 Serializer
Serializer
!!本篇将阐述序列化类Serializer的使用!!
我们从数据库中查出来的对象是queryset对象或者是模型类的一个实例对象,我们需要将其字典格式的数据序列化提供给前端用.
序列化的过程可以自己写,也可以用序列化类Serializer来实现!! 反序列化的过程同理,也可以借助序列化类实现!
# 基础
# 基本使用(序列化)
Postman Get请求输入地址
http://127.0.0.1:8000/books/获取所有图书
返回结果[{"name":"红楼梦","price":"11","publish":"北京出版社"}]Postman Get请求输入地址
http://127.0.0.1:8000/books/1获取单个图书
返回结果{"name":"红楼梦","price":"11","publish":"北京出版社"}
models.py
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=64)
price = models.IntegerField()
publish = models.CharField(max_length=32)
2
3
4
5
6
7
serializer.py
通常会在app01下新建serializer.py文件! (名自个儿取,通常叫这个名罢了)
Django REST framework中的Serializer使用类来定义, 须继承自rest_framework.serializers.Serializer
# from rest_framework.serializers import Serializer
from rest_framework import serializers
# serializers是一个py文件,Serializer是一个类!
class BookSerializer(serializers.Serializer):
# -- 通过序列化类控制需要序列化的字段
# -- 这里的CharField是drf提供的,跟Django models提供的CharField不是同一个东西!
# Ps:选中CharField command+b 发现跳转到了fields.py文件!!这是因为做了一个代理.(了解)
name = serializers.CharField()
# -- 在models.py中,Book表的price字段用的IntegerField类型
# 这里用CharField接收也是ok的,因为它可以从数据库中取到的数字映射成字符串!即用引号包起来.
price = serializers.CharField()
publish = serializers.CharField()
2
3
4
5
6
7
8
9
10
11
12
13
14
urls.py
from django.urls import path, re_path
from django.contrib import admin
from app01.views import BookView, BookDetailView
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', BookView.as_view()), # -- ★查询所有图书
# -- Django2.x的re_path跟Django1.x的url一样!
# Django1.x的有名分组 re_path(r'^books/(?P<pk>\d+)', BookView.as_view()),
# -- Django2.x使用 path转换器 达到同样的效果!
# 推荐使用转换器,因为有名分组的正则其一难写,其二其它地址也可能匹配成功.
# path转换器默认有五种,str和int用的最多!! <转换器的类型:变量名>
# eg: '/books/1'-> 将数字1传给变量pk,以关键字参数的形式 pk=1 传递给视图函数
path('books/<int:pk>', BookDetailView.as_view()), # -- ★获取单个图书
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book
from .serializer import BookSerializer
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all() # <QuerySet [<Book: Book object (1)>]>
# -- 需要改动的代码!
# l = []
# for book in book_list:
# l.append({'name': book.name, 'price': book.price})
# return Response(l)
# -- 借助序列化类实现序列化!
# (序列化 -- 列表/字典转成json往外给; 反序列化 -- json转成列表/字典往数据库里存!)
# 实际上,完整的序列化的结果应该是json格式的字符串,但这里只是转换成了 列表/字典..
# 虽然不严谨,但我们也称该过程为序列化啦!不必纠结!
# -- BookSerializer类实例化触发的是它父类的父类BaseSerializer的__init__
# 参数instance: 需要序列化的数据
# 1> 'queryset对象/列表嵌套字典/表中的多条记录'
# 2> 或 '单个对象/单个字典/表中的单条记录'.
# 参数many: True--序列化多条,False--序列化单条. (不填默认为False)
ser = BookSerializer(instance=book_list, many=True) # -- 得到一个序列化对象
return Response(ser.data) # -- 完成序列化
class BookDetailView(APIView):
# def get(self, request, pk):
def get(self, request, *args, **kwargs):
book = Book.objects.all().filter(pk=kwargs['pk']).first() # Book object (1)
ser = BookSerializer(instance=book)
return Response(ser.data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 常用字段类
掌握这几个即可,其余的不晓得也没关系!
