 连锁超市数据分析
连锁超市数据分析
该项目数据集链接: https://pan.baidu.com/s/1uYZ2GvTbKTjoj4tLxwjg-g?pwd=8j6r
# 数据加载
原始数据长下面这个样子:

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
# plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # windows使用设置微软雅黑字体
plt.rcParams['font.sans-serif']=['PingFang HK'] # mac系统使用
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常的显示负号
warnings.filterwarnings('ignore') # 忽略所有警告信息
df = pd.read_csv('./data/superstore_dataset2011-2015.csv')
2
3
4
5
6
7
8
9
10
11
12
数据集介绍
- Row ID: 行编号
- Order Date: 下单日期
- Sales: 销售金额
- Quantity: 销量
- Profit: 利润
- Customer ID: 顾客ID
- Customer Name: 顾客名字
- Market: 各地区销售市场
- APAC亚太地区,EU欧盟,US美国,LATMA拉丁美洲,Canada加拿大,Africa非洲,EMEA欧洲、中东及非洲
- Region: 各地区销售市场所属的州
- Postal Code: 邮编
- Product ID: 商品ID,TEC电子产品,OFF办公用品,FUR家具等
- Ship Date: 商品的发货日期
- Ship Mode: 商品的运输模式
- Discount: 折扣(打几折)
- Shipping Cost: 运费
- Order Priority: 订单优先级
- Product_Name: 商品名称
- Category: 商品大类
- Sub_Category: 商品小类
- Country: 客户所在国家
- State: 客户所在州/省份
- City: 客户所在城市名称
- Segment: 客户类型,Consumer普通客户, Home Office Corporate公司客户
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 数据清洗
df.info() # 分析有无空值和每列的数据类型.
df.rename(columns=lambda x:x.replace(' ','_').replace('-','_'),inplace=True) # 列索引命名规范
# 转换成时间类型
df['Order_Date'] = pd.to_datetime(df['Order_Date'])
""" df['Order_Date'].head(3),df['Order_Date'].dtypes
(0 2011-01-01
1 2011-01-01
2 2011-01-01
Name: Order_Date, dtype: datetime64[ns],
dtype('<M8[ns]'))
"""
# 增加单独的年份和月份字段
df['year'] = df['Order_Date'].dt.year
df['y_m'] = df['Order_Date'].values.astype('datetime64[M]') # 精度 年月,是包含年的哦!!
df['m'] = df['Order_Date'].dt.month # 精度 只有月!!
""" df['year'].head(),df['y_m'].head(),df['m'].head()
(0 2011
1 2011
2 2011
3 2011
4 2011
Name: year, dtype: int64,
0 2011-01-01
1 2011-01-01
2 2011-01-01
3 2011-01-01
4 2011-01-01
Name: y_m, dtype: datetime64[ns],
0 1
1 1
2 1
3 1
4 1
Name: m, dtype: int64)
"""
# 发现Postal_Code列缺失的数据比较多,该列数据对分析没帮助. - 直接删除该列
df.isnull().sum()
df.drop(columns=['Postal_Code'],inplace=True)
# 查看是否有重复行
df.duplicated().sum() # 0
# 查看是否有异常数据 因为原始数据的Row_ID列的数据类型是int类型,我们不想让其参加 df.describe() 的运算进行了类型转换!
df['Row_ID'] = df['Row_ID'].astype('str')
df.describe()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 场
首先构造整体销售情况子数据集, 销售情况主要需要观察如下字段, 包含: 下单日期、销售额、销量、利润、年份和月份信息.
sales_data = df[['Order_Date','Sales','Quantity','Profit','year','y_m','m']]
sales_data.head()
2
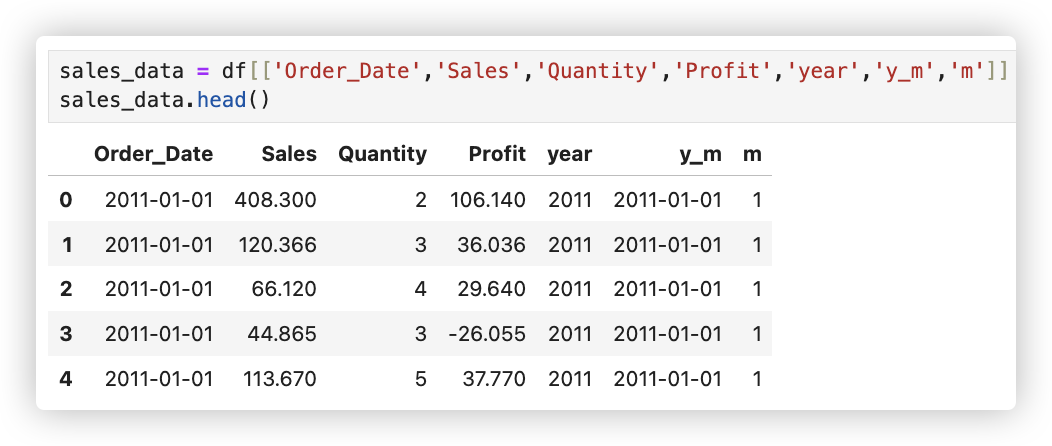
# 每年销售总额和增长率
Q1: 计算分析每年销售额的销售总额和增长率..
