 drf-后篇
drf-后篇
# restful规范
我们熟知restful规范
- http://127.0.0.1:8000/api/shipper/wallet/
GET 数据列表
POST 新建
- http://127.0.0.1:8000/api/shipper/wallet/1/
GET 单条数据
PUT 全部更新
PATCH 局部更新
DELETE 删除
2
3
4
5
6
7
8
9
# 前后端交互
★ 前后端交互一定要清楚知道这个逻辑图!
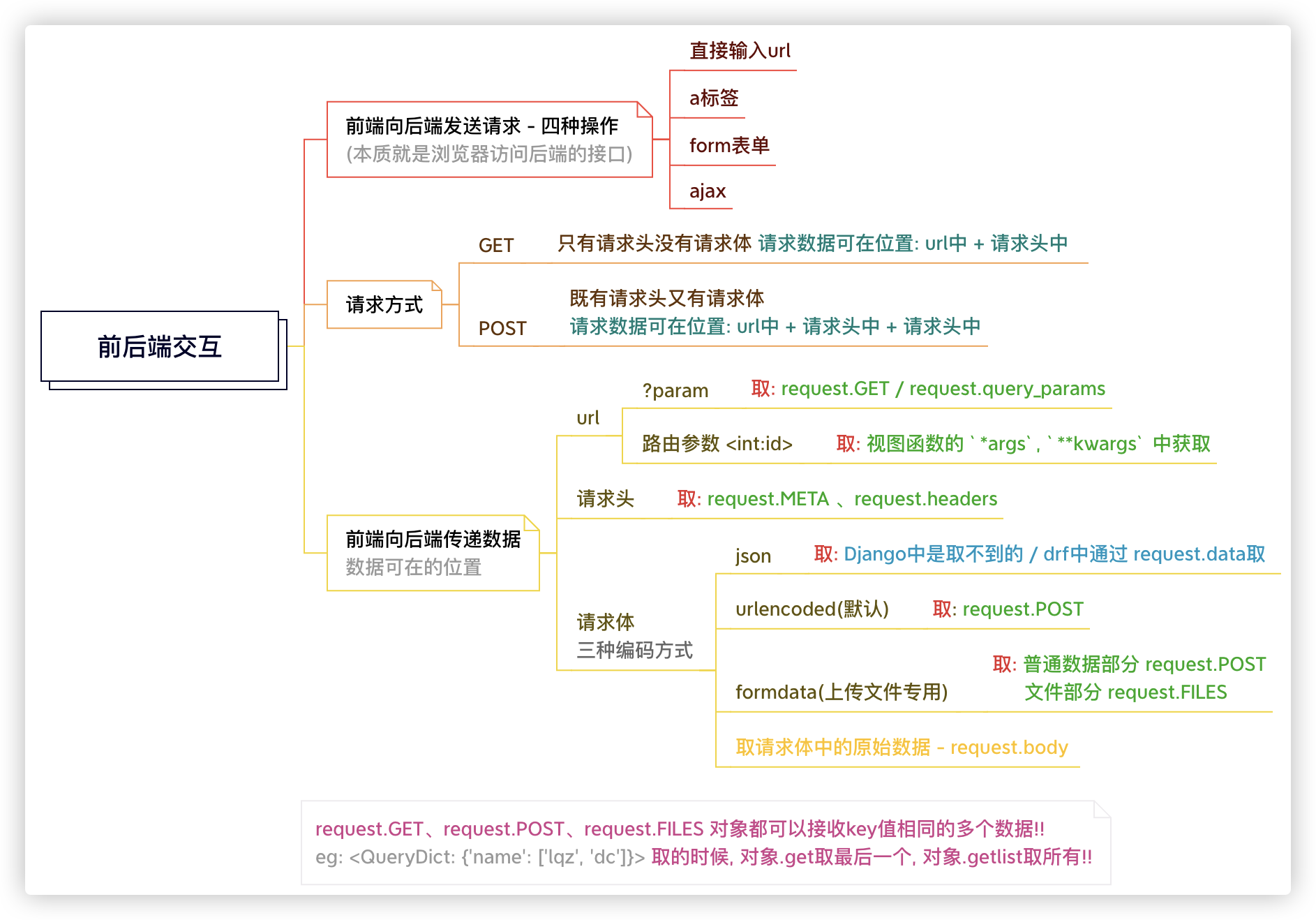
数据格式如下:
# Django反向解析
首先需要明白: Django的反向解析, 是通过name反向解析 [路由] !!而不是反向解析url哦!
其次需要知道: 在[任意]视图函数或者模版代码中都可以 根据name反向解析出任一路由!!
即使用路由反向解析,跟当前访问哪个api是无关的.
与request请求是无关的.只不过reverse方法里的参数kwargs的值可能需要通过request得到.
在路由层我们设置了4个路由: "提醒:path是路径完全适配才行哦!"
