 进程池与线程池
进程池与线程池
# 并发的套接字通信
# 服务端
from socket import *
from threading import Thread
def talk(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0: break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
# -- 省略了粘包问题的解决
def server(ip, port, backlog=5):
s = socket(AF_INET, SOCK_STREAM)
s.bind((ip, port))
s.listen(backlog)
while True:
conn, addr = s.accept()
t = Thread(target=talk, args=(conn,))
t.start()
if __name__ == '__main__':
server('127.0.0.1', 8080)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 客户端
import os
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(("127.0.0.1", 8080))
while True:
msg = "%s say hello" % os.getpid()
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
2
3
4
5
6
7
8
9
10
11
若同时有一万个客户端连接服务端,远远超过了服务端的并发上限,服务端垮了,就没有效率一说了.
而且Python的线程使用的是OS的原生线程.
一来OS要调度这么多线程压力山大;二来线程占用的内存虽然小,但架不住量多.
那如何解决呢? 这就不得不提及进程池与线程池啦!
# 概念!!
异步通常和回调一起使用.
Q: 什么时候用进程池,什么时候用线程池?
A: 这个问题要分解成 两方面 来回答.
1> 什么时候用线程,什么时候用进程 -- 计算型的用多进程,IO密集型的用多线程.
2> 什么时候用池 -- 池的功能是 限制 启动的进程数或线程数.
什么时候限制呢? 当并发的任务数远远超过了计算机的承受能力, 即无法一次性开启过多的进程数或线程数时, 就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内!!
(通常来说,有几个cpu/核开几个进程,开的线程数是cpu/核的5倍)
Q: 同步 vs 异步!! ★
A: 同步与异步指的的是 提交任务的两种方式.
同步: 提交完任务后就在原地等待,直到任务运行完毕后拿到任务的返回值,再继续运行下一行代码!
虽然同步提交任务后,该任务的运行确实是串行的,但是别将同步与串行画上等号,要明确!
同步指的是提交任务的方式,串行指的是运行任务的时候的一种效果!
异步: 提交完任务(绑定一个回调函数)后根本就不在原地等待.直接运行下一行代码! 等到任务有返回值后会 自动 触发回调函数. (任务是否起来不管、是否运行完不管、运行完后也不管, 只管提交 )
谁来执行这个回调函数,进程池和线程池也不大一样,进程池是主进程做,线程池是谁闲下来谁做!
注意, 异步是提交任务的方式, 而回调是异步拿到结果后处理的方式!
回顾下程序的运行状态.(阻塞、非阻塞)
阻塞: IO阻塞
非阻塞: 运行 或 就绪.
# 进程池
# 异步提交
pool.submit(task, i)
import os
import time
# -- concurrent.futures模块提供了高度封装的异步调用接口
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid()) # -- 标识进程池里的哪个进程在执行任务
time.sleep(n)
return n ** 2
if __name__ == '__main__':
# -- 参数max_workers:提交的最大任务数,不写默认赋值None
# 若值为None,创建的进程数跟机器的cpu的核数一样!
# 执行完该语句后,现目前有5个进程,主进程+池子里的4个进程
pool = ProcessPoolExecutor(4) # -- 造池
# -- 往进程池里<异步>提交了10个任务,进程池里的4个进程需要哼哧哼哧的干完这10个活
# 异步提交的,10个活会快速的提交到进程池里.
# 进程池的4个进程先一人领一个活干,干完后再领一个活干,直到10个活全部干完
# 从始至终就进程池里的4个进程在干活,不会再启动其它的进程,牢牢的将子进程数控制在4个
for i in range(1, 11):
# -- 参数: 指定任务函数、给指定的任务函数传参
pool.submit(task, i) # -- 该行代码只管提交,提交后就啥也不管啦,不会原地等待
print("主")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
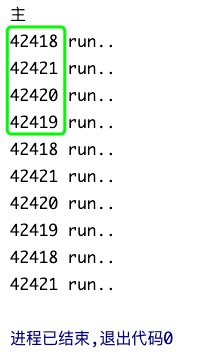
Ps: 注意,运行结果中看起来四个进程是依次循环做任务,是因为10个任务的运行时间依次递增导致的.. 我没有 random.randint() 设置随机时间.
