Python语言介绍
Python语言介绍
1.python语言的特性 解释、强、动
2.python的垃圾回收机制
3.值类型(值语义)和引用类型(引用语义)
4.字符编码 ASCII、unicode、utf-8、乱码..
2
3
4
# Python语言特性
解释|编译型语言、强|弱类型、动|静类型
# 解释型、编译型
参考链接:
http://c.biancheng.net/view/4136.html
https://zhuanlan.zhihu.com/p/38855233
https://www.jianshu.com/p/3bd1e1e44991
刚开始接触Python的时, 老师就告诉我"python是解释型语言".. 这样的说法没错,但不够具体,不严谨.
首先明确一点,python、java、c这些高级语言不管是编译型还是解释型,都需要转换成计算机能听得懂的机器语言(01的二进制),而转换的过程就需要借助编译器或解释器.
"""
编译型 VS 解释型
"""
○ 编译型语言:
使用编译器,提前将所有源代码一次性转换成二进制指令,即生成一个可执行程序
“一次编译,无限次运行”,生成的可执行程序不再需要源代码和编译器,So,编译型语言可以脱离开发环境运行
但编译型语言不能跨平台,原因有二:
1> 可执行程序不能跨平台,eg:不能将Windows下的可执行程序拿到Linux下使用
2> 源代码不能跨平台,eg:Windows平台下Sleep函数以毫秒为时间单位;Linux平台下则是以秒为单位
○ 解释型语言:
使用解释器,每次执行程序都需要边转换边执行.只将用到的源代码转换成机器码(二进制),用不到的不需处理.
“一次编写,到处运行” 解释型语言是跨平台的,注意!所说的跨平台,是指源代码跨平台,而非解释器跨平台
eg:以Python为例,Python官方针对不同平台(比如 Windows、macOS、Linux)开发了不同的解释器
这些解释器遵守同样的语法,所以同一份源代码才能在不同平台上拥有相同的执行结果
"""
下载程序
"""
当我们说"下载一个程序(软件)"时,不同类型的语言有不同的含义
对于编译型语言,下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的;
对于解释型语言,下载到的是所有源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的.
"""
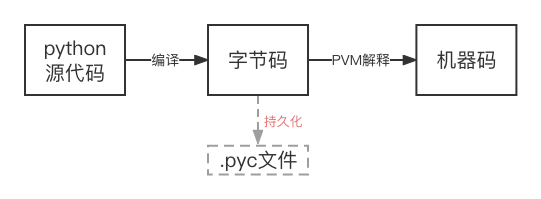
python虚拟机
将需用到的py源代码/需执行的py文件 --(进行编译)-- 字节码 --(通过python的PVM虚拟机逐行解释)-- 机器码
"""
随着Java等基于虚拟机的语言的兴起,我们不能再把语言纯粹地分成解释型和编译型这两种
Python是一门先编译后解释的语言.
编译的结果"字节码"会放到内存的PyCodeObject中,若需持久化保存,会写入pyc文件
什么时候需要pyc?
import的时候,会将import的模块编译成.pyc文件,便于下次运行加快效率
.pyc文件的过期:会跟import的模块最后的修改日期进行对比,若py文件/模块修改了,.pyc文件就会重新生成
# -- python本质与java c# 一样,python程序的执行原理都可以用两个字概括 -- 虚拟机、字节码
1> 在demo.py真正运行之前,python编译器要对py文件中的源代码进行编译.
2> 在程序运行期间,编译结果存在于内存的PyCodeObject对象中,python结束运行后,若编译结果保存到了pyc文件中,那么下一次的运行相同的程序的时候,python会根据pyc文件中记录的编译结果直接建立内存中的PyCodeObject对象,而不用对源文件再次进行编译.
3> demo.py模块会对应一个PyCodeObject对象,而里面的代码块都会一一对应一个PycodeObject对象.是嵌套的!
4> demo.py对应的PyCodeObject对象包含其他PyCodeObject对象.
5> 作用域、代码块、scope的环境、PycodeObject对象都是嵌套的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
我想,正因为python支持跨平台,所以大家更愿意称python是解释型语言!
