 函数基础
函数基础
在函数开始之前,声明下我的一个基础概念的认知错误, namespace指的是命名空间! scope指的是作用域! 我混用了..在类的学习中才认识到这个问题.. 问题不大.
# 函数的定义调用
函数的使用必须遵循先定义,后调用的原则
扩展: 提高健壮性 -- https://www.cnblogs.com/liuqingzheng/p/11012099.html (该篇博文的开头写错了, python是一门强类型语言!!不是弱类型.)
使用该方式,传递的实参或者返回的数据不是指定的类型,不会报错,指定的那些东西也不会允许,只是辅助,写来方便看的..
像java和go这些编译型语言,必须指定类型并且传指定的类型,不然报错.. 非常严格. 动态一时爽, 重构火葬场.
Python中的错误至少有两种:
语法/解析错误 -- 语句或表达式在语法上的错误
异常 -- 在执行时检测到的错误被称为异常
函数 定义 阶段: 只检测函数体的语法,不执行函数体代码
函数 调用 阶段: 执行函数体代码
"""
a.py模块下只有这些代码,运行a.py文件. 第5行会报语法错误.
第二行没报错,证明了在定义阶段函数体代码是不会执行的!!
打开注释 调用func函数,开始执行函数体代码,第二行会报UnboundLocalError的异常
"""
def func():
a
a = b + 1
yuasyf
m n p
# func()
2
3
4
5
6
7
8
9
10
11
函数定义的 规范 写法:
def 函数名(参数1,参数2,...):
"""
函数功能描述消息
:param 参数1:描述
:param 参数2:描述
:return: 返回值
"""
pass
2
3
4
5
6
7
8
函数返回值
函数中不写return或return不带任何返回值,都相当于在函数体最后一行添加 return None
# 函数参数传递
敲重点, 函数参数传递等同于直接赋值, 根据 定理1 , 函数被调用后, 函数的参数就是局部变量!!
# 赋值操作
在理清函数参数传递之前,要先记住两个重要的定理!! 非常重要! 知其然要知其所以然..
◎ 定理1: python在作用域里对变量的 赋值操作 规则:
若被赋值的变量在该作用域已存在,则对其绑定新的对象; 若不存在,则将此次赋值视为对这个变量的定义..
提一嘴哈,定理1的由来跟变量的可见性的判定有关!!
◎ 定理2: python中的绑定操作(eg 赋值)都是对象引用(内存地址)的传递
换个说法,一系列的绑定操作都是在传递某一对象的地址给某一变量名进行绑定!!
引用是啥?引用就是指向. 变量名指向自身绑定对象的内存地址!!
被赋值 = (右侧的变量/对象们)被引用 -- 找到引用变量绑定的对象, 进行运算后的结果/对象 传递给被赋值的变量
在这里,体会下 "python引用语义" 带来的 坑.. ▲需求:循环去除列表中的3
"""
分析: 我们知道,A操作会根据nums列表的 "下标" 1、2、3..的顺序循环取值赋值给i
即i变量是nums[0]、nums[1]、nums[2]的引用
当下标循环到2时,去除了nums列表中的第一个3,
但因为remove操作,nums列表从下标为3开始的位置的数据都往前挪动了一位,最后变为了[1,2,3,3,4];
A循环操作的下标按照顺序接着循环到3,问题来啦,此时列表中nums[2]的值为3却被跳过了..
"""
nums = [1, 2, 3, 3, 3, 4]
for i in nums: # A
if i == 3:
nums.remove(i) # B
print(nums, len(nums)) # [1, 2, 3, 4] 4
# -- 正解 进行列表的浅拷贝
nums = [1, 2, 3, 3, 3, 4]
for i in nums[:]:
if i == 3:
nums.remove(i)
print(nums, len(nums)) # [1, 2, 4] 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 传递不可变对象
针对不可变对象(tuple\str\bool\数字\不可变集合)
很多资料将其称作 函数参数 --值传递(拷贝) 别被骗了,本质是传递内存地址,还是引用语义,不是值语义!!
仔细想哈嘛, 不可变对象变不了啊, 一变就是重新赋值, id都变了.. 有点值类型那味,但不是值类型!!
"""-- 分析
1> 参数a接收到的是值的类型是数字,数字是一个不可变对象
2> So,会将接收到的值进行一份拷贝! -- 值传递(拷贝)
根据定理1,因为func函数内不存在变量a,所以会在func函数里新定义局部变量a,并将拷贝的值赋值给局部变量a.