CharField 、 IntegerField 、DecimalField 、DateTimeField 、DateField
ListField 、DictField
BooleanField Bool类型
NullBooleanField 不为空的Bool,当数据库中存的bool类型的字段设置了null=True时,意味着可以不填
往数据库里取数据进行序列化时,若为空,默认设置为False
CharField
EmailField
RegexField 与正则表达式有关
SlugField
URLField 存url地址的.用CharField不就行了吗?URLField的作用在于反序列化时的对url的验证
UUIDField uuid的格式:5ce0e9a5-5ffa-654b-cee0-1238041fb31a
IPAddressField
IntegerField
FloatField
DecimalField
DateTimeField
DateField
TimeField
DurationField
ChoiceField
MultipleChoiceField
FileField
ImageField
ListField
DictField
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 常用字段类参数
重点: read_only 、write_only
了解: required 、default 、allow_null 、validators 、error_messages
忽略: label 、help_textCharField独有的 -- max_length 、min_length 、allow_blank 、trim_whitespace
IntegerField独有的 -- max_value 、min_value
# 通用的
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于 序列化''输出'' , 反序列化时忽略该字段, 默认False |
| write_only | 表明该字段仅用于 反序列化''输入'' , 序列化时忽略该字段, 默认False |
| required | 表明该字段在 反序列化时必须输入/填 , 否则报错, 默认True |
| default | 反序列化时使用的默认值, 该字段也用不到,我们通常使用的是数据库里的默认值 |
| allow_null | 表明该字段是否允许 传入/前端往里写 None, 默认False 注意: 不传和传空是两码事!! |
| validators | 该字段使用的验证器 (写函数的列表,使用这些函数校验该字段) |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
Ps: label、help_text在前后端分离的模式下几乎用不到,直接忽略.
# 独有的
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_length | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
# 五个接口(序列+反序列)
books/的get、post
books/<int:pk>的get、put、delete
# models.py
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=64)
price = models.IntegerField()
publish = models.CharField(max_length=32)
2
3
4
5
6
7
# urls.py
from django.urls import path
from django.contrib import admin
from app01.views import BookView, BookDetailView
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', BookView.as_view()), # -- 获取所有图书
path('books/<int:pk>', BookDetailView.as_view()), # -- 获取单个图书
]
2
3
4
5
6
7
8
9
10
# serializer.py
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.CharField()
def create(self, validated_data):
# -- validated_data是前端提交过来校验通过的数据
book = Book.objects.create(**validated_data)
return book # -- 一定要返回!若不返回,sre.data是拿不到的,你不晓得新增了谁.
# -- ★sre.data是以返回的这个对象做序列化的!!
def update(self, instance, validated_data):
# -- instance是表中要修改的那条数据!
# validated_data是前端传过来的数据,有些字段可能没有,就用该条记录原来的字段值.
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish = validated_data.get('publish', instance.publish)
instance.save()
return instance # -- 一定要返回!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book
from .serializer import BookSerializer
class BookView(APIView):
# -- ◎ 获得所有图书
def get(self, request):
# -- 序列化
qs = Book.objects.all()
ser = BookSerializer(instance=qs, many=True)
# -- 序列化的结果就是ser.data
return Response(ser.data)
# -- ◎ 新增数据
def post(self, request):
# -- 反序列化
# -- ★ 前端POST请求提交的数据,在body体中无论是什么格式(三种),都会放到request.data中
ser = BookSerializer(data=request.data)
if ser.is_valid(): # -- 校验提交过来的数据是否合法,验证成功返回True,验证错误返回False.
ser.save() # -- ▲ 若是新增,使用save就新增啦!(修改也是)
# 1) request.data接收前端传过来的序列化好的数据
# 2) 后端将其反序列化的结果是ser,并保存到了数据库中
# 3) ser.data将反序列化的结果进行了序列化
return Response({'code': 100, 'msg': '新增成功', 'data': ser.data})
else:
return Response({'code': 999, 'msg': ser.errors})
class BookDetailView(APIView):
# -- ◎ 获得单本图书
def get(self, request, *args, **kwargs):
book = Book.objects.all().filter(pk=kwargs['pk']).first()
# -- 若没有找到 book的值为None,这里应该先判断有没有,有的话再序列化.. 不判断影响也不大.
ser = BookSerializer(instance=book)
return Response(ser.data)
# -- ◎ 修改单本图书的信息
def put(self, request, *args, **kwargs):
book = Book.objects.all().filter(pk=kwargs['pk']).first()
# -- 拿到修改的数据request.data来修改book这个对象!
ser = BookSerializer(instance=book, data=request.data)
if ser.is_valid(): # -- 真正修改之前校验修改的数据是否合法!验证成功返回True,验证错误返回False.