-1- path('home/', demo.HomeView.as_view(), name='hh1'),
-2- path('home/<int:pk>/', demo.HomeDetailView.as_view(), name='hh2'),
-3- path('index/<int:pk>/<str:version>/', views.IndexView.as_view(), name='ww1'),
-4- path('order/<int:pk>/', views.OrderView.as_view(), name='yy1'),
2
3
4
5
| 浏览器输入网址/url | 匹配的路由 | 视图函数中 request.get_full_path() |
|---|---|---|
http://127.0.0.1:8000/home/?version=v1 | 路由1 | /home/?version=v1 |
http://127.0.0.1:8000/home/2/?version=v1 | 路由2 | /home/2/?version=v1 |
http://127.0.0.1:8000/index/1/v1/ | 路由3 | /index/1/v1/ |
http://127.0.0.1:8000/order/98/ | 路由4 | /order/98/ |
我们可在 [任一] 视图函数中通过name值反向解析路由!
name对应的路由中有多少个路由参数反向解析时就需传递多少个!! 这些往往可以从 request.GET、*args、**kwargs中取到!
reverse('hh1') -- /home/
reverse('hh2', kwargs={'pk': 11}) -- /home/11/
reverse('ww1', kwargs={'pk': 12, 'version':'v3'}) -- /index/12/v3/
reverse('yy1', kwargs={"pk": 98}) -- /order/98/
2
3
4
# 版本
想要每个api接口都有版本信息,那么 版本信息就不能在 请求体中传递! 因为 GET请求是没有请求体的!
传递版本信息的渠道: url的?params、路由参数、请求头中.. 我们通常会选择在路由参数中传递!
配置版本类后, 版本信息可以通过 request.version 来获取.
注: 剖析drf的源码, 版本是在 认证、权限、限流 前面执行的哦!
# ◎ 实现版本
1. 在我们自己的视图类中 局部配置 版本类, 或者 在settings配置文件中进行全局配置
- 局部配置 "当前视图类里的所有接口应用了版本"
from rest_framework.versioning import QueryParameterVersioning
versioning_class = QueryParameterVersioning
- 全局配置 "所有视图类下的所有接口都应用了版本"
DEFAULTS = {
'DEFAULT_VERSIONING_CLASS': "rest_framework.versioning.QueryParameterVersioning",
}
2. 在settings配置文件中配置 默认版本号、运行版本号、版本参数名, 举个栗子:
DEFAULTS = {
'DEFAULT_VERSION': 0.1, # 默认版本号
'ALLOWED_VERSIONS': ['2','3','4'], # 允许的版本号
'VERSION_PARAM': 'xx', # 版本参数名
}
-★- 当然,你设置版本,通常有三种选择 QueryParameterVersioning / URLPathVersioning / AcceptHeaderVersioning
VERSION_PARAM版本的参数名 应该分别 出现在 ?params中 / 路由参数中 / 请求头中 !
若从 request.query_params.get / kwargs.get / request.META.get 中 没有找到 该VERSION_PARAM参数名
那么, 其值 就使用 默认版本号 DEFAULT_VERSION.
否则 其对应的值 应该出现在 ALLOWED_VERSIONS 允许的版本号中.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# ◎ drf版本的应用场景
在请求中携带版本号, 便于后续API的更新迭代!
后端跟前端(app‘ios/安卓’、小程序、网页)配合开发,前端向后端api发送请求,后端向前端返回json格式的数据.
同一个api会随着更新迭代有版本的不同,在开发过程中,版本不是一下子全部切换过去的,肯定会有两个版本同时存在的情况.
比如:小程序开发的快,网页开发的慢.. 同一个api都要对其进行支持,所以会有版本区分.
--> 在视图函数中判断request.version,然后写相应的代码即可!
2
3
4
5
# ◎ drf版本的默认配置
DEFAULTS = {
'DEFAULT_VERSIONING_CLASS': None,
'DEFAULT_VERSION': None, # 默认版本号
'ALLOWED_VERSIONS': None, # 允许的版本号
'VERSION_PARAM': 'version', # 版本参数名
}
==> drf版本的默认设置,没有配置版本类,意味着整个流程就没有版本呗!
2
3
4
5
6
7
# ◎ drf版本的返回结果
根据下面的述源码可知,版本类配置后
-1- 若通过 scheme.determine_version, 版本号合法性验证成功, request当前请求中会加入两个成员 版本号和版本类实例
可分别根据 request.version 和 request.versioning_scheme 获取到!!
-2- 若通过 scheme.determine_version, 版本号合法性验证失败, 会返回错误信息
{"detail": "Invalid version in query parameter."}
def initial(self, request, *args, **kwargs):
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme # request当前请求中加入了两成员 版本号,版本类实例
self.perform_authentication(request) # 认证
self.check_permissions(request) # 权限
self.check_throttles(request) # 限流
def determine_version(self, request, *args, **kwargs):
if self.versioning_class is None:
return None, None
scheme = self.versioning_class()
return scheme.determine_version(request, *args, **kwargs), scheme
2
3
4
5
6
7
8
9
10
11
12
13
# ◎ drf版本的反向解析
关于这个我还是有点迷糊的,以下的规则在当前请求匹配成功的视图函数中使用是没有任何问题的.
PS:那在其他视图函数中使用呢,多少应该会有点问题. 待验证,遇到了再验证.
首先一点,就是结果中不仅有路径,还有协议、主机名等.
- 版本号在URL中传递参数
运用版本类的reverse进行反向解析时, 协议://主机名 + Django的reverse反向解析得到的路由 + ?version=v1
- 版本号在路由参数中传递
运用版本类的reverse进行反向解析时, 关于版本的动态参数可以不传,会自动帮忙传
eg:
浏览器地址: http://127.0.0.1:8000/api/2/home/
匹配的路由: path('api/<str:version>/home/', views.HomeView1.as_view(), name='hh'),
在视图函数中进行drf版本的反向解析,下面两条语句皆可.
1> request.versioning_scheme.reverse('hh', request=request)
2> request.versioning_scheme.reverse('hh', kwargs=kwargs, request=request)
- 版本号在请求头中传递
暂时没发现跟Django的reverse有啥不同,后续发现了再补充.