★ 注意: func函数新定义的局部变量a与全局变量a无任何瓜葛!!
"""
def func(a):
a = a + '3'
return a
a = '5'
res = func(a)
print(a,res) # '5' '53'
2
3
4
5
6
7
8
9
10
11
12
13
# 传递可变对象
函数参数 --引用传递(内存地址) 针对可变对象(list\dict\set)
"""-- 初步分析
1> 参数a接收到的是值的类型是列表,列表是一个不可变对象
2> So,会对接收到的值进行引用 -- 引用传递(内存地址)
根据定理1,因为func函数内不存在变量a,所以会在func函数里新定义局部变量a,将接收到的引用给局部变量a.
★ 注意: func函数新定义的局部变量a与全局变量a维护/指向的是同一个内存地址!!
"""
def func(a):
a += [4] # -- 列表+=操作原地改变 等同于 a.extend([4])
return a
a = [1,2,3]
res = func(a)
print(a,res) # [1, 2, 3, 4] [1, 2, 3, 4]
# --- --- ---
def func(a): # -- 根据定理1,参数传递,定义了局部变量a. 此时[1,2,3]的引用计数为2
a = a + [4] # -- 根据定理1,因为已经存在局部变量a,该赋值操作是在对局部变量a重新赋值
# 重新赋值后,局部变量a重新绑定了一个新的对象[1,2,3,4]. 导致[1,2,3]的引用计数减1
# id(左边a) != id(右边a) 它俩不是同一个对象
return a
a = [1,2,3]
res = func(a)
print(a,res) # [1, 2, 3] [1, 2, 3, 4]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# UnboundLocalError
官方解释: When a name is not found at all, a
NameErrorexception is raised.
If the name refers to a local variable that has not been bound, aUnboundLocalErrorexception is raised.UnboundLocalErroris a subclass ofNameError.
翻译成人话:
若引用了某个变量,此变量在各个作用域里都找不到,就会报错 NameError ;
若引用的变量是 局部变量 ,但还未完成绑定,就会报错 UnboundLocalError ..
UnboundLocalError 是 NameError 的一个子类..
深度分析详见后文 “python变量的可见性” 部分的内容!!!
"""
代码第二行报错: local variable 'a' referenced before assignment
翻译过来: 局部变量'a'在赋值前被引用
分析: func()函数没有参数,即不存在函数传递过程中定义局部变量
函数体内有对a的赋值操作,根据定理1,因为func函数内没有局部变量a,则该赋值操作是在定义局部变量a,而在赋值操作的右侧引用了还未被定义完成的局部变量a
Ps:有很长一段时间我是这样理解这个报错的.开始回溯我的理解.理解出错的地方在于(-- --)包含起来的这段文字.
(-- 解释器发现右侧的a变量在局部作用域里还未绑定好,就引用全局变量a-- ),而"="左侧的a是局部变量,在一个赋值操作中,某一变量不可能既充当局部变量,又充当全局变量.. 进而产生了冲突.报错提示不是这样的,显然这样理解有偏差!!
正确的过程应该是,调用函数,函数体代码开始执行,在执行之前会扫描函数体代码,看是否有绑定操作的代码,在这个案例里,
a = a + 4,这个语句,发现它是赋值操作(绑定操作的一种),a变量在该局部命名空间(就是存放变量名与绑定对象的栈区!!)便具备可见性,到这一步a变量已经定性为一个局部变量啦..但要注意一点,可见性的变量在完成绑定后,才能被引用.
函数体代码开始真正执行,执行到a = a + 4这行代码,等式右边会先执行,发现右侧引用了还未绑定好的局部变量a..
为啥报错,"UnboundLocalError:局部变量'a'在赋值前被引用"也就得到了合理的解释.
