PyTorch简单分类
PyTorch简单分类
下面, 我们将演示和学习如何使用Pytorch构建网络结构处理分类问题的全过程. (∩_∩)
# 数据准备
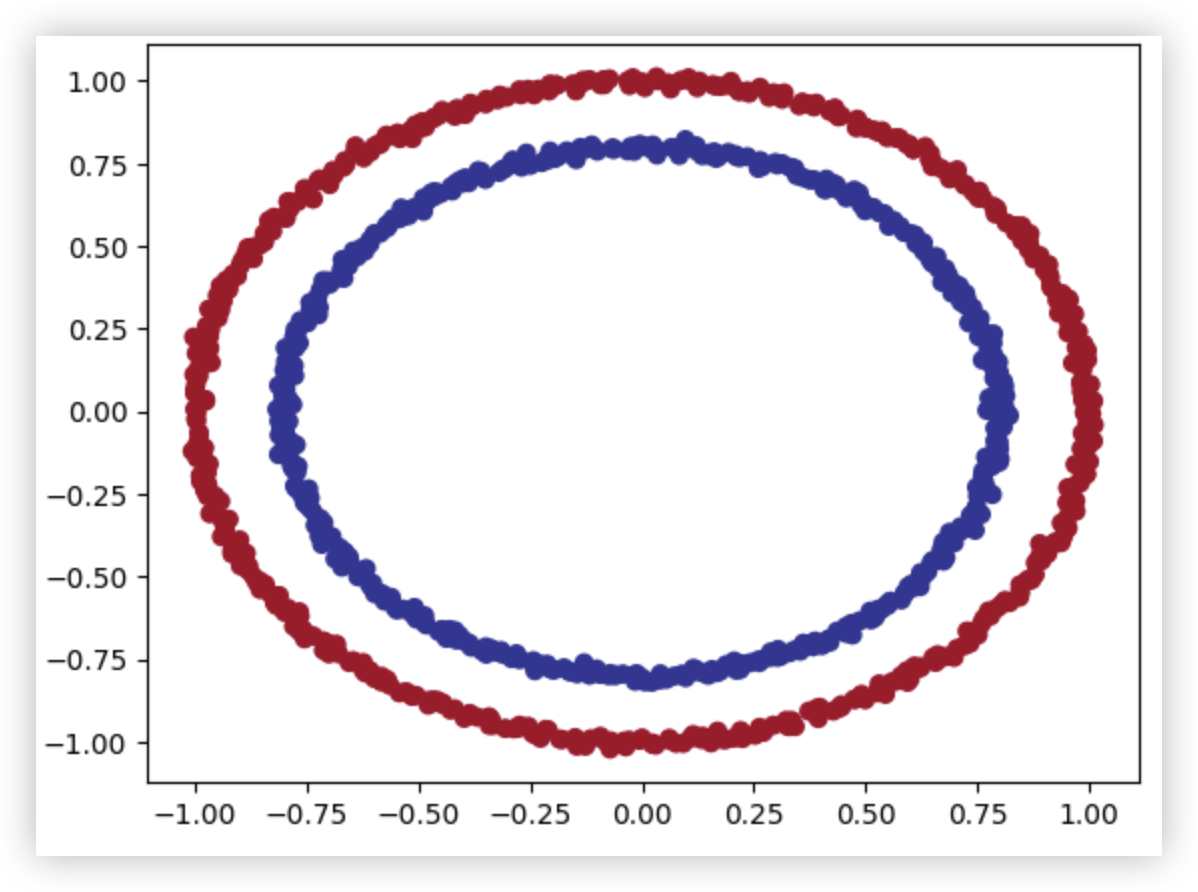
利用sklearn来构建环形数据, 后续会对其进行二分类的处理.
from sklearn.datasets import make_circles
import pandas as pd
import matplotlib.pyplot as plt
n_samples = 1000
# Create circles
X, y = make_circles(n_samples, # 1000个样本
noise=0.01, # 添加一点噪点数据
random_state=42) # 随机数种子
# 将数据封装成dataframe类型(key是列),便于可视化
circles = pd.DataFrame({"X1": X[:, 0],"X2": X[:, 1],"label": y})
plt.scatter(x=X[:, 0], y=X[:, 1], c=y, cmap=plt.cm.RdYlBu);
2
3
4
5
6
7
8
9
10
11
12
13
14
PS: 可能会出现版本兼容的问题.