# 初探异步结果
# future.result()
这种要结果的方式是不正确的!!
import os
import time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid())
time.sleep(n)
return n ** 2
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(1, 11):
# -- 异步提交的,不能立马拿到返回结果. So,此处的future拿到的只是一个对象
future = pool.submit(task, i)
# -- 调用future对象的result方法,就是在向该对象要结果
# 没有就会一直等着/阻塞着,直到拿到结果后,再进行下一次循环
print(future.result())
print("主")
"""
42565 run..
1
42567 run..
4
42568 run..
9
42566 run..
16
42565 run..
25
42567 run..
36
... ... ...
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
可以看到任务的运行结果已经变成串行了..
So,虽说任务是异步提交的,但循环里的 future.result() 语句 导致 干活过程跟同步提交的干活过程是一样.
不应该这样做! 这样做还不如用主进程 依次 干完这10个活/调用这10个函数.
# pool.shutdown()
那怎么搞呢? 等所有的任务运行完,统一的拿结果?
该程序加了个任务结果处理的函数.
import os
import time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid())
time.sleep(n) # -- 固定每个任务的处理时间为5s
return n ** 2
def parse(res):
time.sleep(1) # -- 每个任务的处理时间都为1s
print(res)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
future_list = []
for i in range(1, 11):
future_list.append(pool.submit(task, i))
start = time.time()
# -- 参数wait的默认值就为True!
# -- 该语句做了两件事: "相当于pool.close()+pool.join()"
# 1> shutdown代表关闭进程池的入口,即不能再往进程池里提交任务
# 2> wait=True 原地等待池内所有任务执行完毕回收完资源后才继续
# So,`print("主")`肯定是在进程池运行完后再执行的!
pool.shutdown(wait=True) # -- 此行代码执行完,意味这10个任务全部执行完啦!
task_over = time.time()
print("完成任务花费(s):", task_over - start)
for future in future_list:
print(future.result()) # -- 会瞬间得到10个任务的运行结果!
print("处理结果花费(s):", time.time() - task_over)
print("主")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
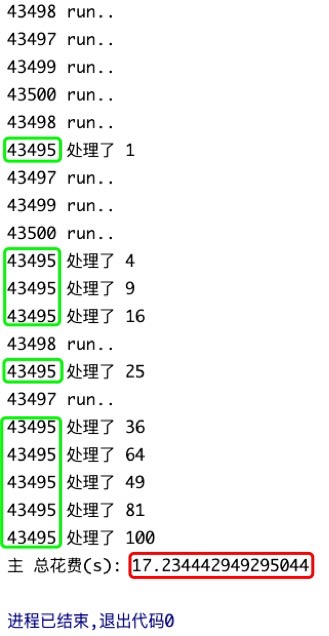
结果分析:
可以从下面的运行结果中看到, 每个任务都需要10秒, 计算机有4个核, 刚好是我们设置的进程池数, 4个核 并行 处理任务, 完成任务花费了15秒, 10/4=2.5 要运行3个5秒.. 每个任务处理结果需花费1s,花费了10s..
这样的话, 一共花费了15+10=25s.
当然可以 再启用4个进程并行的对任务结果进行处理! 这样处理任务的结果会从10s减为3s..
这一通操作下来,该程序共计运行18s, 一共用了9个进程(包括了主进程).

# 强耦合
不返回 n**2 啦,直接完成任务时把任务的结果一并进行处理, 将生产任务和处理任务糅合到一个进程里.
有结果后立马处理结果, 程序花费时间同样是18s..
看起来这样做会更好,因为只会用到4个进程,而不是8个..(没有算主进程 节省了4个并行处理任务结果的进程)
import os
import time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid())
time.sleep(5)
parse(n ** 2)
def parse(res):
time.sleep(1)
print("%s 处理了 %s" % (os.getpid(), res))
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
start = time.time()
for i in range(1, 11):
pool.submit(task, i)
pool.shutdown(wait=True)
print("主 总花费(s):", time.time() - start) # 主 总花费(s): 18.28273892402649
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们的程序需要在有结果的时候立马处理结果,但不应该将生产任务跟处理任务强耦合在一起!! 将所有的需求放到同一个进程里不合理!