"""
def func():
a += 4 # a+=[4]报错 a.extend([4])不会报错
return a
a = 1 # a=[] 当a是一个列表时
res = func()
print(a,res)
# --- --- ---
# `若引用的变量是局部变量,但还未完成绑定,就会报错UnboundLocalError.`
# 注意报UnboundLocalError错误的前提是该变量是局部变量!!而下方的m是全局变量!
m = m + 1 # -- NameError: name 'a' is not defined
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 函数形参和实参
在上文我们知道 函数的参数传递 可看作是一个赋值操作
a = ?定义的是函数的局部变量
具体一点, 参数分为形参和实参:
形参 -- 本质就是变量名; 实参 -- 本质就是变量的值
# 定义函数时 -- 行参
定义函数时 位置形参-默认形参-不定长位置形参-命名关键字形参-不定长关键字形参
| 形参 | 特性 |
|---|---|
| 位置形参 | 必须被传值,多一个不行少一个也不行!! |
| 默认形参 | 意味着调用阶段可以不用为其赋值(可以不用指定对应的实参)!! |
| 不定长位置形参 | *args 会将溢出的位置实参全部接收,然后以元祖的形式赋值给*后面的变量args |
| 命名关键字形参 | * (*或者*args) 后面的形参对应的实参必须按照key=value的形式进行传值 |
| 不定长关键字形参 | **kwargs 会将溢出的关键字实参全部接收,然后以字典的形式赋值给 **后面的变量kwargs |
# 调用函数时 -- 实参
调用函数时 位置实参 关键字实参
1> 两种实参可以混用, 但位置实参必须在关键字实参前面!且不能对一个形参重复赋值!
2> 实参可以拆包!
实参中带*,*会将该变量的值循环取出,打散成位置实参.
即以后但凡碰到实参中带*的,它就是位置实参,应该立刻打散成位置实参来看
实参中带**,**会将该变量的值循环取出,打散成关键字实参.
即以后但凡碰到实参中带**的,它就是关键字实参,应该立刻打散成关键字实参去看
def func3(a1, a2, a3, a4=10, *args, a5=20, a6, **kwargs):
# 11 22 33 44 20 10 (55, 66, 77) {'a10': 123}
print(a1, a2, a3, a4, a5, a6, args, kwargs)
# func3(11, *[22, 33, 44, 55, 66, 77], **{'a6': 10, 'a10': 123})
func3(11, 22, 33, 44, 55, 66, 77, a6=10, a10=123)
def func(*p):
return sum(p)
func(1,2,3,4) # 10
def func(**p):
return ''.join(sorted(p))
func(x=1,z=2,y=3) # 'xyz'
# ======================
>>> def func1(a):
print(a)
>>> func1(3)
3
>>> func1(a=5)
5
>>> k = {'a':5}
>>> func1(**k) # **k拆包 -> a=5
5
# ============★★★★★★★★★★★
def func1(*args, **kwargs): # 不定长关键字形参接受多余的关键字实参 kwargs是字典-->{'id':2,'age':20}
return func2(*args, **kwargs) # **kwargs拆包-->id=2,age=20
def func2(id, **kwargs):
return id, kwargs
res = func1(id=2, age=20)
print(res) # (2, {'age': 20})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 默认形参陷阱
记住两点:
除非程序结束,否则该共享空间不会被释放; 类似于全局变量 .
默认形参的值通常应该定义为不可变类型.
egon说, "默认形参的值只在定义阶段赋值一次,即默认参数的值在函数定义阶段就已经固定死了".
这意味着当函数被定义时将对表达式求值一次,相同的“预计算”值将在每次调用时被使用
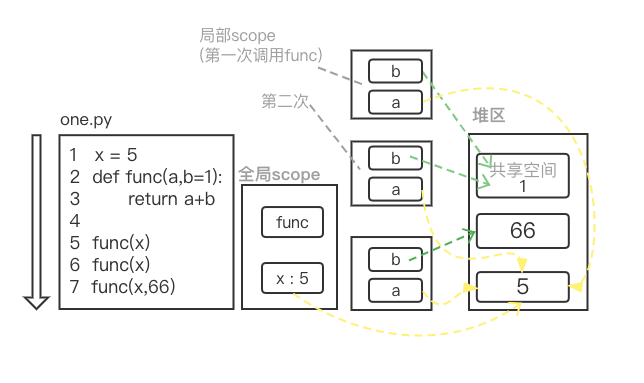
○ one.py文件开始运行,创建全局scope, 从上往下依次执行代码
执行第1 2行代码, 实现将x、func依次压入全局scope这个栈中
执行第2行代码时, 发现该func函数有默认参数,则会创建一个 "共享空间" ,将该默认参数的值存储起来
○ 第3行代码暂时不会执行,往下执行第5行代码,调用func函数,并传递了一个不可变类型的参数.. 具体展开:
1> 调用函数时,解释器就会为该函数创建一个局部scope命名空间
2> 在函数真正执行之前扫描函数代码, 找绑定操作, 发现了有两个形参 ( 形参是绑定操作的一种 )
因为绑定操作, 变量a和b便在刚创建的scope空间中具备了可见性!!意味着a和b变量定性为局部变量..
