 TCP粘包问题
TCP粘包问题
先睹为快!
TCP协议的nagle算法会将数据量较小,并且发送时间间隔较短的多个数据包合并为一个发送!
该算法优化了传输效率,减少了网络IO..但产生了粘包问题. 接收端无法区分合在一起的多个数据包的界限.
如何解决粘包问题? 自定义报头 有很多种方式自定义报头(也不一定固定长度)
把握一个核心精髓,在发送真实数据之前要把报头送到对方.
★☆★☆★☆ "报头 + 数据" 接收端应该想方设法先把报头部分精准拿到!!!
具体来说,由于报头和要发送的数据都是属于TCP协议的一部分.也是会粘到一起的.
制作报头,将报头转换成bytes类型发送很容易实现,关键是接收端要先将报头准确的接收到..
在本章节中是将报头的长度做成4个bytes发送给对方,接收端先接收这4个bytes的数据,解出报头的长度..再接收报头.
HTTP协议的实现过程不大一样,但核心思想是一样的!先来一个报头(里面包含了数据有多长),再来真实的数据.
HTTP协议如何实现的呢?假如下载一个A文件.
先把报头和数据粘在一起往接收端发,只不过报头跟真实数据之间来了两个回车.
接收端可以先一个字节一个字节的收,直到收到连续两个字节都是回车,那就证明报头已经收完了.
再根据报头信息(里面有A文件的长度信息)把A文件完整的数据一次性收干净.
TCP协议称为流式协议.精髓在于流stream!!顾名思义,像流水一样传输数据.
TCP就一股脑的传真实数据.
传输过程涉及滑动窗口机制、序列号、停止等待返回ACK等等.
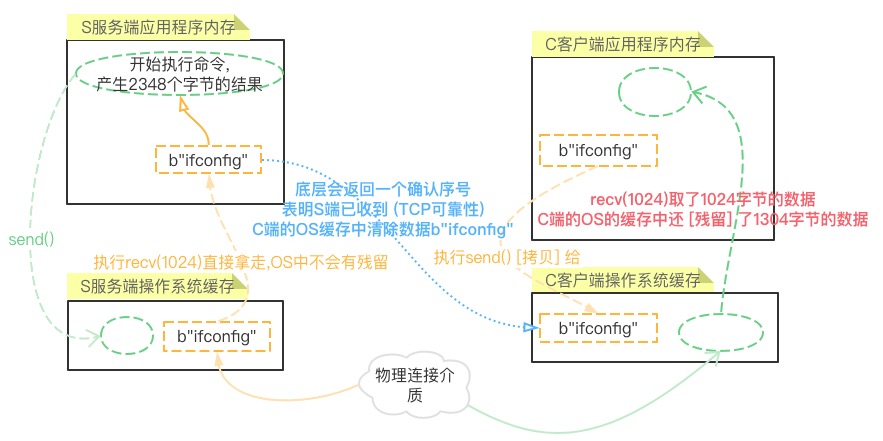
发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段.
1> 若连续对此send的数据量小且间隔短,会用nagle算法.接收端收到的是粘包数据.
2> 若传输一个大文件,会分段.发送时文件内容是按照一段一段的字节流发送的,
在接收方看来,根本不知道该文件的字节流从何处开始,在何处结束
提醒:粘包问题,注意思考下TCP两端收发的数据量. -- <两种粘包情况>!!
解决粘包,会人为的加报头.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 模拟ssh远程执行命令
SSH是一种网络协议
可实现两个设备之间的安全通信, 通常用于访问远程服务器以及传输文件或执行命令..