# 强、动
动态语言: a = 10, a不用指定int 运行时才会进行数据类型的检查
强类型语言: 变量的数据类型一旦被定义,那就不会再改变,除非进行强转
不同类型的变量不能进行运算(不考虑隐式转换) eg: 5 - '3'报错
python很少会自动进行隐式转换...
5/2.5 = 2.0 int类型和float类型计算会自动把int类型转换为float类型
悄悄告诉你,linux中的shell是弱类型语言,shell定义一个变量,随着调用方式的不同,数据类型可随意切换..
# 垃圾回收机制!!!
参考:
https://zhuanlan.zhihu.com/p/108683483★
https://zhuanlan.zhihu.com/p/83251959
Python引入了"标记-清除"与"分代回收"来分别解决引用计数的致命弱点循环引用和引用计数效率低的问题..
# 变量存储
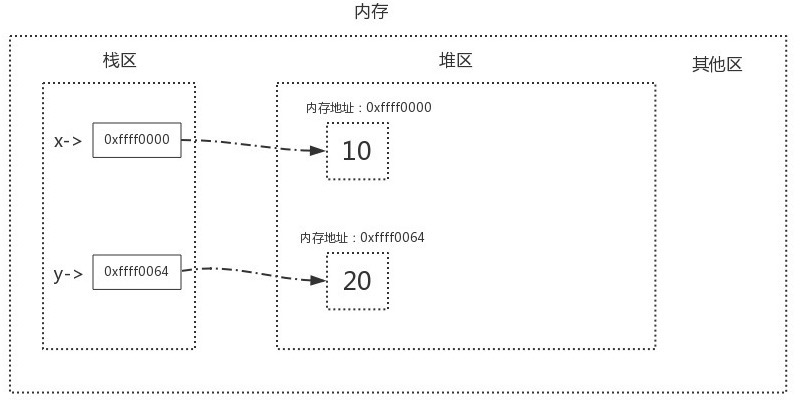
内存中有两块区域: 栈区 stack与 堆区 heap.
在定义变量时, 变量名与值内存地址的关联关系 存放于栈区 (命名空间),变量值 存放于堆区,
内存管理回收的则是堆区的内容
简单理解栈区和堆区,栈区由操作系统自动分配释放,堆区由开发人员分配释放;前者地址连续,具备后进先出的特性,后者地址不连续,类似于数据结构中的链表..
举个栗子, 定义了两个变量 x=10, y=20
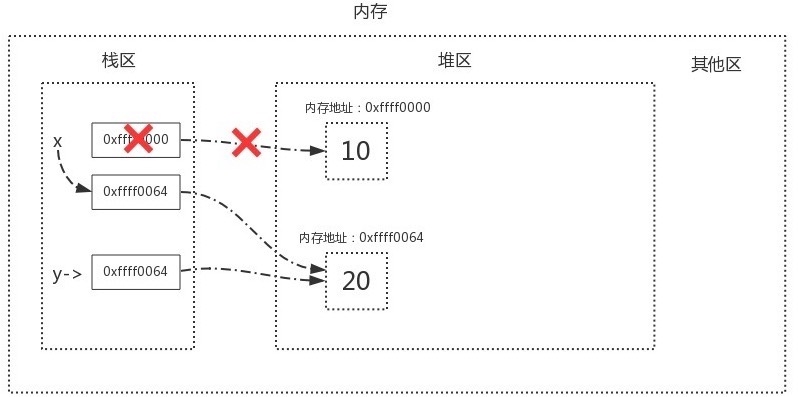
当我们执行 x=y 时, 内存中的栈区与堆区变化如下:
# 引用计数
引用计数:变量值被变量名关联的次数
当值不再被任何名字关联,值的引用计数为0时应该被gc机制回收
○ 引用计数增加 -- 创建a = 1、直接赋值 b=a 、 函数形参 、成为容器元素等
○ 引用计数减少 -- del、被重新赋值、容器销毁、删除容器元素等
引用计数的 致命弱点 : 容器元素的循环引用(也称交叉引用)
a = [1,2,3] # [1,2,3]的引用计数为1
b = [4,5,6] # [4,5,6]的引用计数为1
a.append(b) # [4,5,6]的引用计数变为2
b.append(a) # [1,2,3]的引用计数变为2
del a # [1,2,3]的引用计数变为1
del b # [4,5,6]的引用计数变为1
值不再被任何名字关联,值的引用计数为0,应该被回收但因为循环引用的存在不能被回收..
