 路由和视图层
路由和视图层
# 路由介绍
url"统一资源定位符,即网址" = 协议 + 域名 + 路径 + get的请求参数"?k1=v1&k2=v2"
from django.contrib import admin
from app01 import views
urlpatterns = [
# -- ★ 特别注意!!首页的正则若写成r'',是能匹配所有的路由/url的,就不会走下面的路由匹配啦!
# 只想匹配空字符,应该以空开头空结尾^$
url(r'^$', views.home), # -- 首页
url(r'^admin/', admin.site.urls),
url(r'^train1/', views.func1),
url(r'^train2/', views.func2),
"""
1> urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续;
2> 若要从URL中捕获一个值,只需要在它周围放置一对圆括号 (分组匹配);
3> 不需要添加一个前导的反斜杠,因为每个URL 都有.
eg: 应该是^articles 而不是 ^/articles.
4> 每个正则表达式前面的'r'是可选的但是建议加上.
Ps:
是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
APPEND_SLASH=True
Django settings.py配置文件中默认没有APPEND_SLASH 这个参数
但Django默认这个参数为 APPEND_SLASH = True. 其作用就是自动在网址结尾加'/'.
具体来说,浏览器会发两次请求,第一次没有/,会301重定向;加上/再发送一次请求!!
若路由是 path("login",views.login) 这样的,那么浏览器只有通过 127.0.0.1:8000/login 才能访问到.不能加/.
"""
### --- ### --- ### --- ### --- ### --- ### --- ###
def home(request):
return HttpResponse('This is home!')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
url函数的第一个参数是匹配的正则!! 举两个例子!
1> 以 r'^test/' 为例, 网址 http://127.0.0.1:8000/test/daf342kmf是可以匹配到的!!
也就是说url的路径部分 test/daf342kmf 能匹配到数据 test/且该数据处于匹配字串的开头!!
2> 再以 r'test' 为例, 网址 http://127.0.0.1:8000/fafatest12是可以匹配到的!!
也就是说url的路径部分中有test 即可.
在Django2.X以上的版本里,使用的是path和re_path!!
path -- 里面写什么就匹配的是什么!多一个少一个都不行!
re_path -- 等同于Django1.X里的url!
用pycharm创建一个名为route的django项目,并在该项目中创建一个名为app01的应用.
记得改模版的路径设置 'DIRS': [os.path.join(BASE_DIR, 'templates')],
暂且把中间件的csrf验证给注释掉!不然post请求会报错.
# 无名/有名分组
无名分组就是将路由后面匹配的参数用小括号阔起来(即通过小括号来捕获URL中的值),
以 位置参数 的形式传递给视图函数!!
url(r'^index/(\d+)', views.index)有名分组就是将路由后面匹配的参数用小括号阔起来,以 关键字参数 的形式传递给视图函数!!
url(r'^test/(?P<aaa>\d+)', views.test)
语法:(?P<name>pattern), 其中name是组的名称,pattern是要匹配的模式.
Ps: url(r'^test/(\d+)/(\d+)/(\d+)', views.index) def index(request, arg1, arg2, arg3) 有名分组同理!
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/(\d+)', views.index), # -- \d+ 一个或多个数字,\d等同于[0-9]
url(r'^test/(?P<aaa>\d+)', views.test),
]
### --- ### --- ### --- ### --- ### --- ### --- ###
from django.shortcuts import render, HttpResponse
def index(request, arg):
print(arg)
return HttpResponse('index')
def test(request, aaa): # -- aaa形参需与命名的名字一样!!若接收多个关键字参数,可以用**kwargs!!
print(aaa)
return HttpResponse('test')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
进行实验验证!
- 启动项目,浏览器输入以下网址:
http://127.0.0.1:8000/index/ -- 报错
http://127.0.0.1:8000/index/ykfd12 -- 报错
http://127.0.0.1:8000/index/12 -- 传递给arg的值为12
http://127.0.0.1:8000/index/12mfd123 -- 传递给arg的值为12
http://127.0.0.1:8000/test/111 -- 传递给aaa的值为111
http://127.0.0.1:8000/test/111fafa -- 传递给aaa的值为111
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图
即无论正则表达式使用的是什么匹配方式,传递到视图函数中的参数永远是一个字符串类型
2
3
4
5
6
7
8
9
10
11
# 反向解析(了解)
反向解析: 通过路由的名字找到该路由的对应的 路径/url..
使用反向解析的 前提 : 给路由起个别名!!
了解即可,用的场景很少!!
1> 普通路由的反向解析
2> 无名分组的反向解析
3> 有名分组的反向解析
还分位置 -- 后端views.py reverse方法、前端html页面..
"""
▲ views.py
"""
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^$', views.home),
url(r'^admin/', admin.site.urls),
url(r'^index/(\d+)', views.index, name='wu_ming'),
url(r'^test/(?P<aaa>\d+)', views.test, name='you_ming'),
url(r'^test1/', views.test1, name='xxx'), # -- name参数给该路由取了个别名!
