 pandas绘图
pandas绘图
绘图! 绘图! 绘图! (*≧ω≦)
★★★
■ matplotlib绘图
- 线图: [两组数组] 分别作为x轴y轴的值,同一位置的元素一一对应,构成每个点的坐标 > 点连成线
- 散点图: [两组数组] 分别作为x轴y轴的值,同一位置的元素一一对应,构成每个点的坐标 > 点
- 条形图/柱状图
eg: 城市 北 上 广
2019 1w 1.2w 2w
2020 2w 3.5w 2.2w
示例中是 城市+2019、城市+2020 画了两次,每次都是 [两组数组]
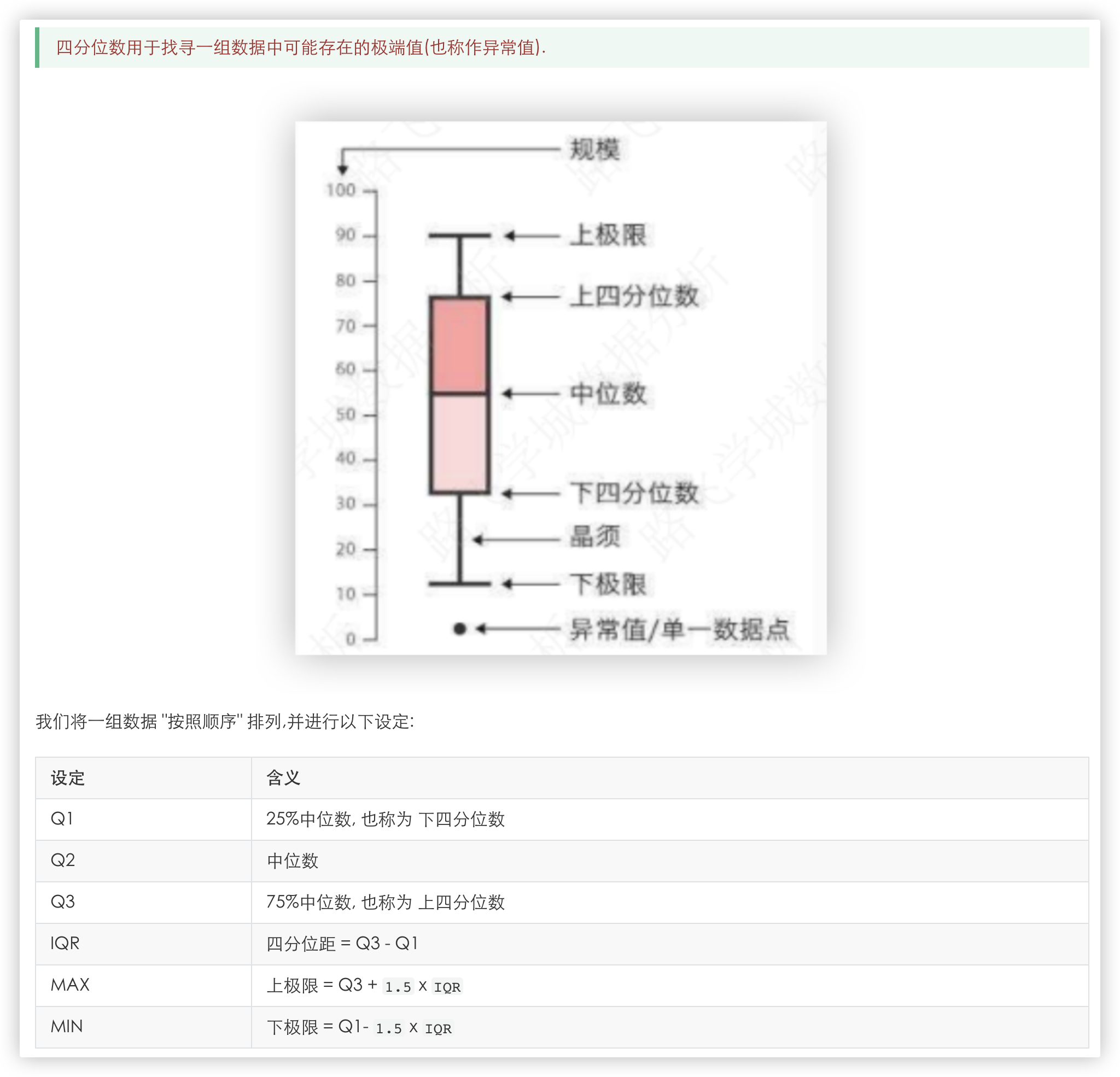
- 箱线图: 找出 <n组数组 n>=1 > 中的异常数据
- 饼图: <一组数组> 中每个元素占总体的百分比
- 直方图: 将<一组数组> 的取值范围分为若干个区间,计算每个区间里元素个数的数量
■ seaborn绘图
- 线性图:
给定一个df,取出两列数值型数据,分别作为x轴和y轴,两组数据中的元素一一对应,构成每个点的坐标. > 点连成线
"hue" 再取一列字符串类型数据,作为分类/分组的依据,有多少类别就会画多少条线.
- 散点图:
与线性图同理,不过散点图是点,线性图是点连成线
- 分类散点图:
对比散点图,散点图是取两列数值型数据;分类散点图是取一列数值型数据,一列分类相关的字符串数据.
分类散点图就多进行了一次分类,其余的没啥变化.
- 柱状图/条形图:
□ 基础版
给定一个df,取出两列数据,一列为类别相关的字符串数据,另一列是数值型数据. 这两列数据随意分配给x、y轴.
可以算出类别相关的那组数据有多少个类别,根据类别对数据型的那一组数据进行分组(一个分组对应一个类别),求出每组的均值.
□ 升级版
给定一个df,取出两列数据,一列为类别相关的字符串数据A,另一列是数值型数据B. 这两列数据随意分配给x、y轴.
"hue" 再另外取一列类别相关的字符串数据C,此时,就可以分两次类. 因此,最后会有 A的类别*C的类别 个柱子!! 每个柱子默认都是均值.
- 箱式图:
给定一个df,取出两列数据,一列为类别相关的字符串数据A,另一列是数值型数据B.
根据A的类别对B进行分组,找出每个组里的异常数据.
- 直方图:
给定一个df,取出一列数值型的数据,将其取值范围分为若干个区间,计算每个区间里元素个数的数量
- 热力图:
关键在于转换下df的结构,将df的value全部变成数值!
■ Plotly Express绘图
- 注意,Plotly的柱状图/条形图的柱子的最高点默认是总值,不是平均值.
- 注意,有些图的color参数是作为了分类标准的哦!
思考: 条形图与直方图区别
例如有100个学生的身高 >>
柱状图: 对比男生的平均身高和女生的平均身高
直方图: 根据数值的大小分区间进行分组统计,统计100个学生在各个身高段的分布情况
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# matplotlib绘图
# 线图
参数解释
- 函数功能: 展现变量的变化趋势/线性关系
- 调用方法: plt.plot(x, y, linestyle, linewidth,color,marker, markersize, markeredgecolor,
markerfactcolor, label, alpha)
x: 指定折线图的x轴数据;
y: 指定折线图的y轴数据;
linestyle: 指定折线的类型, 可以是实线、虚线、点虚线、点点线等,默认文实线;
linewidth: 指定折线的宽度
marker: 可以为折线图添加点,该参数是设置点的形状;
markersize: 设置点的大小;
markeredgecolor: 设置点的边框色;
markerfactcolor: 设置点的填充色;
label: 为折线图添加标签,类似于图例的作用;
2
3
4
5
6
7
8
9
10
11
12
13
基本使用
import numpy as np
import matplotlib.pyplot as plt
# 中文乱码的处理
# plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置微软雅黑字体(测试了下,配置它会报错.
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常的显示负号
x = np.linspace(0, 10, 30) # 生成0-10之间30个等差数列,包含0和10
plt.figure(figsize=(10, 10)) # 设置画布大小,figsize=(宽, 高),单位为英寸
# ■ 用plot方法画出x=(0,10)间sin的图像
plt.subplot(421) # 把画布分割成4行2列,放在第一个位置
# ★★★ np.sin(x)会将x的每个元素计算一次正弦值
# plot第一个参数是横坐标,第二个参数是纵坐标,一一对应在图中画出
plt.plot(x, np.sin(x))
# ■ 用点加虚线的方式画出x=(0,10)间sin的图像
plt.subplot(422) # 把画布分割成4行2列,放在第二个位置
plt.plot(x, np.sin(x), linestyle='--', marker='o')
# ■ 同时绘制cos和sin图像在同一图中
plt.subplot(4, 1, 2) # 把画布分割成4行1列,放在第二个位置
plt.plot(x, np.sin(x), color='b', linestyle='-', marker='+')
plt.plot(x, np.cos(x), color='g', linestyle='--', marker='*')
# ■ 画出sin和cos图像,并添加图例
plt.subplot(4, 1, 3)
plt.plot(x, np.sin(x), color='b', linestyle='-', marker='+', label='sin(x)') # 或'b-+'
plt.plot(x, np.cos(x), color='g', linestyle='--', marker='*', label='cos(x)') # 或'g--*'
plt.legend(loc='upper right')
# ■ 绘制折线图
plt.subplot(4, 1, 4)
y = np.random.randn(100)
x = np.arange(100)
plt.plot(x, y)
plt.tight_layout() # 自动调整子图间距
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
结果截图如下:
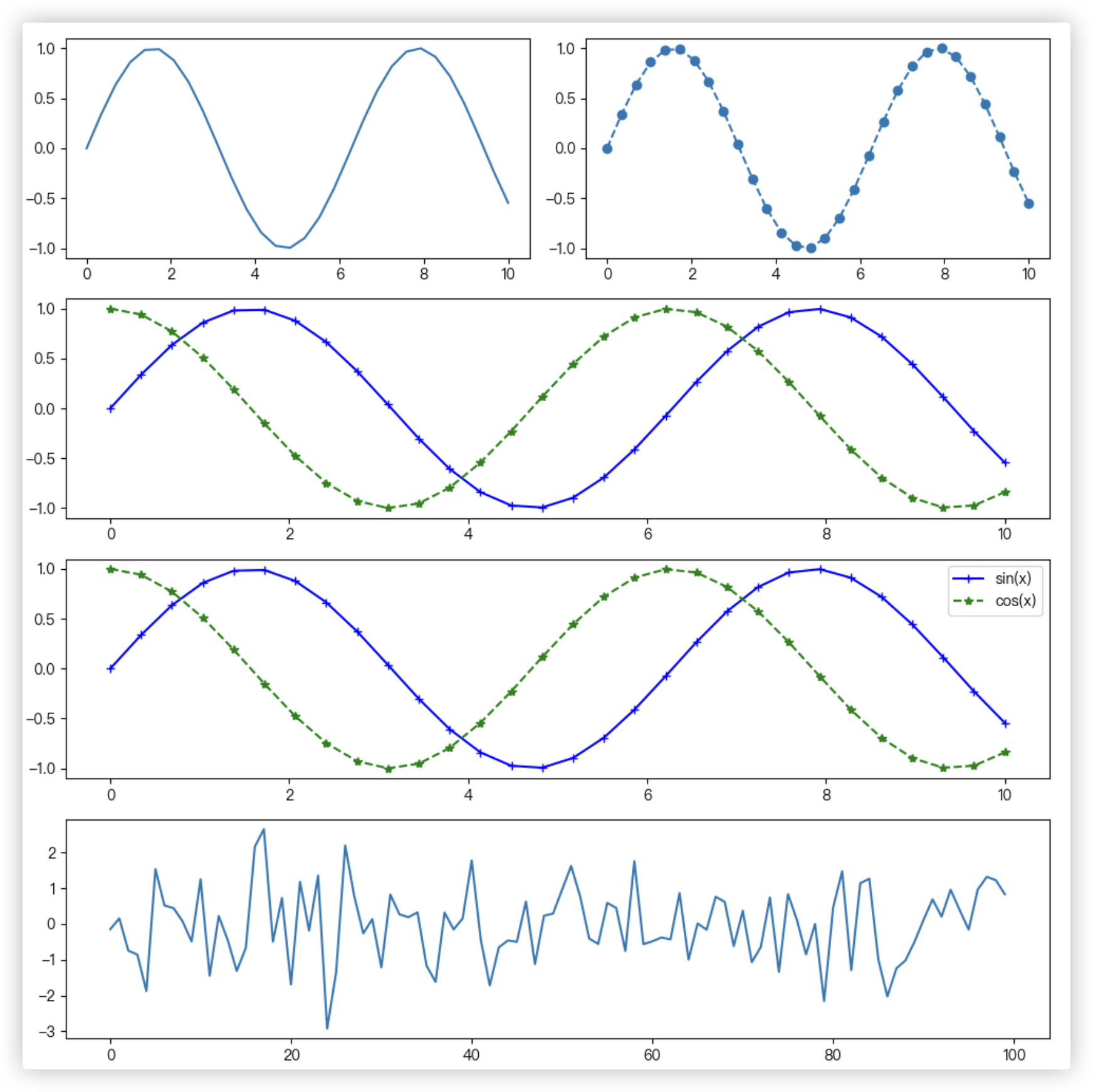
# 散点图
参数解释
函数功能: 散点图,寻找变量之间的关系 (机器学习中用的比较多
调用方法: plt.scatter(x, y, s, c, marker, cmap, norm, alpha, linewidths, edgecolorsl)
x: x轴数据
y: y轴数据
s: 散点大小,大小的个数与散点个数一致
c: 散点颜色,颜色的个数与散点个数一致
marker: 散点图形状
cmap: 指定某个colormap值,该参数一般不用,用默认值
alpha: 散点的透明度
linewidths: 散点边界线的宽度
edgecolors: 设置散点边界线的颜色
2
3
4
5
6
7
8
9
10
11
12
基本使用
import numpy as np
import matplotlib.pyplot as plt
# 中文乱码的处理
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 15), dpi=80) # figsize=(宽, 高,分辨率),宽高单位为英寸,分辨率单位是每英寸多少点
# ■ 绘制两组100个随机数的散点图
plt.subplot(311)
x = np.random.randn(100)
y = np.random.randn(100)
plt.scatter(x, y)
# ■ 增加颜色,大小,透明度设置 -- 气泡图
plt.subplot(312)
colors = np.random.randn(100)
x = np.random.randn(100) # 在[0,1)之间生成100个数
y = np.random.randn(100)
plt.scatter(x, y,
# 大小 你也可以写100个值,表示每个点的大小
s=np.power(10 * x + 20 * y, 2), # 和散点个数一致 此处power函数用于幂计算
# 颜色
c=colors, # 和散点个数一致
# 标注/散点图形状
marker='o',
# 透明度
alpha=0.9)
# ■ 散点图分三类并显示图例
plt.subplot(3, 1, 3)
colors = ['r', 'y', 'b'] # 设置颜色
markers = ['*', 'o', 'x'] # 设置标注
x = np.random.randn(100)
for i in range(0, 3):
y = np.random.rand(100)
plt.scatter(x, y, s=60, c=colors[i], marker=markers[i])
plt.legend(['class1', 'class2', 'class3'], loc='best') # best表示自动选择最佳位置
plt.tight_layout() # 自动调整子图间距
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
结果截图如下:
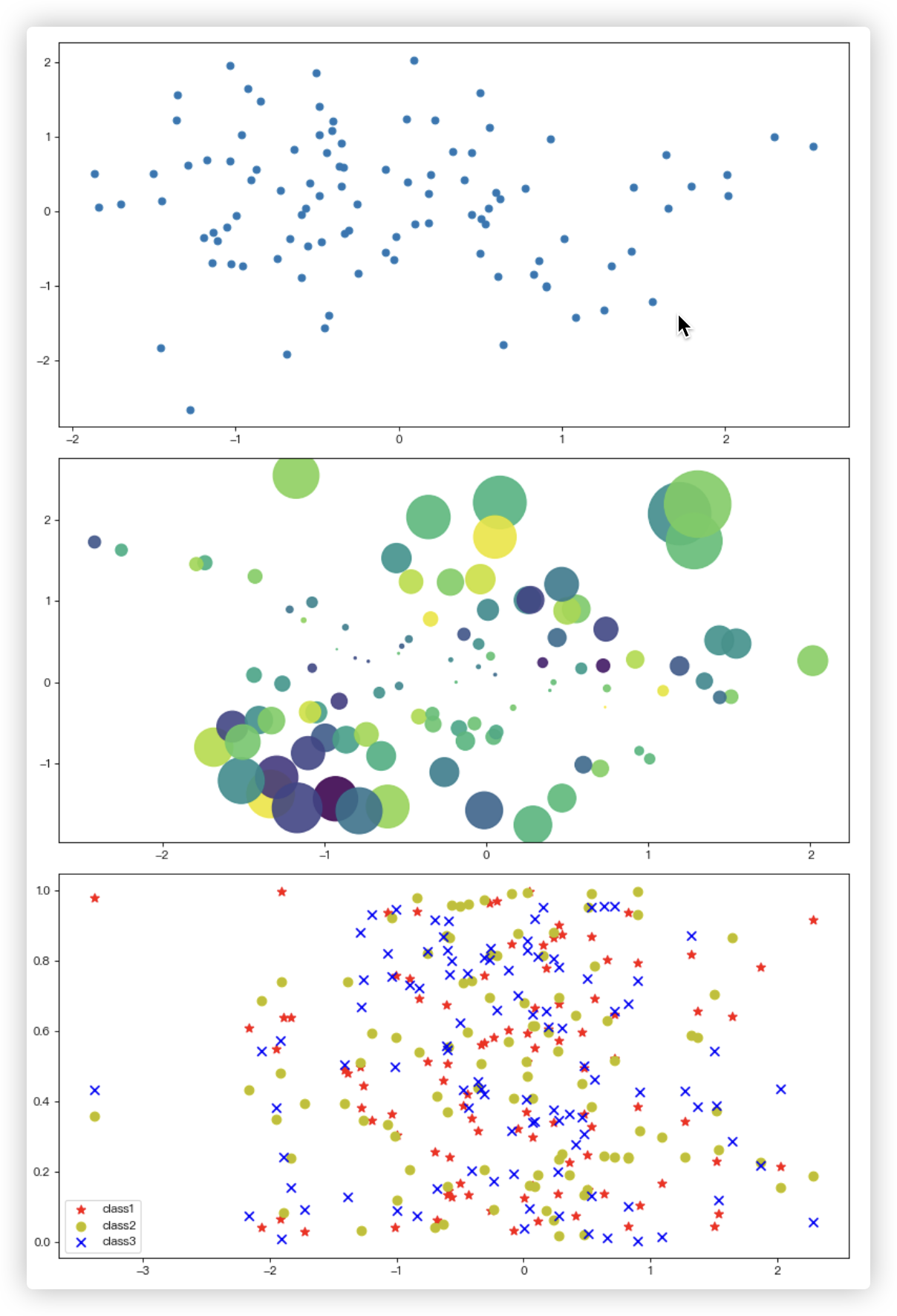
# 条形图/柱状图
参数解释
- 调用方法: plt.bar(x, y, width,color, edgecolor, bottom, linewidth, align, tick_label, align)
x: 指定x轴上数值
y: 指定y轴上的数值
width: 表示条形图的宽度,取值在0~1之间,默认为0.8
color: 条形图的填充色
edgecolor: 条形图的边框颜色
bottom: 百分比标签与圆心距离
linewidth: 条形图边框宽度
tick_label: 条形图的刻度标签
align: 指定x轴上对齐方式, "center","edge"边缘
2
3
4
5
6
7
8
9
10
11
基本使用
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 15), dpi=80)
# ■ 简单垂直条形图
plt.subplot(321)
GDP = [36102, 38700, 14083, 25002] # 2020年四大直辖市GDP水平
city = ['北京市', '上海市', '天津市', '重庆市']
plt.bar(city, GDP, color='steelblue', alpha=0.8)
plt.ylabel('GDP')
plt.title('2020年四大直辖市GDP条形图')