# 基本实现
"""
★ -- 服务端
"""
import subprocess
from socket import *
IP_PORT=('127.0.0.1',8080)
BUFSIZE=1024
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(IP_PORT)
server.listen(5)
while True:
conn, client_addr = server.accept()
print("连接的C端:", client_addr)
while True:
try:
cmd = conn.recv(BUFSIZE)
if not cmd: break
print("来自C端的消息:", cmd)
obj = subprocess.Popen(
# -- 接受客户端发过来的字符串是bytes模式,因而需要解码;
# 客户端用什么编就用什么解(自己规定的啊)
cmd.decode('utf-8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE
)
# -- 系统命令的运行结果就是bytes类型的,固定了的.
stdout_res = obj.stdout.read()
stderr_res = obj.stderr.read()
print(len(stdout_res + stderr_res))
conn.send(stdout_res + stderr_res) # -- 回复cmd命令的执行结果
except ConnectionResetError:
break
conn.close()
server.close()
"""
★ -- 客户端
"""
from socket import *
IP_PORT=('127.0.0.1',8080)
BUFSIZE=1024
client = socket(AF_INET, SOCK_STREAM)
client.connect(IP_PORT)
while True:
cmd = input(">>: ").strip()
if not cmd: continue
client.send(cmd.encode('utf-8'))
data = client.recv(BUFSIZE)
# -- 拿到subprocess执行的系统命令..
# 系统命令需要解码(跟平台有关).windows gbk; mac utf-8
print(data.decode('utf-8'))
""" 两个执行文件所在的目录结构
train
├── C
│ └── 客户端.py
└── S
└── 服务端.py
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
注意哦!
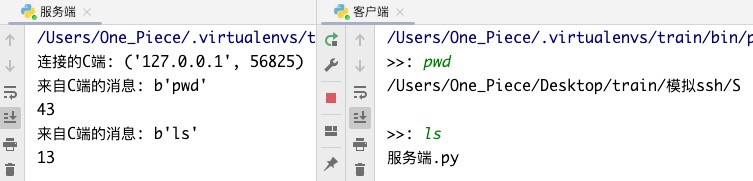
客户端输入的"pwd"命令是在服务端执行的!!
所以打印的是"服务端.py"所在路径!! 而不是"客户端.py"所在路径!!!
# 一些BUG
# cd命令
客户端不能输入cd命令.. 输入后,会在服务端真正的执行cd命令..
即服务端不能在运行过程中执行cd命令
要知道, 项目会以执行文件当前目录为基准去生成环境变量..
客户端输入的cd命令会让服务端的执行文件把自己的当前路径给切换掉..
程序中有很多地方用的是执行cd命令之前的环境变量,一旦执行cd命令,程序就崩了..
实验后的效果就是客户端在输入cd命令后,没有响应,输入其它也不会有任何响应,服务端崩溃掉了..
解决方案: 服务端无需真的切换目录.也能模拟出cd命令的效果.
当客户端敲cd命令时,服务端可以用 current_dir变量 记录下要切换的到的目录;
当客户端敲ls命令的时候, 服务端返回 查看current_dir路径下文件结果 即可..
# 实时反馈的命令
比如: linux上的top命令,默认每隔5秒刷新一次.
当前设计的程序只能执行立马有结果的命令...
top命令每隔5s刷新一次, 意味着此命令一直在运行,永远执行不完.. 服务端就拿不到命令产生的结果!
客户端输入python 这种 不能产生结果的命令 也是不ok的.. 我们目前设计的程序也无法执行!!!
暂且不要考虑怎么解决啦, 我们重点在于解决该程序的粘包问题!!
# 制造粘包现象
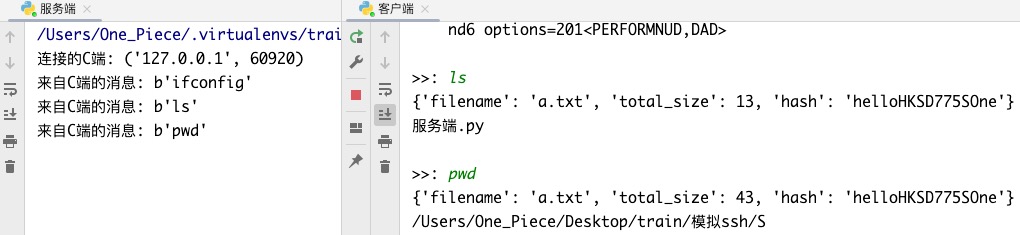
粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
连接的C端: ('127.0.0.1', 58299)
来自C端的消息: b'ifconfig'
2348
来自C端的消息: b'ls'
13
2
3
4
5
Ps: 该实验默认命令的大小不会超过1024bytes..