ser.save() # -- ▲ 如果是修改,使用save就修改啦!(新增也是)
return Response({'code': 100, 'msg': '修改成功', 'data': ser.data})
else:
return Response({'code': 999, 'msg': ser.errors})
# -- ◎ 删除单本图书
def delete(self, request, *args, **kwargs):
# -- 返回的res指的是影响的行数
res = Book.objects.filter(pk=kwargs['pk']).delete()
if res:
return Response({'code': 100, 'msg': '删除成功'})
else:
# -- 数据不存在,也是一种变相的删除成功嘛.(´▽`)
return Response({'code': 999, 'msg': '数据不存在'})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# save()的源码分析
若继承的是Serializer类, 如果要保存和修改,一定要在 自定义的序列化器 里重写update和create!!
why? 从源码进行分析!
save()的查找过程 BookSerializer => Serializer => BaseSerializer -- save方法
save()的核心源码如下:
意味着当我们在视图类的请求方法(post、put)里调用ser.save()时;
会先判断自定义序列化类(这里是BookSerializer)实例化时对instance参数进行初始化的值是否为None;
若为None, 会调用BookSerializer里重写的create方法; 若不为None, 会调用BookSerializer里重写的update方法!
validated_data = {**self.validated_data, **kwargs}
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
# -- 断言证明了 重写的update方法必须返回一个对象
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
# -- 断言证明了 重写的create方法必须返回一个对象
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
return self.instance
Q: 若在BookSerializer中不重写update和create方法呢?
A: 根据查找规则,会在BaseSerializer类里找到这两个方法!!源码如下:
这也就证明了BookSerializer中为啥一定要重写这两个方法!!
def create(self, validated_data):
raise NotImplementedError('`create()` must be implemented.')
def update(self, instance, validated_data):
raise NotImplementedError('`update()` must be implemented.')
Ps:这里raise主动抛出异常,涉及到接口、鸭子类型的概念!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 进阶
# 反序列化的验证
操作serializer.py!! -- 给字段设置参数, 会在post、put反序列化时进行验证!!!!
>> (⁎⁍̴̛ᴗ⁍̴̛⁎) ★★★★★★ 只有我自己看得懂的理解.
name1 -- read_only=True, source='name'
name -- write_only=True
无论序列化还是反序列化,先进行自定义序列化类初始化得到序列化对象ser
1) ser.data完成序列化时是包含name1字段,不包含name字段的!
2) 反序列化的过程,会进行校验后,执行save方法,调用重写的两个方法之一,观察validated_data的值可以判断通过校验的字段
也就是说通过校验的字段是包含name字段,不包含name1字段的!!
反序列化保存数据库成功后,会再次ser.data序列化返回前端信息.
从后端的处理逻辑思考问题,前端不过是提交给后端数据或者拿到后端返回的值.
2
3
4
5
6
7
8
9
# 独有的参数
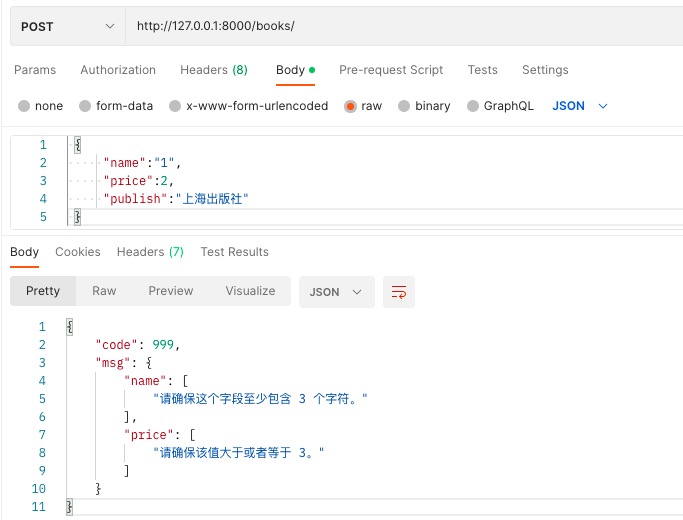
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
publish = serializers.CharField()
def create(self, validated_data):
# -- validated_data是校验通过的数据,在这里name字段read_only,所以是没有的!
print(validated_data) # {'price': 5, 'publish': '上海出版社'}
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish = validated_data.get('publish', instance.publish)
instance.save()
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
为了保证校验不合格时返回的错误信息是中文,需要在settings.py中进行国际化的配置!! 记得注册rest_framework.
若国际化不是很成功,可以添加给字段添加 error_messages 属性!!
name = serializers.CharField(min_length=3, max_length=8, error_messages={'min_length': '不够.'})
"""
-- 国际化!
