 ★增量+聚类
★增量+聚类
# 增量学习
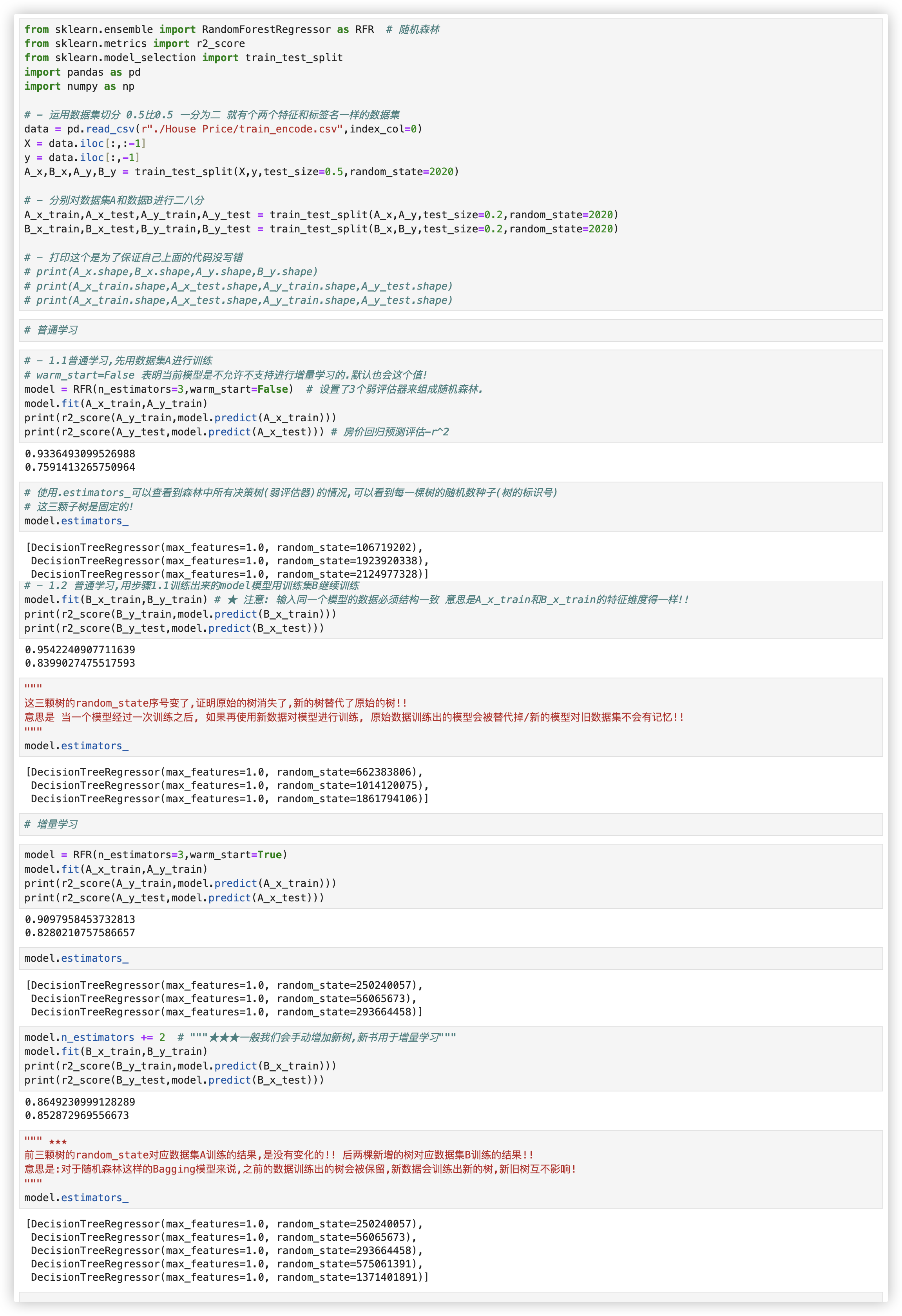
# 普通学习 vs 增量学习
(普通学习)使用两组数据集分别对模型进行训练, 查看训练后的结果:
通常来说, 当一个模型经过一次训练之后, 如果再使用新数据对模型进行训练, 原始数据训练出的模型会被替代掉.
(增量学习) 对于随机森林这样的Bagging模型来说:
意味着之前的数据训练出的树会被保留, 新数据会训练出新的树, 新旧树互不影响!!
# 增量学习的应用
在实际应用中可能会使用几个G以上的数据进行模型的增量学习. 我们这里选择一个几百MB的数据为例..
训练数据集: Big_data/bigdata_train.csv (600Mb).
测试数据集: Big_data/bigdata_test.csv (10Mb).
该数据集是来此Kaggle的五大人格心理特质回归数据集. 它收集了100W+人群在80个问题当中的选项, 得出最终性格分数和分类.
思路: 超大号数据集进行分批次读取,然后基于增量模式多模型进行分批训练..
# step1: 定义数据路径
定义训练和测试数据路径
import pandas as pd
from sklearn.ensemble import RandomForestRegressor as RFR
train_path = 'Big_data/bigdata_train.csv'
test_path = 'Big_data/bigdata_test.csv'
2
3
4
5
# step2: 确定数据总量
确定数据集的数据总量
我们在确定使用增量学习时, 数据应该是巨大到无法直接打开查看的地步(比如100G的数据).
但是, 我们在实现过程中是需要对巨量数据集进行循环批次导入, 那么就必须要知道数据量大概是多少/大概有多少行..
有两种方式实现:
方式1: 使用双向队列deque, 加载数据集的最后5行数据, 查看最后一行数据的索引
from collections import deque # 双向队列,默认右进左出,出去的就销毁了,数据集再大,也不会存在内存问题.
from io import StringIO
with open(train_path,'r') as fp:
# 如果deque的长度已经达到5,那么再添加新的行数据时,最左边(即最早添加的)行会被移除,以确保 deque 的长度始终不超过5.
# 队列中最多只会有5行数据!!因为是依次循环数据集放入队列中的,所以最后管道中留存的是数据集的最后5行数据.
ret = deque(fp,5)
# StringIO提供了一个在内存中读写字符串的方法. 简单理解就是你可以像操作文件一样操作这个字符串!!
# header=None 表示加载 CSV 文件时不将任何一行作为列名,所有的数据都被视为原始数据
d = pd.read_csv(StringIO(''.join(ret)),header=None)
d.head(1)
""" > 可以看到这个数据集一共有995029行数据!!
0 1 2 3 4 5 6 7 8 9 ... 103 104 105 106 107 108 109 110
0 995029 3.0 3.0 5.0 5.0 2.0 3.0 2.0 5.0 5.0 ... 469.0 37.0 1954.0 33.0 0.0 41.0 865.0 -70.6503
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
方式2: 使用read_csv函数的skiprows和nrows参数
- skiprows: 本次导入文件中跳过skiprows的行数据
- nrows: 本次只导入文件中nrows行数据
- 例如: 当skiprows=100, nrows=100, 则read_csv就会导入第101-200行的数据 注意: 当skiprows超出数据量时就会报出EmptyDataError错误信息
for index in range(0,10**7,100000): # index取值范围为0-1000w,初始值为0,步伐为10w
# 从train_path文件中每次跳过index行读取nrows行数据
df = pd.read_csv(train_path,skiprows=index,nrows=1)
print(index) # 打印行索引index,查看为多少时报错,就知道数据集行数的大致范围!!
"""
0
100000
200000
300000
400000
500000
600000
700000
800000
900000
报错 # 证明数据集在90w到100w之间!!然后也可以使用类似的方式,继续精确数据行数.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我们已经知道 数据集在90w行到100w行之间..
