 拍拍贷数据分析
拍拍贷数据分析
该项目数据集链接 - https://pan.baidu.com/s/15ZLLTc3gC8N3xTarShKm2g?pwd=k8vf
本文对拍拍贷 从2015年1月1日到2017年1月30日, 共328553条 《贷款到期用户》的数据进行分析.
分析得出逾期用户的特征, 及公司核心业务标的, 达到降低业务逾期风险, 增加业务收入的目的.
分析目的: 降低用户的逾期率和逾期金额
# 准备工作
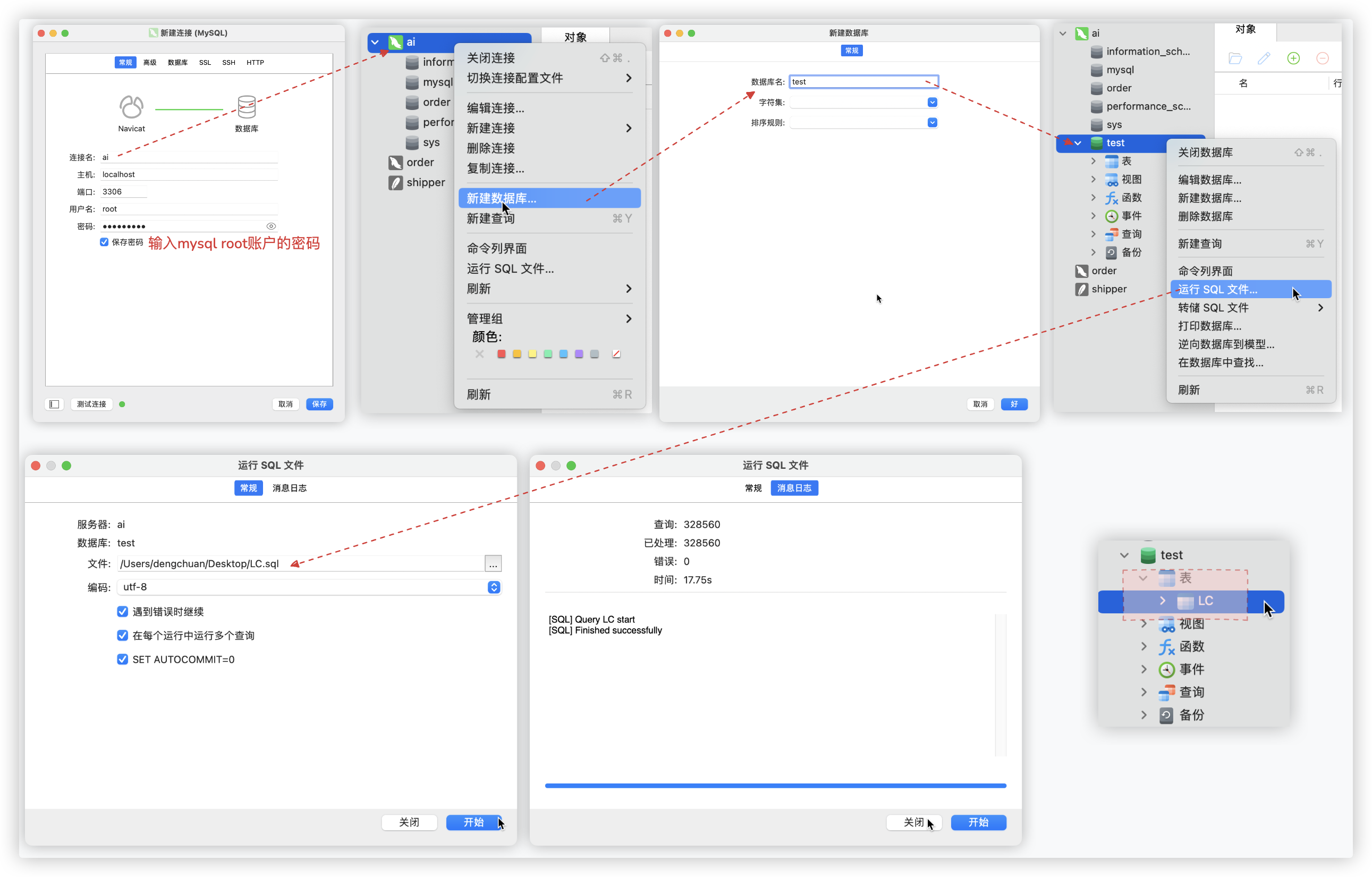
启动mysql服务
- source ~/.zhsrc
- mysqlstart (执行命令mysqlstop停止) >> 需要输入的是电脑用户的密码!!
