 解析器
解析器
class HomeView(APIView):
# drf配置文件默认就是这样的,So,这两行代码其实不写也可以.
parser_classes = [JSONParser, FormParser, MultiPartParser] # 解析器!!
content_negotiation_class = DefaultContentNegotiation # 根据请求头匹配对应的解析器!!
通过DefaultContentNegotiation类的select_parser方法,将请求头匹配的 解析器 筛选出来
然后解析器使用parse方法解析body里的数据.
★★★ 对应编码格式
JSONParser类 -- media_type = 'application/json'
FormParser类 -- media_type = 'application/x-www-form-urlencoded'
MultiPartParser类 -- media_type = 'multipart/form-data'
FileUploadParser类 -- media_type = '*/*'
★★★ 对应的应用场景
JSONParser -- 请求体里是json数据;
FormParser -- 请求体里是用&符号作为分隔符组织多组k-v数据 / 只上传普通数据.
MultiPartParser -- 请求体里既有普通数据(b'v1=123&v2=234')又有文件数据 / 既上传文件又上传普通数据.
FileUploadParser -- 请求体里只有文件数据; / 只上传文件数据.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
drf中可以使用 request.data 获取请求体中的数据(三种编码格式的数据都可以通过它取到). Django中是没有request.data的.
这个 reqeust.data 的数据怎么来的呢? 其实在drf内部是由解析器, 根据请求者传入的数据格式 + 请求头来进行处理得到的!
# Django知识回顾
# 请求体编码格式
json、urlencoded、formdata
Django的前后端交互的三种编码方式. 看源码就更加明白咋回事了!!
从wsgi.py开始,一步步往下分析,重点是WSGIRequest类!它的实例化对象就是Django中的request!!
往后关键在于_load_post_and_files方法!!里面的那个if-elif-else!
而drf对数据的解析自己重新写了,相比下,还多了对json格式数据的支持!!
http://127.0.0.1:8000/api/home/?xx=123&xx=321&yy=234
- 不管是GET请求还是POST请求:
- url中的参数通过 request.GET 取到. --> <QueryDict: {'xx': ['123', '321'],'yy':['234']}>
- 请求头中的参数通过 request.headers 取到.
--> {'Content-Length': '', 'Content-Type': 'text/plain', 'Host': '127.0.0.1:8000', ...}
- POST的请求方式才会有请求体,GET请求是没有请求体的!!
Post请求携带的Body请求体里提交到后端的数据, 对其常用的<编码格式>有3种! / 前后端交互的三种编码格式.
★ 即前端的POST请求以 什么样子/什么编码格式 组织数据并将其放到请求体中提交到后端!
- request.body 能够拿到请求体中的原始数据,只要有人给你发请求体的数据,一定在request.body里放着呢,没有?那就是没发过来!!
- <编码格式由请求体中的Content-Type参数指定>
1 json>
前端提交到后端 Json格式数据 {"name":"wupeiqi","age":19}
请求头 Content-Type:application/json
请求体 request.body --> b'{"name":"wupeiqi","age":19}'
- ★ 注意!POST请求提交到Django后端的json格式的数据,Django通过request.POST是接受不到的!!!
Django的request.POST只能取出urlencoded编码格式的数据!
2 urlencoded(默认)>
应用场景1> 前端提交到后端 form登陆表单中的数据,通过点击submit按钮提交.
应用场景2> ajax提交默认格式.
请求头 Content-Type:application/x-www-form-urlencoded
请求体 request.body --> b'phone=17380765456&password=admin123' (若有汉字会对汉字进行编码.)
(会用&符号作为分隔符组织多组k-v数据放到请求体中,提交到后端)
- Django内部会将 b'phone=17380765456&password=admin123' 自动进行切割,封装解析成一个字典
我们可以通过request.POST获取到这个字典
--> <QueryDict: {'phone': ['17380765456'], 'password': ['admin123']}>
3 formdata >
前端提交到后端 普通数据+文件 (So,既可以传文件,又可以传普通数据)
请求头 Content-Type:multipart/form-data
请求体 request.body -->
普通数据部分 b"name=egon&age=18" + 文件部分 "先以--flakjfalk--作为分割,然后是文件的二进制数据"
有分割后,就能清楚的知道从哪开始读文件.