举个例子<版本参数在url中传递为例>:
浏览器地址 -- http://127.0.0.1:8000/home/2/?version=v1
匹配的路由 -- path('home/<int:pk>/', demo.HomeDetailView.as_view(), name='hh2'),
在视图函数中进行drf版本的反向解析
语句: request.versioning_scheme.reverse('hh2', kwargs={'pk': 11}, request=request)
结果: http://127.0.0.1:8000/home/11/?version=v1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
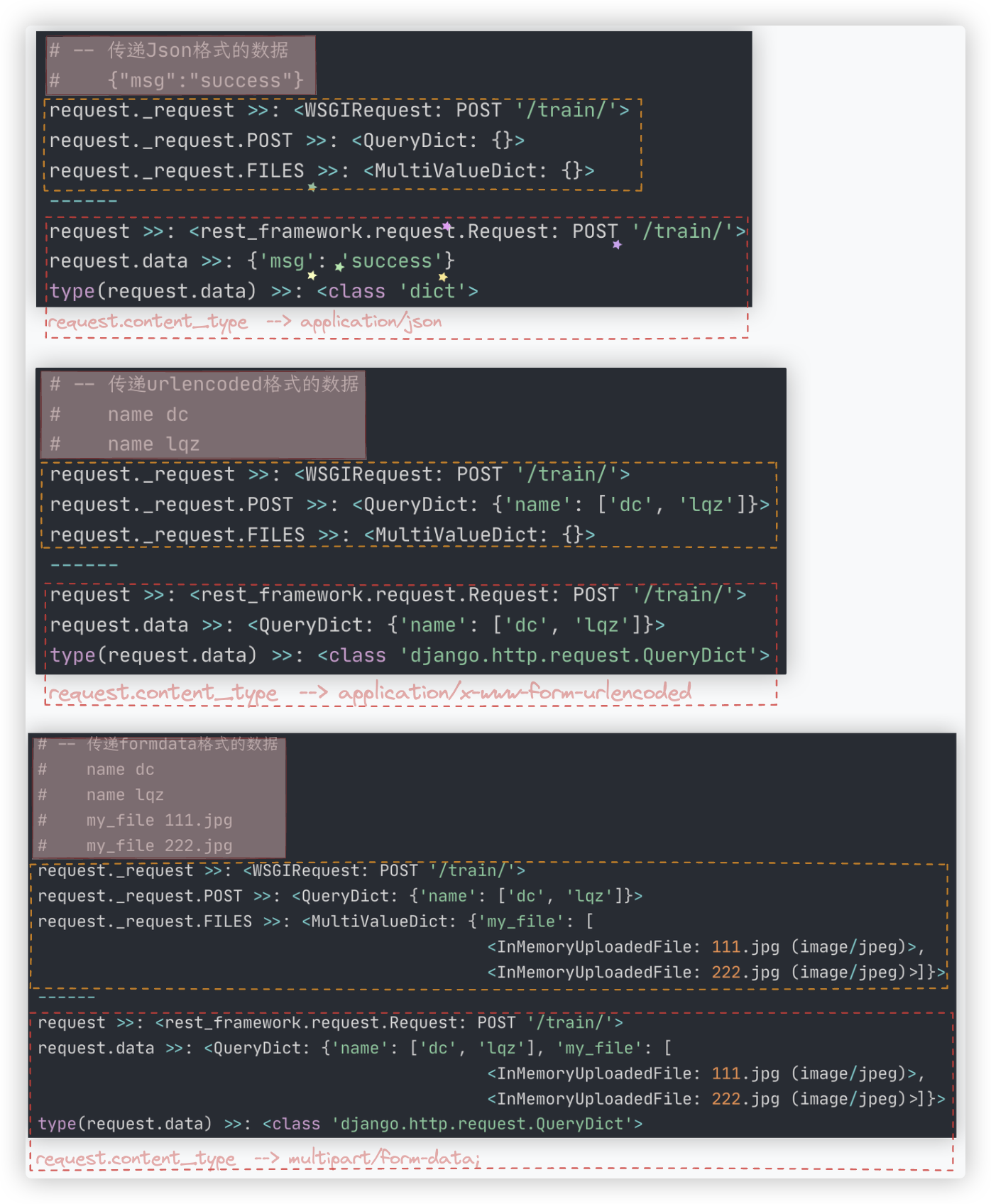
# 解析器
drf中可以使用 request.data 获取请求体中的数据(三种编码格式的数据都可以通过它取到).
# □ 实现解析器
啥也不用配置即可!
我们可以通过POSTMAN模拟POST请求. 在post视图函数中进行输出.
- POST请求,向http://127.0.0.1:8001/api/home/ 发送Json格式的数据 {"name": "武沛齐","age": 20}
request.content_type --> application/json # 等同于request.META.get('CONTENT_TYPE', '')
request.body --> b'{"name": "\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90", "age": 20}'
request.data --> {'name': '武沛齐', 'age': 20} # 其类型 <class 'dict'>
- POST请求,向http://127.0.0.1:8001/api/home/ 发送表单格式的数据,但表单中只包含普通数据
request.content_type --> application/x-www-form-urlencoded
request.body --> b'name=%E5%90%B4%E6%B2%9B%E9%BD%90&age=20'
request.data --> <QueryDict: {'name': ['武沛齐'], 'age': ['20']}>
# 其类型 <class 'django.http.request.QueryDict'>
- POST请求,向http://127.0.0.1:8001/api/home/ 发送表单格式的数据,表单中包括普通数据和文件数据
multipart/form-data;
boundary=--------------------------801261790305533003359691
b'----------------------------710861461266211277324559\r\nContent-Disposition: form-data;
name="name"\r\n\r\n\xe5\x90\xb4\xe6\xb2\x9b\xe9\xbd\x90\r\n---------------------------
-710861461266211277324559\r\nContent-Disposition: form-data;
name="img";filename="2321bd5a395d4d7ba2991869c5790950.jpg"\r\nContent-Type:
image/jpeg\r\n\r\n\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xfe\x00;
CREATOR: gd-jpeg v1.0 (using IJG JPEG v80), quality = 90\n\xff\xdb\x00C\x00\x03\...'
