 博客练习
博客练习
# 注意事项
一些小小的注意事项
# 路由编写
- 直接写自己写对应关系,注:得继承ViewSetMixin
urlpatterns = [
path('register/', account.RegisterView.as_view({"post": "create"})),
]
- 自动生成路由,注:得继承ViewSetMixin
router = routers.SimpleRouter()
router.register(r'register', account.RegisterView)
urlpatterns = []
urlpatterns += router.urls
==> ★ 查看下源码便知
- 不写name,相应的视图类需要写类变量 queryset! 因为需要利用该值自动生成name值.
- 写了name,假如name="xxx" 那么新增的name是"xxx-create"、查询的name是"xxx-list"
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 版本
体现API的标识 -- 版本!!
- settings.py文件中
REST_FRAMEWORK = {
# 版本配置
"DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.QueryParameterVersioning",
"DEFAULT_VERSION": "v1",
"ALLOWED_VERSIONS": ["v1"],
"VERSION_PARAM": "version",
}
- 在视图函数中,可以通过 self.request.version 拿到当前的版本号!然后做不同的处理!!
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 全局认证
- settings.py文件中
REST_FRAMEWORK = {
# 认证配置
"DEFAULT_AUTHENTICATION_CLASSES": ["api.extension.auth.TokenAuthentication", ],
"UNAUTHENTICATED_USER": lambda: None,
"UNAUTHENTICATED_TOKEN": lambda: None,
}
- api.extension.auth.TokenAuthentication
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
from api import models
from api.extension import return_code
class TokenAuthentication(BaseAuthentication):
"""必须认证成功之后才能访问视图 认证失败压根走不到视图,因为认证失败直接抛出异常了"""
def authenticate(self, request):
token = request.query_params.get("token")
if not token:
raise AuthenticationFailed({"code": return_code.AUTH_FAILED, "error": "未传token,认证失败"})
user_object = models.UserInfo.objects.filter(token=token).first()
if not user_object:
raise AuthenticationFailed({"code": return_code.AUTH_FAILED, "error": "没有该token,认证失败"})
if datetime.datetime.now() > user_object.token_expiry_date:
raise AuthenticationFailed({"code": return_code.AUTH_OVERDUE, "error": "认证过期"})
return user_object, token
def authenticate_header(self, request):
return 'Bearer realm="API"'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 全局分页
- settings.py文件中
REST_FRAMEWORK = {
# 分页配置
"DEFAULT_PAGINATION_CLASS": "api.extension.page.DigLimitOffsetPagination"
}
- api.extension.page.DigLimitOffsetPagination
from rest_framework.pagination import LimitOffsetPagination
class DigLimitOffsetPagination(LimitOffsetPagination):
# xxx?limit=2 limit不传默认是10,最大只能传100
default_limit = 10
max_limit = 100
# 印象中的偏移分页是这样的 xxx?limit=5&offset=2 从第2个位置往后读5条数据
# 但在该项目中的分页用不到offset,哪怕传了也没意义.. 因为我们用到了latest_id
offset_query_param = None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# ★序列化!
# (≧▽≦)/ drf的视图类
Q ★ 什么时候用自动生成路由,用drf提供的那些视图类;什么时候自己写直接用APIView呢?
A ★ 标准在于,需求的实现逻辑 与 drf提供的那些视图类的源码逻辑 有多少是重合的!!关联性强不强. ==> eg:登陆
(¯﹃¯) 首先得清楚,源码中self.get_object干了四件事,获取数据集、过滤、pk值、细粒度的权限
类似于 "Publish.objects.all()"."filter()"."filter(pk=kwargs['pk'])".first()
- CreateModelMixin ==> "序列化器类(data=request.data)"
实例化 - 验证 - 存储 - 序列化返回
- DestroyModelMixin ==> "序列化器类(instance=instance)"
instance = self.get_object - 实例化 - 删除
- UpdateModelMixin ==> "序列化器类(instance=instance,data=request.data,partial=partial)"
instance = self.get_object - 实例化 - 验证 - 更新 - 返回
- ListModelMixin ==> "序列化器类(instance=p_list,many=True)"
获取数据集、过滤 (就是get_object的前两件事) - 分页得到p_list - 实例化 - 返回
- RetrieveModelMixin ==> "序列化器类(instance=instance)"
instance = self.get_object - 实例化 - 返回
★【小口诀】
POST 增 create data=request.data ==> 实 验 增 返
DELETE 删 destroy instance=instance ==> 集过pk 实 删
PUT 更 update instance=instance,data=request.data,partial=partial ==> 集过pk 实 验 更 返
GET 多 list instance=p_list,many=True ==> 集过 分 实 返
GET 单 retrieve instance=instance ==> 集过pk 实 返
- "实例化时传递了data参数" 证明该接口的请求体中需传递一些数据,有些字段数据是前端必传的
- "验" 正是因为实例化时传递了data参数/前端传递了一些数据,所以需要对这些数据进行验证! "验"涉及到 增加和更新.
- "pk" 证明该接口的url中需携带ID参数
- "返" 排除序列化器类中write_only=True的字段,剩下的字段返回(换个说法,read_only=True的字段+既能读也能写的字段)
- "增" 必定会使用钩子函数perform_create,若在该函数中调用了save,会去序列化器类中找create方法执行!!
- "更" 必定会使用钩子函数perform_update,若在该函数中调用了save,会去序列化器类中找update方法执行!!
- "删" 必定会使用钩子函数perform_destroy,可根据需求进行物理删除和逻辑删除!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 思考步骤
第一步: 看需求是什么,是新增?是删除?是更新?是查找? 明确后,以"小口诀"为标准开始编写代码!
第二步: 当进行到"验证阶段"以及"返回序列化数据阶段"时,需观察序列化器类,分析出序列化器类中有哪些字段对象.
--> {字段类型的类变量} | {ORM表中的字段名} 这两者取并集,前者的优先级高于后者!后者优先级低的会db匹配自动创建.
第三步: 对序列化器类中的字段对象进行分类, 可写/可验证、可读/可序列化、可读可写/即可验证也可序列化.
--> 换个说法就是 not read_only=True的字段对象"可验证的字段对象" 、not write_only=True的字段对象."可序列化的字段对象"
第四步: 开始产生分支
4.1 "验证阶段" 不难分析出,只有新增和更新才会进行验证.
4.1.1 看序列化器中"可验证的字段对象"的属性,判断出哪些是前端必须传的字段!! (注:可验证的字段对象
有默认值和允许为空以及自动生成的字段,其属性都是不必填的,即required=False
★ required=True + 可验证的字段 == 前端必须传递的字段
4.1.2 这些可验证的字段对象验证通过后 与 save有关!!
1> ★ 验证时,会获取request.data中 与可序列化字段的字段名对应的值;
2> ★ save时,用的是验证通过后的 validated_data, 得特别注意其键名是source_attrs!
- 新增
ORM表中的字段除了默认值和允许为空以及自动生成的字段,前端都必须提供!! (这个与4.1.1相辅相成
在save时,ORM表里面的字段应该一个不多一个不少!!
- 更新
肯定得先表明是对哪个instance进行更新 (在序列化器类实例化时就已经表明了
- 全局更新PUT 前端必须传递的字段都必须得传
除了必传的,只要Meta的fields中写了的可验证的字段,传进去都可进行更新!(前提是可验证的字段哦!
- 局部更新PATCH 前端必须传递的字段变成可选的,没选上也就不会进行校验
只要Meta的fields中写了的可验证的字段,传进去都可进行更新!(前提是可验证的字段哦!
▲ 注:PATCH 还可以不传值,返回的就是该条记录,变相的相当于查询该条记录
▲ 特别特别注意,更新时,只要有字段是ORM表中的字段即可!! 像下面的例子,Company表中有mobile字段,并没有old字段!!
from apps.repository import models
obj = models.Company.objects.filter(mobile=13888888881).first()
if obj:
print(obj.mobile) # 13888888881
obj.old = 13888888881
obj.mobile = 13888888882
obj.save()
print(obj.mobile) # 13888888882
print(obj.old) # 13888888881
4.2 "返回序列化数据阶段"
本质就是对 "可序列化的字段对象" 进行序列化返回!!
- 无论save是新增还是更新 save()返回的instance都会提供给ser.data使用!
进行序列化返回时,执行的是 "instance.字段对象的source_attr" 的操作!!
- 若验证后没有save直接序列化,序列化的数据是ser.validated_data
▽ 但要注意,这并不意味着序列化的结果就是ser.validated_data中的那些字段 (看序列化过程的源码就明白的.