- Django如何读取数据? 普通数据部分 request.POST; 文件部分 request.FILES
Ps:form表单元素在使用包含文件上传的表单控件时,必须给表单元素的enctype属性设置该值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 请求头
在ajax中发送的请求头,假如是如下的数据:
headers: {
'X-CSRFTOKEN': getCookie('csrftoken'),
'xxx-123': 9999,
},
在视图函数中,需要添加"HTTP_"的前缀来获取自定义的请求头! 并且在前端的 `-` 会在后端转化成 `_`
request.META.get("HTTP_X_CSRFTOKEN")
request.META.get("HTTP_XXX_123")
★ 花了一点时间,弄清楚了 request.META 和request.headers的区别..
他们都是字典,前者包含了请求中所有请求头的信息;后者包含了以HTTP_ 为前缀的请求头的信息 + 'Content-Length' + 'Content-Type'.. (在视图函数中打印,request.META和request.headers的值可以验证)
对于自定义的请求头,做了个实验,使用postman发送get请求,在请求中加入请求头 xxx-123 = waowao ;
那么在视图中 通过request.META.get("HTTP_XXX_123") 和 request.headers.get("xxx_123") 都能取到.
2
3
4
5
6
7
8
9
10
11
12
13
# 简单使用
什么时候使用什么解析器呢?
JSONParser -- 请求体里是json数据;
FormParser -- 请求体里是用&符号作为分隔符组织多组k-v数据 / 只上传普通数据.
MultiPartParser -- 请求体里既有普通数据(b'v1=123&v2=234')又有文件数据 / 既上传文件又上传普通数据.
FileUploadParser -- 请求体里只有文件数据; / 只上传文件数据.建议: 该视图会用到哪个解析器就只写那个解析器..便于更好的判断.
当前, parser_classes和content_negotiation_class都可以进行全局配置.. 是否全局配置看情况而定吧.
# drf默认配置
在drf的配置文件里:
DEFAULTS = {
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser', # media_type = 'application/json'
'rest_framework.parsers.FormParser', # media_type = 'application/x-www-form-urlencoded'
'rest_framework.parsers.MultiPartParser' # media_type = 'multipart/form-data'
# ps: FileUploadParser -- media_type = '*/*'
],
'DEFAULT_CONTENT_NEGOTIATION_CLASS': 'rest_framework.negotiation.DefaultContentNegotiation',
}
# 补充:默认的解析器还可以在视图函数中通过 self.parser_classes 打印出来.
"""
[
<class 'rest_framework.parsers.JSONParser'>,
<class 'rest_framework.parsers.FormParser'>,
<class 'rest_framework.parsers.MultiPartParser'>
]
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Json和表单
JSONParser, FormParser, MultiPartParser
url.py 根路由
from django.urls import path
from api import views
urlpatterns = [
path('api/home/', views.HomeView.as_view()),
]
2
3
4
5
6
api/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.parsers import JSONParser, FormParser, MultiPartParser
from rest_framework.negotiation import DefaultContentNegotiation
class HomeView(APIView):
# drf配置文件默认就是这样的,So,这两行代码其实不写也可以.
parser_classes = [JSONParser, FormParser, MultiPartParser] # 解析器!!
content_negotiation_class = DefaultContentNegotiation # 根据请求头匹配对应的解析器!!
