 过拟合与欠拟合的处理
过拟合与欠拟合的处理
在传统机器学习中,我们知道模型在经过训练后,会出现两个病灶 - 过拟合和欠拟合..
- 过拟合: 模型在训练集中表现很好,在测试集中表现不好 - 过度依赖训练集,泛化能力差
- 欠拟合: 模型在训练集和测试集中表现都不好
无论是过拟合还是欠拟合,都会影响模型最后的精度.
神经网络模型也会出现 过拟合和欠拟合 两个病灶.. 接下来,我们来阐述下如何解决!
# 欠拟合处理
# 常用方式
通用的欠拟合解决方案
关于神经网络欠拟合的处理, 在"PyTorch简单分类"这篇博客中有所提及, 解决的方案如下方截图所示.

# 数据增强
主要阐述在 图像分类场景中 如何增加样本量..
除了截图中的方案, 还有一个非常重要的解决方案-增加样本量.. (在图像分类任务中,叫作数据增强)
数据增强就是增加数据量, 数据对于机器学习或者深度学习来说非常重要, 有时候拥有更 多的数据胜过拥有一个好的模型.
一般来说更多的数据参与训练, 训练得到的模型就更好.
若数据太少, 而我们构建的神经网络又太复杂的话就比较容易产生欠拟合的现象.
在图像领域, 数据增加的手段经常被使用, 我们可以通过对图片进行一些调整来生成更多图片. 常用的手段如下:
| 手段 | 解释 |
|---|---|
| 旋转/反射变换(Rotation/reflection) | 随机旋转图像一定角度; 改变图像内容的朝向 |
| 翻转变换(flip) | 沿着水平或者垂直方向翻转图像 |
| 缩放变换(zoom) | 按照一定的比例放大或者缩小图像 |
| 平移变换(shift) | 在图像平面上对图像以一定方式进行平移 |
| 尺度变换(scale) | 对图像按照指定的尺度因子, 进行放大或缩小 |
| 颜色变换(color) | 对训练集图像的颜色进行一些有规律的调整 |
用代码实现:
from PIL import Image
from torchvision import transforms # pip install torchvision 在迁移学习中会常用该模块
import matplotlib.pyplot as plt
img_path = "one.jpg"
img = Image.open(img_path)
# 列表中是该图片进行调整的一系列操作
img_com = transforms.Compose(
[
transforms.RandomRotation(45), # 随机旋转,若设置值为45,则表明随机旋转的角度范围是-45到45度之间
transforms.CenterCrop(224), # 从图像最中心位置进行裁剪,裁剪成224*224大小-通常统一图像大小
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转-若设置值为0.5是,则50%概率水平翻转
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
# 参数1为亮度、参数2为对比度、参数3为饱和度、参数4为色相 也是随机的
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
]
)
img = img_com(img)
img
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 过拟合处理
下面阐述神经网络中最常用的三种处理过拟合的方式.
# Dropout
Dropout 是一种用于抵抗过拟合的技术, 它试图改变网络本身来对网络进行优化
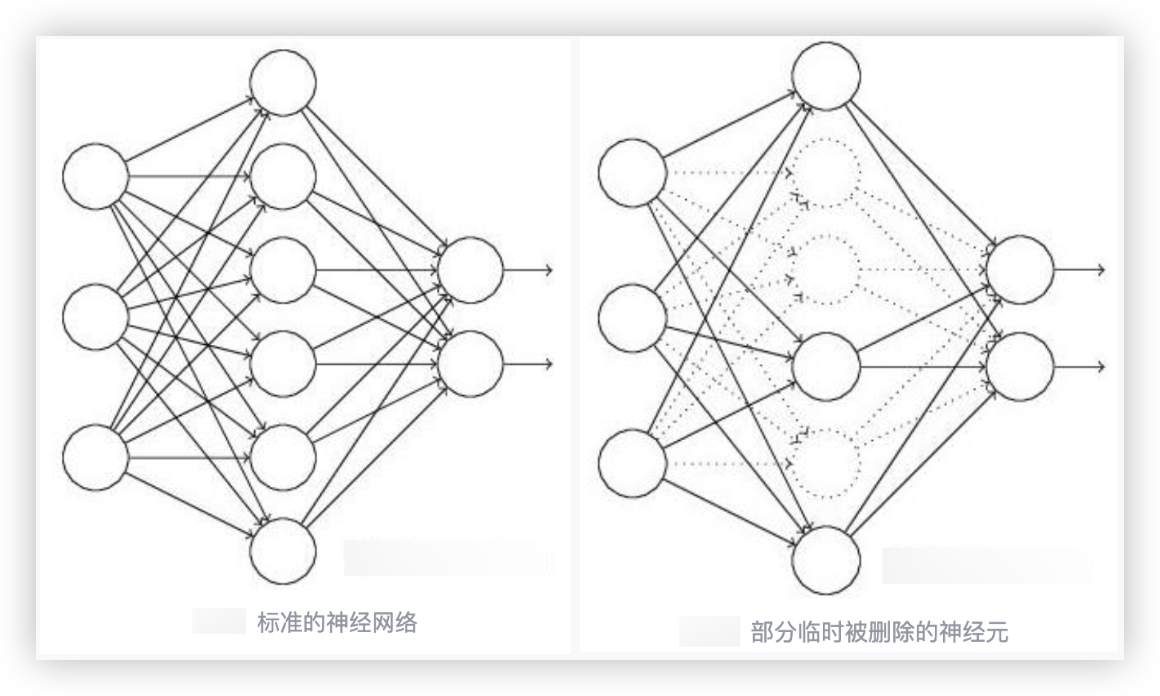
如上图所示, Dropout通常应用于神经网络的隐藏层, 使用的时候会临时关闭掉隐藏层一部分的神经元..