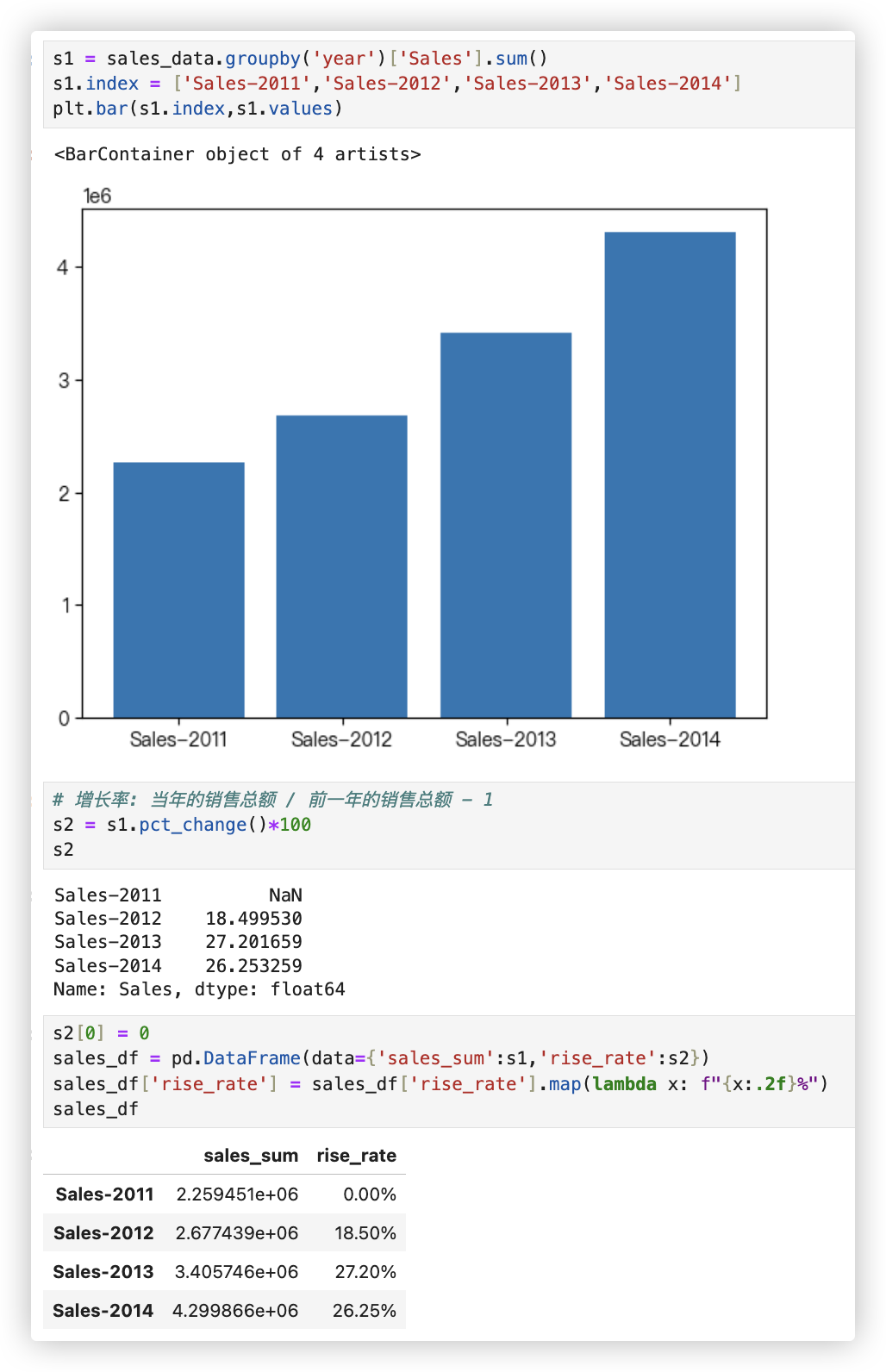
# 不同年月的总销售额
Q2: 查看不同年份对应不同月份的总销售额 看是否有淡旺季之分!
# -- 方案一
# sales_data.groupby('year')['Sales'].sum()
pivot_table = sales_data.pivot_table(index='year',values='Sales',aggfunc='sum',columns=['m']).T
pivot_table
pivot_table.plot(kind='line', marker='o')
# -- 方案二
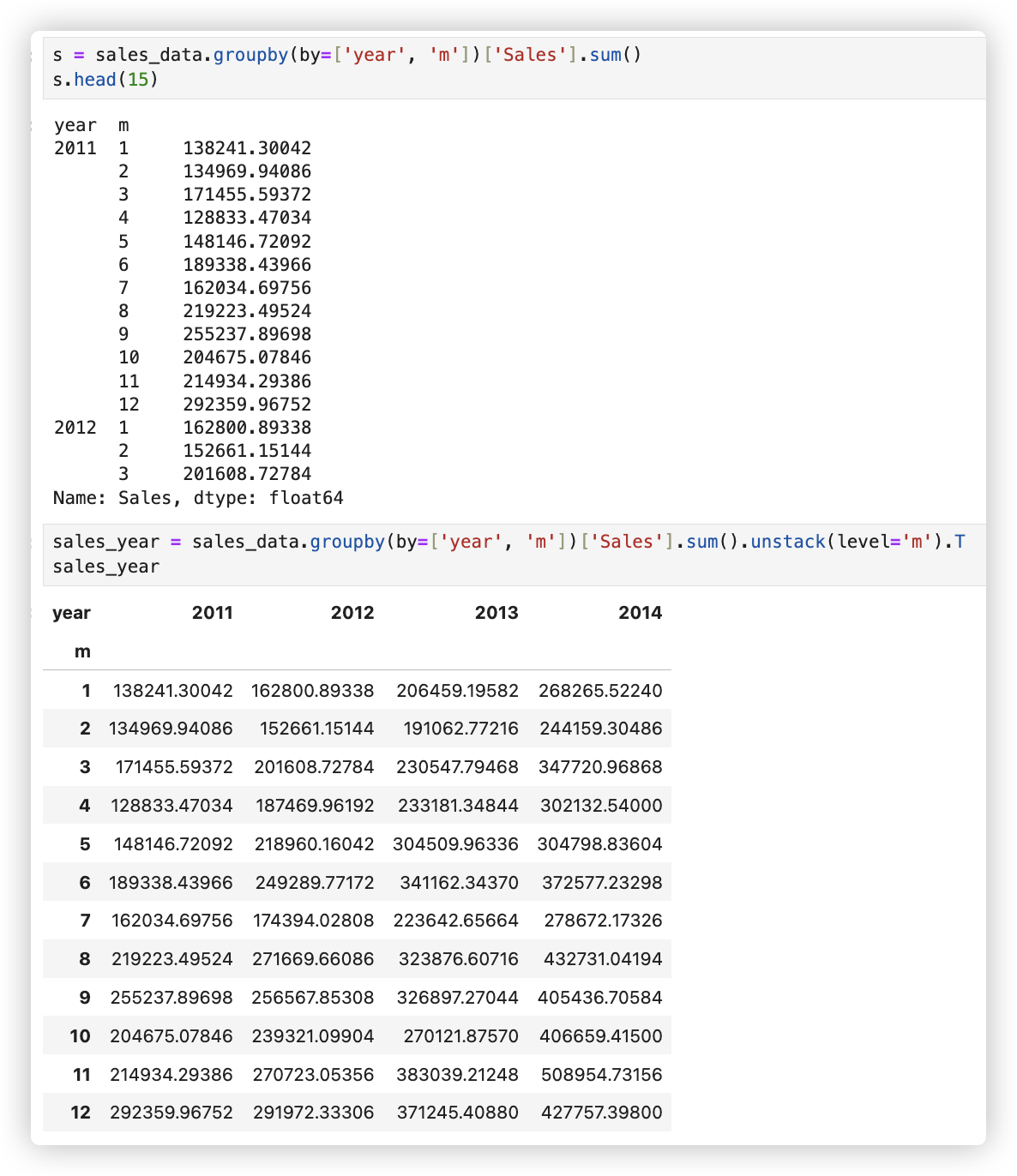
# - 查看不同年份对应不同月份的总销售额、总销量和总利润
sales_year = sales_data.groupby(by=['year','y_m'])[['Sales','Quantity','Profit']].sum()
sales_year.head() # 可以看到格式不是我们想要的,它进行的是行分割.
sales_year.loc[2011].head()
sales_year.loc[2011].head().reset_index()
year_2011 = sales_year.loc[2011].reset_index()
year_2012 = sales_year.loc[2012].reset_index()
year_2013 = sales_year.loc[2013].reset_index()
year_2014 = sales_year.loc[2014].reset_index()
sales = pd.concat([year_2011['Sales'],year_2012['Sales'],year_2013['Sales'],year_2014['Sales']],axis=1)
sales.columns = ['Sales-2011','Sales-2012','Sales-2013','Sales-2014']
sales.index = ['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月']
sales.style.background_gradient(axis=0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
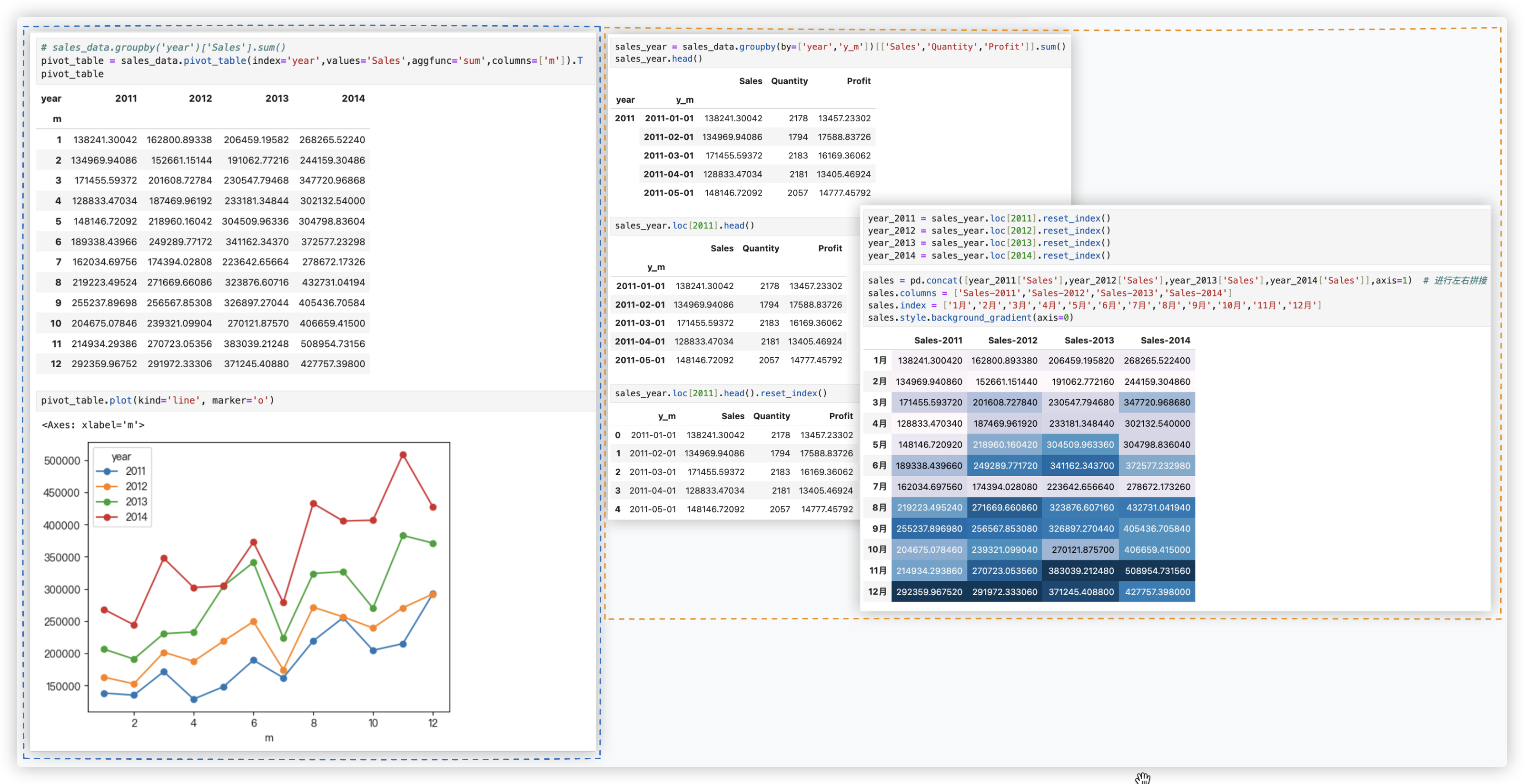
还有个方案, 使用unstack:
从上图中观测到, 基本上每一年都是下半年销售额比上半年要高, 而且随着年份的增大, 销售额也有明显的增加.
说明销售业绩增长较快, 整体发展呈现良性循环.
Q3:
前面关于销售额提了两个问题:
-1- 计算分析每年销售额的销售总额和增长率..
-2- 查看不同年份对应不同月份的总销售额、总销量和总利润.看是否有淡旺季之分!
接下来几个问题都是一样的解决,代码改个变量就行.
- 销量分析
