 初识
初识
1997 年, 超级计算机"深蓝"战胜世界国际象棋冠军"卡斯帕罗夫";
2016 年, AlphaGo 战胜世界顶级围棋棋手"李世石";
2022年11月30日发布了Chatgpt...
人工智能早已渗透在了我们生活的方方面面, 被越来越多的人熟知, 那人工智能到底是什么呢?
# 人工智能
人工智能是英文 Artificial Intelligence 的缩写, 简称 AI.
◎ 定义
人工智能只是一个抽象概念, 它不是任何具体的机器或算法. 它可以对人的意识、思维进行模拟, 但又不是人的智能.
换个说法, 任何类似于人的智能或高于人的智能的机器或算法都可以称为人工智能.
◎ 分类
人工智能也有强弱之分, 我们会把人工智能分为 弱人工智能 (Weak AI) 和强人工智能 (Strong AI).
-1- 弱人工智能: 擅长于单个方面技能的人工智能. eg: 图像识别, 语言识别, 自然语言处理等等.
-2- 强人工智能: 人类能干的脑力劳动它都能干. 很难, 我们现阶段还做不到!
◎ 图灵测试
图灵测试是由计算机科学之父图灵提出来的, 指的是测试者和被测试者 (被测试者有可能是人或机器) 在隔离的情况下,
测试者通过一些装置 (如键盘) 向被测试者提问. 经过多次测试之后:
若有 30%的测试者不能确定被测试者是人还是机器, 那么说明这台机器通过了测试.
从1950 年至今都没有机器能够很好地通过图灵测试, 包括Chatgpt.
◎ 人工智能技术演变
从3个维度进行的演变, 分别是 计算速度、算法、识别规则, 这三者依次递进..
-1- 计算速度: 象棋能看几十步远
-2- 算法:
围棋用暴力求解穷举, (把几步之内所有可能的走法都遍历一次, 然后选一个最优下法, 围棋的可能性太多了) 需要很大的算力支持
但运用算法后, 会更快, 会灵活, 机器就拥有"智慧"了, 棋力会更好.
-3- 识别规则:
在人工智能的早期阶段, 计算机的智能通常是基于人工制定的 "规则",
我们可以通过详细的规则去定义下棋的套路, 推理的方法, 以及路径规划的方案.
但是我们却很难用规则去详细描述图片中的物体, 比如我们要判断一张图片中是否存在猫.

识别猫, 给猫制定规则: 有两只三角形耳朵, 圆脸.. 但猫躲被子里只露出脸, 蜷缩起来呢? 那我们是要重新制定规则吗?
在图像识别领域, 使用使用人为定义的规则去做识别肯定是行不通的.
人类比较擅长的任务, 比如图像识别、语音识别、自然语言处理等, 计算机却完成得很差很多其他的领域也同样存在这种问题.
由于人们没有办法设计出足够复杂的规则来精确描述世界
So, AI 系统需要具备自我学习的能力, 即从原始数据中获取有用的知识. 这种能力被称为机器学习 (Machine Learning).
# 初识机器学习
机器学习就是从数据中自动分析获得规律, 并利用规律对未知数据进行预测、分类或者决策的过程.
换个说法: 机器学习可以利用 [已有的数据] 进行 [学习] , 获得一个训练好的 [模型], 然后可以利用此模型 [预测] 未来的情况.
举个原始人分辨太阳和月亮的例子:
- 假如我们现在都是原始人,并不知道太阳和月亮是什么东西.
