 进程开发必用
进程开发必用
参考链接:
https://www.cnblogs.com/linhaifeng/articles/7428874.html
# 开启子进程的两种方式
开启子进程的目的:
想把父进程里串行执行的任务(eg,一段函数代码)分给独立的进程去执行,从而实现任务的并发执行!
# Process类实例化
我们通常使用的就是这一种!!
# 实现代码
# -- a.py
import time
from multiprocessing import Process
def task(x):
print(f"{x} is running.")
time.sleep(3)
print(f"{x} is done.")
if __name__ == '__main__':
# -- 参数说明:
# group不用管;target是我们的任务/子进程;name子进程的名字,不传会有个默认值;
# 给我们的任务传参,有两种形式,args"元组,按位置传 注意元组里的逗号"、kwargs"字典"任选其一即可
# Process(target=task, kwargs={'x': '子进程'})
p = Process(target=task, args=('子进程',)) # -- 调用类实例化一个对象p
# -- 只是在向操作系统发送一个开启p对象对应任务/子进程的信号,该行代码运行会非常非常的快.
# 信号发完后,这个子进程什么时候造,造多长时间,运行多久,OS说的算,应用程序是管不了的!!
p.start()
# time.sleep(5) # -- 可以实验下,运行该代码,"主"会最后打印.证明等待的5s的时间里子进程造出来啦!
print("主")
""" # -- 屏幕输出结果如下:
主
子进程 is running.
子进程 is done.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 执行过程
在这里,a.py文件中task函数体的代码归子进程执行; 其它代码归父进程执行!!
[父进程的启动]
pychram里显示的a.py文件代码在硬盘里放着呢,右键点击运行,OS接收指令,先开辟一个内存空间;
接着,OS将a.py文件的代码从硬盘读入开辟的空间,OS再调用CPU执行代码.. 该a.py文件就运行起来啦!!
将这一个过程进行抽象,抽象的结果就叫做进程!!
[子进程的启动]
执行a.py文件里的 p.start() 代码, 父进程会给OS发信号, 告知它需要启动一个子进程!
注意:信号发完后,这行代码父进程就执行完毕了!!
OS会申请新的内存空间放子进程的代码,还会拷贝一份父进程的namespace放进去.
即父进程的所有资源都会被子进程继承,包括运行父进程的进程,如pycharm.exe/cmd.exe!!
注意: 子进程只会将 a.py 中 if __name__ == '__main__': 之上的代码通过 导入的方式 拷贝一份..
OS吭哧吭哧造子进程的过程中,父进程也在运行.. 子进程造完后,父子进程并发执行.
父进行运行最后一行打印 print("主") 的时候, 子进程还没有造完呢..
所以会看到终端先打印的"主"... 提醒一哈,父进程与子进程共用的同一个输出终端..
# 注意事项
开启子进程的操作 p.start() 应该写到 if __name__ == '__main__': 下面!!
这样使得该操作在导入该操作所在模块时不被运行. 即这个if语句中的语句将不会在导入时被调用!!!
具体来说, 在windows上,开启子进程时,子进程拷贝父进程空间的方式比较特殊.
它会将父进程对应的文件当作模块重新导一遍, 将导入的成果放到子进程自己的内存里..
我们晓得, 执行文件不等于导入文件 ; 导入模块会运行文件、产生namespace、丢入一堆数据.
意味着,一旦执行代码 p.start() 开启子进程, 该代码又将被执行一遍,无限套娃/无限开启子进程!!
Ps: 我试了下,在mac上也需要放到那下面,centos则不用..Hhh 为了兼容性,还是得放.
# 继承Process类
自定义的类一定要继承Process, 并且自定义类里一定要有一个名为 run 的绑定方法!!
敲黑板! 把子进程开启后需要执行的代码放到绑定方法run里!!!
# 实现代码
import time
from multiprocessing import Process
class Myprocess(Process):
def __init__(self, x):
super().__init__()
self.x = x
def run(self):
print(f"{self.x} is running.")
time.sleep(3)
print(f"{self.x} is done.")
if __name__ == '__main__':
p = Myprocess('子进程')
p.start() # -- 内部就是在调用run方法! 你问为啥?那就需要看源码的调用关系了.
print("主")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 与第一种方式的区别
直接使用默认的Process类实例化对象调用start创建子进程, 是通用的造进程的方式 !!