# 为每个条形图添加数值标签.
for x, y in enumerate(GDP):
# x哪个柱子,y+200在比柱子高200的位置写文本,y文本的值,ha居中
plt.text(x, y + 200, y, ha='center')
# ■ 简单水平条形图
plt.subplot(322)
GDP = [36102, 38700, 14083, 25002]
city = ['北京市', '上海市', '天津市', '重庆市']
plt.barh(city, GDP, color='steelblue', alpha=0.8)
plt.xlabel('GDP')
plt.title('2020年四大直辖市GDP水平条形图')
# 为每个条形图添加数值标签. 注,va='center'
for x, y in enumerate(GDP):
plt.text(y + 200, x, y, va='center')
# ■ 簇状条形图2019-2020年四大直辖市GDP对比条形图 - 重叠
plt.subplot(323)
GDP_2019 = [35371, 38155, 14104, 23606]
GDP_2020 = [36102, 38700, 14083, 25002]
bar_width = 0.35
plt.bar(city, GDP_2019, label='2019年', color='steelblue', alpha=0.8,
width=bar_width)
plt.bar(city, GDP_2020, label='2020年', color='indianred', alpha=0.8,
width=bar_width)
# ■ 簇状条形图2019-2020年四大直辖市GDP对比条形图 - 分开
plt.subplot(324)
GDP_2019 = [35371, 38155, 14104, 23606]
GDP_2020 = [36102, 38700, 14083, 25002]
bar_width = 0.35
plt.bar(np.arange(4), GDP_2019, label='2019年', color='steelblue', alpha=0.8,
width=bar_width)
plt.bar(np.arange(4) + bar_width, GDP_2020, label='2020年', color='indianred',
alpha=0.8, width=bar_width)
# ■ 簇状条形图2019-2020年四大直辖市GDP对比条形图 - 分开(优化版
plt.subplot(313)
GDP_2019 = [35371, 38155, 14104, 23606]
GDP_2020 = [36102, 38700, 14083, 25002]
city = ['北京市', '上海市', '天津市', '重庆市']
bar_width = 0.35
# - 绘图
plt.bar(np.arange(4), GDP_2019, label='2019年', color='steelblue', alpha=0.8, width=bar_width)
# ★★★ 神之一笔,它加了个柱宽!
plt.bar(np.arange(4) + bar_width, GDP_2020, label='2020年', color='indianred', alpha=0.8, width=bar_width)
# - 添加轴标签
plt.xlabel('城市')
plt.ylabel('GDP')
plt.title('2019-2020年四大直辖市GDP对比条形图')
# - ψ(`∇´)ψ 增加刻度标签
plt.xticks(np.arange(4) + 0.15, city)
# - ψ(`∇´)ψ 为每个条形图添加数值标签
for x2019, y2019 in enumerate(GDP_2019):
plt.text(x2019 - 0.2, y2019 + 100, y2019)
for x2020, y2020 in enumerate(GDP_2020):
plt.text(x2020 + 0.2, y2020 + 100, y2020)
# - ψ(`∇´)ψ 显示图例
plt.legend(loc='upper right')
plt.tight_layout() # 自动调整子图间距
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
结果截图如下:
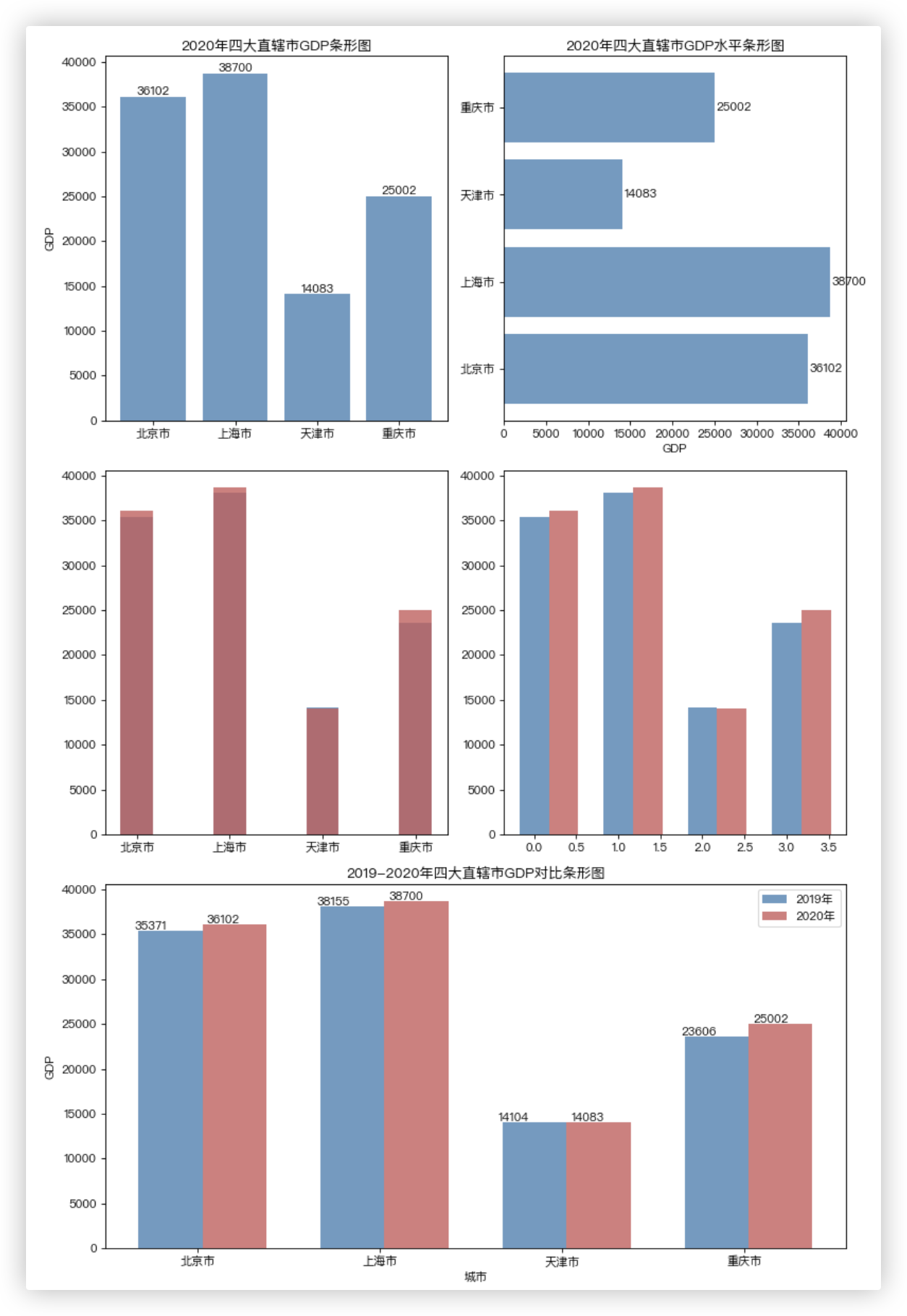
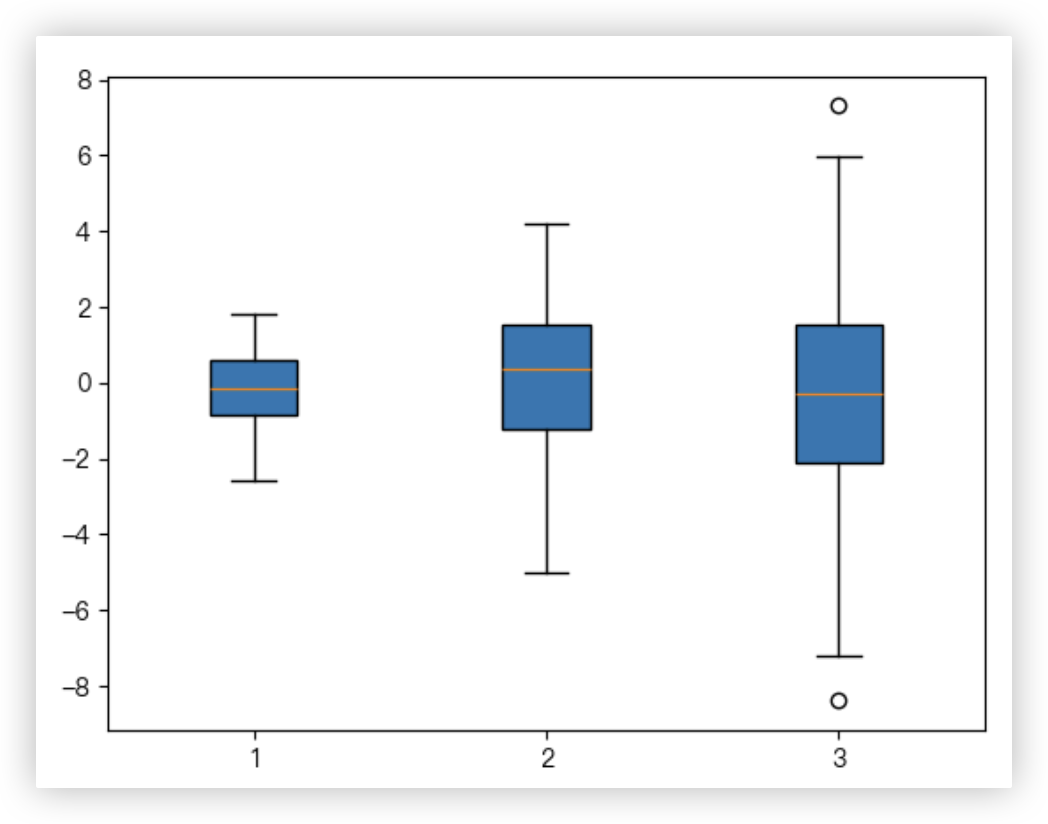
# 箱线图
参数解释
- 函数功能: 反映数据的异常情况/找离散值,是一种用作显示一组数据分散情况的统计图.因形状如箱子而得名,在各种领域也经常被使用.
