 验证&源码
验证&源码
注意, 若数据库设置该字段blank=True,null=True, 那么验证时, 哪怕写了__all__, 该字段也是可以不用传的..
存储结果是空, 序列化出来是 null.
前言
序列化器, 有两部分功能.
1> 将数据库表中的 QuerySet"多条记录" 或 数据对象"单条记录" 序列化成Json格式.
2> 请求数据格式校验 / 对用户发来的请求数据进行校验.
功能一在前面已经详细阐述过了. 接下来, 开始功能二的学习!! (⁎⁍̴̛ᴗ⁍̴̛⁎)
该篇博文只涉及进行 校验+save !!不涉及序列化.
# Serializer
Serializer的get_fields方法会会直接
return copy.deepcopy(self._declared_fields)返回所有字段对象
所以使用Serializer获得的字段对象都来自序列化器列里定义的类变量, 并且此小节的示例中不会使用save..
So, 我们可以大胆的说, 此 "Serializer" 大节中三个小节中的示例均与Django ORM表以及数据库存储的数据无关!!
仅仅是对 前端发送给后端的请求里的请求体数据 进行校验!!
# 基本校验
注意点1> 序列化器类实例化时使用的参数是data, 而不是instance.
注意点2>ser.is_valid()进行验证后.ser.validated_data可得到验证成功的数据;ser.errors可得到验证失败的数据.
url.py 根路由
from django.urls import path
from api import views
urlpatterns = [
path('api/<str:version>/info/', views.InfoView.as_view()),
]
2
3
4
5
6
api/views.py
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
class InfoSerializer(serializers.Serializer):
# 设置字段自身的检验规则required=True 意味着,验证时 - 必填/前端必传.
username = serializers.CharField(required=True)
password = serializers.CharField(required=True)
class InfoView(APIView):
def post(self, request, *args, **kwargs):
print("请求体中数据 >>:", request.data)
ser = InfoSerializer(data=request.data) # ★ 注意:此处序列化器类实例化时使用的参数是data!
if ser.is_valid():
res = ser.validated_data
print("验证成功的数据 >>:", res)
else:
res = ser.errors
print("验证失败的数据 >>:", res)
return Response(res)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
利用PostMan模拟前端发送请求. 进行验证.
验证成功的情况
http://127.0.0.1:8001/api/v1/info/ POST请求 发送Json数据 {"username":"dc","password":123,"xxx":0}
- pycharm控制台打印:
请求体中数据 >>: {'username': 'dc', 'password': 123, 'xxx': 0}
验证成功的数据 >>: OrderedDict([('username', 'dc'), ('password', '123')])
- PostMan显示
{"username": "dc","password": "123"}
Ps:
2
3
4
5
6
7
8
验证失败的情况 "前端没有传password字段对应的数据"
http://127.0.0.1:8001/api/v1/info/ POST请求 发送Json数据 {"username":"dc","password_eee":123,"xxx":0}
- pycharm控制台打印:
请求体中数据 >>: {'username': 'dc', 'password_eee': 123, 'xxx': 0}
验证失败的数据 >>: {'password': [ErrorDetail(string='This field is required.', code='required')]}
- PostMan显示
{
"password": [
"This field is required."
]
}
2
3
4
5
6
7
8
9
10
若想将错误信息的显示从英文变为中文.需将配置文件中 LANGUAGE_CODE = 'en-us' 改为 LANGUAGE_CODE = 'zh-hans'.
# 内置和正则校验
用 内置的校验规则 和 正则表达式 来进行 用户请求数据格式 的校验!
一些内置的规则!!
| 参数名 | |
|---|---|
| 通用的 | 重要 : read_only 、write_only 、 了解 : required 、default 、allow_null 、validators 、error_messages、 忽略 : label 、help_text |
| CharField独有的 | max_length 、min_length 、allow_blank 、trim_whitespace |
| IntegerField独有的 | max_value 、min_value |
该示例需关注, serializers.ChoiceField 、serializers.EmailField() 、正则表达式校验参数validators.
from django.core.validators import RegexValidator, EmailValidator
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
class InfoSerializer(serializers.Serializer):
title = serializers.CharField(required=True, max_length=20, min_length=6)
order = serializers.IntegerField(required=False, max_value=100, min_value=10)
# ★ 此处的1,2写成字符串还是整型都没关系,得到前端传递过来的对应数据后,会在内部都转换成字符串,以字符串类型来进行判断.
level = serializers.ChoiceField(choices=[("1", "高级"), (2, "中级")]) # 选项
# 正则表达式校验
# ★ validators是一个列表,意味这里面可以写很多正则,若写多个,都得满足才能说该字段数据格式正确.
more = serializers.CharField(validators=[RegexValidator(r"\d+", message="格式错误")])
# email = serializers.EmailField() # 本质是CharField,但必须符合邮箱的格式.
email = serializers.CharField(validators=[EmailValidator(message="邮箱格式错误")])
# -- 相较于“基本校验”小节的视图类,此处的视图类是没有更改的.
class InfoView(APIView):
def post(self, request, *args, **kwargs):
print("请求体中数据 >>:", request.data)
ser = InfoSerializer(data=request.data)
if ser.is_valid():
res = ser.validated_data
print("验证成功的数据 >>:", res)
else:
res = ser.errors
print("验证失败的数据 >>:", res)
return Response(res)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
利用PostMan模拟前端发送请求. 进行验证.