- 但是我们可以观察天上的太阳和月亮
并且把太阳出来时候的光线和温度记录下来,把月亮出来时候的光线和温度记录下来(这就相当于是收集数据)
- 观察了100天之后,我们进行思考,总结这 100 天的规律我们可以发现:
太阳和月亮是交替出现的.出太阳的时候光线比较亮,温度比较高. 月亮出来的时候光线比较暗,温度比较低(这相当于是分析数据,建立模型)
- 之后我们看到太阳准备落山,月亮准备出来的时候我们就知道温度要降低可能要多穿树叶或毛皮(预测未来的情况)
2
3
4
5
6
□ 机器学习和人类思维的对比
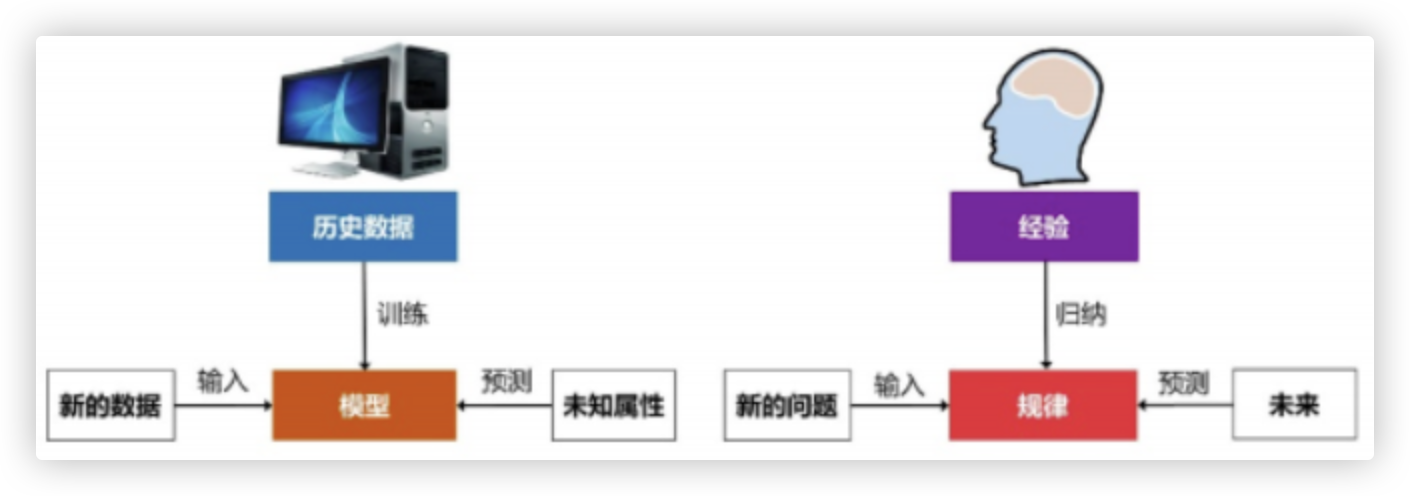
-1- 人类善于从以往的经验中总结规律, 当遇到新的问题时, 我们可以根据之前的经验来预测未来的结果.
-2- 我们可以使用历史数据来训练一个机器学习的模型, 模型训练好之后, 再放入新的数据, 模型就可以对新的数据进行预测分析.
□ 算法模型对象
算法模型对象可以理解是一种特殊的载体或容器,简单来说, y=w*x+b 这个方程/算法 就可算是一个算法模型对象..
它用于寻找数据间的规律. 每个算法模型里封装的算法都是不一样的.
□ 样本数据
样本数据分为两类, 很关键, 务必记住.
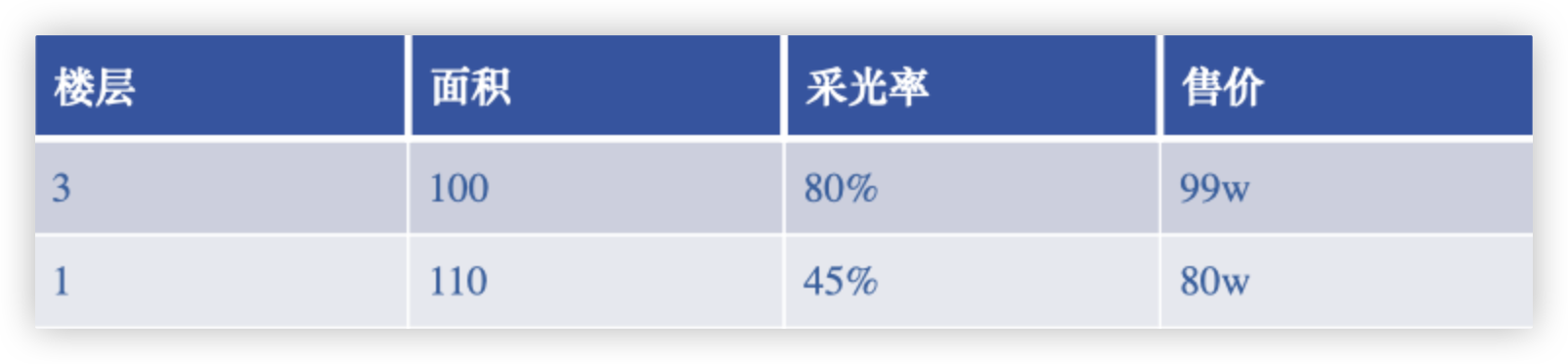
以上面表格数据为例, 我们通过 楼层、面积、采光率等信息 评估出相应的售价..