import sklearn
import numpy
import pandas
print(sklearn.__version__,numpy.__version__,pandas.__version__)
"""1.6.1 1.26.4 1.4.4"""
# 更新完后,记得shut down当前ipynb后,再重新打开该ipynb.
2
3
4
5
6
7
# 数据集切分 + 数据转换
# 数据集切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将数据从numpy类型转换为张量类型
import torch
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
2
3
4
5
6
7
8
9
10
11
# 建模
此示例中搭建了一个4层的网络结构
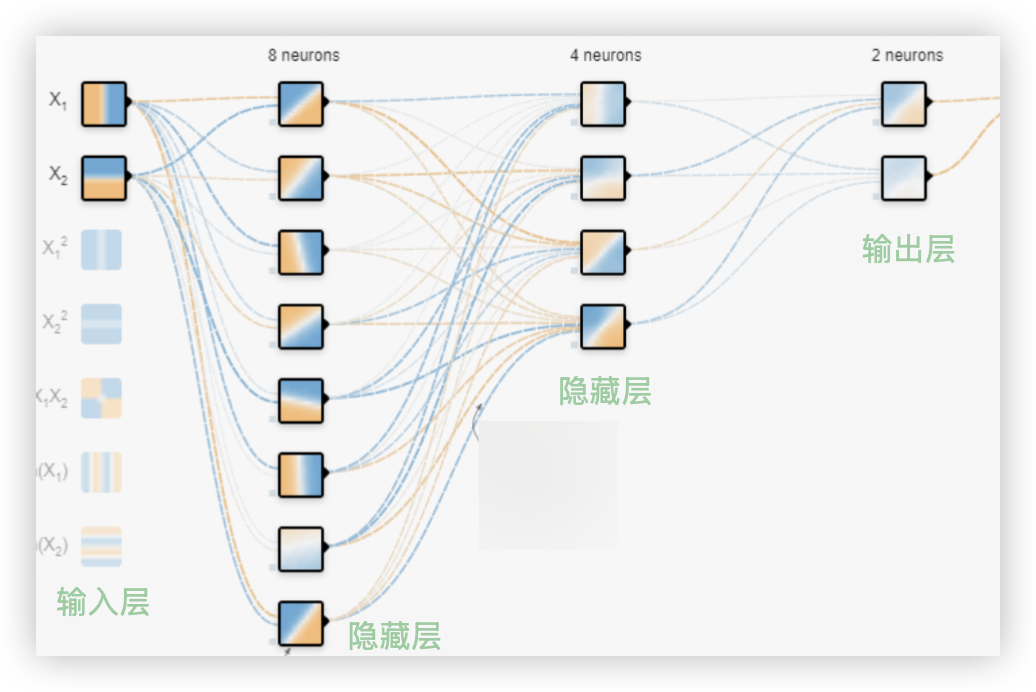
- 输入层只有两个神经元, 因为数据集只有两个维度的特征
- 第二层、第三层是隐藏层, 分别有8个和4个神经元, 这是我们自己设定的, 当然你可以改.
- 因为是二分类任务, 所以输出层也只有两个神经元..
这两个神经元输出的是概率, 分别代表样本是类别0和类别1的概率.. 哪个概率高,则该样本就属于哪个类别.
ps: 若是回归任务,输出层只需要一个神经元,因为只需一个预测结果
# 搭建网络结构
搭建网络结构有两种方式实现, 任选其一即可:
nn.Module;nn.Sequential
我更喜欢使用第二种方式搭建网络结构, 因为 nn.Sequential 不用自定义表, 也不用手写正向传播的函数..
