 deepseek本地部署+知识库
deepseek本地部署+知识库
啦啦啦!啦啦啦!我是卖报的小行家..
# ollama拉取deepseek本地部署
# Step1: ollama软件的安装.
下载地址
https://ollama.com/download/macOllama是一个开源的大型语言模型(LLM)本地部署和运行的工具.
Ollama软件让用户能够在本地高效的运行大型语言模型(Llama 3.3、 DeepSeek-R1、 Phi-4、 Mistral、 Gemma2等)此外,Ollama还提供了类似OpenAI的API接口和聊天界面,方便用户部署和使用
我下载的是mac版本.
若下载的是window版本,只能将该软件安装到系统盘-C盘.
注: 为了不让后续下载的大模型一并放在C盘.需要设定下环境变量. (记得重启ollama软件或重启电脑让环境变量生效)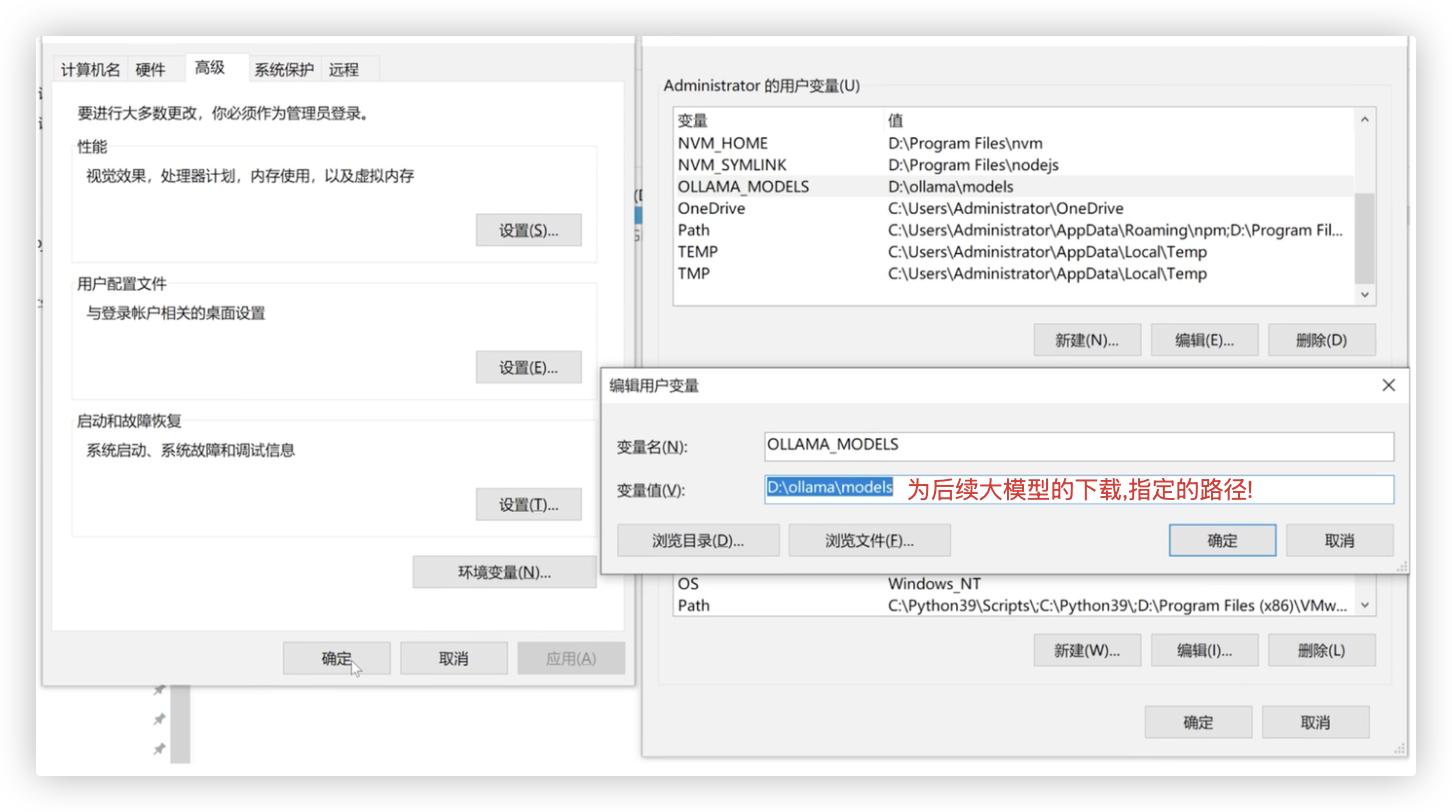
# Step2: 下载大模型
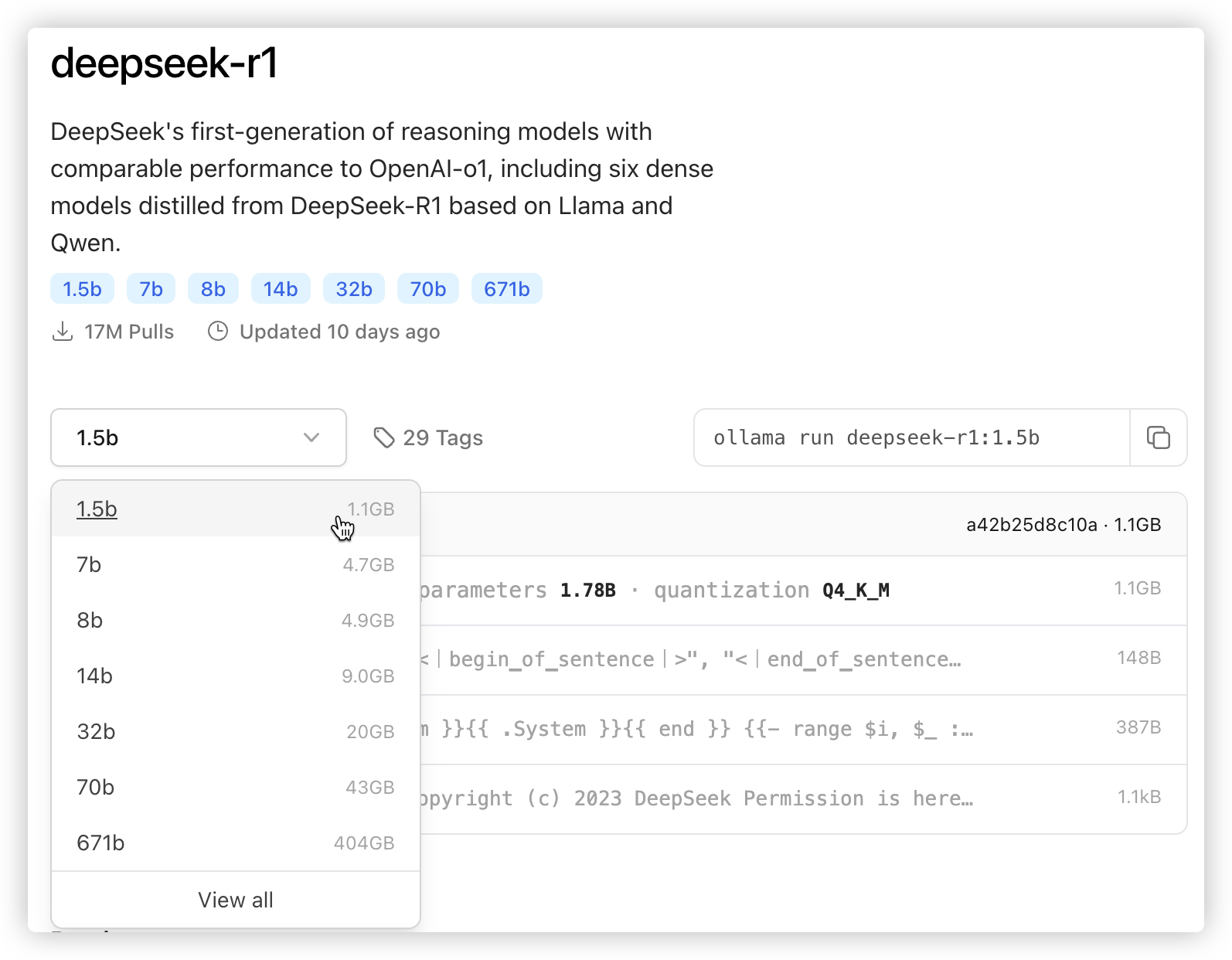
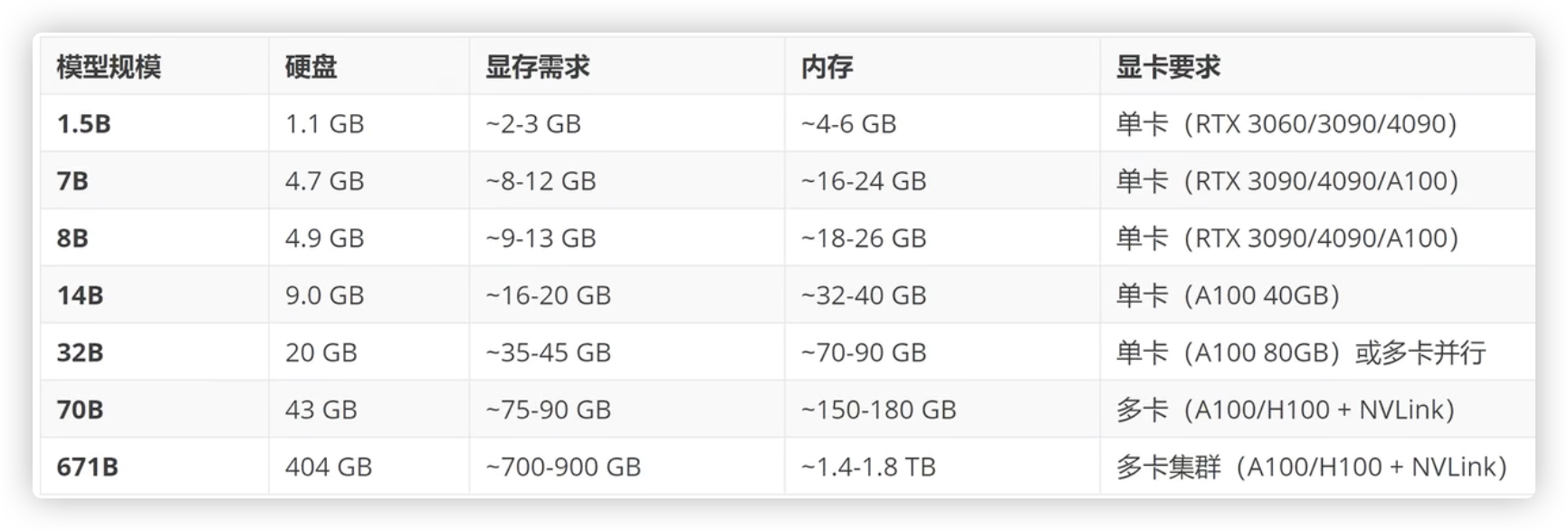
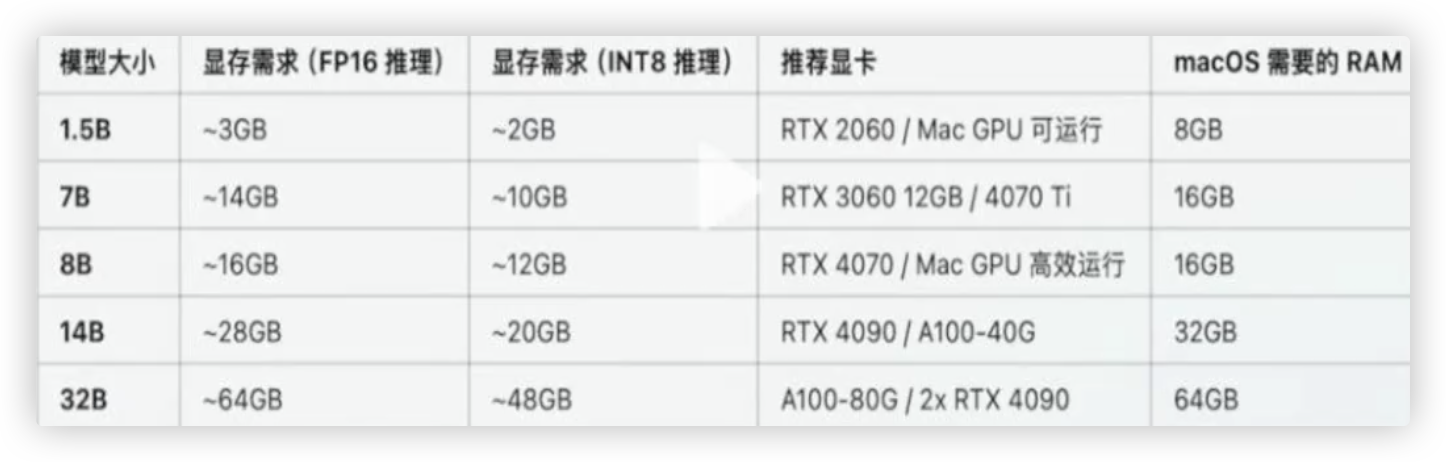
注: 多少b指的是参数的个数(量级),32b以下都是小模型,70b大模型,671b是满血版..