在该例子中, 楼层、面积、采光率 就是 特征数据/自变量/一个样本的描述信息; 售价是 标签数据/因变量/一个样本数据的结果.
□ 算法模型的分类
-1- 有监督类别: 用到的样本需要传特征和标签..
-2- 无监督类别: 用到的样本只需传特征.. 不需要标签..
其实, 还有种 半监督类别 我们初学者暂且不考虑.
□ 机器学习的应用
看一眼就行了, 有一丢丢了解即可.
几乎所有领域的企业都能够找到适合机器学习的应用场景, 并通过数据驱动决策、自动化流程等方式提升企业价值.
目前机器学习的应用已经渗透在了我们生活、工作和学习的方方面面和角角落落了. 比如:
1. 风险评估:
机器学习可以通过分析大量的历史数据和特征,构建风险模型,帮助企业评估客户的信用风险和授信决策.
这对金融机构、电商平台等企业在风控方面起到重要作用,减少坏账风险、提高贷款和信用的准确性.
2. 营销和销售预测:
机器学习可以通过分析市场数据、客户行为等信息,预测产品需求和客户购买意愿,帮助企业进行营销和销售策略的决策.
这可以提高市场推广的效果,减少成本,增加销售额和利润.
3. 客户细分和个性化推荐:
通过机器学习模型,企业可以将大量的客户数据分析成不同的细分群体,并根据用户的偏好和行为,提供个性化的产品推荐、优惠券和推广活动.
这提高了客户体验,增加了客户忠诚度.
4. 故障预测和预防性维护:
利用机器学习模型和传感器数据,可以预测设备或系统的故障和损坏,帮助企业进行预防性维护和减少停机时间.
这对制造业、能源行业等有关设备运维的企业非常有价值,提高了设备的可靠性和生产效率.
5. 供应链优化:
通过机器学习分析供应链相关数据,可帮助企业预测需求、优化库存管理、提高生产计划准确性,
并提供供应商选择和物流路线优化建议,提高供应链的效能和灵活性.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 基本操作
◎ 数据集获取途径
-1- 公开数据集: UCI机器学习库(最常用)、Kaggle竞赛平台等.
-2- 数据采集: 爬虫技术, 从网站或API中抓取数据.
-3- 数据库查询: 企业或组织可能已经维护了一个大量数据的数据库, 读取这些数据, 根据需求保存为csv等文件.
-4- 数据生成: 在需要大量数据或者无法直接获得真实数据的情况下, 可以通过模拟、随机生成或合成数据来创建自己的数据集.
-5- sklearn提供的开源数据集: sklearn的datasets模块中提供了小规模和较大规模的数据集, 可供大家在日常学习中进行测试..