# nn.Module
import torch
from torch import nn
# 设置device
# device = "cuda" if torch.cuda.is_available() else "cpu" # 若是windows
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu") # mac
class CircleModelV0(nn.Module): # 1.继承 nn.Module
def __init__(self):
super().__init__()
# 2.创建网络结构
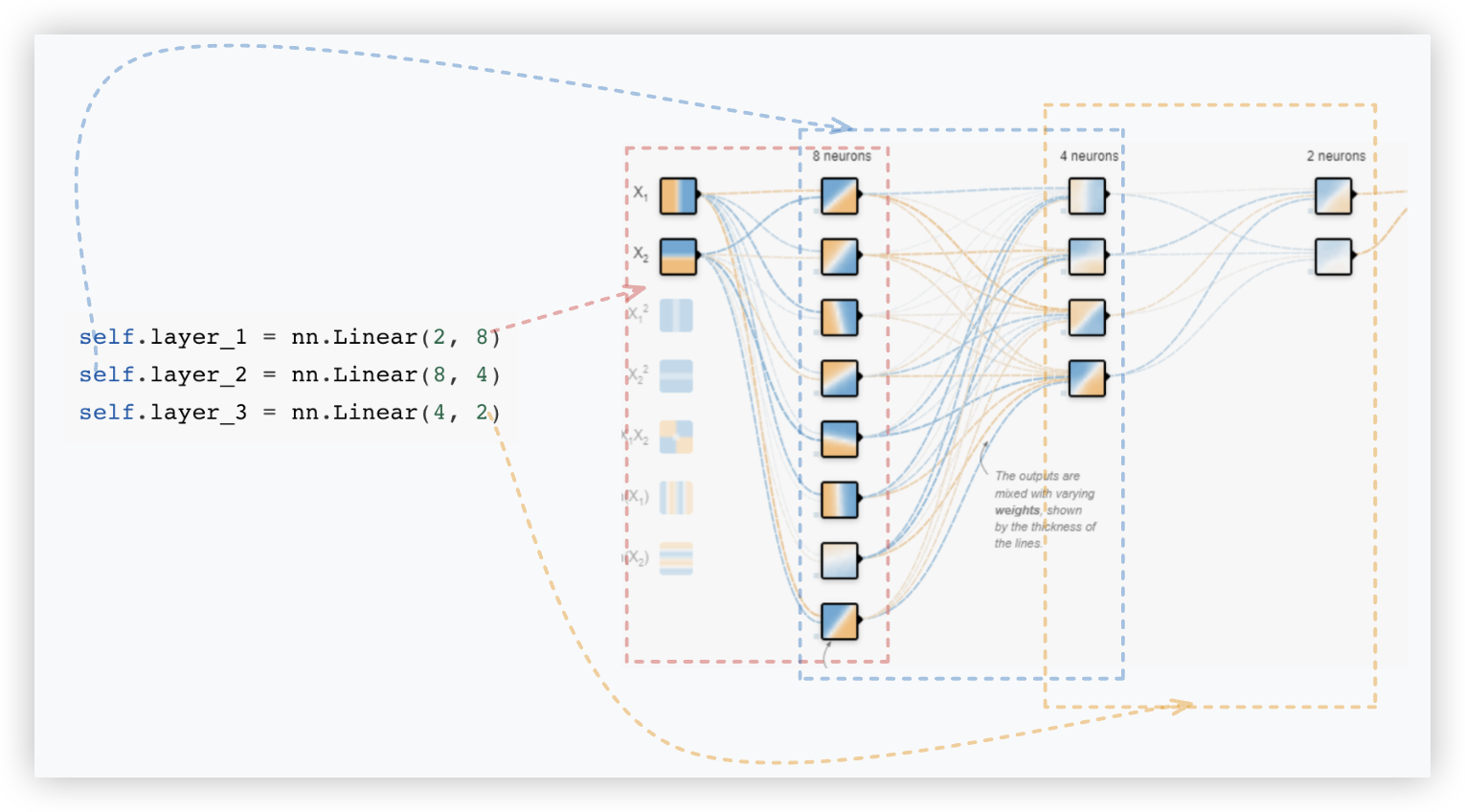
self.layer_1 = nn.Linear(2, 8)
self.layer_2 = nn.Linear(8, 4)
self.layer_3 = nn.Linear(4, 2)
# 3.定义一个包含模型前向传递计算的 forward() 方法.
# >> 前一层的输出要作为下一层的输入.
def forward(self, x):
out1 = self.layer_1(x) # 2->8 输出的8个数据会提供给layer_2
out2 = self.layer_2(out1) # 8->4 输出的4个数据会提供给layer_3
out3 = self.layer_3(out2) # 4->2 最后输出2个数据
return out3 # out3是由2个数据组成的!