粘包现象,客户端先输入命令 ifconfig, 再输入命令命令ls 会发现客户端打印的结果不是ls命令的结果!!
而是上一次没打印完的 ifconfig 命令的结果!! Hhh 得到的命令结果直接乱套
# ugly的错误想法
# 接收字节数无限大
我们很容易想到一个解决方案, 将C客户端的套接字对象client的recv()方法接收的字节数调大..
修改代码 client.recv(1024) 为 client.recv(1024000000) , 接收数据的大小直接从1024字节长到1个G!!
命令的结果几乎不可能会超过1个G的大小,该程序的粘包问题得到了完美解决!!
但是 传文件的原理跟执行命令的原理基本是一致的!! 文件的大小是极有可能超过1个G的..
怎么办呢?继续调整recv()的接收字节的大小吗?
当我们修改程序为 client.recv(1024000000). 调整客户端接收的数据大小为10G..
执行客户端程序时报错:
Traceback (most recent call last):
File "/Users/One_Piece/Desktop/train/模拟ssh/C/客户端.py", line 10, in <module>
data = client.recv(10240000000)
OSError: [Errno 22] Invalid argument # -- windows上会报MemoryError的错误!!
2
3
4
报错分析: recv本质是在向自己的OS缓存要数据,OS缓存占用的是内存空间, OS缓存的大小再大也不会超过内存的大小.. 还要注意,之所以叫缓存是因为内存不可能将全部空间用于收数据这件事情..内存还要腾出空间运行软件等.
所以 client.recv() 设置的字节数无限大是没有意义的, 是无效的!!
# 单纯的循环接收
Q: 那么我们设置个循环,一直收,直到收干净为止. 可行吗?(代码如下)
A: 客户端一直recv从OS缓存中取数据,当recv发现OS缓存中没有数据后,会一直在那死等..
Ps: 当服务端终止运行后,客户端会收到一个b" "的字节数据.
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
cmd = input(">>: ").strip()
if not cmd: continue
client.send(cmd.encode('utf-8'))
while True: # -- 此循环出不来,一直死等.
data = client.recv(1024)
print(data.decode('utf-8'))
if len(data) == 0:break
2
3
4
5
6
7
8
9
10
11
12
13
提醒一下, client.recv(1024) 并不意味着一直从OS内存中循环取1024个字节数据,直到最后一次取的数据小于1024字节,将OS缓存中的数据取完.. 这样理解是错误的!!
1024只意味着一次从OS缓存中取数据大小的 最大限制 是1024字节.
TCP是流式协议,TCP可以连续发送多个数据段,具体发送数据段的多少取决于对方返回的窗口大小..
假如服务端的命令结果会分为三个数据段传给客户端,依次是800bytes、500bytes、1300bytes.因为网络原因到达客户端OS缓存的时间有间隔. 那么前面两次客户端从OS缓存中取的数据就会小于1024字节.. (过程不严谨,跟TCP具体的窗口机制有关,不深究,但想表达的意思是到位了的.)
# 不完美的解决方案
解决粘包现象的关键在于: 在发送真实数据之前先把此次数据的相关信息(长度)通知给对方
先传输一个 固定长度的报头 !!!
# 补充: struct模块
struct模块 可以将<整形的数据>转成<固定长度的bytes类型的数据>
import struct
# -- pack打包 其参数: (格式,整型数字)
# i格式 表示将后面的整型数字转成bytes类型 并且这个bytes类型数据的固定长度为4
header = struct.pack('i', 128)
# b'\x80\x00\x00\x00' <class 'bytes'> 4
print(header, type(header), len(header))
# -- unpack解包 其参数: (格式,字节串)
obj = struct.unpack('i', header)
# (128,) -- 其结果是元祖
print(obj)
total_size = struct.unpack('i', header)[0] # -- 我们需要的是元祖里的第一个数据
2
3
4
5
6
7
8
9
10
11
12
敲黑板: 格式不同,所能支持的整型数字的大小也不一样!超出范围会报错 (此方案不完美的地方之一)
struct.error:argument out of range
# 报头+较小单位循环
先接受 固定长度 的bytes类型的报头, 再以较小的单位循环收,直到收干净为止..
