 数据类型之哈希
数据类型之哈希
经实验,序列的方法, 长大小 和排翻 二元祖 三转换 zip 以及 in 操作符 字典和序列都可以用!!!
特别需要注意的是, 具备哈希特性的字典和集合不能使用下标进行索引(即不能切片)..
字典遍历时取得的是键!
# 字典
# 创建的7种方式
{}、dict、formkeys
注意: 字典的键必须是可哈希的(从里到外都是不可变对象)!!! 哪怕元祖内包含可变对象也不行..
d = {1: 123} d[1.0] = 234 d[True] = 345 三者是等价的..
1> {'one':1,'tow':2,'three':3}
{} # -- 创建空字典(推荐)
2> dict(one=1,two=2,three=3) # -- 注意此方式键不能加引号
3> dict({'one':1,'tow':2,'three':3})
4> dict([('one',1),('two',2),('three',3)]) dict((('one',1),('two',2),('three',3)))
5> dict(zip(['one','two','three'],[1,2,3]))
6> dict.fromkeys(序列,每个键的初始值) # -- 默认初始值为None
7> 字典生成式
keys = ['names','age','sex']
values = ['egon',18,'male']
res = {k:v for k,v in zip(keys,values)}
"""
-- fromkeys
"""
>>> v = dict.fromkeys(['k1','k2'],[])
>>> v
{'k1': [], 'k2': []}
>>> v['k1'] is v['k2']
True
>>> v['k1'].append(666)
>>> v
{'k1': [666], 'k2': [666]}
>>> v['k1'] = 777
>>> v
{'k1': 777, 'k2': [666]}
data = [12, 5, 6, 4, 6, 5, 5, 7]
print(dict.fromkeys(data, 0)) # -- {12: 0, 5: 0, 6: 0, 4: 0, 7: 0}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 增加、修改、查找
查找 -- key、values、items、get、setdefault、my_dict[key值].
增加 -- 直接赋值、update、setdefault.
修改 -- update、直接赋值覆盖
key()、values()、items()皆返回iterable可迭代对象..
price.values() 等同于 dict.values(price) 其余同理
get() 若键不存在,默认返回None,也可以设置返回值 my_dict.get(12,'木有')
增添键值对的三种方式:
1> setdefault() 类似于get(),区别在于若键不存在,设置的返回值会作为value自动添加键值对.
2> 直接给字典赋值, 若该键存在,则改写键对应的值; 若该键不存在, 则给字典添加一个新的键值对..
3> update更新操作同理,若键不存在则新增键值对
my_dict.keys() # -- 返回字典中的键
my_dict.values() # -- 返回字典中的值
my_dict.items() # -- 返回字典中的键值对(项)
"""
-- update 更新字典中指定键的值,若键不存在则新增键值对
my_dict.update({'键':值}) my_dict.update(键=值)
"""
>>> a = {'k1':10,'k2':20}
>>> a.update(k1=80) # -- 注意此方式更新,键不需要加引号
>>> a
{'k1': 80, 'k2': 20} # -- 'k1'的值更新为80
>>> a.update({'k1':30})
>>> a
{'k1': 30, 'k2': 20} # -- 'k1'的值更新为30
>>> a.update({'k3':50}) # -- 字典中没有名为'k3'的键,则新增键值对
>>> a
{'k1': 30, 'k2': 20, 'k3': 50}
"""
-- setdefault
"""
>>> a.setdefault('k1',0)
30
>>> a
{'k1': 30, 'k2': 20, 'k3': 50}
>>> a.setdefault('k4',0)
0
>>> a
{'k1': 30, 'k2': 20, 'k3': 50, 'k4': 0}
"""
-- 直接赋值
"""
>>> a['age'] = 18
>>> a
{'k1': 30, 'k2': 20, 'k3': 50, 'k4': 0, 'age': 18}
>>> a['age'] = 22
>>> a
{'k1': 30, 'k2': 20, 'k3': 50, 'k4': 0, 'age': 22}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 删除、复制
删除 -- pop、popitem、del、clear 复制 -- copy
"""
★ --删除
"""
my_dict.pop('指定键') # -- 指定键,删除对应的键值对,返回key对应的value,若指定键不存在,报错
pop(key[,default]) # -- default当key不存在时的返回的值
my_dict.popitem() # -- 返回删除的键值对(py3.6之前是随机删除,py3.6之后是移除最后的)
del my_dict['指定键'] # -- 指定键,删除对应的键值对
my_dict.clear() # -- 清空字典
>>> from random import randint
>>> d1 = {k:randint(1,10) for k in 'abcd'} # -- 字典生成式
>>> d1
{'a': 7, 'b': 3, 'c': 5, 'd': 6}
>>> d1.pop('b')
3
>>> d1
{'a': 7, 'c': 5, 'd': 6}
>>> d1.popitem()
('d', 6)
>>> d1
{'a': 7, 'c': 5}
>>> del d1['c']
>>> d1
{'a': 7}
>>> d1.clear()
>>> d1
{}
"""
★ --复制
"""
my_dict.copy() # -- 复制字典,是浅拷贝!!