3> 函数真正执行, 变量绑定了5的内存地址,b变量绑定了共享空间中1的内存地址..
和b变量完成绑定操作后, 和b变量便可以被引用!! retuen语句中就有对 和b变量的引用.
○ 第5行代码执行完后,对应的局部scope空间会释放!!
继续往下执行,只要是调用函数的代码就会创建新的局部scope,函数调用完就释放..
三次函数调用,不同点在于第三次调用的func函数,没有用共享空间里的值.. 但对共享空间没有影响!!
按理来说,堆区里的数据根据gc机制,引用计数为0会释放掉, 但共享空间里的值类似于全局变量..
除非程序结束,否则该共享空间不会被释放!!!
▲实验见真知: 默认参数是可变类型的数据带来的麻烦!!!
def func(a=[555]):
a.extend([1, 2, 3]) # -- 等同于 a+=[1,2,3]
return a,id(a)
# -- 函数第一次调用时共享空间为[555];第二次调用时没有用共享空间;第三次调用时共享空间为[555,1,2,3];
# 可以观察到,第一次id(a)和第三次id(a)是一样的..
# 证明第二次调用虽然没有用共享空间会导致[555]的引用计数为0,但该共享空间没有被释放!!
print(func())
print(func([])) # -- 若不使用默认的[555],自己指定值,那么函数体内的a的id不是共享空间中a的id.
print(func())
"""结果
([555, 1, 2, 3], 140573741203776)
([1, 2, 3], 140692741938688)
([555, 1, 2, 3, 1, 2, 3], 140573741203776)
"""
# --- --- ---
# 依照python在作用域里对变量的赋值操作规则
# 注意哦,函数体内对此默认形参重新赋值,是为此变量绑定了一个新的对象!!!
def func(a=[555]):
print(a, id(a))
a = a + [1, 2, 3] # -- 局部变量a重新赋值,其id发生变化
return a,id(a)
# -- 可以观察到函数第一次和第二次调用的共享空间都为[555],其id也没有发生变化!
# 证明 a = a + [1, 2, 3] 该行代码虽然导致[555]的引用计数为0,但该共享空间没有被释放!
print(func()) # [555, 1, 2, 3]
print(func()) # [555, 1, 2, 3]
"""结果
[555] 140263832453056
([555, 1, 2, 3], 140263832467520)
[555] 140263832453056
([555, 1, 2, 3], 140263832428928)
"""
# --- --- --- 正解
def func0(a,b=None):
if b is None:
b = []
# --- --- --- 换个思考角度理解 默认形参陷阱
"""
默认形参的共享空间可以简单理解成 一个全局变量
"""
def func(a=[555]):pass func() func()
b = [555] def func(a=b):pass func() func()
b = [555] def func(a):pass func(b) func(b)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 函数命名空间与作用域
# 函数对象
# 函数是第一类对象
函数是第一类对象,可以当作数据进行传递!
a = lambda x:x+1
1> 被引用;b = a
2> 当作参数传递;func(a):pass
3> 返回值是函数;func(*args):return a
4> 作为容器类型的元素[1,2,a,3]
def foo():
print('foo')
def bar():
print('bar')
dic = {
'foo': foo,
'bar': bar,
}
while True:
choice = input('>>: ').strip()
if choice in dic:
dic[choice]()
2
3
4
5
6
7
8
9
10
11
12
13
14
# 函数嵌套定义
需求: 将圆相关的计算(面积、周长)集中在一起.
from math import pi
def circle(radius, action='area'):
def area():
return pi * (radius**2)
def perimeter():
return 2 * pi * radius
if action == 'area':
return area()
elif action == 'perimeter':
return perimeter()
print(circle(10, 'perimeter'))
# -- Ps: max(max(2,3),8)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 打破层级限制
函数对象可以将定义在函数内的函数返回到全局中使用,从而打破函数的层级限制
def f1():
def inner():
print('from inner')
return inner
f = f1() # -- 拿到inner函数的内存地址.