]
### --- ### --- ### --- ### --- ### --- ### --- ###
"""
▲ urls.py
"""
from django.shortcuts import render, HttpResponse, reverse
def index(request, arg):...
def test(request, aaa):...
def home(request):
# -- 普通路由的反向解析
print(reverse('xxx')) # /test1/
# -- 无名分组的反向解析
# args=('faf456',) -- 报错!
print(reverse('wu_ming', args=(456,))) # /index/456
print(reverse('wu_ming', args=('456faf',))) # /index/456faf
# -- 有名分组的反向解析
# kwargs={'aaa': "yyds2022"} -- 报错!
print(reverse('you_ming', args=(2022,))) # /test/2022
print(reverse('you_ming', args=("2022yyds",))) # /test/2022yyds
# 注意:k值的命名要跟分组的命名一样!!
print(reverse('you_ming', kwargs={'aaa': 2022})) # /test/2022
print(reverse('you_ming', kwargs={'aaa': "2022yyds"})) # /test/2022yyds
return HttpResponse('home')
def test1(request):
return render(request, 'test1.html')
### --- ### --- ### --- ### --- ### --- ### --- ###
"""
▲ test1.html
"""
{# /test1/ /index/456 /index/456faf /test/2022 /test/2022yyds /test/2022 /test/2022yyds #}
<body>
{# -- 前端普通路由的反向解析#}
{% url 'xxx' %}
{# -- 前端无名分组的反向解析 若有多个参数,空格分割即可#}
{% url 'wu_ming' 456 %}
{% url 'wu_ming' '456faf' %}
{# -- 前端有名分组的反向解析 若有多个参数,空格分割即可#}
{% url 'you_ming' 2022 %}
{% url 'you_ming' '2022yyds' %}
{% url 'you_ming' aaa=2022 %}
{% url 'you_ming' aaa='2022yyds' %}
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 路由分发
总路由不再写路由与视图函数的对应关系,总路由用来识别当前过来的url属于哪一个应用!!
一共有两种方式!!
1> 方式一:url(r'^app01/', include(app01_urls)),
2> 方式二:url(r'^app01/', include('app01.urls'))
强调! **总路由中的路径最后不能加' 这样写是错误的!
pycharm Tools - Run manage.py Task 在下方弹出的窗口中,执行命令. startapp app02
记得在settings.py的INSTALLED_APPS列表中添加app02这个应用. 'app02.apps.App02Config'
"""
route下的urls.py -- 总路由
"""
from django.conf.urls import url, include # -- 使用include.
from django.contrib import admin
from app01 import urls as app01_urls # -- 使用别名.
from app02 import urls as app02_urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
# -- ★ 第一种方式!
# url(r'^app01/', include(app01_urls)),
# url(r'^app02/', include(app02_urls)),
# -- ★ 第二种方式!
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]
"""
app01下的urls.py -- 分路由
"""
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^index/', views.index),
]
"""
app02下的urls.py -- 分路由
"""
from django.conf.urls import url
from app02 import views
urlpatterns = [
url(r'^index/', views.index),
]
"""
app01下的views.py
"""
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('app01_index')
"""
app02下的views.py
"""
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('app02_index')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
进行实验验证!
- 启动项目,浏览器输入以下网址:
http://127.0.0.1:8000/app01/index/ -- 页面展示内容'app01_index'
http://127.0.0.1:8000/app02/index/ -- 页面展示内容'app02_index'
2
3
# JsonResponse对象
想在后端将字典转换成json格式的数据在前端页面展示!
有一个问题,若字典中的k-v的值里包含中文,在某些浏览器上展示的是unicode编码!!
Ps:谷歌会自动将unicode编码转成中文,Mac自带的浏览器不会!
这里以苹果浏览器为例.
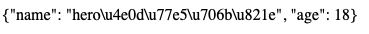
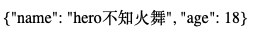
★ 有两种方式将上面的unicode展示成中文!!
1> json.dumps(user_dic, ensure_ascii=False)
2> JsonResponse(user_dic, json_dumps_params={'ensure_ascii': False})
import json
from django.http import JsonResponse
from django.shortcuts import HttpResponse
def a_json(request):
user_dic = {'name': 'hero不知火舞', 'age': 18}
# -- 方式一
# user_json = json.dumps(user_dic, ensure_ascii=False)
# -- 方式二
user_json = JsonResponse(user_dic, json_dumps_params={'ensure_ascii': False})
return HttpResponse(user_json)
Ps: 前端JS中的序列化与反序列化 -- JSON.stringify、JSON.parse
2
3
4
5
6
7
8
9
10
11
12
13
14
15
为何?查看dumps和JsonResponse的源码进行分析!