验证成功的情况
http://127.0.0.1:8001/api/v1/info/ POST请求
发送Json数据 {"title":"hello_world","order":99,"level":"2","email":"[email protected]","more":22}
- pycharm控制台打印:
请求体中数据 >>: {'title': 'hello_world', 'order': 99, 'level': '2', 'email': '[email protected]', 'more': 22}
验证成功的数据 >>:
# ★ 注意到了吗,前端输入的是字符串的"2",此处显示的是数字2,后端是以字段对象choice属性里的设置为准的!!
OrderedDict(
[('title', 'hello_world'), ('order', 99), ('level', 2), ('email', '[email protected]'), ('more', '22')])
- PostMan显示
{
"title": "hello_world",
"order": 99,
"level": 2,
"email": "[email protected]",
"more": "22"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
验证失败的情况
http://127.0.0.1:8001/api/v1/info/ POST请求
发送Json数据 {"title":"hello_world","order":200,"level":"2","email":"123"}
- pycharm控制台打印:
请求体中数据 >>: {'title': 'hello_world', 'order': 200, 'level': '2', 'email': '123'}
验证失败的数据 >>:
{'order': [ErrorDetail(string='Ensure this value is less than or equal to 100.', code='max_value')],
'email': [ErrorDetail(string='邮箱格式错误', code='invalid')],
'more': [ErrorDetail(string='This field is required.', code='required')]}
- PostMan显示
{
"order": [
"Ensure this value is less than or equal to 100."
],
"email": [
"邮箱格式错误"
],
"more": [
"This field is required."
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 钩子校验
现目前, 我们学会了 基本、内置、正则校验, 但依旧无法满足复杂的校验场景..
何为复杂? 校验的过程需要查询文件、数据库等.. 这些应用场景就需要用到“钩子校验”来解决!!
局部钩子 validate_字段名 ; 全局钩子 validate
from django.core.validators import RegexValidator, EmailValidator
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework import exceptions
class InfoSerializer(serializers.Serializer):
title = serializers.CharField(required=True, max_length=20, min_length=6)
code = serializers.CharField()
# ■ 局部钩子
# 若前端传递json {"title":"hello_world","code":"1234567"}
# code字段的钩子函数校验失败. 后端返回前端数据: { "code": ["字段钩子校验失败"] }
def validate_code(self, value): # ★ 此处的value是前端传递的code字段的值
if len(value) > 6:
raise exceptions.ValidationError("字段钩子校验失败")
return value
# ■ 全局钩子
# 若前端传递json {"title":"hello_world","code":"123"}
# 走到全局钩子时,里面抛出了异常. 后端返回前端数据: {"non_field_errors":["全局钩子校验失败"]}
def validate(self, attrs): # ★ 此处的attrs是所有校验成功的数据
print("attrs :>>", attrs) # attrs :>> OrderedDict([('title', 'hello_world'), ('code', '123456')])
# api_settings.NON_FIELD_ERRORS_KEY
raise exceptions.ValidationError("全局钩子校验失败")
# return attrs
"""
全局钩子的错误 在视图函数中,通过 print(ser.errors)可得到结果
{'non_field_errors': [ErrorDetail(string='全局钩子校验失败', code='invalid')]}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
若具体到哪个字段出错, 比如code字段在钩子函数里raise错误, 那么key键名就是字段名"code";
若是全局钩子里的报错, 其key键名是 non_field_errors. 它出自drf配置文件 api_settings.NON_FIELD_ERRORS_KEY 的值.
这里code字段对象类型是CharField, 但前端给code传个数字..然后实验下来,到勾子那传递的value值类型是str. 不要纠结!!
我们只需要明白, code字段对象类型是CharField, 前端就传字符串, 肯定就没错!!! (´▽`)
举例全局钩子应用场景:
大佬“武sir”一般都习惯于将可写在全局钩子中的代码写在业务的视图逻辑中, 哈哈哈哈!
用户上传文件“上传的数据中不仅包含该文件,还有文件的大小名字等字段”. ==> 这些字段都可以单独校验.
但上传的文件是保存到 腾讯的COS对象存储里的.上传到腾讯COS的操作。 ==>就在全局校验里面做.
上传COS失败是什么原因 可以是多个字段不符合腾讯cos的规范导致的错误 在全局钩子里就可以抛出!!
2
3
# ModelSerializer
虽说前面继承Serializer 写的代码都不涉及到数据库, 但不意味着不能涉及..
我们若想将校验成功后的数据存储到数据库中. 就得保证校验的某些字段与数据库字段做强关联,一一对应!
继承ModelSerializer的第一大好处就是db匹配自动生成字段对象.. "自动生成字段对象"
因而自动生成的这些字段对象肯定是与数据库强关联的!是与数据库字段一一对应的!