2
3
4
5
6
# 命名空间scope/栈区
# 命名空间概念
在一个复杂的程序中,会定义成千上万个变量(函数名、类名都是变量), 为了便于追踪这些变量,让它们互不干扰,命名空间就应运而生啦!!
命名空间 scope/namespaces: 这几种说法都正确
1> 存放名字与值绑定关系的地方, 一般简说命名空间(栈区)为存放变量名的地方.
2> 命名空间是键值对的集合! 变量名与值是一一对应的关系..
3> 命名空间是变量名到对象内存地址的映射.
eg:x=1 开辟一块空间,1 存放在内存中; x:id(1) 放在命名空间中
从 变量存储 的角度, 在定义变量时, 变量名与值内存地址的关联关系 存放于栈区 stack, 变量值 存放于堆区 heap .
# 命名空间分类
一个命名空间中不能有重名的变量名
各个命名空间是独立的 , 没有任何关系的, 所以 不同的命名空间是可以有重名的,没有任何影响
Ps: 一个套一个的名字空间中同名的变量名会形成名字空间链
print(len) # <built-in function len>
x=1
if 3>2:
z=5
def func():
y=2
func()
# -- 内置命名空间中的对象可以通过 dir(__builtins__) 命令查看.
2
3
4
5
6
7
8
9
| 类别 | 解释 |
|---|---|
| 内置命名空间 built-in names | 存放python解释器自带的名字 len |
| 全局命名空间 global names | 存放模块中定义的名字(该模块中除开内置的和局部的,都是全局的) x func z |
| 局部命名空间 local names | 存放函数调用时函数中定义的名字 y 提一嘴,严谨点说应该说是代码块里绑定操作中的名字!! |
Ps: 严谨一点, 解释器还为程序使用 import 语句加载的任何模块创建一个全局命名空间
注意: 全局和局部命名空间的实现是字典, 但内置命名空间不是!
# 命名空间与代码块的关系
代码块通常是指, 类、函数 中包含的代码!!
Python解释器会在 执行 函数代码块时,为其分配一个局部命名空间..
"""
0 不是一个代码块,是除类和函数以外的代码,归属于全局命名空间管!
1-2 是一个代码块
3-10 是一个代码块
5-10 是一个代码块
7-9 是一个代码块
(后三个代码块实现了代码块的嵌套)
代码块与命名空间
上述的四个代码块,每个代码块在执行时,python解释器会分配一个局部命名空间(是真实的内存空间)
注意哦,函数在调用时才会执行!
还要特别注意,代码块可以嵌套,但命名空间是相互独立的!!
"""
m = 0 # 0
def func0(): # 1
return 1 # 2
class Test: # 3
a = 1 # 4
def func1(self): # 5
a = 2 # 6
def func2(): # 7
b = 3 # 8
print(b) # 9
return func2 # 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 命名空间生命周期
指的是命名空间中的 变量名!! 不是内存中的变量值的生命周期!!
内置: 在解释器启动时直接创建加载,直到解释器关闭时失效. 全局: 在文件执行时生效,在文件执行完毕时失效. 局部: 在 文件执行过程中 ,如果调用了某个函数才会 临时生效 ,在 函数执行完毕后失效.
局部命名空间的声明周期是自其建立开始,到它们各自的函数执行完毕终止.. 当这些命名空间的函数终止时, Python可能不会立即回收分配给这些命名空间的内存, 但是对其中对象的所有引用都将失效..
# 变量加载查询顺序
变量加载进命名空间的顺序: 内置 --> 全局 --> 局部
变量在命名空间里查找的顺序: 从当前位置的局部命名空间 --> 全局 --> 内置
通俗点解释下:
在代码从而下的执行过程中,不断有变量被加载进对应的命名空间..当遇到def语句,会先将函数名字加载进全局命名空间,但函数体代码不会执行,会暂时跳过; 函数内部的变量要等到函数调用的时候才会加载进局部命名空间...
引用的变量在命名空间里查找的顺序(作用域关系):
举个例子,函数里使用了x变量,但此变量不在该函数的局部命名空间里,就会去全局命名空间里找...
当然实际情况会更复杂.后文会详细阐述作用域.