每个版本对电脑的硬件配置要求也是不一样的.
模型地址:
https://ollama.com/library/deepseek-r1(我们下载个1.5b的版本试试水就好啦!)在确保ollama软件已经运行的情况下,在电脑终端输入命令:
ollama run deepseek-r1:1.5b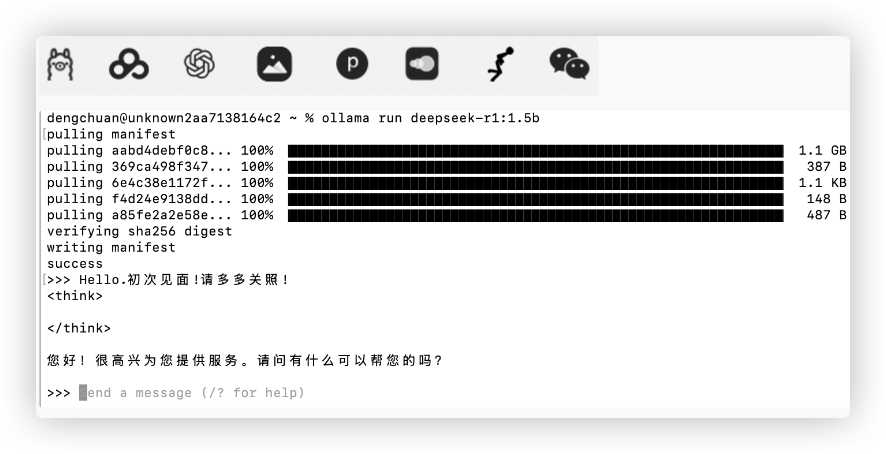
# 部署后在本地调用
# 调用-在终端
- 首先,要保证ollama服务已经启动
- ollama软件运行方式一: 直接点击ollama应用图标,就会看到一个小羊驼
- ollama软件运行方式二: 在终端输入命令
ollama serve
- 在终端输入命令
ollama list查看本地下载了哪些大模型 - 使用下载的大模型
ollama run deepseek-r1:1.5b
(实测下来,mac运行该命令时会出现小羊驼,默认启动ollama服务,则mac不用像window一样要先运行命令ollama serve)

# 调用-谷歌插件
在谷歌商店里搜索
Page Assist, 并安装这个谷歌插件.启动ollama服务. (小羊驼出现)
打开插件, 在设置里配置好RAG为下载好的模型. 就可以使用了..
该插件还支持联网搜索哦!!
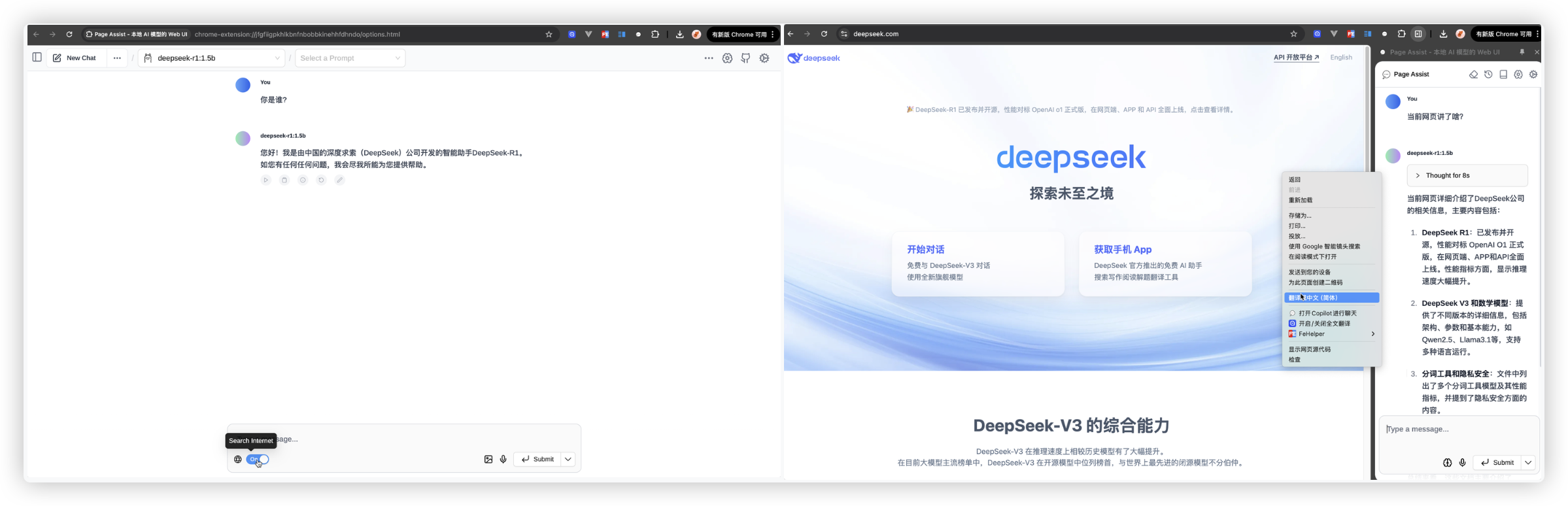
# 调用-chatbox AI
Chatbox AI 是一款 AI 客户端应用和智能助手, 支持众多先进的 AI 模型和 API..
即作为一个模型 API 和本地模型的连接工具.. 可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用
下载地址:
https://chatboxai.app/zh该客户端可以调用刚在ollama里下载好的本地大模型. 需要进行的配置如下:
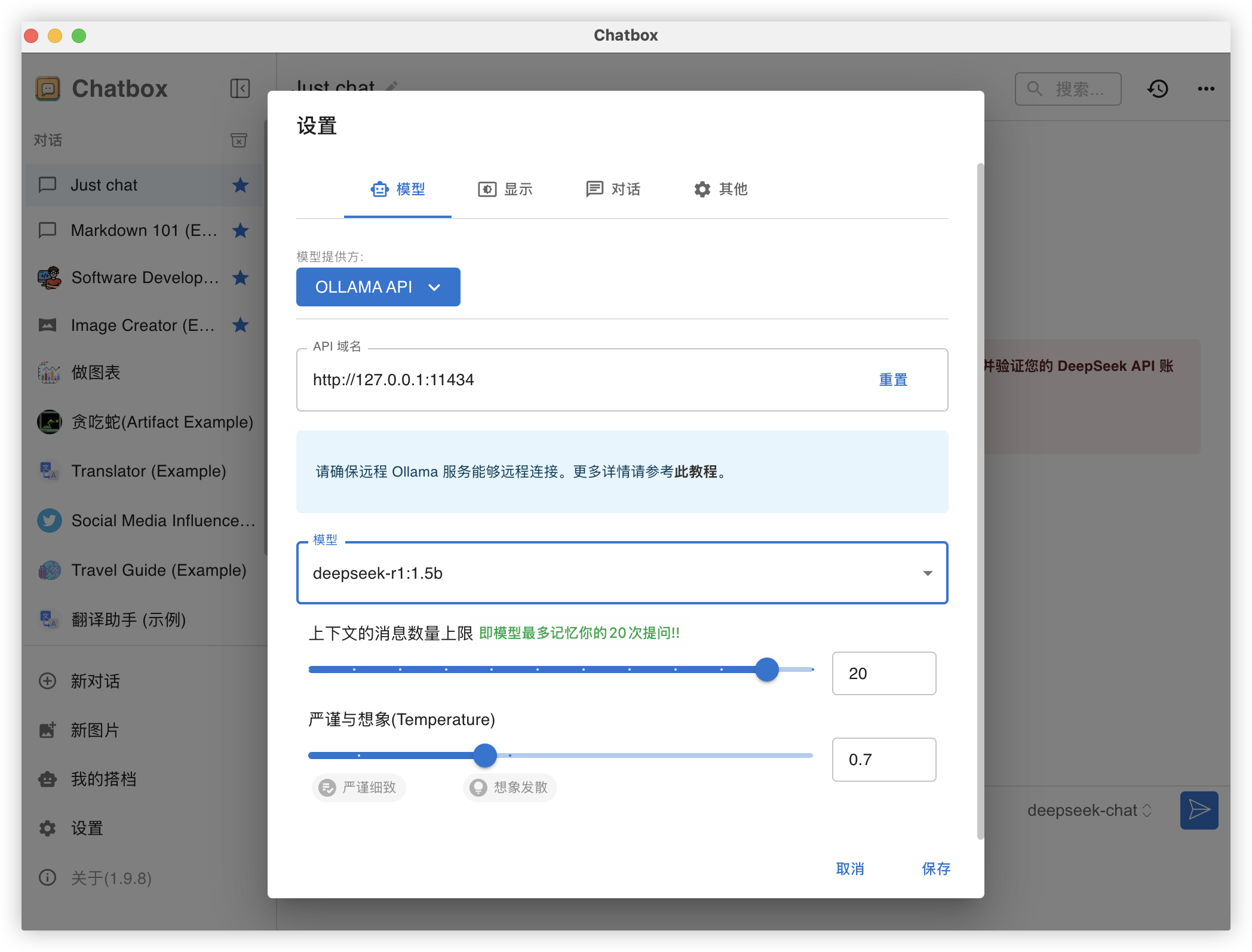
该客户端还可以通过调用API key使用deepseek的全量大模型.