在继承ModelSerializer情况下, 完成以下功能:
1> 完成 基本校验、内置和正则校验、钩子校验代码的编写!! + 添加数据库字段之外额外校验的字段
2> 校验成功后, 将数据存储到数据库中 (有两个点要注意!即传递参数个数多和少的两种情况!) "自动保存数据库"
3> 一对多外键 数据的存储
4> 多对多外键 数据的存储
# 准备工作
url.py 根路由
from django.urls import path
from api import views
urlpatterns = [
path('api/<str:version>/depart/', views.DepartView.as_view()),
path('api/<str:version>/user/', views.UserView.as_view()),
]
2
3
4
5
6
7
api/models.py
from django.db import models
class Depart(models.Model):
title = models.CharField(verbose_name="部门", max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class Tag(models.Model):
caption = models.CharField(verbose_name="标签", max_length=32)
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(
verbose_name="性别", choices=((1, "男"), (2, "女")))
ctime = models.DateTimeField(
verbose_name="创建时间", auto_now_add=True)
# - ★★★ 外键 部门:用户=1:n 一个部门可以有多个用户.
depart = models.ForeignKey(
verbose_name="部门", to="Depart", on_delete=models.CASCADE)
# - ★★★ 外键 标签:用户=n:n 一个标签可以多个用户使用,一个用户可以有多个标签
tag = models.ManyToManyField(verbose_name="标签", to="Tag") # 自动帮忙生成第三张表,tag是虚拟字段
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 内置&正则&钩子&额外
内置校验 + 正则校验 + 钩子校验 + 额外字段
POST请求 http://127.0.0.1:8001/api/v1/depart/
发送json数据/请求体中数据. {"title":"hello_world","order":1, "count": 20, "more":1}
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class DepartModelSerializer(serializers.ModelSerializer):
more = serializers.CharField(required=True) # 额外需要校验的字段
class Meta:
model = models.Depart
# 通过ModelSerializer给我们自动生成字段对象
fields = ["title", "order", "count", "more"] # 等同于 fields = "__all__"
# 想为字段对象传递一些参数用于内置验证怎么搞? 在Meta中使用extra_kwargs属性!
extra_kwargs = {
"title": {"max_length": 20, "min_length": 6},
"order": {"max_value": 100, "min_value": 1},
"count": {"validators": [RegexValidator(r"\d+", message="格式错误")]}
}
def validate_more(self, value):
return value
def validate(self, attrs):
return attrs
class DepartView(APIView):
def post(self, request, *args, **kwargs):
ser = DepartModelSerializer(data=request.data)
if ser.is_valid():
return Response(ser.validated_data)
else:
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# save新增数据
若使用的是继承的Serializer的序列化器类, 在校验成功, 拿到校验成功后的数据, 存储数据库:
ser = DepartSerializer(data=request.data)
models.Depart.objects.create(**ser.validated_data)
(若有多对多的外键,还需obj.虚拟字段.add()).
ser.validated_data是一个字典, 在添加进数据库之前, k-v多了就删, k-v少了就添加若使用的是继承的ModelSerializer的序列化器类, 在校验成功, 拿到校验成功后的数据, 存储数据库:
ser = DepartModelSerializer(data=request.data)
ser.save()可使用save()直接存储, 它会帮忙找到与之关联的数据库Depart, 将ser.validated_data里的数据存储进去.
但使用save保存, 会面临两个小问题: 参数少了; 参数多了.
注意: 该处新增示例涉及的Depart表中的字段都是些普通字段, 不涉及到外键!! 关于外键的存储会在后面跟外键的验证一起阐述.
# 参数少了
如果用户传递的参数有点少. 缺少数据库里面其他的相应字段!
举个栗子, 我需要用户传 depart表中的 "title", "order", "count", 但用户只传了 "title", "order"..
并且我在序列化器类里没有额外字段, 还通过 fields = ["title", "order"] 指定了只校验这两个字段..
(若写成__all__, 校验所有字段, count字段是必填的话, 在字段自身校验那就会报错, 不会在save那报错..)
校验成功后, ser.validated_data里会有两个k-v. 就像: OrderedDict( [('title', 'hello_world'), ('order', 1)])
而当我们执行ser.save()时, 与之关联的depart表新增数据需要传3个字段, 而验证成功的数据里只有两个字段. 缺少字段 "count".
解决方法: 可以通过给save传参数来实现. 源码里save(**kwargs).
应用场景:
用户登陆成功后/认证成功后, 访问问卷的表单页面, 并提交问卷表单, 该表单的数据需保存到数据库中..
但还得存储当前登陆用户的信息,表明是谁填写的, 但该信息用户并没有通过表单提交..
So, 我们就得给save传参, ser.save(user_id=request.user) 认证成功后, 用户信息在request.user中
POST请求 http://127.0.0.1:8001/api/v1/depart/
发送json数据/请求体中数据. {"title":"hello_world","order":1} 该数据肯定验证成功.
class DepartModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = ["title", "order"]
extra_kwargs = {
"title": {"max_length": 20, "min_length": 6},
"order": {"max_value": 100, "min_value": 1},
}
class DepartView(APIView):
def post(self, request, *args, **kwargs):
ser = DepartModelSerializer(data=request.data)
if ser.is_valid():
# Depart表中有三个必填字段"title","order","count",验证成功后,ser.validated_data中只有字段"title", "order"
# 给save传关键字参数,补全Depart表新增数据时所需的字段count.
# 这样的话, 用户传递的两个字段 "title", "order" 和自己在这补充的"count"字段 就可以保存到数据库中啦!
ser.save(count=100) # -- ★★★
return Response(ser.validated_data)
else:
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 参数多了
如果用户传递的参数有点多. 即用户传入的多,数据库中没有这个字段,而需要保存. 此时应该删除掉一些字段.