# 服务端
import struct
import subprocess
from socket import *
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
print("连接的C端:", client_addr)
while True:
try:
"""
提醒一下下:
recv()的参数值通常设置一次从OS缓存中取数据的大小为1024bytes.
设置的值最好不要超过8096,一般来说操作系统的缓存8096就是极限啦..
"""
cmd = conn.recv(1024)
if not cmd: break
print("来自C端的消息:", cmd)
obj = subprocess.Popen(
cmd.decode('utf-8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE
)
stdout_res = obj.stdout.read()
stderr_res = obj.stderr.read()
"""
TCP是流式协议
三条send语句的数据会依次流到自己的OS缓存中
<"粘到一起">像水流一样<"源源不断">的流向客户端
"""
# -- step1:先制作报头,固定长度
# 将整形的total_size数据转成固定长度的bytes类型的数据
total_size = len(stdout_res + stderr_res)
print(total_size)
header = struct.pack('i', total_size)
# -- step2:先发固定长度的报头
conn.send(header)
# -- step3:再发真实的数据
# -- conn.send(stdout_res + stderr_res)
# +号表明生成一个新的内存空间将加号左右的内容拿过来,相当于拷贝了一遍,效率问题
# 优化下,解决方案:连续发两次
conn.send(stdout_res) # -- 发送真实的数据
conn.send(stderr_res) # -- 发送真实的数据
except ConnectionResetError:
break
conn.close()
server.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 客户端
import struct
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
cmd = input(">>: ").strip()
if not cmd: continue
client.send(cmd.encode('utf-8'))
# -- step1:先收固定长度的报头
header = client.recv(4)
# -- step2:从报头中 解析/反解 出对数据的描述信息
total_size = struct.unpack('i', header)[0]
# -- step3:再收真实的数据
recv_size = 0
res_data = b""
while recv_size < total_size:
data = client.recv(1024)
res_data += data
recv_size += len(data)
print(res_data.decode('utf-8'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# perfect的解决方案
# 报头的制作
上面的解决方案有两个弊端:
1>struct.pack('i', 整型数字)参数中整型数字的大小,可能非常大, i q格式都不好使.
2> 报头是对数据有描述性的功能, 上面的解决方案中报头里只包含数据总长度..不合理!
现实中, 若是一个文件, 还会包含其它相关信息, 比如文件的名字、文件的md5值等...
且听我娓娓道来!!
import json
import struct
"""
下载的文件通常会包含文件名、文件大小、md5值
列表可以存储,但存不同类型的数据最好用字典!!!
"""
header_json = {
'filename': 'a.txt',
'total_size': 12313123124875981723895718257812538912353411234,
'hash': 'sfadfa1231ksdfakhf8fASDS829rjkjhJJKLJSDHAHD'
}
"""
Q:套接字只能发bytes类型的数据.
字典的数据类型是 <class 'dict'> 如何是好呢?
A:将字典格式的报头制作成可以被套接字传输的bytes类型的数据
解决方案如下:
dict -- json -- 进行encode
字符串类型的数据可以进行encode编码成bytes二进制的数据.
json格式的数据的类型就是字符串.
"""
header_json = json.dumps(header_json)
print(type(header_json)) # <class 'str'>
header_bytes = header_json.encode('utf-8')
print(type(header_bytes)) # <class 'bytes'>
"""
Q:在真实情况下,我们有bytes类型的报头啦,也有了真实数据
在发送的时候,报头会与真实数据粘在一起..
并且报头信息改动一点长度就变了,报头长度是不固定的.
接收端在收数据的时候,不知道该收多少个字节的数据表示报头,如何是好?
A:重点在于让接收端先知道报头的长度!
So,使用struct先pack打包报头的长度给接收端,再发送报头的数据和真实数据.
then,接收端先收取包含报头长度的4个字节的数据,对其unpack解包解包后拿到报头的长度;
再取报头长度的字节数据,解码后得到json串,再反序列化拿到文件所有的描述信息;
再循环取真实的数据.