<QueryDict: {
'name': ['武沛齐'],
'img': [<InMemoryUploadedFile: 2321bd5a395d4d7ba2991869c5790950.jpg (image/jpeg)>]}
>
注: Django REST framework 还提供了 parsers.FileUploadParser 类, 可以用来处理原始格式的文件内容的上传.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# □ drf解析器的默认配置
DEFAULTS = {
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
'rest_framework.parsers.MultiPartParser'
],
'DEFAULT_CONTENT_NEGOTIATION_CLASS': 'rest_framework.negotiation.DefaultContentNegotiation',
}
相当于每个视图类
class HomeView(APIView):
parser_classes = [JSONParser, FormParser, MultiPartParser] # 解析器!!
content_negotiation_class = DefaultContentNegotiation # 根据请求头匹配对应的解析器!!
2
3
4
5
6
7
8
9
10
11
12
13
# □ drf解析器的应用场景
核心原理:
-1- 通过DefaultContentNegotiation类的select_parser方法,将请求头匹配的 解析器 筛选出来.
-2- 然后解析器使用parse方法,解析body里的数据.
★★★ 对应编码格式/对应请求头
JSONParser类 -- media_type = 'application/json'
FormParser类 -- media_type = 'application/x-www-form-urlencoded'
MultiPartParser类 -- media_type = 'multipart/form-data'
FileUploadParser类 -- media_type = '*/*'
★★★ 对应的应用场景
JSONParser -- 请求体里是json数据;
FormParser -- 请求体里是用&符号作为分隔符组织多组k-v数据 / 只上传普通数据.
MultiPartParser -- 请求体里既有普通数据(b'v1=123&v2=234')又有文件数据 / 既上传文件又上传普通数据.
FileUploadParser -- 请求体里只有文件数据; / 只上传文件数据.
2
3
4
5
6
7
8
9
10
11
# □ 关于源码
Django的前后端交互的三种编码方式.
从wsgi.py开始,一步步往下分析,重点是WSGIRequest类!它的实例化对象就是Django中的request!!
往后关键在于_load_post_and_files方法!!里面的那个if-elif-else!
而drf对数据的解析自己重新写了,相比下,还多了对json格式数据的支持!!
具体的剖析过程,祥看相关博客.
2
3
4
5
6
# ORM实现原理
Django中ORM相关的源码没有那么简单, 这里只是简单的实现了下基本的原理.
完整代码在 gitee仓库, 地址: https://gitee.com/One_PieceDC/source
关键代码截图如下: (不复杂,很容易就看懂啦 嘻嘻)
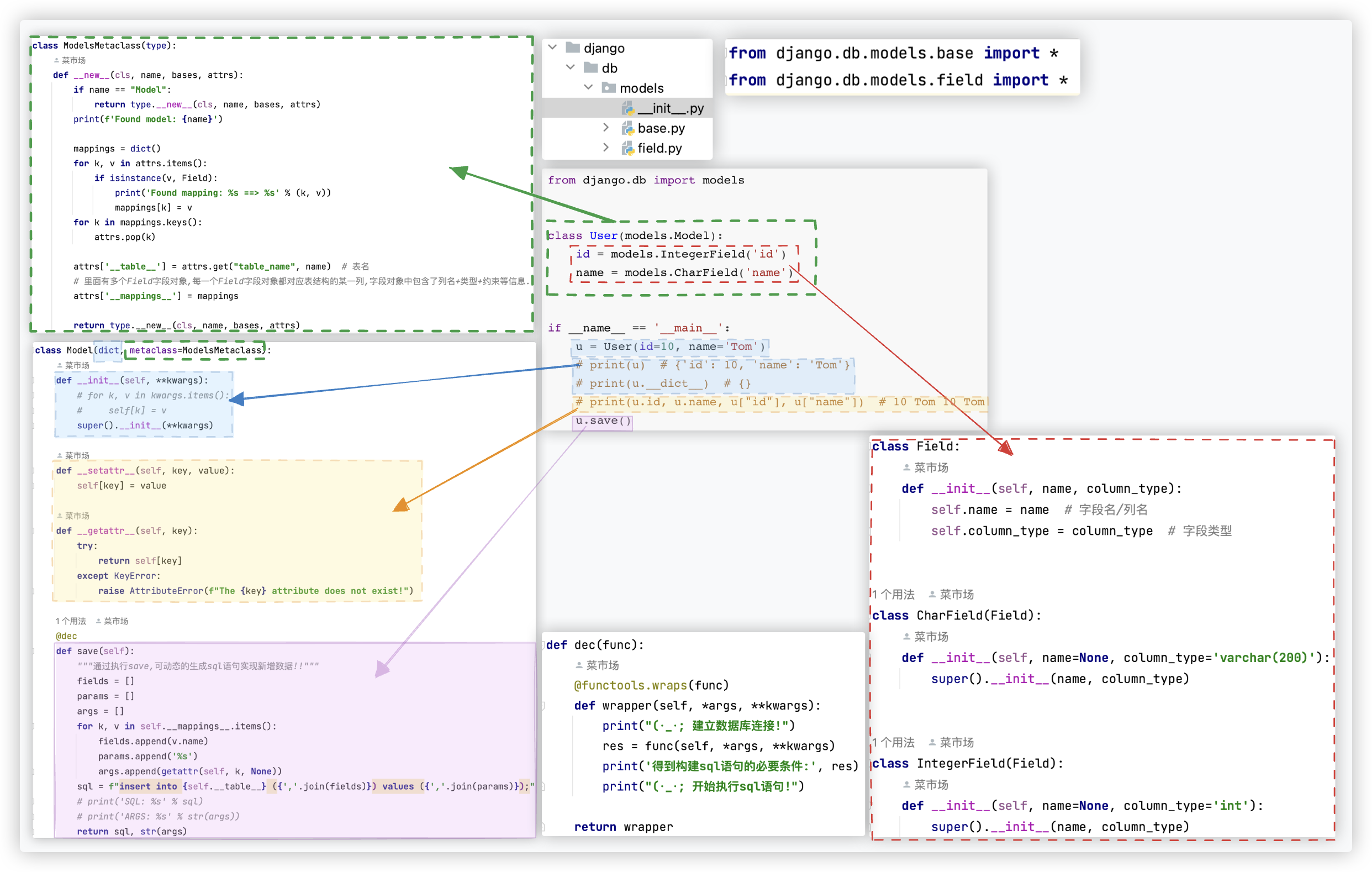
# 创建表结构SQL
■ 分析: 这是原生的创建表结构的sql语句
create table tb5(
id int not null auto_increment primary key, -- 不允许为空 & 主键 & 自增
name varchar(16) not null, -- 不允许为空
email varchar(32) null, -- 允许为空(默认)
age int default 3 -- 插入数据时,如果不给age列设置值,默认值:3
)default charset=utf8;
进而我们可以推断出, User通过元类创建后,User.__dict__中应包含了表结构的信息.