解决方法: 在validated_data中将多余的字段删除掉即可! 在保存之前剔除非数据库字段!
应用场景: 注册时需要输入重复密码等!
POST请求 http://127.0.0.1:8001/api/v1/depart/
发送json数据/请求体中数据. {"title":"hello_world","order":1, "count": 20, "more":1}
class DepartModelSerializer(serializers.ModelSerializer):
more = serializers.CharField(required=True)
class Meta:
model = models.Depart
fields = ["title", "order", "count", "more"]
extra_kwargs = {
"title": {"max_length": 20, "min_length": 6},
"order": {"max_value": 100, "min_value": 1},
"count": {"validators": [RegexValidator(r"\d+", message="格式错误")]}
}
class DepartView(APIView):
def post(self, request, *args, **kwargs):
ser = DepartModelSerializer(data=request.data)
if ser.is_valid():
# 用del也行 之所以用pop是因为,若删除的字段在其它地方可能会用到,用一个变量接收即可
ser.validated_data.pop("more") # -- ★★★
ser.save()
return Response(ser.validated_data)
else:
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# FK: 一对多
观察准备工作里编写的数据表 + 回顾 Django一对多新增
前端传递 {"depart":1} | 前端传递 {"depart_id":1} | |
|---|---|---|
| 是否需要额外字段 | 不需要额外字段 fields中写 "depart" | 额外字段 depart_id = serializers.IntegerField() fields中写 "depart_id" |
| 内置外键字段规则 自动判断该值在关联表中是否存在 | 有 存在则拿到对象 | 没有, 但可以在其钩子函数中查询数据库变相完成该功能 |
| 勾子函数中的value参数 | 是一个对象 | 是一个int类型的数字 |
| ser.save() | 相当于执行 语句1 | 相当于执行 语句2 |
语句1 models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart=depart_obj)
语句2 models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart_id=1)
# depart
1> 前端传入的FK字段depart的值是数字 代表所关联表中某条记录的ID值
drf在内部会给外键编写内置字段校验规则, 即会判断该值在关联表Depart表中是否存在.
2> 若存在, 在内部会拿到该字段在关联表Depart表中对应的那条记录/那个对象.
3> 内置校验外键是否存在通过后, 会进行到FK外键的局部钩子, 注意,FK外键字段的局部钩子函数的 value值 是 对象!
4> 可通过ser.save()语句将 前端传入的数据自动保存数据库.
简单来说: FK字段前端传数字; FK字段内置校验在关联表中是否存在; 存在会拿到在关联表中对应的对象; 可通过save直接存.
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
""" ★★★
若写成fields = "__all__"
虽说我们用Django ORM 给UserInfo表添加一条数据时,不用指定虚拟字段tag参数/不用给tag传值
但在drf中,虚拟字段tag在内部是会被转化ManyRelatedField字段对象的!!
字段对象的都有内置的验证参数 required=True 是默认的. - 必填.
So,写成fields = "__all__",前端传递的json中得有tag字段且得有值. 不然tag字段验证失败.
(在序列化器里重写get_fields方法可以得到验证!`def get_fields(self): return super().get_fields()`)
"""
fields = ["name", "age", "gender", "depart"] # 等同于 exclude = ["tag"]
def validate_depart(self, value):
# 虽然前端传入的是一个数字,但value的值是一个对象!
print(value, type(value)) # Depart object (1) <class 'api.models.Depart'>
if 0 < value.pk < 10:
return value
raise exceptions.ValidationError("depart字段局部校验失败.")
class UserView(APIView):
def post(self, request, *args, **kwargs):
print(request.data)
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
"""
request.data --:> {'name': '武沛齐1', 'age': 22, 'gender': 1, 'depart': 2}
若验证成功:
ser.validated_data --:> OrderedDict([('name', '武沛齐1'), ('age', 22),
('gender', 1), ('depart', <Depart: Depart object (2)>)])
可以看到,虽然前端传入的外键字段depart的值是数字2,但drf把该值在Depart表中对应的那条记录/部门对象拿到啦!
★ 注意,验证成功后,不能 return Response(ser.validated_data), 会报错!
因为,"depart"字段的值是一个db obj,不能序列化. 若非要返回,需 return Response(ser.data)
"""
print(ser.validated_data)
# ser.save()等同于执行语句
# models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart=depart_obj)
# 或者
# models.UserInfo.objects.create(**ser.validated_data)
ser.save()
return Response("success.")
else:
"""
request.data --:> {'name': '武沛齐1', 'age': 22, 'gender': 1, 'depart': 6}
若用户传入的外键字段depart的值在与之关联的Depart表中不存在该pk值,则验证失败:
ser.errors --:> {'depart':[ErrorDetail(
string='Invalid pk "6"-object does not exist.',code='does_not_exist')]}
So,在FK外键字段内部还有一个是否存在的字段内置校验!!
▲ 若需要对FK外键字段的校验的更为苛刻,比如:存在且pk值处于1-10之间. 这时就需要用到局部钩子!
"""
print(ser.errors)
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# depart_id
思考一个问题:
UserInfo表中的FK外键字段depart在数据库中生成字段的时候, 其字段名是depart_id;
那么我在序列化器的Meta.fields里将"depart", 改写成"depart_id", 是否可以?