基本使用
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
# 列表推导式,每个数组都是从均值为0,标准差为std(分别为1、2和3)的正态分布中生成的100个随机数.
all_data = [np.random.normal(0, std, 100) for std in range(1, 4)]
plt.boxplot(all_data, patch_artist=True) # patch_artist=True 参数使得每个箱体被填充颜色.
plt.show()
2
3
4
5
6
7
8
9
10
11
结果截图如下:
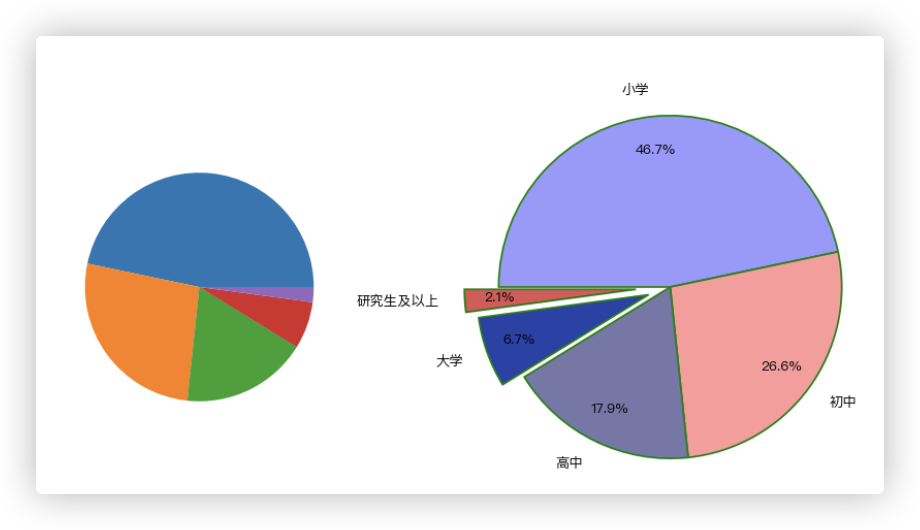
# 饼图
参数解释
- 函数功能: 表示离散变量各水平占比情况
x: 指定绘图的数据
explode: 指定饼图某些部分的突出显示,即呈现爆炸式
labels: 为饼图添加标签说明,类似于图例说明
colors: 指定饼图的填充色
autopct: 自动添加百分比显示,可以采用格式化的方法显示
pctdistance: 设置百分比标签与圆心的距离
shadow: 是否添加饼图的阴影效果
labeldistance: 设置各扇形标签(图例)与圆心的距离;
startangle: 设置饼图的初始摆放角度;
radius: 设置饼图的半径大小;
counterclock: 是否让饼图按逆时针顺序呈现;
wedgeprops: 设置饼图内外边界的属性,如边界线的粗细、颜色等;
textprops: 设置饼图中文本的属性,如字体大小、颜色等;
center: 指定饼图的中心点位置,默认为原点
frame: 是否要显示饼图背后的图框,如果设置为True的话,需要同时控制图框x轴、y轴的范围和饼图的中心位置;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
基本使用
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 15), dpi=80)
# ■ 绘制最简单的饼图
plt.subplot(121)
x = [9823, 5601, 3759, 1400, 450]
plt.pie(x)
# ■ 为饼图添加一些参数
plt.subplot(122)
# 构造数据:某城镇受教育程度
education = [9823, 5601, 3759, 1400, 450]
labels = ['小学', '初中', '高中', '大学', '研究生及以上']
explode = [0, 0, 0, 0.2, 0.3] # 用于突出显示特定人群
colors = ['#9999ff', '#ff9999', '#7777aa', '#2442aa', '#dd5555'] # 自定义颜色
# 绘制饼图
a = plt.pie(
x=education, # 绘图数据
explode=explode, # 分割部分距离圆心的距离
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance=1.15, # 设置教育水平标签与圆心的距离
startangle=180, # 设置饼图的初始角度
radius=1.5, # 设置饼图的半径
counterclock=False, # 是否逆时针,这里设置为顺时针方向
wedgeprops={'linewidth': 1.5, 'edgecolor': 'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize': 12, 'color': 'k'}, # 设置文本标签的属性值
)
plt.tight_layout() # 自动调整子图间距
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
结果截图如下:
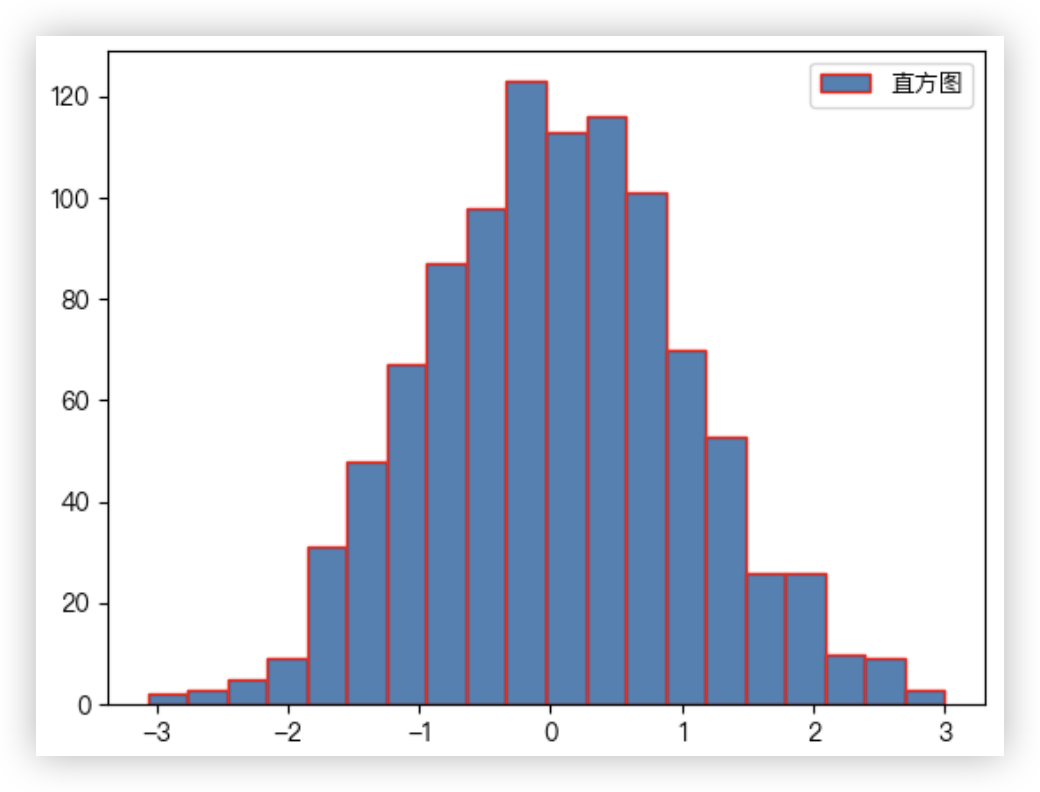
# 直方图/密度图
参数解释
- 函数功能:判定数据的分布情况.
直方图是一种通过条形的高度来表示数据频数或频率分布的图表.
它通常用于展示连续变量的分布情况,如身高、体重等.
★ 直方图将连续变量的取值范围分成若干个区间,然后计算每个区间内数据点的数量,最后将这些数量以条形图的形式展示出来.
x: 指定要绘制直方图的数据.
bins: 指定直方图条形的个数;
range: 指定直方图数据的上下界,默认包含绘图数据的最大值和最小值;
density: 是否将直方图的频数转换成频率;
weights: 该参数可为每一个数据点设置权重;
cumulative: 是否需要计算累计频数或频率;
bottom: 可以为直方图的每个条形添加基准线,默认为0;
histtype: 指定直方图的类型, 默认为bar, 除此还有’barstacked’, ‘step’, ‘stepfilled’;
align: 设置条形边界值的对其方式, 默认为mid, 除此还有’left’和’right’;
orientation: 设置直方图的摆放方向, 默认为垂直方向;
rwidth: 设置直方图条形宽度的百分比;
log: 是否需要对绘图数据进行log变换;
color: 设置直方图的填充色;
label: 设置直方图的标签, 可通过legend展示其图例;
stacked: 当有多个数据时, 是否需要将直方图呈堆叠摆放,默认水平摆放;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
基本使用
plt.hist 返回一个包含三个元素的元组 (n, bins, patches):
-1- n: 一个包含直方图每个箱子的频数(即每个箱子中的样本数量)的数组. 这个数组的长度等于 bins 的数量.
-2- bins: 一个包含箱子边界的数组. 这个数组的长度是 bins 的数量加 1, 因为它包含了每个箱子的右边界.
-3- patches: 一个列表, 包含了每个直方图条形(patch)的对象. 这些对象可以用来进一步定制图形, 如修改颜色、边框等.
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
data = np.random.randn(1000) # 从标准正态分布中生成 1000 个随机样本
res = plt.hist(data, # 绘图数据
bins=20, # 指定直方图的条形数为20个,即20个区间,将1000个数放入符合的区间
color='steelblue', # 指定填充色
edgecolor='r', # 指定直方图的边界色
label='直方图') # 为直方图呈现标签
# 显示图例
plt.legend()
plt.show()
print(res)
"""
(array([ 2., 3., 5., 9., 31., 48., 67., 87., 98., 123., 113.,
116., 101., 70., 53., 26., 26., 10., 9., 3.]),
array([-3.06685409, -2.76337038, -2.45988667, -2.15640296, -1.85291924,
-1.54943553, -1.24595182, -0.94246811, -0.63898439, -0.33550068,
-0.03201697, 0.27146674, 0.57495046, 0.87843417, 1.18191788,
1.48540159, 1.78888531, 2.09236902, 2.39585273, 2.69933644,
3.00282015]), <BarContainer object of 20 artists>)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
结果截图如下:
# 多图合并展示
subplot()和subplots(), 在上面我们就已经使用过 subplot()啦.. 这里再来瞅瞅.
# subplot()函数
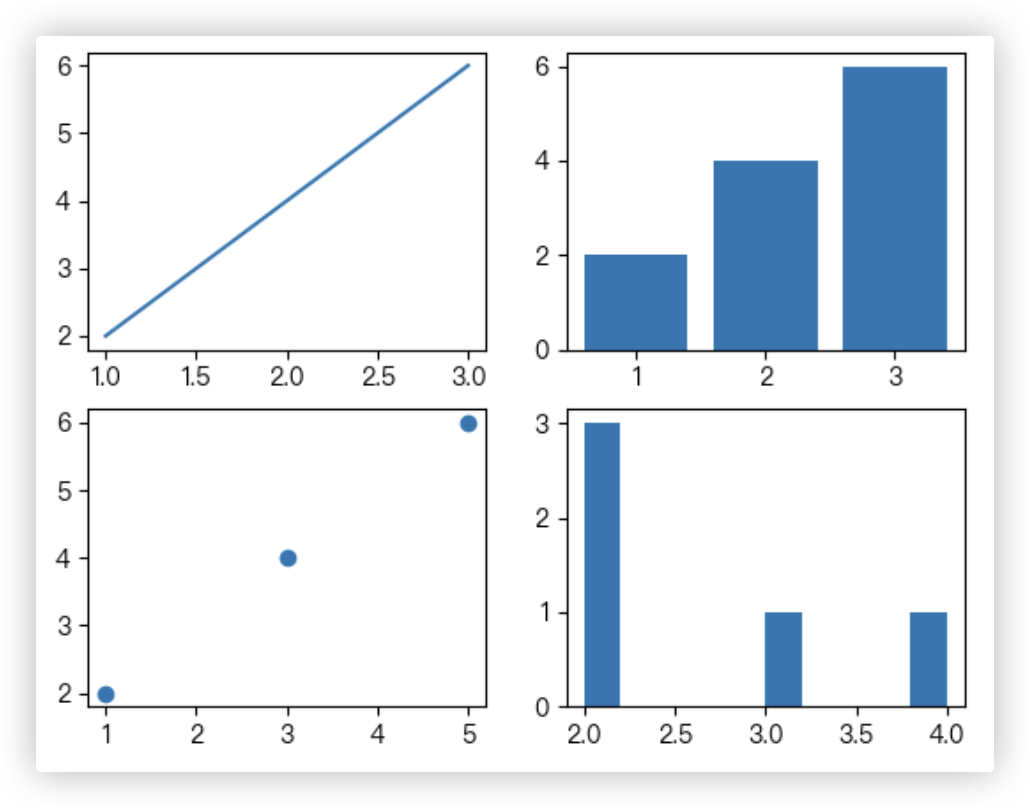
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
