 过滤排序分页异常
过滤排序分页异常
# 准备工作
使用三种写法实现查询所有图书接口 (三种写法分为两类 - 手动和自动生成路由)
models.py
迁移数据库并手动添加几条数据.
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
"""
id,name,price
1,红楼梦,11
2,红楼记,12
3,西厢记,15
4,石头记,16
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
serializer.py
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = '__all__'
2
3
4
5
6
7
8
views.py
from rest_framework.generics import ListAPIView
from rest_framework.viewsets import ViewSetMixin, GenericViewSet
from rest_framework.mixins import ListModelMixin
from .models import Book
from .serializer import BookSerializer
# -- 获取所有图书
# -- 方式一: 手动写路由
# class BookView(ListAPIView):
# -- 方式二: 自动生成路由1
# class BookView(ViewSetMixin, ListAPIView):
# -- 方式三: 自动生成路由2
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
"""
ListAPIView = ListModelMixin + GenericAPIView
即ViewSetMixin ListModelMixin GenericAPIView
GenericViewSet = ViewSetMixin + GenericAPIView
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
urls.py
from django.contrib import admin
from django.urls import path
from rest_framework.routers import SimpleRouter
from app01 import views
# -- 自动
router = SimpleRouter()
router.register('books', views.BookView, 'books')
urlpatterns = [
path('admin/', admin.site.urls),
# -- 手动
# path('books/', views.BookView.as_view()),
]
urlpatterns += router.urls
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 过滤
在请求地址中带过滤条件.
内置的/第三方的/自定义 的过滤类 都需要在视图函数中配置 filter_backends
视图必须继承 GenericAPIView+ListModelMixin 及其 子类, 配置的filter_backends 才会生效!!
查询所有才涉及到过滤.
固定了类变量queryset里就弄了,动态的再使用过滤类. 五个视图扩展类的源码中全员加入了过滤的逻辑.
# 内置的过滤类
http://127.0.0.1:8000/books/?search=记
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from rest_framework.filters import SearchFilter, OrderingFilter
from .models import Book
from .serializer import BookSerializer
# -- 获取所有图书
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# -- 配置过滤类
filter_backends = [SearchFilter]
# -- 配置要过滤的字段
# 1> http://127.0.0.1:8000/books/?search=记
# 只要是name中带'记'都会查出来
# search_fields = ['name']
# 2> http://127.0.0.1:8000/books/?search=记
# 只要是name -或者- price中带'记'的都会查出来
search_fields = ['name', 'price']
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 第三方过滤类
此处讲解下 django-filter 的基本使用!
http://127.0.0.1:8000/books/?name=红楼梦&price=12
先下载django-filter, 注意它有支持的django的版本限制.
注册django-filter.
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from django_filters.rest_framework import DjangoFilterBackend
from .models import Book
from .serializer import BookSerializer
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# -- 配置第三方的过滤类
filter_backends = [DjangoFilterBackend]
# eg:http://127.0.0.1:8000/books/?name=红楼梦&price=11
# 查询名字是'红楼梦',并且价格为11的
filterset_fields = ['name', 'price'] # DjangoFilterBackend类会读取这个属性值,根据哪个字段来进行筛选.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 自定义过滤类
auth.py
from rest_framework.filters import BaseFilterBackend
# SearchFilter、OrderingFilter都继承了BaseFilterBackend,自定义的也要继承!!
class MyFilterByPrice(BaseFilterBackend):
# -- 重写BaseFilterBackend类的filter_queryset方法,不重写就会raise
# 这里,我们规定自定义的过滤要支持 /?price_gt=12
def filter_queryset(self, request, queryset, view):
# queryset里面是我们要过滤的数据
# -- 不用那么死板,我们也可以规定url里写price_dy=12,那么这里就'price_dy'
price = request.query_params.get('price_gt')
if price:
queryset = queryset.filter(price__gt=price)
return queryset # -- 把过滤完的数据返回!