可以造不同的子进程执行不同的任务, 类实例化对象时指定不同的target参数值就可以啦!!
p1 = Process(target=task1, args=('子进程1',))
p2 = Process(target=task2, args=('子进程2',))
p3 = Process(target=task3, args=('子进程3',))
p1.start()
p2.start()
p3.start()
2
3
4
5
6
而自定义类继承Process的方式,相当于只能造一个特定的子进程.. (Because只能执行run函数..)
# 僵尸进程与孤儿进程
详见 前面linux基础中"管理进程"章节相关的内容..
# 抛出问题
思考一个问题: 在创建子进程的第一种方式 "Process类实例化" 中,父进程在自己代码执行完后,并不会立马结束掉, 会等到所有子进程结束后 ,才会结束,为什么呢?
# -- a.py
import os
import time
from multiprocessing import Process
def task(x, n):
print(f"{x} is running.")
time.sleep(n)
print(f"{x} is done.")
if __name__ == '__main__':
p1 = Process(target=task, args=('子进程1', 3))
p2 = Process(target=task, args=('子进程2', 5))
p1.start() # -- 再次强调!信号发完后,这行代码父进程就执行完毕了!!
p2.start() # -- 再次强调!信号发完后,这行代码父进程就执行完毕了!!
print(p1.pid, p2.pid, os.getpid())
print("主")
time.sleep(50)
"""
21233 21234 21231
主
子进程2 is running.
子进程1 is running.
子进程1 is done.
子进程2 is done.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在a.py程序运行5-50s的时间段,在cmd终端输入以下命令.. 可以看到z状态!! z为僵尸进程的标识!!!

# 理论阐述
若现在有一个父进程和两个子进程(p1和p2).
[正常情况,父进程等着所有子进程运行完后再结束] -- 僵尸进程
首先要知道,从运行角度来看,这里的父进程和两个子进程是完全独立不相干的3个进程.彼此隔离的.
父进程无法预知子进程什么时候结束,为了保证在父进程在活着的时候,可以随时查看三个子进程的状态. 设置了僵尸进程这种独特的数据结构.
僵尸进程是指 子进程在运行完毕以后 ,OS会将子进程占用的重型资源都释放掉(eg:关闭已打开的文件,舍弃已占用的cpu、内存、交换空间等), 但 是会保留部分子进程的关键状态信息(eg: PID 、退出状态、已运行时间等)
父进程把自己活干完后,没有立刻结束,是为了等着给子进程收尸, 即所有的子进程进入僵尸状态后,父进程会统一发起回收操作.具体来说,会由父进程发起一个 系统调用 wait / waitpid来通知linux操作系统来清理这些僵尸进程.
所有的子进程结束后都会进入僵尸进程的状态!!
通常我们不会等父进程结束时自动回收,会使用join提前回收这个僵尸进程..
[子进程还未运行完,父进程先嗝屁了] -- 孤儿进程
若父进程先死掉, 不会影响子进程的运行, 但还未运行完的子进程将会成为孤儿进程..
孤儿进程将被PID为1的 顶级进程init/systemd (其PID为0,是所有进程的祖宗,linux的进程是一个树形结构) 所收养,并由该顶级进程对它们完成状态收集工作..
通俗来说,父进程死的时候,否管它的子进程是处于僵尸状态还是孤儿状态,只要父进程不等所有子进程结束就嗝屁,这些子进程都将被顶级进程init/systemd托管!! 父进程死之前,已经结束变成僵尸进程的子进程在父进程死后会被init回收;父进程死后,还未运行完的进程是孤儿进程,运行完后会变成僵尸状态的孤儿进程,也将被init回收!!
[注意事项]
孤儿进程没有害,是因为有人管它;正常情况下,子进程死后会被父进程发起系统调用回收.也没有害.
坏就坏在父进程一直不死,不停的在开子进程,还不发起回收僵尸进程的信号.那么保留的信息就得不到释放.
僵尸进程越积越多,占用过多的PID号,新的软件就启动不起来! (PID是有限的!!)