有时,序列化器类中有的字段只读,但它允许为空,也会被序列化出来!! 所以啊,要抓住重点,是序列化器类中的那些可读字段!!
- 如果是纯粹的序列化,就是序列化器类实例化时传进来的instance进行序列化 (可参考纯序列化的那篇博文)
PS:开发过程中,遇到了一个很有趣的现象
- 我在perform_create中这样写.进行测试,是通的.
def perform_create(self, serializer):
print(serializer.data) # 虽说,这里序列化用的数据是ser.validated_data,但结果是序列化器类中可读的字段哦.
return Response("ok")
- 但在perform_create中先serializer.data,在serializer.save()是会报错的!!
究其原因,serializer.data后序列化器类的self._data就有值了
在进行serializer.save()时,会断言assert not hasattr(self, '_data'),(...)
这样的操作是不被允许的,别问为啥!源码里这么规定的,不要纠结!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 设置只读只写的技巧
- 在ORM表中的字段若设置了属性choices,那么在序列化器类中,一般会写额外字段让其返回前端中文.
- 这些额外的字段往往都会设置 read_only=True !!
- 这些额外的字段,也可分两种情况
命名为 topic -> topic_title 、或者说就用ORM表中的字段名 status -> status (这种情况准确点说是重写)
- 像这里的topic往往会对其设置 write_only=True, 因为有topic_title了,无需重复返回含义相同的数据
- 像这里关于状态的status就单纯的返回给前端用户,因为分析需求可明确前端不用传status
- 尽管序列化器类用到了某张ORM表
但某个业务的开发(比如某业务包含资讯的创建和返回列表数据)
是不需要前端传递某些字段数据的,只需返回前端
(eg:News表中的collect_count收藏数, recommend_count推荐数, comment_count点赞数) -> 单纯为了减少查询设计的!!
那么就给这些字段设置 read_only=True !!
⚠️ 注意!! 别一味的使用read_only_fields、write_only_fields
https://stackoverflow.com/questions/68946823/django-drf-read-only-fields-not-working-properly
验证代码:
serializer = self.get_serializer(data=request.data)
print("****", repr(serializer))
print("****", serializer._declared_fields)
print("****", serializer.get_extra_kwargs())
☆ 简单来说,序列化器类中字段类型的类变量别用read_only_fields、write_only_fields,用了也不会生效!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 一些小锦囊
- write_only 跟验证、save有关 ; read_only 跟序列化返回有关!!
- ser.validated_data验证通过后才会有、那么在验证过程中使用self.initial_data.get('password')
- 视图类中的方法"皆"可以通过 self.request 拿到请求相关数据
源码出处: dispatch方法
request = self.initialize_request(request, *args, **kwargs) # 二次封装的request
self.request = request
- 序列化器类中的方法"皆"可以通过 self.context["request"] 拿到请求相关的数据
源码出处:
1> 第一步先看: drf的GenericAPIView类中关于序列化器类实例化的方法get_serializerg
def get_serializer(self, *args, **kwargs):
serializer_class = self.get_serializer_class()
kwargs.setdefault('context', self.get_serializer_context())
return serializer_class(*args, **kwargs)
def get_serializer_context(self):
return {
'request': self.request,
'format': self.format_kwarg,
'view': self
}
2> 第二步,看序列化器类在实例化时,触发的__init__ 根据继承关系,在BaseSerializer里
self._context = kwargs.pop('context', {})
3> 第三步,找context方法!! 在BaseSerializer的父类Field里
@property
def context(self):
return getattr(self.root, '_context', {})
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 错误信息
★ 关于错误信息,我们习惯于这样
- 详细的,具体的错误信息 code + detail detail类似于{'username':[错误信息,], 'phone':[xxxx,]}
- 整体的错误信息 code + error
1
2
3
2
3
# 何时Serializer
Q ★ 什么时候使用serializers.ModelSerializer 什么时候使用serializers.Serializer? ==> eg:登陆
A ★ 其实没啥标准,只需要知道
1. ModelSerializer可以帮我们自动生成字段对象
2. ModelSerializer可以自动save,若使用serializers.Serializer时save,需重写create和update
这两点都不需要,那么我们就直接用serializers.Serializer也是无碍的!!
1
2
3
4
5
2
3
4
5
# 数据表设计
结合学习的drf知识开发 简易版的"抽屉新热榜"
https://dig.chouti.com/
from django.db import models
class DeletedModel(models.Model):
# deleted 是否已删除 -- 做逻辑删除用的,逻辑删除时其值为true
deleted = models.BooleanField(verbose_name="已删除", default=False)
# 提取出来作为父类,做逻辑删除的表都会继承它 但注意不要让它生成表 只是为其他表提供公共字段 abstract=True
class Meta:
abstract = True
class UserInfo(DeletedModel):
""" 用户表 """
username = models.CharField(verbose_name="用户名", max_length=32)
phone = models.CharField(verbose_name="手机号", max_length=32, db_index=True)
password = models.CharField(verbose_name="密码", max_length=64)
token = models.CharField(verbose_name="token", max_length=64, null=True, blank=True, db_index=True)
token_expiry_date = models.DateTimeField(verbose_name="token有效期", null=True, blank=True)
# 有些账户异常,经常爬虫,我们就把它禁用掉
status_choice = (
(1, "激活"),
(2, "禁用"),
)
status = models.IntegerField(verbose_name="状态", choices=status_choice, default=1)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
class Meta:
# Meta里联合索引,建议3.2后用index,而不是index_togeter
indexes = [
models.Index(fields=['username', "password"], name='idx_name_pwd')
]
class Topic(DeletedModel):
""" 话题 """
title = models.CharField(verbose_name="话题", max_length=16, db_index=True)
# is_hot 这个话题是不是热门话题 这样前端用户在发布话题时,可以选择数据库里的那些热门话题(管理员设置哪些是热门话题)
is_hot = models.BooleanField(verbose_name="热门话题", default=False)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
class News(DeletedModel):
""" 新闻资讯 """
title = models.CharField(verbose_name="文字", max_length=150)
url = models.CharField(verbose_name="链接", max_length=200, null=True, blank=True)
# 可上传多张图片,会以逗号分割的字符串存储到image字段中 eg:xxxx.jpg,dddxeu.png
image = models.TextField(verbose_name="图片地址", help_text="逗号分割", null=True, blank=True)
topic = models.ForeignKey(verbose_name="话题", to="Topic", on_delete=models.CASCADE, null=True, blank=True)
zone_choices = ((1, "42区"), (2, "段子"), (3, "图片"), (4, "挨踢1024"), (5, "你问我答"))
zone = models.IntegerField(verbose_name="专区", choices=zone_choices)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
# 发布后,需要审核
status_choice = (
(1, "待审核"),
(2, "已通过"),
(3, "未通过"),
)
status = models.IntegerField(verbose_name="状态", choices=status_choice, default=1)
# 注:取消收藏,收藏数减一,新增收藏,收藏数加一; 推荐数、评论数同理
collect_count = models.IntegerField(verbose_name="收藏数", default=0)
recommend_count = models.IntegerField(verbose_name="推荐数", default=0)
comment_count = models.IntegerField(verbose_name="评论数", default=0)
# 取消收藏是直接删除该条记录,并不是逻辑删除 是物理删除
class Collect(models.Model):
""" 收藏 """
news = models.ForeignKey(verbose_name="资讯", to="News", on_delete=models.CASCADE)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
class Meta:
# unique_together = [['news', 'user']]
# 联合唯一索引 即某一用户只能对某一资讯收藏一次,不能重复收藏
constraints = [
models.UniqueConstraint(fields=['news', 'user'], name='uni_collect_news_user')
]
# 同收藏 物理删除
class Recommend(models.Model):
""" 推荐 """
news = models.ForeignKey(verbose_name="资讯", to="News", on_delete=models.CASCADE)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
class Meta:
constraints = [
models.UniqueConstraint(fields=['news', 'user'], name='uni_recommend_news_user')
]
# 物理删除
class Comment(models.Model):
""" 评论表 """
news = models.ForeignKey(verbose_name="资讯", to="News", on_delete=models.CASCADE)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
content = models.CharField(verbose_name="内容", max_length=150)