dumps的源码如下:
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
2
3
JsonResponse的源码如下:
class JsonResponse(HttpResponse):
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
# -- safe为True且JsonResponse的实例化对象不是字典的话就会raise抛出异常!
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
# -- 看这里,本质还是调用了json.dumps!
# **json_dumps_params是将字典拆分成关键字参数传值!
# so,我们只需要将json_dumps_params={'ensure_ascii': False}
# 就能达到json.dumps(user_dic, ensure_ascii=False)的效果!! amazing!
data = json.dumps(data, cls=encoder, **json_dumps_params)
super(JsonResponse, self).__init__(content=data, **kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
扩展: 我们不局限于将字典序列化,还可以将列表序列化!!
def a_json(request):
user_list = ['hero不知火舞', 18]
user_json = json.dumps(user_list, ensure_ascii=False)
print(type(user_json)) # <class 'str'>
user_json = JsonResponse(user_list, safe=False, \
json_dumps_params={'ensure_ascii': False})
print(type(user_json)) # <class 'django.http.response.JsonResponse'>
return HttpResponse(user_json)
"""实验结果如下:
return HttpResponse(user_list)
前端展示的是 hero不知火舞18
return HttpResponse(user_json)
前端展示的是 ["hero不知火舞", 18]
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# request对象
request.FILES 接收上传的文件
request.path和request.path_info只能取到url中的路径
request.get_full_path()可以取到url中的路径以及get请求的请求参数!
先回顾前面已经学习了的request对象的方法:
request.method
request.GET.get()
request.GET.getlist()
request.POST.get()
request.POST.getlist()
2
3
4
5
app01下的views.py
★ 在浏览器里输入网址 http://127.0.0.1:8000/app01/func/ ;
会先执行一遍func函数,此时MultiValueDict也是为空的;
上传图片提交后,会再执行一遍func函数,MultiValueDict对象才有了文件数据!
★ request.get_full_path()
1> 若输入的网址是http://127.0.0.1:8000/app01/func/123456,
path、path_info、get_full_path()得到的结果 都是 /app01/func/123456;
2> 若输入的网址是http://127.0.0.1:8000/app01/func/?name=dc,
path和path_info得到的结果是 /app01/func/
get_full_path()得到的结果是/app01/func/?name=dc
def func(request):
print(request.POST) # <QueryDict: {}>
# <MultiValueDict: {'myfile': [<InMemoryUploadedFile: one.jpg (image/jpeg)>]}>
print(request.FILES)
print(request.path) # /app01/func/
print(request.path_info) # /app01/func/
print(request.get_full_path()) # /app01/func/
# -- 在func.html的form表单里,实现上传图片必须做两件事:
# 1> 请求方式改成post;
# 2> 改enctype="multipart/form-data"
return render(request, 'func.html')
2
3
4
5
6
7
8
9
10
11
app01下的urls.py
urlpatterns = [
... ...
url(r'^func/', views.func),
]
2
3
4
func.html
<body>
<form action="" method="post" enctype="multipart/form-data">
<input type="file" name="myfile">
<input type="submit">
</form>
</body>
2
3
4
5
6
# CBV使用及源码
FBV : function base view 基于函数的视图, 即视图用函数的形式编写 -- 多用于前后端混合
CBV : class base view 基于类的视图, 即视图用类的形式编写 -- 多用于前后端分离(drf).若是get请求,views.MyLogin.as_view(),直接调用了MyLogin类中get的方法!源码分析可验证!
究其本质, 无论是FBV还是CBV, 都是一个url对应一个函数!!!
app01下的views.py
cbv是根据请求方式区别访问哪个方法的
eg: http://127.0.0.1:8000/app01/login/ 是get请求,会访问get方法!
from django.shortcuts import render, HttpResponse
from django.views import View
# -- !! CBV必须继承View
class MyLogin(View):
def get(self, request):
# 若请求方式是GET,会自动执行该函数
return HttpResponse('get')
def post(self, request):
# 若请求方式是POST,会自动执行该函数
return HttpResponse('post')
# -- 那如何使用的MyLogin里的get方法呢?
# 按照我们的理解,需要 obj = MyLogin() obj.get()
# 这个操作不需要我们来做,Django帮我们做了!哪里做的?看后面的源码分析.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
app01下的urls.py
urlpatterns = [
# -- fbv的路由
url(r'^func/', views.func),
# -- cbv的路由
# MyLogin类里没有as_view,就会去as_view的父类View里找!!
url(r'^login/', views.MyLogin.as_view()),
]
2
3
4
5
6
7
views.func的结果指向func这个PyFunctionObject对象的内存地址;
我们猜想,views.MyLogin.as_view()的结果应该是MyLogin类中get/post方法的内存地址???
通过源码进行分析验证!!
分析结果证明,views.MyLogin.as_view()里用了闭包,先返回了一个函数,路由匹配成功,最终直接调用了MyLogin里的get/post方法!!
从as_view的源码进行切入!
class View(object):
# -- 该列表里存放着所有的请求方式,共8种!
http_method_names = ['get', 'post', 'put', 'patch', ... ]
... ...