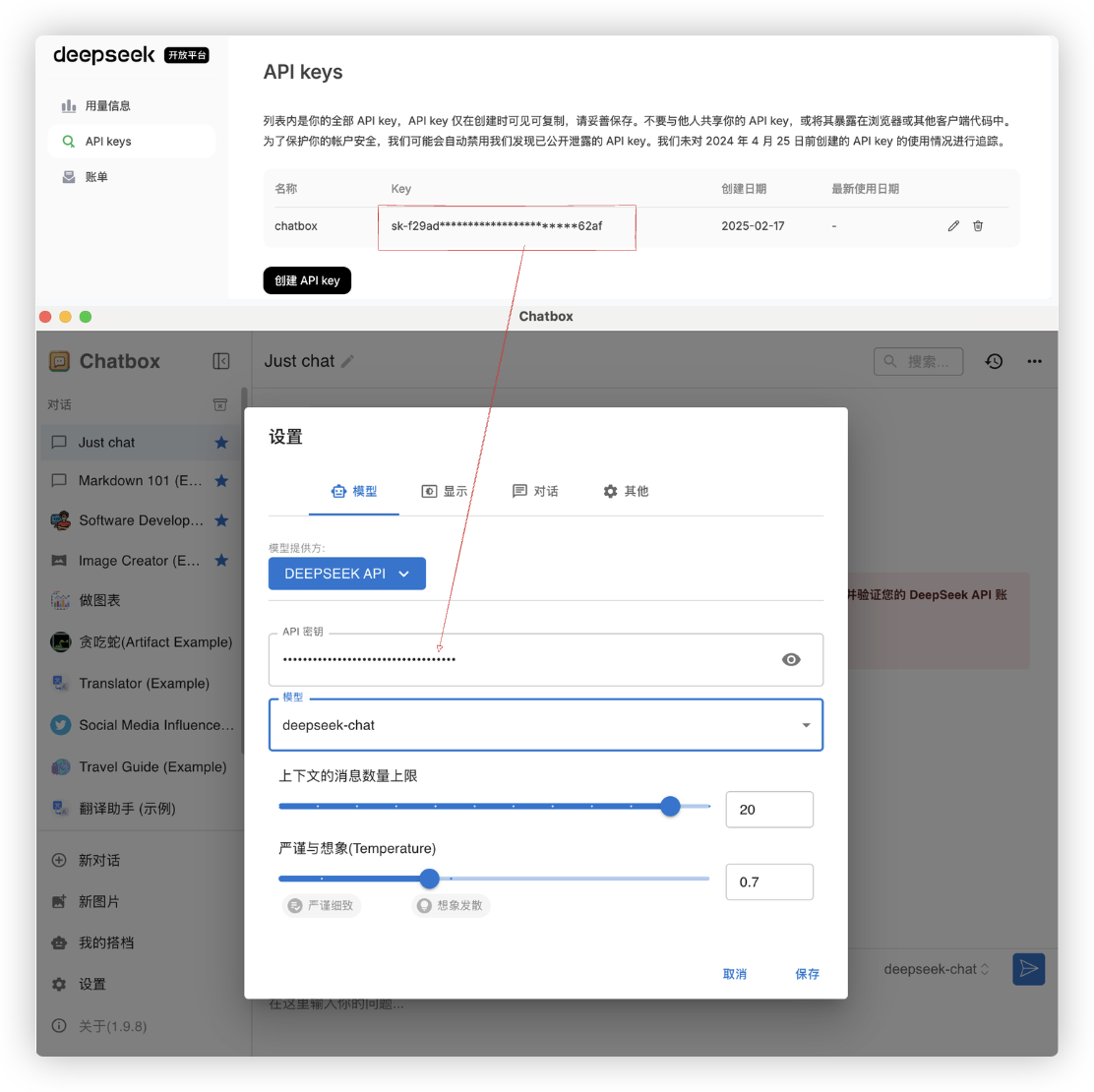
# 调用-搭建网站
下载别人写好的网站,安装相关依赖并启动网站.
本地安装nodejs,用于运行网站
网站源码下载地址
https://github.com/ollama-webui/ollama-webui-lite(需科学上网)dengchuan@unknown2aa7138164c2 Desktop % git clone https://github.com/ollama-webui/ollama-webui-lite.git Cloning into 'ollama-webui-lite'... remote: Enumerating objects: 313, done. remote: Counting objects: 100% (55/55), done. remote: Compressing objects: 100% (28/28), done. remote: Total 313 (delta 32), reused 27 (delta 27), pack-reused 258 (from 1) Receiving objects: 100% (313/313), 6.86 MiB | 6.34 MiB/s, done. Resolving deltas: 100% (113/113), done.1
2
3
4
5
6
7
8进行该网站项目的根目录.执行以下命令.
(运行的端口号可自行指定,该示例中我随便用了个未被占用的端口号9001)dengchuan@unknown2aa7138164c2 Desktop % cd ollama-webui-lite dengchuan@unknown2aa7138164c2 ollama-webui-lite % sudo npm ci Password: added 213 packages in 4s 42 packages are looking for funding dengchuan@unknown2aa7138164c2 ollama-webui-lite % sudo npm run dev -- --port=9001 > [email protected] dev > vite dev --host --port 3000 --port=9001 Forced re-optimization of dependencies VITE v4.5.2 ready in 815 ms ➜ Local: http://localhost:9001/ ➜ Network: http://192.168.2.36:9001/ ➜ press h to show help1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20在浏览器中输入网址
http://localhost:9001/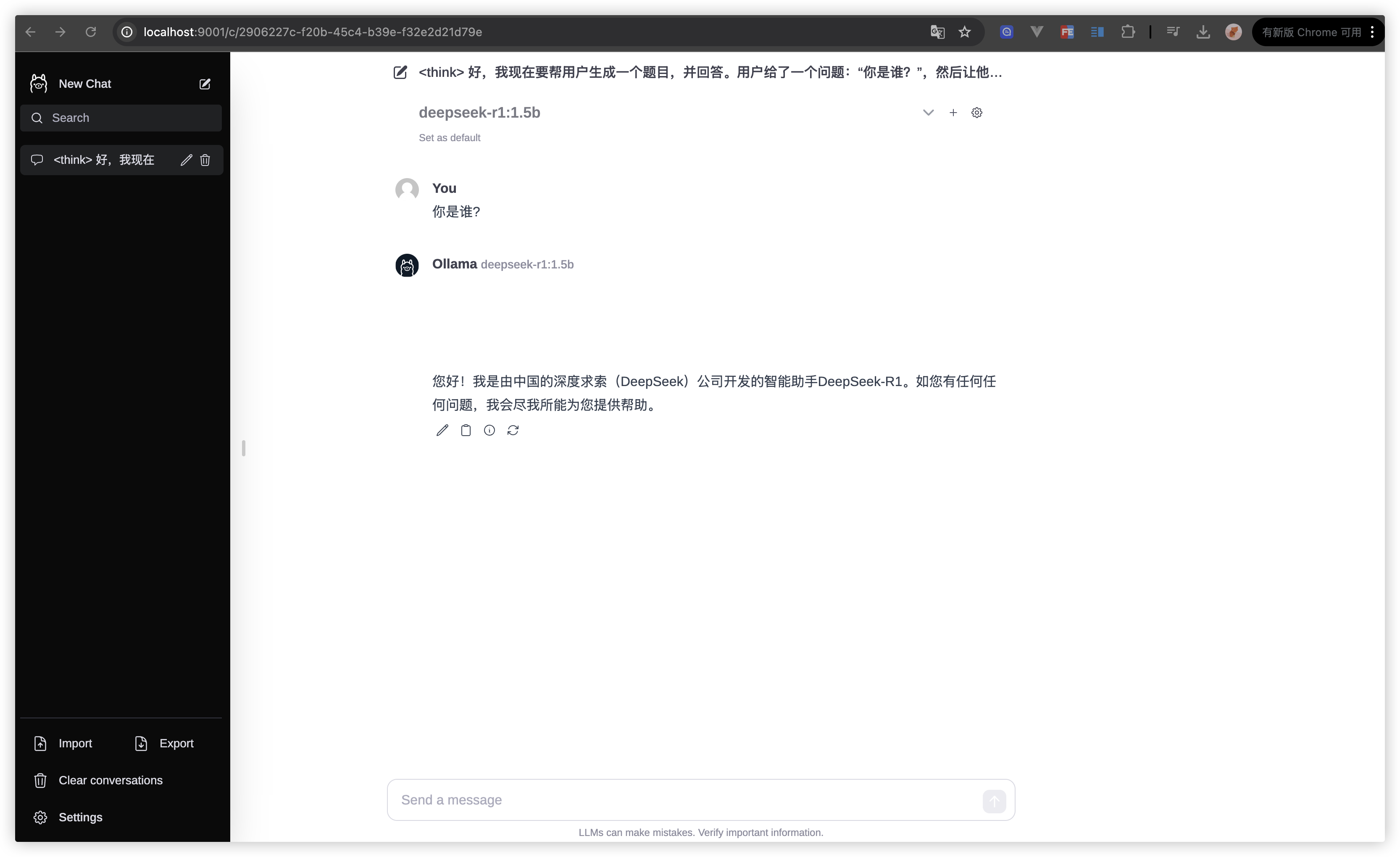
# 调用-API
官方api文档: https://github.com/ollama/ollama/blob/main/docs/api.md
# api - /api/generate
该 API 主要用于基于给定的提示信息生成文本内容. 它适用于一次性生成特定文本的场景, 不涉及对话上下文的维护.
参数
- model参数要使用的模型名称
- prompt参数是模型的提示词,即向模型输入的内容
- stream参数是bool值,表示是否流式输出.