计算分析每年销量的销量总额和增长率.
查看不同年份对应不同月份的总销量. 看是否有淡旺季之分!
- 利润分析
计算分析每年利润的利润总额和增长率
查看不同年份对应不同月份的利润. 看是否有淡旺季之分!
2
3
4
5
6
7
8
9
10
11
# 客单价分析
Q4: 客单价分析
客单价是指超市每一位顾客平均购买商品的金额.
从某种程度上反应了超市的消费群体的特点以及超市的销售类目的盈利状态是否健康.
客单价 = 总消费金额 / 总消费人数.
df1 = df[['year','Customer_ID','Order_Date','Sales']]
def func(year_data):
# total_num = year_data.groupby('Customer_ID')['Order_Date'].nunique().sum()
total_num = year_data.drop_duplicates(subset=['Customer_ID', 'Order_Date']).shape[0]
total_amount = year_data['Sales'].sum()
mean_price = format(total_amount / total_num,'.2f')
return total_num,total_amount,mean_price
s1 = df1.groupby('year').apply(func)
"""
year
2011 (4453, 2259450.89554, 507.40)
2012 (5392, 2677438.6944, 496.56)
2013 (6753, 3405746.44938, 504.33)
2014 (8696, 4299865.87056, 494.46)
dtype: object
"""
s1
p = pd.DataFrame(data=s1.to_list(),index=s1.index,columns=['总消费日期人数','总消费金额','客单价'])
"""
总消费日期人数 总消费金额 客单价
year
2011 17812 2.259451e+06 126.85
2012 21568 2.677439e+06 124.14
2013 27012 3.405746e+06 126.08
2014 34784 4.299866e+06 123.62
"""
p
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
其实通俗一点, 用for循环就行..
for i in range(2011,2015):#2011,2012,2013,2014
data = df.loc[df['year'] == i]
#求当年总消费人数
total_num = data.groupby(by='Order_Date')['Customer_ID'].nunique().sum()
#求当年的总消费金额
total_amount = data['Sales'].sum()
mean_price = format(total_amount / total_num,'.2f')