@classonlymethod # -- ctrl+B跳转后可以看到classonlymethod继承的就是classmethod 准确点说,这里是描述符
# -- as_view是一个类方法!! 我们写的MyLogin类中没有,用的是MyLogin的父类View中的!!
# as_view() 然后直接看as_view的返回值,返回的是view这个函数的内存地址!!!
# 也就是说 views.MyLogin.as_view() 返回的是 view这个函数的内存地址!!!
def as_view(cls, **initkwargs):
... ...
# 匹配成功后,会将路由中的参数给到 def view(request,*args,**kwargs)里
def view(request, *args, **kwargs):
# -- 分析可得,cls就是MyLogin
# cls(**initkwargs)就是MyLogin(**initkwargs) 进行了类实例化 self = MyLogin()
# 参数是啥?不用管. 只要知道这里的self是MyLogin的 类实例化对象/实例
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
# -- !!★ 重点! 实例.dispatch() 按照顺序,最终调用的还是View中的dispatch方法!
return self.dispatch(request, *args, **kwargs)
... ...
return view
# -- CBV的核心代码!!
def dispatch(self, request, *args, **kwargs):
# -- 若是get请求,request.method的值GET,经过转化,值为get,该值在http_method_names列表里!
if request.method.lower() in self.http_method_names:
# -- 运用了反射,通过字符串的形式按照顺序从实例-类-父类等的命名空间中找属性和方法!
# 这里的self是MyLogin的实例!!
# getattr(MyLogin(),'get',没找到返回的值)
# MyLogin类中是有get方法的
# !!★ So!此处的handle是MyLogin类中get方法的内存地址
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
# -- 不成立的情况,跳转到http_method_not_allowed方法里,发现是一个警告
# 不成立的情况没啥好看的.
handler = self.http_method_not_allowed
# -- 直接调用了MyLogin类里的get方法!!
# 这里也证明了我们写的get方法,第一个参数得是request接收一下!
return handler(request, *args, **kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
分析完源码,有个需求,我们的CBV里限制只能GET请求,如何实现?
class MyLogin(View):
# -- 源码里, `if request.method.lower() in self.http_method_names:`
# 虽然在self的命名空间中没有http_method_names,但在MyLogin中已经找到啦!!
# 就不会去View类中找http_method_names啦!!!源码中的http_method_names就没用啦.
http_method_names = ['get'] # -- 限制请求的方式
def get(self, request):
return HttpResponse('get')
def post(self, request):
return HttpResponse('post')
2
3
4
5
6
7
8
9
10
11
# 补充
必掌握: 路由传统写法、路由分发、路由别名name..
# 路由的传统写法
http://127.0.0.1:8000/home/12/etid/?page=20&nid=22
1> <str:nid> str表示nid参数为字符串,注,不包含`/`
2> <int:nid> 整数
3> <slug:nid> 只能匹配字母数字下划线以及`-`
4> <uuid:nid>
>>> import uuid
>>> uuid.uuid4()
UUID('dce81d0c-bca3-4a9f-9eac-300dba32a267') # 特征为8-4-4-4-12
5> <path:nid> 路径,表明可以 匹配到(包含) `/`
eg: http://127.0.0.1:8000/home/f1/f2/f3/etid/?page=20&nid=22
上述的写法,Django1.x是不支持的!!Django1.x更多的是使用正则来表示动态路由!当然Django后续的版本也支持正则.
2
3
4
5
6
7
8
9
10
11
12
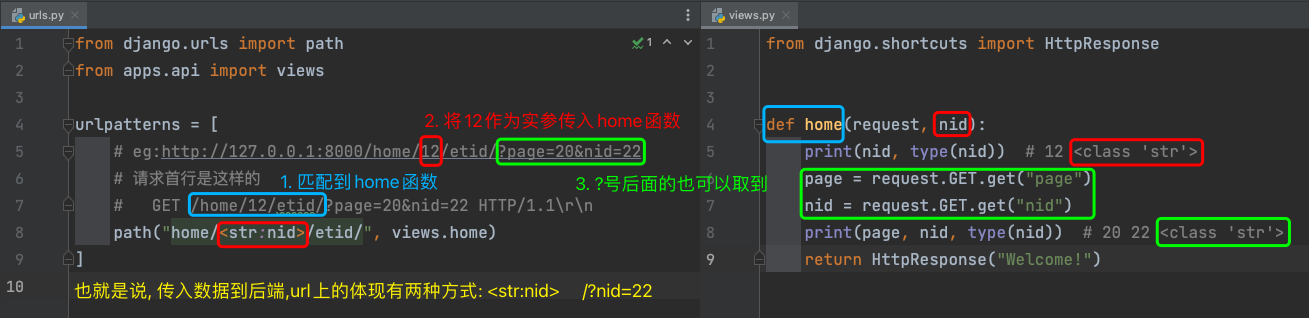
Ps: url中 ?后面的值会赋值给 request.GET --> <QueryDict: {'page': ['20'], 'nid': ['22']}>
# 包含正则的路由
注: 只要路由里有动态值的传递, 视图函数都得拿一个值来接受!!