"""变量加载进命名空间
第几行代码 全局 局部
1 func
4 func x:1
5 func x:1 y:2
6 func x:10 y:2
记住一句话,作用域关系是在函数定义阶段就固定死了,与函数的调用位置无关!!
"""
def func():
y = 2
print(x)
x = 1
func() # 1
x = 10
func() # 10 -- 在调用函数之前,全局命名空间里的x的值被改为10啦
# --- --- ---
x = 10
a = lambda y: x + y
x = 20
b = lambda y: x + y
print(a(10)) # 30
print(b(10)) # 30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 作用域
# 概念
严谨点说,python解释器会给每个代码块分配命名空间,代码块中的绑定操作使得变量在命名空间具备可见性.绑定操作完成后,变量可被引用..
命名空间相互独立,不同命名空间中可能具备相同的变量名,当代码块中出现变量引用时,引用哪个命名空间中的变量呢?这就需要作用域!!
(代码块中的绑定操作 -- 命名空间存储对应的变量名; 代码块中的变量引用 -- 按作用域关系进行查找! )
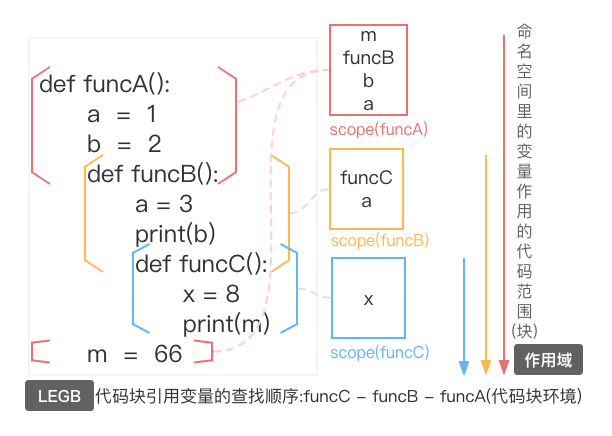
Ps: 代码块环境是什么? 该code block中所有scope中可见的name的集合构成block的环境..
作用域即代码块!! scope空间里的变量作用的范围就是所对应的代码块,这些变量在该代码块中是可见的
作用域关系LEGB/函数里引用变量的搜索路径/依次从LEGB作用域对应的scope中查找!
从嵌套的里层往外层查找
作用域关系 查找顺序LEGB,所以跟 代码块的嵌套 有关, 查的是LEGB对应的scope,所以跟 代码块的环境 有关!
内心OS:感觉自己将简单的东西复杂化了,想与专业名词一一对应上. ╮( ̄▽ ̄"")╭ 当作加深印象理解吧
解释下上图:
该程序有三个函数,可划分出代码块A、B、C,这三个代码块是相互嵌套的.
(代码块A包含1-10行全部代码;代码块B包含4-9行代码;代码块C包含7-9行代码)
A代码块会执行红色框起来的那两部分代码(B函数体代码是不会执行的),将绑定操作代码里的变量存到局部scope中!
即A代码会依次将a b funcB m压入scope(funcA)这个栈中
B代码块、C代码块的执行同理.
scope空间里的变量作用的范围就是所对应的代码块. 代码块A的局部scope的作用范围就是代码块A.
作用域即代码块!!
代码块引用变量的查找顺序LEGB从代码块环境的角度解释是解释得通的.但感觉复杂化了.
代码块引用变量先从本地作用域/里层代码块所对应的scope中查找;
若没有再去嵌套作用域/中间层代码块所对应的scope中查找;以此类推.
在这里,代码块C中引用了变量m,在scope(c)/代码块C的环境中没有,
在scope(B)/代码块B的环境中查找 也没有.
"你想一下代码块B的环境=scope(B)+scope(C),scope(C)中没有是不是就剩scope(B)啦"
最后在scope(A)里找到啦!
依次从LEGB作用域对应的scope中查找!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
提一嘴, 通常在编程语言中, 变量的作用域从代码结构 (代码块) 角度来看, 有块级、函数、类、模块、包等由小到大的级别.但是在Python中, 没有块级作用域, 也就是类似if语句块、for语句块、with上下文管理器等等是不存在作用域概念的, 他们等同于普通的语句!
换个说法: 只有模块module,类class以及函数def、lambda才会引入新的作用域(即开辟新的命名空间), 其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的..
