 other
other
# 基本用法
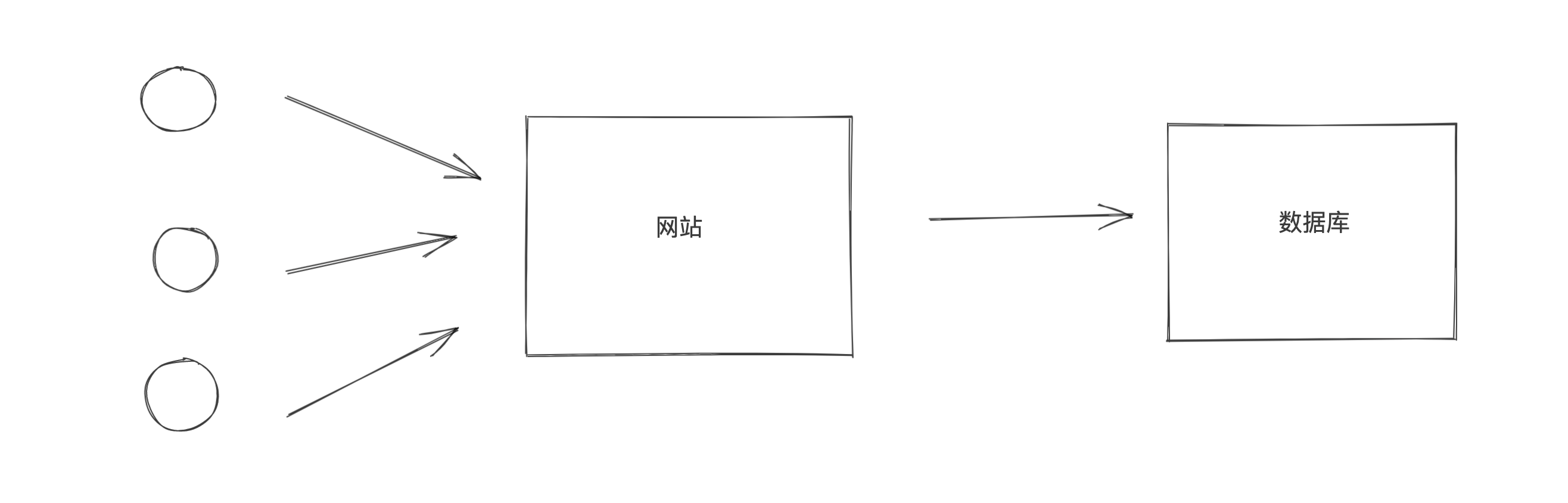
1000客户端并发来 要创建1000个数据库连接吗?创建连接后再回来断掉,下一次又需要再次创建连接?
<1>个数问题 <2>连接后断开再连接消耗内存等资源的问题.需要一个东西控制网站最多连接数据库的数量,够了后来者就排队;
创建连接后不用此连接了但不断开暂时存起来,以便连接的重用.
解决方案: 使用数据库连接池.