>>> d2 = {'a': [1,2,3],'b':'one'}
>>> d3 = d2.copy()
>>> d2 is d3
False
>>> d3
{'a': [1, 2, 3], 'b': 'one'}
>>> d2['b'] = 5
>>> d2['a'].append(6)
>>> d2
{'a': [1, 2, 3, 6], 'b': 5}
>>> d3
{'a': [1, 2, 3, 6], 'b': 'one'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 字典合并
三种 合并方式:
1> dict(dic_1.items()+dic_2.items())
2> dict(dic_1,**dic2) 等同于 dict(dic_1,a=10,b=20) dict(dic_1,dic_2) 报错
3> dic_1.update(dic_2)
# 字典交集、差集、并集
该操作仅限于keys()和items()!!!
& # -- 交集
- # -- 差集
| # -- 并集
>>> a = {'x':1,'y':2,'z':3}
>>> b = {'w':10,'x':11,'y':2}
>>> a.keys()&b.keys()
{'y', 'x'}
>>> a.keys()-b.keys()
{'z'}
>>> a.keys()|b.keys()
{'y', 'x', 'z', 'w'}
>>> a.items()&b.items()
{('y', 2)}
>>> a.items()-b.items() # -- a有的,b没有.
{('z', 3), ('x', 1)}
>>> a.items()|b.items()
{('w', 10), ('x', 11), ('z', 3), ('x', 1), ('y', 2)}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 对字典遍历
但凡对字典进行循环,循环的是它的key值
>>> price = {'a': 205.34, 'b': 612.98, 'c': 45.23}
>>> min(price) # -- 会对字典遍历
'a'
>>> max(price)
'c'
>>> sorted(price)
['a', 'b', 'c']
>>> min(price,key=lambda k:price[k])
'c'
>>> max(price,key=lambda k:price[k])
'b'
>>> sorted(price,key=lambda k:price[k])
['c', 'a', 'b']
>>> x = {1:3,2:4}
>>> sum(x)
3
>>> sum(x.values())
7
>>> my_dict = {'a':24,'g':52,'i':12,'k':33}
>>> dict(sorted(my_dict.items(),key=lambda x:x[1]))
{'i': 12, 'a': 24, 'k': 33, 'g': 52}
>>> sorted(my_dict)
['a', 'g', 'i', 'k']
>>> x = {i:str(i+3) for i in range(3)}
>>> ''.join(x.values())
'345'
>>> ''.join(map(str,x))
'012'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 集合
# 创建、增删改
集合和字典都是不能根据下标来获取和修改数据的
set() frozenset
add update
remove discard clear
set() # -- 创建空集合
{"a","b","c"}、 set(["a","b","c"]) # -- 创建集合
frozenset({1,2,3,4}) # -- 创建不可变集合
my_set.add('abc') # -- 为集合添加元素
my_set1.update(my_set2) # -- 添加新的元素或集合到当前集合中
my_set.remove('abc') # -- 删除结合中已知元素,若元素不存在,报错
my_set.discard('abc') # -- 删除结合中已知元素,若元素不存在,忽略
my_set.clear() # -- 清空集合
"""
-- update
"""
>>> x = {1,2,3}
>>> y = {2,3,4,5}
>>> x.update(y)
>>> x
{1, 2, 3, 4, 5}
>>> y
{2, 3, 4, 5}
>>> x.update('6778') # -- 会进行遍历,结果会自动去重,即集合中的元素具有唯一性
>>> x
{1, 2, 3, 4, 5, '8', '7', '6'}
>>> x.update({'6778'})
>>> x
{1, 2, 3, 4, 5, '7', '6', '8', '6778'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 集合的运算符
A<B -- 判断&NBSP;是否是B的 子集
{1,2,3,4}-{3,4,5,6} -- {1,2} 差集 取一个集合中另一个集合没有的元素
{1,2,3}|{3,4,5} -- {1,2,3,4,5} 并集
{1,2,3}&{2,3,4} -- {2,3} 交集
{1,2,3,4,5}^{4,5,6,7} -- {1,2,3,6,7} 对称差集
# 字典集合的高性能
字典的底层是借助 哈希表 实现的.. 所以 字典的添加、删除、查找元素等操作的平均时间复杂度是O(1).