# Ps:content_negotiation_class还有个功能,寻找渲染器,了解即可,不重要.
# http://127.0.0.1:8001/api/home/ 和 http://127.0.0.1:8001/api/home/?format=json
def post(self, request, *args, **kwargs):
print(request.content_type) # 等同于request.META.get('CONTENT_TYPE', '')
print(request.body)
print(request.data, type(request.data))
return Response('ok')
"""
- 若通过PostMan,POST请求,向http://127.0.0.1:8001/api/home/ 发送Json格式的数据
打印结果
application/json
b'{"name": "\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90", "age": 20}'
{'name': '武沛齐', 'age': 20} <class 'dict'>
- 若通过PostMan,POST请求,向http://127.0.0.1:8001/api/home/ 发送表单格式的数据
"表单中只包括普通数据"
打印结果
application/x-www-form-urlencoded
b'name=%E5%90%B4%E6%B2%9B%E9%BD%90&age=20'
<QueryDict: {'name': ['武沛齐'], 'age': ['20']}> <class 'django.http.request.QueryDict'>
- 若通过PostMan,POST请求,向http://127.0.0.1:8001/api/home/ 发送表单格式的数据
"表单中包括普通数据和文件数据"
打印结果
multipart/form-data; boundary=--------------------------801261790305533003359691
b'----------------------------710861461266211277324559\r\nContent-Disposition: form-data;
name="name"\r\n\r\n\xe5\x90\xb4\xe6\xb2\x9b\xe9\xbd\x90\r\n---------------------------
-710861461266211277324559\r\nContent-Disposition: form-data; name="img";
filename="2321bd5a395d4d7ba2991869c5790950.jpg"\r\nContent-Type:
image/jpeg\r\n\r\n\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xfe\x00;
CREATOR: gd-jpeg v1.0 (using IJG JPEG v80), quality = 90\n\xff\xdb\x00C\x00\x03\...'
<QueryDict: {
'name': ['武沛齐'],
'img': [<InMemoryUploadedFile: 2321bd5a395d4d7ba2991869c5790950.jpg (image/jpeg)>]}
>
<class 'django.http.request.QueryDict'>
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
补充, 若不通过postman模拟前端发送请求. 前端代码这样写:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://127.0.0.1:8000/test/" method="post" enctype="multipart/form-data">
<input type="text" name="name" />
<input type="file" name="img">
<input type="submit" value="提交">
</form>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# FileUploadParser
专门用于上传文件的.
应用场景: 用户只上传一个头像. 就可以专门为其写一个接口.
Django REST framework 提供了 parsers.FileUploadParser 类, 可以用来处理原始格式的文件内容的上传.
后端获取到的 request.data 为字典结构, 其中包含的 'file' 键对应的值即为上传的文件对象!!
若 FileUploadParser 类被包含 filename 参数的 Django路由 调用, 则该参数会作为文件保存到服务端后的文件名.
如 path('api/home/<str:filename>/', views.HomeView.as_view()),
若 Django路由 中不包含 filename 参数, 则客户端发起的请求必须包含 Content-Disposition 请求头及 filename 参数.
如 Content-Disposition: attachment; filename=upload.jpg
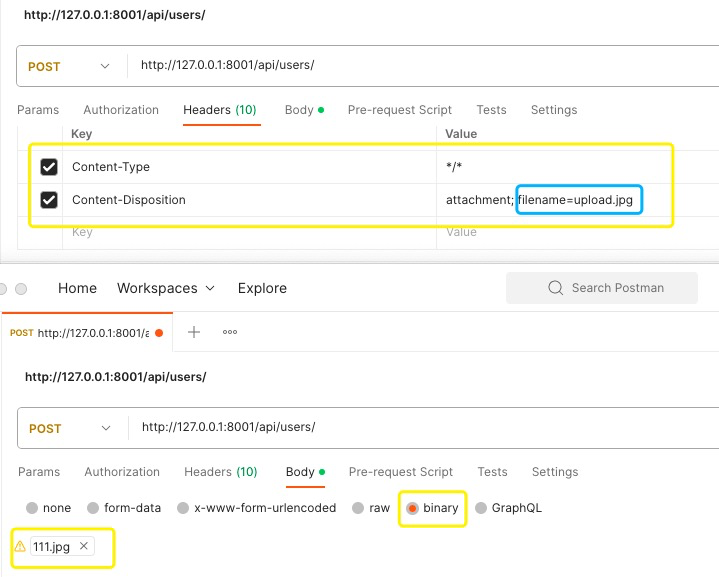
Ps: 选择 binary 表明直接上传图片的二进制数据!!