测试下. 利用read_csv跳过90w行,每次读取5w行, 不足5w行时, 会不会报错? 答案是 不会.
for i in [900000,950000]:
d = pd.read_csv(train_path,skiprows=i,nrows=50000)
print(d.shape)
# 在read_csv中如果文件剩余数据不足nrows,则read_csv会将实际剩余数据行数读取出来,而不会报错.
# 若跳过的行数skiprows超过了数据集拥有的行数,是会报错的!!
"""
(50000, 111)
(45034, 111) # 所以我们可以精确到行数 为950000+45034= 995034行
"""
2
3
4
5
6
7
8
9
10
# step3: 建模
# 初始模型中弱评估器的数量一般不会太大,因为在增量过程中会增加树的数量
model = RFR(n_estimators=10
,random_state=2020
,warm_start=True # 使用增量模式
,n_jobs=-1 # 调用电脑全部资源进行训练
,verbose=True # 展示模型学习过程
)
2
3
4
5
6
7
# step4: 循环增量学习
for line in looprange:
#如果第一次/首次批量读取文件数据,需要将第一行作为索引而不是真正的数据
if line == 0:
header = 'infer' # 首次读取,read_csv的header=infer表示第一行作为列索引,不作为数据
newtree = 0 # 首次读取,增量过程中增加新树的初始值为0
else:
header = None # 非首次读取时,将读取的第一行作为真正的数据
newtree = 10 # 非首次读取时,每次增加10颗树
# index_col=0表明降第一列作为行索引!
train_subset = pd.read_csv(train_path,header=header,index_col=0,skiprows=line,nrows=50000) # 分批次切分
x_train = train_subset.iloc[:,:-1]
y_train = train_subset.iloc[:,-1]
model.n_estimators += newtree # 为每次增量训练添加子树.
model = model.fit(x_train,y_train)
print('已经完成了%d条数据的训练'%(line+50000))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# step5: 模型评估R^2
test = pd.read_csv(test_path,index_col=0)
x_test = test.iloc[:,:-1]
y_test = test.iloc[:,-1]
model.score(x_test,y_test) # 0.9903561557128914
2
3
4
5
# cuML简介
在使用增量学习时, 如果需要调参, 则需要将增量学习的过程封装成一个函数, 以便在调参过程中的不断调用..
调参过程所需的计算量无疑是巨大的, 需要耐心等待. 当然也可以将算法接入到GPU上进行训练, 减少训练所需的耗时!!
要求用传统模型作GPU加速, sklearn是不支持GPU的,应使用cuML, cuML需要安装一些环境.
cuML是一套快速的, GPU加速的机器学习三方库, 设计用于数据科学和分析任务.
它的API类似于Sklearn的, 这意味着你可以使用训练Sklearn模型的代码来训练cuML的模型.
from sklearn.svm import SVC
from cuml.svm import SVC as SVC_gpu
# ★cuML与Sklearn的API相比,代码没有任何变化!!
2
3
4
# 聚类算法
只需关注两个参数: n_clusters、random_state
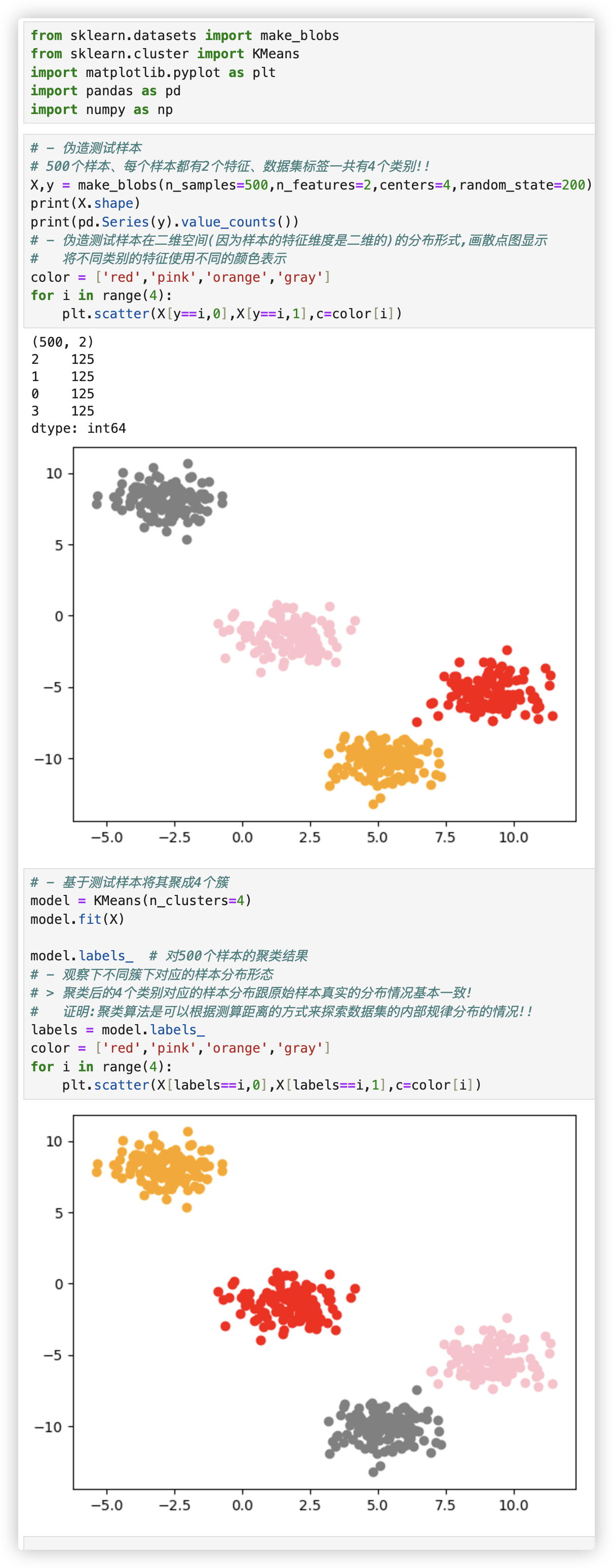
# 首次探索
看聚类后的4个类别对应的样本分布跟原始样本真实的分布情况是否一致? 基本上是一致的!