# 绘制第一个子图: 折线图
ax1 = plt.subplot(221)
plt.plot([1, 2, 3], [2, 4, 6])
# 绘制第二个子图: 柱状图
ax2 = plt.subplot(222)
plt.bar([1, 2, 3], [2, 4, 6])
# 绘制第三个子图: 散点图
ax3 = plt.subplot(223)
plt.scatter([1, 3, 5], [2, 4, 6])
# 绘制第四个子图: 直方图
ax4 = plt.subplot(224)
plt.hist([2, 2, 2, 3, 4])
plt.show()
print(ax1, ax2, ax3, ax4)
"""
Axes(0.125,0.53;0.352273x0.35)
Axes(0.547727,0.53;0.352273x0.35)
Axes(0.125,0.11;0.352273x0.35)
Axes(0.547727,0.11;0.352273x0.35)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# subplots()函数
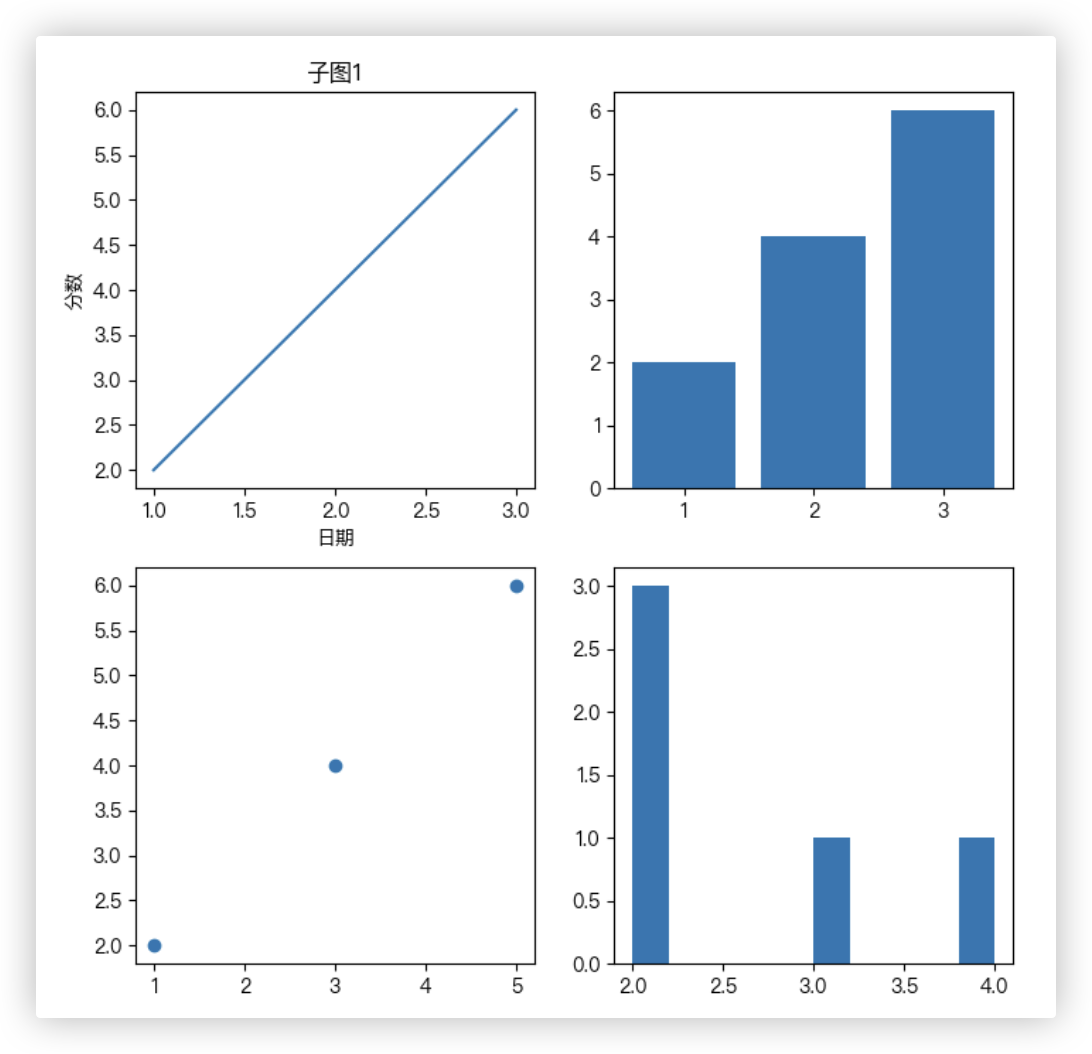
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
ax1, ax2, ax3, ax4 = axes.flatten() # 创建工具对象
ax1.plot([1, 2, 3], [2, 4, 6]) # 绘制第一个子图
ax1.set_title('子图1')
ax1.set_xlabel('日期')
ax1.set_ylabel('分数')
ax2.bar([1, 2, 3], [2, 4, 6]) # 绘制第二个子图
ax3.scatter([1, 3, 5], [2, 4, 6]) # 绘制第三个子图
ax4.hist([2, 2, 2, 3, 4]) # 绘制第四个子图
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 图表动态刷新
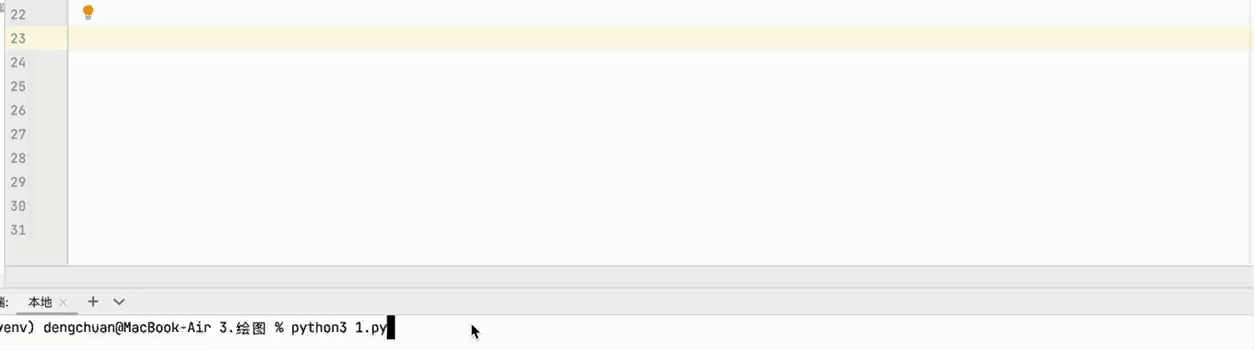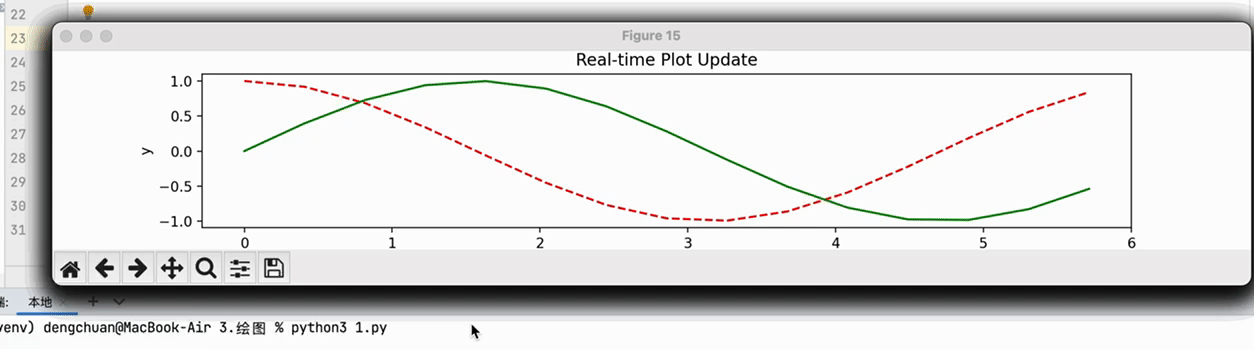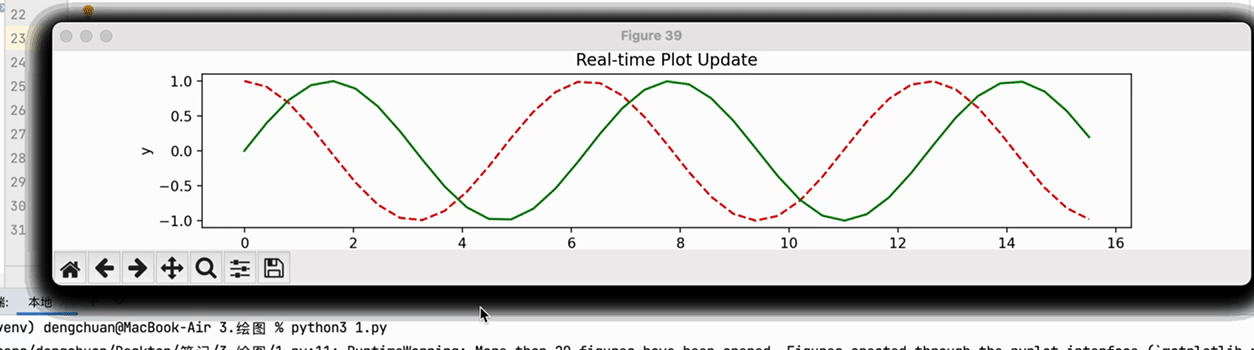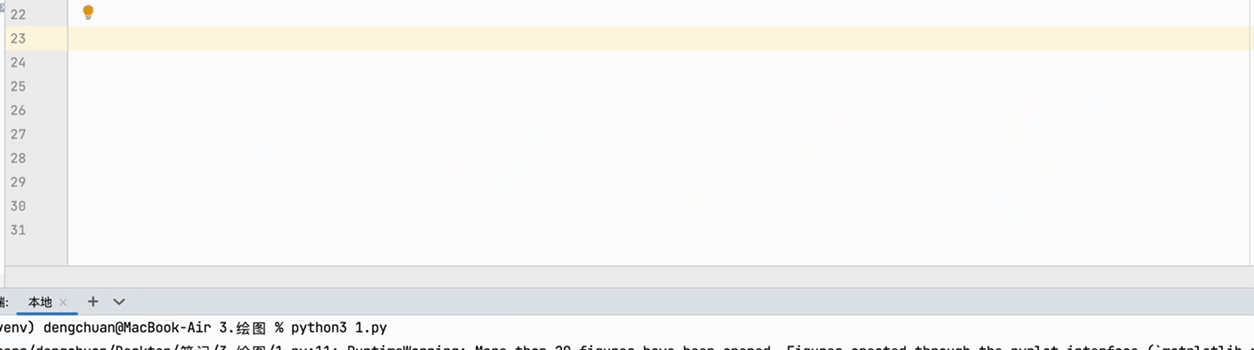
import numpy as np
import matplotlib.pyplot as plt
x, y1, y2 = [], [], []
plt.ion() # 打开交互模式
# 生成从 0 到 20 的 50 个均匀分布的样本
for i in np.linspace(0, 20, 50):
x.append(i)
y1.append(np.cos(i))
y2.append(np.sin(i))
plt.figure(figsize=(12, 2))
plt.plot(x, y1, '--r')
plt.plot(x, y2, 'g')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Real-time Plot Update')
plt.pause(0.1)
plt.clf() # 清除当前图形,避免图形重叠
plt.show()
plt.ioff() # 关闭交互模式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# seaborn绘图
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易.
在大多数情况下使用seaborn能做出很具有吸引力的图, 而使用matplotlib就能制作具有更多特色的图.
应该把Seaborn视为matplotlib的补充, 而不是替代物.
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
★注意seaborn绘图的hue参数哦, 相当于对数据进行分类处理啦, 好好利用它. 分类的默认聚合操作是均值哦!
# 线性图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
"""
- font设置字体;
- stlyle设置,修改主题风格,属性如下:
darkgrid 黑色网格(默认)
whitegrid 白色网格
dark 黑色背景
white 白色背景
ticks 四周有刻度线的白背景
- context设置,决定了图表元素的尺寸,以适应不同的展示场合:
paper 用于小型文档或论文
notebook 用于Jupyter notebook
talk 用于演讲
"""
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
# - 伪造数据
np.random.seed(0) # 设置随机种子以保证结果可重复
n_samples = 50
timepoints = np.linspace(0, 10, n_samples) # 生成一个包含50个均匀分布在0到10之间的时间点的数组
# 这会生成一个包含50个随机事件的数组, 每个事件是'A'或'B'.
events = np.random.choice(['A', 'B'], size=n_samples)
# 这会生成一个包含50个随机信号的数组, 信号值是从标准正态分布中生成的, 然后对事件'A'添加2, 对事件'B'减少2.
signals = np.random.randn(n_samples) + 2 * (events == 'A') - 2 * (events == 'B')
fmri = pd.DataFrame({
'timepoint': timepoints,
'signal': signals,
'event': events
})
"""
timepoint signal event
0 0.000000 1.039245 A
1 0.204082 -1.623073 B
2 0.408163 -1.966561 B
3 0.612245 2.680567 A
4 0.816327 -3.563497 B ['A' 'B']
"""
print(fmri.head(), fmri['event'].unique())
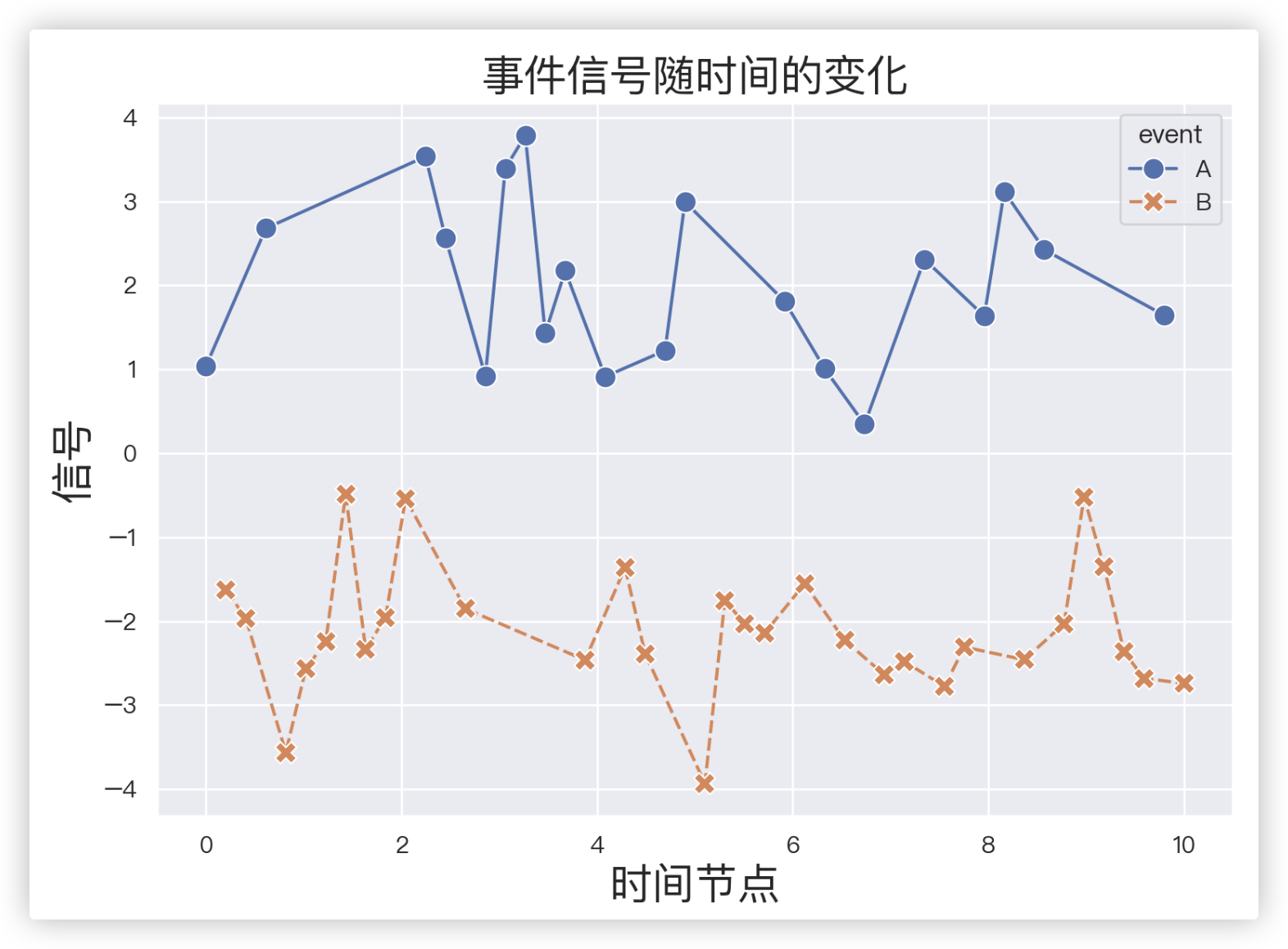
# - 绘制线形图
"""
- lineplot()函数作用是绘制 线型图.
参数x、y, 表示横纵坐标;
参数hue, 表示根据属性 分类 绘制两条线(此示例中"event"属性分两类"A"、"B");
参数style, 表示根据属性分类设置样式,实线和虚线;
参数data, 表示 数据; 参数marker、markersize,分别表示画图 标记点 以及尺寸大小!
"""
ax = sns.lineplot(x='timepoint', y='signal',
hue='event', style='event',
data=fmri,
markers=True,
markersize=10)
plt.xlabel('时间节点', fontsize=20)
plt.ylabel('信号', fontsize=20)
plt.title('事件信号随时间的变化', fontsize=20)
# 保存图片 (要在show之前保存哦!!
plt.savefig('./线形图.png', dpi=200)
# 显示图形
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
示例结果截图:
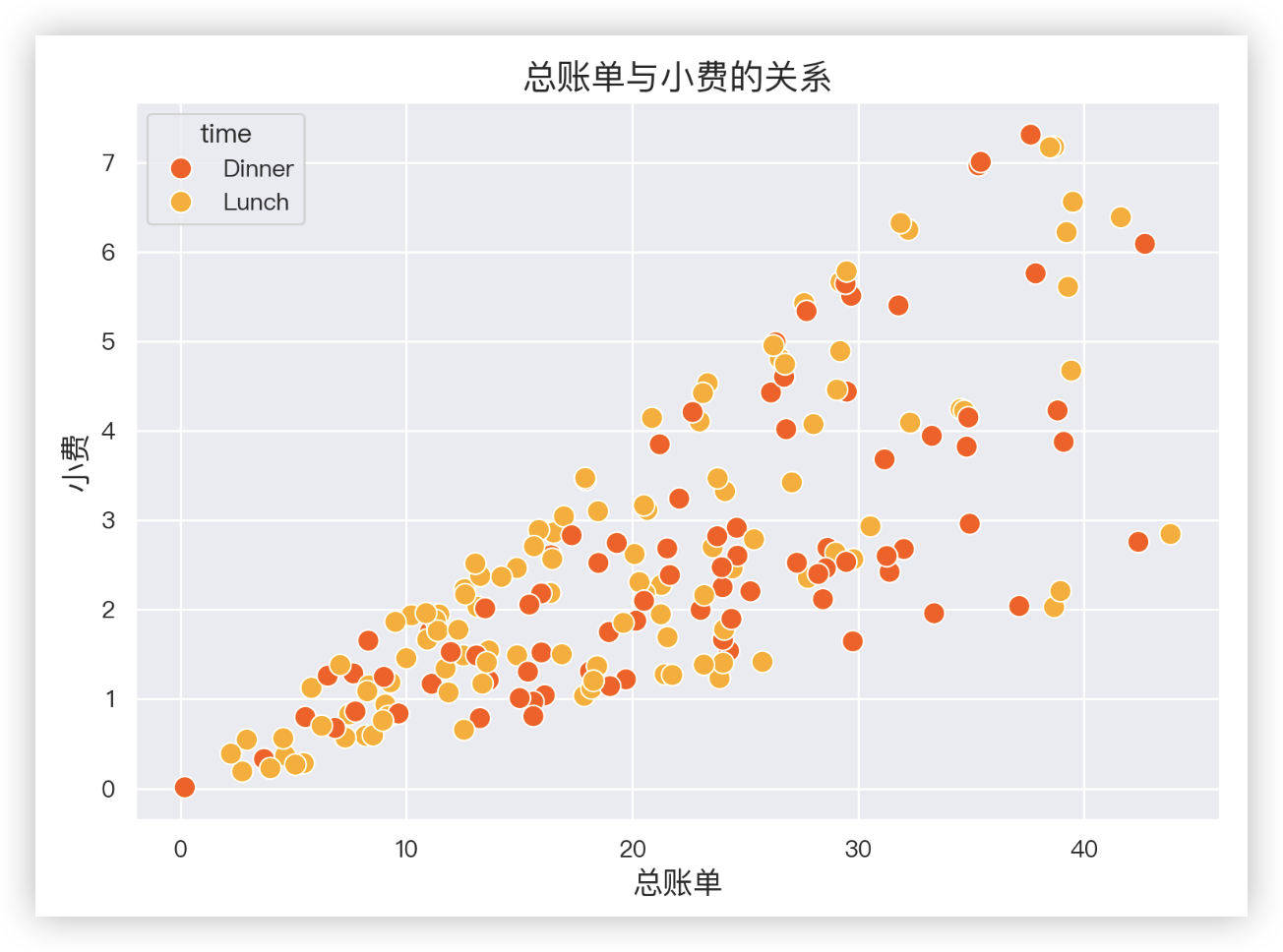
# 散点图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
# - 伪造小费数据
np.random.seed(0) # 设置随机种子以保证结果可重复
n_samples = 200
# 正态分布,loc是均值、scale是标准差 abs取绝对值保证是正数
total_bills = np.abs(np.random.normal(loc=20, scale=10, size=n_samples))