即不会给关闭的神经元传递参数.
Dropout是不能影响输入层(神经元个数取决于样本特征维度)和输出层(神经元个数取决于标签类别数)的.
在代码中的具体实现, 就是在设置模型网络结构时, 我们可以给线性层函数设置Dropout参数.
例如 0.4. 意思该线性层中的隐藏层中的神经元 大约有60%是在工作的, 大约40%神经元是不工作的.
因此, Dropout 比较适合应用于只有少量数据但是需要训练复杂模型的场景, 这类场景在图像领域比较常见.
So, Dropout 经常用于图像领域..
示例,有这样一个四层的网络模型, 输入层+隐藏层+隐藏层+输出层, 对该网络模型使用Dropout.
方式一
# - 创建网络结构,使用Dropout机制
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(784, 128) # 输出层与隐藏层之间的线性层
self.dropout1 = nn.Dropout(p=0.5) # !!添加的代码
self.layer2 = nn.Linear(128, 256) # 隐藏层与隐藏层之间的线性层
self.dropout2 = nn.Dropout(p=0.5) # !!添加的代码
self.layer3 = nn.Linear(256, 10) # 隐藏层与输出层之间的线性层
def forward(self, x):
o1 = torch.relu(self.layer1(x)) # 将x输入到 输出层与隐藏层之间的线性层,对该线性层的输出使用relu激活
o2 = torch.relu(self.layer2(o1))
y = self.layer3(o2)
return y
model = Mnist_NN().to(device)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
方式二
# - 创建网络结构,使用Dropout机制
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(nn.Linear(784,500),
nn.Dropout(p=0.5), # p=0.5表示50%的神经元不工作
nn.relu()) # 定义激活函数
self.layer2 = nn.Sequential(nn.Linear(500, 300),
nn.Dropout(p=0.5),
nn.relu())
self.layer3 = nn.Sequential(nn.Linear(300, 10),
nn.Softmax(dim=1))
# 在前向传播的代码块中,就不用指定激活函数了,因为在__init__中已经指定好了
def forward(self,x):
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x
model = Mnist_NN().to(device)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 提前停止训练(早停法)
我们用大神写好的代码来实现这个功能!! 该代码里大神是用 [损失] 来作为停止迭代的评判标准的.无伤大雅.
核心原理: 在训练模型的时候, 我们往往会设置一个比较大的迭代次数 n.
我们将当前迭代测试准确率 p 与后续m个迭代的结果作对比, 若之后连续 m 个连续迭代周期没有超过该测试集准确率 p,
我们就可以认为 p 不再提高了, 此时便可以提前停止迭代(Early-Stopping).
# pytorchtools.py
大神写好的代码封装在pytorchtools.py里
# pytorchtools.py
import numpy as np
import torch
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}) Saving model ...')
torch.save(model.state_dict(), 'checkpoint.pt') # 这里会存储迄今最优模型的参数
self.val_loss_min = val_loss
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 核心用法
用上一篇博客手写字体识别举例.. 只需改动模型 迭代批次训练测试部分的代码即可.
ps: 下述代码中有◎标注的地方就是新增或改变的代码. 重点关注这些代码!