"""
print(len(header_bytes)) # 139 -- 这个长度可远远小于total_size的长度
header_bytes_len_pack = struct.pack('i', len(header_bytes)) # -- 此时,i格式已经足够我们使用了
# -- 将报头的长度转成了一个4字节("i格式")长度的bytes对象
print(type(header_bytes_len_pack), len(header_bytes_len_pack)) # <class 'bytes'> 4
header_bytes_len = struct.unpack('i', header_bytes_len_pack)[0]
print(header_bytes_len) # 139 -- 接收端解包得到bytes类型的报头的字节长度大小
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 终极方案
# 服务端
文件信息存放到字典中 -- 序列化 -- 编码 -- 先发送报头长度 -- 再发送报头 -- 再发送真实数据
import json
import struct
import subprocess
from socket import *
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
print("连接的C端:", client_addr)
while True:
try:
cmd = conn.recv(1024)
if not cmd: break
print("来自C端的消息:", cmd)
obj = subprocess.Popen(
cmd.decode('utf-8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE
)
stdout_res = obj.stdout.read()
stderr_res = obj.stderr.read()
# -- step1:先制作报头
header_dic = {
'filename': 'a.txt',
'total_size': len(stdout_res + stderr_res),
'hash': 'helloHKSD775SOne' # -- 此hash值是瞎写模拟的
}
header_json = json.dumps(header_dic) # -- 序列化
header_bytes = header_json.encode('utf-8') # -- 编码
# -- step2:先发送报头的长度
# "pack将报头长度len(header_bytes)打包成4个bytes,然后发送!!"
conn.send(struct.pack('i', len(header_bytes)))
# -- step3:发送报头的数据
conn.send(header_bytes)
# -- step4:再发真实的数据
conn.send(stdout_res)
conn.send(stderr_res)
except ConnectionResetError:
break
conn.close()
server.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 客户端
先接收4字节包含报头长度的数据 -- 接收报头,取出想要的文件信息 -- 循环取真实数据
import json
import struct
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
cmd = input(">>: ").strip()
if not cmd: continue
client.send(cmd.encode('utf-8'))
# -- step1:先收4个字节,4个字节中包含了报头的长度
header_len = struct.unpack('i', client.recv(4))[0] # -- 解包后是元祖,取第一个元素
# -- step2:再接收报头,取出我们想要的信息
header_bytes = client.recv(header_len)
header_json = header_bytes.decode('utf-8') # -- 解码
header_dic = json.loads(header_json) # -- 反序列化
print(header_dic)
total_size = header_dic['total_size'] # -- 取出报头中文件的长度信息
# -- step3:再收真实的数据
recv_size = 0
res_data = b""
while recv_size < total_size:
data = client.recv(1024)
res_data += data
recv_size += len(data)
print(res_data.decode('utf-8'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# TCP粘包底层原理分析
# nagle算法
send一次就走一次网络IO/网络延迟?
No,第一次send的数据只有0.1kb,间隔0.01s后,又send了一个0.2kb的数据.. 走两次网络IO是不合理的!!
网络IO越多,程序效率越低. 一次网络IO尽可能的传输网络带宽能承受的数据量..
Don't worry!! 你想到了的,TCP当然也想到啦!!
# 算法规则
TCP协议会告诉OS在组织数据传送时,应该按照 nagle算法 将 "[数据量较小]" 并且 "[时间间隔较短]" 的 "[多条数据合并成一条]" 沿着网络发送!!!
这多条数据是应用程序会不断send给OS的缓存..
# 两种情况粘包
两种情况下会发生粘包
1> 发送数据时间间隔很短, 数据很小, 会合到一起,产生粘包 -- nagle算法的粘包
2> 发送方发送了一段数据, 接收方只收了一小部分, 接收方下次再取的时候还是从缓冲区拿上次遗留的数据,产生粘包 -- 模拟ssh远程执行命令的粘包
这里验证的是 第一种情况 的粘包..
针对客户端正常结束后,服务端收到空数据进行特别说明:
Ps: 注意! 客户端.py中相较于上方的截图中没有了 while True:pass 代码..