- mysql -uroot -p (初使密码 admin1234)
2
3
打开Navicat Premium, 新建链接 - 创建数据库 - 导入sql文件
安装pymysql库, pip install pymysql
(AI) dengchuan@MacBook-Air ~ % pip list|grep PyMySQL
PyMySQL 1.1.1
2
安装sqlalchemy库, pip install 'sqlalchemy<2.0'
注意: jupyter里用pymysql会被警告,根据提示使用sqlalchemy.
默认安装的sqlalchemy的版本是2.0以上的, 读取数据时会报错.. 需要将版本降到2.0以下
2
# 加载数据
数据集共有328553行, 分为21个字段.
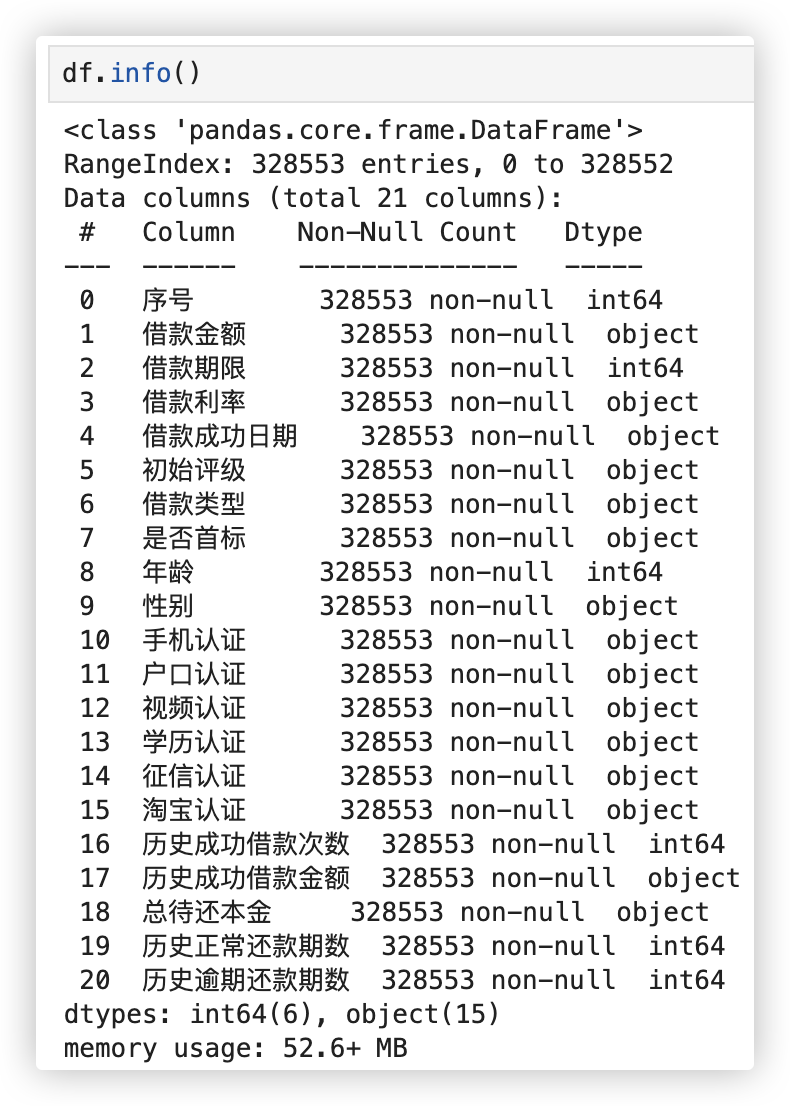
序号: 列表序号,为列表的唯一键(贷款到期用户的唯一标识)
借款金额: 列表成交总金额
借款期限: 总的期数(按月计)
借款利率: 年化利率(百分数)
借款成功日期: 列表成交的日期。都在2015年1月1日以后
初始评级: 列表成交时的信用评级。AAA为安全标,AA为赔标,A-F为信用等级
借款类型: 分为应收安全标,电商,APP闪电,普通和其他
是否首标: 该标是否为借款人首标
年龄: 借款人在该列表借款成功时的年龄
性别: 该列表借款人性别
手机认证: 该列表借款人手机实名认证是否成功
户口认证: 该列表借款人户口认证是否成功
视频认证: 该列表借款人视频认证是否成功
学历认证: 该列表借款人学历认证是否成功。成功则表示有大专及以上学历
征信认证: 该列表借款人征信认证是否成功。成功则表示有人行征信报告
淘宝认证: 该列表借款人淘宝认证是否成功,成功则表示为淘宝店主
历史成功借款次数: 借款人在该列表成交之前的借款成功次数