解决方案: kill掉父进程,父进程在世时产生的僵死进程就会变成了处于僵死状态的孤儿进程..还未运行完的子进程会变成孤儿进程,在运行完后也会进入僵死状态.. 这些孤儿进程都会被init进程接管...
egon语录:不懂开发的运维就是秋后的蚂蚱,蹦跶不了几天.Hhh
# 进程内存空间彼此隔离
验证子进程与父进程内存空间之间是隔离的! (通过前面多道技术的讲解我们得知这隔离还是物理隔离的)
提醒一下, 说的是内存空间彼此隔离,硬盘空间是共享的.
import time
from multiprocessing import Process
x = 100
def task():
# -- 子进程在开启时会拿到和父进程有一样的变量x和task (定义函数和定义变量是一回事)
# 所以子进程在启动起来后能访问得到task! global x 声明的全局变量x是以子进程自己的为准!
# 因而子进程改的全局变量是子进程里的全局变量,不会影响到父进程!!
global x
x = 0
print("子进程已经运行完毕!")
if __name__ == '__main__':
p = Process(target=task)
p.start() # -- 发信号
time.sleep(3) # -- 睡3秒,让父进程在原地等待3秒,是不想让父进程立刻运行`print(x)`这行代码.
# 确保OS把子进程开启并执行完.才会让父进程运行`print(x)`这行代码.
print(x) # 100 -- 父进程里的x仍为100,证明没有被子进程影响到!!
"""
子进程已经运行完毕!
100
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
思考: time.sleep(3) 3秒时间能保证子进程运行完吗?但凡子进程代码多点, 我们压根不知道子进程会运行多久!把时间改成300秒? crazy. 合理情况下,我们需要一个接口等到子进程结束就不用再等了. 使用 p.join() !!!
# 进程对象的方法和属性
上面已经接触了Process类的start方法.. 下面介绍下Process类的其它方法!!
start()、join()是必须掌握的!! 其余的了解即可!
# join方法!!
p.join()本质跟time.sleep(n)一样, 但时间更精准, 不用我们自己控制!
# 实现代码
time.sleep() 让父进程原地等待,等待500s后,才执行下一行代码.
p.join() 让父进程原地等待,不影响子进程的运行, 等到子进程彻彻底底的运行完毕, 会回收子进程(确切点应称作僵尸进程)占用的pid等资源.. 再执行下一行代码.
import time
from multiprocessing import Process
def task(x):
print(f"{x} is running!")
time.sleep(2)
print(f"{x} is done!")
if __name__ == '__main__':
p = Process(target=task, args=('子进程1',))
p.start()
# time.sleep(500)
p.join()
print("主")
"""
子进程1 is running!
子进程1 is done!
主
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
★官方文档有如下的说明!!

join方法对应的源码里面有一行代码起到了发起系统调用 wait / waitpid 的作用 !!
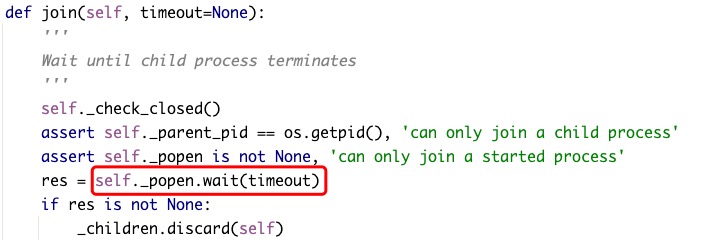
# 举一反三
核心要点: 是父进程在等,不会影响子进程的运行!!
p1、p2、p3三个子进程是并发执行的!! 三个join是在三个start信号发出去后再执行的操作!
import time
from multiprocessing import Process
def task(x, n):
print(f"{x} is running!")
time.sleep(n)
print(f"{x} is done!")
if __name__ == '__main__':
p1 = Process(target=task, args=('子进程1', 5))
p2 = Process(target=task, args=('子进程2', 2))
p3 = Process(target=task, args=('子进程3', 6))
start_time = time.time()
# -- 依次发送3个信号,发送完信号后,对应子进程就开始执行
p1.start()
p2.start()
p3.start()
# -- 【★look here!】虽然父进程的三个join代码是依次执行的,但子进程的运行实则是并行的!!
# 是因为父进程在等的时候,造这三个子进程的信号start早就发给OS啦.
# 进程只要start就会在开始运行了,所以p1-p3.start()时,系统中已经有四个(一父三子)并发的进程了
# -- 父进程等p1用了5s,但在等的过程中p2,p3也在运行
# 运行p2.join()时,p1,p2已经执行完了(p2只需要2s),就不用等了 即该行代码没有任何的阻塞
# 运行p3.join()时,p3已经执行了5s,还需执行1s
# ★ So,换一换p1、p2、p3 join的顺序,谁先谁后都一样!共运行的时间是一样的!!
# ★ 3个join花费的总时间仍然是耗费时间最长的那个子进程运行的时间
print("等p1结束..")