UCI官网: https://archive.ics.uci.edu/
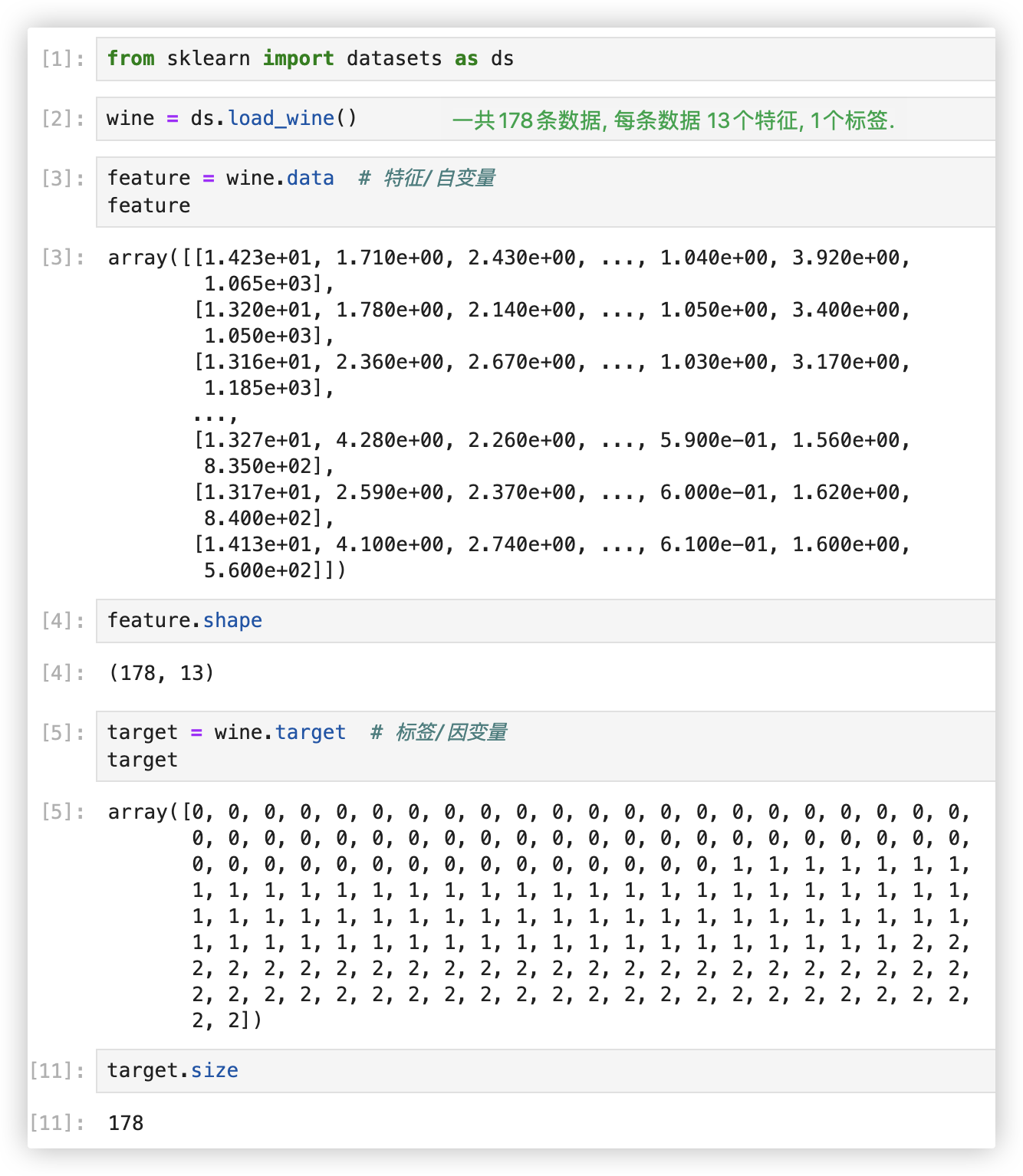
sklearn数据集接口:
sklearn.datasets.load_*():获取小规模的数据集; sklearn.datasets.fetch_*():获取大规模的数据集
PS: 获取大规模数据时,可能会因为网络原因获取不到,需多试几次.