# - 你仔细想想, 众多评论,有了深度,即该条评论属于哪个层级+有了该条评论所属根评论,就可以根据根评论分开,构建 评论的层级结构!!
# 相当于 根评论-子评论-子评论的子评论-...-... 前端展示时可以指定先显示深度为2的评论,不至于全部一下子展示出来
depth = models.IntegerField(verbose_name="深度", default=0)
# 记录该条评论的根评论 因为我们要获取最新的20条评论的根评论,根据根评论拿到它下面的所有子孙评论
# 本身就是根评论,即root字段可为空
root = models.ForeignKey(
verbose_name="根评论", to="Comment", related_name="descendant",
on_delete=models.CASCADE, null=True, blank=True)
# 该评论回复的是哪条评论
reply = models.ForeignKey(
verbose_name="回复", to="Comment", related_name="reply_list",
on_delete=models.CASCADE, null=True, blank=True)
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
# 针对根评论 根评论下的某条子孙评论被回复了,那么就需要更新该字段
# 以便于实现需求:根据后代的最新更新时间进行排序,获取所有根评论
descendant_update_datetime = models.DateTimeField(verbose_name="后代更新时间", auto_now_add=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
# 环境准备

# account
用户表相关 登陆、注册
# 注册
细节还是蛮多的
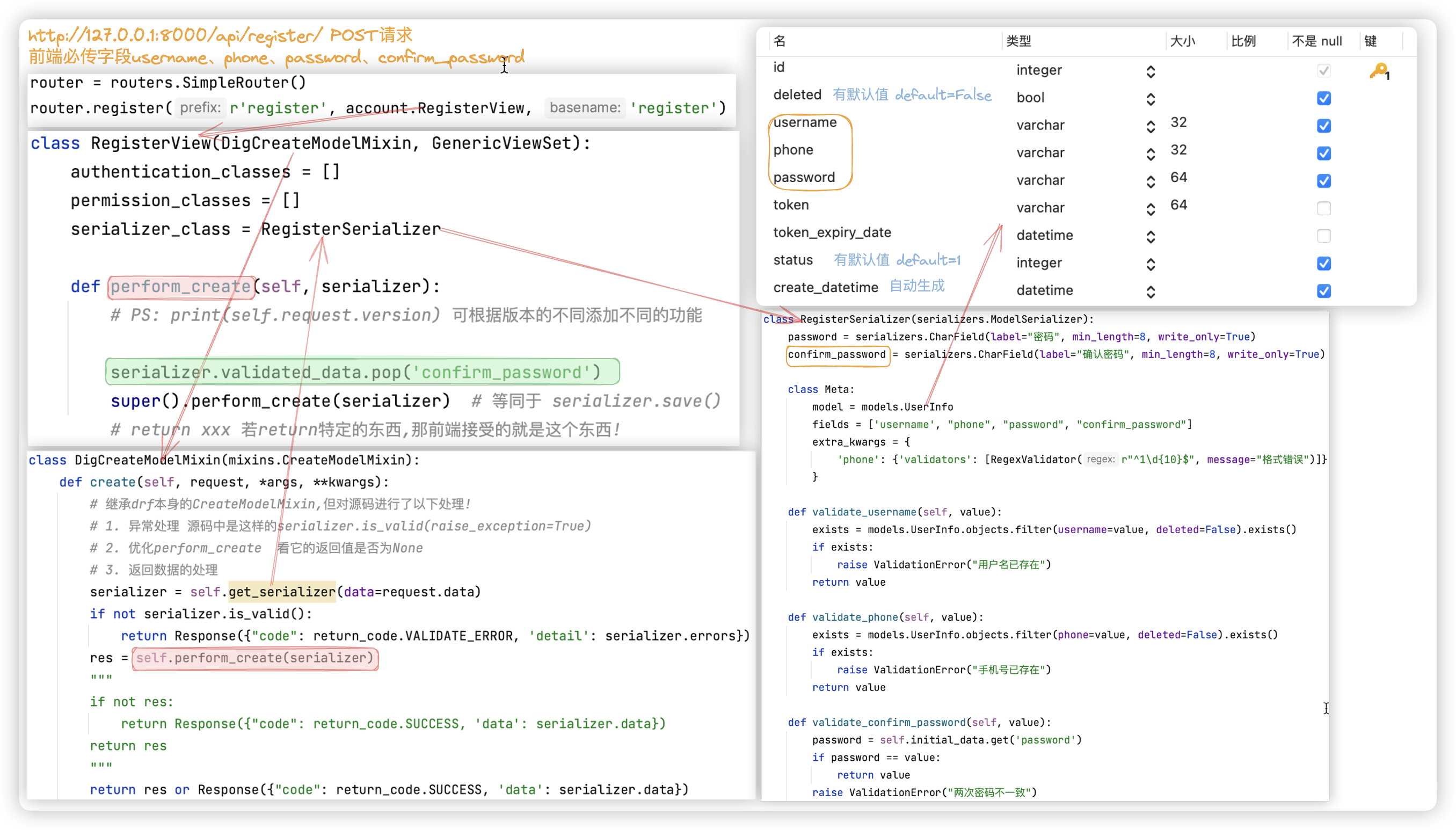
== 需求 ==
1> 用户输入 用户名、手机号、密码、重复密码. -- ORM表中没有重复密码字段, confirm_password是自己写的额外字段!!