from django.urls import path, re_path
from apps.api import views
urlpatterns = [
# eg: http://127.0.0.1:8000/users/abc-22/
# 记得加括号,加括号进行分组,提取url中的`abc-22`传递给视图函数users的xid参数. -- 是按位置传递的!!
# re_path(r"users/(\w+-\d+)", views.users)
# eg: http://127.0.0.1:8000/users/abc-22/33/
# 有名分组,是以关键字参数的形式传递给视图函数的 当然视图函数可以用 **kwargs来接收
re_path(r"users/(?P<xxid>\w+-\d+)/(?P<yid>\d+)", views.users)
]
def users(request, xxid, yid):
print(xxid, yid) # abc-22 33
return HttpResponse("Hello")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 路由分发
1> 将路由分发到不同的app里, 以便实现功能业务的划分.
2> 路由手动分发. - 将一些url的前缀提取出来.
扩展思维, 可以在api这个app里创建一个urls文件夹, 里面有v1.py、v2.py两个路由文件.. 总路由分发到这两个文件.
path('api/', include("apps.api.urls.v1")),path('api/', include("apps.api.urls.v2"))
views视图函数文件同理!! 不要只看到表象, 重点是理解路由分发的本质!!
from django.urls import path, re_path, include
urlpatterns = [
# 查看源码,这里include函数返回的是一个包含三个元素的元组 (api这个app的urls模块对象,None,None)
# 虽然该元祖的第一个元素是urlconf_module,但path方法会提取该模块对象的urlpatterns..
"""
在总路由里写了 path('api/', include("apps.api.urls"))
针对 include函数,查看源码,带入"apps.api.urls"这个实参, 发现include函数返回了一个包含三个元素的元祖,
该元祖的第一个元素是在api这个app里定义的urls模块..
既然确定了返回的元祖中的第一个元素是模块对象.. 那么肯定有后续的处理来 拿到api.urls里的urlpatterns列表.
简单的找了下,path -- _path -- URLResolver -- url_patterns里面
patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module)
"""
path('api/', include("apps.api.urls"))
]
from django.urls import path, re_path
from . import views
urlpatterns = [
path("home/<str:nid>/etid/", views.home),
# http://127.0.0.1:8000/api/users/abc-22/33
re_path(r"users/(?P<xxid>\w+-\d+)/(?P<yid>\d+)", views.users),
]
# !!可以将路由进行手动分发,即提取多个路由的公共部分
# ★ 可以看include的源码,路由手动分发的本质跟include是一样的!!
"""
# path("user/add/", views.user_add),
# path("user/list/", views.user_list),
# path("user/delete/", views.user_delete),
# path("user/edit/", views.user_edit),
# -- 等同于
path("user", ([
path("add/", views.user_add),
path("list/", views.user_list),
path("delete/", views.user_delete),
path("edit/", views.user_edit),
], None, None)) # 看源码可知,第一个None赋值给app_name,第二个None赋值给namespace
# -- 扩展下,也等同于
path("user", include(([
path("add/", views.user_add),
path("list/", views.user_list),
path("delete/", views.user_delete),