★ 敲黑板!! 二进制上传的话,需指明解析器是FileUploadParser!! parser_classes = [FileUploadParser, ]
因为默认drf配置文件里只写了JSONParser, FormParser, MultiPartParser
若你不指明它, 你可以通过form-data表单形式进行上传, 注意键名为 file, 值是上传的图片(也是二进制数据).
url.py 根路由
from django.urls import path
from api import views
urlpatterns = [
path('api/home/<str:filename>/', views.HomeView.as_view()),
]
2
3
4
5
6
api/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.parsers import FileUploadParser
from rest_framework.negotiation import DefaultContentNegotiation
class HomeView(APIView):
parser_classes = [FileUploadParser, ]
content_negotiation_class = DefaultContentNegotiation
def post(self, request, *args, **kwargs):
print(request.content_type) # */*
print(request.data) # {'file': <InMemoryUploadedFile: upload.jpg (*/*)>}
# 后端获取到的 request.data 为字典结构, 其中包含的 'file' 键对应的值即为上传的文件对象!!
file_object = request.data.get("file")
filename = file_object.name
print(filename) # upload.jpg
# -- 打开上传的文件,读取后写入到本地. [<可以看到上传完毕后,项目的根目录下多了文件 upload.jpg>]
with open(filename, 'wb') as f:
for chunk in file_object:
f.write(chunk)
f.close()
return Response("ok")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
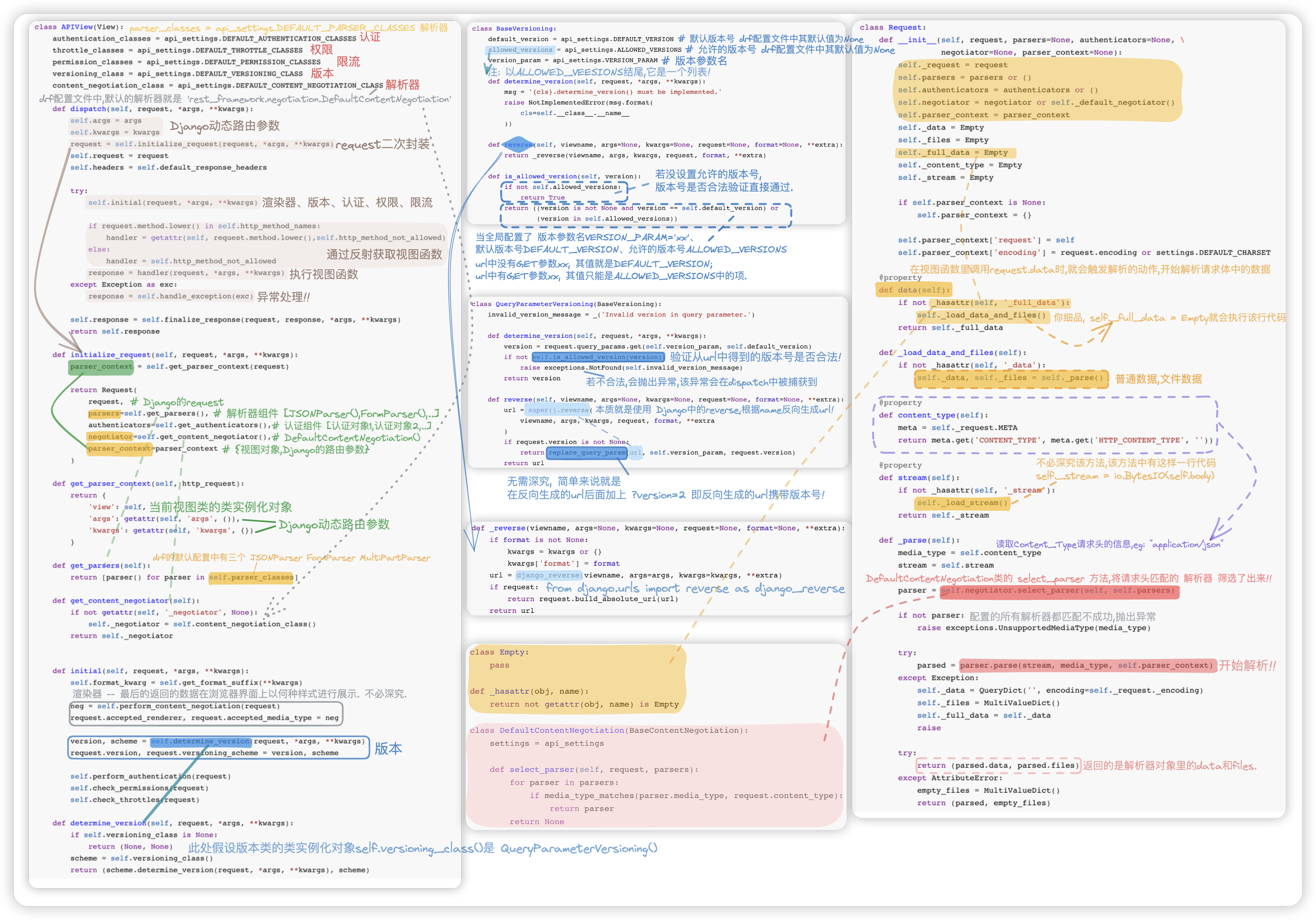
# 源码分析
解析器: 解析请求者发过来的数据(一般是JSON数据) -- 主要针对POST请求
因为很多数据会嵌套很多层,表单数据满足不了该复杂的数据结构,So,前后端分离一般都是Json数据! 执行request.data时,会根据 Content-Type/编码格式 解析数据