p1.join()
print("等p2结束..")
p2.join()
print("等p3结束..")
p3.join()
end_time = time.time()
print("共运行:", end_time - start_time)
"""
等p1结束..
子进程1 is running!
子进程2 is running!
子进程3 is running!
子进程2 is done!
子进程1 is done!
等p2结束..
等p3结束..
子进程3 is done!
共运行: 6.1702961921691895 # -- 6s多一点,多的这一点是OS创建进程以及切换进程的时间
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
蜜汁操作: 如果分要把p1、p2、p3三个子进程变成串行呢?
(自己可以这样玩, 写程序这么写,纯纯的瞎搞! 子进程串行,还不如依次执行三个函数节省进程的开销.Hhh)
start_time = time.time()
p1.start()
print("等p1结束..")
p1.join()
p2.start()
print("等p2结束..")
p2.join()
p3.start()
print("等p3结束..")
p3.join()
end_time = time.time()
print("共运行:", end_time - start_time)
# -- 想提醒一点的是,父进程执行`p1.start()`语句.OS就开始着手于创建进程p1并开始执行.
# 父进程发完信号后,接着会执行`print("等p1结束..")`语句
# 终端屏幕上先打印"等p1结束..",再打印"子进程1 is running!"
# 是因为父进程与子进程p1是并发执行的!!!看谁先执行罢了.
"""
等p1结束..
子进程1 is running!
子进程1 is done!
等p2结束..
子进程2 is running!
子进程2 is done!
等p3结束..
子进程3 is running!
子进程3 is done!
共运行: 13.303465843200684
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 代码优化
import time
from multiprocessing import Process
def task(x, n):
print(f"{x} is running!")
time.sleep(n)
print(f"{x} is done!")
if __name__ == '__main__':
# p1 = Process(target=task, args=('子进程1', 1))
# p2 = Process(target=task, args=('子进程2', 2))
# p3 = Process(target=task, args=('子进程3', 3))
# p1.start()
# p2.start()
# p3.start()
p_list = [] # -- 里面放的是三个进程对象
for i in range(1, 4):
p = Process(target=task, args=(f'子进程{i}', i))
p_list.append(p) # -- 注意:随着循环,p变量的指向是最后一个子进程的内存地址
# 所以得将进程对象放入列表进行保存
p.start() # -- 循环三次发送三个信号
# p1.start()
# p2.start()
# p3.start()
for p in p_list:
p.join()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# pid属性
pid -- 进程id号,即进程在操作系统内的身份证号,独一无二的
paid -- 当前进程的父进程的pid..
# 子进程是py进程
import time
from multiprocessing import Process
def task(x, n):
print(f"{x} is running!")
time.sleep(n)
print(f"{x} is done!")
if __name__ == '__main__':
p1 = Process(target=task, args=('子进程1', 10))
# print(p1.pid) # None -- 子进程还没开始创建呢,当然没有
p1.start()
print(p1.pid) # -- 18689
print("主")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们在上述代码中,将子进程执行时间设置为10s. 保证子进程还在执行时, 在cmd中输入以下命令.
windows: tasklist | findstr 18689
linux: ps aux | grep 18689 | grep -v grep
# -- Mac下显示结果
One_Piece@DC的MacBook ~ % ps aux | grep 18689 | grep -v grep
One_Piece ... ... ... /Library/Frameworks/Python.framework/Versions/3.8.../Python -c from multiprocessing.spawn...
# -- windows下显示结果
C: > tasklist | findstr 18689
python.exe 10524 Console 1 12,792k
2
3
4
5
6
7
Ps: mac上显示的结果..不是很通俗易懂. 以后的程序都在Linux上运行. linux上的运行实验结果,详见前面linux基础中"管理进程"章节中僵尸进程与孤儿进程中实验验证部分的内容!!!