path("edit/", views.user_edit),
], None)))
"""
# -- 补充一个知识点,便于看include的源码.
path = "apps.api.urls"
import importlib
md = importlib.import_module(path) # 等同于 from apps.api imort urls
md.app_name # 等同于 urls.app_name
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 路由别名name
根据名字反向生成url
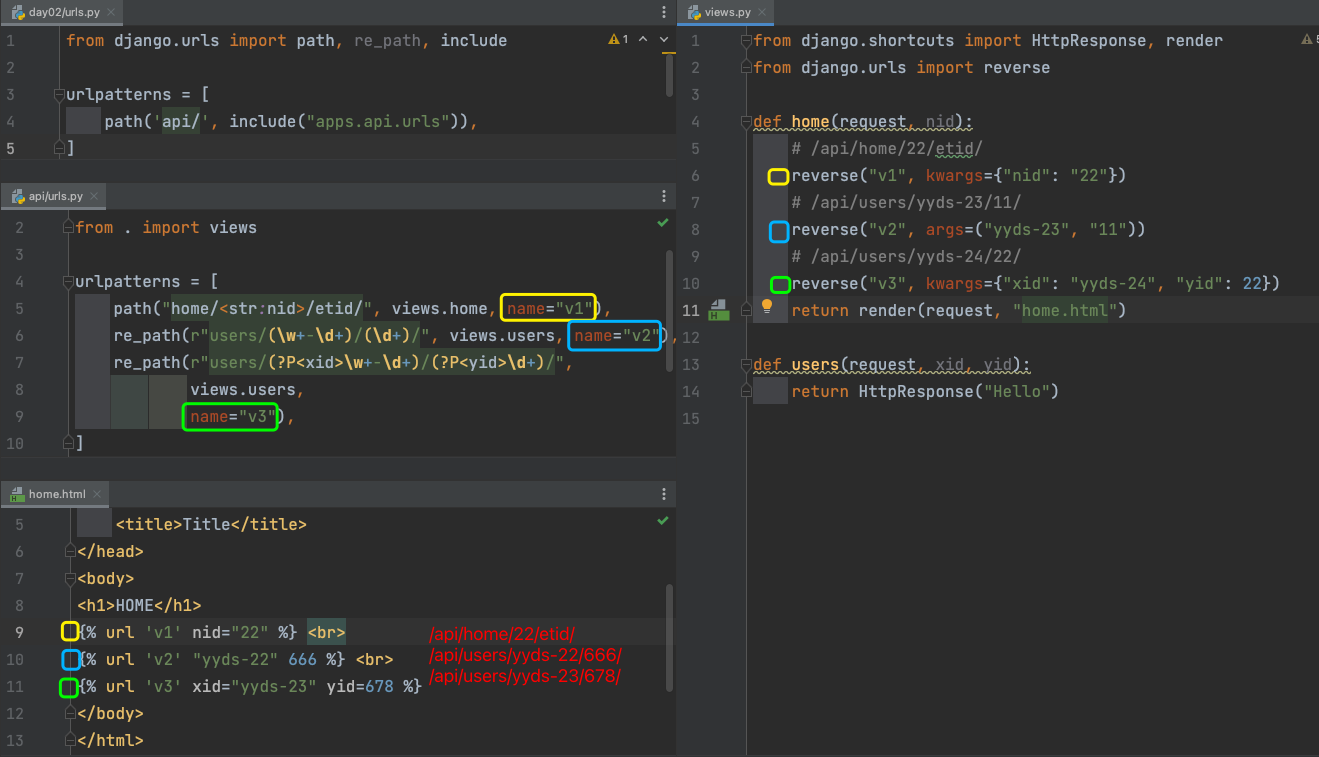
# namespace
协同开发, 在api和web两个app里都有一个名为auth的路由..
利用name反向解析url的时候就会报错.. 需要定义namespace!!! 记得加上 app_name.namespace的应用场景: 定义了很多url,name重名时,反向解析url可能找不到..可以加上namespace加以区分.
总路由urls.py
from django.urls import path, re_path, include
urlpatterns = [
path('api/', include("apps.api.urls", namespace='x1')), # namespace
path('web/', include("apps.web.urls", namespace='x2')),
]
2
3
4
5
6
api/urls.py
from django.urls import path, re_path
from . import views
urlpatterns = [
path("login", views.login, name="login"),
path("auth", views.auth, name="auth")
]
app_name = 'api' # app_name
2
3
4
5
6
7
8
9
web/urls.py
from django.urls import path, re_path
from . import views
urlpatterns = [
path("home", views.home, name="home"),
path("auth", views.auth, name="auth")
]
app_name = 'web' # app_name
2
3
4
5
6
7
8
利用路由别名name反向生成url
from django.urls import reverse
url = reverse("x1:login")
url = reverse("x1:auth")
url = reverse("x2:home")
url = reverse("x2:auth")
# -- 模版中的改法同理.
# 扩展,基本用不到就不做过多阐述了.
# 其实可以手动分发路由.([],app_name,namespace)
# 还可以进行namespace的多层嵌套. 反向生成url时,namespace:namespace:name -- django admin组件的源码中有用到.
2
3
4
5
6
7
8
9
10
11
12
# 路由当前匹配对象
"""
ResolverMatch(func=apps.api.views.home,
args=(),
kwargs={'nid': '22'},
url_name=v1,
app_names=['api'],
namespaces=['x1'],
route=api/home/<str:nid>/etid/)
"""
在视图函数里, print(request.resolver_match)
app_name、namespaces是列表,是因为路由分发是可以嵌套的.
有什么用呢?用于用户权限访问控制!!!
2
3
4
5
6
7
8
9
10
11
12
13
# 偏函数partial
学会偏函数,便于看源码eg:path和re_path -- 包裹一个函数,并默认传递一个值
from functools import partial
def _xx(a, b):
return a + b
xx = partial(_xx, b=100)
print(xx(1)) # 101
2
3
4
5
6
7
8
# request对象
request是一个对象
- 存放了浏览器给咱们发过来的所有内容.即请求相关的所有数据: 请求方式、当前访问的路由...
- Django额外添加的数据:
匹配成功后,生成的一个包含所有路由相关数据的路由对象 request.resolver_match
session相关的数据 request.session
扩展思维:
若能在路由层和视图函数层中间捕获到request
捕获到后,进行request.xxx = 123的操作,那么视图函数的request对象里就会有xxx这个成员!!