# 小费的百分比从0.05到0.2的均匀分布中随机选择.
tips = total_bills * np.random.uniform(low=0.05, high=0.2, size=n_samples)
times = np.random.choice(['Lunch', 'Dinner'], size=n_samples)
data = pd.DataFrame({
'total_bill': total_bills,
'tip': tips,
'time': times
})
"""
total_bill tip time
0 37.640523 7.313194 Dinner
1 24.001572 2.251879 Dinner
2 29.787380 2.565418 Lunch
3 42.408932 2.758450 Dinner
4 38.675580 2.029093 Lunch
"""
print(data.head())
# - s参数用于控制散点图的大小;palette是调色板,用于控制图形颜色.
# palette系统默认提供了六种选择: `deep, muted, bright, pastel, dark, colorblind`. print(plt.colormaps())
fig = sns.scatterplot(x='total_bill', y='tip',
hue='time', data=data,
palette='autumn', s=100)
# 设置标签和标题
plt.xlabel('总账单', fontsize=14)
plt.ylabel('小费', fontsize=14)
plt.title('总账单与小费的关系', fontsize=16)
# 保存图片
plt.savefig('./散点图.png', dpi=200)
# 显示图形
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
示例结果截图:
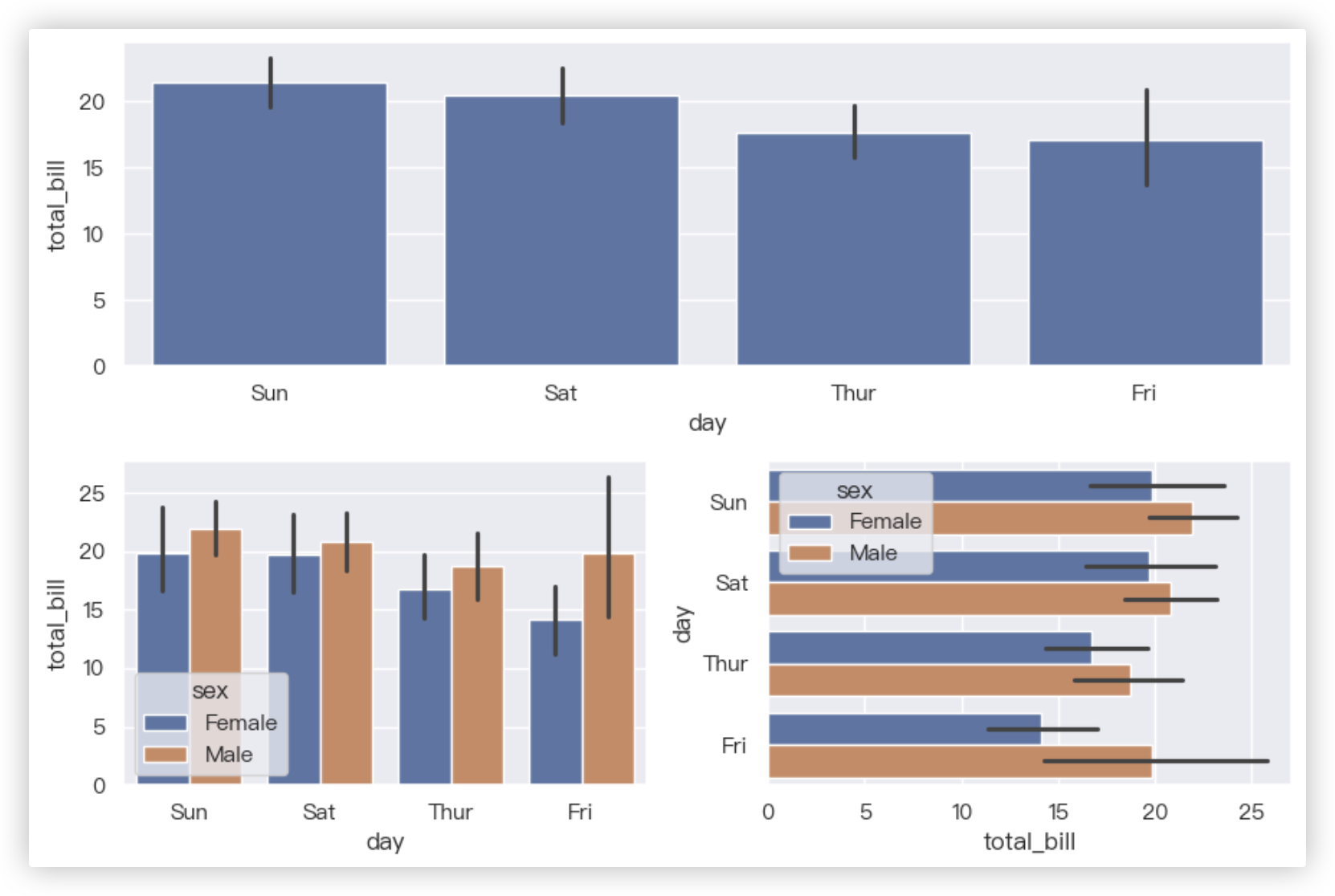
# 柱状图/条形图
★ x, y为绘图时指定的x轴和y轴数据, x、y如果有一个是离散型数据(或者说定性数据、分类数据),另一个是连续性数值数据.
seaborn将会 [根据其中的离散型数据对另一个连续性数据进行分组统计, 同时也决定绘图的方向.]
如果两个都是数值型数据, 可以通过orient指定方向.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
tips = pd.read_csv('./data/tips.csv') # 小费
"""
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
"""
print(tips.head())
plt.subplot(211)
sns.barplot(x="day", y="total_bill", data=tips)
plt.subplot(223)
sns.barplot(x="day", y="total_bill", data=tips, hue='sex')
plt.subplot(224)
# ★简单理解哈,根据day进行分组后,每组再根据sex进行分组,每个小组再计算total_bill的均值.Hhh
sns.barplot(y="day", x="total_bill", data=tips, hue='sex')
# 显示图形
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
示例结果截图:
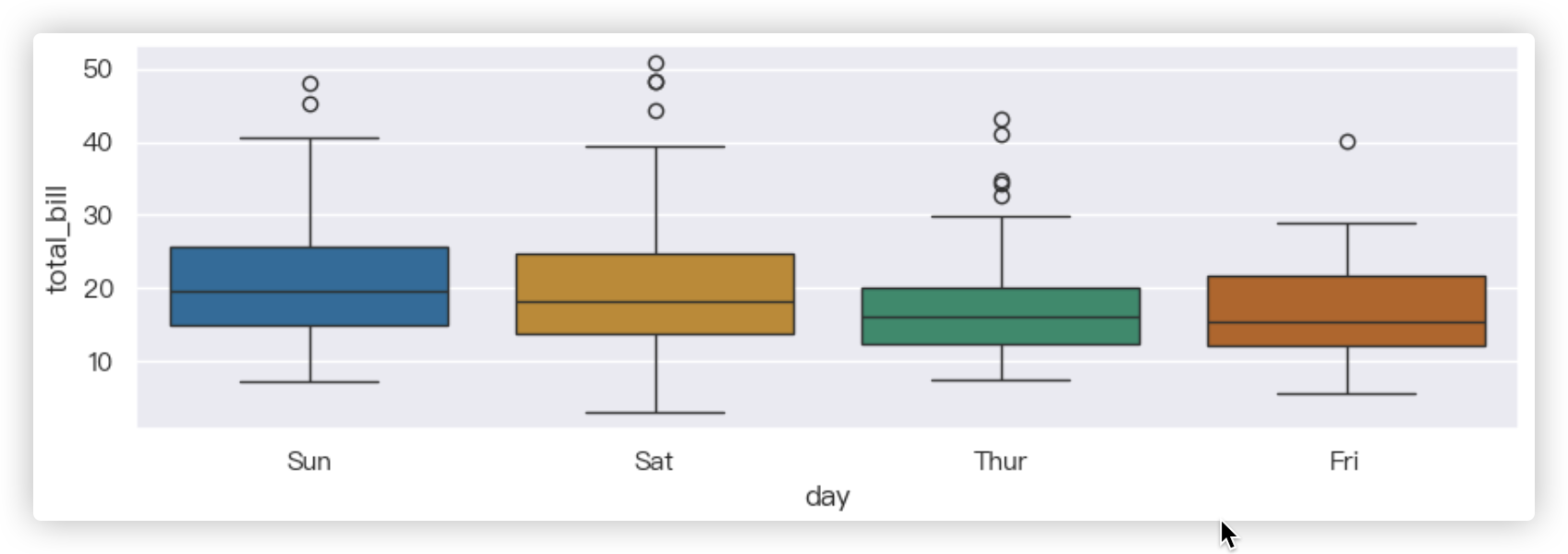
# 箱式图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
tips = pd.read_csv('./data/tips.csv') # 小费
"""
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
"""
print(tips.head())
# 按照day进行分组后,求每组的四分位数!
sns.boxplot(x="day", y="total_bill", data=tips, palette='colorblind')
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
示例结果截图:
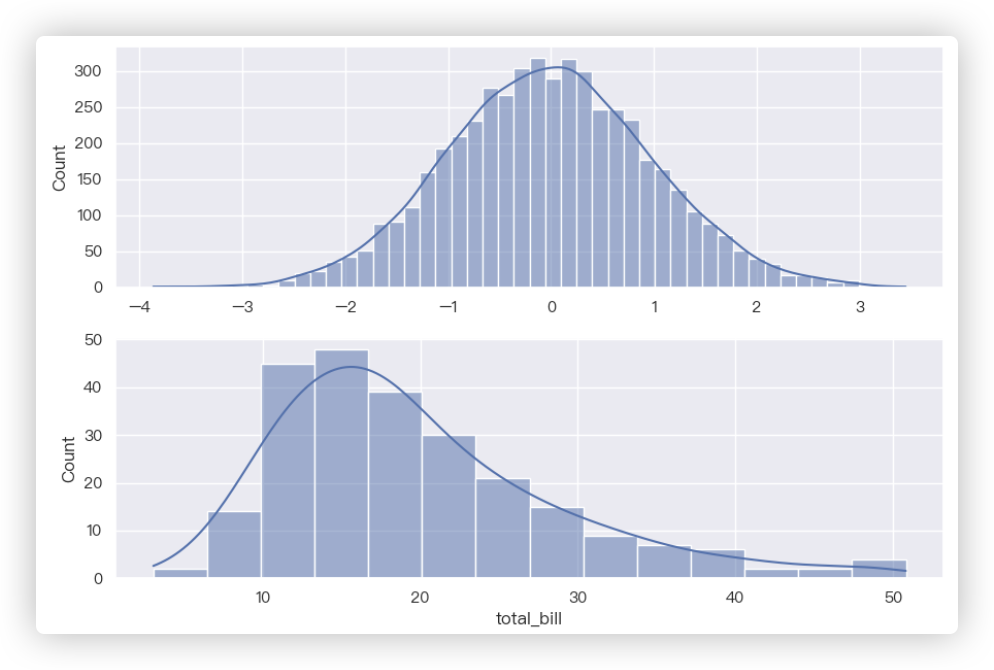
# 直方图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
plt.subplot(211)
x = np.random.randn(5000)
# kde = True: 设置是否在直方图上绘制核密度估计曲线
sns.histplot(x, kde=True) # ★ 你可以看histplot的参数,bins默认值是auto.
plt.subplot(212)
tips = pd.read_csv('./data/tips.csv')
"""
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
"""
print(tips.head())
sns.histplot(x='total_bill', data=tips, kde=True)
# 显示图形
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
示例结果截图:
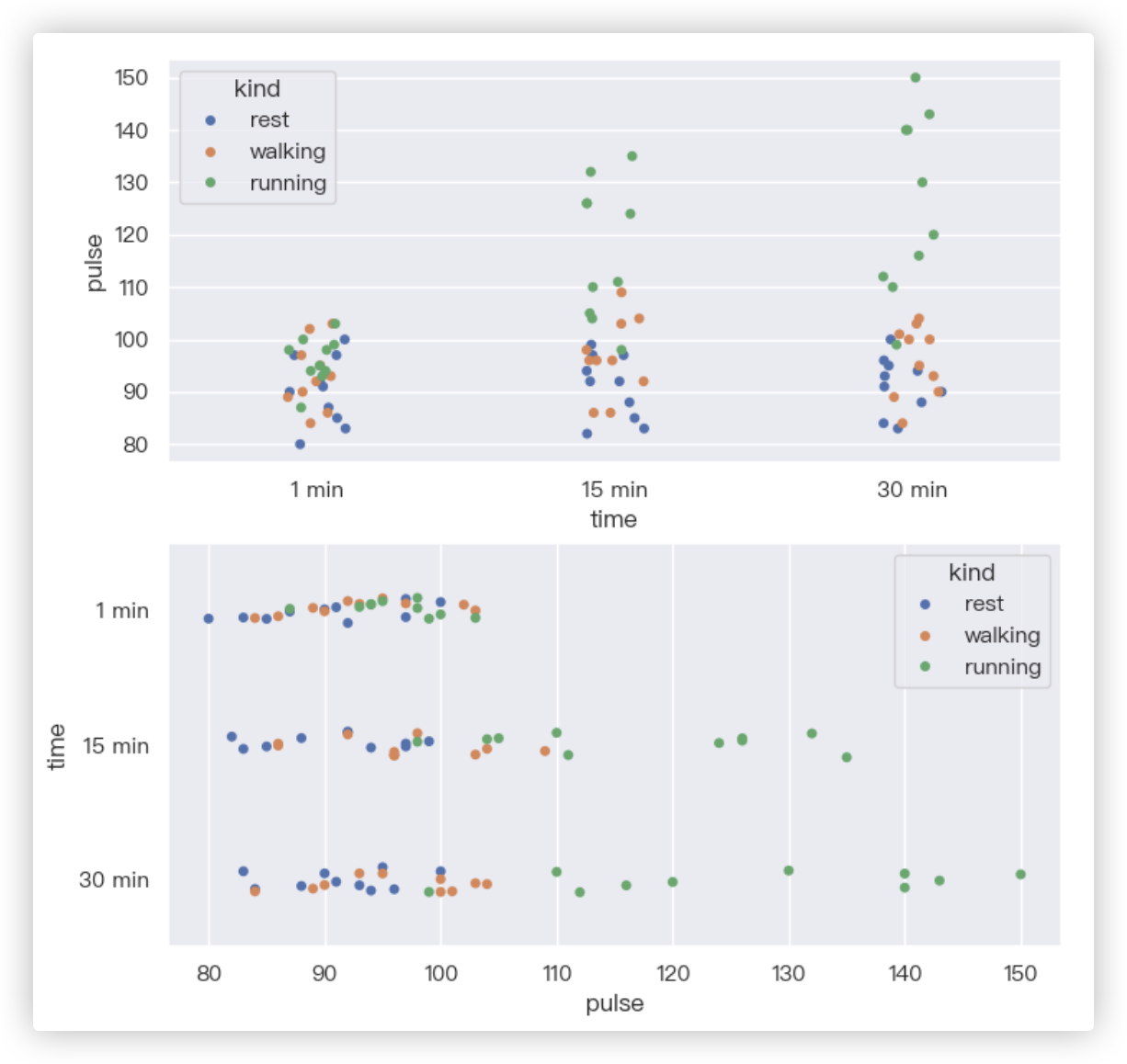
# 分类散点图
查看1min、15min、30min时,针对3种运动, 同学们的脉搏数值的分布情况.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
exercise = pd.read_csv('./data/exercise.csv')
"""
Unnamed: 0 id diet pulse time kind
0 0 1 low fat 85 1 min rest
1 1 1 low fat 85 15 min rest
2 2 1 low fat 88 30 min rest
3 3 2 low fat 90 1 min rest
4 4 2 low fat 92 15 min rest
"""
print(exercise.head())
plt.figure(figsize=(9, 6))