Q: 哇!! 子进程怎么是个python进程?
A: 教给子进程执行的是python代码,python代码离开解释器后就没有执行一说啦!
如何运行一个python程序的?把解释器和代码依次从硬盘加载到内存,用python解释器解释代码.
开启子进程的话,不会从硬盘加载代码,会从父进程的内存拷贝一份代码给子进程..
不仅如此, 父进程地址空间里的python解释器的代码也会拷贝一份给子进程..
# PID查看
父进程的爹是运行该py文件的程序, 在pycharm里运行就是pycharm,在cmd里运行就是cmd!!
import os
import time
from multiprocessing import Process
def task():
print(f"子进程里看自个儿pid: {os.getpid()}")
print(f"子进程里看父进程pid: {os.getppid()}")
time.sleep(10)
if __name__ == '__main__':
p1 = Process(target=task)
p1.start()
print("父进程里看子进程pid:", p1.pid)
print("父进程里看自个儿pid:", os.getpid())
print("查看父进程它爹的pid:", os.getppid())
"""
父进程里看子进程pid: 19344
父进程里看自个儿pid: 19342
子进程里看自个儿pid: 19344
子进程里看父进程pid: 19342
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
扩展说一点,关于linux中父进程终止后的现象(有占用终端前台运行,和不占用终端的后台运行一说).. 详见linux基础中"管理进程"章节!! 看一个进程有没有被终止,用命令查看,不要被表象迷惑!!
(弄个VMware虚拟机安装个centos7来实验.. 别在windows和mac上实验,有些实验结果不一致.就很烦.想不通就不要想了,以linux上的实验结果为准!╮( ̄▽ ̄"")╭)
# 注意:join与pid
疑惑之处:
p.join()最后不是会回收僵尸进程所占用的资源嘛,那为啥join后还能打印p.pid呢?
诚然, 执行join操作会,会回收僵尸进程占用的资源(eg:pid).
但该回收操作是删除父进程namespace里p对象下面的pid属性吗? no!!
回收的是OS的资源 - OS所占用的PID ; 不会影响python程序的资源 - p对象里面pid..
Ps: 回收的僵尸进程会标记为free状态(涉及到linux文件系统中删除后的inode号)..
举个极端 的例子,如果没有僵尸进程这种机制,进程一结束,就回收所有的资源.. 可能会导致py程序里p.start()给OS发送信号后,立刻查看p.pid ,查看不到, 因为此时OS还没来得及给该子进程分配pid号.. Hhh Amazing.
import time
from multiprocessing import Process
def task():
time.sleep(3)
if __name__ == '__main__':
p = Process(target=task)
p.start() # -- 一旦执行就会给子进程申请到一个pid号
print(p.pid) # 20344
p.join()
print(p.pid) # 20344
print("主")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# name属性
current_process().name查看当前进程的进程名
import time
from multiprocessing import Process, current_process
def task():
print(f"子进程里看子进程的名字: {current_process().name}")
time.sleep(10)
if __name__ == '__main__':
p1 = Process(target=task, name="子进程1") # -- 不设置name属性的话,默认是Process-1
p1.start()
print("父进程里看父进程的名字:", p1.name)
print(current_process().name)
"""
父进程里看父进程的名字: 子进程1
MainProcess
子进程里看子进程的名字: 子进程1
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# terminate,is_alive
import time
from multiprocessing import Process
def task(n):
time.sleep(n)
if __name__ == '__main__':
p1 = Process(target=task, name="子进程1", args=(2,))
p2 = Process(target=task, name="子进程1", args=(5,))
p1.start() # -- 只要信号一发出,子进程就处于活着的状态
p2.start()
print(p1.is_alive()) # True
print(p2.is_alive()) # True
p1.terminate() # -- 给OS发送SIGTERM信号,表明终止该子进程的.. 但OS啥时候终止OS说的算
# 几乎没有terminate()的使用场景,了解即可
time.sleep(0.1) # -- 0.1s的时间足够OS终止p1进程啦
print(p1.is_alive()) # False
# time.sleep(3)
p2.join() # -- p1,p2两个子进程是并发执行,p1、p2执行分别需要2s、5s,p2执行完时p1早已经执行完
print(p1.is_alive()) # False
print(p2.is_alive()) # False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23