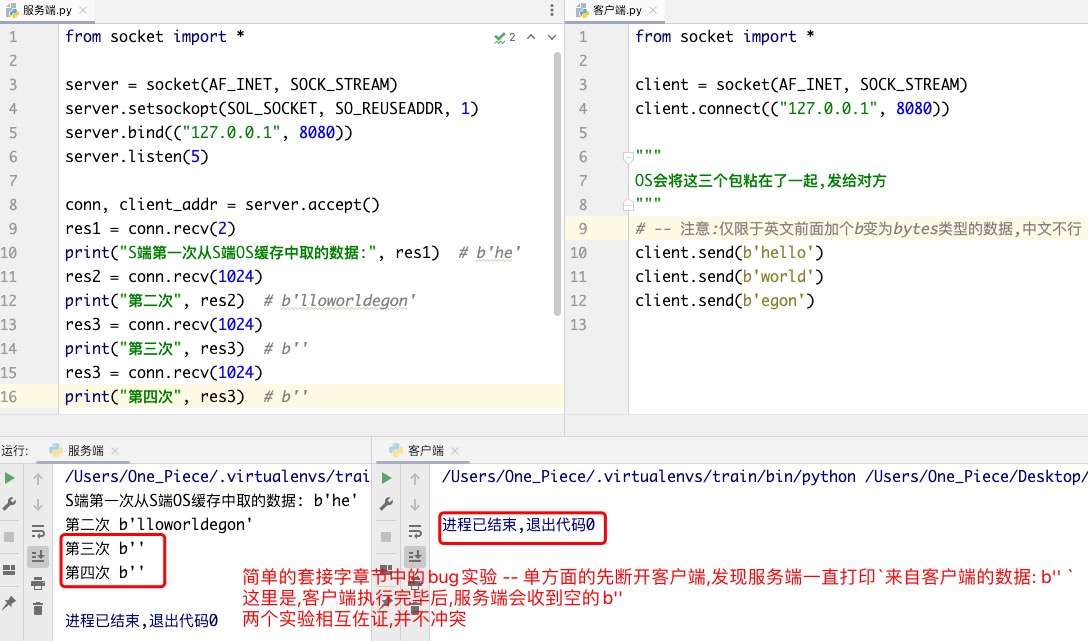
# 解决粘包
# 精准接收
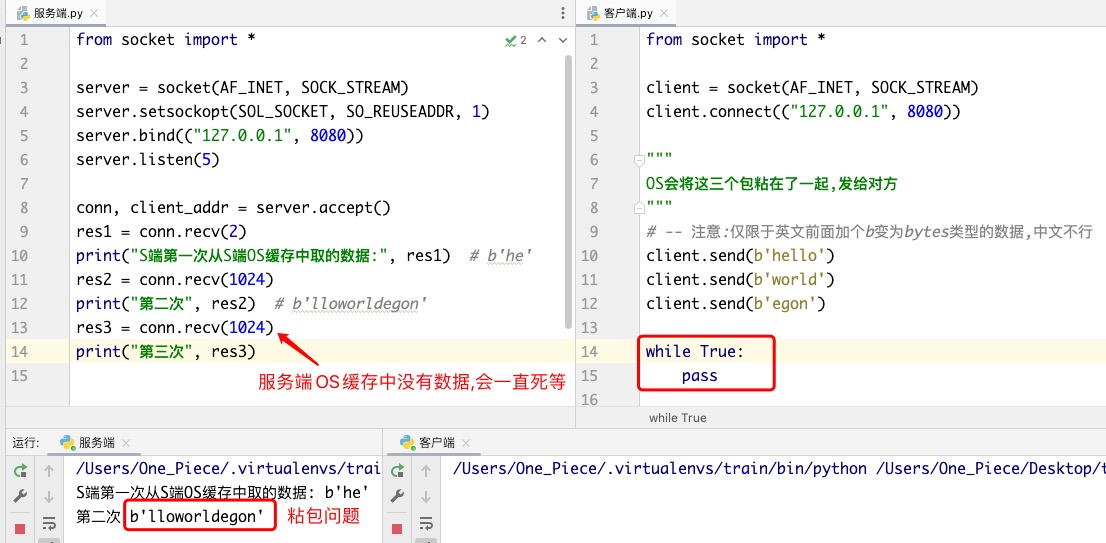
遵循 "perfect的解决方案"的核心思想, 只要服务端知道每个包的长度,每次按照长度收干净/精准接收就行啦!!