2
3
4
5
6
7
8
9
10
11
12
13
14
views.py
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from .models import Book
from .serializer import BookSerializer
from .auth import MyFilterByPrice
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# -- 当然,也可以搭配排序来使用!!略.
filter_backends = [MyFilterByPrice]
# eg:http://127.0.0.1:8000/books/?price_gt=11
# 查询图书价格大于11的.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 武sir总结的过滤
武sir 笔记中的过滤类笔记 我直接粘贴过来了!
如果某个API需要传递一些条件进行搜索,其实就在是URL后面通过GET传参即可,例如:
/api/users?age=19&category=12
在drf中也有相应组件可以支持条件搜索.
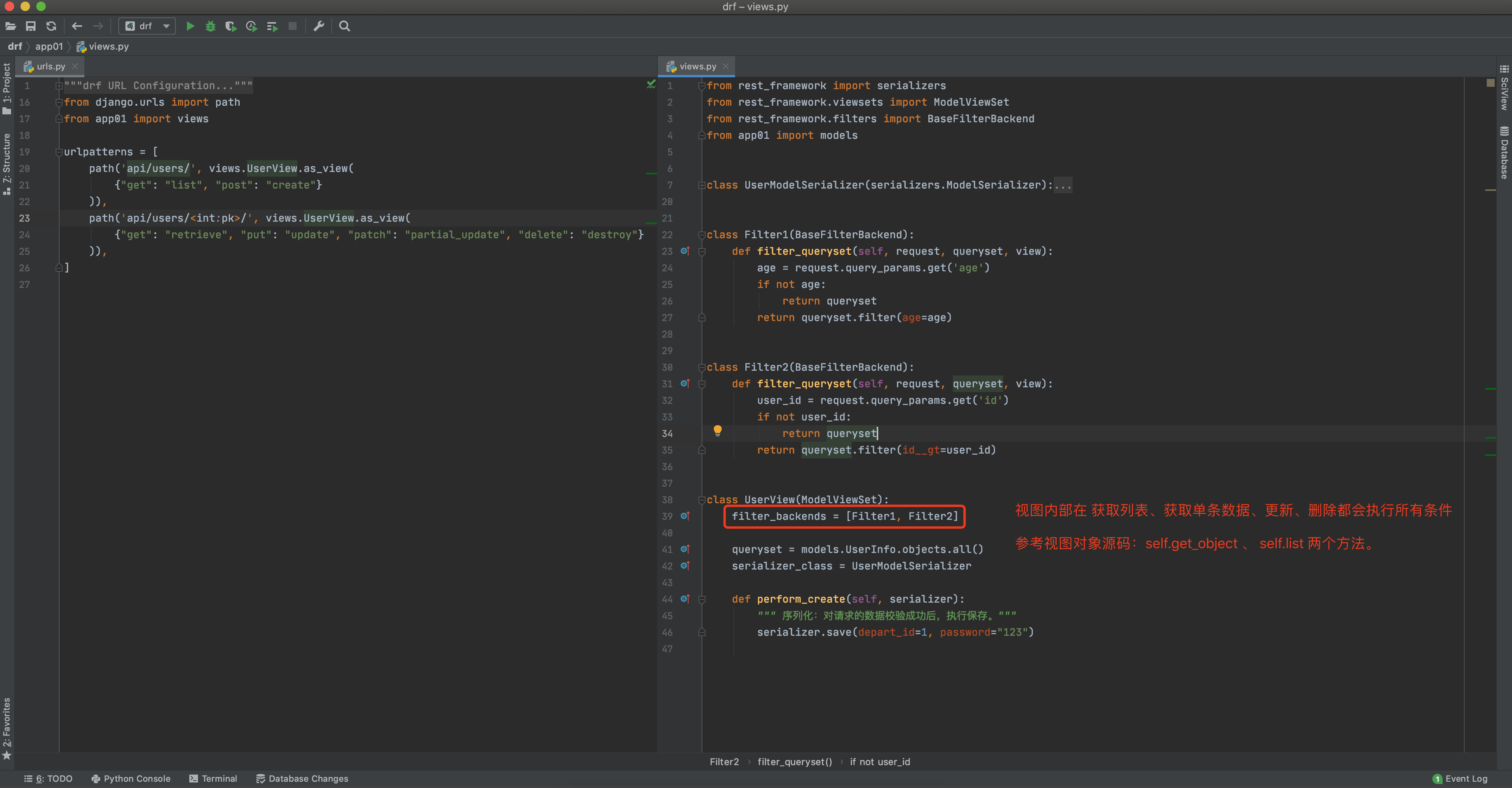
# 自定义Filter(推荐)
# urls.py
from django.urls import path
from app01 import views
urlpatterns = [
path('api/users/', views.UserView.as_view(
{"get": "list", "post": "create"}
)),
path('api/users/<int:pk>/', views.UserView.as_view(
{"get": "retrieve", "put": "update", "patch": "partial_update", "delete": "destroy"}
)),
]
2
3
4
5
6
7
8
9
10
11
12
13
# views.py
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from rest_framework.filters import BaseFilterBackend
from app01 import models
class UserModelSerializer(serializers.ModelSerializer):
level_text = serializers.CharField(
source="get_level_display",
read_only=True
)
extra = serializers.SerializerMethodField(read_only=True)
class Meta:
model = models.UserInfo
fields = ["username", "age", "email", "level_text", "extra"]
def get_extra(self, obj):
return 666
class Filter1(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
age = request.query_params.get('age') # 获取url中的参数
if not age:
return queryset
return queryset.filter(age=age)
class Filter2(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
user_id = request.query_params.get('id')
if not user_id:
return queryset
return queryset.filter(id__gt=user_id)
class UserView(ModelViewSet):
filter_backends = [Filter1, Filter2] # Filter1的结果集合作为Filter1过滤的原始数据继续进行过滤
queryset = models.UserInfo.objects.all()
serializer_class = UserModelSerializer
def perform_create(self, serializer):
""" 序列化:对请求的数据校验成功后,执行保存。"""
serializer.save(depart_id=1, password="123")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 第三方Filter
在drf开发中有一个常用的第三方过滤器:DjangoFilterBackend。