pip3.9 install pymysql
pip3.9 install dbutils
1
2
2
import threading
import pymysql
from dbutils.pooled_db import PooledDB
MYSQL_DB_POOL = PooledDB(
creator=pymysql, # -- 使用链接数据库的模块
maxconnections=10, # -- 连接池允许的最大连接数,0和None表示不限制连接数
# -- 初始化时/程序运行时,链接池中至少创建的空闲的链接,0表示不创建
# 最开始的时候没有那么多请求的到来,没必要在内部创建10个连接 "10是上面maxconnections的值"
# 所以最小创建连接数,最开始的时候创建两个,等着用,后面不够用了,再自动去增加.
mincached=2,
# -- 链接池中最多闲置的链接,0和None不限制
# 一开始连接池有两个连接,突然用户猛增连接池满了,过了一会用户量又少了,那么过段时间就要对其进行回收.
maxcached=5,
# -- 该参数值无论设置为多少,生效的只会是0! 不用设置!
# 连接池中最多共享的连接数量.0和None表示全部共享!
maxshared=3,
# -- 连接池中如果没有可用连接,是否阻塞等待. True等待、False不等待然后报错.
# eg: 同时来11个人,有个人就得等.. 因为maxconnections=10
blocking=True,
# -- 一个连接最多被重复使用的次数. None表示无限制! 一般都设置为None!
maxusage=None,
# -- 开始会话(连接)前执行的命令列表. 如: ["set datestyle to ...", "set time zone ..."]
setsession=[],
# -- 使用连接前先ping下MySQL服务端,检查mysql服务是否可用 该参数值通常设置为0
# 0 = None = never 不用ping; 1 = default = whenever it is requested 当用连接时ping
# 2 = when a cursor is created; 4 = when a query is executed ; 7 = always
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='youku',
charset='utf8'
)
def task():
conn = MYSQL_DB_POOL.connection() # -- 去连接池获取一个连接
print("该链接被拿走了!", conn._con)
print("池子里目前有这些链接:", MYSQL_DB_POOL._idle_cache, '\r\n')
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select * from user')
result = cursor.fetchall()
cursor.close()
# -- 并不是关闭连接 而是将连接交还给数据库连接池
conn.close()
def run():
for i in range(10):
t = threading.Thread(target=task)
t.start()
if __name__ == '__main__':
run()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# SQL工具类
基于数据库连接池开发一个公共的SQL操作类, 方便以后操作数据库.
# 单例和方法
# db.py
import pymysql
from dbutils.pooled_db import PooledDB
# 这个类中集成了所有的数据库连接池和pymysql数据的操作
class DBHelper(object):
def __init__(self):
# TODO 此处配置,可以去配置文件中读取。
self.pool = PooledDB(
creator=pymysql,
maxconnections=5,
mincached=2,
maxcached=3,
blocking=True,
setsession=[],
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='root123',
database='userdb',
charset='utf8'
)
def get_conn_cursor(self):
conn = self.pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
return conn, cursor
def close_conn_cursor(self, *args):
for item in args:
item.close()
def exec(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
conn.commit()
self.close_conn_cursor(conn, cursor)
def fetch_one(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
result = cursor.fetchone()
self.close_conn_cursor(conn, cursor)
return result
def fetch_all(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
result = cursor.fetchall()
self.close_conn_cursor(conn, cursor)
return result
db = DBHelper()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
# other.py 导入db这一个对象(它是单例模式实现的)
from db import db
db.exec("insert into d1(name) values(%(name)s)", name="武沛齐666")
ret = db.fetch_one("select * from d1")
print(ret)
ret = db.fetch_one("select * from d1 where id=%(nid)s", nid=3)
print(ret)
ret = db.fetch_all("select * from d1")
print(ret)
ret = db.fetch_all("select * from d1 where id>%(nid)s", nid=2)
print(ret)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 上下文管理
如果你想要让他也支持 with 上下文管理.
with 获取连接:
执行SQL(执行完毕后,自动将连接交还给连接池)
1
2
2
# db_context.py
import threading
import pymysql
from dbutils.pooled_db import PooledDB
# 全局变量
POOL = PooledDB(
creator=pymysql,
maxconnections=5,
mincached=2,
maxcached=3,
blocking=True,
setsession=[],
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='root123',
database='userdb',
charset='utf8'
)
class Connect(object):
def __init__(self):
self.conn = conn = POOL.connection()
self.cursor = conn.cursor(pymysql.cursors.DictCursor)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.conn.close()
def exec(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
self.conn.commit()
def fetch_one(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
result = self.cursor.fetchone()
return result
def fetch_all(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
result = self.cursor.fetchall()
return result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
from db_context import Connect
# 有一个好处 在同一个连接下可以执行多个sql语句
with Connect() as obj:
# print(obj.conn)
# print(obj.cursor)
ret = obj.fetch_one("select * from d1")
print(ret)
ret = obj.fetch_one("select * from d1 where id=%(id)s", id=3)
print(ret)
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12