"""
# LANGUAGE_CODE = 'en-us'
LANGUAGE_CODE = 'zh-hans'
# -- 东八区的时间
# 上海的S要大写,小写的在windows上没问题,在Linux上会报错!
# TIME_ZONE = 'UTC'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
# USE_TZ = True
USE_TZ = False # -- 使用非UTC的时间
"""
若不国际化,前端得到的返回结果是
{
"code": 999,
"msg": {
"name": [
"Ensure this field has at least 3 characters."
],
"price": [
"Ensure this value is greater than or equal to 3."
]
}
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# read_only参数
从后端角度看,仅用于序列化, 反序列化时忽略该字段!!
也就是说get请求,后端查询时是有该字段的; post增加/put修改请求, 后端操作的数据中 没有/忽略 该字段的!!
仅用于序列化,往外走有这个字段!! 往里进的时候,反序列化的数据中是没有该字段的!!
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8, read_only=True)
price = serializers.IntegerField(min_value=3, max_value=30)
publish = serializers.CharField()
def create(self, validated_data):
# -- validated_data是校验通过的数据,在这里name字段read_only,所以是没有的!
print(validated_data) # {'price': 5, 'publish': '上海出版社'}
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish = validated_data.get('publish', instance.publish)
instance.save()
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
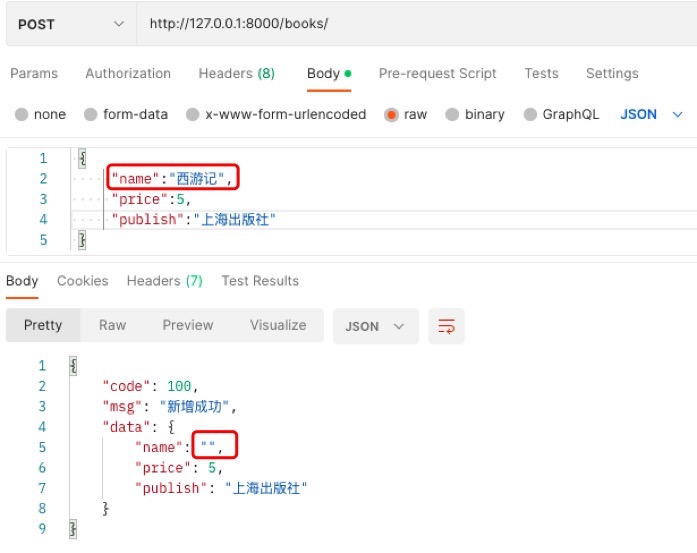
注意! 因为项目里用的sqlite文件数据库,没有那么高的限制, 所以存进去了; 若使用的是mysql数据库,会直接报错,存不进去的, 因为在model.py里给Book表设置name字段时,并没有给该字段添加null=True的属性,Django默认字段的null=False,即该字段不能为空!!
# write_only参数
从后端角度看,仅用于反序列化, 序列化时忽略该字段!!
也就是post增加/put修改请求, 后端操作的数据中是有该字段的; get请求,后端查询时是 没有/忽略 该字段的;
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
# -- 若Book表中没有name1这个字段,可以指定个参数source!
# source='name' 意味着将name1映射成models中Book表的name!
name1 = serializers.CharField(min_length=3, max_length=8, read_only=True, source='name')
price = serializers.IntegerField(min_value=3, max_value=30)
publish = serializers.CharField()
# -- 该字段只用于反序列化!序列化时忽略该字段!
# 这里不能写成name2,然后再指定个source='name'
# 因为重写的create方法里**validated_data会将前端传过来的序列化数据打散,要保证book表中有对应字段!
name = serializers.CharField(write_only=True)
def create(self, validated_data):
print(validated_data)
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish = validated_data.get('publish', instance.publish)
instance.save()
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Ps: 说实话,挺奇怪的.. 直接 name = serializers.CharField(min_length=3, max_length=8) 不好吗?
read_only和write_only的应用场景不是很明确!