1> 根据 Content-Type/编码格式 获取解析器class Form解析器: content-type = "application/x-www-form-urlencoded" def parse(self):pass # 具体的解析动作 class Json解析器: content-type = "application/json" def parse(self):pass # 具体的解析动作1
2
3
4
5
6
72> 执行相应解析器的parse方法
1> 请求来了,会调用disptch方法, 该函数体内依次 initialize_request、initial, 最后反射执行视图函数..
在这个过程中, 就解析器而言.. 只是获取了解析器组件authenticators和字典parser_context, 并将其封装进了Request里面.
2> 当我们在视图函数里调用request.data时, 才会触发解析的动作, 开始解析请求体中的数据!!
# -- 自己项目中的视图类
class HomeView(APIView):
parser_classes = [JSONParser, FormParser] # 解析器
content_negotiation_class = DefaultContentNegotiation # 根据请求头匹配对应的解析器
def post(self, request, *args, **kwargs):
self.dispatch
print(request.data, type(request.data))
return Response('ok')
# -- rest_framework/views.py
class APIView(View):
parser_classes = api_settings.DEFAULT_PARSER_CLASSES
content_negotiation_class = api_settings.DEFAULT_CONTENT_NEGOTIATION_CLASS
def dispatch(self, request, *args, **kwargs): # *args, **kwargs Django路由中的参数
self.args = args
self.kwargs = kwargs
request = self.initialize_request(request, *args, **kwargs) # 封装请求
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
self.initial(request, *args, **kwargs)
# 通过反射获取视图函数
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
# 执行视图函数
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
def initialize_request(self, request, *args, **kwargs):
parser_context = self.get_parser_context(request) # {视图对象,Django的路由参数}
"""
条件反射,类实例化看有无做特殊的操作.