截图中的User类 <---对应---> 表结构
User类通过元类创建后,User.__dict__中包含了表结构的信息:
1. __table__:表名
2. __mappings__:里面有多个Field字段对象,每一个Field字段对象都对应表结构的某一列,字段对象中包含了列名+类型+约束等列相关的信息.
2
3
4
5
6
7
8
9
10
11
12
13
# 新增SQL
■ 分析: 这是原生的新增表记录的sql语句
insert into tb5(name,age) values("小明", 20);
tb5表名,name、age列名/字段名 都可以从 User的属性字典__dict__中取到; 那么值 "小明",20 呢?
User() <---对应---> 表的一条记录
u = User(name="小明", age=20) 通过类实例化后得到的实例 u
它是一个字典,eg: {'name': '小明', 'age': 20} 该字典是表中的一条记录的全部或部分信息!
pymysql连接mysql数据库,通过 User和User() 构建sql语句并执行!
2
3
4
5
6
7
8
# ★ 代码整个过程逻辑
- from django.db import models 包
- 类定义阶段 先字段对象id、name后class User
- class User 因为继承关系,在创建User类时会调用ModelsMetaclass中的__new__方法
为了将User类和MySql的一张表映射起来, User类中应该有个数据结构存储 Mysql一张表的结构 表名、每一列的信息[列名+类型+约束]
- User继承了dict 所以User的实例就是个字典!
- u = User(id=10, name='Tom') 会进行类实例化 先new后init
User继承了dict 根据继承链关系,__new__、__init__都会调用 dict中的
So. dict的__new__导致 实例是个空字典
dict的__init__ 说白了就是 for k, v in kwargs.items(): self[k] = v
该实例不是空字典啦!但没有给该实例添加任何独有的属性,导致u.__dict__()结果为{}
- u.id, u.name 与 __setattr__ 、__getattr__ 有关, 将字典只能通过 [] 取值 变成 还可以通过 . 取值!
- 装饰器
用sql语句创建表结构 <==> ORM表中得有相应的表信息+每列字段的特征
用sql语句新增记录 <==> ORM表的实例得有该记录的内容
用已有的信息(ORM表和ORM表的实例)去构建sql, 然后用pymysql连接数据库执行该sql语句. pymysql 单例?上下文?连接池?
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 序列化过程
# Step1:创建字段对象
序列化器类里的字段对象 都有实例属性_creation_counter 我们称其为计数器
意义何在? 让后续的源码,可根据该值的大小来决定对各个字段的处理顺序!表明它们的先后加载顺序.
> 实现原理
class Field:
count = 0
def __init__(self):
self.count = Field.count
Field.count += 1
- 序列化器类里的每个字段对象都是Field的实例,isinstance皆为True (会找继承链的
2
3
4
5
6
7
8
9
10
11
# Step2: 元类创建序列化器类
元类是个啥,这里就不再赘述.
注: 一个类在没有指定的metaclass的时候,如果它的父类指定了,那么这个类的metaclass等于父类的metaclass!!
Q:SerializerMetaclass元类的__new__(cls,name,bases,attrs)方法里做了什么? (attrs字典就是指序列化器类里的成员
A:
-1- 剔除 序列化器类中“Field字段类型的类变量” 并加到 新增的类变量_declared_fields中,其余类变量Meta等不变
-2- 序列化器类的类变量_declared_fields中有 "当前序列化器类" 中的字段对象 + "该类继承的其他自己写的序列化器类" 中的字段对象
遵循规则:
class C(A, B), and A and B both define 'field', use 'field' from A.