- temperature参数是生成的文本的随机性,值越高越随机 (可选)
- max_tokens参数是限制生成文本的最大令牌数 (可选)
curl调用
dengchuan@unknown2aa7138164c2 ~ % curl http://localhost:11434/api/generate -d'{ "model": "deepseek-r1:1.5b", "prompt": "你好!", "temperature": 0.5, "stream": false }' { "model":"deepseek-r1:1.5b", "created_at":"2025-02-17T03:55:03.215318Z","response":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n你好!很高兴见到你,有什么我可以帮忙的吗?", "done":true,"done_reason": "stop","context":[151644,108386,0,151645,151648,271,151649,271,108386,6313,112169,104639,56568,3837,104139,109944,106128,9370,101037,11319], "total_duration":789297250, "load_duration":38284584, "prompt_eval_count":5, "prompt_eval_duration":174000000, "eval_count":17, "eval_duration":576000000}%1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19python代码调用
import requests import json # 设置请求的 URL url = "http://localhost:11434/api/generate" # 请求数据,注意这个是 JSON 格式 data = { "model": "deepseek-r1:1.5b", "prompt": "你好!", "temperature": 0.5, "stream": False, } # 发送 POST 请求并传递 JSON 数据 response = requests.post(url, json=data) # 输出响应状态码和响应内容 print("Status Code:", response.status_code) response_data = response.json() # 尝试解析返回的 JSON 数据 print("Response Data:", json.dumps(response_data, indent=2).encode().decode('unicode_escape'))1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20运行该python代码. 返回的截图内容如下:
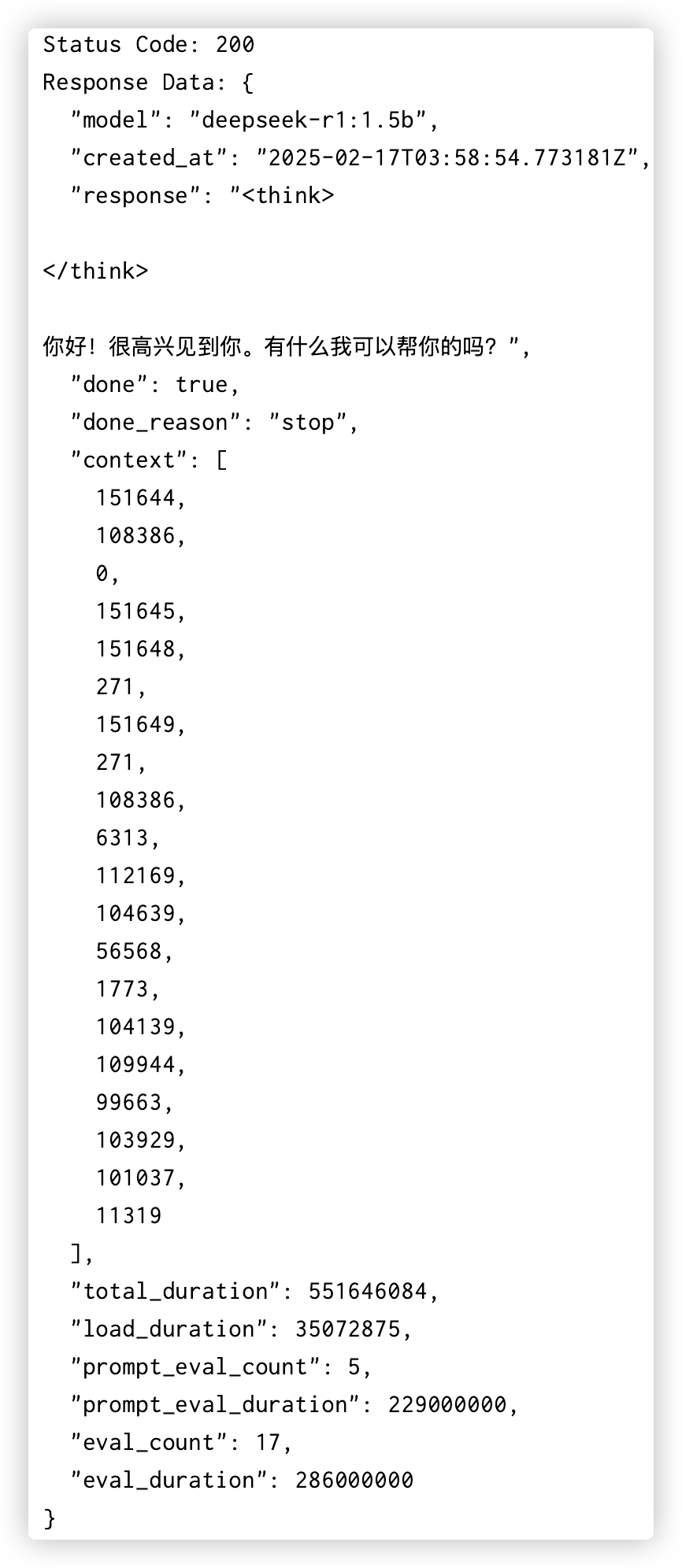
# api - /api/chat
用于模拟对话交互,它会维护对话的上下文,使得模型能够根据之前的对话内容生成合适的回复,实现更自然、连贯的对话效果.
注意: 模型本身不会记录以前的沟通,我们只有在发送请求时,把以前所有的沟通记录一并发给模型.
模型再基于发送的信息中的上下文作出回复.curl调用
dengchuan@unknown2aa7138164c2 ollama-webui-lite % curl http://localhost:11434/api/chat -d '{ "model": "deepseek-r1:1.5b", "messages": [ { "role": "user", "content": "你好!" }, { "role": "assistant", "content": "你好!很高兴见到你,有什么我可以帮忙的吗?无论是聊天、解答问题还是提供建议,我都在这里为你服务。" }, { "role": "user", "content": "你是谁?" } ], "stream": false }' {"model":"deepseek-r1:1.5b", "created_at":"2025-02-17T04:30:06.966479Z", "message":{"role":"assistant","content":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。"}, "done_reason":"stop","done":true,"total_duration":3431007709, "load_duration":18767709,"prompt_eval_count":40, "prompt_eval_duration":159000000,"eval_count":40, "eval_duration":3251000000}%1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27python代码
import requests message_list = [] while True: text = input("请输入:") user_dict = {"role": "user", "content": text} message_list.append(user_dict) res = requests.post( url="http://localhost:11434/api/chat", json={ "model": "deepseek-r1:1.5b", "messages": message_list, "stream": False } ) data_dict = res.json() res_msg_dict = data_dict['message'] print(res_msg_dict) message_list.append(res_msg_dict) print(message_list)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24运行python代码
请输入:你好 {'role': 'assistant', 'content': '<think>\n\n</think>\n\n你好!很高兴见到你,有什么我可以帮忙的吗?'} 请输入:为什么天空是蓝色的? {'role': 'assistant', 'content': '<think>\n\n</think>\n\n天空是蓝色的这是因为地球表面的阳光在进入大气层时会受到地球自转和大气折射的影响,使得光线呈球形,并且由于地球周围的大气密度逐渐减小,导致光线颜色变蓝。这个现象被称为“散射效应”(diffraction effect),它在太阳光的传播过程中造成色带的形成,从而使天空呈现蓝色。'} 请输入:你是谁? {'role': 'assistant', 'content': '<think>\n\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。'} 请输入:1
2
3
4
5
6
7
# 提示词模版
如何让大模型给我们更好的回答呢? 这与我们如何向大模型提问息息相关...
提示词模版: 身份+背景+问题+需求 举个例子:
我是一个从未接触过编程的小白,目前在从事销售相关的工作.
我现在不是很清楚GPT到底是怎样的一个事物.请你可以通俗易懂尽量用举例和比喻的方式帮我解释下.
2
那是否让AI工具帮我制作提示词,然后向AI发起提问呢? - 万能词模版
我想让你成为我的提示词创作者。你的目标是帮助我创建最佳的提示词,这个提示词将由你使用.你将遵循以下过程:
1.首先,你会问我提示词是关于什么的.我会告诉你,但我们需要通过不断的重复来改进它,通过则进行下一步.
2.根据我的输入,你会创建三个部分:
a)修订后的提示词(你编写修订后的提示词,应该清晰、精确、易于理解)
b)建议(你提出建议,哪些细节应该包含在提示词中,以使其更好)
c)问题(你提出相关问题,询问我需要哪些额外信息来改进提示词)
3.你提供的提示词应该采用我发出请求的形式,由你执行.
4.我们将继续这个迭代过程,我会提供更多的信息,你会更新”修订后的提示词“部分的请求,直到它完整为止!
2
3
4
5
6
7
8
最后,你再说 "提示词优化就执行到这里,给我最终的提示词."
# DeepSeek的版本
DeepSeek的R系列和V系列是该模型体系中的两个不同分支,它们各自具有独特的特点和应用场景.
R系列
- 专注于高级的推理任务.
- 模型的推理能力是指模型根据已有的知识和信息,通过逻辑分析和思考,最终得出一个合理的结论的能力.
- R系列的性能在综合测试中超越了openAI的o1系列模型
- R系列的DeepSeek提供了基于Qwen和oLlama这些模型的蒸馏版本,显著提升了小模型的性能
使这些小模型的推理能力与满血版的DeepSeek相媲美.
基于知识储备进行推断+处理多步骤复杂问题+按照逻辑规则进行推导+生成合理的预测和结论 应用场景: 针对科研、算法交易、代码生成等需要复杂逻辑推理的任务设计1
2V系列
- 面向多功能的自然语言任务的自然语言处理模型
- 应用场景适用于内容创作,比如写文案、写小说、知识问答(智能客服)..等
Q: 什么是蒸馏,什么是迁移学习,两者有何不同?
- 蒸馏
- 在蒸馏中,学生模型通过模仿教师模型的输出(如soft targets)来学习,而不是直接学习目标任务的标签.
即让小模型的输出尽可能的靠近大模型的输出 - 假设你有一个大型的 GPT-3 模型,目标是通过蒸馏将其精华知识转移到一个更小的 GPT-2 模型上
这样即使是在资源有限的环境中, GPT-2 也能生成质量较高的文本.
- 在蒸馏中,学生模型通过模仿教师模型的输出(如soft targets)来学习,而不是直接学习目标任务的标签.
- 迁移学习
- 在迁移学习中,通常源模型的参数、特征提取器或网络层会被直接迁移到目标任务中.
然后在目标任务上进行微调(fine-tuning).
迁移学习不一定要求源任务和目标任务非常相似, 只要它们之间有一定的共性或可以共享的知识. - 假设你在 ImageNet 数据集上训练了一个深度神经网络用于图像分类任务.
后来你想将这个网络应用到一个医学影像分类任务上,就可以使用迁移学习.
迁移学习通过将 ImageNet 上训练好的网络层作为预训练模型,并进行微调来解决医学图像分类问题.
- 在迁移学习中,通常源模型的参数、特征提取器或网络层会被直接迁移到目标任务中.
# MaxKB构建企业级知识库
部署安装文档: https://maxkb.cn/docs/installation/online_installtion/
# 虚拟机与docker
先简单了解下虚拟机和docker.
虚拟机
- 共享硬件资源但有独立的操作系统
- 虚拟机运行在虚拟化层(hypervisor)上,虚拟化层负责将宿主机的硬件资源(CPU、内存、硬盘等)虚拟化并分配给虚拟机.
每个虚拟机都有自己的完整操作系统(例如 Ubuntu、Windows 等) - 使得虚拟机能够像一台独立的物理计算机一样运行
> 两种常用的 Linux 发行版: Ubuntu 和 CentOS > 常用的虚拟化技术: vmware 和 kvm > 在window系统上利用虚拟化技术创建虚拟机,和从阿里云平台购买云主机.本质上是一样的!! 云主机就是阿里云平台通过虚拟化技术得到的虚拟机!!1
2
3
4docker
- 共享宿主机的操作系统内核
- Docker镜像不是一个完整的操作系统,它包含了应用程序所需的库、配置文件和依赖项,但是没有内核
- 容器中的应用运行时,容器中的进程与宿主机的操作系统内核是共享的.但文件系统和网络等资源是隔离的.