实践是检验真理的唯一标准.
编写下方的代码, Post请求传递json数据 {"name": "武沛齐111","age": 22,"gender": 1,"depart_id": 1}
在ser.save()这行代码处报错!! NOT NULL constraint failed: api_userinfo.depart_id
其根由在于, ModelSerializers自动生成的字段对象是参照 Django的ORM表 中的那些字段来生成!
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart_id"]
class UserView(APIView):
def post(self, request, *args, **kwargs):
# {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart_id': 1}
print(request.data)
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
# OrderedDict([('name', '武沛齐111'), ('age', 22), ('gender', 1)]) -- 看到没,没有"depart_id"字段
print(ser.validated_data)
# 报错: django.db.utils.IntegrityError: NOT NULL constraint failed: api_userinfo.depart_id
ser.save()
return Response("success.")
else:
print(ser.errors)
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
解决办法: 自己写额外字段depart_id..
与在fields中写"depart", 不同的地方在于
1> depart_id 我们自己写了相对应的额外字段对象, 相比下字段内置校验外键是否存在的校验规则就没有了..
但该字段值不存在的话, 在save时会报错!! FOREIGN KEY constraint failed
提醒一点, 我们完全可以在 该depart_id字段的局部钩子里 查询数据库 变相的完成该内置的校验外键是否存在的功能.
2> depart_id的局部钩子里的value不是对象, 而是int类型的数字!!
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class UserModelSerializer(serializers.ModelSerializer):
depart_id = serializers.IntegerField()
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart_id"]
def validate_depart_id(self, value):
print(value, type(value)) # 1 <class 'int'> - 注意哦,此处value是int
if 0 < value < 10:
return value
raise exceptions.ValidationError("depart字段局部校验失败.")
class UserView(APIView):
def post(self, request, *args, **kwargs):
# {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart_id': 1}
print(request.data)
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
# OrderedDict([('name', '武沛齐111'), ('age', 22), ('gender', 1), ('depart_id', 1)])
print(ser.validated_data)
# ▲ 相当于执行语句
# models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart_id=1)
ser.save()
return Response("success.")
else:
print(ser.errors)
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# M2M: 多对多
观察准备工作里编写的数据表 + 回顾 Django多对多新增
前端传的都是 {"tag":[1,2]} , ORM表中使用的是 ManyToManyField 创建的虚拟字段.
前端传递 {"tag":[1,2]}使用默认的 | 前端传递 {"tag":[1,2]} 手动完成 | |
|---|---|---|
| 是否需要额外字段 | 不需要额外字段 fields中写 "tag" | 额外字段 tag = serializers.ListField() fields中写 "tag" |
| 内置外键字段规则 自动判断值在关联表中是否存在 | 有 | 没有, 但可以在其钩子函数中查询数据库变相完成该功能 |
| 钩子函数中的value参数 | 是一个包含多个对象的列表 | 是一个包含多个int类型数字的列表 |
| ser.save() | 相当于执行 语句1 | 相当于执行 语句2 |
语句1 user_obj = models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart=depart_obj)
user_obj.tag.add(<Tag: Tag object (1)>,<Tag: Tag object (2)>)
语句2 user_obj = models.UserInfo.objects.create(name="武沛齐1",age=22,gender=1,depart=depart_obj) user_obj.tag.add(1,2)
# 默认的m2m字段
M2M外键字段前端传[1,2];
M2M外键字段内置校验在关联表中pk=1、pk=2的数据是否存在; 存在会拿到在关联表中对应的对象;
内置校验通过后, 可进入局部钩子校验, M2M字段的局部钩子的value参数是一个字段对象列表.
可通过save直接存.
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "tag"] # 等同于 fields = "__all__"
def validate_tag(self, value):
# ★ 注意,value值是列表,里面是对象!即value是一个对象列表.
print(value, type(value)) # [<Tag: Tag object (1)>, <Tag: Tag object (2)>] <class 'list'>
return value
class UserView(APIView):
def post(self, request, *args, **kwargs):
print(request.data)
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
"""
request.data --:> {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart': 1, 'tag': [1, 2]}
若验证成功:
ser.validated_data --:> OrderedDict([
('name', '武沛齐111'), ('age', 22), ('gender', 1),
('depart', <Depart: Depart object (1)>),
('tag', [<Tag: Tag object (1)>, <Tag: Tag object (2)>])])
"""
print(ser.validated_data)
"""
会在内部通过虚拟字段tag的值,给第三张表添加数据 等同于执行两条命令
user_obj = models.UserInfo.objects.create(name="武沛齐111",age=22,gender=1,depart=depart_obj)
user_obj.tag.add(<Tag: Tag object (1)>,<Tag: Tag object (2)>)
结果就是,数据库中api_userinfo表多了一条记录、api_userinfo_tag表多了两条记录
"""
ser.save()
return Response("success.")
else:
"""
request.data --:> {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart': 1, 'tag': [1, 20]}
外键字段tag内置是否存在的校验规则不通过,因为,Tag表中没有pk值为20的表数据,所以报错
ser.errors --:> {'tag': [ErrorDetail(
string='Invalid pk "20" - object does not exist.', code='does_not_exist')]}
"""
print(ser.errors)
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 手动完成
同样的, 写了格外字段tag后, 内置外键校验规则是否存在就没有了, 但完全可以在该字段的钩子函数中查询数据库变相完成该功能.