当然还是要知道, 在 哈希不均匀 的情况下, 最坏时间复杂度是O(n), 但是这种情况很少发生.字典的"快"不会受到数据量的影响, 从含有一万个键值对和含有一千万个键值对的字典中查找,两者花费的时间几乎是没有区别的
# 实验一: 查询元素效率
从测试中我们看到, 随着循环次数越来越多, 列表所花费的总时间越来越长.
但字典查询所花费的时间极少, 查询速度非常快, 即便循环20万次, 花费的总时间也不过0.06秒..
import time
import numpy as np
def test(count: int, value: int):
"""
:param count: 循环次数
:param value: 查询的元素
:return:
"""
lst = list(np.random.randint(0, 2**30, size=1000)) # --拥有一千万个随机数的列表
d = dict.fromkeys(lst) # --根据这个列表构造出含有一千万个键值对的字典
print(f"查询次数为{count}次 --:>")
# --查询元素value是否在列表中,循环count次,并统计时间
t1 = time.perf_counter()
for _ in range(count):
value in lst
t2 = time.perf_counter()
print(" 列表查询耗时:", round(t2 - t1, 2))
# --查询元素value是否在字典中,循环count次,并统计时间
t1 = time.perf_counter()
for _ in range(count):
value in d
t2 = time.perf_counter()
print(" 字典查询耗时:", round(t2 - t1, 2))
# --分别查询一千次、一万次、十万次、二十万次
test(10**3, 22333)
test(10**4, 22333)
test(10**5, 22333)
test(10**5*2, 22333)
"""
查询次数为1000次 --:>
列表查询耗时: 0.09
字典查询耗时: 0.0
查询次数为10000次 --:>
列表查询耗时: 0.58
字典查询耗时: 0.0
查询次数为100000次 --:>
列表查询耗时: 5.42
字典查询耗时: 0.02
查询次数为200000次 --:>
列表查询耗时: 12.2
字典查询耗时: 0.06
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 实验二: 电商后台数据
某电商企业的后台, 存储了每件产品的 ID和价格.. 现需根据给定的某件商品ID,找出其价格..
"""
每件产品的ID和价格的存储,有两个方案:
1> 用列表存储
2> 用字典存储
方案一,假设列表有n个元素,查找需要遍历列表,平均时间复杂度为O(n);
即遍我们先对列表进行排序,排序需要O(nlogn)时间;然后使用二分查找,二分法需要O(logn)时间..
方案二,只需O(1)的时间复杂度就可以完成!!!
"""
products_list = [(143121312, 100), (432314553, 30), (32421912367, 150)]
products_dict = {143121312: 100, 432314553: 30, 32421912367: 150}
def find_product_price(proID, products_list):
for id, price in products_list:
if id == proID:
return price
print(find_product_price(32421912367, products_list)) # 150
print(products_dict[32421912367]) # 150
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
现需统计这些商品有多少种不同的价格.. (假定商品的ID和价格是用列表存储的) 仅仅模拟了十万的数据量, 两者的速度差异就如此之大! 事实上, 大型企业的后台数据往往有上亿乃至十亿数量级, 如果使用了不合适的数据结构, 就很容易造成服务器的崩溃, 不但影响用户体验, 并且会给公司带来巨大的财产损失..