- 由于容器不包含操作系统内核, 所以它比虚拟机要轻量级得多
扩展: - 容器依赖宿主机内核,所以 Ubuntu 容器镜像只能在使用 Linux 内核的宿主机上运行,不能直接在 Windows 宿主机上运行 - 如果宿主机是 Windows 系统,想要运行 Linux 容器,可以借助 WSL2 或 Docker Desktop 通过虚拟化技术来运行 Linux 内核.1
2
3
# mac上用docker启动maxkb
Step1: 安装docker桌面版
- 下载地址:
https://www.docker.com/ - 安装后,双击启动.. 会出现货轮的图标. docker应用启动成功.
- 下载地址:
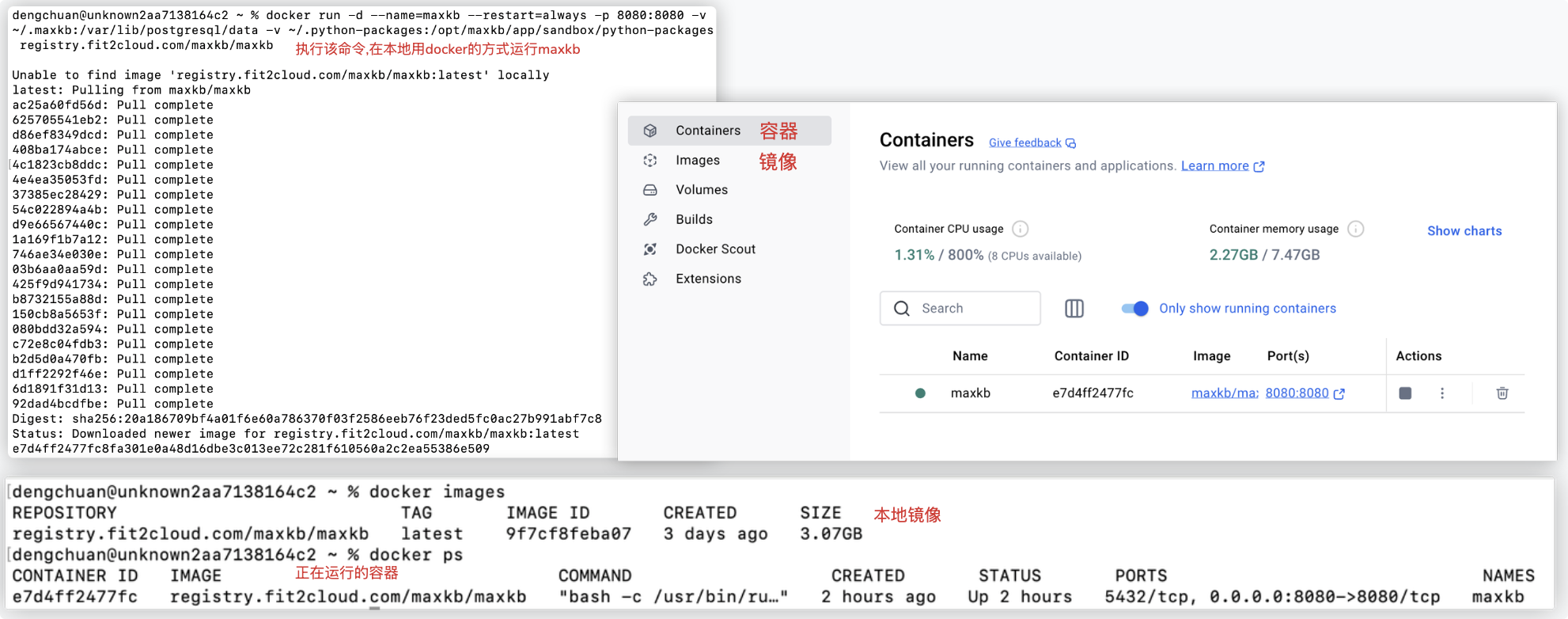
Step2: 我的系统是Mac,在终端执行对应的linux部署命令
# Linux 操作系统 docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb # Windows 操作系统 docker run -d --name=maxkb --restart=always -p 8080:8080 -v C:/maxkb:/var/lib/postgresql/data -v C:/python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb1
2
3
4
5可以通过命令或docker桌面软件看到正在运行的容器..
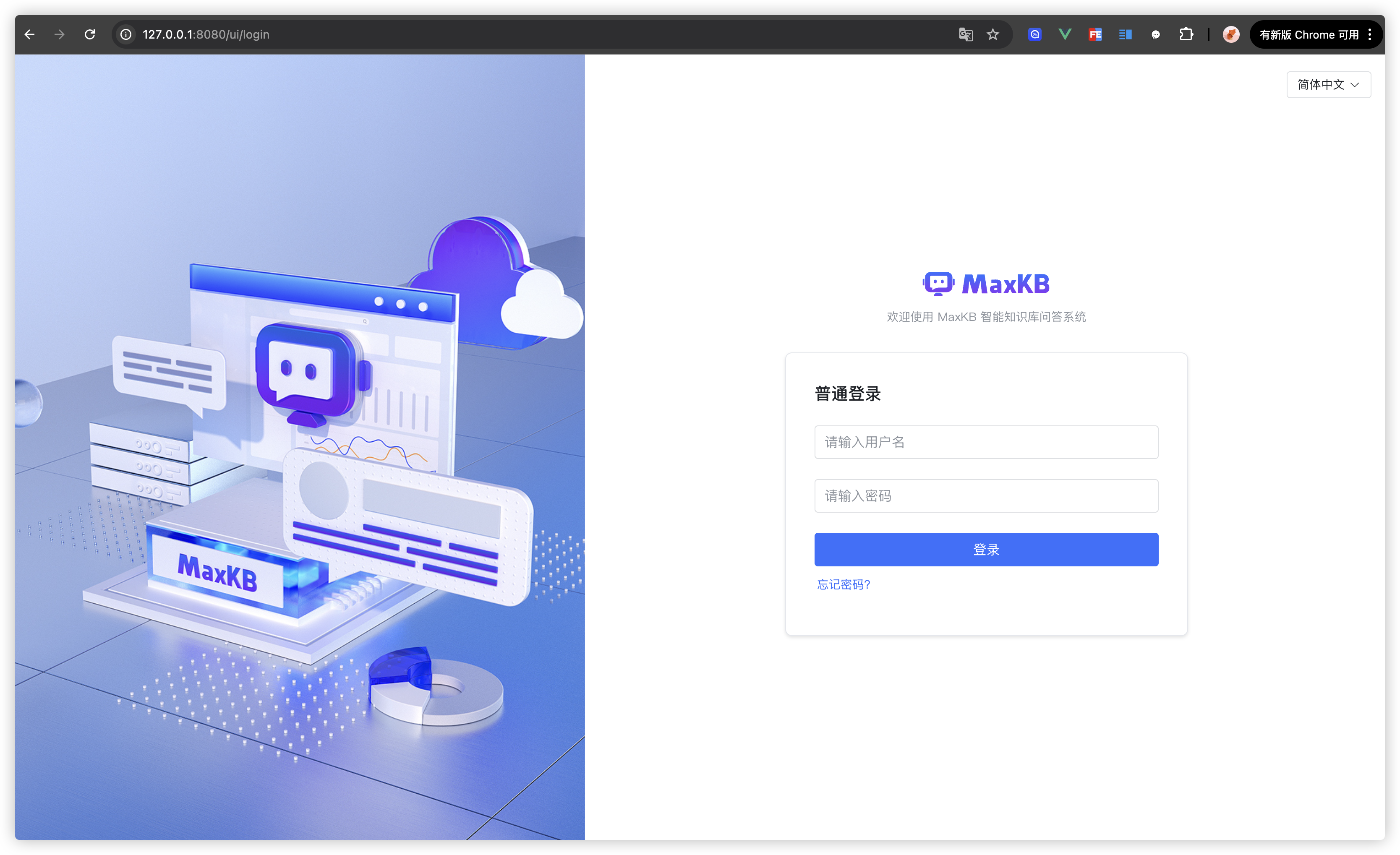
Step3: 在浏览器里输入
127.0.0.1:8080即可打开项目!- 默认登陆信息 用户名:
admin默认密码:MaxKB@123..
- 默认登陆信息 用户名:
注意: 当我们在docker桌面版中停止了容器后.. 若想重新执行 第二步的linux的docker部署命令.. 需要先删除掉停止的容器.