# 4.实例化模型并将其发送到目标device
model = CircleModelV0().to(device) # .to(device)将模型搞到了gpu中
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# nn.Sequential
nn.Sequential 是 PyTorch 库中的一个类, 它允许通过按顺序堆叠多个层来创建神经网络模型.
它提供了一种方便的方式来定义和组织神经网络的各层.
简单来说, Sequential可以理解成是一个容器, 可以作为一个容器包装各个网络层.
import torch
from torch import nn
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model = nn.Sequential(
nn.Linear(in_features=2, out_features=8),
nn.Linear(in_features=8, out_features=4),
nn.Linear(in_features=4, out_features=2)
).to(device)
model
"""
Sequential(
(0): Linear(in_features=2, out_features=8, bias=True)
(1): Linear(in_features=8, out_features=4, bias=True)
(2): Linear(in_features=4, out_features=2, bias=True)
)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 定义优化器
在后续训练时,会基于优化器进行参数的迭代更新.
import torch.optim as optim
# 创建一个优化器(此处暂且选择Adam,效果不好再试试SGD
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
optimizer = optim.Adam(model.parameters(), lr=0.001) # model.parameters()是随机参数; lr是学习率
2
3
4
5
# 定义损失函数
在后续训练时,反向传播会根据损失函数计算梯度..
# 先临时使用一个基于分类任务中的某一个损失函数 (此处暂且使用的是 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
2
# 定义评估指标
评估指标可用于提供有关模型进展情况的另一个视角.
有多种评估指标可用于分类问题, 在该示例中 我们采用 准确性,也可称作准确度.
准确度可以通过将正确预测总数除以预测总数来衡量.
例如, 如果模型能够在 100 次预测中做出 99 次正确的预测, 则准确率将达到 99%.
def accuracy(outputs, labels):
"""
参数output: 模型返回n条测试集样本数据的分类概率结果,形状为(n,2)> 就是输出层两个神经元的输出'输出的是概率'
参数labels: 测试集的真实类别(n,1)
"""
# torch.max 表示计算轴向为1(即每一行)上的最大值和最大值坐标, 因为outout每行两个元素,因此有坐标为0和1
# eg: 假设模型对某个样本的输出概率为 [0.3,0.7] 则predicted的值等于1,代表模型将该样本分到了1类别
_, predicted = torch.max(outputs, 1) # predicted为最大元素下标
# correct为分对的样本数量
correct = (predicted == labels).sum().item()
# 总样本数量
total = labels.size(0)
return correct / total
2
3
4
5
6
7
8
9
10
11
12
13
14
# 模型训练
基于GPU作模型的训练
# 将数据加入到device中,这样就会使用GPU而不是CPU
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# 训练和测试模型
num_epochs = 500 # 迭代训练500次
for epoch in range(num_epochs):
# 训练阶段
model.train() # ★ 是一个标识,标识在该行代码下面放的是模型训练的代码
optimizer.zero_grad() # 清空梯度
outputs = model(X_train) # 前向传播
loss = criterion(outputs, y_train) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 测试评估阶段