请细品那个重要思想!!
from django.core.validators import RegexValidator
from rest_framework import exceptions
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class UserModelSerializer(serializers.ModelSerializer):
tag = serializers.ListField()
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "tag"]
def validate_tag(self, value):
print(value, type(value)) # [1, 2] <class 'list'>
# - 你可以直接返回value, 那打印ser.validated_data时, "tag"字段的值就是[1,2]
# - 当然,你可以在局部钩子中查询数据库完成该数值是否在数据库存在的校验.
# 相当于用默认的tag,drf内部会有的内置是否存在的校验规则.这样的话,就不会在ser.save()处报错了.
# 注意,若在此处返回queryset对象,那么"tag"字段的值就是[<Tag: Tag object (1)>, <Tag: Tag object (2)>])]啦.
"""
# ★★★ 一个重要的思想.
# 前端不是得非传列表,非得是这样 tag = serializers.ListField()
# 也可以是字符串 tag = serializers.CharFieldField() "1,2"
# 但在这里的话就要用进行下处理,splite进行分割 id__in=value.splite(",")
queryset = models.Tag.objects.filter(id__in=value)
if queryset:
# 那打印ser.validated_data时, "tag"字段的值就是<Tag: Tag object (1)>,<Tag: Tag object (2)>
return queryset
raise exceptions.ValidationError("这个数据在数据库不存在!")
"""
return value
class UserView(APIView):
def post(self, request, *args, **kwargs):
print(request.data)
ser = UserModelSerializer(data=request.data)
if ser.is_valid():
"""
- 报错的情况 -
request.data --:> {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart': 1, 'tag': [1, 20]}
若验证成功:
ser.validated_data --:> OrderedDict([
('name', '武沛齐111'), ('age', 22), ('gender', 1),
('depart', <Depart: Depart object (1)>),
('tag', [1, 20])])
但在执行ser.save()语句时会报错. FOREIGN KEY constraint failed
因为,Tag表中没有ID值为20的记录.
- 成功存储的情况 -
request.data --:> {'name': '武沛齐111', 'age': 22, 'gender': 1, 'depart': 1, 'tag': [1, 2]}
若验证成功:
ser.validated_data --:> OrderedDict([
('name', '武沛齐111'), ('age', 22), ('gender', 1),
('depart', <Depart: Depart object (1)>),
('tag', [1, 2])])
执行ser.save()会成功保存.相当于执行语句.
user_obj = models.UserInfo.objects.create(name="武沛齐111",age=22,gender=1,depart=depart_obj)
user_obj.tag.add(1,2)
同样的,结果就是,api_userinfo表多了一条数据、api_userinfo_tag表多了两条数据
"""
print(ser.validated_data)
ser.save()
return Response("success.")
else:
print(ser.errors)
return Response(ser.errors)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# 梳理
就目前而言,我们就已经学习了的关于序列化验证的知识,作一个简单的梳理:
Serializer
示例中的字段只要跟用户提交的一样,就可以做校验.仅做校验,跟数据库无任何关系.
1. 基本校验 Serializer + “自己写字段对象”
2. 内置和正则校验 Serializer + “自己写字段对象”(内置+正则)
3. 钩子校验 Serializer + “自己写字段对象”(内置+正则) + 字段钩子 + 全局钩子
ModelSerializer
可以自动生成字段对象;便于校验成功后保存到数据库. 示例中自动生成的字段对象与数据库强关联.
1. 内置&正则&钩子&额外 ModelSerializer + Meta的extra_kwargs属性
2. save新增数据 ModelSerializer + Meta的extra_kwargs属性 + save(多了,pop;少了,save参数)
3. FK ModelSerializer + FK
(depart可以根据用户传入的id自动获取关联的数据对象 ; depart_id自定制)
4. M2M ModelSerializer + M2M
(tag虚拟字段可以根据用户传入的id列表自动获取关联的数据对象 ; tag自定制 ListField()/DictField())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 校验源码分析
这部分总结的有点草率.. Hhh (つД`)ノ 因为坐了一天, 不清醒了.