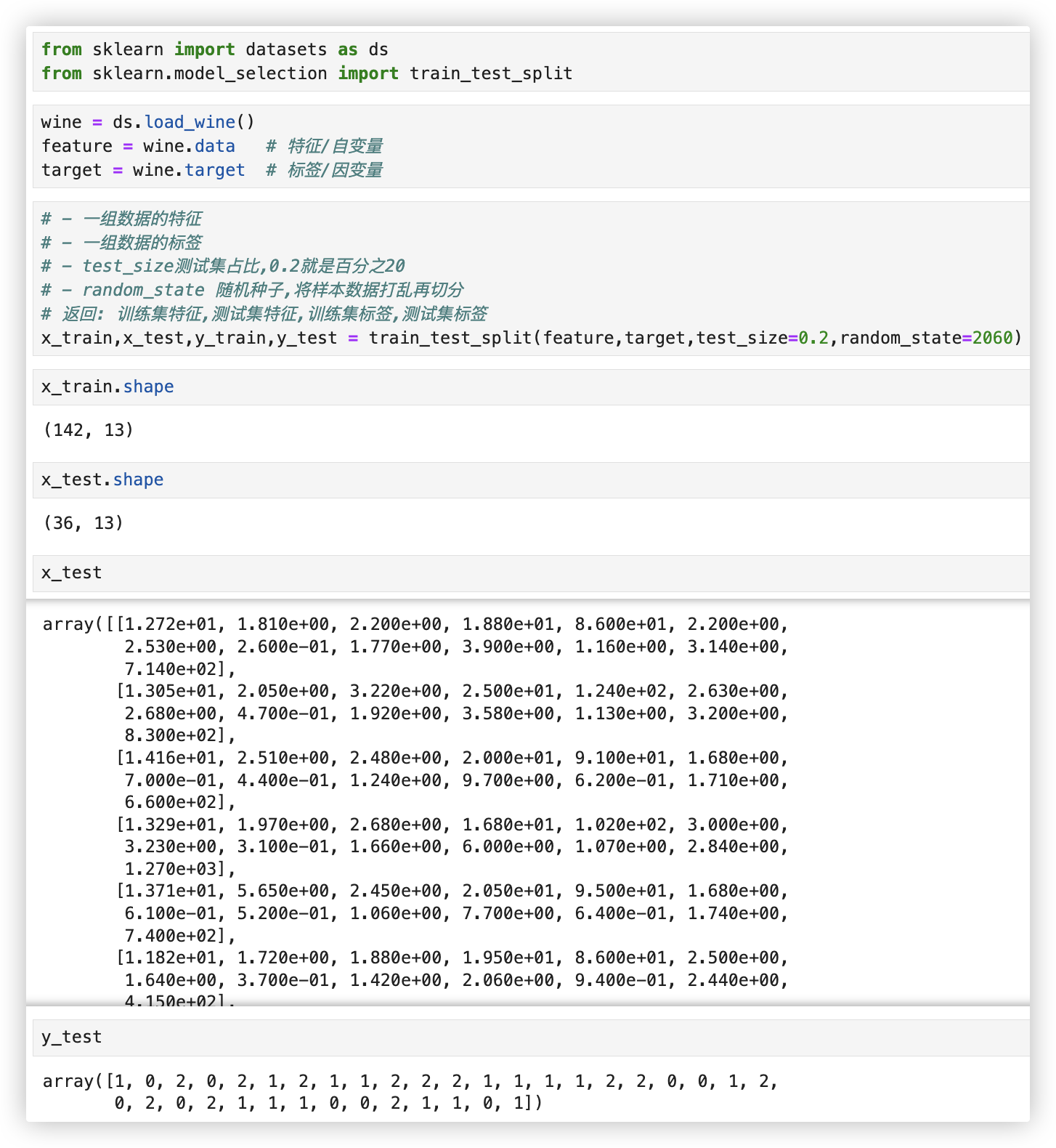
◎ 数据集切分
不能将一组数据全部都用来训练后, 然后又取这一组数据的一部分来进行测试... 这样检测出的训练效果无意义..
正确的做法, 将一组数据进行二八分, 80%的数据用于训练, 20%的数据用于对训练的结果进行测试..
获取大规模数据集 老是报403的错误.. 可以曲线救国..
在源码里找到下载路径. 下载数据集并解压到任意目录.. 读取文件手动加载数据集..