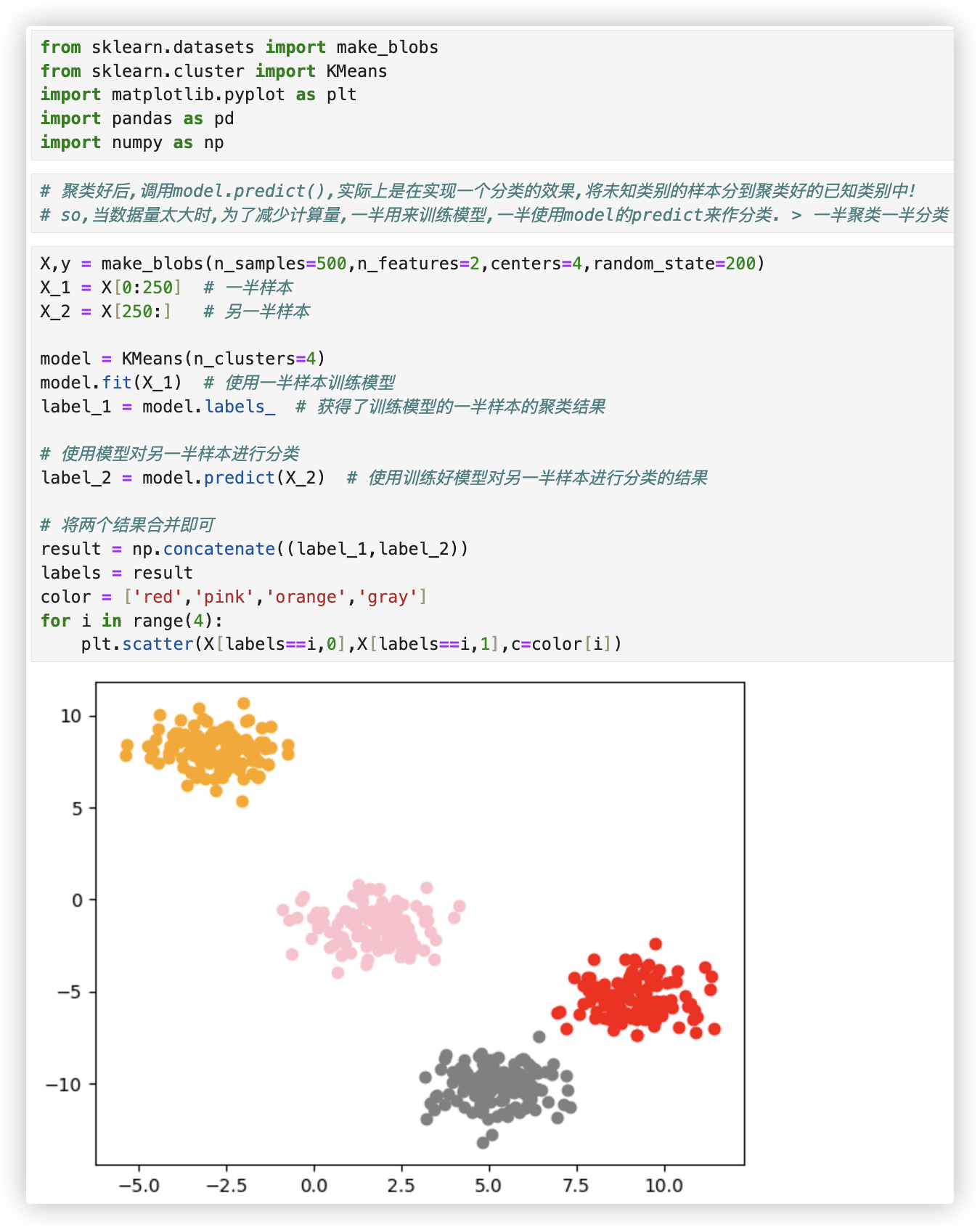
# predict的妙用
我们什么时候需要predict呢? 当数据量太大的时候!
其实我们不必使用所有的数据来寻找质心, 少量的数据就可以帮助我们确定质心了.
当我们数据量非常大的时候, 我们可以使用部分数据来帮助我们确认质心; 剩下的数据的聚类结果, 使用predict来调用.
代码如下:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 聚类好后,调用model.predict(),实际上是在实现一个分类的效果,将未知类别的样本分到聚类好的已知类别中!
# so,当数据量太大时,为了减少计算量,一半用来训练模型,一半使用model的predict来作分类. > 一半聚类一半分类
X,y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=200)
X_1 = X[0:250] # 一半样本
X_2 = X[250:] # 另一半样本
model = KMeans(n_clusters=4)
model.fit(X_1) # 使用一半样本训练模型
label_1 = model.labels_ # 获得了训练模型的一半样本的聚类结果
# 使用模型对另一半样本进行分类
label_2 = model.predict(X_2) # 使用训练好模型对另一半样本进行分类的结果
# 将两个结果合并即可
result = np.concatenate((label_1,label_2))
labels = result
color = ['red','pink','orange','gray']
for i in range(4):
plt.scatter(X[labels==i,0],X[labels==i,1],c=color[i])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 模型评估 - 轮廓系数
上面的示例中. 伪造的数据集的特征维度是二维的, 我们可以画散点图来看肉眼观测聚类的效果..
那数据集的特征维度有10多维呢? 所以我们一定要有一个对模型聚类效果评估的指标.
Q: 是否可以使用整体平方和来作为评估聚类模型聚类的效果?
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X,y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=200)
k_list = [2,4,6,8]
for k in k_list:
model = KMeans(n_clusters=k)
model.fit(X)
print(model.inertia_)
"""
9127.29613886488
922.7731740025497
775.1662159623875
590.8546000914953
1.实际上,在质心不断变化不断迭代的过程中,整体平方和是越来越小的.
我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化了!
2.整体平方和也会随着k的增大而减小
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
A: 通过测试发现, 整体平方和会随着k的增大而减小, 所以说 用整体平方和, k值越大, 聚类效果越好是不对的..
