 序列化源码
序列化源码
# 示例代码
大致会分为四步详细来剖析这段代码, 剖析这段代码底层有关序列化的相关源码!!
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class InfoSerializer(serializers.ModelSerializer):
id = serializers.IntegerField()
title = serializers.CharField()
order = serializers.IntegerField()
class Meta:
model = models.UserInfo
fields = ["id", 'title',"order"]
class UserView(APIView):
def get(self, *args, **kwargs):
"""获取数据-序列化-返回"""
# 情况1.数据库获取单条数据进行序列化 默认many=False
# instance = models.UserInfo.objects.all().first()
# ser = InfoSerializer(instance=instance)
# 情况2.数据库获取多条数据进行序列化 many=True
queryset = models.UserInfo.objects.all()
ser = InfoSerializer(instance=queryset, many=True)
context = {"status": True, "data": ser.data}
return Response(context)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
注意哦, 呈列的源码是精剪过的, 有些判断、异常处理等直接去除了, 只保留了跟序列化有关的核心源码, 但不影响大体逻辑..
不厌其烦的提醒一点 死记!: 只要self.xxx 查找这个xxx属性时, 一定要 self实例 - 父类 - 父类的父类 ... 一步步的往上查找!!
序列化的源码, 我们一般不会在它里面做扩展, 所以不必一行行的探究其细节!! 明白大致流程即可!!
但感觉自己差不多都把关键代码的细节扣完了. ╮( ̄▽ ̄"")╭
定义类、创建类

序列化
# step1: 创建字段对象
分为两部分进行阐述: 计数器和字段对象方法
★先说结论:
step1: 创建字段对象
每个字段对象都有成员`_creation_counter`, 后续会通过这个计数器排序, 以此来实现字段的先后执行!
class Field:
_creation_counter = 0
def __init__(self, *, read_only=False, ...):
self._creation_counter = Field._creation_counter
Field._creation_counter += 1 # ★★★
class IntegerField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
class CharField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 计数器
维护了一个计数器! 该计数器定义了后续源码对这些字段的处理顺序.
Q: 根据下面这段代码, 先思考一个问题, v1、v2先创建还是Foo这个类先创建?
class Foo(object,metaclass=MyType):
v1 = 123
v2 = 456
2
3
A: 上面代码等同于 Foo = MyType("Foo",(),{"v1":123,"v2":456,}) , 也就是说:
元类MyType在实例化创建Foo这个类的过程中, {"v1":123,"v2":456,} 会作为参数传递进去!! So, 是123最先创建, 哈哈哈!
-=- 有了以上的思考, 我们很容易分析出下面这个序列化器类先创建什么. -=-
from rest_framework import serializers
class InfoSerializer(serializers.Serializer):
id = serializers.IntegerField()
title = serializers.CharField()
order = serializers.IntegerField()
2
3
4
5
6
它会先执行 serializers.IntegerField() 这样的代码!!
准确点说, 在类 InfoSerializer 创建之前, 其内部会先调用IntegerField等进行类实例化,创建出 id、title、order 等字段
-=- ok, 我们接着来看看 IntegerField、CharField 这些个类的源码长啥样?! -=-
关键代码如下:
class Field:
_creation_counter = 0
def __init__(self, *, read_only=False, write_only=False ,...,lable=None, ...):
self._creation_counter = Field._creation_counter
Field._creation_counter += 1 # ★★★
class IntegerField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
class CharField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-=- 源码中, 涉及到一个OOP相关的知识点. 我们单独提出来品一下. -=-
Field类每实例化一次, 其类变量count的值就会加1!! 所有的对象都看得到的且值都是一样的,这得是个类属性.
class Field:
count = 0
def __init__(self):
self.count = Field.count
Field.count += 1 # ★★★
f = Field()
print(f.count, Field.count) # 0 1
f = Field()
print(f.count, Field.count) # 1 2
f = Field()
print(f.count, Field.count) # 2 3
2
3
4
5
6
7
8
9
10
11
12
13
14
-=- OK, 回到 IntegerField、CharField 这些个类的源码, IntegerField、CharField 继承了 Field类 -=-
意味着, IntegerField、CharField 共享/可调用 Field类 命名空间中的一切东西(类变量、类中的方法).