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
ax1, ax2 = axes.flatten() # 创建工具对象
# ★ 简单来说,先根据time分类,然后根据kind分类,最后根据pulse值在图上绘点.
sns.stripplot(x="time", y="pulse", hue="kind", data=exercise, ax=ax1)
sns.stripplot(y="time", x="pulse", hue="kind", data=exercise, ax=ax2)
plt.show()
"""
因为用了多图合并展示,所以使用的是sns.stripplot()
若只有单图, sns.catplot(x="time", y="pulse", hue="kind", data=exercise) 也是可以的!
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
示例结果截图:
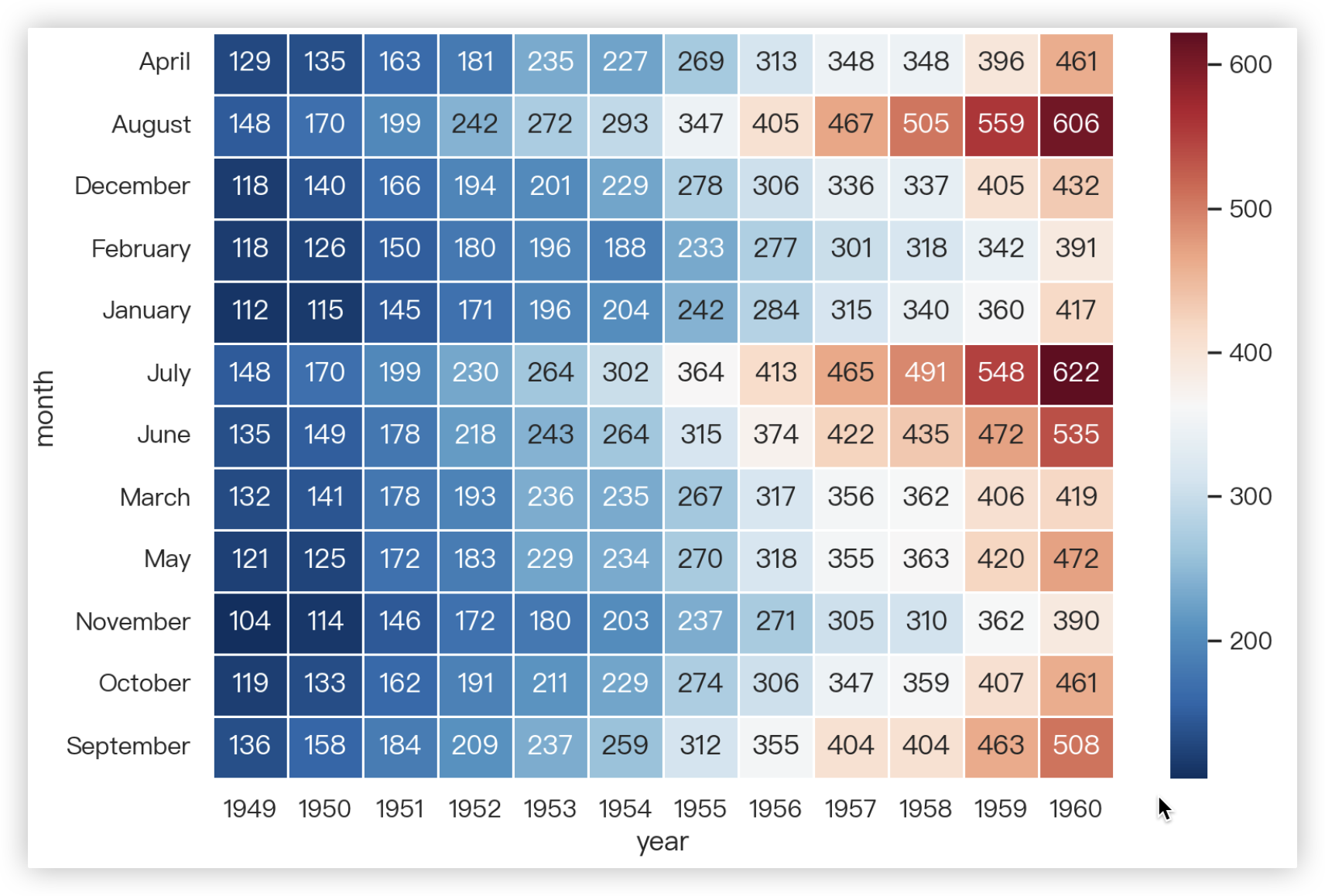
# 热力图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='darkgrid', font='PingFang HK') # 设置样式
plt.figure(figsize=(9, 6))
flights = pd.read_csv('./data/flights.csv')
"""
year month passengers
0 1949 January 112
1 1949 February 118
2 1949 March 132
3 1949 April 129
4 1949 May 121
"""
print(flights.head())
flights = flights.pivot(index="month", columns="year", values="passengers")
"""
year 1949 1950 1951 1952 1953 ... 1956 1957 1958 1959 1960
month ...
April 129 135 163 181 235 ... 313 348 348 396 461
August 148 170 199 242 272 ... 405 467 505 559 606
December 118 140 166 194 201 ... 306 336 337 405 432
February 118 126 150 180 196 ... 277 301 318 342 391
January 112 115 145 171 196 ... 284 315 340 360 417
"""
print(flights.head())
"""
- `flights`: 这是一个二维数组或DataFrame,表示要绘制热力图的数据.
- `annot=True`: 设置是否在每个单元格上显示数值注释. 设置为`True`表示显示数值.
- `fmt='d'`: 设置数值的格式,这里使用整数格式('d').
- `cmap='RdBu_r'`: 设置颜色映射方案,这里使用的是反向的红蓝色调色板('RdBu_r').
- `linewidths=0.5`: 设置单元格之间的线宽,这里设置为0.5.
"""
sns.heatmap(flights, annot=True, fmt='d', cmap='RdBu_r', linewidths=0.5)
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
示例结果截图:
# Plotly Express绘图
pip install plotly_express -i https://pypi.tuna.tsinghua.edu.cn/simple
# 散点图
# 基本散点图
import plotly.express as px
df = px.data.iris()
"""
sepal_length sepal_width petal_length petal_width species species_id
0 5.1 3.5 1.4 0.2 setosa 1
1 4.9 3.0 1.4 0.2 setosa 1
2 4.7 3.2 1.3 0.2 setosa 1
3 4.6 3.1 1.5 0.2 setosa 1
4 5.0 3.6 1.4 0.2 setosa 1
"""
print(df.head())
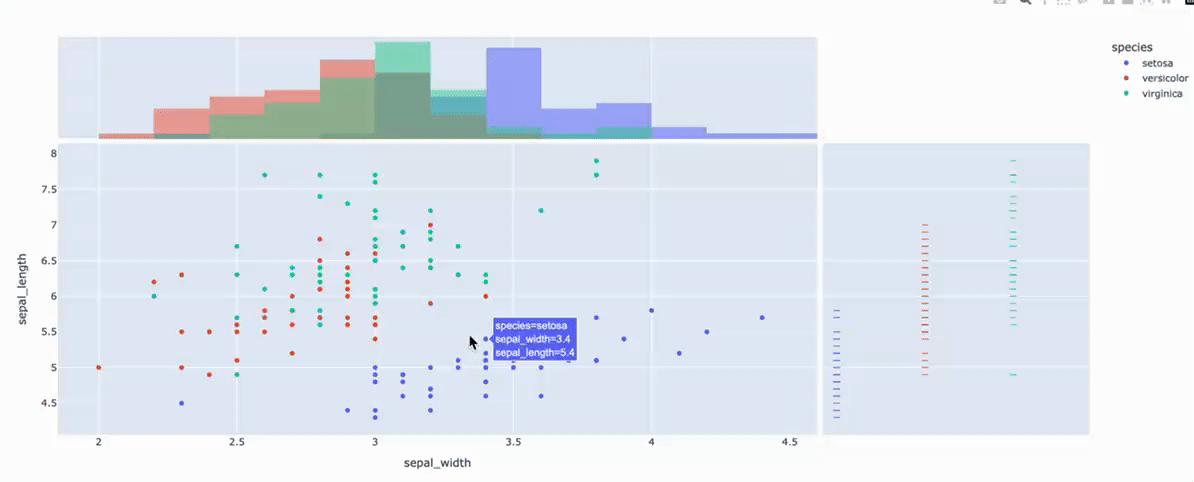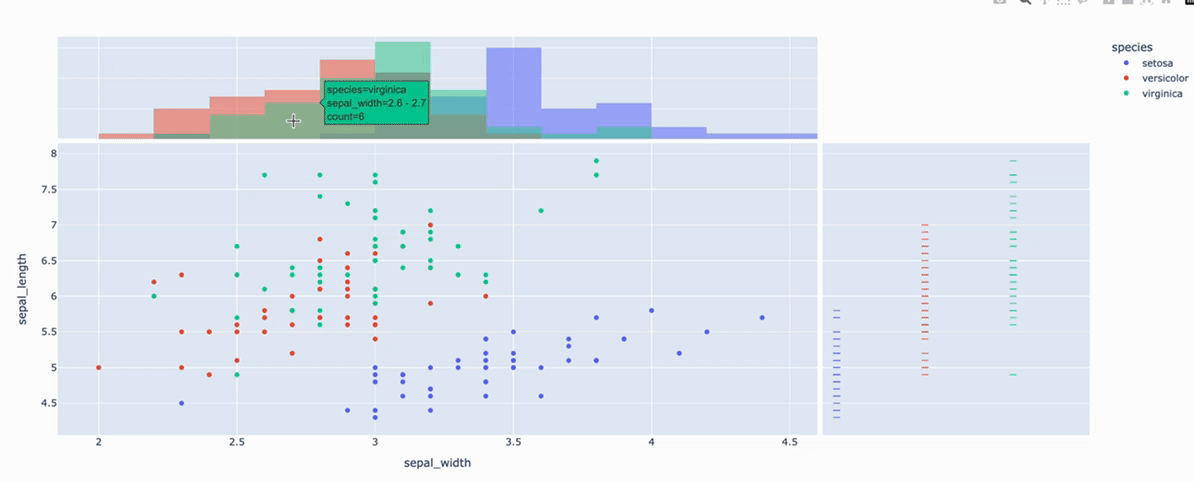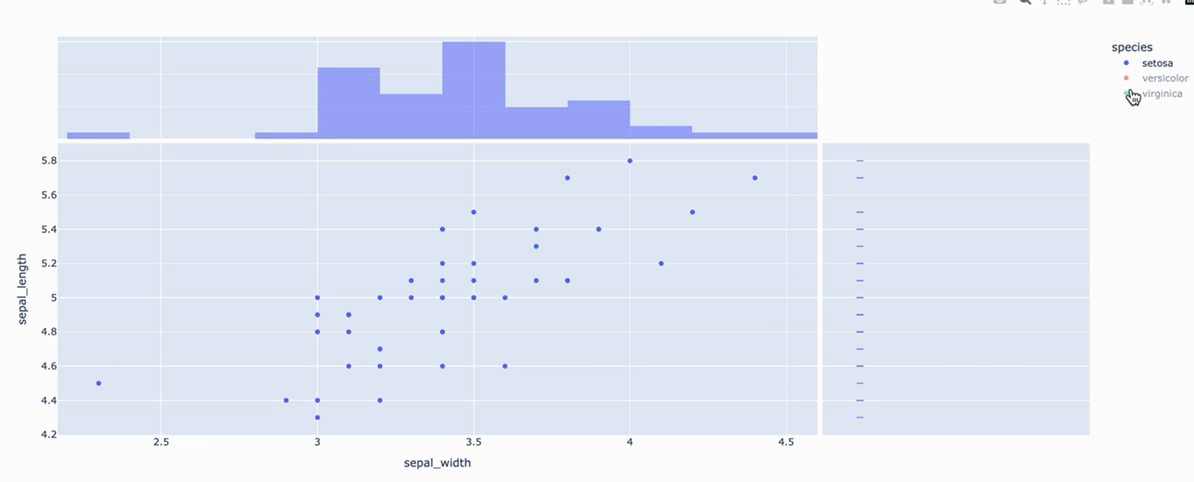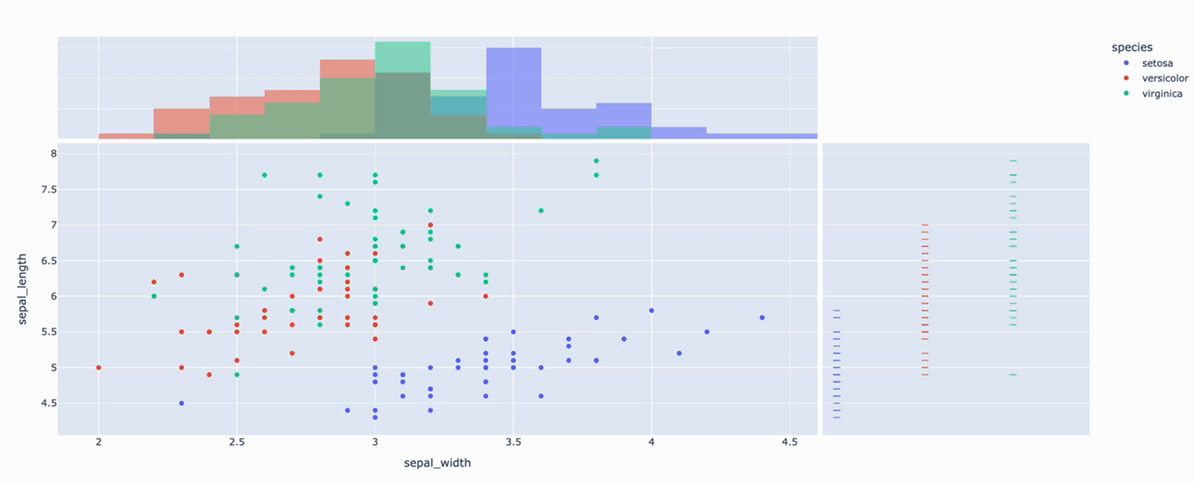
fig = px.scatter(
df, x="sepal_width", y="sepal_length", color="species", marginal_y="rug", marginal_x="histogram")
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
示例结果动态gif如下:
简单解释下:
x="sepal_width", y="sepal_length" >> 两组数据的元素一一对应构成每个点的坐标!
color="species" >> 根据species物种的类别给每个点上色. len(df['species'].unique())值是多少,就有多少个颜色!
marginal_y="rug" >> sepal_length这一列的数据,根据species的类别进行分类,画细条图!
marginal_x="histogram" >> sepal_width这一列的数据,画直方图!观察直方图上每一个柱子上的颜色,可以看到该组中每个类别所占数量.