print('%d年的总消费人数是:%d,总消费金额是:%f,客单价是:%s'%(i,total_num,total_amount,mean_price))
"""
2011年的总消费人数是:4453,总消费金额是:2259450.895540,客单价是:507.40
2012年的总消费人数是:5392,总消费金额是:2677438.694400,客单价是:496.56
2013年的总消费人数是:6753,总消费金额是:3405746.449380,客单价是:504.33
2014年的总消费人数是:8696,总消费金额是:4299865.870560,客单价是:494.46
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 市场布局分析
这家超市是全球连锁的, 在不同地区都有对应的市场, 所以接下来分析下不同地区之间的销售情况.
计算下不同市场不同年份对应的总销售额:
market_year_sales = df.groupby(by=['Market','year'])['Sales'].sum().reset_index()
"""
Market year Sales
0 APAC 2011 6.392453e+05
1 APAC 2012 7.627193e+05
2 APAC 2013 9.745809e+05
3 APAC 2014 1.209199e+06
4 Africa 2011 1.271873e+05
"""
market_year_sales.head()
import seaborn as sns #高级的plt
sns.barplot(x='Market',y='Sales',hue='year',data=market_year_sales) # 画柱状图
2
3
4
5
6
7
8
9
10
11
12
13
再看一下四年来各个地区销售额占总销售额的百分比
Market_Sales = df.groupby(['Market']).agg({'Sales':'sum'})
Market_Sales["percent"] = Market_Sales["Sales"] / df["Sales"].sum()
"""
Sales percent
Market
APAC 3585744.129000 0.283626
Africa 783773.211000 0.061995
Canada 66928.170000 0.005294
EMEA 806161.311000 0.063766
EU 2938089.061500 0.232398
LATAM 2164605.167080 0.171217
US 2297200.860300 0.181705
"""
Market_Sales
2
3
4
5
6
7
8
9
10
11
12
13
14
从以上图表可以看出, 每个地区每年销售额总体处于上升趋势, 其中APAC(亚太地区)、EU(欧盟)、US(美国)、LATAM(拉丁美洲)
的销售额超过了总销售额的85%, 总体也与地区的经济发展相匹配.