# 校验整体流程

( ̄O ̄;)
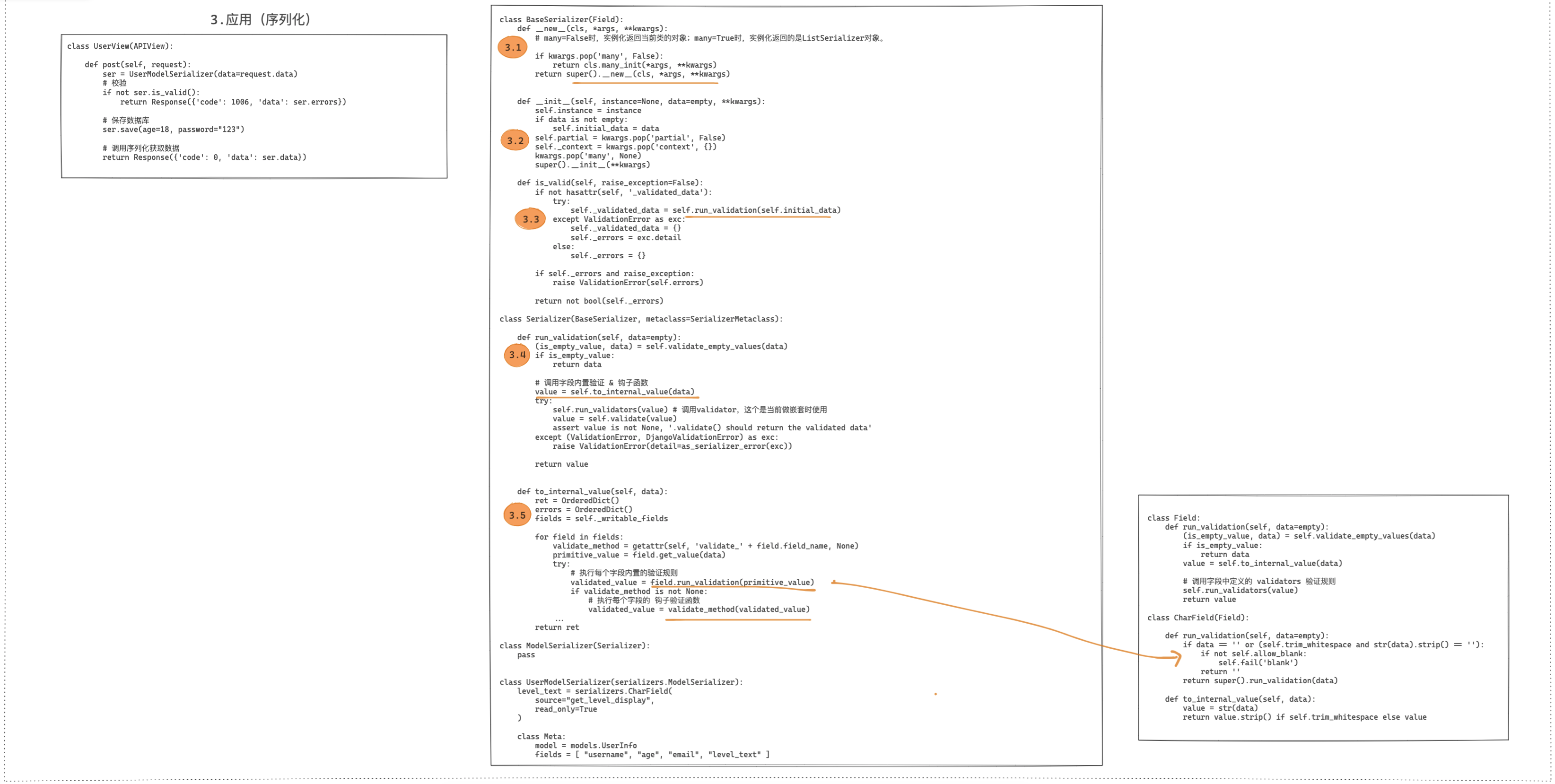
创建字段对象
基于元类创建序列化器类 类中多了个成员_declared_fields
创建序列化器类的对象
- ser = ExampleModelSerializer(data=request.data) 实例化,先new后init 根据mro关系,在BaseSerializer中
看源码,因为默认many=False,所以new方法只是返回一个对象
init方法执行完后,关键是ser多了个成员initial_data,其值为request.data
- ser.is_valid()
1. 获取所有的字段对象 {字段名:字段对象,字段名:字段对象...}, 并会执行每个字段的bind方法!
字段对象没设置source的话,source=字段名
2. 循环所有字段
先执行字段1的自身校验以及钩子校验,再执行字段2的自身校验以及钩子校验,以此类推,最后执行全局钩子.
钩子校验的参数拿到的是 数字/字符串/对象/对象列表 ; 全局钩子的参数拿到的 所有校验通过前端传递的数据
- 检验成功后,执行ser.save()
根据mro关系,跳转到BaseSerializer的save方法..
validated_data = {**self.validated_data, **kwargs}
self.instance = self.create(validated_data)
return self.instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
校验的源码如下:
class SerializerMetaclass(type):pass
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data # ser = UserModelSerializer(data=request.data)
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super().__init__(**kwargs)
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
# ser.is_valid
def is_valid(self, *, raise_exception=False):
# 该assert规定了,若想调用is_valid,序列化器类实例化时必须传入参数data!
assert hasattr(self, 'initial_data'), (...)
# 注意,重复多次校验,只会走一次
if not hasattr(self, '_validated_data'):
try:
# ★ 开始校验 跳转到Serializer类的run_validation方法
self._validated_data = self.run_validation(self.initial_data) # 【1】【12】
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail
else:
self._errors = {}
if self._errors and raise_exception:
raise ValidationError(self.errors)
return not bool(self._errors)
def save(self, **kwargs):
validated_data = {**self.validated_data, **kwargs} #【13】
# ★该self就是ser,给ser.instance赋值啦!!
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data) # --
assert self.instance is not None, (
'`create() did not return an object instance.'