历史成功借款金额: 借款人在该列表成交之前的借款成功金额
总待还本金: 借款人在该列表成交之前待还本金金额
历史正常还款期数: 借款人在该列表成交之前的按期还款期数
历史逾期还款期数: 借款人在该列表成交之前的逾期还款期数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# pymysql
import pymysql
import pandas as pd
conn = pymysql.Connect(
host = '127.0.0.1', # 连接数据库的主机地址
port = 3306, # mysql端口号
user = 'root', # mysql的用户名
password = 'admin1234', # mysql密码
db = 'test', # 连接的数据仓库的名字
)
sql = 'select * from LC'
df = pd.read_sql(sql,conn)
df
2
3
4
5
6
7
8
9
10
11
12
13
14
# sqlalchemy
from sqlalchemy import create_engine
import pandas as pd
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'admin1234'
MYSQL_HOST = '127.0.0.1'
MYSQL_PORT = '3306'
MYSQL_DB = 'test'
# mysql+pymysql://用户名:密码@IP:Port/dbName?charset=UTF8MB4
# conn = create_engine('mysql+pymysql://root:[email protected]:3306/test?charset=UTF8MB4')
url = f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_DB}?charset=utf8MB4"
conn = create_engine(url)
sql = 'select * from LC'
df = pd.read_sql(sql, conn)
df
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 数据分析
■ 逾期率是指贷款到期的用户里面未还款用户的占比,df中的每一条数据都是贷款到期的数据!! - 平均逾期率
res = (df['历史逾期还款期数'] > 0).sum() / df.shape[0]
res = format(res,'.2%')
res # '15.33%'
2
3
■ 计算出不同年龄段的总用户数量、未还款用户数、逾期率和逾期期数总计.
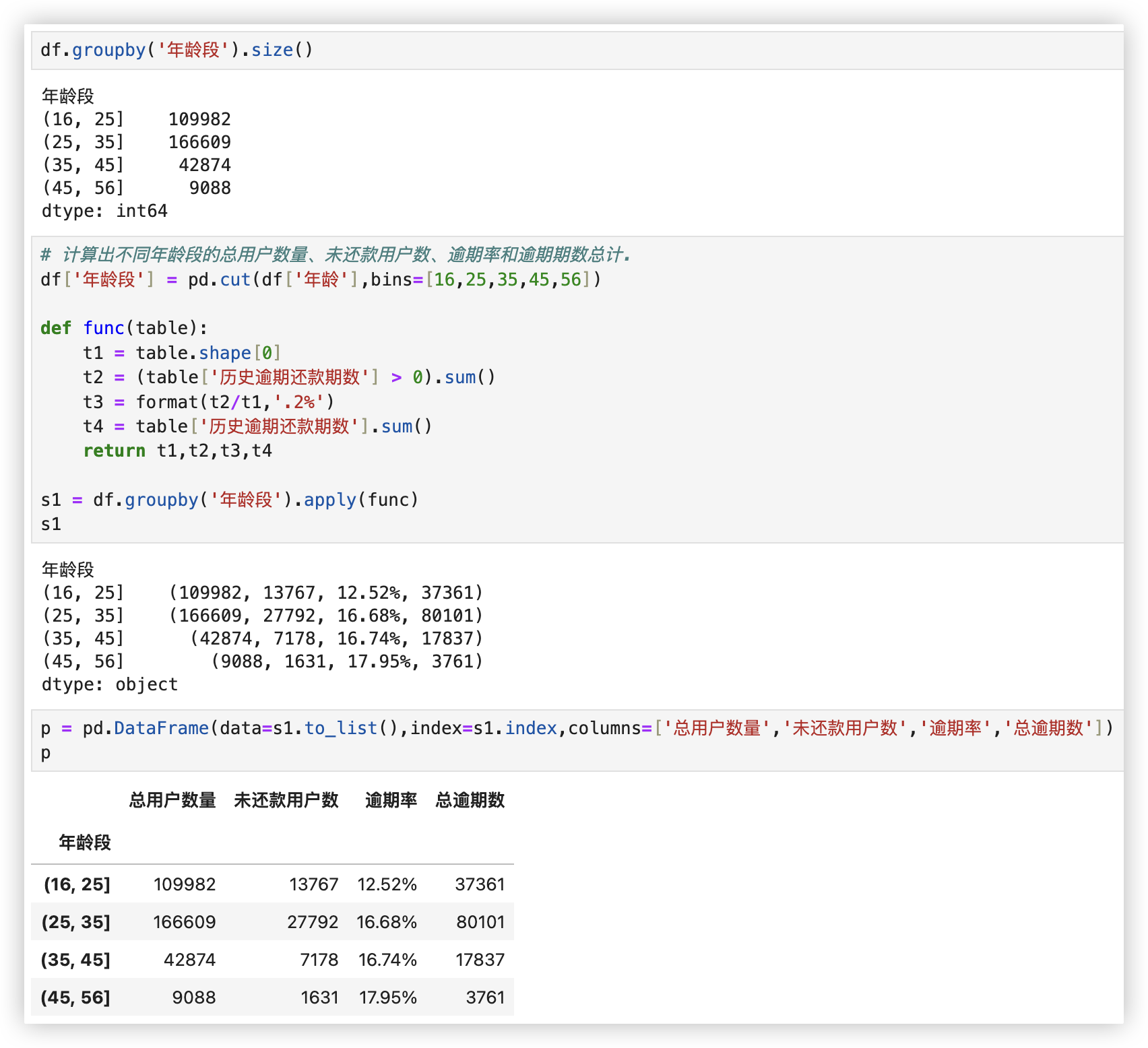
结论:
-1- 产品主要用户年龄分布在17-35岁之间, 其中25-35岁用户群体基数最庞大..
-2- 17-25岁的用户的逾期低于平均值, 其他年龄段的用户逾期率高与平均值, 且随着年龄的增大, 逾期率风险也越高.
因此建议将获客目标放在17-25岁的年轻用户群体, 适当降低该用户群体的准入门槛.
同时对高年龄段的用户在审核和推广方面更加严谨.
■ 计算出不同性别的总用户数量、未还款用户数、逾期率和逾期期数总计. 同上
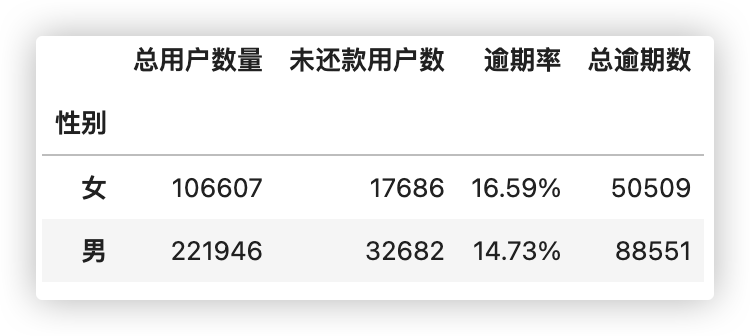
结论:
男性用户数约为女性用户数的2倍, 女性逾期率比男性逾期率高了2%.
说明男性还款意识高一点, 因此可以拓展男性用户为主要获客目标..
■ 计算出不同初始等级的总用户数量、未还款用户数、逾期率和总历史成功借款金额.