So,循环引用是致命的,这与手动进行内存管理所造成的内存泄露毫无区别..
Ps:魔法方法`__del__` 析构函数
2
3
4
5
6
7
8
9
10
11
12
# 标记-清除
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时, 就会停止整个程序,然后进行两项工作
第一项则是标记,第二项则是清除 以前面a、b列表的循环引用为例.
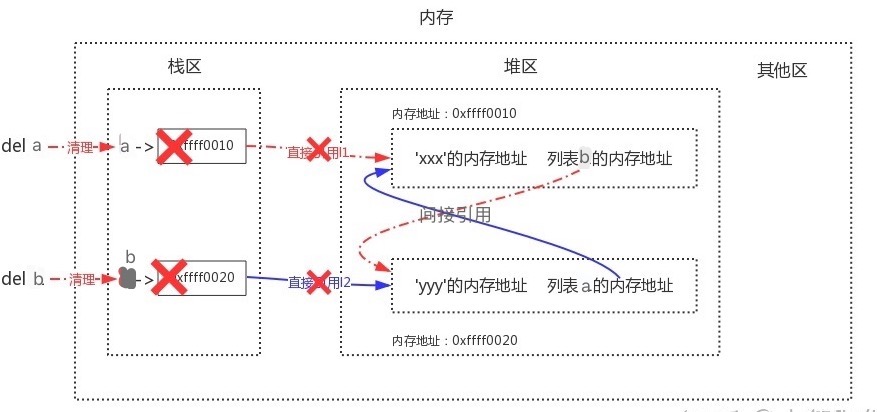
当我们同时删除a与b时,会清理到栈区中a与b的内容,只剩下堆区内二者的相互引用...
于是列表a与b都未被标记存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题!!!
# 分代回收
基于引用计数的回收机制, 每次回收内存, 都需要把所有对象的引用计数都遍历一遍, 这是非常消耗时间的
于是引入了分代回收来提高回收效率, 分代回收采用的是用“空间换时间”的策略
核心思想: 存活的越久的越不可能是垃圾
在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是经常用的变量,gc对其扫描的频率会降低
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代),回收依然是使用引用计数作为回收的依据
假设gc机制划分了3个代: 新生代、青春代、老年代
1> 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一;
2> 当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长);假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间
3> 接下来,青春代中的对象,也会以同样的方式被移动到老年代中.也就是等级(代)越高,被垃圾回收机制扫描的频率越低..
分代回收的弊端:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,该变量的回收就会被延迟..
2
3
4
5
6
7
8
9
10
# 值类型与引用类型
变量分为 -- 值类型(值语义)和引用类型(引用语义)
给爷刻在骨髓里:
引用是啥?引用就是指向.变量名指向自身绑定对象的内存地址!!
一系列的绑定操作都是在传递某一对象的地址给某一变量名进行绑定!!
值类型
int a = 10 必须指定类型,a中只能存整数
把变量的值直接保存在变量的存储区里,例如C语言,采用这种存储方式,每一个变量在内存中所占用的空间就要根据变量的实际大小而定,无法固定下来..
引用类型
a = 10
问: a是数值10内存的别名?(X); a中存的是数值10?(X)
答: 这与上面的 变量存储 部分的内容交相呼应... 简单来说.
a独立开发了一块空间(栈区), 里面保存(维护)的是 变量名与10的内存地址的关联关系.
因而 指向数值10的内存地址,是id(10)的一个引用..
Python变量是引用语义,变量名 引用(指向) 绑定对象的内存地址 变量记录了对象在堆空间中的地址
百度谷歌查阅文档,很多文章中都会这样说
变量名只是给对应的内存地址起了个别名.就像是一个标签贴在了上面!! ☑️
变量即某一对象的内存地址.. ☑️
刚接触python时,这样解释可以方便理解,但这些说法都是简说.