2
3
4
5
6
7
8
9
request对象里常见的东西 -- 《请求相关的数据》
request.POST、request.FILE、request.COOKIES 对传过来的数据进行了再次加工处理
"""
GET http://127.0.0.1:8000/api/login/?name=dc&age=18
"""
request.path_info # 当前url --> /api/login/
request.method # GET
request.GET # <QueryDict: {'name': ['dc'], 'age': ['18']}>
request.GET.get("name") # dc
request.GET.get("xxx") # None
request.body # 若发送的是GET请求,请求体是空的,得到的结果是 --> b''
request.headers # {'Content-Length': '', 'Content-Type': 'text/plain', 'Host': '127.0.0.1:8000', ...}
request.COOKIES
"""
先注销掉crsf中间件,用postman模拟发送POST请求
POST http://127.0.0.1:8000/api/login/?name=dc&age=18
request.POST是取不到json格式的数据!!!!!!!
"""
request.path_info # 当前url --> /api/login/
request.method # POST
request.GET # <QueryDict: {'name': ['dc'], 'age': ['18']}>
request.GET.get("name") # dc
request.GET.get("xxx") # None
request.headers # Django内部将请求头封装成了一个字典!
# !!若想提取请求头中的cookie,若通过request.headers['cookie']的方式,得到的结果是 "csrftoken=....;session=..."
# 还需要自行切割,得到想要的数据. request.cookies会将其处理成一个字典.
request.COOKIES # {"csrftoken":"...","session":"..."}
★ request.body 能够拿到请求体中的原始数据,只要有人给你发请求体的数据,一定在request.body里放着呢,没有?那就是没发过来!!
-- `POST请求发送JSON格式数据,{"code":200,"msg":"请求成功!"}`
其请求头中包含 Content-Type:application/json
request.body # b'{"code":200,"msg":"\xe8\xaf\xb7\xe6\xb1\x82\xe6\x88\x90\xe5\x8a\x9f!"}'
-- `POST请求发送urlencoded格式数据`
request.body # b'phone=17380765456&password=admin123'
-- `若request.body得到的数据的格式是 b'v1=123&v2=234'
且请求头中包含 Content-Type:application/x-www-form-urlencoded
只要满足这两个条件,Django内部会将b'v1=123&v2=234'自动进行切割,封装解析成一个字典
我们可以通过request.POST获取到这个字典`
应用场景:比如登陆的表单一般就会构建成 v1=123&v2=234 这个格式,并加上一个Content-Type请求头发送到后端.
request.POST # <QueryDict: {'phone': ['17380765456'], 'password': ['admin123']}>
request.POST.get("phone") # 17380765456
request.POST.get("password") # admin123
-- `若POST请求传给后端的是文件
满足两个条件,文件格式的数据 + 请求头Content-Type:multipart/form-data
Django内部就会将request.body中的文件数据转换为文件对象
我们可以通过request.FILES获取到这个文件对象`
request.FILES
request.FILES.get("file_name")
★ POST请求补充:
首先要明确!
POST的请求方式才会有请求体,GET请求是没有请求体的!!
POST请求的参数放在请求体里,无大小限制;GET请求的参数放到URL地址中,有大小限制(小于1k)!!
Post请求携带的Body请求体里提交到后端的数据, 对其常用的<编码格式>有3种!
即POST以 什么样子/什么编码格式 组织数据提交到后端!
1> urlencoded(默认) -- request.POST
会用&符号作为分隔符组织多组k-v数据放到请求体中,提交到后端
eg: hobby=篮球&hobby=足球&aa=aa # -- 会对汉字篮球足球进行编码!
2> formdata -- 普通数据部分 request.POST; 文件部分 request.FILES
既可以传文件,又可以传普通数据
其在请求体中的格式如下(了解):
普通数据部分"name=egon&age=18" + 文件部分"先以--flakjfalk--作为分割,然后是文件的二进制数据"
有分割后,就能清楚的知道从哪开始读文件.
Ps:form表单元素在使用包含文件上传的表单控件时,必须给表单元素的enctype属性设置该值
3> json
json格式的数据直接放到请求体中
eg: {"name":"egon","age":19}
注意!POST请求提交到Django后端的json格式的数据,request.POST是接受不到的!!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
源码分析
"""
application = get_wsgi_application() # 从wsgi.py文件入手!
def get_wsgi_application():
return WSGIHandler()
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest
def __call__():
... ...
return response # 意味着,在application该实例加括号时,会得到response!!
# ps:在settings文件里,还有这样的配置 - WSGI_APPLICATION = 'day00.wsgi.application'
class WSGIRequest(HttpRequest):
WSGIRequest类继承了HttpRequest类,可以在HttpRequest类的__init__源码中,看到
self.GET = QueryDict(mutable=True)
self.POST = QueryDict(mutable=True)
So,我们在视图函数中打印request.GET、request.POST的类型都是QueryDict,并且QueryDict继承的是dict字典类!!
更准确来讲,还用不到HttpRequest类里的POST和GET,WSGIRequest类里对POST、GET已经进行了定义!
关键代码:
@cached_property
def GET(self):..
POST = property(_get_post, _set_post)
详细说说POST,request.POST会调用request._get_post, 即request.POST和request._get_post()的效果一样!!