JSONParser(),FormParser(),DefaultContentNegotiation()都是单纯的创建一个对象,当前类及其父类里都没有__init__.
"""
return Request(
request, # Django的request
parsers=self.get_parsers(), # 解析器组件 [JSONParser(),FormParser(),..]
authenticators=self.get_authenticators(), # 认证组件 [认证对象1,认证对象2,..]
# 后续会通过DefaultContentNegotiation类的select_parser方法,将请求头匹配的 解析器 筛选出来
negotiator=self.get_content_negotiator(), # DefaultContentNegotiation()
parser_context=parser_context # {视图对象,Django的路由参数args,Django的路由参数kwargs}
)
def get_parser_context(self, http_request):
return {
'view': self, # 当前视图类的类实例化对象
# 回看disptch函数,在执行initialize_request之前,将Django路由中的参数封装到了self.args和self.kwargs中!
# So,当前视图类的类实例化对象中是有args和kwargs这两个成员的!
'args': getattr(self, 'args', ()),
'kwargs': getattr(self, 'kwargs', {})
}
def get_parsers(self):
return [parser() for parser in self.parser_classes]
def get_content_negotiator(self):
if not getattr(self, '_negotiator', None):
self._negotiator = self.content_negotiation_class() # DefaultContentNegotiation()
return self._negotiator
def initial(self, request, *args, **kwargs):
self.format_kwarg = self.get_format_suffix(**kwargs)
# 渲染器 -- 最后的返回的数据在浏览器界面上以何种样式进行展示.
# 它跟请求数据的处理无关,不做过多的分析.略.
neg = self.perform_content_negotiation(request)
request.accepted_renderer, request.accepted_media_type = neg
# 版本
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
self.perform_authentication(request) # 认证
self.check_permissions(request) # 权限
self.check_throttles(request) # 限流
# -- rest_framework/request.py
class Empty:
"""
Placeholder for unset attributes. 未设置属性的占位符.
Cannot use `None`, as that may be a valid value. 不能使用'None',因为这可能是一个有效值.
"""
pass
def _hasattr(obj, name):
return not getattr(obj, name) is Empty
class Request:
def __init__(self, request, parsers=None, authenticators=None, negotiator=None, parser_context=None):
assert isinstance(request, HttpRequest), (
'The `request` argument must be an instance of `django.http.HttpRequest`, not `{}.{}`.'
.format(request.__class__.__module__, request.__class__.__name__)
)
self._request = request #
self.parsers = parsers or () #
self.authenticators = authenticators or () #
self.negotiator = negotiator or self._default_negotiator() #
self.parser_context = parser_context #
self._data = Empty
self._files = Empty
self._full_data = Empty # !!注意这里,这可以解释 request.data方法中的 _hasattr(self, '_full_data')
self._content_type = Empty
self._stream = Empty
if self.parser_context is None:
self.parser_context = {}
# 注意!! drf的request对象的parser_context成员,经过下面两行代码多添加了一点东西.
# --> {视图对象,Django的路由参数args,路由参数kwargs,drf的request,encoding编码}
self.parser_context['request'] = self
# 从Django的request中取到当前请求对应的encoding编码
self.parser_context['encoding'] = request.encoding or settings.DEFAULT_CHARSET
force_user = getattr(request, '_force_auth_user', None)
force_token = getattr(request, '_force_auth_token', None)
if force_user is not None or force_token is not None:
forced_auth = ForcedAuthentication(force_user, force_token)
self.authenticators = (forced_auth,)
@property
def data(self):
"""
So,在视图函数内,多次执行request.data 解析只会进行一次!!
"""
# 这里为何不直接,hasattr(self, '_full_data')?
# 因为在Request类的__init__里定义了 self._full_data = Empty
# 之所以不设置 self._full_data = None Empty类里也说了,None可能是个有效值!!
if not _hasattr(self, '_full_data'):
# 你看看上方粘贴的_hasattr方法的源码,结合分析下来,逻辑就是,self._full_data = Empty就会执行该行代码!!
self._load_data_and_files()
return self._full_data
"""
其实不细细分析,粗眼一看
将if not _hasattr(self, '_full_data')简单理解成self中没有_full_data成员条件就成立
这样的分析对整体逻辑是没有影响的!! 代码即文档.