# LEGB
在表达式中引用变量时,Python解释器将按照如下顺序遍历各作用域,以解析该引用:
局部作用域/局部命名空间里变量的作用范围 -- 当前函数的范围 L Local
内嵌作用域/内嵌命名空间里变量的作用范围 -- 函数嵌套里外围函数的范围 E Enclosing
全局作用域/全局命名空间里变量的作用范围 -- 当前py模块的范围(不包含import的py模块) G Global
内置作用域/内置命名空间里变量的作用范围 -- 包含len及str等函数的那个scope B Built-in
若在这些地方都找不到名称相符的变量,就会抛出NameError异常..
作用域关系(函数里引用变量的搜索路径)是在函数定义阶段就固定死了,与函数的调用位置无关!!
作用域是scope里变量作用的范围,就是scope所在代码块. 而LEGB遵循最内作用域原则,所以定义阶段就固定死了!
def f1():
x = 1 # -- 提一嘴,f1函数结束后,x变量还能被函数嵌套中的内部函数inner访问到..Why?因为x是自由变量!
# 后续的闭包部分会详细阐述!!
def inner():
print(x) # -- 作用域关系是在函数定义阶段就固定死了,与函数的调用位置无关!!
return inner
f = f1()
def bar():
x = 111
f() # -- 与调用位置无关
bar() # 1
2
3
4
5
6
7
8
9
10
11
12
13
14
# globals()、locals()
python提供了两个内置函数globals()和locals(),前者返回全局命名空间的字典,后者返回局部命名空间字典..
>>> type(globals()),type(locals())
(<class 'dict'>, <class 'dict'>)
2
注意: globals()返回全局命名空间的实际引用; 随便怎么折腾都是在操作全局命名空间, 类似于 a = b
"""
可以通过引用对象的变量名x,以常规的方式访问该对象..亦可以通过全局命名空间字典间接访问它
"""
>>> x = 'foo'
>>> 'x' in globals() # -- 注意,变量名是以字符串的形式作为键的
True
>>> x
'foo'
>>> globals()['x']
'foo'
>>> x is globals()['x'] # -- x的值与"x"键所对应vlaue值的内存地址相同
True
"""
可以使用globals()函数在全局命名空间中创建和修改全局变量
"""
>>> y
NameError: name 'z' is not defined # -- 全局命名空间中没有变量y
>>> glo = globals() # -- 注意:glo是全局命名空间的引用
>>> glo = 100 # -- 创建 等同于 globals()['y'] = 100
>>> y
100
>>> glo['y'] = 123 # -- 修改
>>> y
123
"""
globals结合format的应用
"""
>>> x = 1
>>> y = 2
>>> "{x},{y}".format(**globals())
'1,2'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
locals()返回的不是对局部命名空间的引用!! 那到底返回的是什么呢?
查阅资料,很多博客说是拷贝、副本.. 云里雾里的. 自己做了实验后, 发现这样的描述都不够严谨..
先说结论: locals()函数返回的是对局部命名空间的一个**"拷贝"** (打了引号哦) ,但此拷贝有点特殊,它具备浅拷贝的一些特点,同时当我们再次调用locals()函数时,它会 **同步更新 **"拷贝"的值..
此"拷贝"添加,改变可变类型的变量是ok的,但修改不可变变量是不成功的..
"""
什么是拷贝、副本、视图?
参考链接: https://blog.csdn.net/Reborn214/article/details/124539097
简单来说,副本、视图是python numpy数组中的专业名词,但其具备的特性跟拷贝差不多.
numpy中引用 = python中引用; numpy中视图 = python中浅拷贝; numpy中副本 = python中深拷贝
值得一提的是,引用一般发生在赋值操作(python赋值都是引用"内存地址"传递)
还要注意一个坑!!
id():返回对象的“标识值”.该值是一个整数,在此对象的生命周期中保证是唯一且恒定的.
两个生命期不重叠的对象可能具有相同的id()值..
举例分析
没有将a[:]赋值给变量进行引用,当执行完a[:]后,这个对象就释放啦.但这块内存可能并没有来得及释放.
当我们新执行a[:]的时候,用的将会是同一个内存,并没有申请新的内存.