model.eval() # ★ 是一个标识,标识在该行代码下面放的是模型评估测试的代码
# 表明with代码块的这些代码不用计算梯度,因为模型已经训练好了,借此提升运行效率
# 其实加不加with torch.no_grad()都行,因为这里不会涉及到反向传播,反向传播才会计算梯度!
with torch.no_grad():
train_outputs = model(X_train) # 基于训练集特征的分类结果
test_outputs = model(X_test) # 基于测试集特征的分类结果
train_acc = accuracy(train_outputs, y_train) # 训练集准确率
test_acc = accuracy(test_outputs, y_test) # 测试集准确率
train_loss = criterion(train_outputs, y_train) # 训练集损失
test_loss = criterion(test_outputs, y_test) # 测试集损失
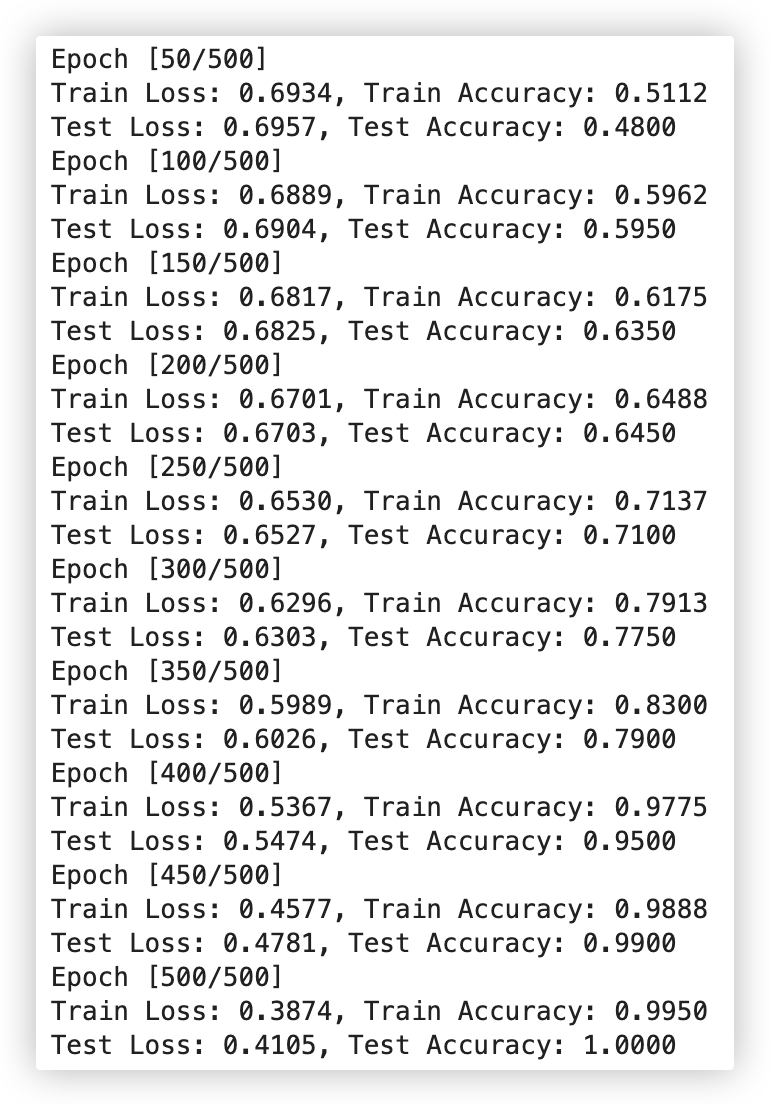
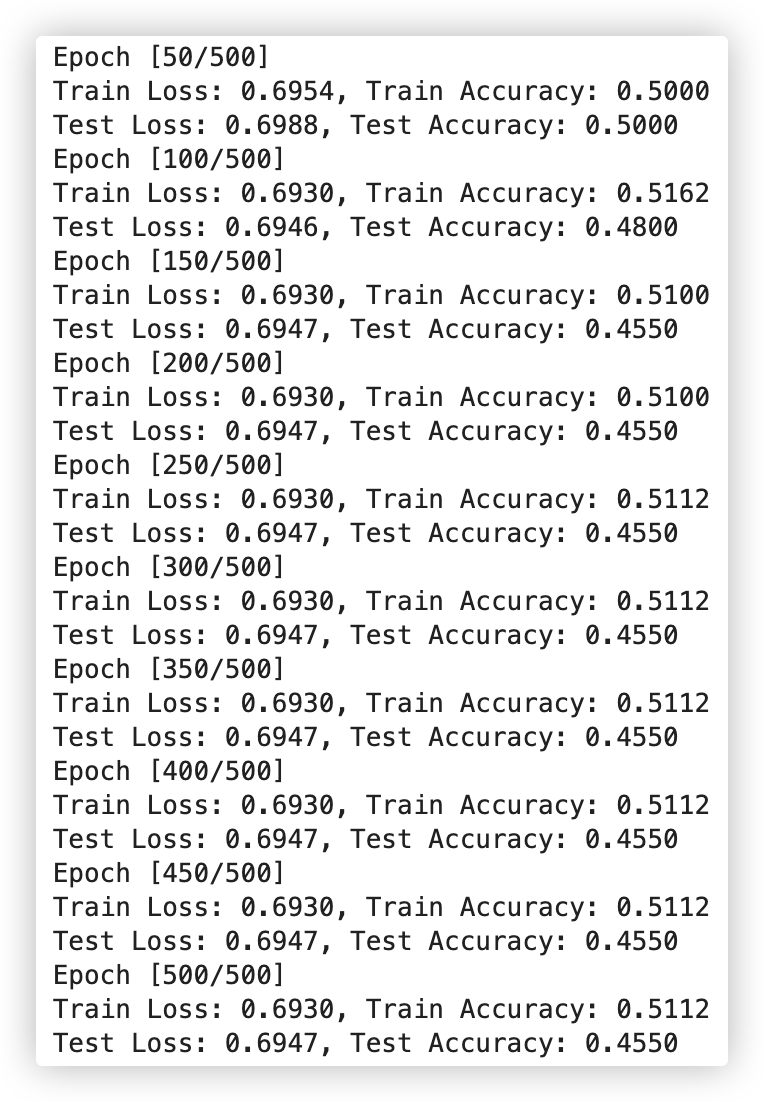
if (epoch+1) % 50 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}]')
print(f'Train Loss: {train_loss.item():.4f}, Train Accuracy: {train_acc:.4f}')