- marginal_x:字符串,该参数用于在主图上方,绘制一个水平子图,以便对x分布,进行可视化;
- marginal_y:字符串,该参数用于在主图右侧,绘制一个垂直子图,以便对y分布,进行可视化;
取值 > rug(细条)、box(箱图)、violin(小提琴图)、histogram(直方图)...
2
3
4
5
6
7
8
9
10
# 矩阵散点图
import plotly.express as px
df = px.data.iris()
# ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species', 'species_id']
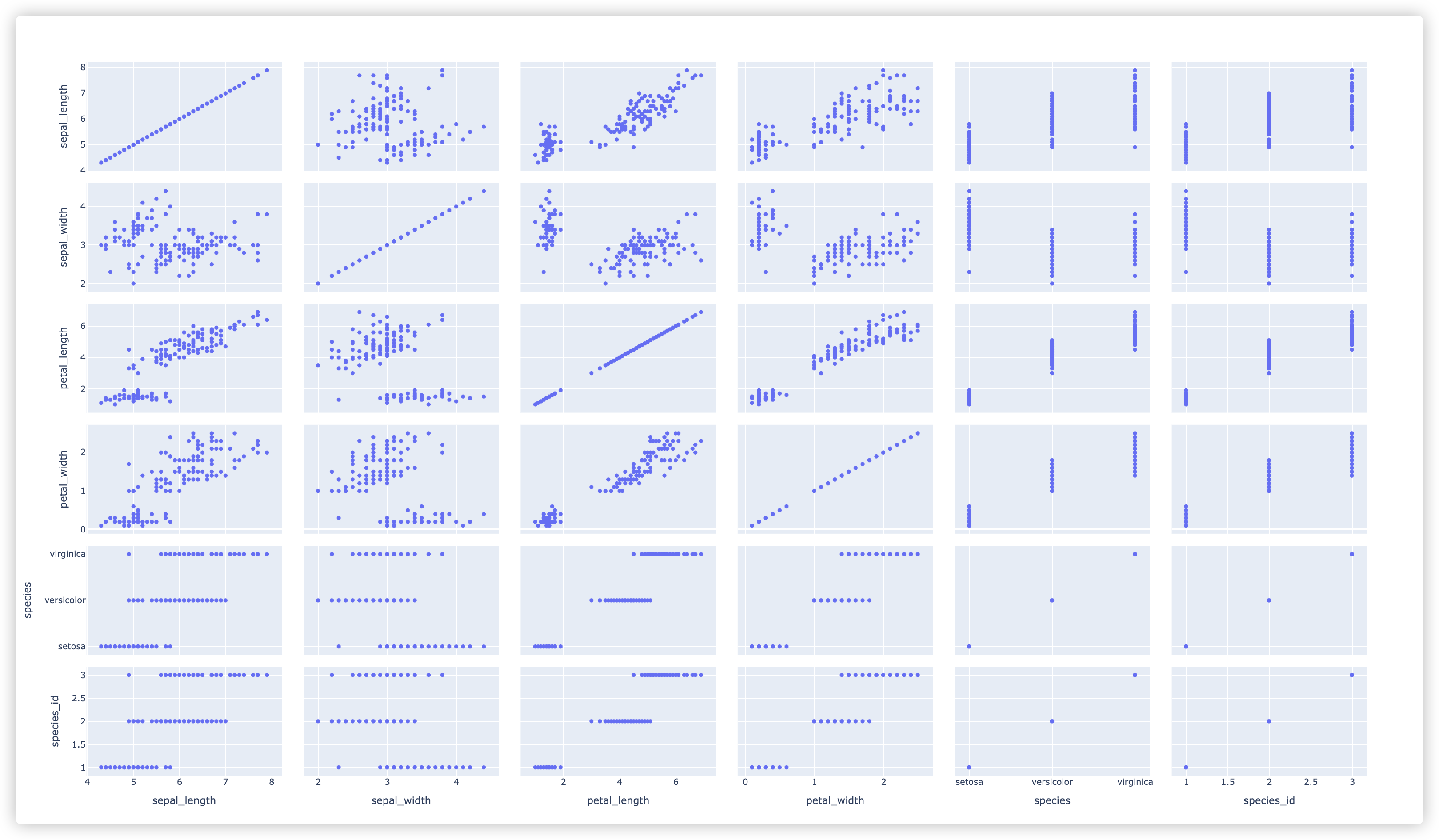
print(list(df.columns)) # 6*6 即36个图
fig = px.scatter_matrix(df)
fig.show()
"""
# 当然,矩阵散点图还可以选定几个变量
fig = px.scatter_matrix(
df, dimensions=["sepal_width", "sepal_length", "petal_width", "petal_length"], color="species")
fig.show()
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
示例结果截图如下:
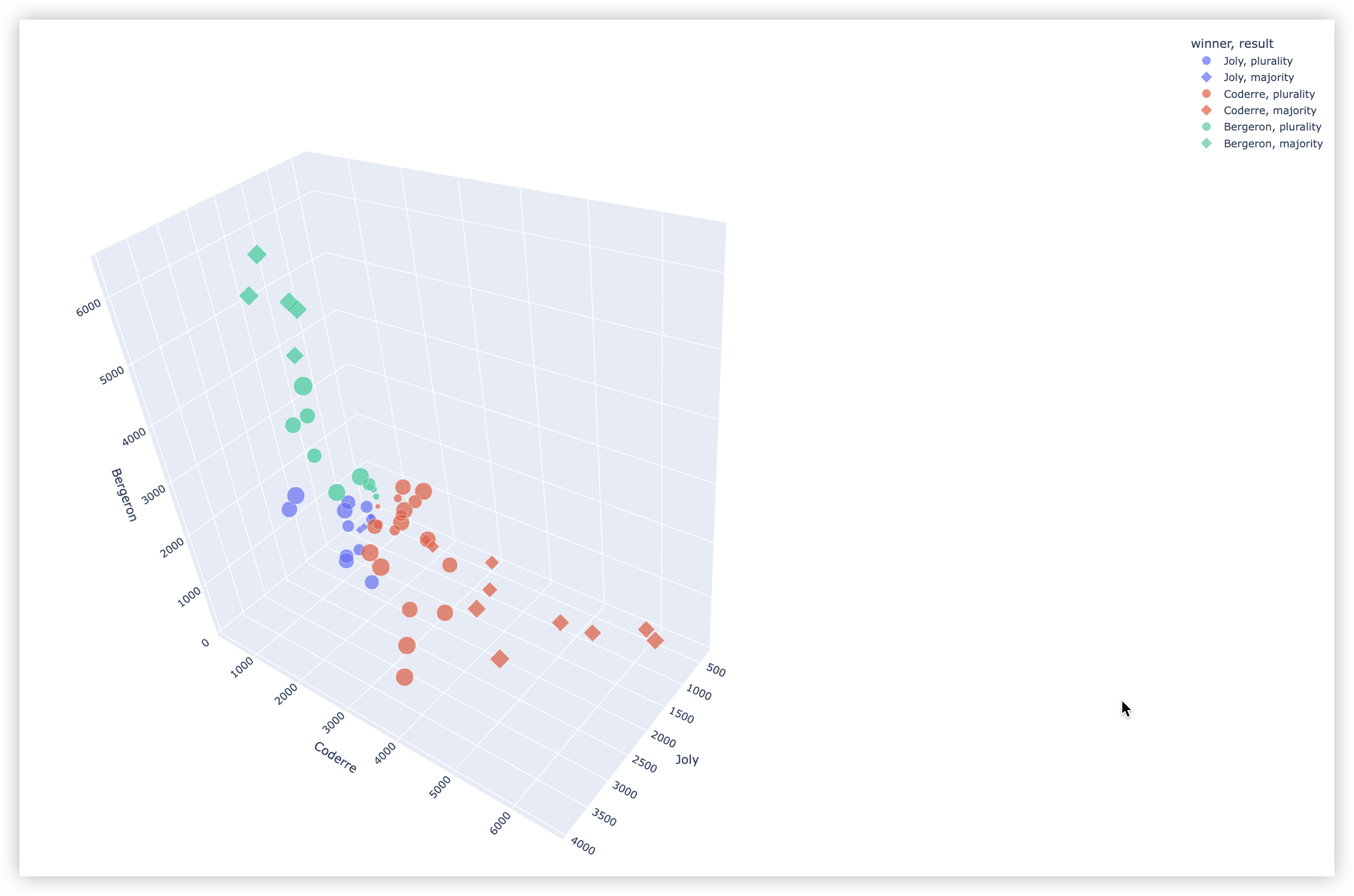
# 3D散点图
import plotly.express as px
df = px.data.election()
# - size: 指定列名. 为列中的不同值,设置不同的标记大小
# - symbol: 指定列名. 为列中的不同值,设置不同的标记形状
fig = px.scatter_3d(
df, x="Joly", y="Coderre", z="Bergeron", color="winner", size="total", symbol="result")
fig.show()
2
3
4
5
6
7
8
示例结果截图如下:
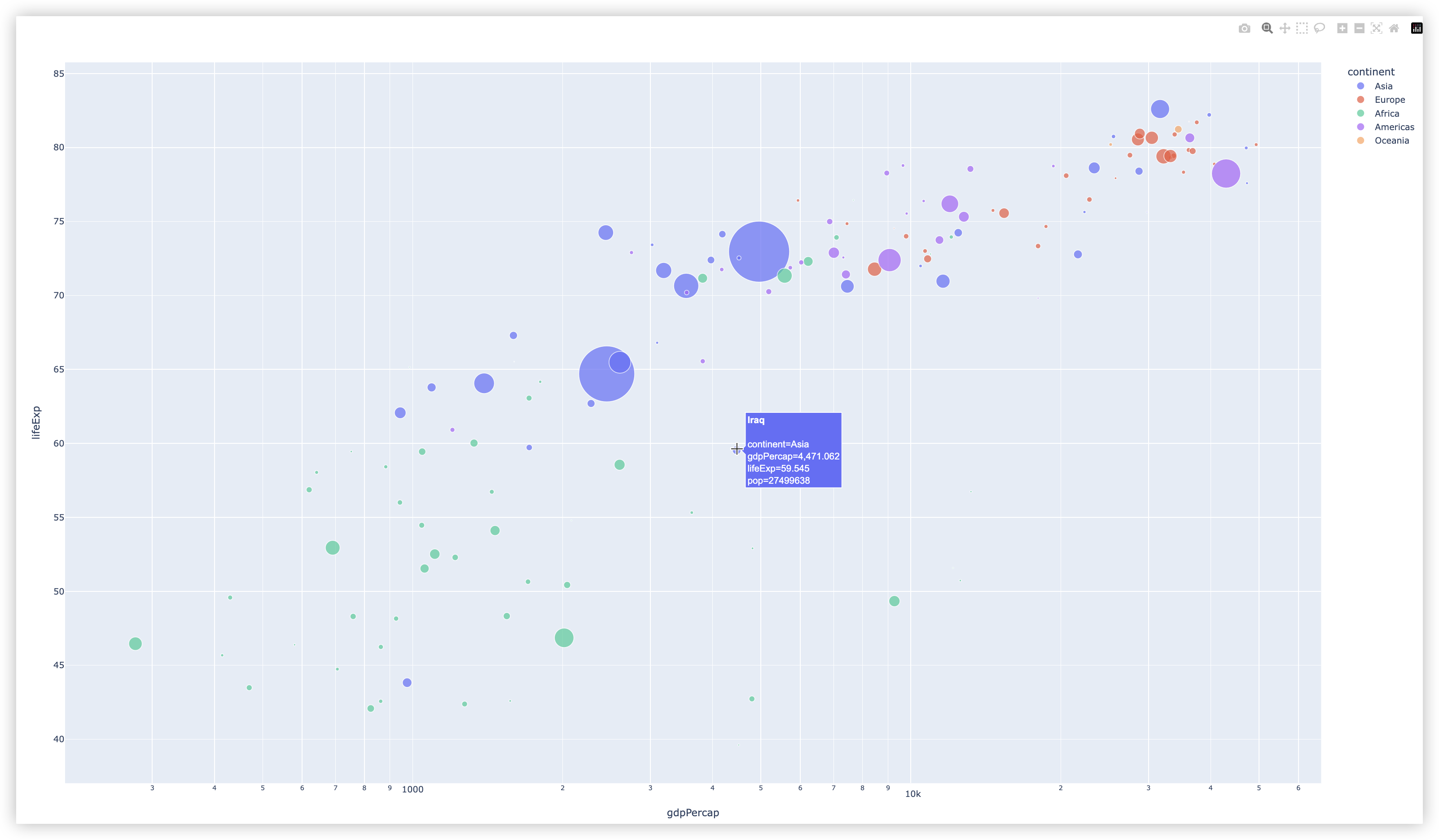
# 气泡图
import plotly.express as px
df = px.data.gapminder() # 获取不同国家历年GDP收入与人均寿命数据
print(df.head())
"""
- df.query("year==2007") 保留df中year这一列值为2007所对应的那些行!