pip install django-filter
注册app:
INSTALLED_APPS = [
...
'django_filters',
...
]
2
3
4
5
视图配置和应用(示例1):
# views.py
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from django_filters.rest_framework import DjangoFilterBackend
from app01 import models
class UserModelSerializer(serializers.ModelSerializer):
level_text = serializers.CharField(
source="get_level_display",
read_only=True
)
extra = serializers.SerializerMethodField(read_only=True)
class Meta:
model = models.UserInfo
fields = ["username", "age", "email", "level_text", "extra"]
def get_extra(self, obj):
return 666
class UserView(ModelViewSet):
filter_backends = [DjangoFilterBackend, ]
# DjangoFilterBackend内部会读取filterset_fields的值!!
# 只传id,表明筛选该id值的数据; 传了id和age,就是且的关系,要同时满足.
filterset_fields = ["id", "age", "email"]
queryset = models.UserInfo.objects.all()
serializer_class = UserModelSerializer
def perform_create(self, serializer):
""" 序列化:对请求的数据校验成功后,执行保存。"""
serializer.save(depart_id=1, password="123")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
视图配置和应用(示例2):
实例1有局限性,只能实现id等于多少,不能说大于或小于等. 实例二可以解决这个问题.
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from django_filters.rest_framework import DjangoFilterBackend
from django_filters import FilterSet, filters
from app01 import models
class UserModelSerializer(serializers.ModelSerializer):
level_text = serializers.CharField(
source="get_level_display",
read_only=True
)
depart_title = serializers.CharField(
source="depart.title",
read_only=True
)
extra = serializers.SerializerMethodField(read_only=True)
class Meta:
model = models.UserInfo
fields = ["id", "username", "age", "email", "level_text", "extra", "depart_title"]
def get_extra(self, obj):
return 666
class MyFilterSet(FilterSet): # 该第三方的过滤组件规定了必须继承该组件里的FilterSet
# field_name表明数据库在筛选时会用这个字段;lookup_expr表明筛选的条件,exact是等于.
depart = filters.CharFilter(field_name="depart__title", lookup_expr="exact")
min_id = filters.NumberFilter(field_name='id', lookup_expr='gte')
class Meta:
model = models.UserInfo
fields = ["min_id", "depart"] # 在url中可以传的过滤参数
class UserView(ModelViewSet):
filter_backends = [DjangoFilterBackend, ]
filterset_class = MyFilterSet # 构造了一个类!