dengchuan@unknown2aa7138164c2 ~ % docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e7d4ff2477fc registry.fit2cloud.com/maxkb/maxkb "bash -c /usr/bin/ru…" 2 hours ago Exited (137) 8 minutes ago maxkb dengchuan@unknown2aa7138164c2 ~ % docker rm -f maxkb maxkb dengchuan@unknown2aa7138164c2 ~ % docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb 536349aa5921a7b8afb066b04b88d55154f041920e2697546c1b273cfa2d1267 dengchuan@unknown2aa7138164c2 ~ % docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 536349aa5921 registry.fit2cloud.com/maxkb/maxkb "bash -c /usr/bin/ru…" 3 minutes ago Up 3 minutes 5432/tcp, 0.0.0.0:8080->8080/tcp maxkb1
2
3
4
5
6
7
8
9
10
11
12
# 配置本地知识库问答系统
# 第一步: 配置知识库
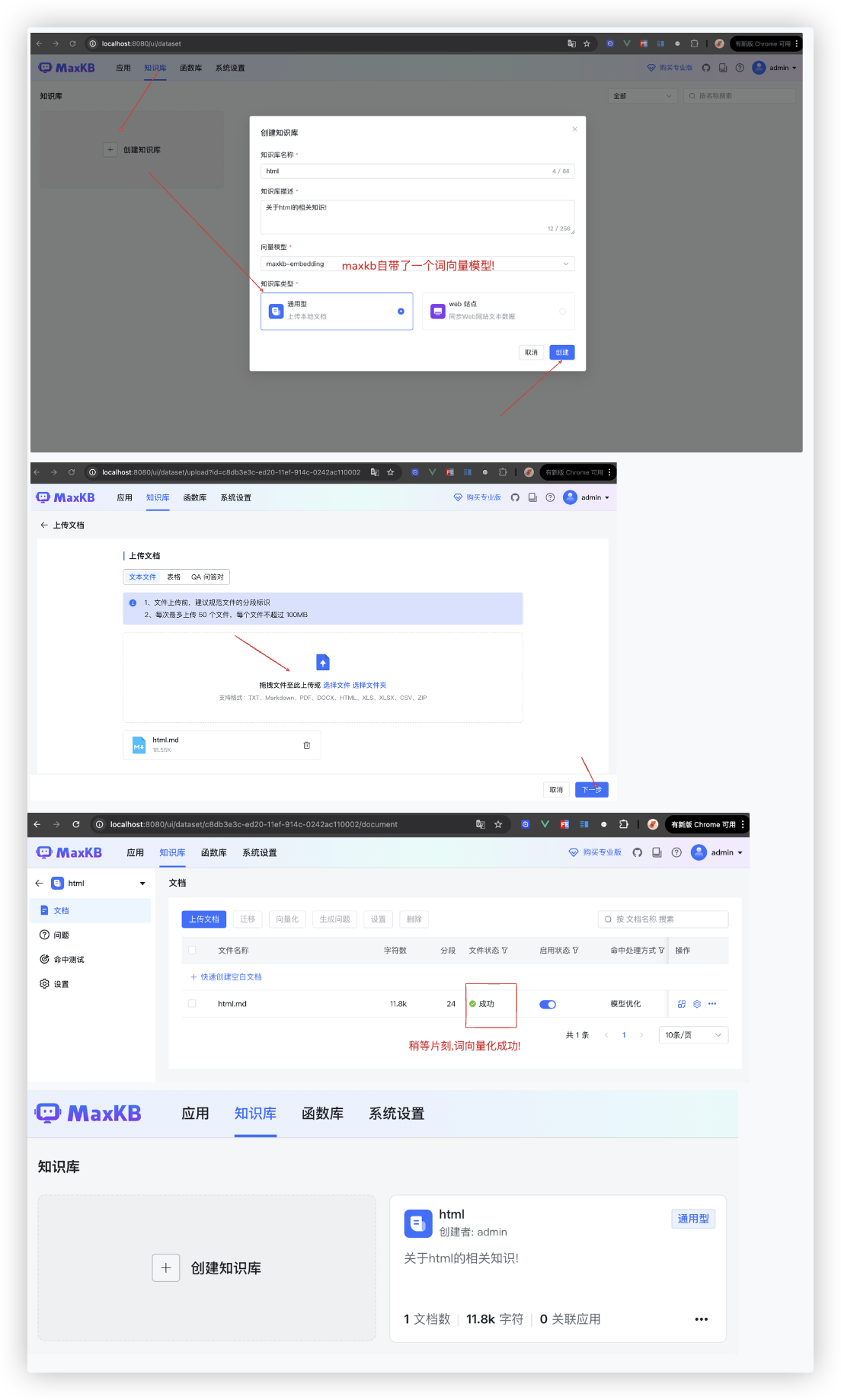
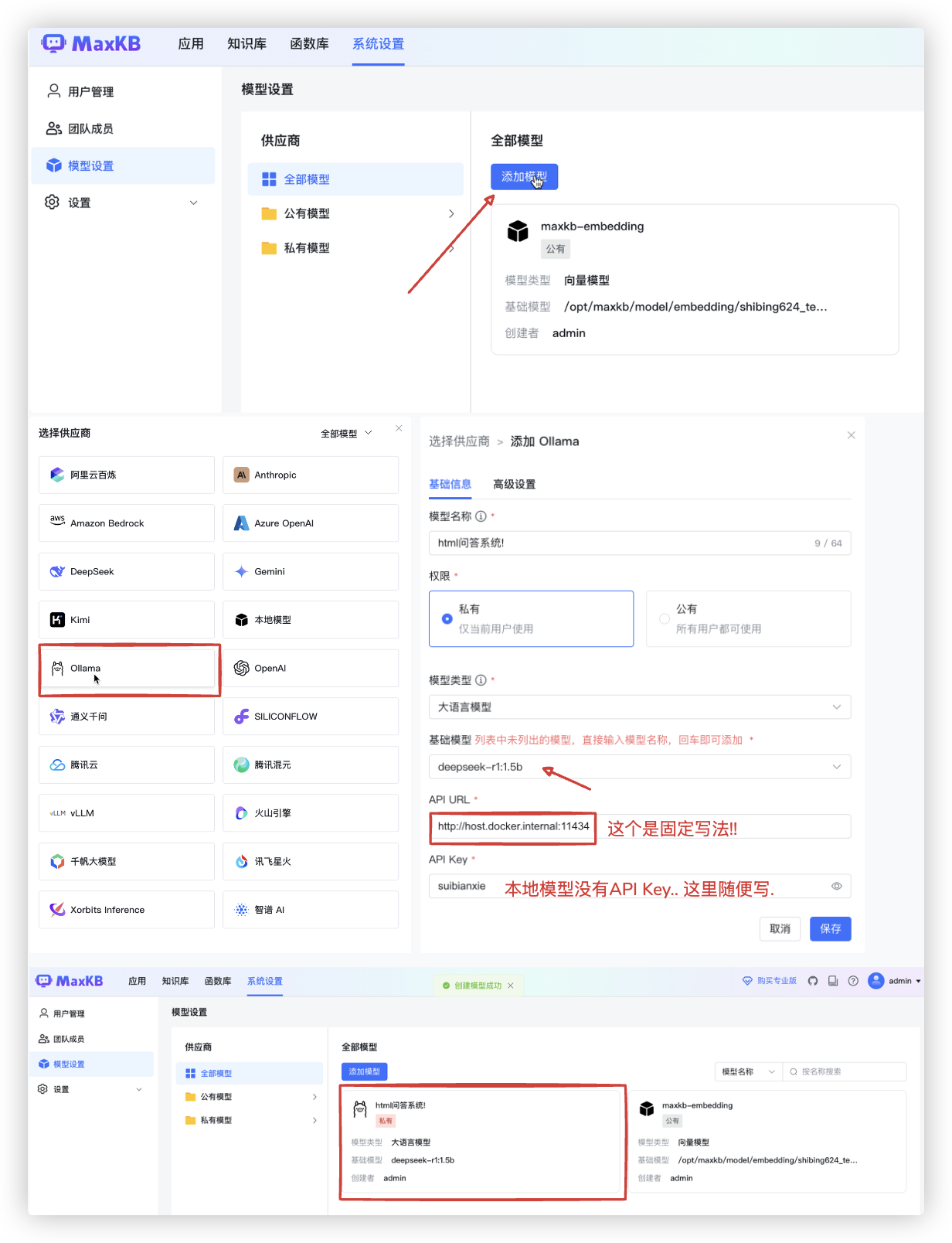
# 第二步: 配置模型
示例中用的是 本地的deepseek-r1:1.5b的大模型..
若你想用满血版的deepseek.. 那么在截图中,选择供应商的地方,点击 DeepSeek.进行api key的配置即可!!
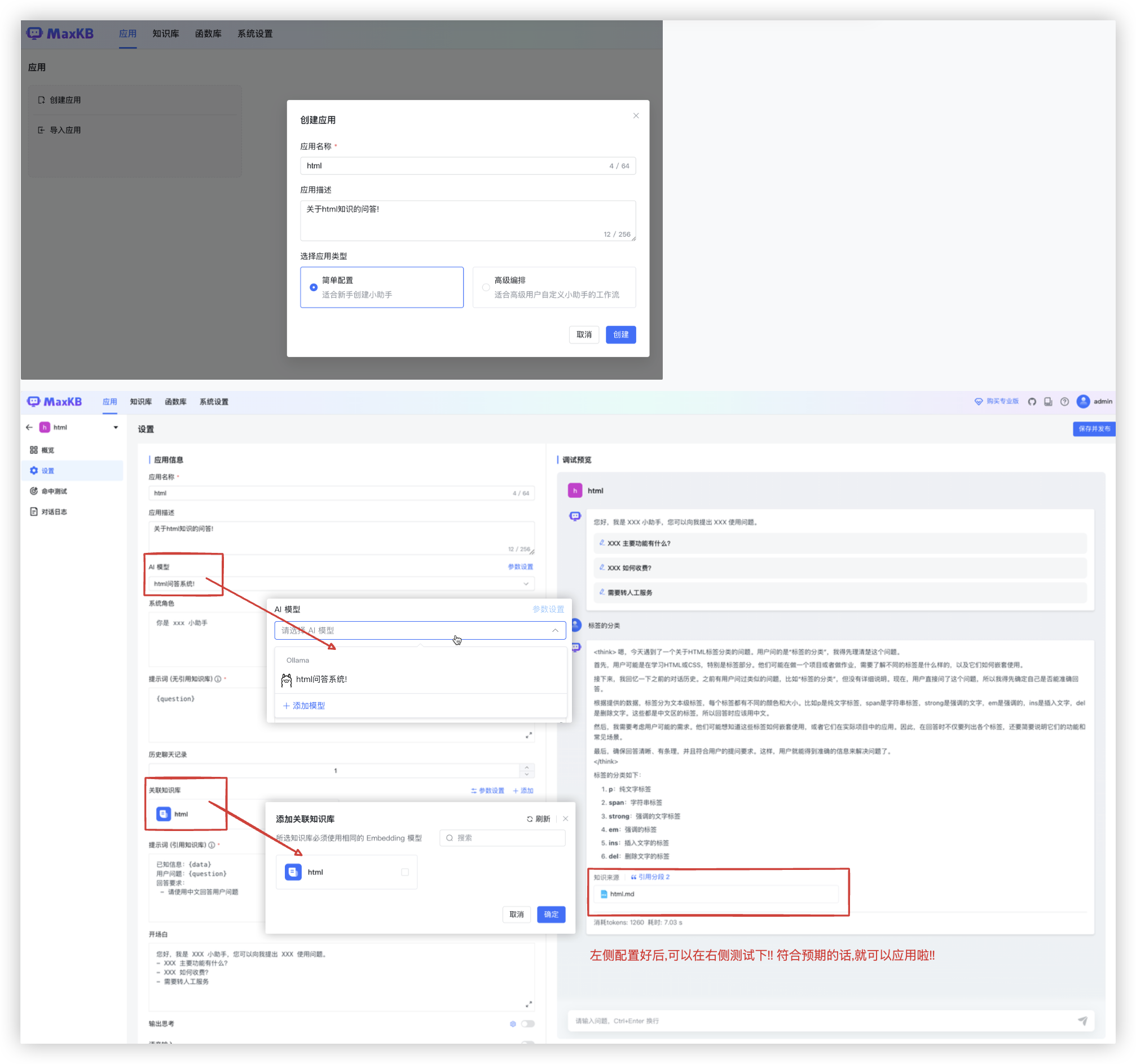
# 第三步: 创建应用
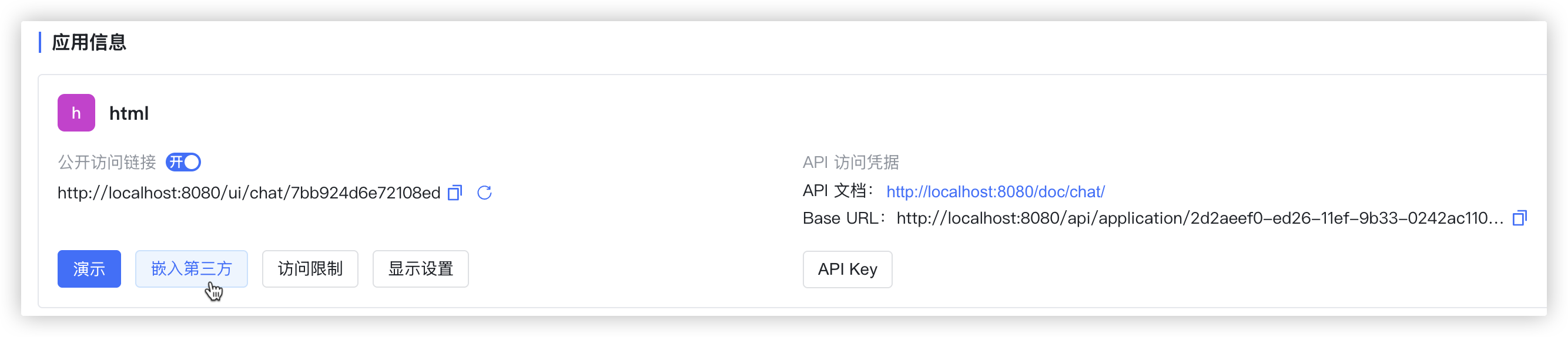
maxkb还贴心的提供了非常便捷嵌入到网页的功能.