# -- 使用列表统计的时间复杂度为O(n)*O(m) m的大小是不断变大的m<=n
def find_unique_price_using_list(products_list):
unique_price_list = []
for _, price in products_list: # -- 遍历商品列表 O(n)
if price not in unique_price_list: # -- in操作遍历unique列表 O(m),最坏时m=n
unique_price_list.append(price) # -- 末尾插入操作 O(1)
return len(unique_price_list)
# -- 使用集合统计的时间复杂度为O(n)
def find_unique_price_using_set(products_list):
unique_price_set = set() # -- 集合会自动去重
for _, price in products_list: # -- O(n)
unique_price_set.add(price) # -- O(1)
return len(unique_price_set)
# -- 模拟出10万条商品数据
# -- enumerate返回的是一个迭代器!节省了空间!一次只产生一个值在内存里
# 所以len(products_list)会很快很快,但很诧异print(products_list)很慢,慢的是打印的时间!
products_list = list(enumerate(range(100000)))
t1 = time.perf_counter()
find_unique_price_using_list(products_list)
t2 = time.perf_counter()
print(f"列表方案花费时间{t2-t1}") # -- 列表方案花费时间101.28520515
t1 = time.perf_counter()
find_unique_price_using_set(products_list)
t2 = time.perf_counter()
print(f"集合方案花费时间{t2-t1}") # -- 集合方案花费时间0.09064802600001087
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 字典工作原理
不同于其他数据结构, 字典和集合的内部结构都是一张哈希表.. 这使得进行查找 插入 删除操作时很高效!!
参考文档: -_-感觉自己好菜!!
https://zhuanlan.zhihu.com/p/73426505https://www.cnblogs.com/traditional/p/13503114.html
从py3.6开始,字典存储的底层原理被进行了优化.
内置字典已经是有序字典了! 遍历迭代出来的顺序就是存储的顺序.
# -- 可以发现字典最终的结果的顺序就是存储的顺序 c a e d b
>>> from random import randint
>>> a = {k:randint(1,4) for k in 'caed'}
>>> a
{'c': 4, 'a': 2, 'e': 3, 'd': 3}
>>> a['b'] = 33
>>> a
{'c': 4, 'a': 2, 'e': 3, 'd': 3, 'b': 33}
# -- 要注意哦!!集合是不会自动排序的,若遇到了,只是恰巧
# -- 有点疑惑的是,集合和字典底层都使用的是哈希,为何集合最终结果的顺序与存储的顺序不一致
# 猜测是与集合底层的去重原理有关..面向对象学习后再深究.
>>> a = set([1, 3, 8, -2, 99, 98, 77, 1, 5, 3, 77, 12])
>>> a
{1, 98, 3, 99, 5, 8, 12, 77, -2}
>>> set([1,3,2])
{1, 2, 3}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 老版本哈希表
python3.5(含)之前,字典的底层原理
# 初始化空列表
当我们初始化一个空字典的时候, CPython的底层会初始化一个二维数组, 这个数组有8行, 3列
第一列: 哈希值(hash) ; 第二列: 键(key) ; 第三列: 值(value)
每一行有三列, 每一列占用 8byte 的内存空间, 所以每一行会占用 24byte 的内存空间
my_dict = {}
"""
简单描绘此时的内存示意图
"""
[
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 往字典里添加数据
由于Hash值取余数以后, 余数可大可小, 所以字典的Key并不是按照插入的顺序存放的
step1: 调用Python的hash函数,计算键name、age、salary在 当前运行 时的hash值!
特别强调,是当前运行,因为python自带的hash函数不同于传统的hash函数,当python进程关闭后,对同一个值的哈希结果可能不一样
step2: 将name的hash值对8取余数, 若余数为5,则会把该hash值放在刚刚初始化的二维数组中下标为5的这一行的第一列; 底层C语言会使用两个变量存放hash(name)对应的键和值..依次放入hash值所在行的第二、三列..
age、salary同理..
key通过哈希函数映射成一个数值, 作为索引. -- 因而哈希表又称为映射表!
即将key转换成类似于列表的索引,但索引不是连续的..是随机的 所以字典不可能像列表一样通过下标取值、切片..