)
return self.instance
@property
def validated_data(self):
if not hasattr(self, '_validated_data'):
msg = 'You must call `.is_valid()` before accessing `.validated_data`.'
raise AssertionError(msg)
return self._validated_data # 返回所有校验通过的数据 【14】
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
def run_validation(self, data=empty):
(is_empty_value, data) = self.validate_empty_values(data)
if is_empty_value:
return data
# 跳转到Serializer类的to_internal_value方法
value = self.to_internal_value(data) # 字段自己的规则+字段局部钩子的校验! 【2】【9】
try:
self.run_validators(value) # 与嵌套功能相关,略
value = self.validate(value) # 全局钩子 【10】
assert value is not None, '.validate() should return the validated data'
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value # 【11】
# 字段自己的规则+字段局部钩子的校验!
def to_internal_value(self, data):
ret = OrderedDict()
errors = OrderedDict()
fields = self._writable_fields # 获得验证功能可用的所有字段对象!! 【3】【6】
for field in fields:
# ★ 通过反射 看自定义序列化类里有没有 validate_字段名 的方法!!
validate_method = getattr(self, 'validate_' + field.field_name, None)
primitive_value = field.get_value(data) # 其实就是 data.get(field.field_name,empty)
"""
此处的异常捕获很有意思
1> 字段自身校验出错,就不会执行字段对象的局部钩子呢
2> 字段自身若有多个规则,不符合的都会被收集到!
3> 当在ORM中编写的字段null=True,blank=True;并写到了Meta的fields中
那么到这里,该字段经过处理后primitive_value的值为empty
在执行field.run_validation(primitive_value)会抛出SkipField异常,捕获后pass啥也不处理
这使得最终返回的ret中是没有该字段的信息的!!
"for循环中执行某个函数,该函数抛出异常,在for循环中捕获,直接pass. 就相当于在for循环中使用 continue"
"""
try:
"""
字段对象自己的规则包括:
serializers.CharField(一些规则)"字段对象__init__实例化时加进去的" +
Meta.extra_kwargs属性里key为字段名对应的那些规则"它啥时候加进去的没有深究"
"""
validated_value = field.run_validation(primitive_value) # 校验字段自己的规则 【7】
if validate_method is not None:
# 反射有的话,就会执行该字段对应的局部钩子函数 【8】
validated_value = validate_method(validated_value)
except ValidationError as exc:
errors[field.field_name] = exc.detail
except DjangoValidationError as exc:
errors[field.field_name] = get_error_detail(exc)
except SkipField:
pass # !!!
else:
# ★ 很关键!! 特别关注键名使用的是field.source_attrs!!
set_value(ret, field.source_attrs, validated_value)
if errors:
raise ValidationError(errors)
return ret
def fields(self): # 【5】
fields = BindingDict(self)
for key, value in self.get_fields().items():
fields[key] = value
return fields
# -- 【4】
@property
def _writable_fields(self):
for field in self.fields.values():
if not field.read_only:
yield field
@property
def _readable_fields(self):
for field in self.fields.values():
if not field.write_only:
yield field
class ModelSerializer(Serializer):pass
class InfoSerializer(serializers.ModelSerializer):pass
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
# 一点小思考
- 获得全部的字段对象
OrderedDict([
('id', IntegerField(label='ID', read_only=True)),
('title', CharField(label='部门', max_length=32)),
('order', IntegerField(label='顺序')),
('count', IntegerField(label='人数', write_only=True))])
- 获得可用于校验的字段对象
[CharField(label='部门', max_length=32),
IntegerField(label='顺序'),
IntegerField(label='人数', write_only=True)]
- 最后校验通过后,打印 ser.validated_data 的值 是起那段传递过来的校验通过的数据!!
OrderedDict([('title', '事业部'), ('order', 7), ('count', 10)])
1> 获得全部的字段对象中, key是字段名 value是字段对象
2> 获得可用于校验的字段对象中, 就只有字段对象啦
3> ser.validated_data 的值 就是我要思考的地方!
※我觉得: 元祖的第一项应该是字段对象中source属性的值;元祖里的第二项应该是经过校验后前端传递的值!!!!!!
为啥这样觉得,看校验的源码
在Serializer的to_internal_value方法的最后,执行了语句 set_value(ret, field.source_attrs, validated_value)
field.source_attrs 熟悉吧,它跟source有关, 然后又联想到了bind方法!!
我突然又想知道OrderedDict方法是个啥玩意儿..于是.
>>> from collections import OrderedDict
>>> OrderedDict({'a': 1, 'b': 2})
OrderedDict([('a', 1), ('b', 2)])
所以啊!元祖的第一项应该是字段对象中source属性的值.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
有个奇淫技巧.. 在源码的其它地方"视图类CreateModelMixin中"会看到. 它利用了drf里的异常处理机制.
class InfoView(APIView):
def post(self, request, *args, **kwargs):
print("请求体中数据 >>:", request.data)
ser = InfoSerializer(data=request.data)
ser.is_valid(raise_exception=True)
return Response(ser.validated_data)
"""
ser.is_valid(raise_exception=True)结果为True,会往下执行return Response(ser.validated_data)
ser.is_valid(raise_exception=True)结果为False,会执行源码里的raise语句.
该语句抛出的异常会被APIView类里的dispatch函数里的try..except捕获到!!
此种写法,一般不用,因为没办法自己定制失败的时候返回的消息格式.错误信息想嵌套一层,放到一个字典中都不行.
(´▽`) 看下is_valid函数的源码很容易理解,它的逻辑.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15