2> 用户名、手机号都是唯一的并且是未删除的(即所有未删除的用户用户名、手机号都未重复)
输入的密码得一致!
-- 看字段的钩子.其中注意查询语句条件 filter(phone=value, deleted=False)
3> 返回给前端的数据中, 不能返回密码相关的信息. -- password、confirm_password 都是write_only=True
1
2
3
4
5
6
2
3
4
5
6
# 登陆
很好的阐述了啥时候直接用APIView, 啥时候直接使用serializers.Serializer
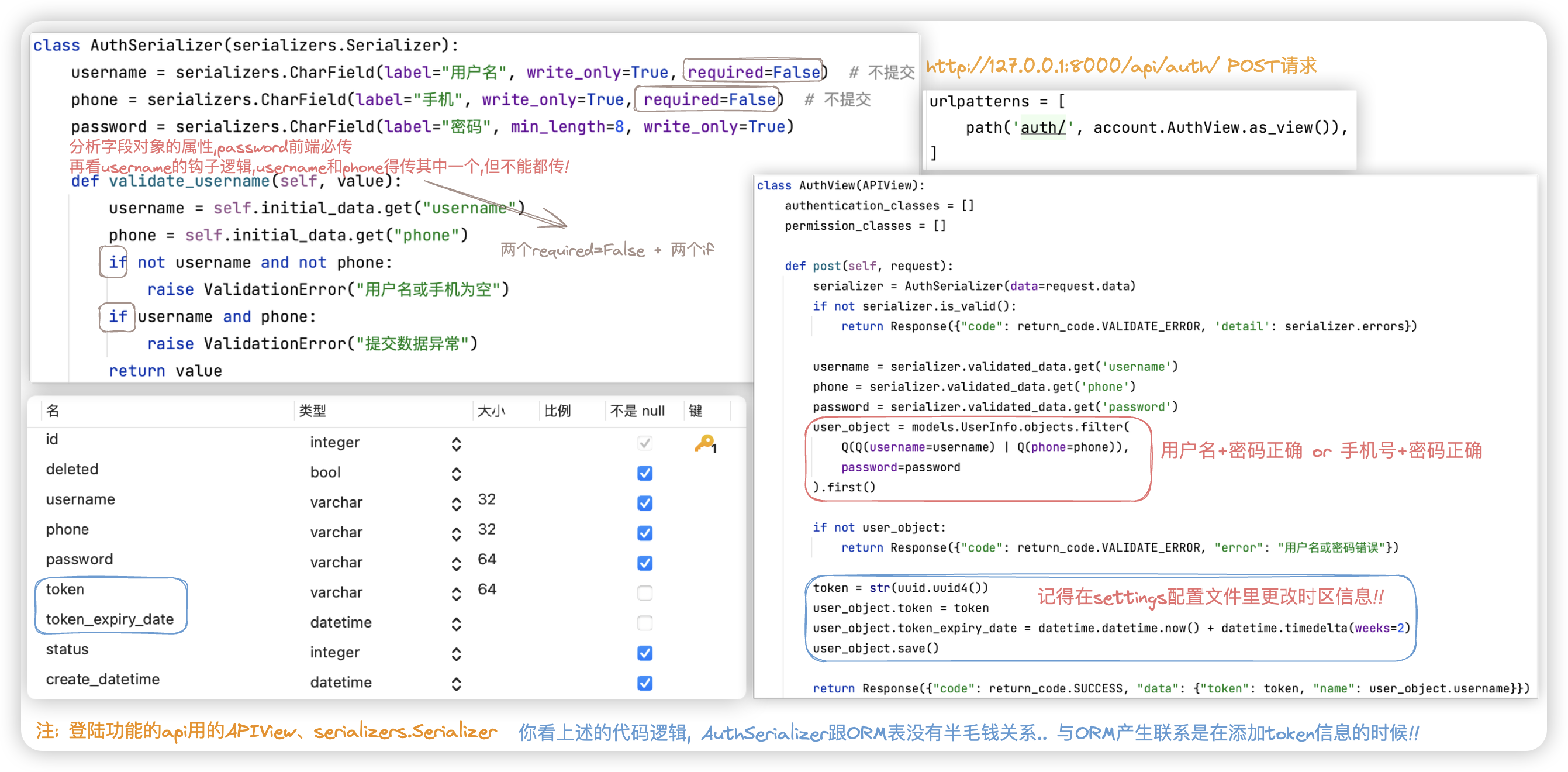
== 需求 ==
输入: [手机号 或 用户名] + 密码
注意: 登录成功后给用户返回token,后续请求需要在url参数中携带token值用于后端认证组件的校验 (默认设置有效期为2周)
1
2
3
2
3
# topic
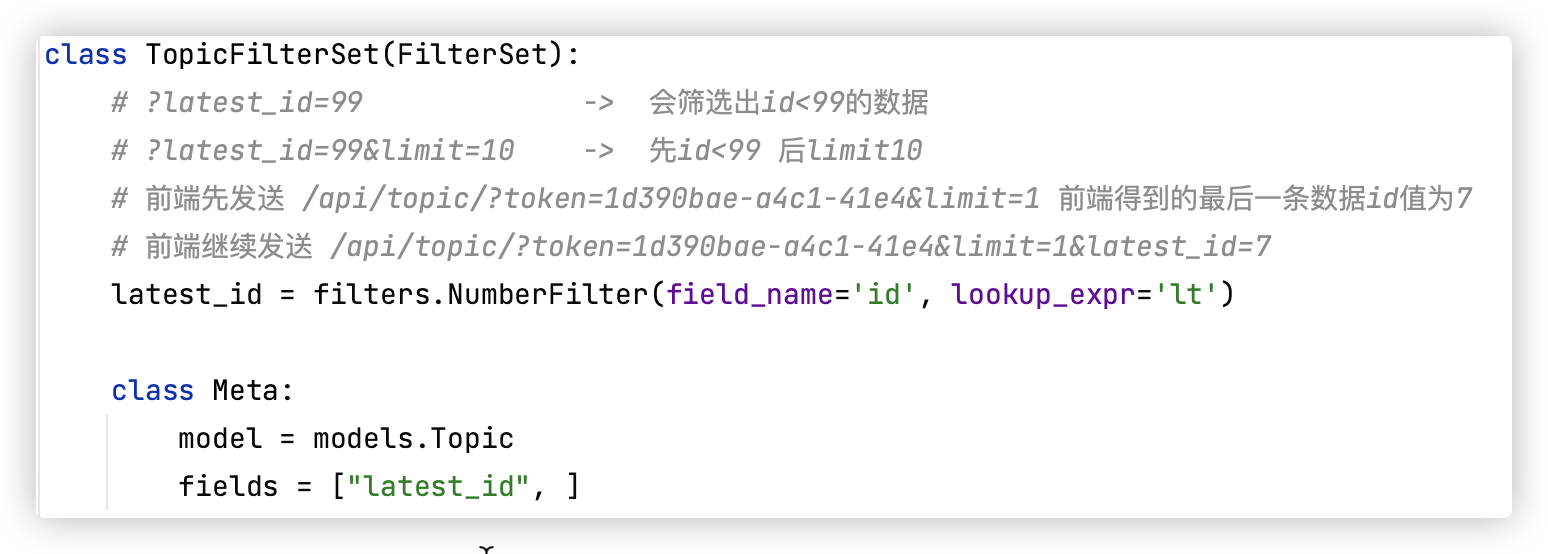
关于话题的四个接口!! 创建、删除、更新某一条、查看多条 值得细品!! (查看单条的接口该话题示例中没有)
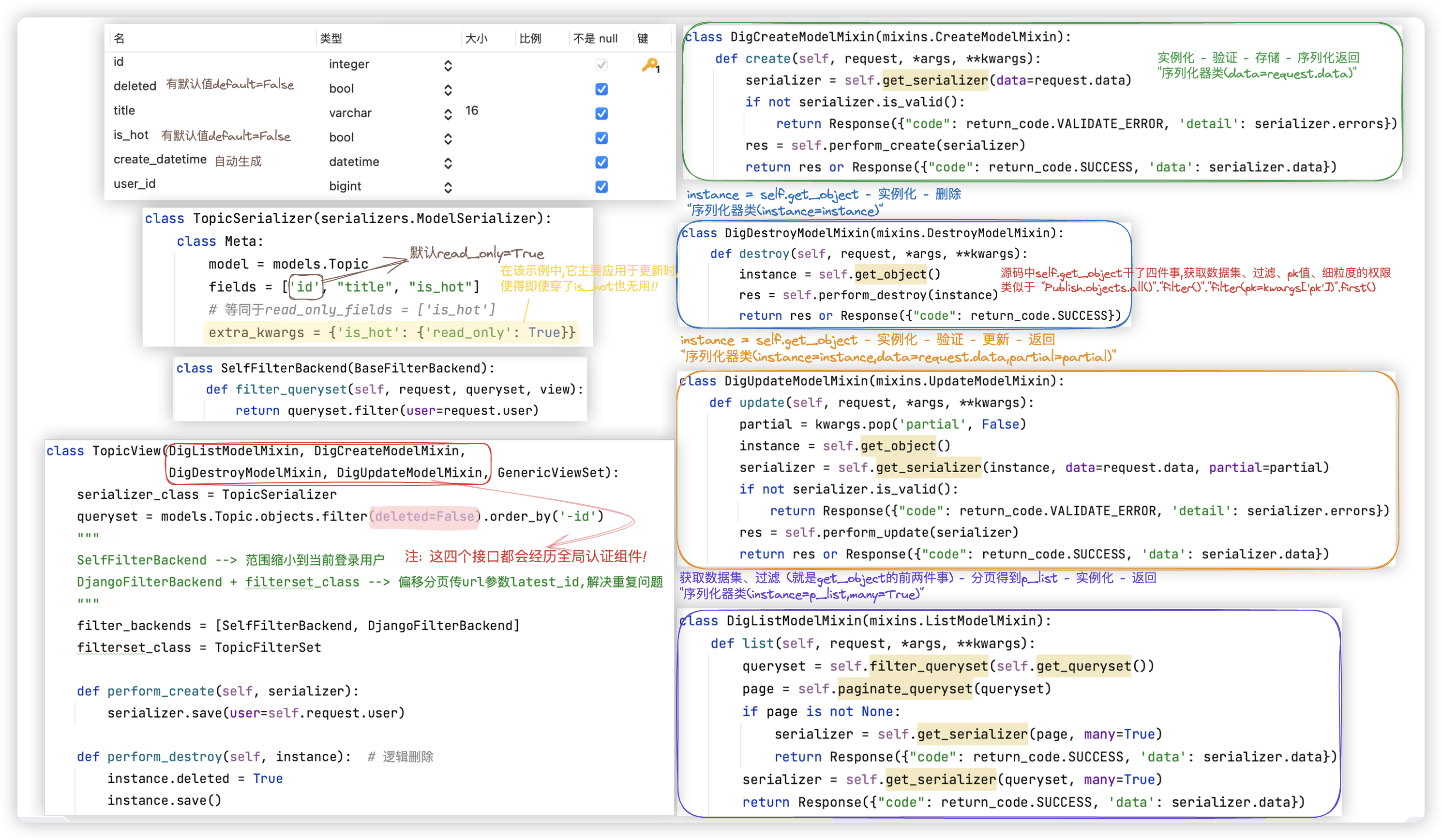
Ps: 其实你细品, TopicSeralizer的fields里的is_hot和extra_kwargs里的is_hot不写, 没有任何的影响!!
Ps: 获取多条数据是用到了分页的, 该分页的配置是全局的!! 注-没有用到offset,因为该偏移会使用latest_id!!
- 创建
http://127.0.0.1:8000/api/topic?token=... POST {"title":"树胶"}
- 删除 !!逻辑删除
http://127.0.0.1:8000/api/topic/7?token=... DELETE
- 更新
http://127.0.0.1:8000/api/topic/10?token=... PUT {"title":"啊哈哈","is_hot":true} is_hot传过去没用!!
