证-页面A初始化、账号认证-页面B初始化小节,当时为了图方便
我们使 "当前登陆用户ID" 和 "新增认证的数据的ID" 以及 "新增的这条认证数据中外键字段company的值" 都是1 !!
所以当时误打误撞正确了,但存在巨大的代码隐患.
★★★ 初始化数据时,动态路由ID不应该是当前登陆用户ID
而应该是 CompanyAuth表中的某条记录的ID,该条记录得满足外键字段的值等于当前登陆用户的ID!!
2
3
4
5
6
7
8
9
10
11
12
13
14
如何解决呢? 两种解决方案!
★ 不必严格遵守restful API规范, 需按照实际情况来进行调整!
方案1: 不遵守restful API规范
http://127.0.0.1:8000/api/shipper/auth/ 页面AB初始化数据时向该地址发送GET请求
该地址不用携带id!
因为drf认证组件,所以后端可根据request.user获取到当前登陆用户的ID,再通过反向查询拿到CompanyAuth表中对应的那条记录!!
因为向该地址发送请求,会执行后端的list方法,所以需要对list方法进行重写!! 具体如何实现暂略.
方案2: 遵守restful API规范
`http://127.0.0.1:8000/api/shipper/auth/${auth_id}/` 页面AB初始化数据时向该地址发送GET请求
该地址需要携带id, 该id是CompanyAuth表中的某条记录的ID,该条记录得满足外键字段company的值等于当前登陆用户的ID!!
step1.当用户登陆成功后,后端返回前端的值中还需包括auth_id
- 当前登陆用户的id反向查询到CompanyAuth表中对应记录的id,该记录的id也就是我们需要的auth_id
- 若查询到了,auth_id的值就是查询到的id
- 若没有查询到,auth_id的值为0
step2.前端拿到登陆API返回的关于auth_id的数据,保存到vuex中并做持久化
step3.当页面AB进行数据初始化时,从vuex中取出auth_id
通过http://127.0.0.1:8000/api/shipper/auth/${auth_id}/传递到后端
- 若auth_id为0,断然是查不到的,页面AB没有任何数据渲染
PS: RetrieveModelMixin函数中执行self.get_object() 拿id=0到CompanyAuth表中查,直接404
- 若auth_id不为0,肯定是查的到的,页面AB渲染对应的数据
step4.有这么一种情况,刚注册登陆进去还未进行账号认证.
用户在访问页面AB进行数据初始化时,从vuex中拿到的auth_id都是0,意味页面上没有数据渲染,
然后点击 提交审核 按钮,新增了一条数据
但新增后,CompanyAuth表中有当前登陆用户对应的认证数据了,用户再次访问页面AB进行数据初始化时,依旧没有数据渲染..
why?! no why. 我们需要在新增数据后,后端返回当前新增数据的ID,在回调中把vuex中auth_id的值同步更新!!
这样新增数据后,页面AB的数据初始化才能成功!!!
此处的示例中我们使用方案2
特别注意一个问题: API地址中携带的这个auth_id可能没有,啥时候没有,刚注册登陆进去还未进行账号认证,CompanyAuth整张表中没有对应的记录!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
关键代码如下:

这样操作后, 新增账号认证数据后, 再次访问页面AB,页面AB进行初始化数据就能渲染出来!!
# 只能初始化自己的记录
账号认证AB页面进行数据初始化时,后端返回的数据应该是当前登陆用户对应的那条认证信息!!
怎么个原理, 在 基本信息-加载初始数据 时,已经分析的明明白白, 这里不再赘述..
可以发现的是 基本信息-加载初始数据,和账号认证AB页面加载初始数据使用的都是 我们重写的 RetrieveModelMixin
只不过编码到这一步,我们在RetrieveModelMixin多添加了个404的处理!! (屎山就是这么一步步堆起来的Hhh)
PS:你可以做个实验
在视图类中 将filter_backends = [AuthFilterBackend] 这行代码注释掉.
登陆后,在浏览器控制台输入localStorage.setItem('auth_id', 12);
若CompanyAuth表中id为12的记录存在,刷新账号认证页面AB后,就会渲染这条记录,就看到别人的认证信息啦!
2
3
4
5
6
7

# 账号认证 - 其他注意
账号认证还有几个需要注意的地方
注意的地方如下:
1> "提交审核"按钮 关于CompanyAuth表中的remark字段!
账号认证页面B上是没有remark字段的,但通过apifox的工具可以在提交请求时包含该字段!!
我们不希望通过这些工具能随意修改remark/认证的备注信息,这信息应该只能是后台管理人员才能进行的操作
那么备注信息,再次提交时,原来的审核信息是否保留?
- 保留: 将remark字段设置为 read_only=True
extra_kwargs = {
'remark': {'read_only': True},
}
- 不保留: 在save时, ser.save(remark="")
def perform_create(self, serializer):
user_id = self.request.user['user_id']
serializer.save(company_id=user_id, remark="")
def perform_update(self, serializer):
serializer.save(remark="")
2> 关于状态,用户 提交审核后, 审核状态应该由未认证变为认证中!!
ser.save() 有返回值 instance,即当前新增或更新的那条记录. 拿到这条记录去变更审核状态!
# instance.company 从CompanyAuth表跨到了Company表
def perform_create(self, serializer):
user_id = self.request.user['user_id']
instance = serializer.save(company_id=user_id, remark="")
instance.company.auth_type = 2
instance.company.save()
def perform_update(self, serializer):
instance = serializer.save(remark="")
instance.company.auth_type = 2
instance.company.save()
Other: elementPlus的Loading加载组件!账号认证表单提交时前端的校验!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31