_get_post方法里会调用_load_post_and_files方法,该方法最关键的在于,进行了两个判断!
if self.content_type == 'multipart/form-data':
... ...
elif self.content_type == 'application/x-www-form-urlencoded':
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
"""
"""
request.POST command+b查看POST的源码
有两个python知识点,POST = property(_get_post, _set_post) 和 @property
"""
class HttpRequest:
"""A basic HTTP request."""
_encoding = None
_upload_handlers = []
def __init__(self):
self.GET = QueryDict(mutable=True) # !
self.POST = QueryDict(mutable=True) # !
self.COOKIES = {}
self.META = {}
self.FILES = MultiValueDict()
self.path = ''
self.path_info = ''
self.method = None
self.resolver_match = None
self.content_type = None
self.content_params = None
# ... ... ...
class WSGIRequest(HttpRequest):
... ...
def _get_post(self):
# 一开始的时候,里面是没有_post的
# 执行_load_post_and_files方法,去浏览器发送过来的请求体中解析body数据.本质就是解析后赋值给self._post
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
def _set_post(self, post):
self._post = post
@cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return parse_cookie(raw_cookie)
@property # 使得可以通过request.FILES中取得值,调用该方法时就不用加括号了.
def FILES(self):
if not hasattr(self, '_files'):
# 同样的,需要去请求体中进行解析
self._load_post_and_files()
return self._files
POST = property(_get_post, _set_post)
"""
跳转,查看_load_post_and_files方法的源码
"""
def _load_post_and_files(self):
... ...
# 用postman发送数据的时候
# 1> 若发送的是form_data类型的数据,请求体里的content_type == 'multipart/form-data'
# 可以传普通数据,也可以传文件
# 2> 若发送的是urlencoded类型的数据,请求体里的content_type == 'application/x-www-form-urlencoded'
# 只能传递普通数据
# 注:无论发送的数据是啥类型,Django都是对self.body原始数据进行处理.
# Ps: content_type来自WSGIRequest中init里的self._set_content_type_params(environ)
if self.content_type == 'multipart/form-data':
if hasattr(self, '_body'):
# 放到BytesIO对象中
data = BytesIO(self._body)
else:
data = self
try:
# 在Django中,上传文件后,会将文件放到一个临时对象中,通过临时对象.save就能保存.
self._post, self._files = self.parse_file_upload(self.META, data)
except MultiPartParserError:
self._mark_post_parse_error()
raise
elif self.content_type == 'application/x-www-form-urlencoded':
# self.body原始数据,encoding=self._encoding编码,QueryDict类将原始数据进行了封装,将其复制给了self._post
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
# 视图
# 返回数据
HttpResponse、JsonResponse、redirect、render
django返回给客户端浏览器的都必须是HttpResponse对象
"""
字符串/字节/文本数据 应用场景:返回图片的原始文本内容,图片验证码
"""
from django.shortcuts import HttpResponse
def login(request):
return HttpResponse("")
"""
Json格式数据 应用场景:前后端分离、app小程序后端、ajax请求
"""
from django.http import JsonResponse
def login(request):
data_dict = {"status": True, "data": [11, 22, 33]}
return JsonResponse(data_dict)
"""
重定向
"""
from django.shortcuts import redirect
def login(request):
# 原理:将这个地址放到响应头的Location字段中,让浏览器再向这个地址发送请求. 并不是Django拿到这个地址的内容给浏览器.
# ★ 这里面还可以写url的别名!!会反向自动转换成url!!
# 但不建议这样用,若想用name,建议先reverse一下,再放到redirect函数中,这样比较清晰.
return redirect("https://www.baidu.com")
"""
渲染
"""
from django.shortcuts import render
def login(request):
# a.找到login.html并读取内容. 问题:去哪里找?
# 1> 默认先去setting.TEPLATES.DIRS指定的路径中找.一般会在项目根目录下创建一个templates目录.放公共的模版.
# 2> 按照app的注册顺序,去每个app中找它的templates目录!再去该目录中找对应模版!
# ★ 原则:多app的情况,会在app的templates目录下再嵌套一层命名为app名字的目录..该目录下放模版!!
# 扩展,Django内置的app也有一些模版,比如admin这个app的404页面.想要覆盖掉,在项目根目录下,templates/admin/404.html
# b.渲染 得到替换完成的字符串
# c.将数据放到<响应体>里返回给浏览器
return render(request, 'web/login.html')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 设置响应头
应用场景:前后端分离涉及到csrf、jwt、cors跨域时会用到!!
from django.shortcuts import HttpResponse
def login(request):
res = HttpResponse("Hello")
# 设置响应头
res["xx1"] = "qwe"
res["xx2"] = "asd"
res["xx3"] = "zxc"
# 还可以在响应头里设置cookies
res.set_cookie("k1","aaaaa")
res.set_cookie("k2","bbbbb")
return res
2
3
4
5
6
7
8
9
10
11