其中加拿大Canada的销售额微乎其微, 可以结合公司整体战略布局进行取舍.
# 货
# 查看前10的商品
需求: 分别查看销量、销售额、利润前10的商品
# 查看销量前10的商品
df.groupby('Product_ID')['Quantity'].sum().sort_values(ascending=False).head(10)
# 查看销售额top10的商品
df.groupby('Product_ID')['Sales'].sum().sort_values(ascending=False).head(10)
# 查看利润top10的商品
df.groupby('Product_ID')['Profit'].sum().sort_values(ascending=False).head(10)
2
3
4
5
6
7
8
# 查看具体商品种类的销售情况
需求: 查看具体商品种类的销售情况(包含销售量和销售额) 以及按销售额降序排列后,销售额的累积占比
df['Category_and_Sub_Category'] = df[['Category','Sub_Category']].apply(lambda x:x[0]+"_"+x[1],axis=1)
df_t = df.groupby('Category_and_Sub_Category')[['Profit','Sales']].sum().reset_index()
df_t.sort_values(by=['Sales'],ascending=False,inplace=True)
df_t['销售额累计占比'] = df_t['Sales'].cumsum() / df_t['Sales'].sum()
df_t
"""
Category_and_Sub_Category Profit Sales 销售额 累计占比
16 Technology_Phones 216717.00580 1.706824e+06 0.135007
14 Technology_Copiers 258567.54818 1.509436e+06 0.254401
1 Furniture_Chairs 140396.26750 1.501682e+06 0.373181
0 Furniture_Bookcases 161924.41950 1.466572e+06 0.489184
11 Office Supplies_Storage 108461.48980 1.127086e+06 0.578335