my_dict['name'] = 'dc'
my_dict['age'] = 18
my_dict['salary'] = 999999
"""
★ --当前运行时的hash值
"""
One_Piece@DCdeMacBook-Air ~ % python3
Python 3.8.7 (v3.8.7:6503f05dd5, Dec 21 2020, 12:45:15)
>>> hash('name')
-3919752505198988186
>>> exit()
One_Piece@DCdeMacBook-Air ~ % python3
Python 3.8.7 (v3.8.7:6503f05dd5, Dec 21 2020, 12:45:15)
>>> hash('name')
-3236881314859452204
"""
★ --此时的内存示意图
1278649844881305901%8 == 5
1545085610920597121%8 == 1
4234469173262486640%8 == 0
"""
[
[-4234469173262486640, id(salary), id(999999)], # -- id(salary)内存地址即指向salary的指针
[1545085610920597121, id(age), id(18)],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, id(name), id(kingname)],
[---, ---, ---],
[---, ---, ---]
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 读取字典数据
存储时 hash('name') % 8 作为数组的索引... 字典通过键取值时,同理, 按照此公式得到索引,再比较判断后取到结果, 时间复杂度为O(1)
"""
★ --假设我们要读取age对应的值
时间复杂度为O(1) -- 因为索引和key、value是一一对应的,所以通过索引我们能瞬间定位到指定的key
"""
step1: Python先计算在当前运行时,age对应的Hash值是多少 hash("age")
step2: hash("age") % 8 结果为1
step3: 对比二维数组索引为1的位置 即第二行第一列的值是否等于 hash("age")
step3: 若等于,取出第二行第三列指针对应内存中的值 结果为18
Ps:因为都是在同一个当前运行时(同一个python进程),进行的hash运算.所以存与读的hash("age")值是一样的的.
"""
★ --假设需要循环遍历字典
"""
Python底层会遍历这个二维数组,如果当前行有数据,那么就返回Key指针对应的内存里面的值.如果当前行没有数据,那么就跳过.. 要清楚晓得遍历字典总是会遍历整个二位数组的每一行..
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 哈希冲突
不同的key进行哈希、取模运算之后得到的 结果/二维数组索引 可能会是相同的 所以上述的存储和读取的方式存在缺陷.. 需要改变策略重新映射得到新的索引,解决哈希冲突!!
哈希冲突主要有两方面: 设置键值对、根据键获取值
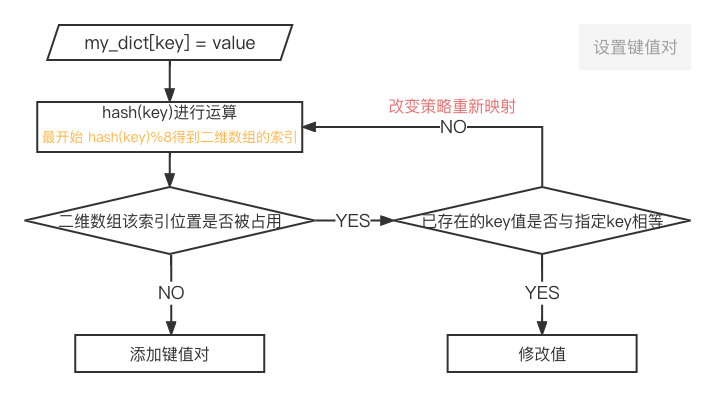
举个例子: (依次执行ABC操作)
my_dict['xx'] = 00 # A
my_dict['yy'] = 11 # B
my_dict['xx'] = 01 # C
通过运算 hash('xx')%8 == hash('yy') % 8 == 1
先成功存储键值对{'xx':00}; 再添加键值对{'yy':11}时发现二维数组索引为1的位置被占用了..
先判断key值是否一样,'yy' != 'xx' Python底层会改变策略重新映射,直到映射出来的索引没有被占用..
假设通过该策略映射出的索引值为4,那么键值对{'yy':11}就会存储到二维数组中索引为4的位置..
进行C操作时,在进行key值是否相等判断时,结果为相等,则直接修改键"xx"的值为01
2
3
4
5
6
7
8
9
10
11
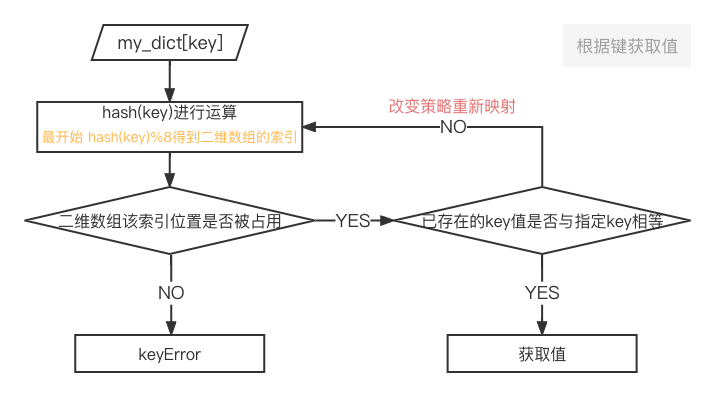
举个例子:
my_dict['zz']
my_dict['xx']
my_dict['yy']
my_dict['zz']运算得到索引,二维数组该索引位置没有数据,直接报错,字典中没有键"zz"
my_dict['xx']运算得到索引后,发现该位置被占用但该位置的key就是'xx',直接获取到值!
my_dict['yy']运算得到索引后,发现该位置被占用且该位置的key不是'yy'..