queryset = models.UserInfo.objects.all()
serializer_class = UserModelSerializer
def perform_create(self, serializer):
""" 序列化:对请求的数据校验成功后,执行保存。"""
serializer.save(depart_id=1, password="123")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
视图配置和应用(示例3):
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from django_filters.rest_framework import DjangoFilterBackend, OrderingFilter
from django_filters import FilterSet, filters
from app01 import models
class UserModelSerializer(serializers.ModelSerializer):
level_text = serializers.CharField(
source="get_level_display",
read_only=True
)
depart_title = serializers.CharField(
source="depart.title",
read_only=True
)
extra = serializers.SerializerMethodField(read_only=True)
class Meta:
model = models.UserInfo
fields = ["id", "username", "age", "email", "level_text", "extra", "depart_title"]
def get_extra(self, obj):
return 666
class MyFilterSet(FilterSet):
# /api/users/?min_id=2 -> id>=2
min_id = filters.NumberFilter(field_name='id', lookup_expr='gte')
# /api/users/?name=wupeiqi -> not ( username=wupeiqi ) exact原本是等于,加了exclude就表明排除不等于!
name = filters.CharFilter(field_name="username", lookup_expr="exact", exclude=True)
# /api/users/?depart=xx -> depart__title like %xx%
depart = filters.CharFilter(field_name="depart__title", lookup_expr="contains")
# /api/users/?token=true -> "token" IS NULL
# /api/users/?token=false -> "token" IS NOT NULL
token = filters.BooleanFilter(field_name="token", lookup_expr="isnull")
# /api/users/?email=xx -> email like xx%
email = filters.CharFilter(field_name="email", lookup_expr="startswith")
# /api/users/?level=2&level=1 -> "level" = 1 OR "level" = 2(必须的是存在的数据,否则报错-->内部有校验机制)
# level = filters.AllValuesMultipleFilter(field_name="level", lookup_expr="exact")
# !!choices是可以支持的筛选条件的值,必须是level_choices里面的值
level = filters.MultipleChoiceFilter(field_name="level", lookup_expr="exact", choices=models.UserInfo.level_choices)
# /api/users/?age=18,20 -> age in [18,20]
age = filters.BaseInFilter(field_name='age', lookup_expr="in")
# /api/users/?range_id_max=10&range_id_min=1 -> id BETWEEN 1 AND 10
# 这里比较特殊,需要多加max和min后缀.
range_id = filters.NumericRangeFilter(field_name='id', lookup_expr='range')
# /api/users/?ordering=id -> order by id asc
# /api/users/?ordering=-id -> order by id desc
# /api/users/?ordering=age -> order by age asc
# /api/users/?ordering=-age -> order by age desc
ordering = filters.OrderingFilter(fields=["id", "age"])
# /api/users/?size=1 -> limit 1(自定义搜索,自定义钩子方法 来完成复杂的查询条件)
size = filters.CharFilter(method='filter_size', distinct=False, required=False)
class Meta:
model = models.UserInfo
fields = ["id", "min_id", "name", "depart", "email", "level", "age", 'range_id', "size", "ordering"]
def filter_size(self, queryset, name, value):
int_value = int(value)
return queryset[0:int_value]
class UserView(ModelViewSet):
filter_backends = [DjangoFilterBackend, ]
filterset_class = MyFilterSet