4 Office Supplies_Appliances 141680.58940 1.011064e+06 0.658308
15 Technology_Machines 58867.87300 7.790601e+05 0.719931
3 Furniture_Tables -64083.38870 7.570419e+05 0.779811
13 Technology_Accessories 129626.30620 7.492370e+05 0.839075
6 Office Supplies_Binders 72449.84600 4.619115e+05 0.875611
2 Furniture_Furnishings 46967.42550 3.855783e+05 0.906110
5 Office Supplies_Art 57953.91090 3.720920e+05 0.935542
10 Office Supplies_Paper 59207.68270 2.442917e+05 0.954865
12 Office Supplies_Supplies 22583.26310 2.430742e+05 0.974091
7 Office Supplies_Envelopes 29601.11630 1.709043e+05 0.987610
8 Office Supplies_Fasteners 11525.42410 8.324232e+04 0.994194
9 Office Supplies_Labels 15010.51200 7.340403e+04 1.000000
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
从结果中我们可以分析出:
- 从图表中可以很清晰的看到不同种类商品的销售额贡献对比.有将近一半的商品的总销售占比达到84%.
应该是自家优势主营产品,后续经营中应继续保持,可以结合整体战略发展适当加大投入,逐渐形成自己的品牌.
- 同时,也可以发现,末尾占比16%的产品中大部分是办公用品中的小物件.
可以考虑与其他主营产品结合,连带销售来提升销量,或者考虑对这些商品进行优化.
2
3
4
# 人
# 不同类型用户分析
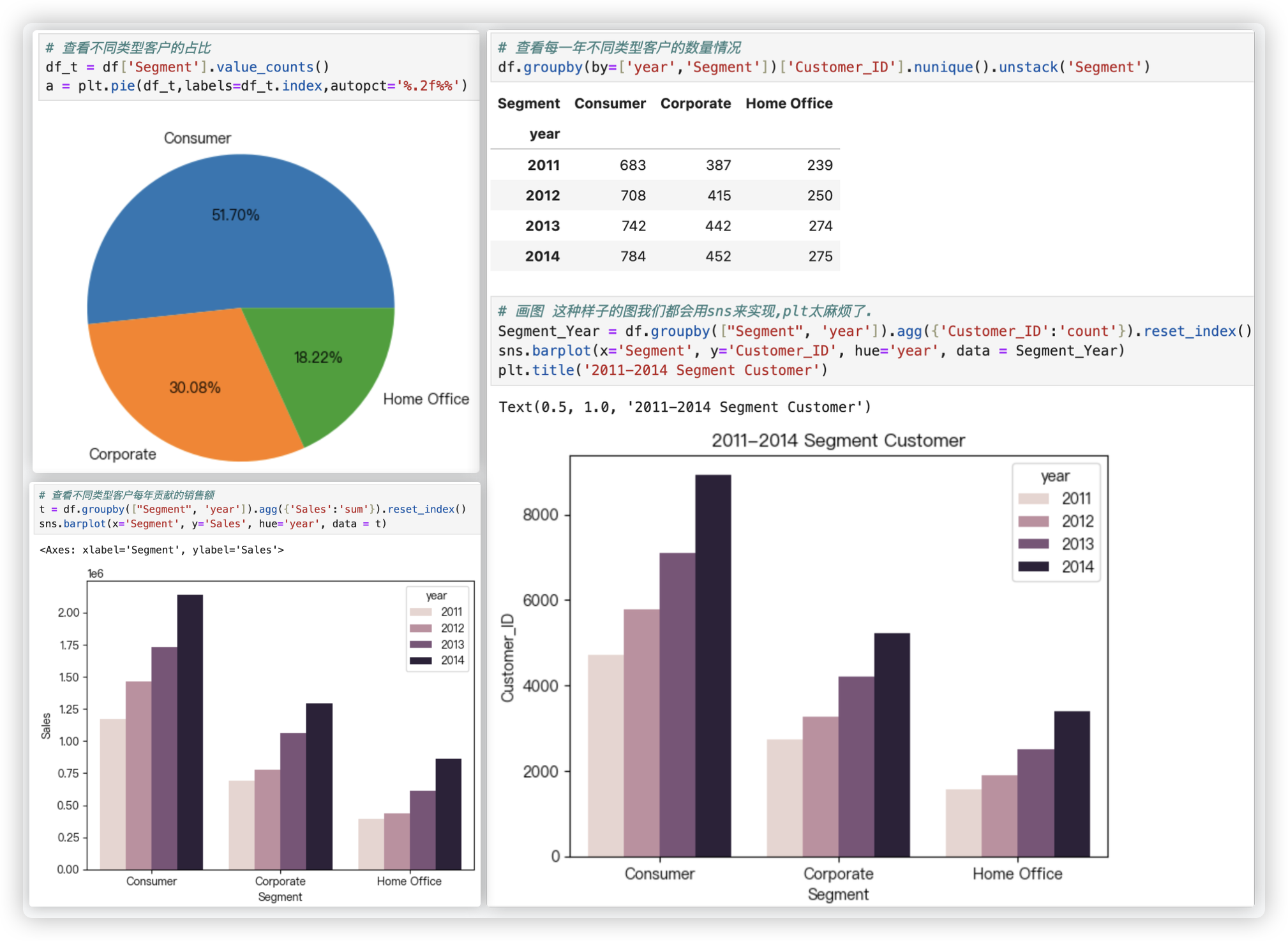
从饼图中可以看出, 这四年来, 普通消费者的客户占比最多, 达到51.7%.
从每一年不同类型客户的数量情况的柱状图可以看出. 每类客户每年均在保持增长趋势, 客户结构还是非常不错的.