具体来说,python不会对变量名单独作存储.但会将变量名与值内存地址的关联关系存到栈区.
(每个"变量名:id(值)"在栈区中的所占空间的大小都是一样的)
记住!在python里,该栈区有个专业名词,叫做命名空间!!
要条件反射,一旦看到某变量名,就要知道指的是命名空间中该变量名与对象内存地址的关联关系.
2
3
4
5
6
7
8
9
"'变量被赋值 = 变量被引用'"
绑定操作(eg 赋值)就是传递某一对象的内存地址, 接收/被绑定/被赋值 的变量与该内存地址进行绑定
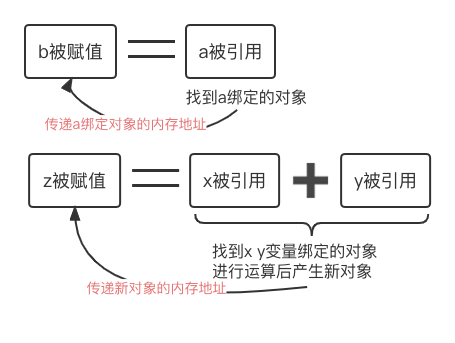
举个赋值操作中最简单的例子:
a=10 b=a
内存(堆区) >> 内存地址xb001存储数值10
命名空间(栈区) >> xb201: a--xb001 xb202: b--xb001
a = 10 # -- 传递对象10的内存地址
a开辟一块空间维护数值10的内存地址 a并没有存10这个值,而是将a变量名与变量值10的地址绑定在了一起
b = a # -- 传递变量a绑定对象的内存地址
'被赋值 = 被引用' 等式右边先执行,首先右边的a变量肯定是能找到的,否则会报错.
a变量被引用,拿到a与其关联的内存地址xb001传递给b变量.
因为python内部的优化机制,只需将数值10的引用计数加1即可.
x=10 y=20 z=x+y # -- 传递一个新对象的内存地址
“=“等号右边的x、y变量被引用,找到各自绑定对象的值进行运算,将运算后的对象的内存地址传递给变量z
"引用" 这个概念,深浅拷贝、函数参数的传递等都与其息息相关..
"python中函数参数的传递" 都是引用,只是要区分引用的对象可变与不可变罢啦..
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 字符编码
首先要知道 在计算机中存储的数据是0101011111的样子,01的高低电平.
b位|比特; B字节; kB千字节;M;G;T 1byte == 8bit
# ASCII
特点: 只有英文字符与数字的一一对应关系,一个英文字符占用1byte
我们可以算一算, 一个字节包含8个bit比特位(8个二进制位),每个位置都可以选择填入0或者1
所以可以表示2^8=256个字符.. 256个字符包含了英文字母以及一些符号.
这就是熟知的 ASCII 编码. 十进制表示:0-127.
# Unicode编码
为了让计算机识别自己国家的语言和英文,中国人订制了GBK..韩国人制定了Euc-kr...
GBK表的特点:
1> 只有中文字符、英文字符与数字的一一对应关系 (Euc-kr同理)
2> 一个英文字符对应1Bytes 2^8=256 可表示所有英文字符
3> 一个中文字符对应2Bytes 2^16=65536 可表示所有中文字符
为了将所有语言统一到一套编码里面,就产生了Unicode编码(所有字符都占用2字节).
UTF-8编码(可变长):
Unicode编码中的一个英文字符会占用两个字节, 若英文字符很多,会浪费大量存储空间以及数据从内存写入硬盘的IO时间...
所以有了UTF-8编码,该编码中一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储
注意一点:文本编辑器输入任何字符都是最先存在于内存中,是unicode编码的,从内存存放于硬盘的过程中数据可以转换成任意其他编码.