- size="pop" 气泡大小,个数与行数一致
- color="continent" 颜色,按照continent类别来,类别相同的一个颜色
- hover_name: 指定列名. 将列中的值,加粗显示在悬停提示内容的正上方
- log_x: 布尔值,默认为False. 如果为True,则 X 轴在笛卡尔坐标系中进行对数缩放
- size_max: 整数,默认为20. 设置整体气泡大小
"""
fig = px.scatter(
df.query("year==2007"), x="gdpPercap", y="lifeExp", size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
示例结果截图如下:
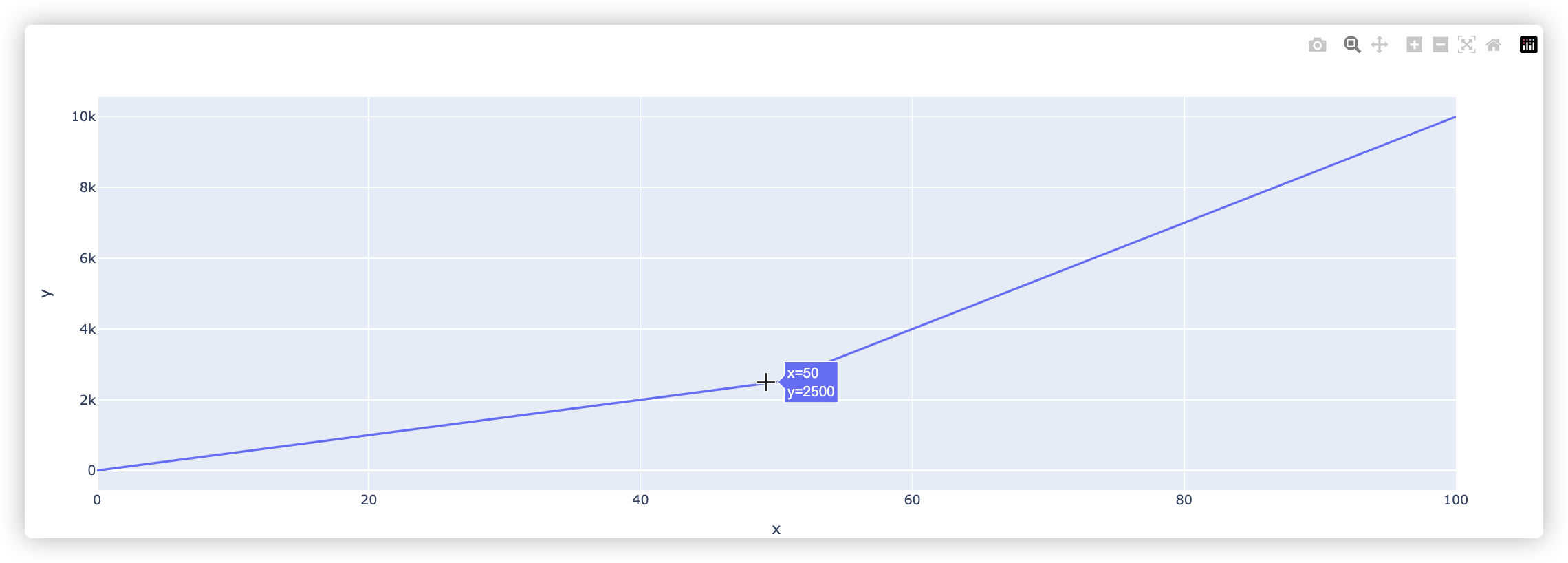
# 折线图
import plotly.express as px
import numpy as np
x = np.linspace(0, 100, 3)
y = x ** 2
fig = px.line(x=x, y=y)
fig.show()
2
3
4
5
6
7
示例结果截图如下:
# 热力图
import plotly.express as px
df = px.data.iris()
"""
sepal_length sepal_width petal_length petal_width species species_id
0 5.1 3.5 1.4 0.2 setosa 1
1 4.9 3.0 1.4 0.2 setosa 1
2 4.7 3.2 1.3 0.2 setosa 1
3 4.6 3.1 1.5 0.2 setosa 1
4 5.0 3.6 1.4 0.2 setosa 1
"""
print(df.head())
fig = px.density_heatmap(df, x="sepal_width", y="sepal_length")
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
示例结果截图如下:
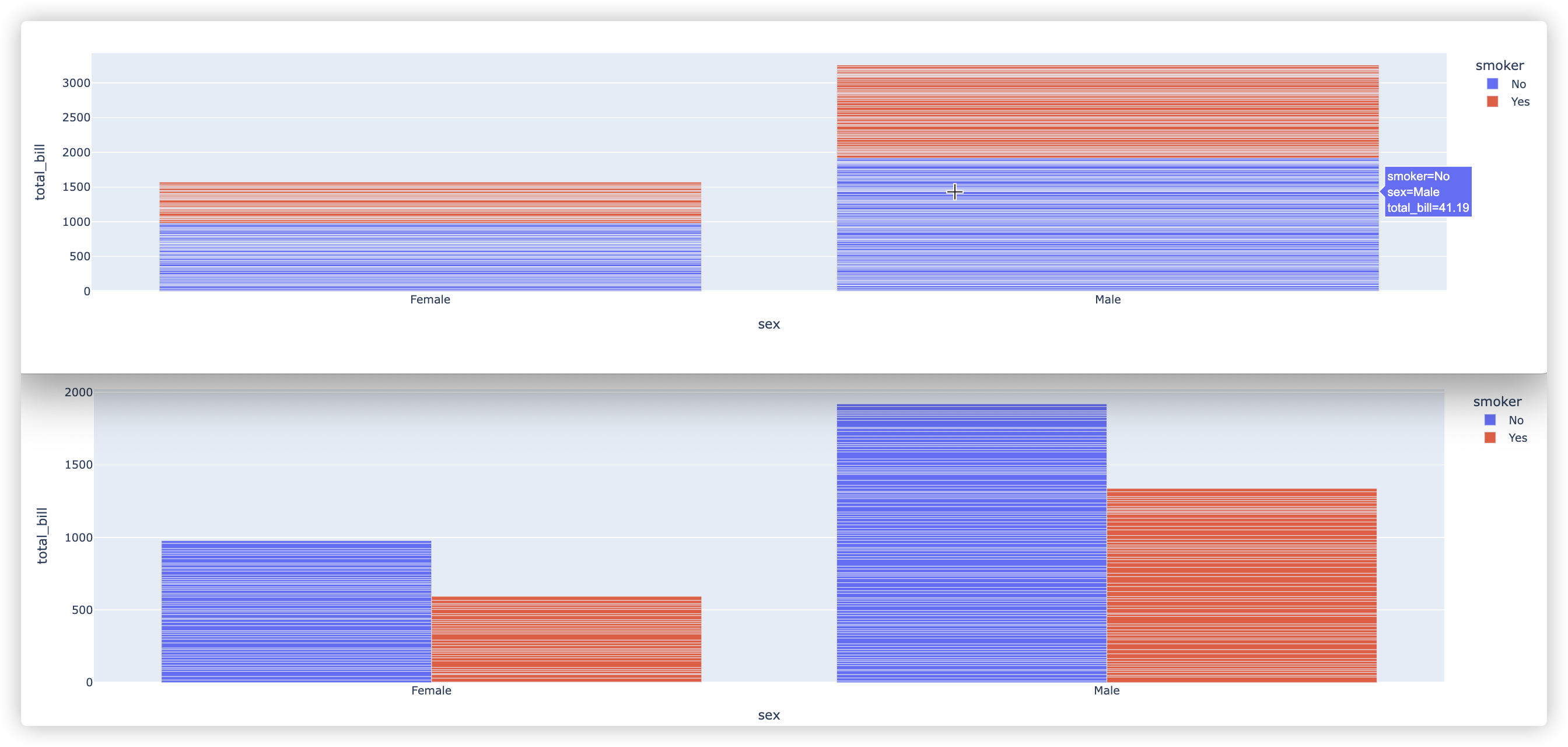
# 条形图/柱状图
注: 柱子的最高点默认是总值, 不是均值哦!!
# barmode="group" 参数指的是是否按照smoker分开展示!
import plotly.express as px
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill", color="smoker")
fig.show()
fig = px.bar(df, x="sex", y="total_bill", color="smoker", barmode="group")
fig.show()
2
3
4
5
6
7
8
9
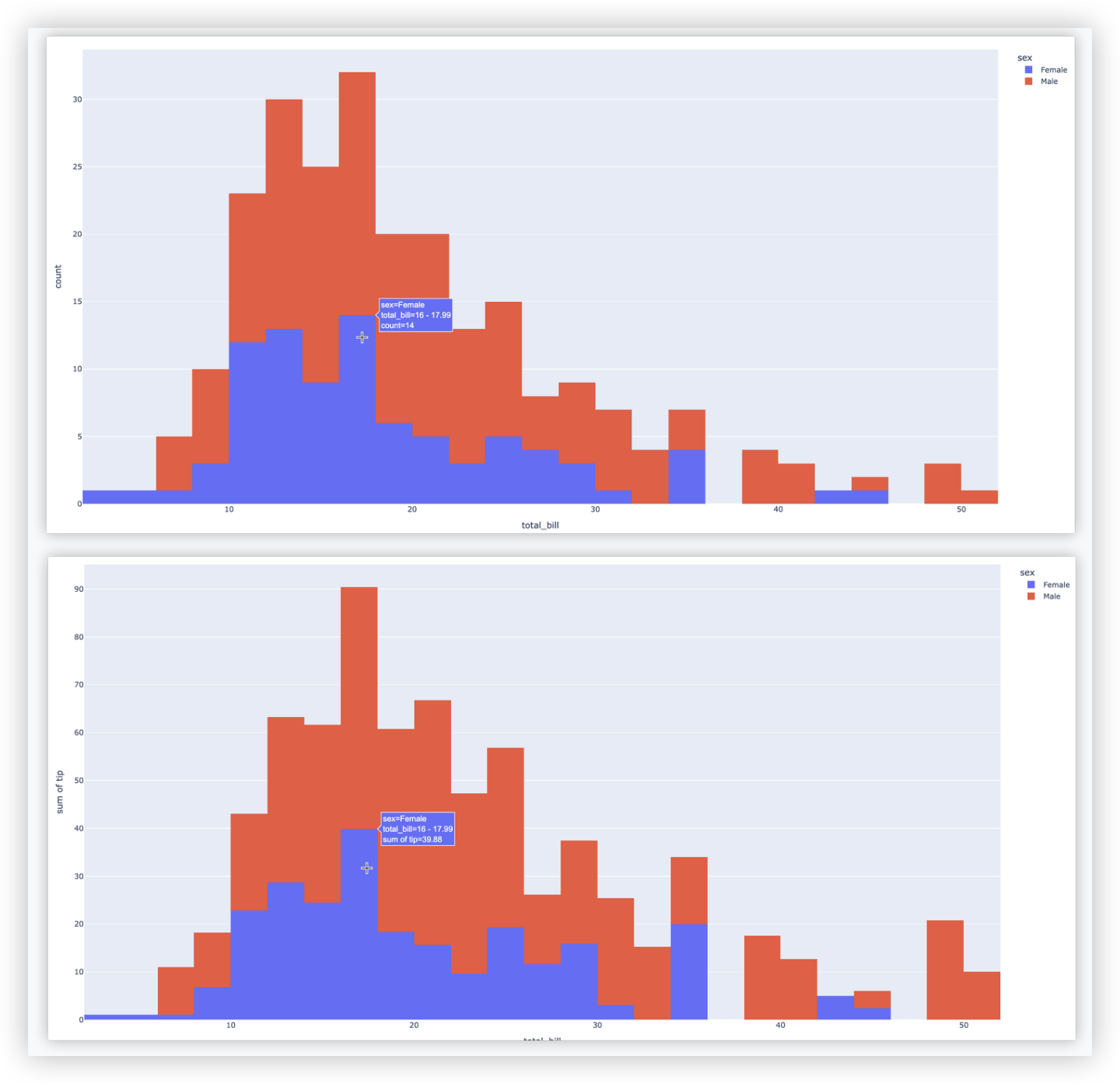
# 直方图
import plotly.express as px
df = px.data.tips()
"""
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
"""
print(df.head())
fig = px.histogram(df, x="total_bill", color="sex")
fig.show()
fig = px.histogram(df, x="total_bill", y="tip", color="sex")
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
示例结果截图如下: (注意哦 第一个图是count, 第二个图是 sum of tip
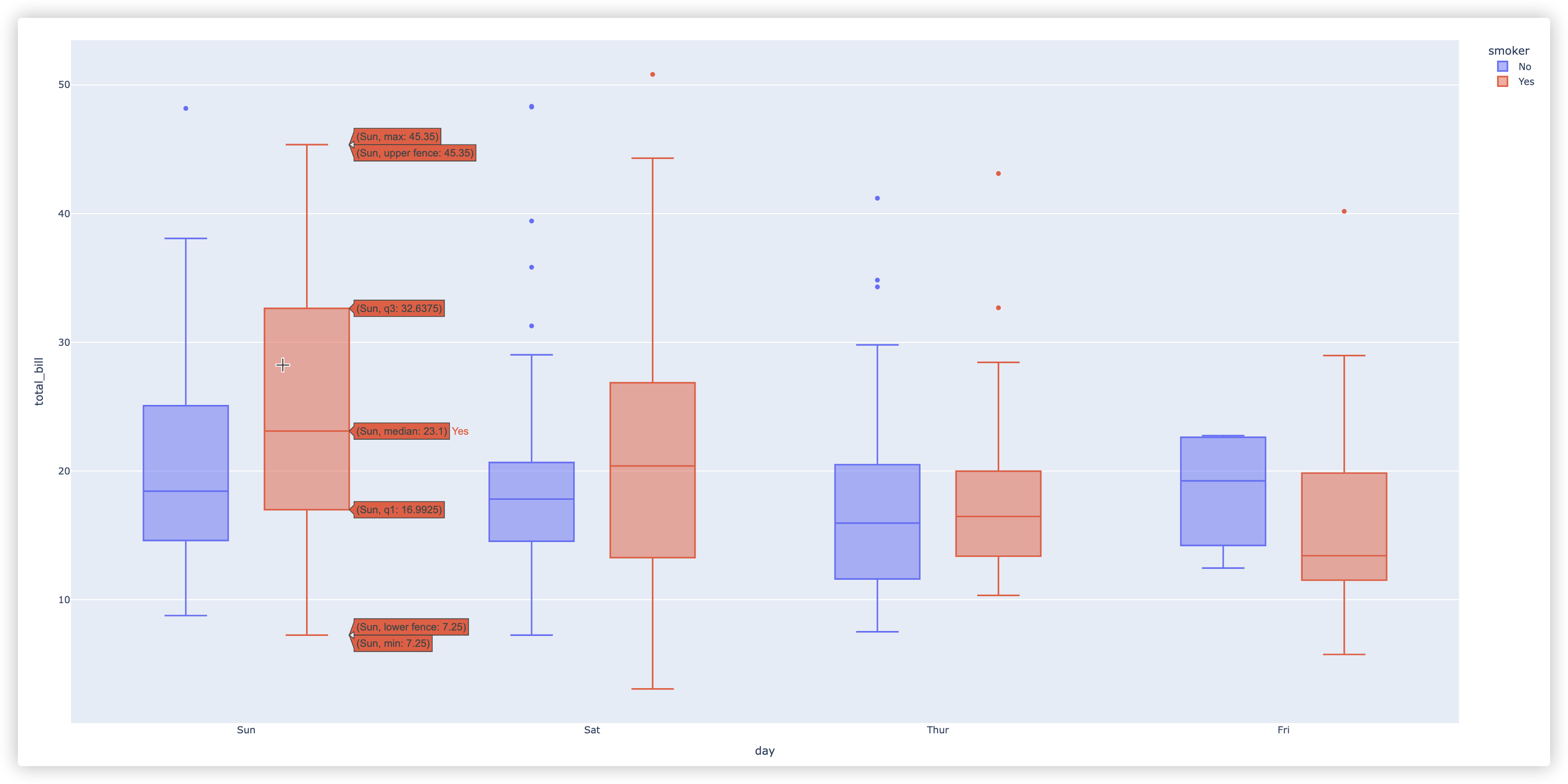
# 箱型图
import plotly.express as px
df = px.data.tips()
"""
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
"""
print(df.head())
fig = px.box(df, x="day", y="total_bill", color="smoker")
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
示例结果截图如下:
# 将plotly与web集成
说一点,pyecharts也是可交互,它与web集成的效果更好. 但是pyecharts有点麻烦,渲染极度依赖网络和渲染资源..
url
from django.urls import path
from api01 import views
urlpatterns = [
path('plotly/', views.plotly_view, name='plotly_view'),
]
2
3
4
5
6
view
import plotly.express as px
import plotly.io as pio
from django.shortcuts import render
def get_plotly_graph():
# 使用 Plotly Express 创建图表
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length")
# 将图表转换为 HTML 字符串
graph_html = pio.to_html(fig, full_html=False)
return graph_html
def plotly_view(request):
# 获取图表的 HTML 字符串
plotly_html = get_plotly_graph()
# 渲染模板,并将图表 HTML 传递给模板
return render(request, 'api01/plotly_template.html', {'plotly_html': plotly_html})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template
<!DOCTYPE html>
<html>
<head>
<title>Plotly Chart</title>
</head>
<body>
<h1>Plotly Chart in Django</h1>
<!-- 将 Plotly 图表的 HTML 插入到模板中 -->
<div>
{{ plotly_html|safe }}
</div>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13