- 查找多条 limit获取几条数据,全局分页里的配置是默认获取10条
前端先发送 GET /api/topic/?token=1d390bae-a4c1-41e4&limit=1 前端得到的最后一条数据id值为7
前端再发送 GET /api/topic/?token=1d390bae-a4c1-41e4&limit=1&latest_id=7
Ps: is_hot是表明该话题是否是热门话题,应该由管理员来设置!!
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# news
资讯相关接口. 新增资讯、查看用户自己的资讯列表 -- 注意哦,这两个接口是经历了全局认证组件的. ★ 这里对限流组件的源码进行了重写以满足需求.
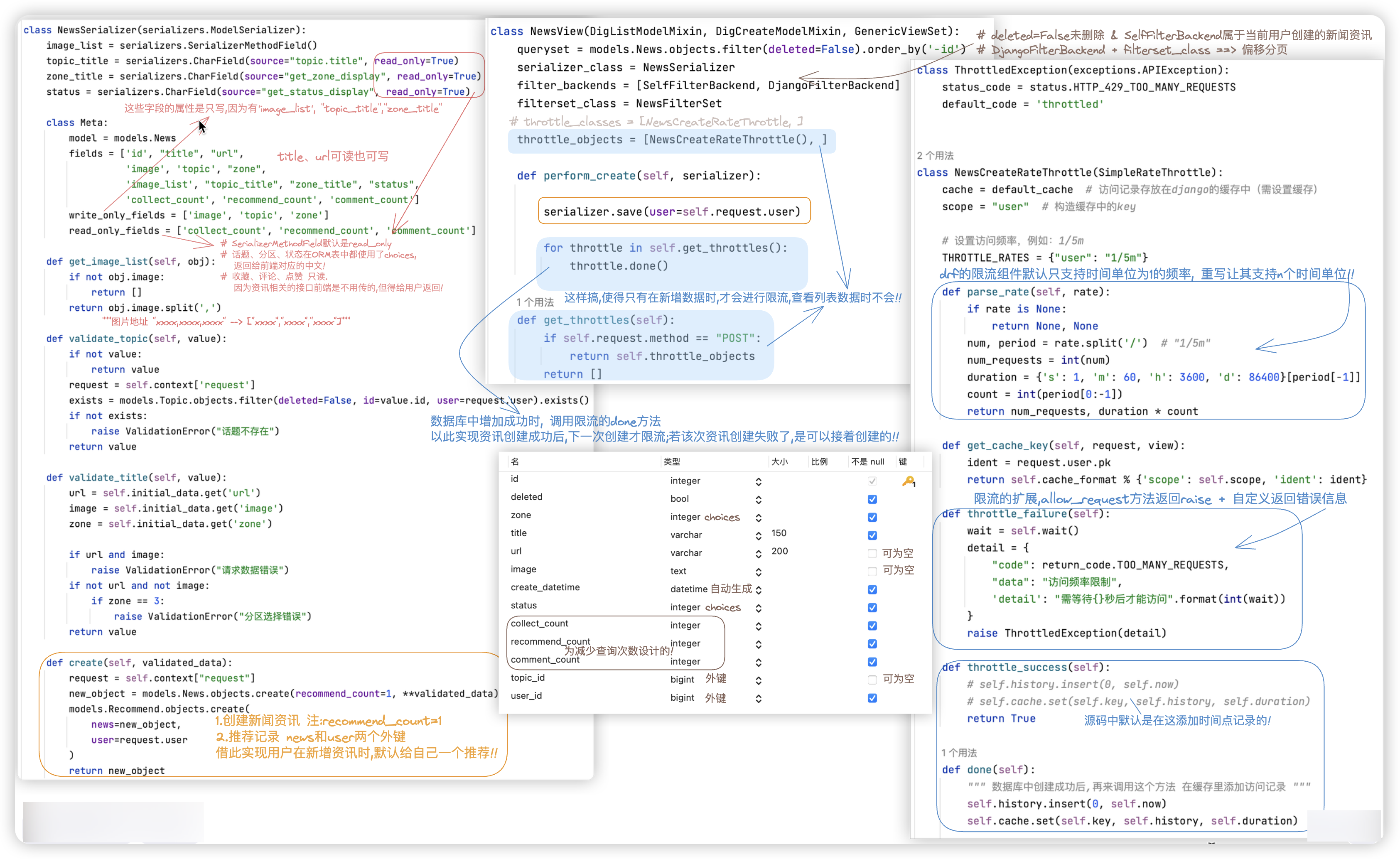
PS: 使用限流组件,记得进行redis的配置!!
[需求1] 创建资讯
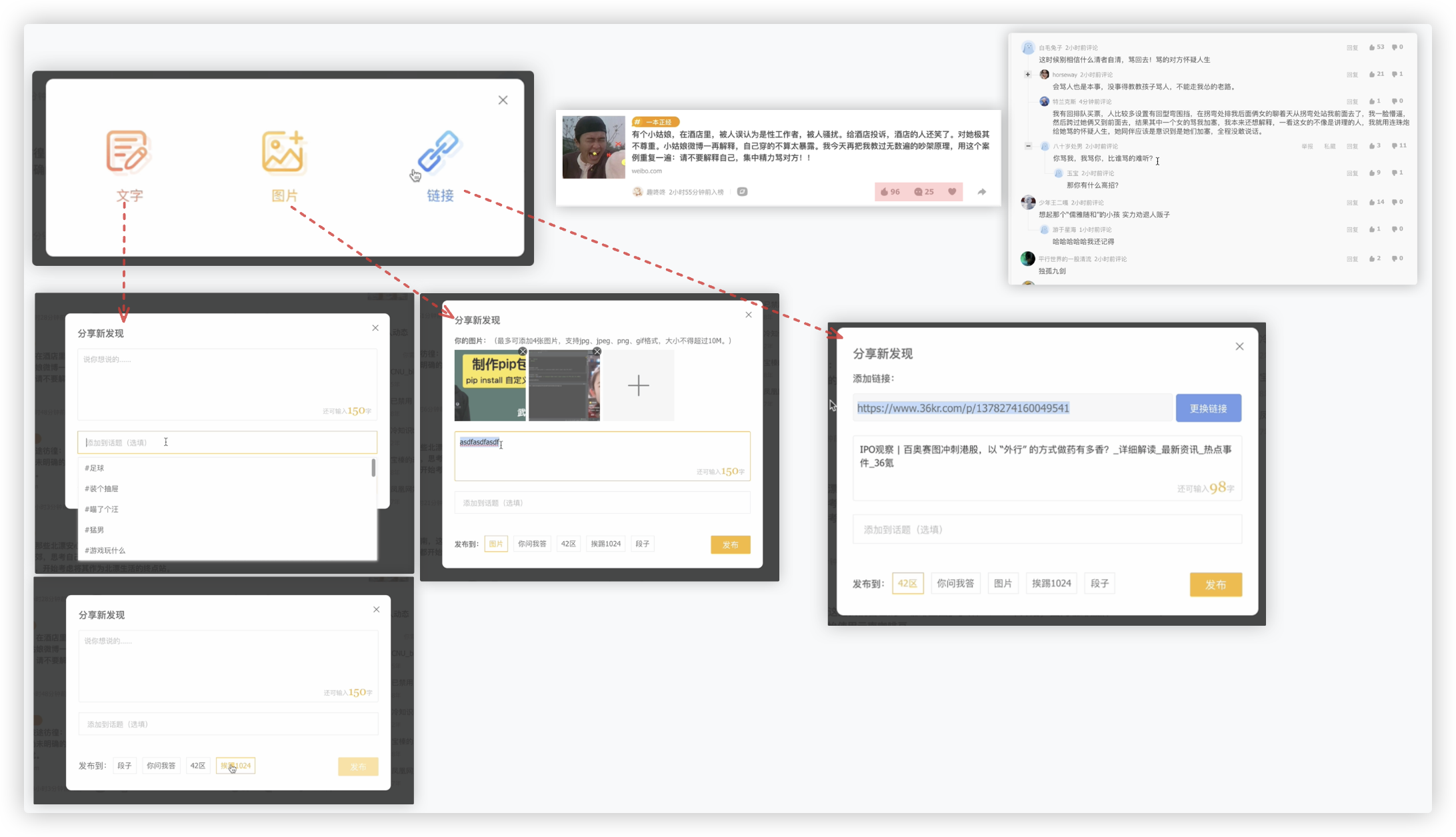
1> 用户在创建资讯有三个选择按钮 文字、图片、链接
- 文字 title必填、分区必选(但无图片选项)、话题可选
- 图片 title必填、img图片地址必传、分区必选、话题可选
- 链接 title必填、url链接地址必传、分区必选、话题可选
PS:分区> 图片、你问我答、42区、挨踢1024、段子
需求解析 ==>
在title的勾子里判断,img和url肯定不能同时传、img和url都没有的话,则分区的选项不能是图片.