改变策略(与存储时解决哈希冲突的策略一致),重新得到索引为4,发现此位置的key就是'yy',成功取值.
2
3
4
5
6
7
8
9
所谓的策略不必深究.. 有开放寻址法、链接法等..
开放寻址法: 如果哈希运算后返回的索引位置已经被占用, 则可以通过线性探查、平方探查等找空位置;
链接法: 用链表的方式(增加结点)将哈希运行结果相同的键值对链接起来.. java的hashmap就是这样做的..
# 扩容
2/3 8,16,32... 不断扩容不断稀疏 扩容需要进行旧数据搬迁O(n)级别操作
字典不会像列表那样容量不够时才扩容, 当字典的键值对数量超过当前数组长度的2/3时, 为了保证相关操作的高效性并避免哈希冲突. 数组会进行扩容, 重新分配更大的内存, 8行变成16行, 16行变成32行.
So, 不断的扩容会使哈希表(二维数组)的容量越来越大,这样一来,空闲的位置越来越多(至少占据数组容量的三分之一),哈希表便会越来越稀疏..
还需要注意的是, 扩容后需要重新申请内存空间,将旧数据重新hash到新数组中...是O(n)级别的操作...
Ps: redis使用渐进式rehash,一点一点扩容
# 新版本哈希表
旧哈希表不断扩容,越来越稀疏,会浪费大量的内存空间..
为了避免空间的浪费,py3.6开始对哈希表进行了优化!!
# 初始化空列表
从Py3.6开始, 字典的底层数据结构发生了变化..
初始化一个字典以后, CPython的底层会初始化一个长度为8的一维数组和一个空的二维数组
my_dict = {}
"""
简单描绘此时的内存示意图
"""
# -- 'None'代表这个位置分配了内存但没有元素
indices = [None, None, None, None, None, None, None, None]
entries = []
2
3
4
5
6
7
8
9
# 添加、读取数据
1> 当我要插入新的数据的时候, 始终只是往
entries的后面添加数据, 这样就能保证插入的顺序..
2> 当我们要遍历字典的Keys和Values的时候, 直接遍历entries即可
里面每一行都是有用的数据, 不存在跳过的情况, 减少了遍历的个数!!
3> 哈希表不断扩充, 哈希表越来越稀疏的情况只会出现在entries这个一位数组中...
添加数据:
插入键值对{'name':'dc'}, hash('name')%8 == 5
把indices这个一维数组里面,下标为5的位置的值修改为0
0是键值对{'name':'dc'}在二维数组entries的行索引, 其余同理
依次添加键值对'name'、'age'、'salary', 它仨在entries的行索引依次为 0 1 2..
读取数据:
hash('salary')%8 == 0 ; indices[0] == 2 ; 则salary所对应的键值对在entries[2]中..
Indices 中元素的值, 对应 entries 中相应的索引 !!!
my_dict['name'] = 'dc'
my_dict['age'] = 18
my_dict['salary'] = 999999
"""
★ --此时的内存示意图
1278649844881305901%8 == 5 'name'
1545085610920597121%8 == 1 'age'
4234469173262486640%8 == 0 'salary'
"""
# -- 新哈希表 将存储的数据依次存入了二维数组entries中
# 将key值通过哈希运算得到的索引值与键值对在二维数组中的索引,这两者的对应关系存储到了一维数组indices中
# 一维数组的下标:key通过哈希运算得到的索引值 一维数组该下标的值:键值对在二维数组中的索引
indices = [2, 1, None, None, None, 0, None, None]
entries = [
[1278649844881305901, id(name), id(kingname)],
[1545085610920597121, id(age), id(18)],
[-4234469173262486640, id(salary), id(999999)],
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
新哈希表节省了大量的空间
"""
旧哈希表 3*8*8==192byte
新哈希表的一位数组只占据8byte
3*8*3+8==80byte
节省 (192-80)/80==58%
"""
# -- 与旧哈希表的存储做个对比
[
[-4234469173262486640, id(salary), id(999999)], # -- salary
[1545085610920597121, id(age), id(18)], # -- age
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, id(name), id(kingname)], # -- name
[---, ---, ---],
[---, ---, ---]
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17