# 回调机制
最合理的是什么时候拿结果? 某个任务一旦运行完,就立马拿到结果去处理它.这样处理最及时!
回调机制 -- 提交一个任务就为该任务绑定一个回调函数.
注意: 最后是<提交者- 主进程 >调用parse()回调函数处理的数据!弊端: 若该程序是IO密集型的,用进程池效率不高..
import os
import time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid())
time.sleep(5)
return n ** 2
def parse(future):
time.sleep(1)
print("%s 处理了 %s" % (os.getpid(), future.result()))
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
start = time.time()
for i in range(1, 11):
future = pool.submit(task, i)
# -- submit提交完任务后,直接为future对象绑定一个回调函数parse
# 该回调函数parse会在future对象有结果时立马触发!!
# 并且会将future当作参数传给parse!!
# 该回调函数谁来运行呢?由提交者-"主进程"回过头来调用!
future.add_done_callback(parse)
pool.shutdown(wait=True) # -- 保证所有任务都已经处理完
print("主 总花费(s):", time.time() - start)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 线程池
# IO密集型
每个任务花费5s时间执行完,每个任务的结果处理需要1s. 一共有4个任务. (这里的4个任务是IO密集型)
1> 若是进程池(主进程造了4个进程), 需要5+4=9s!!
4个进程 并行 执行4个任务需要5s; 4个回调函数主进程 “串行” 执行需要4s.
注意,这里是凑齐四个任务是同时执行完, 特别注意!! 实际上,有任务执行完, 主线程就会去运行它的回调函数!! 也就是说子进程执行任务的时候, 主进程会执行已完成任务的回调函数.. 只有当四个任务是同时执行完的,主进程这时执行回调函数存在效率问题,可以考虑再开4个进程来解决. 绝大多数情况4个任务是不会同时执行完的..
import os
import time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print("%s run.." % os.getpid())
time.sleep(5)
return n ** 2
def parse(future):
time.sleep(1)
print("%s 处理了 %s" % (os.getpid(), future.result()))
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
start = time.time()
for i in range(1, 5):
# -- 简写: pool.submit(task, i).add_done_callback(parse)
future = pool.submit(task, i)
future.add_done_callback(parse)
pool.shutdown(wait=True)
print("主 总花费(s):", time.time() - start) # 主 总花费(s): 9.408581972122192
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2> 若是线程池(父线程造了4个线程), 需要5+1=6s!!
4个线程 并发 执行4个任务花费了5s, 4个线程会 并发 的执行4个回调函数!
(线程池里谁先闲下来谁就先去执行回调函数)
import os
import time
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
def task(n):
print("%s run.." % current_thread().name)
time.sleep(5)
return n ** 2
def parse(future):
time.sleep(1)
print("%s 处理了 %s" % (current_thread().name, future.result()))
if __name__ == '__main__':
pool = ThreadPoolExecutor(4)
start = time.time()
for i in range(1, 5):
future = pool.submit(task, i)
future.add_done_callback(parse)
pool.shutdown(wait=True)
print("主 总花费(s):", time.time() - start) # 主 总花费(s): 9.408581972122192
"""
ThreadPoolExecutor-0_0 run..
ThreadPoolExecutor-0_1 run..
ThreadPoolExecutor-0_2 run..
ThreadPoolExecutor-0_3 run..
ThreadPoolExecutor-0_0 处理了 1
ThreadPoolExecutor-0_3 处理了 16
ThreadPoolExecutor-0_2 处理了 9
ThreadPoolExecutor-0_1 处理了 4
主 总花费(s): 6.002989053726196
进程已结束,退出代码0
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 计算密集型
我们再来想想, 其它条件不变, 假设4个任务是计算密集型!
1> 若是线程池,虽然4个线程是并发执行4个任务,但同一时间只能用1个CPU.该算的时间一个都落不下来.
执行完任务需要4*5=20s. 处理回调函数需要4s时间. -- 共计24s.
2> 若是进程池,4个进程并发的执行4个任务,只需要5s.
进程池会用主进程“串行”处理回调函数. 花费4s. -- 攻击9s.
Ps: 所以面对计算密集型,进程池和线程池对于回调函数的处理时间可以简单理解是一样的!!