这会让我们觉得两个a[:]与a[:]是同一个对象
>>> a = [1,2,3]
>>> id(a[:])
140417051683648
>>> id(a[:])
140417051684544
>>> id(a[:])
140417051684544
>>> id(a[:]) is id(a[:]) # -- 让其处于同一生命周期,每次浅拷贝都会生成不同的对象,结果肯定为False
False
"""
def func():
# -- 验证了id()的坑.
print(id(locals())) # 140204424022656
print(id(locals())) # 140204424022656
print(id(locals()) is id(locals())) # False
m = [1, 2, 3]
n = 66
loc = locals() # -- loc是局部命名空间的“拷贝” loc是对此"拷贝"的引用!!
print(loc) # {'m': [1, 2, 3], 'n': 66}
"""来,简化一下
import copy
scope = {'m': [1, 2, 3], 'n': 66} # -- 指代局部命名空间
loc = copy.copy(scope) # -- 指代局部命名空间的浅拷贝
loc['m'].append(4)
scope.append(5)
scope['n'] = 88
scope['x'] = 20
loc['n'] = 77
print(scope) # -- {'m': [1, 2, 3, 4, 5], 'n': 88, 'x': 20}
print(loc) # -- {'m': [1, 2, 3, 4, 5], 'n': 77}
"""
loc['m'].append(4) # -- 试图通过"拷贝"过来的字典修改局部命名空间里的可变类型的变量m 成功
m.append(5) # -- 在局部命令空间里修改了m变量对应的值
n = 88 # -- 在局部命令空间里修改了n变量对应的值
x = 20 # -- 在局部命名空间里添加了x变量
# -- 可以发现此"拷贝",具备浅拷贝的特性
print(loc) # {'m': [1, 2, 3, 4, 5], 'n': 66}
loc['n'] = 77 # -- 试图通过"拷贝"过来的字典修改局部命名空间里的可变类型的变量n 失败
loc['q'] = 250 # -- loc添加是成功的
print(loc) # {'m': [1, 2, 3, 4, 5], 'n': 77, 'q': 250}
print(locals()) # {'m': [1, 2, 3, 4, 5], 'n': 88, 'q': 250, 'loc': {...}, 'x': 20}
# -- 再次调用locals()后,"拷贝"同步更新了.
print(loc) # {'m': [1, 2, 3, 4, 5], 'n': 88, 'q': 250, 'loc': {...}, 'x': 20}
func()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# global、nonlocal
回顾下Python在作用域里对变量的赋值操作规则:
若这个变量在该作用域存在(已经定义), 则对其绑定新的对象; 若不存在,则将这次赋值视为对这个变量的定义..
global -- 不管是在函数嵌套的哪一层,对x变量的赋值操作都是修改全局作用域里的那个x变量!!
nonlocal -- 如果在闭包内给x变量赋值,那么修改的其实是闭包外那个作用域里的x变量..
nonlocal的唯一限制在于,不能延伸到模块级别,这是为了防止它污染全局变量..
Ps: 提一嘴闭包,后续会详细阐述. 函数嵌套,内部函数引用外部函数的参数或变量,就构成了闭包..
"""
★ --global
在局部若想修改全局的不可变类型,需要借助global声明
在局部若想修改全局的可变类型,不需要借助任何声明,可以直接修改
若全局中没有x变量,global语句和赋值的组合(不管处于嵌套的哪一层)可以间接在局部中创建x全局变量
"""
x = []
def func():
global m # -- 申明m变量是全局变量
m = 10
globals()['n'] = 20 # -- n变量在全局中存在的话,此赋值操作就是在修改;通常不会这么做,完全没必要
x.append(1)
func()
func()
print(x) # [1,1]
print(m, n) # 10,20
"""
★ --nonlocal 指非全局最近的那个
"""
x = 1
def f1(): # E f1的参数对f2而言
x = 111 # E 此处的x对f2而言
def f2(): # E f2的参数对f3而言
x = 222 # E 此处的x对f3而言
def f3():
nonlocal x # -- 若f1函数嵌套里没有x 则报错找不到x变量
x = 333 # -- 改的是最近的x = 222的值
f3()
print(x) # 333
# {'f3': <function f1.<locals>.f2.<locals>.f3 at 0x7fc60c71c9d0>, 'x': 333}
print(locals()) # f2的局部作用域
f2()
print(x) # 111
# {'x': 111, 'f2': <function f1.<locals>.f2 at 0x7fc60c71c790>}
print(locals()) # f1的局部作用域
f1()
print(x) # 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44