# 补充
实测了下.在docker桌面版中停止了maxdb容器.

退出docker桌面版软件..

双击软件重新启动docker桌面版.. docker会运行起来.
☆ 查看命令结果可知,容器自己重新启动了!! 而且访问页面,先前配置的知识库、模型、应用都还在!

为什么呢? 这与执行启动maxdb的docker命令息息相关.
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
参数解释:
1. docker run:这是 Docker 用来启动容器的命令。
2. -d:表示容器在 后台(Detached mode)运行。容器启动后不会占用当前终端。
3. --name=maxkb:为容器指定一个名称 maxkb。这个名称可以用来在后续操作中引用这个容器,而不需要使用容器的 ID。
4. --restart=always:指定容器的重启策略。如果容器意外停止,它将自动重新启动。这里的 always 表示只要 Docker 服务正在运行,该容器就会一直被启动,即使它在运行时失败或退出。
5. -p 8080:8080:将宿主机的端口 8080 映射到容器的端口 8080。这意味着宿主机的 8080 端口流量会被转发到容器的 8080 端口。
6. -v ~/.maxkb:/var/lib/postgresql/data:
-v 参数用于 挂载卷.
它将宿主机的 ~/.maxkb 目录(用户的主目录下的 .maxkb 文件夹)挂载到容器内的 /var/lib/postgresql/data 目录。
这个目录通常用于 PostgreSQL 数据库的存储,挂载卷的目的是将数据保存在宿主机上,容器重启或删除时数据不会丢失。
7. -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages:
另一个卷挂载。
将宿主机的 ~/.python-packages 目录挂载到容器内的 /opt/maxkb/app/sandbox/python-packages 目录。
这通常用于容器内 Python 环境所需的包或依赖的存储,以便容器可以访问宿主机上的某些共享资源。
8. registry.fit2cloud.com/maxkb/maxkb:
这是要运行的 Docker 镜像的名称。
这个镜像来自 registry.fit2cloud.com 仓库,它的名称是 maxkb/maxkb。
Docker 会从该远程仓库拉取该镜像(如果本地没有的话),并使用它启动容器。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 接入满血DeepSeek-R1
因为DeepSeek是开源模型,有各种云服务厂商部署了他们的模型,通过API方式给用户提供服务.
也有一些公司把DeepSeek R1接入了自己的产品,比如AI编程工具Cursor、AI搜索产品Perplexity等.
不过,搜索、编程的使用场景毕竟还是受限,大家更习惯通过chatbot的方式去使用deepseek的服务..
于是各种云服务厂商引来了一波API使用用户量的爆炸!!
哪家deepseek API服务商提供的服务更稳定、速度更快呢?
现目前(25年2月18日),经实测: 火山方舟 > 硅基流动Pro > 阿里云百炼 >> DeepSeek官方
# 火山引擎
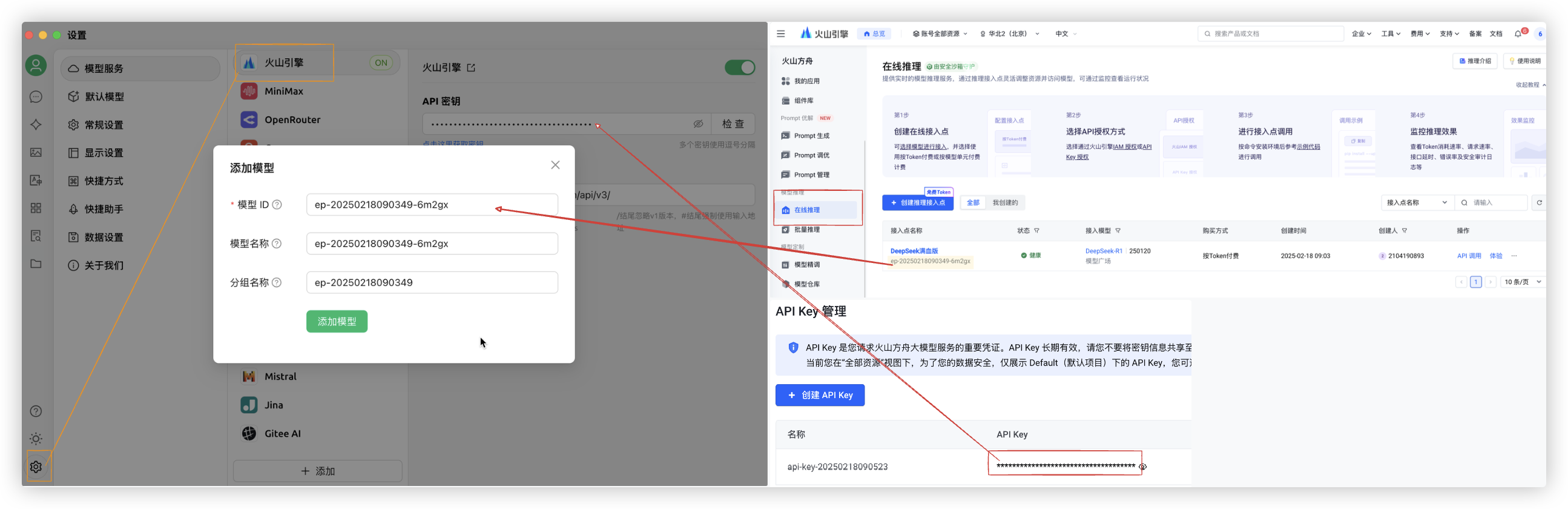
- Step1: 在火山引擎控制台..
在线推理模块创建DeepSeek-R1满血版的接入点. (需实名认证一下.有50w免费token)- 链接地址:
https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint
- 链接地址:
- Step2: 在火山引擎控制台..
API key管理那里创建一个API Key- 链接地址:
https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey
- 链接地址:
# CherryStudio
- Step3: 选择一个套壳产品,填入API key和模型端点信息
- 这里我们使用CherryStudio app. 产品文档:
https://docs.cherry-ai.com/ - CherryStudio是一款面向专业用户的多模型桌面客户端.
内置了30多个行业的智能助手,集成超过300个大语言模型.用户可根据需求自由切换模型.
- 这里我们使用CherryStudio app. 产品文档:
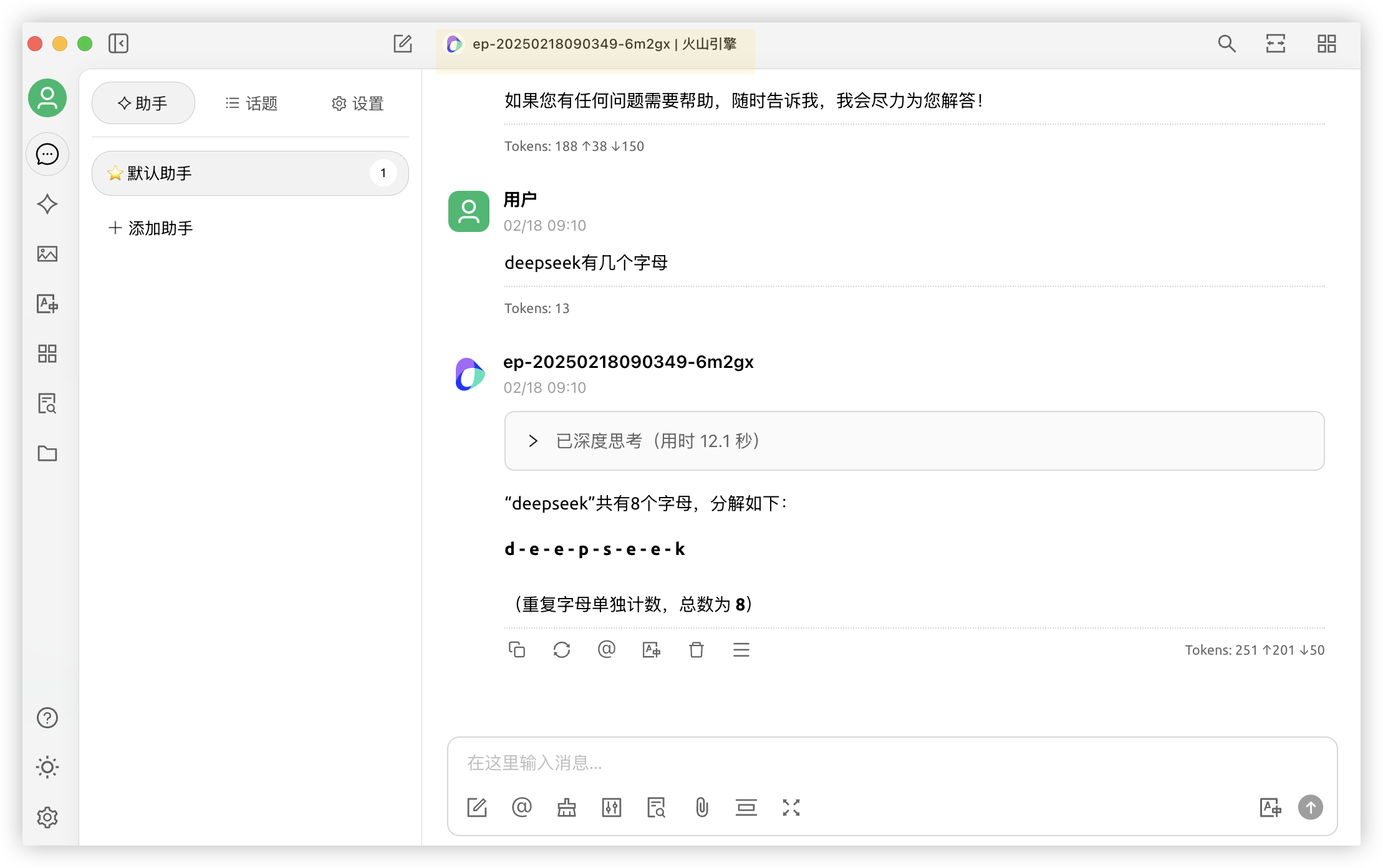
- Step4: 在聊天界面选择我们刚设置的模型,即可使用满血版本的DeepSeek-R1啦!
# 知识库
若想使用CherryStudio的知识库功能.则需要对传入知识库的文档进行RAG..
可以使用硅基流动提供的嵌入模型来对文档进行向量化..