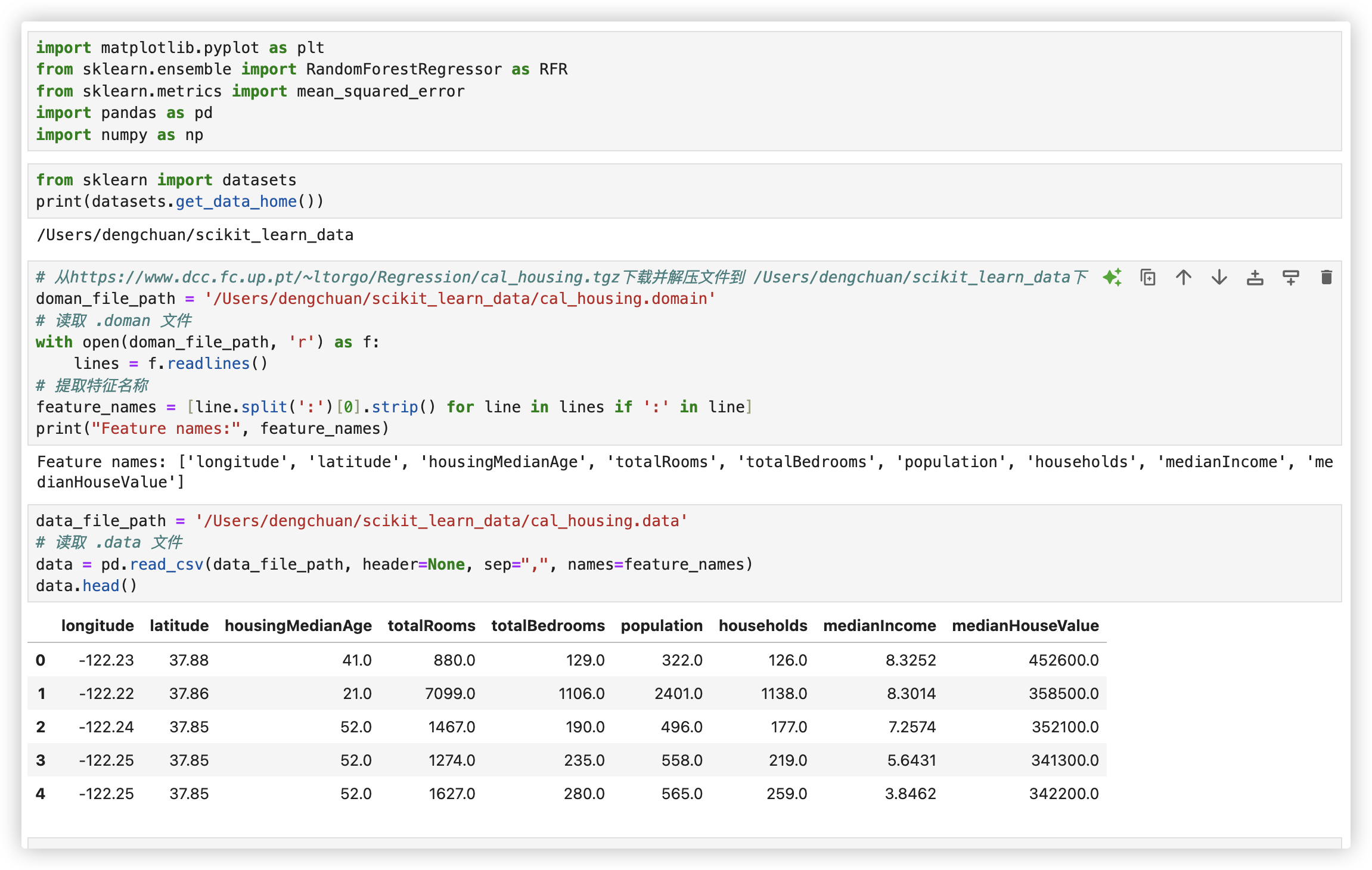
代码如下:
doman_file_path = '/Users/dengchuan/scikit_learn_data/cal_housing.domain'
# 读取 .doman 文件
with open(doman_file_path, 'r') as f:
lines = f.readlines()
# 提取特征名称
feature_names = [line.split(':')[0].strip() for line in lines if ':' in line]
print("Feature names:", feature_names)
data_file_path = '/Users/dengchuan/scikit_learn_data/cal_housing.data'
# 读取 .data 文件
data = pd.read_csv(data_file_path, header=None, sep=",", names=feature_names)
data.head()
X_fc = data.iloc[:,:-1]
y_fc = data.iloc[:,-1]
2
3
4
5
6
7
8
9
10
11
12
13
14
15