queryset = models.UserInfo.objects.all()
serializer_class = UserModelSerializer
def perform_create(self, serializer):
""" 序列化:对请求的数据校验成功后,执行保存。"""
serializer.save(depart_id=1, password="123")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
lookup_expr有很多常见选择:
'exact': _(''),
'iexact': _(''),
'contains': _('contains'),
'icontains': _('contains'),
'startswith': _('starts with'),
'istartswith': _('starts with'),
'endswith': _('ends with'),
'iendswith': _('ends with'),
'gt': _('is greater than'),
'gte': _('is greater than or equal to'),
'lt': _('is less than'),
'lte': _('is less than or equal to'),
'in': _('is in'),
'range': _('is in range'),
'isnull': _(''),
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
全局配置和应用:
# settings.py 全局配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend',]
}
2
3
4
5
# 排序
# 内置的排序
http://127.0.0.1:8000/books/?ordering=-price,id
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from rest_framework.filters import SearchFilter, OrderingFilter
from .models import Book
from .serializer import BookSerializer
# -- 获取所有图书
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# -- 配置排序类
filter_backends = [OrderingFilter]
# -- 配置要排序的字段
# 1> http://127.0.0.1:8000/books/?ordering=-price
# 按照price的降序排列
# ordering_fields = ['price']
# 2> http://127.0.0.1:8000/books/?ordering=-price,id
# 先按照price的降序排列,price相同的再按照id的升序排列
ordering_fields = ['price', 'id']
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 内置 排序+过滤
http://127.0.0.1:8000/books/?search=记&ordering=-price,-id
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# -- 一般会将内置的过滤类写在前面,排序类写在后面,先过滤再排序好一些
filter_backends = [SearchFilter, OrderingFilter]
# eg:http://127.0.0.1:8000/books/?search=记&ordering=-price,-id
# 查询名字中带'记'的,并且按价格降序排列排,价格相同的按照id降序排.
search_fields = ['name']
ordering_fields = ['price', 'id']
2
3
4
5
6
7
8
9
10
# 分页
需要在视图中配置pagination_class
跟过滤一样, 视图必须继承 GenericAPIView+ListModelMixin 及其 子类, 配置的pagination_class 才会生效!!
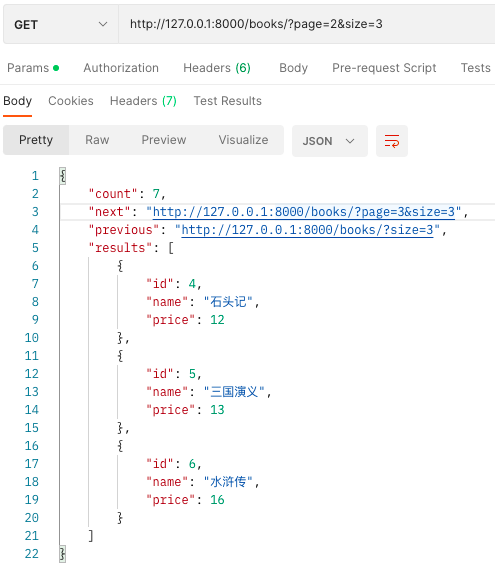
# 基本分页
用的最多.
?page=2&size=3
auth.py
# -- 内置了三种分页类,但都不能直接使用,需要稍微改一下!
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
# -- 基本分页类
class MyPageNumberPagination(PageNumberPagination):
# -- 重写4个类属性即可!
# 默认每页显示多少条
page_size = 2
# 查询条件,eg: /?page=1
page_query_param = 'page'
# 返回多少条,eg: /?page=2&size=4 获取第二页的数据,返回4条
page_size_query_param = 'size'
# 最多返回多少条,eg: /?page=2&size=400 获取第二页的数据,返回5条
max_page_size = 5
2
3
4
5
6
7
8
9
10
11
12
13
14
views.py
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from .models import Book
from .serializer import BookSerializer
from .auth import MyPageNumberPagination as PageNumberPagination
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = PageNumberPagination
2
3
4
5
6
7
8
9
10
11
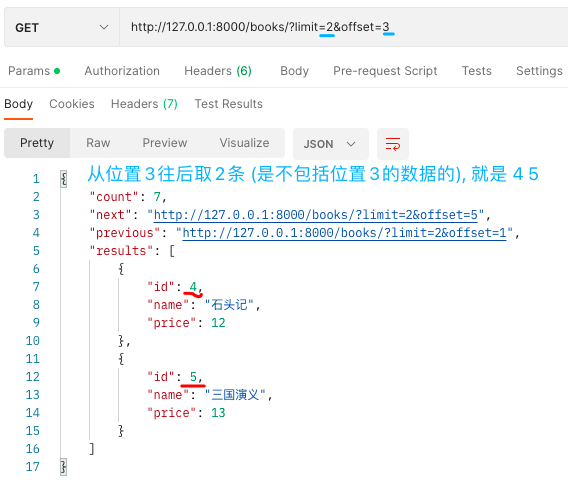
# 偏移分页
/?limit=3&offset=2
auth.py
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
class MyLimitOffsetPagination(LimitOffsetPagination):