print(f'Test Loss: {test_loss.item():.4f}, Test Accuracy: {test_acc:.4f}')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 加入非线性激活函数
观察上述测试评估结果, 很不理想.. 训练集和测试集的准确率都没有达到百分之50, 妥妥的欠拟合. emmm.
★ 可以基于以下几点尝试解决: (先后尝试激活函数、添加更多网络层级、层级设置更多神经元、损失函数、改变学习率等)
| 模型改进技术 | 它有什么作用 |
|---|---|
| 添加更多层 | 每一层都可能增加模型的学习能力 每层都能够学习数据中的某种新模式, 更多层通常会使神经网络更深. |
| 添加更多隐藏单位 | 与上面类似, 隐藏层设置更多的神经元个数, 意味着模型学习能力的潜在增加 更多的隐藏单元通常被称为使你的神经网络更宽 |
| 训练更多批次 | 如果您的模型有更多机会查看数据, 它可能会了解更多信息. |
| 更改激活函数 | 有些数据不能只用直线拟合. 使用非线性激活函数可以帮助解决这个问题. |
| 改变学习率 | 模型特定性较少, 但仍然相关, 优化器的学习率决定模型每一步应改变其参数的程度 太多, 模型会过度校正; 太少, 则学习得不够 |
| 改变损失函数 | 同样, 虽然模型不太具体, 但仍然很重要, 不同的问题需要不同的损失函数 |
在该示例中, 现目前在网络结构中压根就没有使用激活函数, Now, 我们尝试加入非线性激活函数试试.
sigmoid-输出层二分类, softmax-输出层多分类; ReLU? Yes !
我们只需在现有的基础上, 改动下 "搭建网络结构" 的代码 即可..