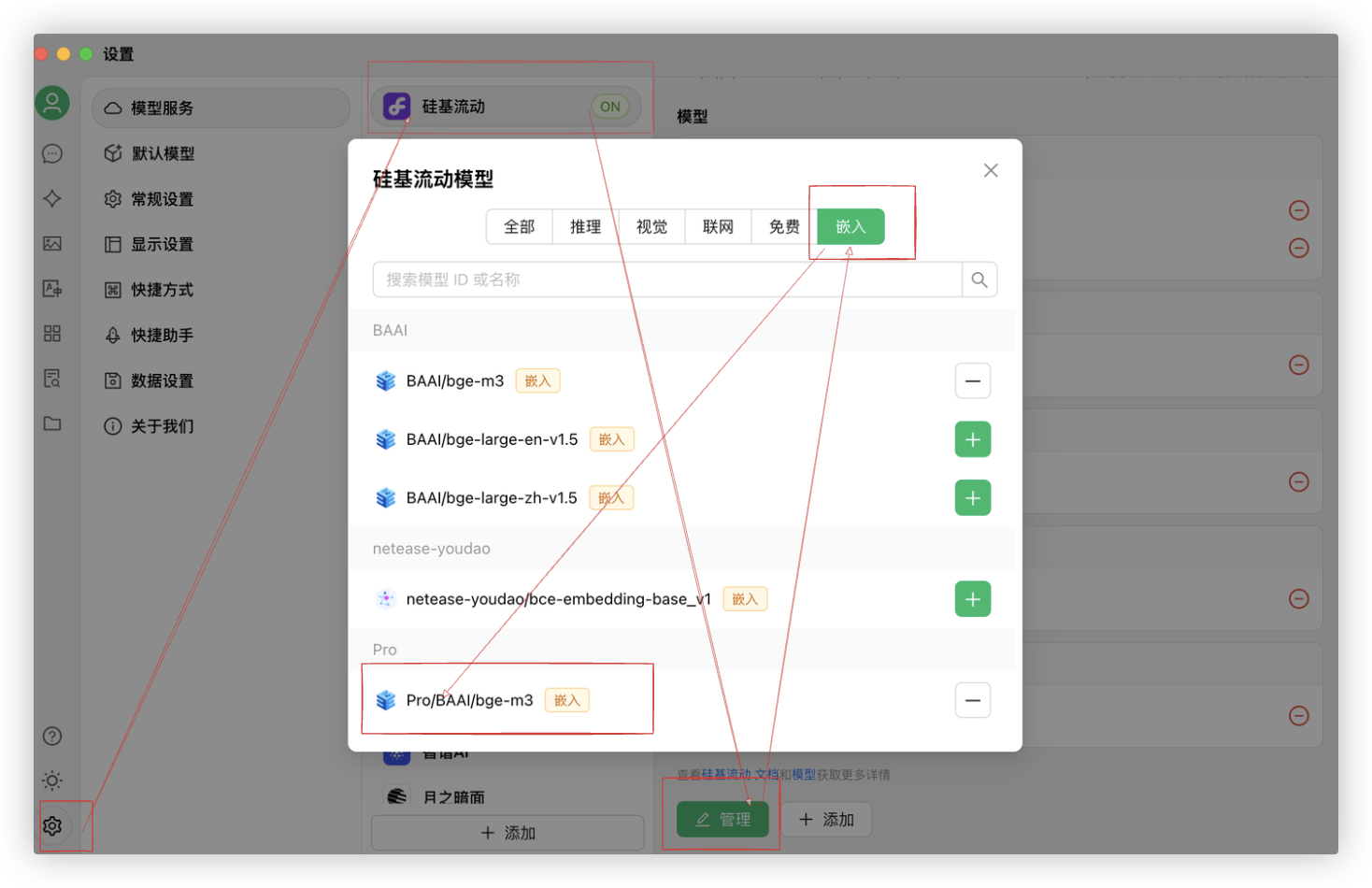
- 首先,你需要在CherryStudio的设置中选择
硅基流动这个模型服务.
配置从硅基流动官网获取API Key.. 以及配置下RAG嵌入模型
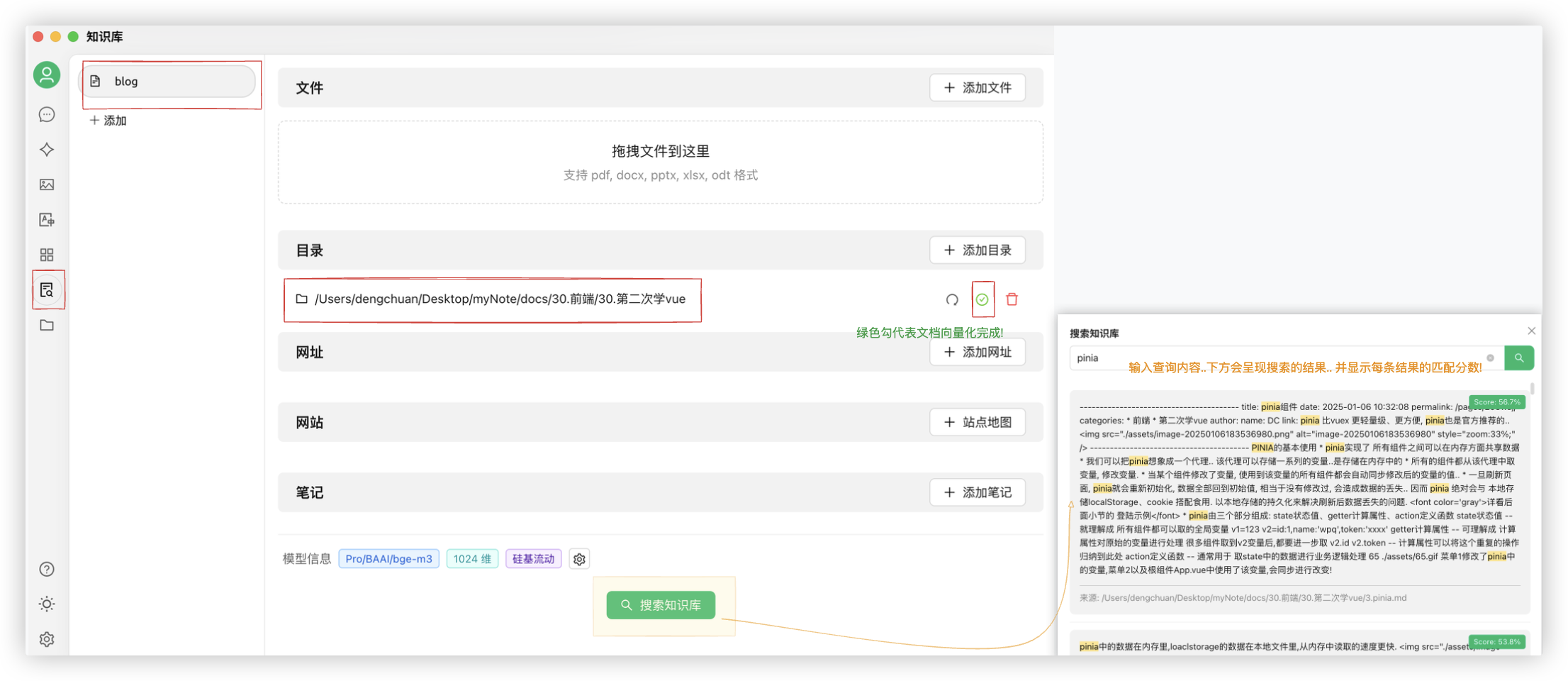
- 在CherryStudio里创建知识库对传入的文档用硅基流动的RAG嵌入模型进行向量化.
- 在CherryStudio里进行AI对话时使用知识库!
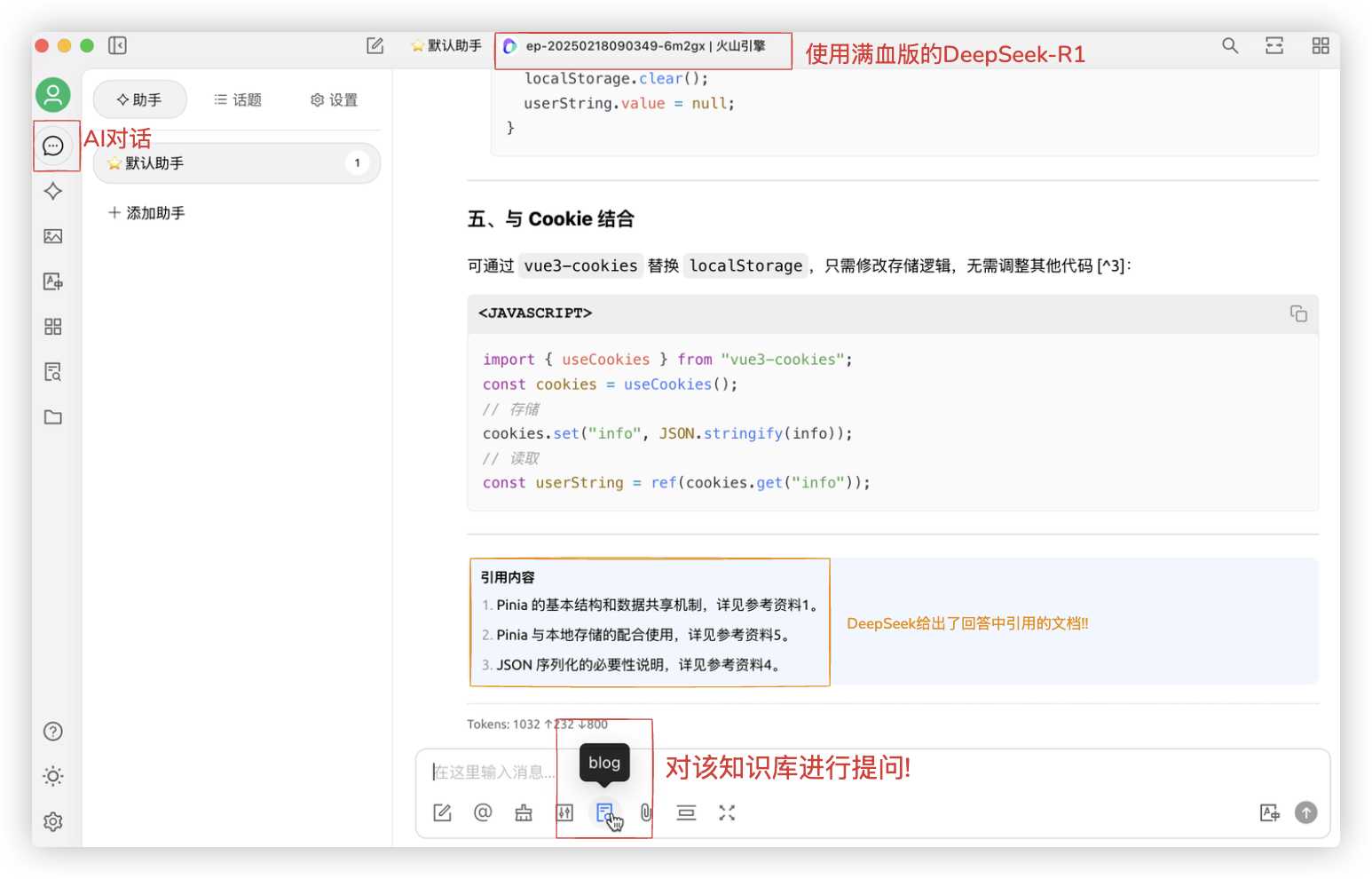
Ps: 在AI对话里也可以使用在硅基流动提供的DeepSeek-R1的API服务.. 但其很不稳定.. 所以我还是使用的火山引擎的!!