# -- 重写4个类属性即可!
# 每页默认显示多少条
default_limit = 2
# eg: /?limit=3&offset=2 从2位置往后取3条数据!
limit_query_param = 'limit'
offset_query_param = 'offset'
# 限制limit最大条数
max_limit = 5
2
3
4
5
6
7
8
9
10
11
12
Ps: 源码里 _('The pagination cursor value.') _ 是个方法, import 时as成了_ , 用于国际化!! 在中国,括号里的话就是中文.
views.py
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from .models import Book
from .serializer import BookSerializer
from .auth import MyLimitOffsetPagination as LimitOffsetPagination
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = LimitOffsetPagination
2
3
4
5
6
7
8
9
10
11
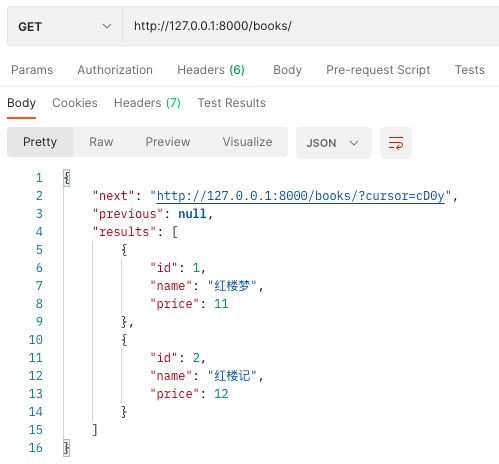
# 游标分页
当数据量很大时,可能会使用游标分页,因为它只能上一页下一页,不能跳到某一页.
优势是搜索速度快(维护了一个游标,只能拿游标前后的,其余两个分页是从头开始检索的). 但不能直接跳到某一页.
auth.py
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
class MyCursorPagination(CursorPagination):
# -- 重写3个类属性即可!
# 查询条件,无用 它等于一个随机的值
cursor_query_param = 'cursor'
# 每页显示多少条
page_size = 2
# 按谁排序,这里我们按照id字段排序
ordering = 'id'
2
3
4
5
6
7
8
9
10
11
views.py
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from .models import Book
from .serializer import BookSerializer
from .auth import MyCursorPagination as CursorPagination
class BookView(GenericViewSet, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = CursorPagination
2
3
4
5
6
7
8
9
10
11
# 继承APIView实现分页
auth.py
# -- 内置了三种分页类,但都不能直接使用,需要稍微改一下!
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
# -- 基本分页类
class MyPageNumberPagination(PageNumberPagination):
# -- 重写4个类属性即可!
# 默认每页显示多少条
page_size = 2
# 查询条件,eg: /?page=1
page_query_param = 'page'
# 返回多少条,eg: /?page=2&size=4 获取第二页的数据,返回4条
page_size_query_param = 'size'
# 最多返回多少条,eg: /?page=2&size=400 获取第二页的数据,返回5条
max_page_size = 5
2
3
4
5
6
7
8
9
10
11
12
13
14
views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book
from .serializer import BookSerializer
from .auth import MyPageNumberPagination
class BookView(APIView):
def get(self, request):
# -- 先获取所有数据
qs = Book.objects.all()
# -- 分页,通过分页类进行分页
# 1> 实例化得到分页类实例,不需要传参数
page = MyPageNumberPagination()
# 2> 对qs进行分页,使用分页对象的某个方法来实现对qs的分页
# 返回的res是列表,是当前页码的所有数据
res = page.paginate_queryset(qs, request, self)
# 3> 对当前页码的数据进行序列化
ser = BookSerializer(instance=res, many=True)
# 4> 将序列化后的数据返回
# return Response(ser.data) # -- 这种方式直接返回就没有上一页下一页啦.
return page.get_paginated_response(ser.data) # -- 这种方式有!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 自定义分页
以实现基本分页为例.