那么如何衡量聚类算法的效果? - 用轮廓系数.
若使用整体平方和, 簇数增加, 其值必定是减少的, 数学可证明.. 所以我们用轮廓系数判断分多少个簇更好!!
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
X,y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=200)
k_list = [2,4,6,8]
for k in k_list:
model = KMeans(n_clusters=k)
model.fit(X)
labels = model.labels_
print(silhouette_score(X,labels))
"""
0.6671635501331497
0.7675237247616932
0.545521187705351
0.315164588776451
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 聚类 - 广告推广优化
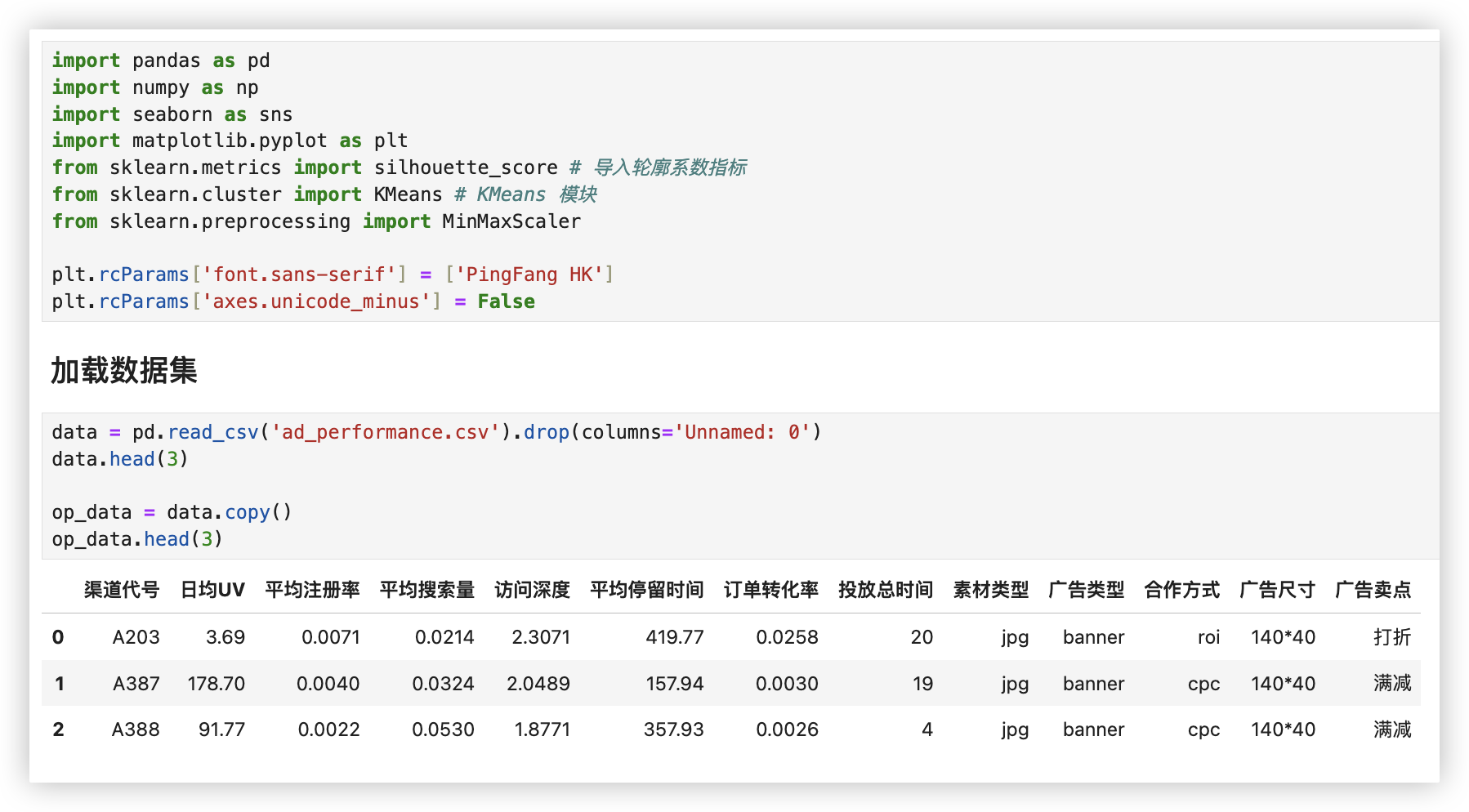
# 加载数据集
# 数据集预处理
# 特征工程
# 聚类建模
# 探究每个簇的含义
详细代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score # 导入轮廓系数指标
from sklearn.cluster import KMeans # KMeans 模块
from sklearn.preprocessing import MinMaxScaler
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
# ■ 加载数据集
data = pd.read_csv('ad_performance.csv').drop(columns='Unnamed: 0')
data.head(3)
op_data = data.copy()
op_data.head(3)
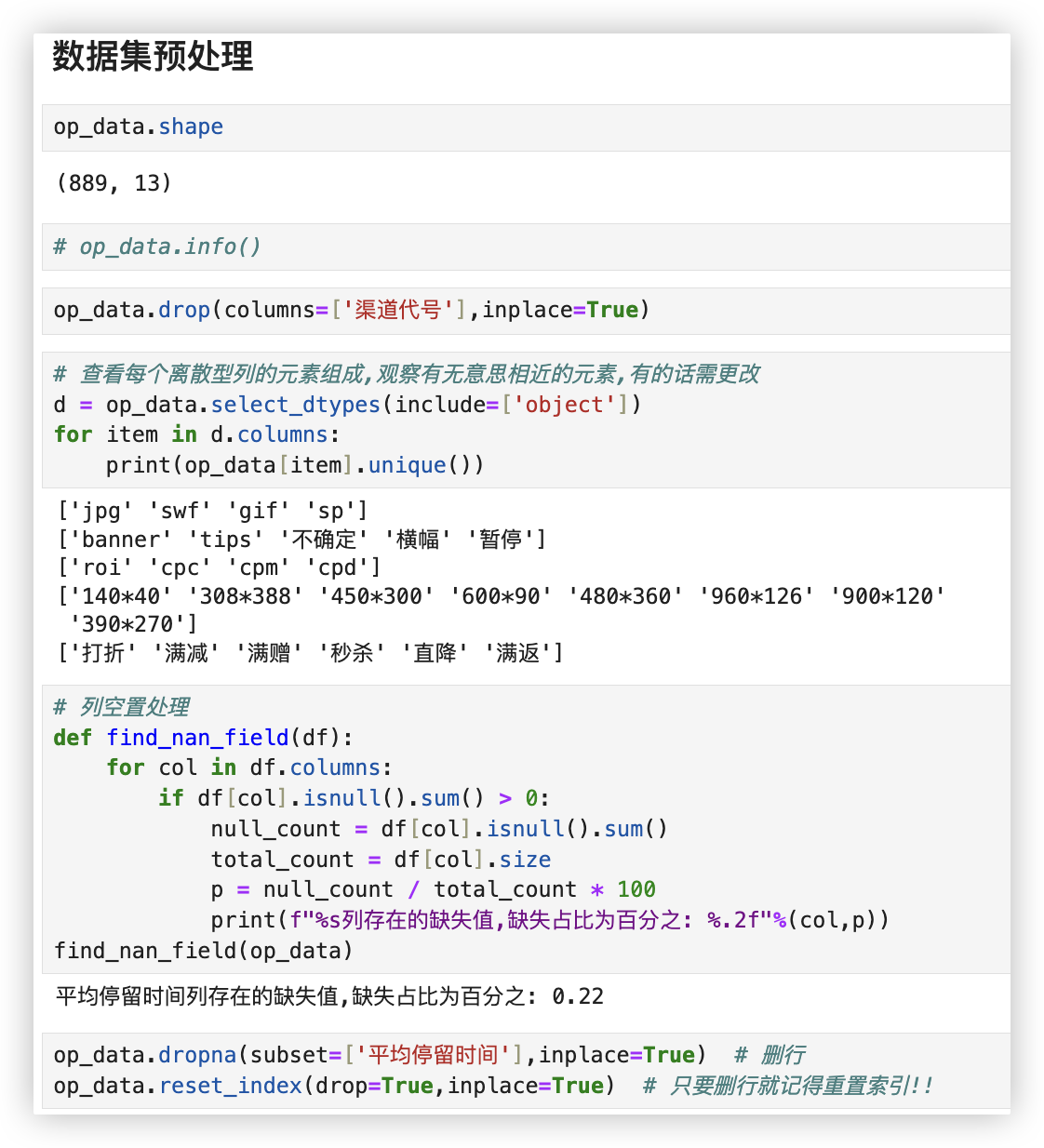
# ■ 数据集预处理
op_data.shape
op_data.info()
op_data.drop(columns=['渠道代号'],inplace=True)
# 查看每个离散型列的元素组成,观察有无意思相近的元素,有的话需更改
d = op_data.select_dtypes(include=['object'])
for item in d.columns:
print(op_data[item].unique())
# 列空置处理
def find_nan_field(df):
for col in df.columns:
if df[col].isnull().sum() > 0:
null_count = df[col].isnull().sum()
total_count = df[col].size
p = null_count / total_count * 100
print(f"%s列存在的缺失值,缺失占比为百分之: %.2f"%(col,p))
find_nan_field(op_data)
op_data.dropna(subset=['平均停留时间'],inplace=True) # 删行
op_data.reset_index(drop=True,inplace=True) # 只要删行就记得重置索引!!