从不同类型客户每年贡献的销售额的柱状图可以看出. 在稳步提升, 普通消费者贡献的销售额最多, 这和客户占比也有一定关系.
# 查看不同类型客户的占比
df_t = df['Segment'].value_counts()
plt.pie(df_t,labels=df_t.index,autopct='%.2f%%')
# 查看每一年不同类型客户的数量情况 画图 这种样子的图我们都会用sns来实现,plt太麻烦了.
# df.groupby(by=['year','Segment'])['Customer_ID'].nunique().unstack('Segment')
Segment_Year = df.groupby(["Segment", 'year']).agg({'Customer_ID':'count'}).reset_index()
sns.barplot(x='Segment', y='Customer_ID', hue='year', data = Segment_Year)
plt.title('2011-2014 Segment Customer')
# 查看不同类型客户每年贡献的销售额
t = df.groupby(["Segment", 'year']).agg({'Sales':'sum'}).reset_index()
sns.barplot(x='Segment', y='Sales', hue='year', data = t)
2
3
4
5
6
7
8
9
10
11
# 客户下单行为分析
# 每日客户的新增和流失
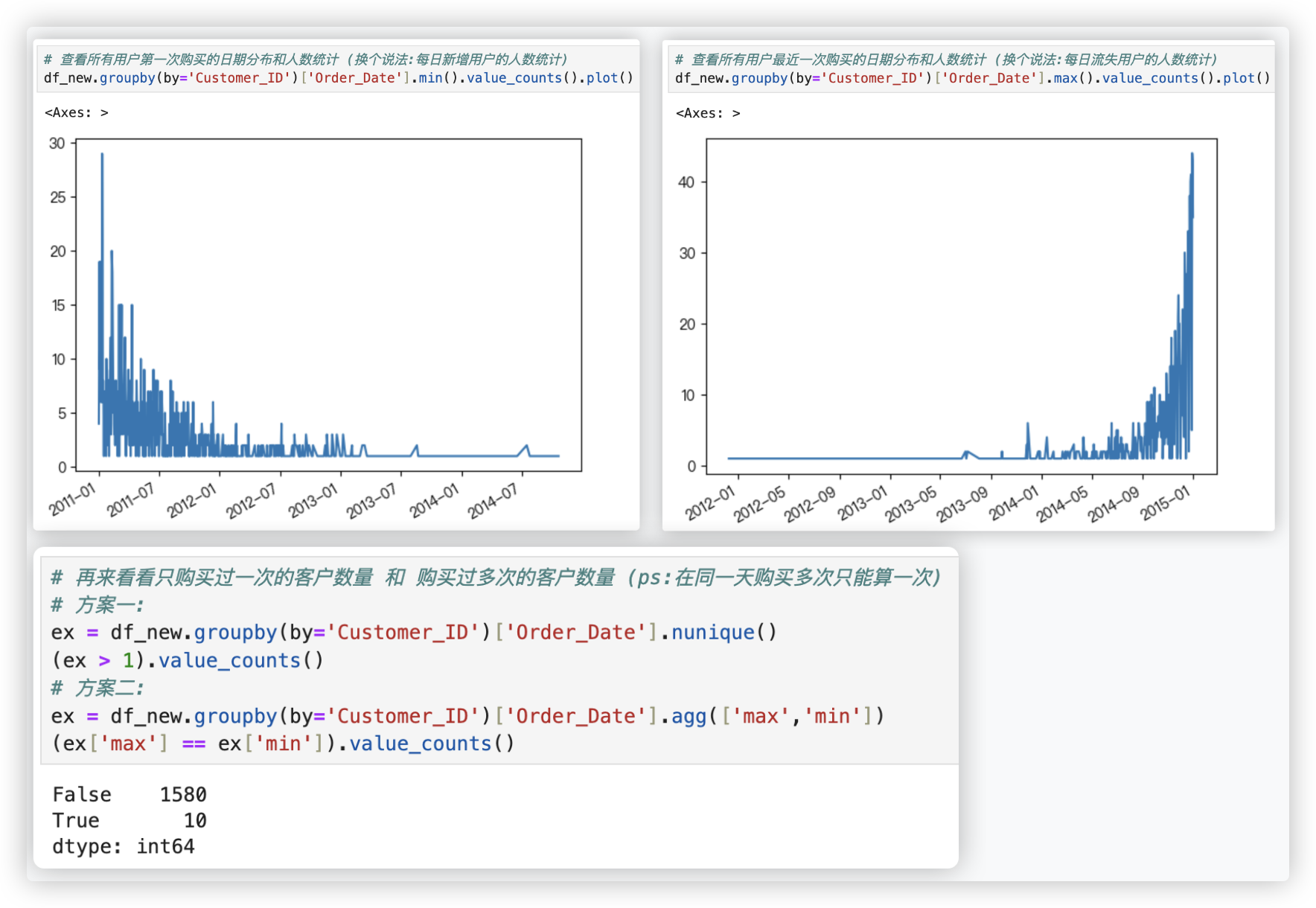
- 从上面的两个折线图可以看出,在13年初以后新用户增长的趋势缓慢,商家可以通过广告等推广策略吸收更多的新用户;
而通过观察最近一次购买日期,可以发现用户基本没有流失,也验证了每年销售额的增长趋势.
总体来说新客户数量是在逐年递减的,说明该企业老客户的维系不错,但新客获取率较低.
如果能够在新客户获取上能够突破,会给企业带来很大的增长空间.
- 从结果来看,只购买一次的用户只有10个,大部分用户都会购买多次,说明回头率很高,也验证了上面关于该企业老客户的维系不错的结论.
2
3
4
5
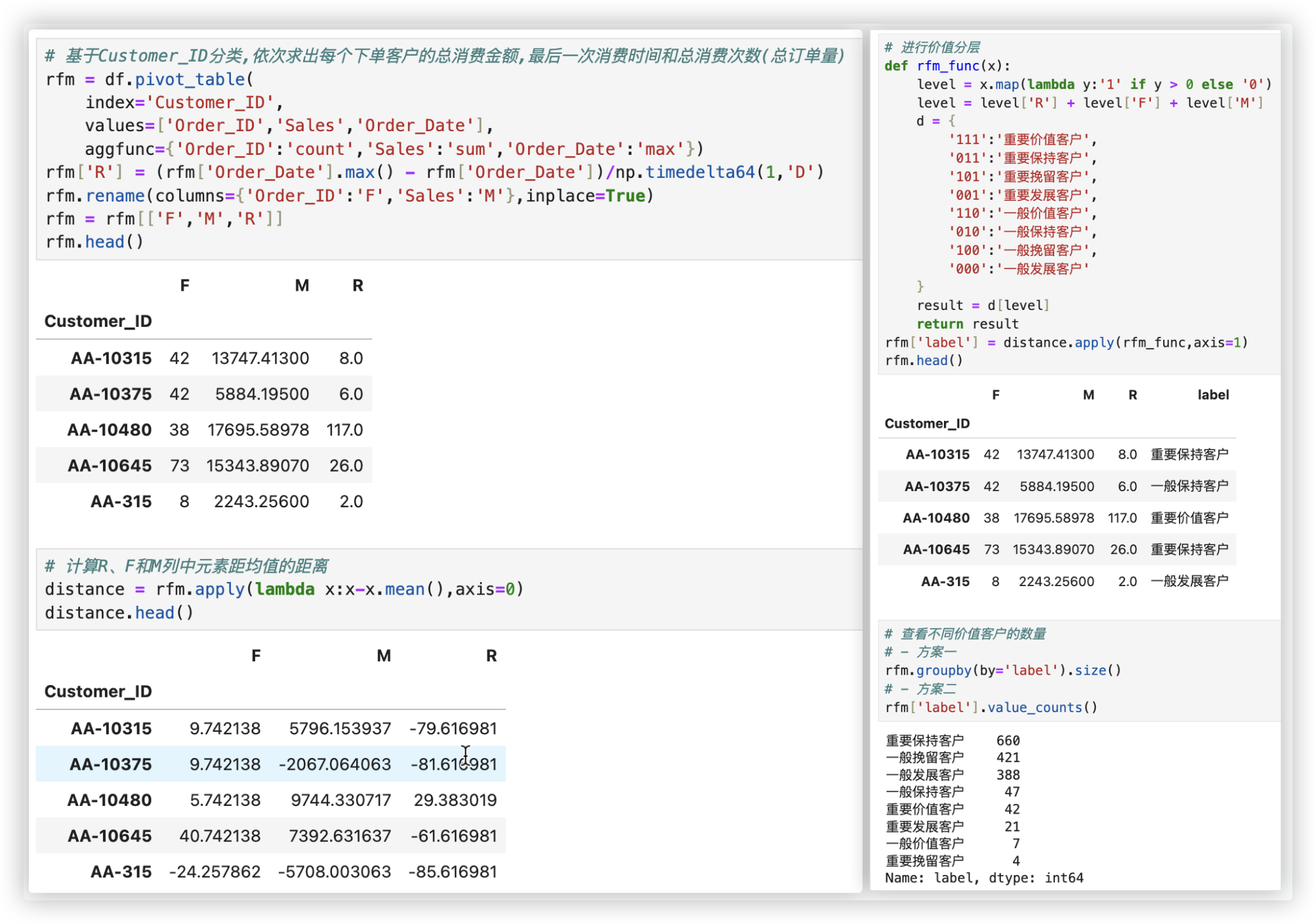
# RFM模型分析
R(Recency): 客户最近一次交易时间的间隔. R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近.