So, 再次说一次, 解决粘包现象的关键在于:在发送真实数据之前先把此次数据的相关信息(长度)通知给对方.
准确来说,不是精准到每个数据包(发送的文件会被分成n个数据段像水流一样源源不断的流向对方).. 而是在发送一个完整的文件之前,先将报头"包含有文件的长度"通知给对方..
"""
★ -- 服务端
"""
from socket import *
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(("127.0.0.1", 8080))
server.listen(5)
# -- 假设服务端已经知道了每个包的长度/数据量的大小!
conn, client_addr = server.accept()
res1 = conn.recv(5)
print("S端第一次从S端OS缓存中取的数据:", res1) # S端第一次从S端OS缓存中取的数据: b'hello'
res2 = conn.recv(5)
print("第二次", res2) # 第二次 b'world'
res3 = conn.recv(4)
print("第三次", res3) # 第三次 b'egon'
"""
★ -- 客户端
"""
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(("127.0.0.1", 8080))
client.send(b'hello')
client.send(b'world')
client.send(b'egon')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# low_B方案
客户端在send数据的过程中使用time.sleep(3)间隔睡3秒..
是通过人为制造延迟解决的,不要这样做!!!
"""
★ -- 服务端
"""
from socket import *
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(("127.0.0.1", 8080))
server.listen(5)
conn, client_addr = server.accept()
res1 = conn.recv(1024)
print("S端第一次从S端OS缓存中取的数据:", res1) # S端第一次从S端OS缓存中取的数据: b'hello'
res2 = conn.recv(1024)
print("第二次", res2) # 第二次 b'world'
res3 = conn.recv(1024)
print("第三次", res3) # 第三次 b'egon'
"""
★ -- 客户端
"""
from socket import *
import time
client = socket(AF_INET, SOCK_STREAM)
client.connect(("127.0.0.1", 8080))
# -- 加入时间间隔条件测试 表明粘包发生的条件 数据量小+时间间隔短
# 虽然第一个数据包'hello'数据量很小,但客户端os会等0.2秒吗?不,相对于一次网络IO/延迟来说太长了
# 客户端的OS不会等这0.2s,直接调用网卡发送给服务端os缓存
client.send(b'hello')
time.sleep(0.2)
client.send(b'world')
time.sleep(0.2)
client.send(b'egon')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 补充!!
TCP分段与IP分片的区别与联系参考:
https://cloud.tencent.com/developer/article/1173790
▼ MTU = MSS + TCP首部长度 + IP首部长度
TCP分段的原因是因为TCP报文段大小受MSS限制
IP分片的原因则是因为IP数据报大小受MTU限制
UDP不会分段,就由IP来分片. TCP会分段,当然就不用IP来分了!
▼ 发送端进行TCP分段后就一定不会在IP层进行分片,因为MSS本身就是基于MTU推导而来,TCP层分段满足了MSS限制,也就满足了MTU的物理限制.但在TCP分段发生后仍然可能发生IP分片,这是因为TCP分段仅满足了通信两端的MTU要求,传输路径上如经过MTU值比该MTU值更小的链路,那么在转发分片到该条链路的设备中仍会以更小的MTU值作为依据再次分片.
▼ 分段仅可能发生在发送端,分片不仅可能发生在发送端,更还可能发生在路径上任何一台工作在三层或以上的设备中,而两者的重组都只会发生在接收端.
2
3
4
5
6
1> 当发送端缓冲区的长度大于网卡的MTU时, tcp会将这次要发送的数据拆成几个数据包发送出去.
2> tcp在数据传输时, 发送端先把数据发送到自己的缓存中, 然后协议控制将缓存中的数据发往对端, 对端返回一个ack=1, 发送端则清理缓存中的数据, 对端返回ack=0, 则重新发送数据, 所以tcp是可靠的..
3> recv里指定的1024意思是从缓存里一次最多拿出1024个字节的数据
4> send 的字节流是先放入己端缓存, 然后由协议控制将缓存内容发往对端, 若待发送的字节流大小大于缓存剩余空间, 缓存空间不足, 那么数据丢失, 用 sendall 就会循环调用send, 数据不会丢失.