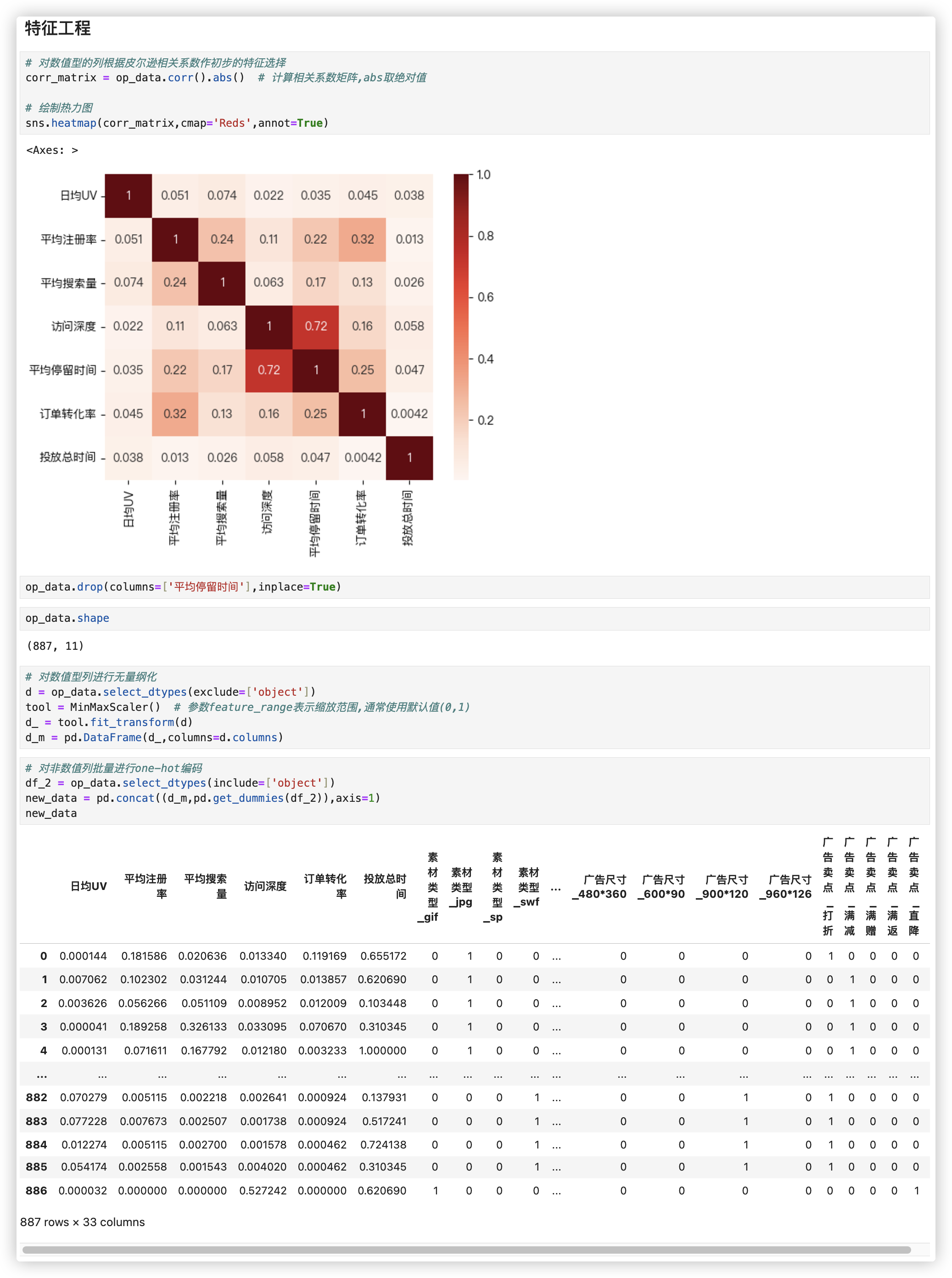
# ■ 特征工程
# 对数值型的列根据皮尔逊相关系数作初步的特征选择
corr_matrix = op_data.corr().abs() # 计算相关系数矩阵,abs取绝对值
# 绘制热力图
sns.heatmap(corr_matrix,cmap='Reds',annot=True)
op_data.drop(columns=['平均停留时间'],inplace=True)
op_data.shape
# 对数值型列进行无量纲化
d = op_data.select_dtypes(exclude=['object'])
tool = MinMaxScaler() # 参数feature_range表示缩放范围,通常使用默认值(0,1)
d_ = tool.fit_transform(d)
d_m = pd.DataFrame(d_,columns=d.columns)
# 对非数值列批量进行one-hot编码
df_2 = op_data.select_dtypes(include=['object'])
new_data = pd.concat((d_m,pd.get_dummies(df_2)),axis=1)
new_data
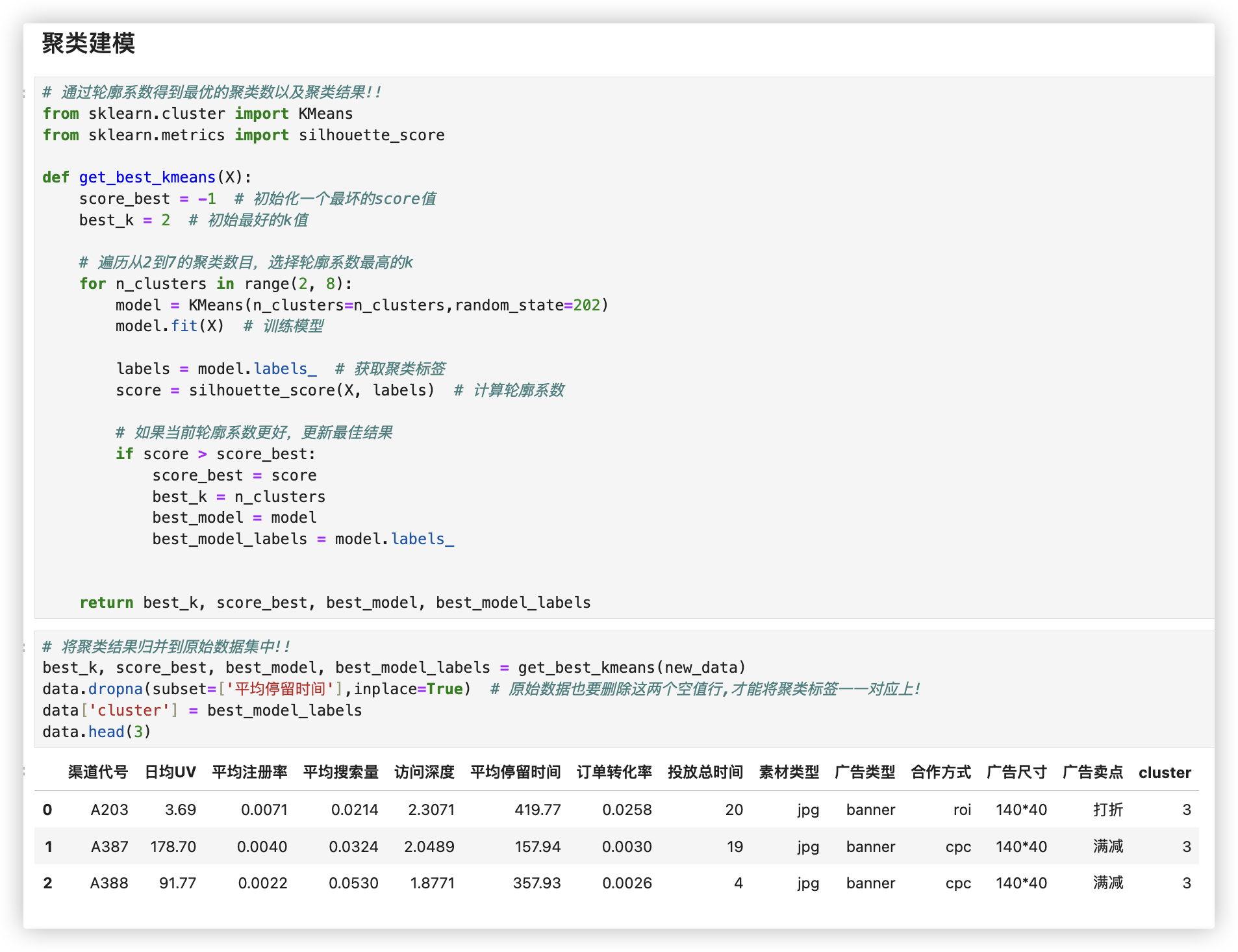
# ■ 聚类建模
# 通过轮廓系数得到最优的聚类数以及聚类结果!!
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def get_best_kmeans(X):
score_best = -1 # 初始化一个最坏的score值
best_k = 2 # 初始最好的k值
# 遍历从2到7的聚类数目,选择轮廓系数最高的k
for n_clusters in range(2, 8):
model = KMeans(n_clusters=n_clusters,random_state=202)
model.fit(X) # 训练模型
labels = model.labels_ # 获取聚类标签
score = silhouette_score(X, labels) # 计算轮廓系数
# 如果当前轮廓系数更好,更新最佳结果
if score > score_best:
score_best = score
best_k = n_clusters
best_model = model
best_model_labels = model.labels_
return best_k, score_best, best_model, best_model_labels
# 将聚类结果归并到原始数据集中!!
best_k, score_best, best_model, best_model_labels = get_best_kmeans(new_data)
data.dropna(subset=['平均停留时间'],inplace=True) # 原始数据也要删除这两个空值行,才能将聚类标签一一对应上!