# 提前停止训练相关变量声明
# 当连续2次训练周期中都没有变得更好(损失都没降低)时,停止模型训练,以防止模型过拟合
# ◎ 以下三行为新增代码
from pytorchtools import EarlyStopping
patience = 2
early_stopping = EarlyStopping(patience, verbose=True)
num_epochs = 10 # 10次迭代
for step in range(num_epochs):
# ■ 训练阶段
model.train()
batch_loss = []
batch_acc = []
for xb,yb in train_dl:
xb = xb.to(device)
yb = yb.to(device)
prediction = model(xb)
loss = criterion(prediction, yb)
loss.backward()
opt.step()
opt.zero_grad()
batch_loss.append(loss.item())
train_acc = accuracy(prediction, yb)
batch_acc.append(train_acc)
# ◎ 这里改变了下,每次迭代都打印
if (step+1) % 1 == 0:
print(f'Epoch [{step+1}/{num_epochs}]')
print(f'Train Loss: {np.mean(batch_loss):.4f}, Train Accuracy: {np.mean(batch_acc):.4f}')
# ■ 测试阶段
model.eval()
batch_loss_test = []
batch_acc_test = []
for xb,yb in test_dl:
xb = xb.to(device)
yb = yb.to(device)
with torch.no_grad():
test_outputs = model(xb)
test_loss = criterion(test_outputs, yb)
batch_loss_test.append(test_loss.item())
test_acc = accuracy(test_outputs, yb)
batch_acc_test.append(test_acc)
# ◎ 这里改变了下,每次迭代都打印
if (step+1) % 1 == 0:
print(f'Epoch [{step+1}/{num_epochs}]')
print(f'Test Loss: {np.mean(batch_loss_test):.4f}, Test Accuracy: {np.mean(batch_acc_test):.4f}')
# ◎ 以下代码为新增代码
# - 提前停止迭代操作
mean_loss_test = np.mean(batch_loss_test)
early_stopping(mean_loss_test, model) # 本质就是调用EarlyStopping类中的__call__方法
# - 若满足 early stopping 要求
if early_stopping.early_stop:
print("Early stopping-------------------------------------")
break
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60

# 正则化
在传统机器学习和神经网络中, 都可通过正则化来解决过拟合的病灶.
正则化也叫作规范化, 通常用得比较多的方式是 L1 正则化和 L2 正则化, 跟传统机器学习中的正则化一样.
- 在pytorch中使用正则化的方式非常简单,只需要在优化器函数中使用weight_decay参数即可
- 该参数的值表示L2正则化的惩罚系数, 一般设置为1、5、10(根据需要设置, 默认为0)
别问为啥, 设置 1、5、10就对了.. - 参数取值范围:
- 正数 - 通常取一个较小的正数, 例如 1e−5, 1e−2 等. 较大的数值会导致学习速率显著下降,从而可能影响模型的训练效果
- 0 - 表示不使用权重衰减
- 负数 - 一般不使用负数, 因为负的权重衰减没有实际意义且可能导致不稳定的训练过程.
- 适用场景
- 过拟合: 当模型在训练集上表现很好但在验证集或测试集上表现较差时, 可能是过拟合现象.
此时引入权重衰减可以帮助减少模型复杂度, 防止过拟合. - 高维数据: 对于高维数据集, 权重衰减可以有效减少参数的数量, 提高模型的泛化能力.
- 深层神经网络: 在深层神经网络中, 权重衰减有助于避免梯度爆炸问题, 并使模型更稳定.
- 小数据集: 当数据集较小时, 模型容易过拟合. 引入权重衰减可以帮助提升模型的泛化能力.
- 过拟合: 当模型在训练集上表现很好但在验证集或测试集上表现较差时, 可能是过拟合现象.
- 该参数的值表示L2正则化的惩罚系数, 一般设置为1、5、10(根据需要设置, 默认为0)
注意: pytorch中的优化函数L2正则化默认对所有网络参数进行惩罚, 且只能实现L2正则化.
如需惩罚指定网络层参数或采用L1正则化, 只能自己定义.
optimizer=optim.SGD(model.parameters(),LR,weight_decay=5) # 优化器 1 5 10 值越小对权重系数惩罚越小
在神经网络结构比较复杂, 训练数 据量比较少的时候, 使用正则化效果会比较好.
如果网络不算太复杂的话, 任务比较简单的时候, 使用正则化可能准确率反而会下降. 像在手写识别中,使用它,准确率会下降..
model.train()、model.train() 没那么简单, 不仅仅是训练测试的标识, 跟过拟合也有关系, 后续的项目会涉及到..