举个例子,文本编辑器中写入多国的字符
多国字符—√—》内存(unicode格式的二进制) ——√—》硬盘(utf-8格式的二进制)
编码encode: 字符--内存--硬盘
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程
若文件中包含汉字、韩文等多国语言,unicode能识别多国字符,但GBK不行,所以往硬盘中存储的时候,会使用utf-8(节省空间、减少IO)
解码decode: 硬盘--内存--字符
由其他编码转换成unicode,以及由内存中的unicode转换成字符的过程
有三个问题(不想深究了 记住他三都是对的就行):
1.为啥存在内存中的字符编码格式不用utf-8,而是unicode?
2.unicode编码是如何转成其他编码的?
3.为何只有unicode才会与字符相对应(文本编辑器输入任何字符都是最先存在于内存中,是unicode编码的导致的?)
2
3
4
5
6
7
8
9
10
11
12
13
14
# 乱码是什么?
归根到底,中间有个unicode在作祟...
# -*- coding:utf-8 -*- 指明该文件写入硬盘时采用的编码格式
x = "上"
print(x)
在python2中,将"上"从硬盘读入内存的解码格式是根据文件头的编码格式决定的,这里是utf-8,没有文件头的话,就用编译器默认的编码;
在打印x时,pycharm发现"上"对应的字符编码是utf-8,(只有unicode才会直接对应字符),所以需要进行了解码..
pycharm默认的编码就是utf-8,所以能正确显示..
但用windows的cmd运行该代码,会乱码,因为windows cmd的默认编码是gbk..若使用cmd的默认编码.
"上"用utf-8编码到硬盘中的,用gbk从硬盘中解码就会乱码..
python2的解决方案就是 x = u"上" 保证"上"在内存中的编码是unicode..
在python3中,不需要文件头,在内存中的编码格式都是unicode!!So不管在pychrm还是windows cmd上都能正确显示!!!
(简单理解 字符与unicode是一起的!!!别分解成 字符--encode--unicode啦.. 我累了.)
具体来说,python3中字节bytes与Unicode字符的转化:
bytes:包含8位的二进制数;
str:包含unicode字符.
Unicode字符 ==> `encode()` ==> bytes二进制数据 即 字符 encode 二进制
bytes二进制数据 ==> `decode()` ==> Unicode字符 即 二进制 decode 字符
"""
chr() 将一个整数转换为一个Unicode字符
ord() 将一个字符转换为它的ASCII整数值
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Python中的下划线
# 环境变量
Cpython就是翻译工作,将python代码翻译成计算机能听懂的!
1. 环境变量
- 在命令行下,使用可执行文件,需要到可执行文件的路径下执行
- 若想在任意路径下执行可执行文件,就需要在环境变量里配置
2. 设置环境变量
- 用户变量: 当前用户登陆到系统,能够识别的环境变量
- 系统变量: 所有用户登陆到系统,能够识别的环境变量
- python配置: 安装时,add to path选中
- python安装路径: 找到 python.exe
- python安装路径的script路径: 找到 pip.exe
3. 需要注意,在终端输入的python、pip install,执行的是哪个环境
与在环境变量里设置的a先后顺序有关
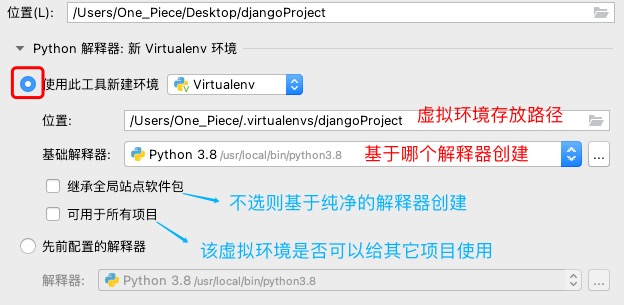
4. pycharm中开发项目,需要注意使用的解释器是哪个
pycharm可以创建虚拟环境,虚拟环境用于解决版本共存的问题.
mac而言:
默认在 /Library/Frameworks/Python.framework/Versions 这个路径下
/Library/Frameworks/Python.framework/Versions/3.8/bin 有unix可执行文件pip
/Library/Frameworks/Python.framework/Versions/3.8 有个unix可执行文件python
Ps:随便网上搜一篇,下载应用点击下一步下一步就在mac上安装好python啦!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20