"""
def _load_data_and_files(self):
if not _hasattr(self, '_data'):
self._data, self._files = self._parse() # _parse方法 返回 普通数据,文件数据
# 有无上传文件的判断.
if self._files:
self._full_data = self._data.copy()
self._full_data.update(self._files)
else:
self._full_data = self._data
if is_form_media_type(self.content_type):
self._request._post = self.POST
self._request._files = self.FILES
@property
def content_type(self):
meta = self._request.META
return meta.get('CONTENT_TYPE', meta.get('HTTP_CONTENT_TYPE', ''))
@property
def stream(self):
if not _hasattr(self, '_stream'):
self._load_stream() # 不深入分析该方法啦,该方法中有这样一行代码 self._stream = io.BytesIO(self.body)
return self._stream
def _parse(self):
media_type = self.content_type # 读取Content_Type请求头的信息,eg: "application/json"
stream = self.stream # 将这行代码简化提取了出来.
"""
try:
stream = self.stream # 二进制数据,请求发过来的原始数据
except RawPostDataException: # - 异常处理暂且不看.
if not hasattr(self._request, '_post'):
raise
if self._supports_form_parsing():
return (self._request.POST, self._request.FILES)
stream = None
if stream is None or media_type is None: # - 我们默认stram是有数据的,这段代码也暂且不看.
if media_type and is_form_media_type(media_type):
empty_data = QueryDict('', encoding=self._request._encoding)
else:
empty_data = {}
empty_files = MultiValueDict()
return (empty_data, empty_files)
"""
# DefaultContentNegotiation().select_parser(drf的request对象, [JSONParser(),FormParser(),..])
# 简单来说,干了个啥事?!
# JSONParser类里写了 media_type = 'application/json'
# FormParser类里写了 media_type = 'application/x-www-form-urlencoded'
# DefaultContentNegotiation类的 select_parser 方法,将请求头匹配的 解析器 筛选了出来!!
"""select_parser 方法的源码如下.
class DefaultContentNegotiation(BaseContentNegotiation):
settings = api_settings
def select_parser(self, request, parsers):
for parser in parsers:
if media_type_matches(parser.media_type, request.content_type):
return parser
return None
"""
# 同时使用多个parser时, rest framework会根据请求头content-type自动进行比对, 并使用对应parser
# 若self.content_type的值为"application/json",那么此处的parser就是 JSONParser()
parser = self.negotiator.select_parser(self, self.parsers) # 获取Content_Type请求头相应的解析器!
if not parser: # 若Content_Type请求头相应的解析器匹配不成功,抛出异常.
raise exceptions.UnsupportedMediaType(media_type)
try:
# !!! 因为已经挑选出解析器了,这里开始进行解析!
"""具体的解析源码就不看啦,简单来说:
JSONParser类中的parse方法
--> 底层会将二进制数据封装到内存对象中, json.load(内存对象)即读取内存对象中的数据并反序列化成字典.
Ps: json.loads('{"v1":123,"v2":234}') json.load(文件对象)
FormParser类中的parse方法
--> 用于解析 b'v1=123&v2=234'格式的数据,最终转换成转换成一个QueryDict对象
"""
parsed = parser.parse(stream, media_type, self.parser_context)
except Exception: # 异常处理暂时不用管.
self._data = QueryDict('', encoding=self._request._encoding)
self._files = MultiValueDict()
self._full_data = self._data
raise
try:
return (parsed.data, parsed.files) # 返回的是解析器对象里的data和files.
except AttributeError: # 异常处理暂时不用管.
empty_files = MultiValueDict()
return (parsed, empty_files)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254