(加入非线性激活函数的代码 可以结合下方这个截图进行理解 (¯﹃¯))
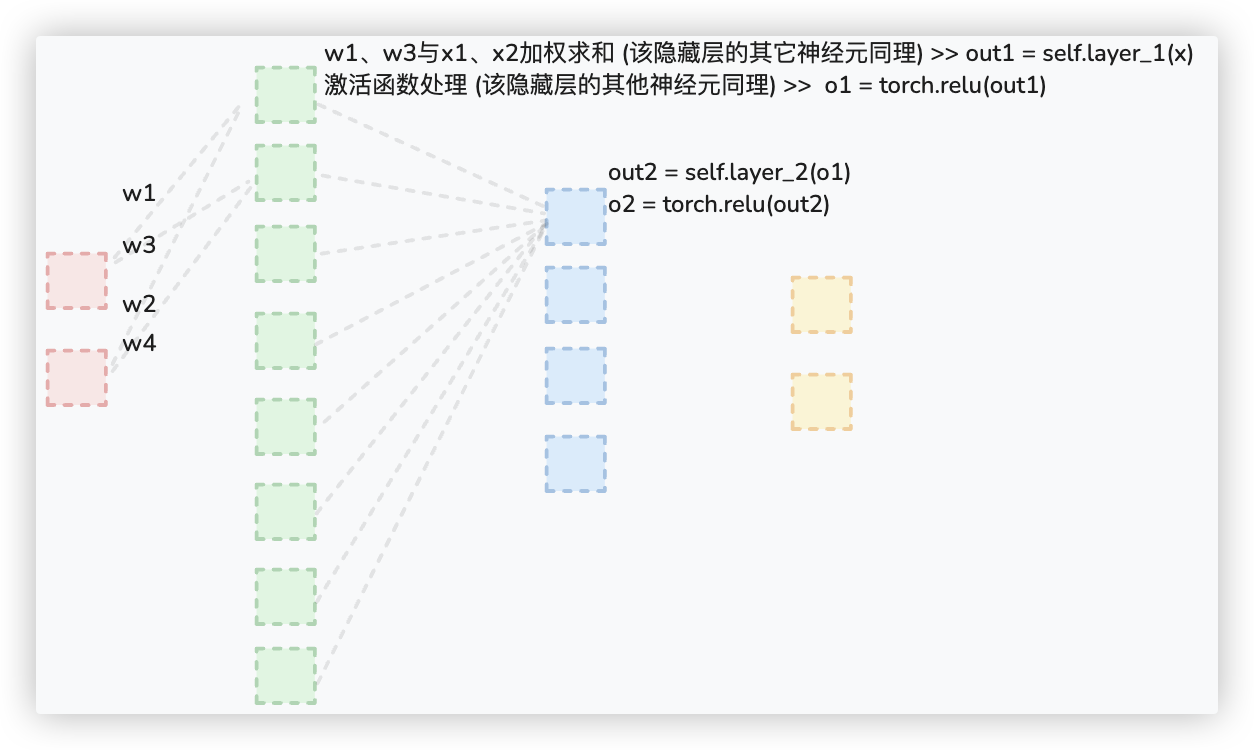
▲ 注意: 因为在该示例中, 我们选择使用的损失函数是交叉熵损失函数.
所以模型网络结构的最后一层无需设置激活函数, 模型的输出仍然会被处理为类别概率..
# nn.Module
import torch
from torch import nn
import torch.optim as optim
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
class CircleModelV0(nn.Module): # 1.继承 nn.Module
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear(2, 8)
self.layer_2 = nn.Linear(8, 4)
self.layer_3 = nn.Linear(4, 2)
def forward(self, x):
out1 = self.layer_1(x)
o1 = torch.relu(out1)
out2 = self.layer_2(o1)
o2 = torch.relu(out2)
# 最后一层没有显式地设置激活函数,通过使用CrossEntropyLoss作为损失函数,模型的输出仍然会被处理为类别概率.
out3 = self.layer_3(o2)
return out3
model = CircleModelV0().to(device)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# nn.Sequential
import torch
from torch import nn
import torch.optim as optim
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model = nn.Sequential(
nn.Linear(in_features=2, out_features=8),
nn.ReLU(),
nn.Linear(in_features=8, out_features=4),
nn.ReLU(),
# 最后一层没有显式地设置激活函数,通过使用CrossEntropyLoss作为损失函数,模型的输出仍然会被处理为类别概率.
nn.Linear(in_features=4, out_features=2)
).to(device)
2
3
4
5
6
7
8
9
10
11
12
13
14
再运行代码看下结果.. 成功达到预期..