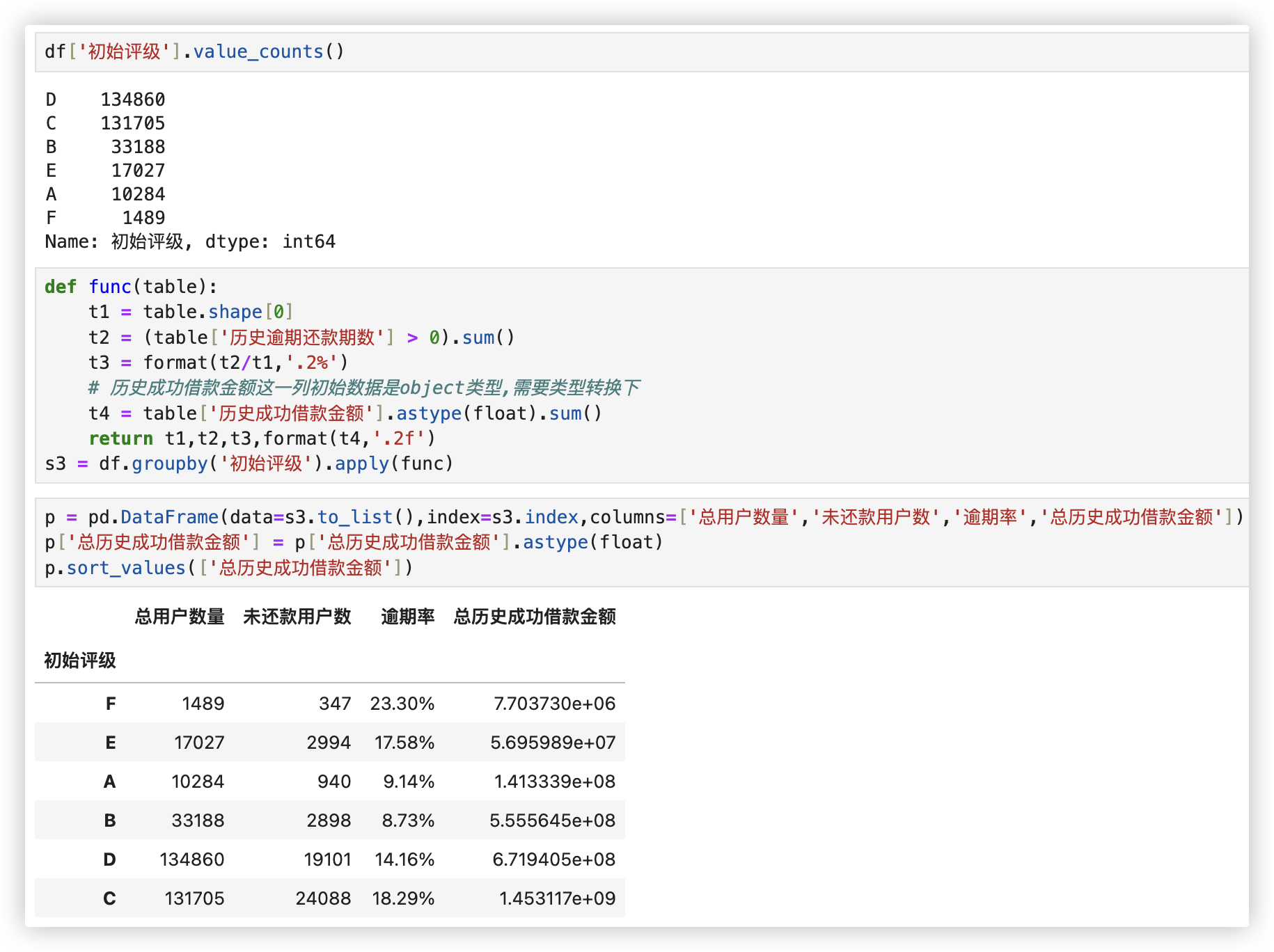
结论:
借款金额主要集中C等级上, 但C逾期率为18%, 高于平均值.
而D等级借款金额仅低于C等级, 但D等级用户的逾期率低于平均值, 建议贷款金额方面向D等级倾斜.
随着等级的下降, 逾期率也相应上升(除D评级逾期率较C有所下降) ,建议加强对风险的把控。
有点懒,剩下的就不弄了.. emmm. 阐述下思维.
剩下的 >>
1. 针对用户认证类型,分别对 '手机认证', '户口认证', '视频认证', '学历认证', '征信认证', '淘宝认证' 进行groupby
利用apply算出每个分组的总用户数、未还款用户数、逾期率、平均单笔金额、总历史借款金额、总历史逾期还款期数
<技术要点跟前面的一样一样的>
2. 针对区间
分别对 "不同借款区间"、"不同借款期限"、"不同区间的借款利率"等 进行分析.
-1- 首先根据区间,用map作映射,给df添加一列
-2- 对映射出的这一列作groupby,往后的分析就跟前面的一样了.
2
3
4
5
6
7
8