data['cluster'] = best_model_labels
data.head(3)
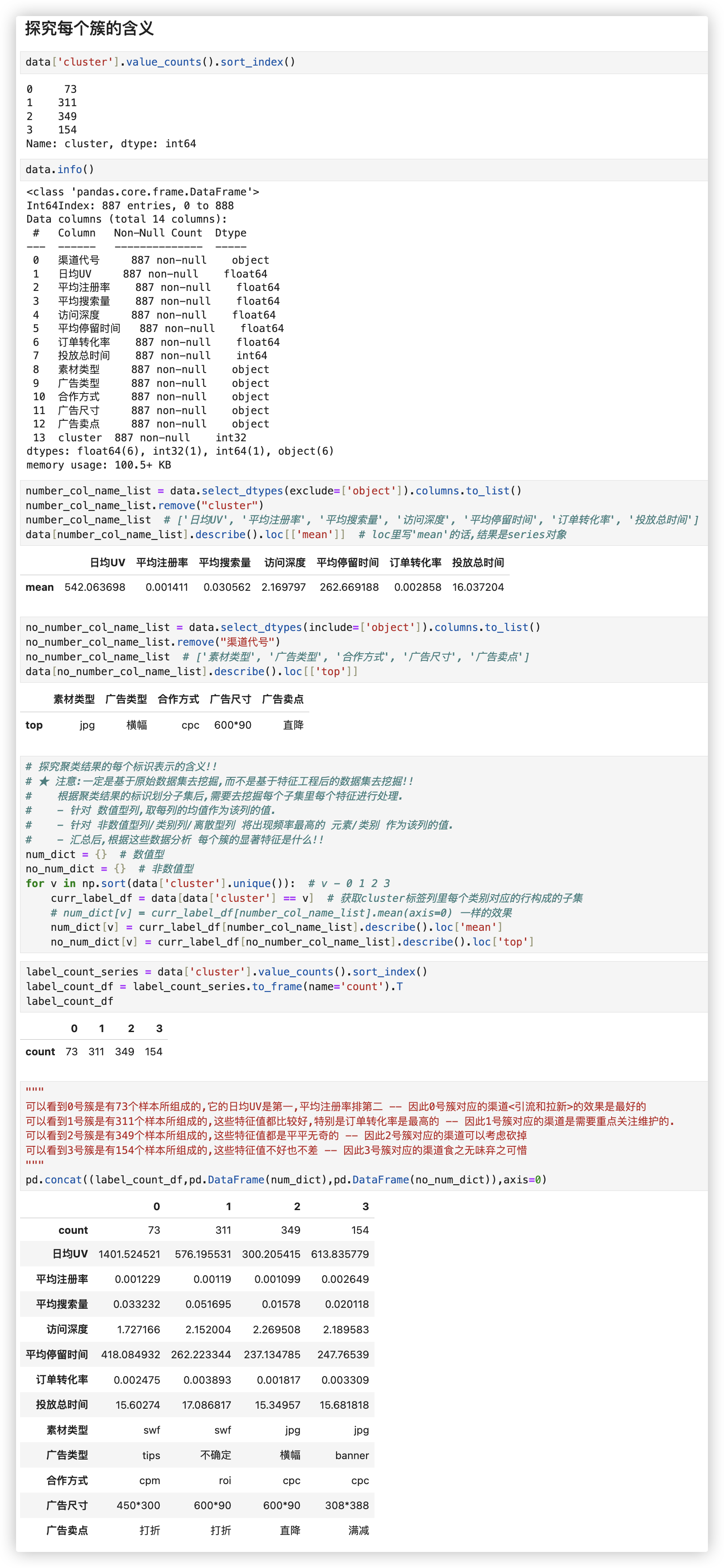
■ 探究每个簇的含义
data['cluster'].value_counts().sort_index()
data.info()
number_col_name_list = data.select_dtypes(exclude=['object']).columns.to_list()
number_col_name_list.remove("cluster")
number_col_name_list # ['日均UV', '平均注册率', '平均搜索量', '访问深度', '平均停留时间', '订单转化率', '投放总时间']
data[number_col_name_list].describe().loc[['mean']] # loc里写'mean'的话,结果是series对象
no_number_col_name_list = data.select_dtypes(include=['object']).columns.to_list()
no_number_col_name_list.remove("渠道代号")
no_number_col_name_list # ['素材类型', '广告类型', '合作方式', '广告尺寸', '广告卖点']
data[no_number_col_name_list].describe().loc[['top']]
# 探究聚类结果的每个标识表示的含义!!
# ★ 注意:一定是基于原始数据集去挖掘,而不是基于特征工程后的数据集去挖掘!!
# 根据聚类结果的标识划分子集后,需要去挖掘每个子集里每个特征进行处理.
# - 针对 数值型列,取每列的均值作为该列的值.
# - 针对 非数值型列/类别列/离散型列 将出现频率最高的 元素/类别 作为该列的值.
# - 汇总后,根据这些数据分析 每个簇的显著特征是什么!!
num_dict = {} # 数值型
no_num_dict = {} # 非数值型
for v in np.sort(data['cluster'].unique()): # v - 0 1 2 3
curr_label_df = data[data['cluster'] == v] # 获取cluster标签列里每个类别对应的行构成的子集
# num_dict[v] = curr_label_df[number_col_name_list].mean(axis=0) 一样的效果
num_dict[v] = curr_label_df[number_col_name_list].describe().loc['mean']
no_num_dict[v] = curr_label_df[no_number_col_name_list].describe().loc['top']
# 算每个簇的样本数
label_count_series = data['cluster'].value_counts().sort_index()
label_count_df = label_count_series.to_frame(name='count').T
label_count_df
"""
可以看到0号簇是有73个样本所组成的,它的日均UV是第一,平均注册率排第二 -- 因此0号簇对应的渠道<引流和拉新>的效果是最好的
可以看到1号簇是有311个样本所组成的,这些特征值都比较好,特别是订单转化率是最高的 -- 因此1号簇对应的渠道是需要重点关注维护的.
可以看到2号簇是有349个样本所组成的,这些特征值都是平平无奇的 -- 因此2号簇对应的渠道可以考虑砍掉
可以看到3号簇是有154个样本所组成的,这些特征值不好也不差 -- 因此3号簇对应的渠道食之无味弃之可惜
"""
pd.concat((label_count_df,pd.DataFrame(num_dict),pd.DataFrame(no_num_dict)),axis=0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
# 综合 - 电信用户流失分析
Churn列是标签列, 值为yes 和 no, 表示用户流失和用户未流失..