简单来说,序列化器类C继承了A和B, [字段对象"名字"重复时] 它是按照继承顺序保留字段对象的!
> 上面第 -1- 点的实现原理类似于 示例中将attrs中整数类型的键值对放到了新的键值对_declared_fields中.
attrs = {'a': 3, 'b': 'hello', 'c': 5, 'd': 9, 'e': 10}
new_dict = {}
for key, value in list(attrs.items()):
if isinstance(value, int):
new_dict[key] = attrs.pop(key)
attrs['_declared_fields'] = new_dict
print(attrs) # {'b': 'hello', '_declared_fields': {'a': 3, 'c': 5, 'd': 9, 'e': 10}}
> 上面第 -2- 点的实现,换个思路理解: A中的全要 + B中“A没有的” + C中“A和B都没有的”
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Step3: 序列化器类实例化
-情况1- InfoSerializer(instance=instance, many=False) => InfoSerializer类的实例
-情况2- InfoSerializer(instance=queryset, many=True) => ListSerializer类的实例,该实例有成员InfoSerializer类的实例!!
等同于 ListSerializer( child=InfoSerializer(instance=queryset, many=False) )
> 实现原理
class ListSerializer:
def __init__(self, child):
self.child = child
class BaseSerializer:
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls)
def __init__(self, instance=None, **kwargs):
self.instance = instance
super().__init__(**kwargs)
@classmethod
def many_init(cls, *args, **kwargs):
# 前面pop就是为了保证此处new时kwargs里没有many,cls()实例化时,就直接执行return super().__new__(cls)
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
return ListSerializer(**list_kwargs)
class InfoSerializer(BaseSerializer): pass
if __name__ == '__main__':
ser1 = InfoSerializer(instance="")
ser2 = InfoSerializer(instance="", many=True)
print(type(ser1)) # <class '__main__.InfoSerializer'>
print(type(ser2)) # <class '__main__.ListSerializer'>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Step4: ser.data - 单条
# Meta获取字段名
- fileds = [序列化器类中字段类型的类变量名"必须写进来"、还可以写ORM表中的字段名] # 无其他选择
fileds = "__all__" # 字段类型的类变量名 + ORM表中的字段名"包含id"
- exclude = 可写ORM表中的字段名(需排除通过类变量重写的字段名) # 无其他选择
即exclude中不应该有跟序列化器类中同名的字段类型的类变量
2
3
4
# 通过字段名获取字段对象
将上一步获得的字段名分为两组 注:第一组优先级高于第二组,因为类变量可能会跟ORM表中的字段名重名.
- 第一组, 字段类型的类变量 保留该字段对象
- 第二组, ORM表中的字段名 db匹配自动创建字段对象
> 实现原理
declared_fields = {"name": "...", "age": "..."} # 模拟序列化器类里字段类型的类变量
ORM_files = {"home": "..."} # 模拟ORM表中的字段对象
field_names = ["name", "age", "home"] # 模拟在Meta中获取的所需的字段名
fields = {}
for field_name in field_names:
if field_name in declared_fields:
fields[field_name] = declared_fields[field_name]
continue # ★
fields[field_name] = ORM_files[field_name]
print(fields)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 字段对象的属性处理
将上一步获取到的所有字段对象进行"bind操作",对其属性进行加工. 属性 -- field_name、parent、label、source、source_attrs
- field_name 字段名
- parent 序列化器类的实例化对象
- label 若字段类型的类变量没有传label值、ORM数据表中的该字段没有设置verbose_name,那么采用规则
label = 字段名.replace('_','').capitalize()
- source和source_attrs
-1- my_field = serializer.CharField(source='my_field') 会报错,source字段值冗余
因为 my_field = serializer.CharField() -- Source值默认与字段名相同
+++ source "字段名" <==> source_attrs ["字段名"]
-2- xxx = serializers.SerializerMethodField() -- 那么其source值为 "*"
+++ source "*" <==> source_attrs []
-3- serializers.CharField(sourse="depart.title")
+++ sourse "depart.title" <==> source_attrs ['depart','title']
-4- gender = serializers.CharField(source="get_gender_display")
+++ sourse "get_gender_display" <==> source_attrs ['get_gender_display']
> 实现原理 哪里调用的bind操作
from collections.abc import MutableMapping
class Field:
def __init__(self, *, source=None):
self.source = source
self.field_name = None
self.parent = None
def bind(self, field_name, parent):
# 对Field对象的属性进行一些处理!
pass
class BindingDict(MutableMapping):
def __init__(self, serializer):
self.serializer = serializer
self.fields = {}
def __setitem__(self, k, v):
self.fields[k] = v
v.bind(field_name=key, parent=self.serializer)
def __getitem__(self, k):
return self.fields[k]
def __delitem__(self, k):
del self.fields[k]
def __iter__(self):
return iter(self.fields)
def __len__(self):
return len(self.fields)
class InfoSerializer:
pass
got_fields_obj = {'name': Field(), 'age': Field(), 'home': Field()}
# 有时候内容容器类型并不能满足我们的需求,我们就需要创造新的容器类型来满足需求 <继承dict来创建自定义字典类型会出现一些问题>
# 使用 `update`、`setdefault`方法会调用`__setitem__`方法, `pop`、`clear`方法会调用`__delitem__`方法!!
fields = BindingDict(InfoSerializer())
for key, value in got_fields_obj.items():
fields[key] = value # 自动调用__setitem__
print(fields)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 字段对象的可序列化筛选
根据字段对象的not write_only的属性值进行判断!