先post请求增加一条数据
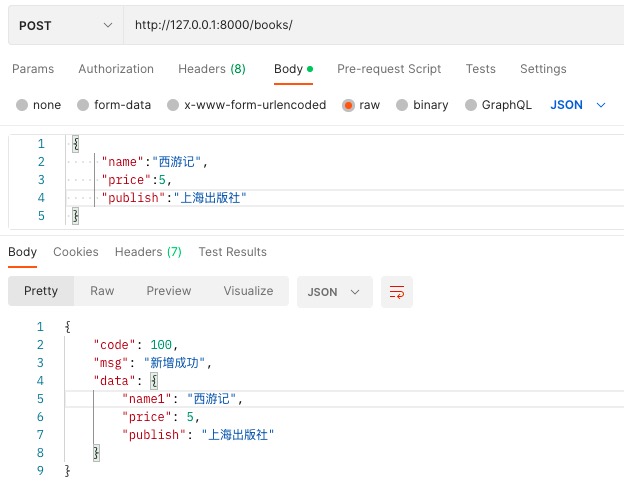
再get请求查找所有数据
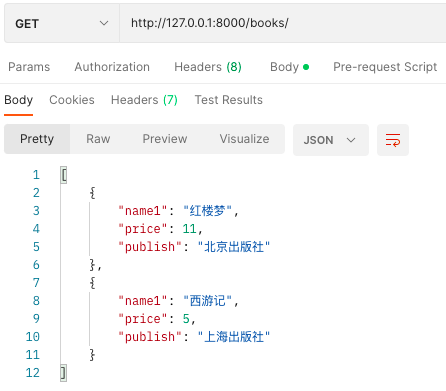
# 高级
# 数据准备
实验准备: 改变下model, 添加个外键关联表 - Publish出版社表! 并添加数据便于实验!
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=64)
price = models.IntegerField()
# -- 默认关联Publish的主键
# -- 1.x上默认on_delete=models.CASCADE级联删除 2.x上需要自己加
# 级联删除 删了某个出版社,该出版社下的书全没了.不合理.暂且这样吧.
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
class Publish(models.Model):
name = models.CharField(max_length=64)
addr = models.CharField(max_length=64)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 序列化时字段格式
我们可以指定 序列化时 , 某个字段展示在前端的格式.
注意: 三种方式的前提都是只用于序列化,相当于加了参数 read_only=True
# 未指定
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
publish = serializers.CharField()
2
3
4
5
6
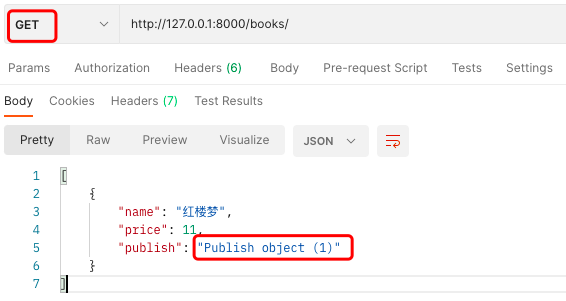
需求:我们需要在前端显示出版社的详情
# 方式一(不常用)
在序列化类中写
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
# publish = serializers.CharField()
# 使用SerializerMethodField !只适用于做序列化!相对于加了参数read_only=True
# 只用于序列化,这个字段名就没啥好讲究的了.
publish_1 = serializers.SerializerMethodField()
# -- 必须配套个方法,方法名固定写法 get_字段名
# 参数obj是要序列化的对象,此处是book对象!
def get_publish_1(self, obj):
# -- 返回出版社的名字
# book对象.publish外键=>跨到了Publish表,再.name取到对应出版社的名字
# return obj.publish.name
# -- 返回出版社的详情
return {'name': obj.publish.name, 'addr': obj.publish.addr}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
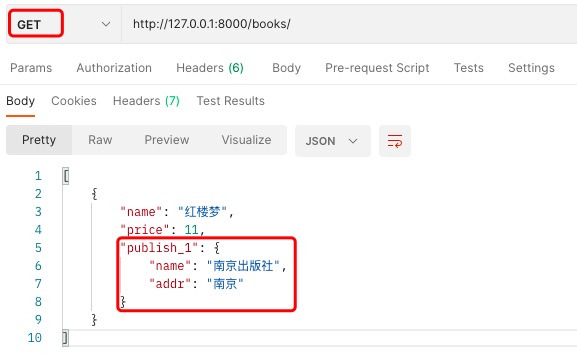
# 方式二(最常用)
在表对应的模型类中写 , 方法返回什么, 这个字段就是什么!!