# 加载数据集
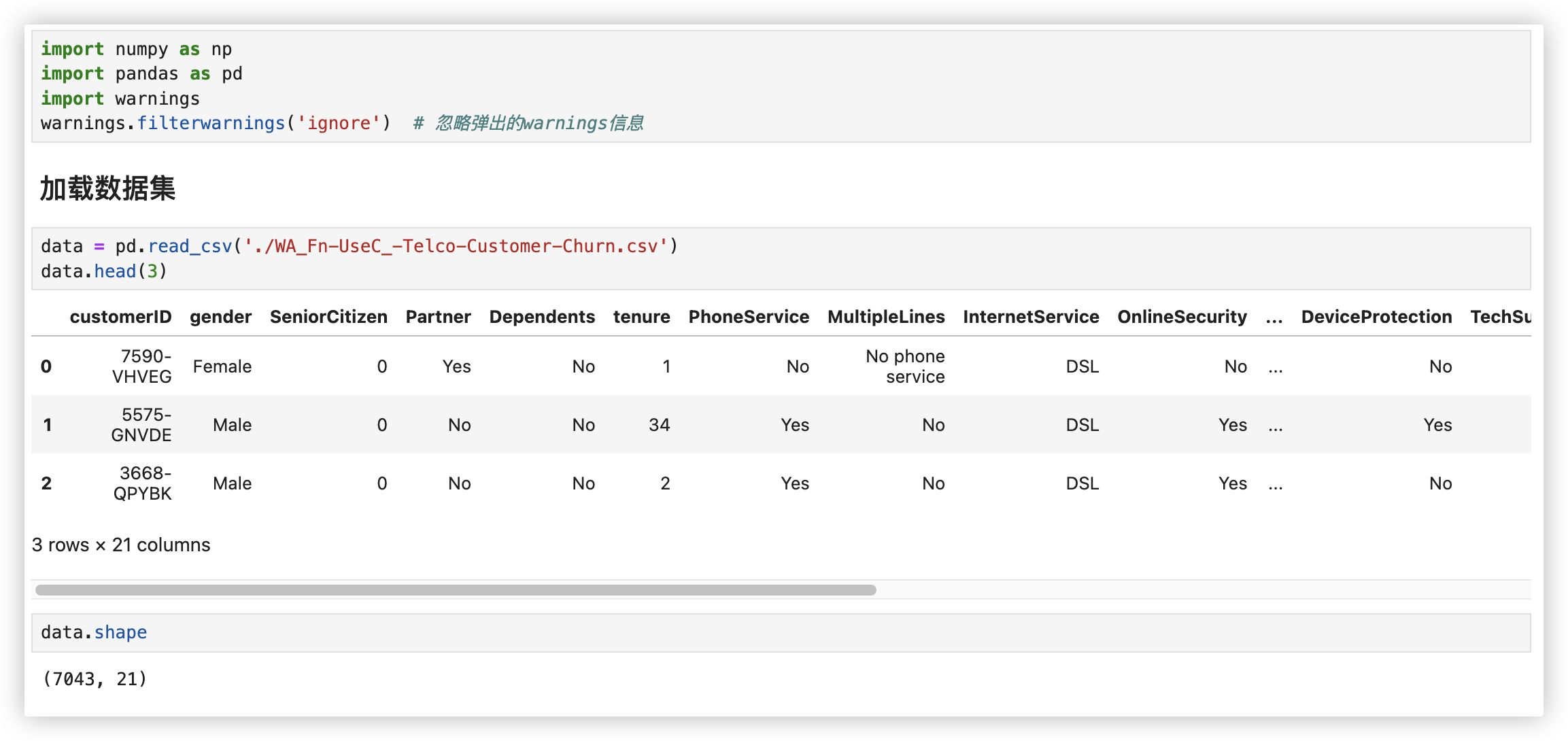
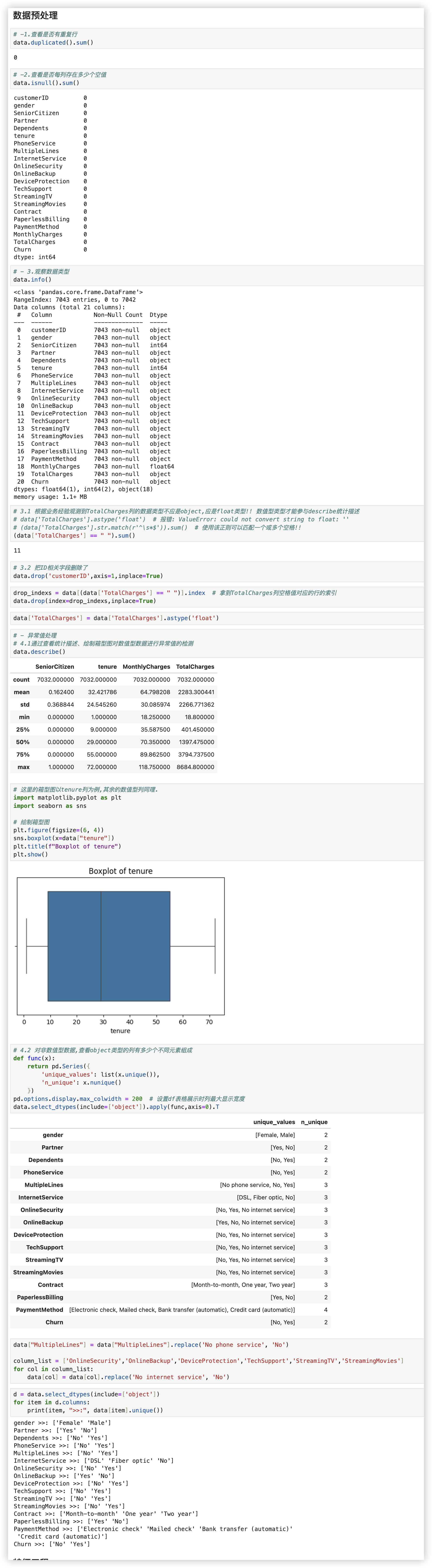
# 数据预处理
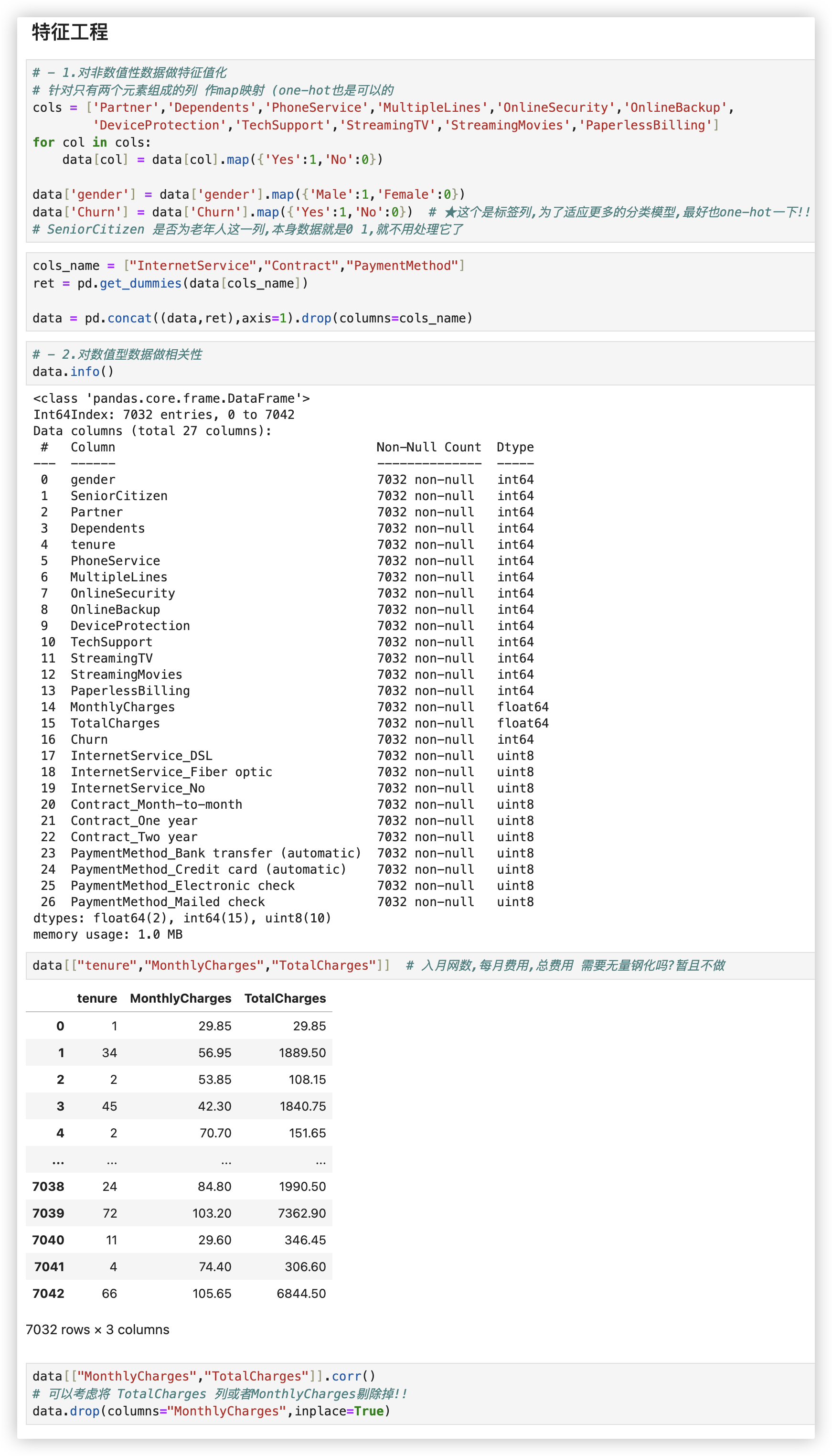
# 特征工程
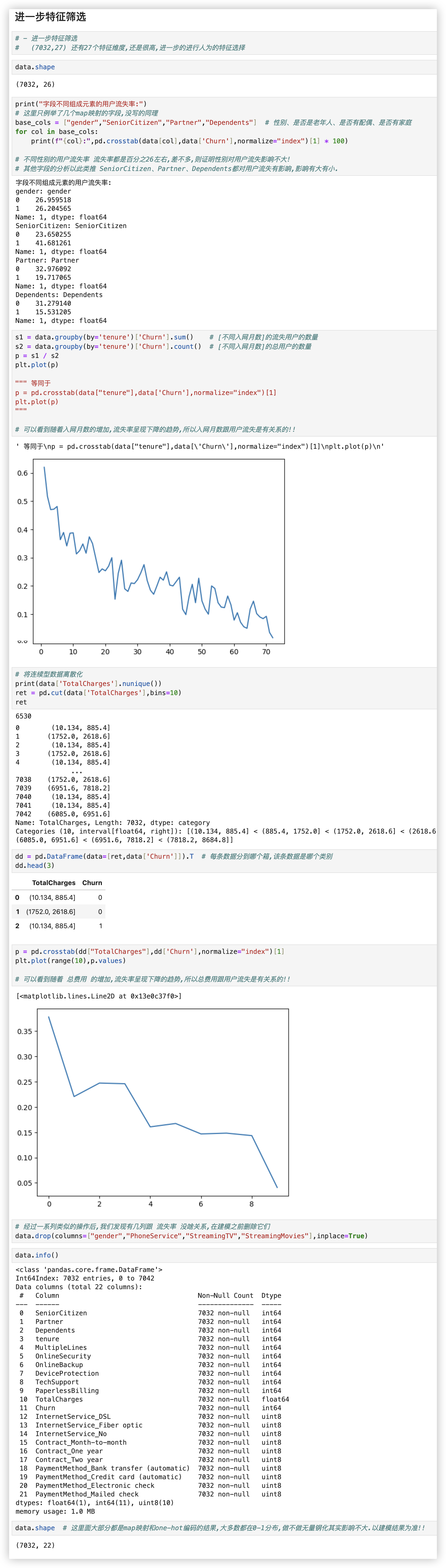
# 进一步特征选择
# 建模分析
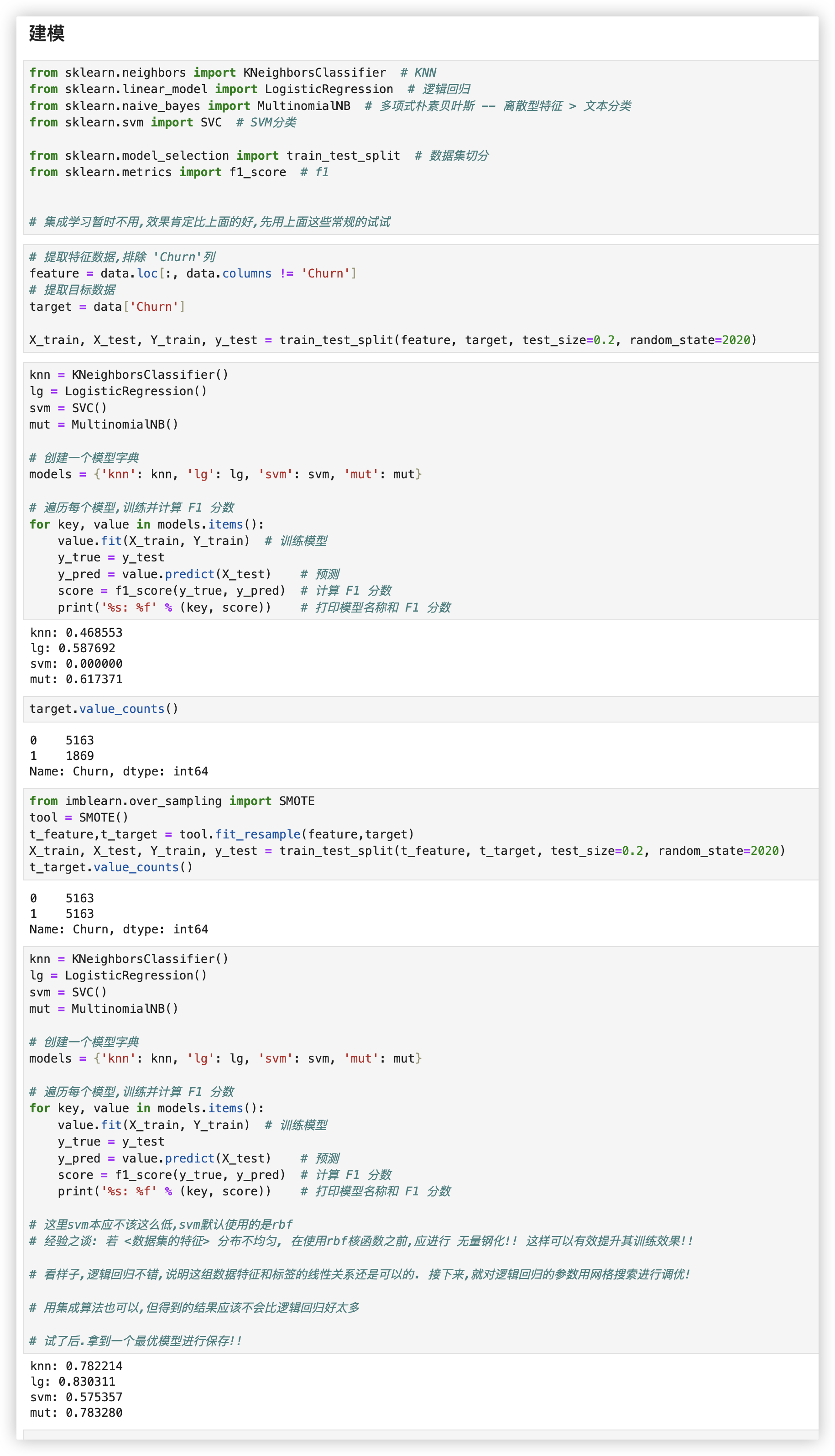
我对特征矩阵做归一化, + 上采样 试了下, SVM有显著的提升!! 0.57提升到了0.8..
feature = data.loc[:, data.columns != 'Churn']
# 提取目标数据
target = data['Churn']
from sklearn.preprocessing import MinMaxScaler
tool = MinMaxScaler() # 参数feature_range表示缩放范围,通常使用默认值(0,1)
feature = tool.fit_transform(feature)
from imblearn.over_sampling import SMOTE
tool = SMOTE()
t_feature,t_target = tool.fit_resample(feature,target)
X_train, X_test, Y_train, y_test = train_test_split(t_feature, t_target, test_size=0.2, random_state=2020)
t_target.value_counts()
knn = KNeighborsClassifier()
lg = LogisticRegression()
svm = SVC()
mut = MultinomialNB()
# 创建一个模型字典
models = {'knn': knn, 'lg': lg, 'svm': svm, 'mut': mut}
# 遍历每个模型,训练并计算 F1 分数
for key, value in models.items():
value.fit(X_train, Y_train) # 训练模型
y_true = y_test
y_pred = value.predict(X_test) # 预测
score = f1_score(y_true, y_pred) # 计算 F1 分数
print('%s: %f' % (key, score)) # 打印模型名称和 F1 分数
"""
knn: 0.788848
lg: 0.783631
svm: 0.805529
mut: 0.761223
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36