在topic的勾子里判断,选择的话题得是用户自己创建的话题,或者是管理员设置的热门话题. (管理员设置的热门话题这个暂时未实现)
2> 用户在新增资讯时,默认给自己一个推荐!!
需求解析 ==>
需要完成两个功能
- 其1 - News表新增一条记录,新增时,recommend_count推荐数等于1
- 其2 - Recommend推荐表,新增一条推荐记录!! (当然取消推荐时,该条记录要删除.)
在何处编写上述两点, 在perform_create新增勾子里.
方案1: 两个功能点全部写在perform_create勾子里.
方案2: 在相对应的序列化器类中重写create方法里完成这两个功能
perform_create勾子里执行save方法时会调用优先调用这个重写的create方法.而不是ModelSerializer里的create.
3> 用户创建资讯,需要进行限流!!
使用drf的默认的限流组件,要解决两个问题: (需修改限流组件的源码!!)
1> drf的限流组件默认不支持 2/5min; 只支持 2/m、5/h
2> 资讯创建成功后,下一次创建才限流;若该次资讯创建失败了,是可以接着创建的!!
3> (´・Д・)」限流只对创建有效,查询多条是不需要限流的!!
- 创建
成功的情况 /api/news/?token=1d390bae-a4c1-41e4 POST {"title":"1121","zone":1}
失败的情况 /api/news/?token=1d390bae-a4c1-41e4 POST {"title":"1131","zone":3}
- 返回 {"code":1001,"detail":{"title":["分区选择错误"]}}
限流 /api/news/?token=1d390bae-a4c1-41e4 POST {"title":"1131","zone":1}
- 返回 {"code":"4000","data":"访问频率限制","detail":"需等待221秒后才能访问"}
[需求2] 用户自己的资讯列表
PS:与上面的话题的创建并无二样.
- 获取资讯列表 limit获取几条数据,全局分页里的配置是默认获取10条
前端先发送 GET /api/news/?token=1d390bae-a4c1-41e4&limit=1 前端得到的最后一条数据id值为7
前端再发送 GET /api/news/?token=1d390bae-a4c1-41e4&limit=2&latest_id=7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
特别注意: 若序列化器类像这么写, 'topic_title', 'zone_title', 'status' 他们仨的read_only=True的设置不会生效!!
class NewsSerializer(serializers.ModelSerializer):
image_list = serializers.SerializerMethodField()
topic_title = serializers.CharField(source="topic.title")
zone_title = serializers.CharField(source="get_zone_display")
status = serializers.CharField(source="get_status_display")
class Meta:
model = models.News
fields = ['id', "title", "url",
'image', 'topic', "zone",
'image_list', "topic_title", "zone_title", "status",
'collect_count', 'recommend_count', 'comment_count']
write_only_fields = ['image', 'topic', 'zone']
read_only_fields = [
'topic_title', 'zone_title', 'status',
'collect_count', 'recommend_count', 'comment_count'
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
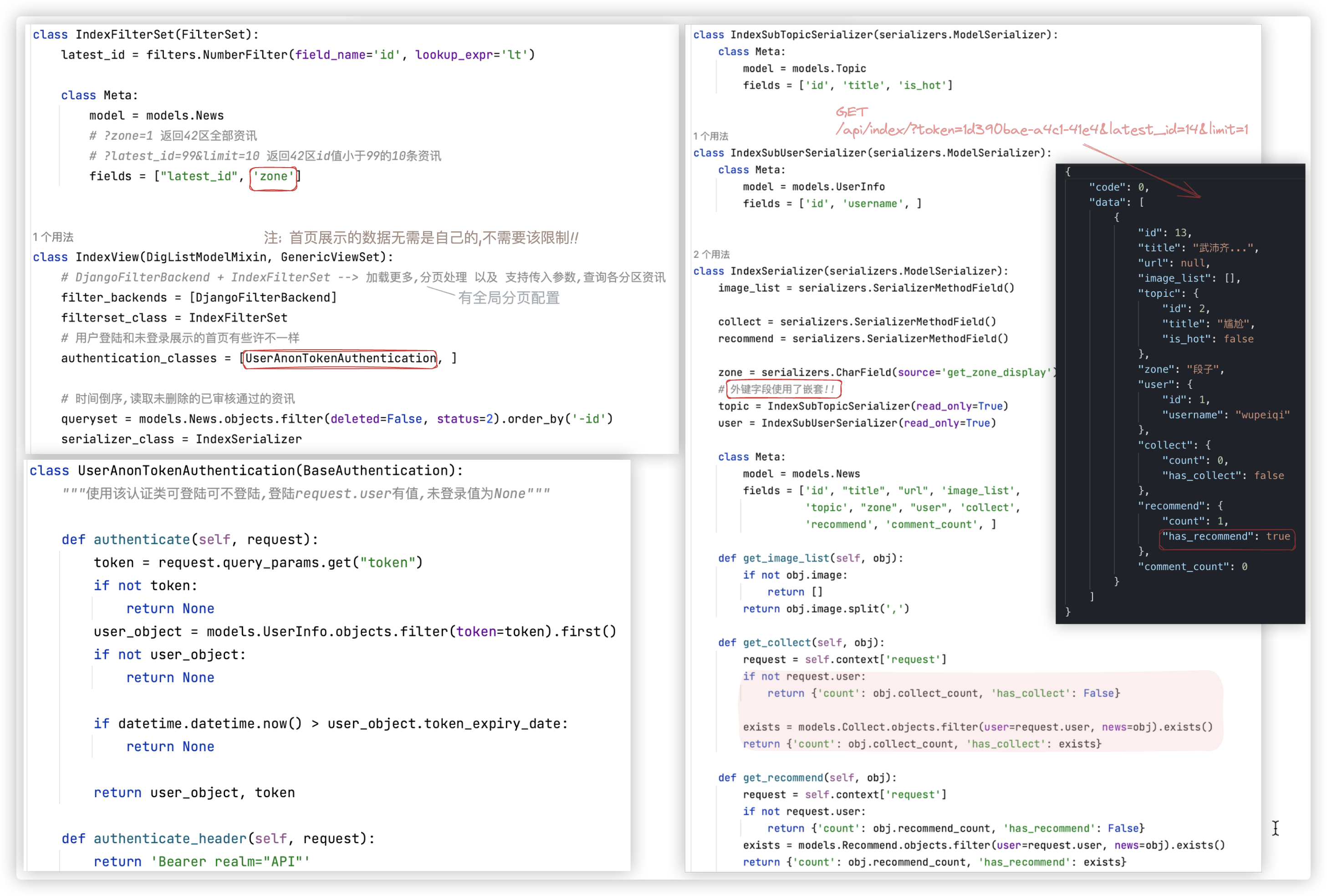
# index
首页 就一个列表展示的接口.
资讯首页
-1- 时间倒序,读取未删除的已审核通过的资讯
-2- 加载更多,分页处理 ?limit=2&latest_id=7
-3- 支持传入参数,查询各分区资讯: 图片、你问我答、42区、挨踢1024、段子 ?zone=2
-4- 用户登陆和未登录展示的首页有些许不一样
- 首页展示的内容,无需是自己的,没有该限制
- 登陆后,若当前登陆用户对该篇资讯进行了推荐、收藏,那个图标会点亮
(使用认证类<该认证类可登陆可不登陆,登陆request.user有值,未登录值为None>结合字段钩子来实现
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
关键代码如下: 再次提醒几点, 一是可登陆亦可不登陆的认证类,二是嵌套,三是该首页数据的展示无需是自己的..
关于外键字段 按照我们的心意进行展示! 详见 序列化+验证.md 这篇博文!! 里面写了三种方式!