"""
-- models.py
"""
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=64)
price = models.IntegerField()
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
# @property # -- 是否包装成数据属性都行.可加可不加.
def publish_detail(self):
return {"name": self.publish.name, "addr": self.publish.addr}
class Publish(models.Model):
name = models.CharField(max_length=64)
addr = models.CharField(max_length=64)
"""
-- serializer.py
"""
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
# publish = serializers.CharField()
# publish_detail = serializers.CharField()
# -- ★★★ 特别注意!应该使用字段类型DictField
# 若models里模型类的publish_detail方法返回的是列表,那么应该使用ListField!!
# -- 只用于做序列化,相对于加了参数read_only=True
publish_detail = serializers.DictField()
# -- 使用CharField,publish_detail的值是字符串,字符串包裹的是一个字典.
# [
# {
# "name": "红楼梦",
# "price": 11,
# "publish_detail": "{'name': '南京出版社', 'addr': '南京'}"
# }
# ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
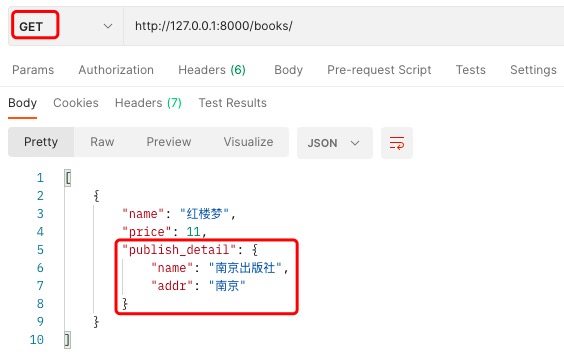
# 方式三(了解)
方式三没法显示出版社详情.
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
# -- 只用于做序列化,相对于加了参数read_only=True
publish_name1 = serializers.CharField(source='publish.name')
2
3
4
5
6
7
8
# Book表的接口实验
五个接口的代码不变,只需改变下BookSerializer类的一些代码!
from rest_framework import serializers
from .models import Book, Publish
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
publish_detail = serializers.DictField(read_only=True) # -- 使用的是方式二
publish_id = serializers.CharField(write_only=True)
def create(self, validated_data):
# print(validated_data)
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
# print(validated_data)
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish_id = validated_data.get('publish_id', instance.publish_id)
instance.save()
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
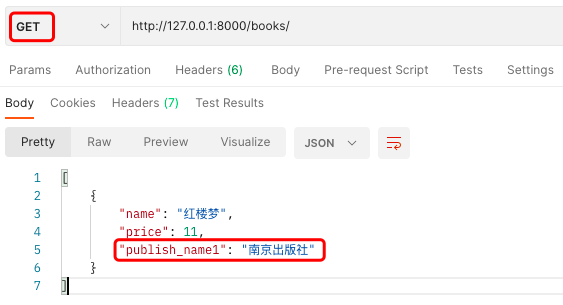
实验过程如下:
1) GET http://127.0.0.1:8000/books/
结果:
[{"name":"红楼梦","price":11,"publish_detail":{"name":"南京出版社","addr":"南京"}}]
2) GET http://127.0.0.1:8000/books/1
结果:
[{"name":"红楼梦","price":11,"publish_detail":{"name":"南京出版社","addr":"南京"}}]
GET http://127.0.0.1:8000/books/2
结果:
{"name":"","price":null,"publish_id":""}
分析:
该路由会调用BookDetailView类的get方法,没有查询到id为2的图书,实例化序列器类时instance的值为None.
阴差阳错的调用的是BookSerializer类里重写的 update方法!
3) POST http://127.0.0.1:8000/books/
传递给后端的Json数据:{"name":"西游记","price":5,"publish_id":1}
Ps: 得是publish_id,不然报错Cannot assign "'1'": "Book.publish" must be a "Publish" instance.
因为models模型里使用了ForeignKey.
若使用的是ModelSerializer类,写publish就行!!
结果:
{"code":100,"msg":"新增成功",
"data":{"name":"西游记","price":5,"publish_detail":{"name":"南京出版社","addr":"南京"}}}
4) PUT http://127.0.0.1:8000/books/2
传递给后端的Json数据:
{"name":"西游记","price":5,"publish_id":1}
结果:
{
"code": 100,
"msg": "修改成功",
"data": {
"name": "西游记",
"price": 20,
"publish_detail": {
"name": "南京出版社",
"addr": "南京"
}
}
}
补充说明:
若要修改的图书id查询结果为None,和前面`GET http://127.0.0.1:8000/books/2`同理.
阴差阳错的调用的是BookSerializer类里重写的update方法!相当于新增了一条数据.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 其它
像什么序列化类的局部钩子(通过validate_字段名进行字段的验证)、全局钩子等. 在 ModelSerializer类中讲解.
因为序列化类ModelSerializer继承了序列化类Serializer!! Serializer有的ModelSerializer都有!!