F(Frequency):客户在最近一段时间内交易的次数. F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃.
M(Monetary): 客户在最近一段时间内交易的金额. M值越大,表示客户价值越高,反之则表示客户价值越低.
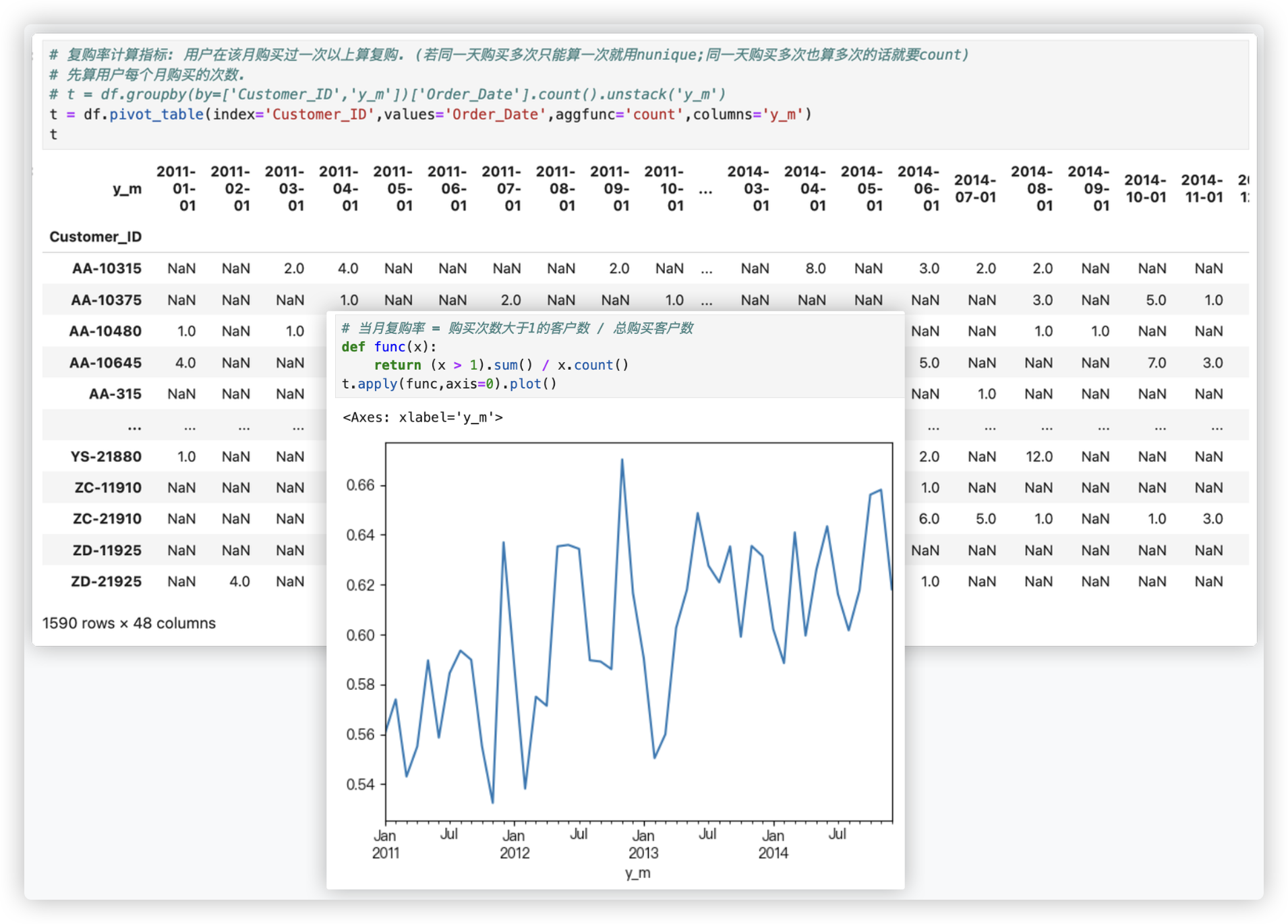
# 复购率
>>> import numpy as np
>>> import pandas as pd
>>> s1 = pd.Series([1,0,3,1,np.nan])
>>> s1
0 1.0
1 0.0
2 3.0
3 1.0
4 NaN
dtype: float64
>>> s1>1
0 False
1 False
2 True
3 False
4 False
dtype: bool
>>> (s1>1).sum()
np.int64(1)
>>> s1.count()
np.int64(4)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
从上可以发现复购率基本大于0.525, 且呈总体上升趋势, 说明客户忠诚度高..