# collect
收藏
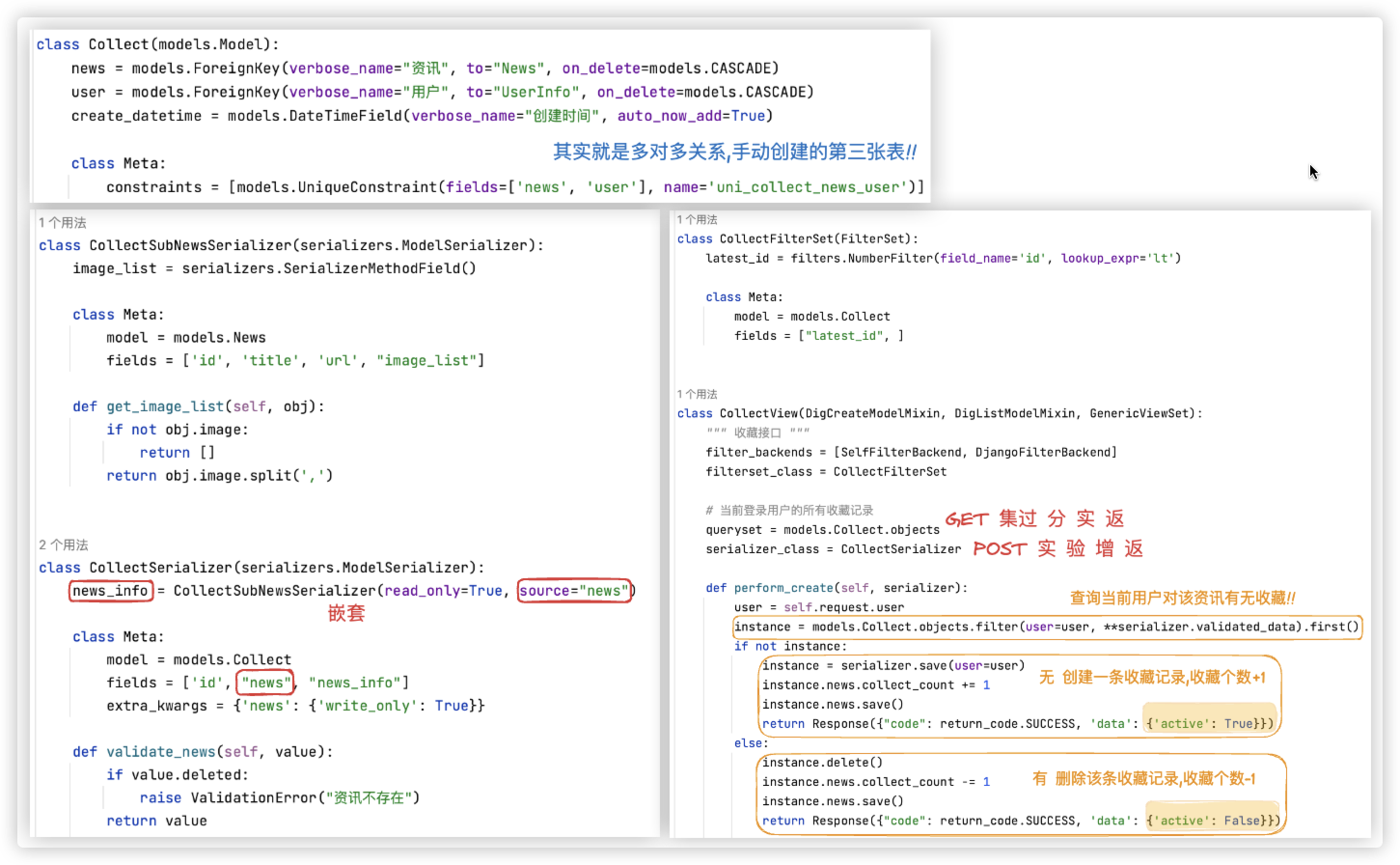
关于外键字段 按照我们的心意进行展示! 详见 序列化+验证.md 这篇博文!! 里面写了三种方式!
[需求1] 收藏、取消收藏 共用一个接口
- 不难分析出,用户只需传news字段,因为认证通过后,后端能自己拿到当前登陆的user
还需对该news字段做校验,得保证该资讯是未删除的是存在的!!
- 在perform_create中判断
若当前登陆用户未收藏该资讯 "未收藏 --> 已收藏 即添加一条收藏记录" + 该资讯的收藏数加1
若当前登陆用户已收藏该资讯 "已收藏 --> 取消收藏 即删除这条收藏记录" + 该资讯的收藏数减1
此示例代码在perform_create进行了return,那么返回给前端的数据就使用return的数据!看DigCreateModelMixin类的代码就清楚啦.
注:返回的数据中,包含active字段,设计该值是为了告诉前端此次接口是收藏还是取消收藏!!
若active值为True,那表明此次接口进行的是收藏的操作,若active的值为False,则表明此次接口进行的是取消收藏的操作!
先收藏 POST http://127.0.0.1:8000/api/collect/ {"news":10} -- {"code":0,"data":{"active":true}}
再取消收藏 POST http://127.0.0.1:8000/api/collect/ {"news":10} -- {"code":0,"data":{"active":false}}
[需求2] 收藏列表
该需求的实现,跟前面的类似,就不赘述了.
注: 收藏相关的ORM表中有两个外键字段,news、user,若想打印外键字段具体的信息,可以使用嵌套!!
但若嵌套字段的名字与ORM表中外键字段的名字不一样,需要给序列化器类中设定的这个嵌套字段设置source值,
source值为ORM表中的外键字段名!! 别问为啥,必须这样设置!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
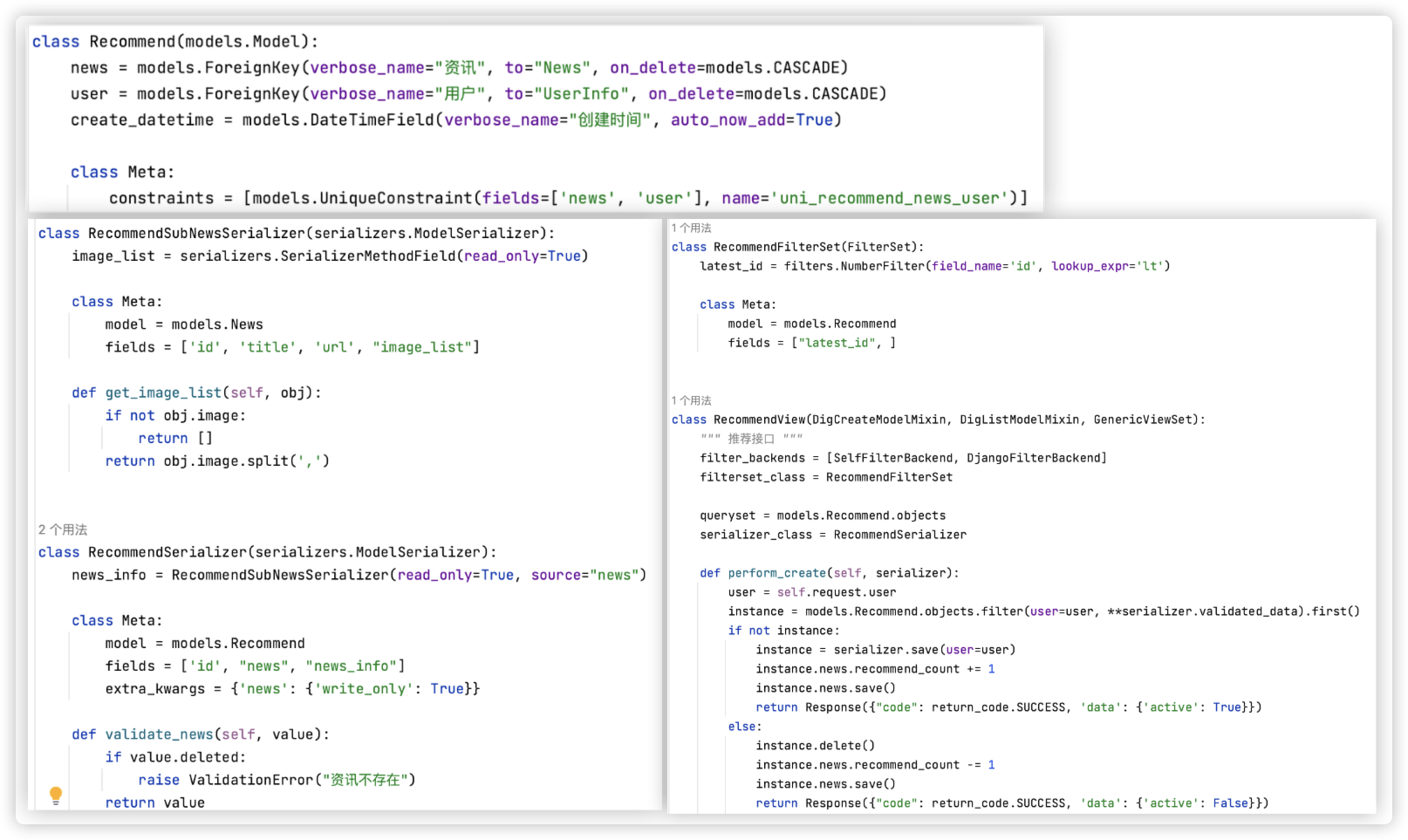
# recommend
推荐. 代码逻辑跟收藏不能说一样,只能是一模一样!!