# 开始序列化
★ 关键逻辑如下:
# instance = models.UserInfo.objects.all().first()
ret = {}
for 字段对象 in 可序列化的字段对象:
attribute = 字段对象.get_attribute(instance)
ret[field.field_name] = 字段对象.to_representation(attribute)
★ 关于attribute的值,分为以下几种情况:
-1- xxx = serializer.CharField() -- source_attrs = ["xxx"]
>> attribute = instance.xxx
-2- xxx = serializers.CharField(sourse="depart.title") -- source_attrs = ['depart','title']
>> attribute = instance.depart.title
-3- gender = serializers.CharField(source="get_gender_display") -- source_attrs ['get_gender_display']
>> attribute = instance.get_gender_display()
-4- xxx = serializers.SerializerMethodField() -- source_attrs []
>> attribute = instance
++伪代码如下++
class Field: # 字段对象继承的是Field
def get_attribute(self, instance):
get_attribute(self.source_attrs, instance)
def get_attribute(source_attrs, instance):
for attr in source_attrs: # attr = [] for循环直接结束
if callable(instance.attr): # attr = ['get_gender_display']
return instance.attr()
if isinstance(instance, Mapping):
instance = instance[attr] # 这个是验证后没有save直接序列化的情况,此处的instance是验证后的结果是字典.
else:
instance = getattr(instance, attr) # attr = ['depart','title'] 它很有意思!!
return instance
★ 关于to_representation,分为以下几种情况:
一般都是 ret[字段名]=int(attribute) ret[字段名]=str(attribute)
自定义方法/额外字段 xxx = serializers.SerializerMethodField() 很特殊!! 看下源码就明白了.
class SerializerMethodField(Field):
def __init__(self, method_name=None, **kwargs):
self.method_name = method_name
kwargs['source'] = '*'
kwargs['read_only'] = True
super().__init__(**kwargs)
def bind(self, field_name, parent):
# The method name defaults to `get_{field_name}`.
# method_name=None 其实可以自己绑定一个方法,不用它默认指定的方法名!
if self.method_name is None:
self.method_name = 'get_{field_name}'.format(field_name=field_name)
super().bind(field_name, parent) # -- 还是会调用Field中的bind.
# value 是instance一条记录 ; self.parent 是序列化器类的实例 ; self.method_name是指定的方法
def to_representation(self, value):
method = getattr(self.parent, self.method_name)
return method(value)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# Step4: ser.data - 多条
-情况1- InfoSerializer(instance=instance, many=Fasle) => InfoSerializer类的实例
-情况2- InfoSerializer(instance=queryset, many=True) => ListSerializer类的实例,该实例有成员InfoSerializer类的实例!!
等同于 ListSerializer( child=InfoSerializer(instance=queryset, many=False) )
(´▽`) 开始ser.data序列化
<单条数据>. 从InfoSerializer开始找data
- 先执行BaseSerializer里的data,里面 self._data = self.to_representation(self.instance)
- 接着执行Serializer里的to_representation
<多条数据>. 从ListSerializer开始找data
- 先执行ListSerializer里的data,因为super,接着执行BaseSerializer里的data
关键代码依旧是 self._data = self.to_representation(self.instance)
- 但该to_representation用的是ListSerializer里面的to_representation
ListSerializer里面的to_representation
for 单条数据 in 多条数据:
每条数据都用 自己写的序列化器类InfoSerializer来进行序列化
("ListSerializer的实例.child".to_representation 调用的是 Serializer里的to_representation)
每条数据的序列化结果都放到同一个列表里
★★★ 综上,不管单条还是多条,序列化都是Serializer里的to_representation在做!!
多条数据时,就是同一个InfoSerializer()实例在对多条数据进行序列化操作!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 使用手册
# 数据库准备
部门:用户 = 1:n ForeignKey外键在用户表,外键字段名为depart
标签:用户 = n:n ManyToManyField外键在用户表,外键字段名为tag,是虚拟字段!
from django.db import models
class Depart(models.Model):
title = models.CharField(verbose_name="部门", max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class Tag(models.Model):
caption = models.CharField(verbose_name="标签", max_length=32)
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(
verbose_name="性别", choices=((1, "男"), (2, "女")))
depart = models.ForeignKey(
verbose_name="部门", to="Depart", on_delete=models.CASCADE)
ctime = models.DateTimeField(
verbose_name="创建时间", auto_now_add=True)
tag = models.ManyToManyField(verbose_name="标签", to="Tag") # 会自动帮忙生成第三张表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 序列化器类
需求一: 不展示UserInfo表中的id字段.
需求二: 既想要choices属性的gender字段在数据库中存储的数字又想要该字段在内存中的文本内容.
需求三: depart 外键字段在 数据库的api_userinfo表中 存储的是数字, 想要展示关联表中的数据.
需求四: 默认时间的显示 年-月-日 时:分:秒, 若我只想显示 年月日, 如何操作?
需求五: 若现在我想随便定义一个字段返回, 如何操作呢? 通过 自定义方法 来实现.
from rest_framework import serializers
class UserSerializer(serializers.ModelSerializer):
gender_text = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title") # A表外键字段跨到B表.B表外键字段跨到C表.C表字段
ctime = serializers.DateTimeField(format="%Y-%m-%d") # "%Y-%m-%d" 是时间里的占位符.
xxx = serializers.SerializerMethodField()
def get_xxx(self, obj):
return "{}-{}-{}".format(obj.name, obj.age, obj.get_gender_display())
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "gender_text", "depart", "ctime", "xxx"]
2
3
4
5
6
7
8
9
10
11
12
13
14
需求六: 默认多对多的虚拟外交字段tag,展示的值是 "tag":[2,3], 若我并不想展示的是数字, 如何是好?