- 使用当次请求的request对象,request.GET.get("page")从url中取出页码数
- 通过页码数和每页显示多少条,具体的取出当前页码的数据 利用queryset对象可以切片!!
- 序列化,将当前页码的数据返回
2
3
4
# 自定义全局异常
drf能捕获和不能捕获的异常都返回给前端统一的格式!
并且在后端还可以对异常纪录日志!!
在app01下,新建文件exceptions.py.
"""
写个函数:写逻辑处理异常
配置在项目的配置文件中
以后只要drf的流程中出现异常,都会触发该函数的执行,统一返回格式
在drf的settings.py配置文件里,对异常的处理配置是这样的:
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler',
我们需要改成我们自定义的全局异常函数 在Django项目的settings.py中配置!
"""
from rest_framework.views import exception_handler
from rest_framework.response import Response
def common_exception_handler(exc, context):
# ★ 不会告诉前端具体哪里出错,但是后端会将错误信息记录日志!
# exc对象就是错误对象!!context是上下文!!
# print(str(exc)) # list index out of range
"""
{
'view': <app01.views.IndexView object at 0x7f84d8160d00>,
'args': (),
'kwargs': {},
'request': <rest_framework.request.Request: GET '/index/'>
}
"""
# print(context)
user_id = context['request'].user.id # -- 用户未登陆,这里user_id值为None
print("视图类%s出错了;是IP地址为%s的用户访问的;该用户的ID为%s;错误原因是%s." % (
context['view'], context['request'].META.get('REMOTE_ADDR'), user_id, str(exc)))
# ★ 处理异常,统一返回格式
# drf中的exception_handler函数是默认的异常处理
# 它的缺陷在于,它只处理APIException及其子类的异常,处理不了的返回None
response = exception_handler(exc, context)
if response:
# -- exception_handler能处理的异常
# return response # -- 原来的返回不用啦!!我们需要统一格式.
return Response(data={'code': 9998, 'msg': response.data})
else:
# -- exception_handler不能处理的异常,统一返回格式
return Response(data={'code': 9999, 'msg': '服务器异常,请联系系统管理员!'})
# -- 在Django项目的settings.py文件中配置
# -- drf配置
REST_FRAMEWORK = {
# -- 以后drf执行流程出异常,就会走该函数!
'EXCEPTION_HANDLER': 'app01.exceptions.common_exception_handler',
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 接口文档
后端写了很多接口,但前端根本不知道后端写了哪些接口.接口的请求参数什么样,响应数据什么样,使用怎样的编码都不知道.
So, 需要写接口文档. 不同的公司有不同的规范!!
方式一: 公司自己的接口文档平台/第三方的接口文档平台(eg:开源的 Yapi ), 后端写了接口就录入
方式二: 使用md、word文档写,写完传到git上
方式三: 自动生成接口文档(eg: swagger、coreapi ) - 可以利用coreapi自动生成后导出,再导入到Yapi中!!
step1: 安装软件包coreapi pip3 install coreapi pyyaml
step2: 设置接口文档访问路径
from rest_framework.documentation import include_docs_urls
urlpatterns = [
# -- ... ...
path('docs/', include_docs_urls(title='xxx接口平台'))
]
2
3
4
5
step3: 在项目的settings.py中配置,避免AttributeError报错
#AttributeError: 'AutoSchema' object has no attribute 'get_link'
REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
# 新版drf schema_class默认用的是rest_framework.schemas.openapi.AutoSchema
}
2
3
4
5
step4: 在视图函数中配置
详见 - https://www.liuqingzheng.top/python/Django-rest-framework框架/8-drf-自动生成接口文档/