# comment
评论. 新增评论、查看评论列表!
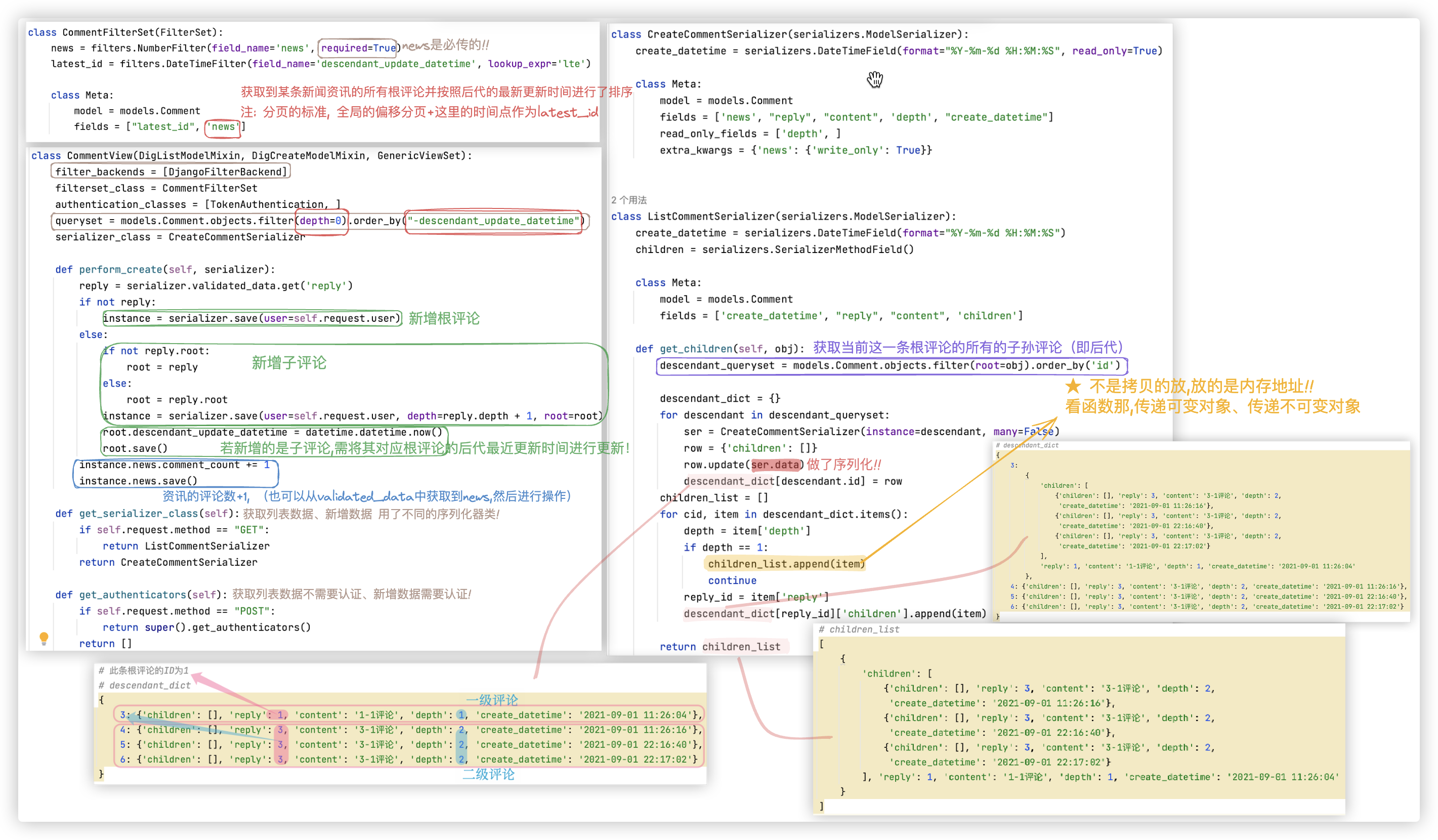
分析如下:
class Comment(models.Model):
""" 评论表 """
news = models.ForeignKey(verbose_name="资讯", to="News", on_delete=models.CASCADE)
user = models.ForeignKey(verbose_name="用户", to="UserInfo", on_delete=models.CASCADE)
content = models.CharField(verbose_name="内容", max_length=150)
# 默认值
depth = models.IntegerField(verbose_name="深度", default=0)
# 可为空的
root = models.ForeignKey(
verbose_name="根评论", to="Comment", related_name="descendant",
on_delete=models.CASCADE, null=True, blank=True)
reply = models.ForeignKey(
verbose_name="回复", to="Comment", related_name="reply_list",
on_delete=models.CASCADE, null=True, blank=True)
# 自动添加的
create_datetime = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
descendant_update_datetime = models.DateTimeField(verbose_name="后代更新时间", auto_now_add=True)
注:创建评论需要认证、查看评论不需要认证
[需求1] 创建评论 "实验增返"
- news 给哪条评论进行评论
- reply 给哪个评论进行回复
- content 评论的内容
- deptch 评论的深度,它不需要传,设置read_only=True 因为内部可找到回复的是"谁",将"谁"的深度加1就是当前评论的深度.
1> 若发布了一条根评论
前端传:
news、content、因为是根评论,该评论是没有给谁回复的,所以 reply=null (默认reply就是null,也可不传
存入数据库实现新增时,还需传递几个字段:
user 认证成功后,后端可自己拿到、
deptch 因为是根评论,所以deptch=0(默认deptch就是0,也可不传、
root 表明该条评论的根评论是谁,因为发布的评论就是根评论,所以root=null (默认root就是null,也可不传
2> 若发布了一条子评论,即给某条评论进行回复
前端传:
news、content、reply=回复的那条评论的ID
存入数据库实现新增时,还需传递几个字段:
user 认证成功后,后端可自己拿到、
deptch 回复的那条评论的深度+1、
root 表明该条评论的根评论是谁. 这里需要读取回复的那条评论的root或者deptch,作以下判断
- 若回复的那条评论的root=null or deptch=0, 那么root=回复的那条评论的ID
- 若回复的那条评论的root不为null or deptch的值不为0, 那么root=回复的那条评论的root
新增后的后续操作
<1> 若添加的是子评论,还需在新增后,更新当前新增的这个子评论所关联的根评论的最新更新时间!!
也就是根评论下新增了子孙评论,这个根评论的最新更新时间就得更新下!后续需要根据这个时间进行排序. <2> 对应的资讯的评论个数需+1
- 创建根评论
POST请求 http://127.0.0.1:8000/api/comment/?token=... 请求体 {"news":1,"content":"Hello"}
返回 {"code":0,"data":{"reply":null,"content":"Hello","depth":0,"create_datetime":"2024-01-18 20:05:45"}}
- 创建子评论
POST请求 http://127.0.0.1:8000/api/comment/?token=... 请求体 {"news":1,"content":"Hello","reply":9}
返回 {"code":0,"data":{"reply":9,"content":"Hello","depth":1,"create_datetime":"2024-01-18 20:07:29"}}
[需求2] 获取评论列表 "集过 分实返"
step1:根据后代的最新更新时间进行排序,获取所有根评论
step2:筛选 指定某一条资讯的根评论,示例代码中的news参数这个必须传 ?news=1 !
- 前两步,获取到某条新闻资讯的所有根评论并按照后代的最新更新时间进行了排序
step3:分页
全局分页limit默认设置的是10条;latest_id是根据最新更新的时间来的,有个弊端,数据不是实时的
eg:第一次取到了 7:01 6:55 6:51 的三条根评论,按道理下一次应取小于6:51时间点的评论
但此刻6:45的那条评论有子孙评论进行回复了,该根评论的最新更新时间变成了7:05 这次取就取不到它啦!! 所以不是实时的. step4:获取到根评论后,需要构造数据结构,将根评论对应的子孙评论放进去!!(这个数据结构的构建用到了传递可变对象,传递的是内存地址!!) - 获取当前这一条根评论的所有的子孙评论(即后代)
- 将子评论挂靠到跟评论上,最终形成父子关系通过JSON返回给前端.
- GET请求 http://127.0.0.1:8000/api/comment/?news=1 获取的到是默认的偏移分页,10条数据.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62