○ 方式一,基于嵌套实现, 嵌套主要针对 fk、m2m, 只有这两个用嵌套才有意义!
# - 当然DepartSerializer、TagSerializer序列化器里也可以自定制,这里从简. 知识是固定的,业务是灵活的,根据需求自由搭配嘛.
class DepartSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = "__all__"
class TagSerializer(serializers.ModelSerializer):
class Meta:
model = models.Tag
fields = "__all__"
class UserSerializer(serializers.ModelSerializer):
# ★★★ 敲黑板!! 当前用户关联部门,对应的部门记录是一条,当前用户关联标签,对应的标签记录是多条.So,多条的需要加上many=True.
depart = DepartSerializer()
tag = TagSerializer(many=True)
class Meta:
model = models.UserInfo
fields = ["name", "depart", "tag"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
○ 方式二, 用自定义方法/额外字段 来实现
class UserSerializer(serializers.ModelSerializer):
tag = serializers.SerializerMethodField()
"""
- 用户表的depart字段是ForeignKey,跨到部门表拿到的是一条数据;
- 用户表的tag字段是ManyToManyField,跨到标签表拿到该用户所关联的所有标签数据,是一个queryset对象,可包含多条数据!
伪代码:
for obj in queryset: # 此处queryset是用户表的所有数据
obj.name
obj.gender
obj.get_gender_display() # choice类型的字段
obj.depart.title # depart
get_xxx(obj) # 自定义方法
obj.tag.all() # 当前用户关联的tag表的所有数据,其结果是一个queryset对象! <QuerySet [Tag对象,Tag对象]>
# 回顾下ORM的查询就知道咋回事了!
"""
def get_tag(self, obj):
# 此处的obj是用户表的一条记录
# 对象.虚拟字段.all() 涉及到n:n ManyToManyField字段的查询.
# obj.tag跨到Tag表,此时可以看着1条用户记录对应多条tag记录,接着通过‘.all()‘取了出来.
tag_queryset = obj.tag.all()
return [{"id": tag.id, "caption": tag.caption} for tag in tag_queryset]
class Meta:
model = models.UserInfo
fields = ["name", "tag"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 视图 + 路由
■ APIView
- path('api/demo/', demo.DemoView.as_view()), -- 一个视图两个方法 GET POST
- path('api/demo/<int:pk>/', demo.DemoDetailView.as_view()) -- 一个视图三个方法 GET PUT DELETE
■ ViewSetMixin + APIView == ViewSet
- ViewSetMixin重写了as_view方法!(原来APIView是要调用Django的as_view的,现在它调用ViewSetMixin的as_view
它做了啥?eg: self.get = self.list 往下程序运行APIView里的dispatch方法时,反射执行的视图函数就变啦!!
■ ViewSetMixin + GenericAPIView == GenericViewSet
- GenericAPIView就是脱了裤子放屁,将我们在APIView里的代码规整了下.提供给五个视图扩展类用!
■ 五个视图扩展类 + GenericViewSet == ModelViewSet
- ListModelMixin -- list
- CreateModelMixin -- create
- RetrieveModelMixin -- retrieve
- UpdateModelMixin -- update
- DestroyModelMixin -- destory
urlpatterns = [
path('api/user/', demo.UserView.as_view({"get":"list","post":"create"})),
path('api/user/<int:pk>/', demo.UserView.as_view({"get":"retrieve","put":"update","delete":"destory"}))
]
一定要注意: 写了对应关系就得继承ViewSetMixin.
■ 每次都写这些路由,太麻烦了.我们可以自动生成路由! [查多条/查一条/增/删/改]
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('api/user', views.UserView, basename='user')
urlpatterns = [] + router.urls
■ 五个接口已经不能满足我了,我要在UserView类里再写几个接口!
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('api/user', views.UserView, basename='user')
urlpatterns = [
# ★ 这两个格外的路由这样写,跟SimpleRouter没有半毛钱关系!!就是普通的路由.
# >>> 你可以实验,这样写+action,相当于有两个路由匹配会执行test1 一个是'test1/' 一个是'api/user/test1/'
# >>> path('test1/', views.UserView.as_view({'get': 'test1'})),
# - 路由匹配,且是GET请求方式,那么就执行TestView类中的test1方法!!
path('api/user/test1/', views.UserView.as_view({'get': 'test1'})),
# - 路由匹配,且是PUT请求方式,那么就执行TestView类中的test方法!!
path('api/user/<int:pk>/test2/', views.UserView.as_view({'put': 'test2'})),
] + router.urls
★ 我们还可以不用自己写这个路由,在login方法上写action装饰器,让它帮我们生成!! >> action往往是与SimpleRouter搭配使用的!!
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('api/user', views.UserView, basename='user')
urlpatterns = [] + router.urls
from rest_framework.decorators import action
class UserView(ModelViewSet):
@action(methods=['GET'], detail=False, url_path='test1', url_name='test1') # -- 'api/user/test1/'
def test1(self,request):
pass
@action(methods=['PUT'], detail=True, url_path='test2', url_name='test2') # -- 'api/user/<int:pk>/test2/'
def test2(self,request,pk):
pass
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56