So, 每当IntegerField和CharField类进行实例化, 都会调用Field类中的__init__方法, 该方法的逻辑使得
Field类里的类变量 _creation_counter 加1. (注意,传入的self不一样,这个基本常识就不说了.) (还可以换个角度思考,在IntegerField和CharField进行类实例化之前,Field这个类早就创建好啦! Field类不会因为它两进行的类实例化操作而重新创建.)
-=- 再看序列化器类的代码. 会通过IntegerField等类实例化出id、title、order等字段. 结合上面精简后的源码, 不难分析出: -=-
from rest_framework import serializers
class InfoSerializer(serializers.Serializer):
id = serializers.IntegerField()
title = serializers.CharField()
order = serializers.IntegerField()
"""
id = serializers.IntegerField() 执行后, id这个实例 其命名空间 {'_creation_counter':0}
title = serializers.CharField() 执行后, title这个实例其命名空间 {'_creation_counter':1}
order = serializers.IntegerField()执行后, order这个实例其命名空间 {'_creation_counter':2}
"""
2
3
4
5
6
7
8
9
10
11
12
补充一点, 若还有代码中还写了其他序列化器类的代码, 同样的道理:
from rest_framework import serializers
class InfoSerializer(serializers.Serializer):
id = serializers.IntegerField() # 命名空间 {'_creation_counter':0}
title = serializers.CharField() # 命名空间 {'_creation_counter':1}
order = serializers.IntegerField() # 命名空间 {'_creation_counter':2}
class OrderSerializer(serializers.Serializer):
title = serializers.CharField() # 命名空间 {'_creation_counter':3}
2
3
4
5
6
7
8
9
结论: 这就像是 基于_creation_counter 维护了一个计数器, 该计数器表明了谁先加载谁后加载!
意义何在? 让后续开发时, 根据该编写顺序来定义后续源码中各个字段的处理顺序!
# 字段对象方法
to_representation 方法.
先记住, 序列化的过程会调用字段对象的to_representation方法!!
Q: IntegerField和CharField里面都有to_representation方法,该方法干嘛的呢?
A: 比如, 某个序列化器中定义了字段 title = serializers.CharField(). 先说结论, 源码里何处调用的后续的源码分析会阐述.
当从数据库中拿到title字段的值后, 该值会作为该序列化器中title字段对象的to_representation方法的value参数的实参..
to_representation方法的返回值就是数据库中title字段序列化后的值.
class IntegerField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def to_representation(self, value):
return int(value)
class CharField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def to_representation(self, value):
return str(value)
2
3
4
5
6
7
8
9
10
11
12
13
14
# step2: 创建类
承上 - 序列化器类里的字段对象都维护了一个计数器, 表明它们的先后加载顺序.
启下 - 字段对象加载完,就该利用metaclass创建类啦!
★先说结论:.
step2: 基于元类创建序列化器类
利用metaclass创建完序列化器类后, 关乎该类中的成员:
1> 会自动剔除成员 - 字段对象
2> 会新增成员 `_declared_fields` , (将剔除的字段对象都放到了里面)
序列化器类中将有成员该成员中有 "自己写的序列化器类" 中的字段对象 以及 "该类继承的其他自己写的序列化器类" 中的字段对象.
- “★该字段对象是我们自己在类中写的字段对象/字段类型的类变量!!
它与后面序列化过程中ModelSerializer自动db匹配,匹配成功后实例化创建的字段对象是两码事哦!!”
- 值是OrderedDict类型! 就像是 `OrderedDict([('id', IntegerField()), ('title', CharField())])`
- 基于元类创建序列化器类时,若当前序列化器继承了多个自己写的其他序列化器类.
当自定义的字段对象名字重复时,它是按照继承顺序保留字段对象的!!
转个弯, A(B,C) 就自己写的字段对象而言 => A()._declared_fields = A + B中“A没有的” + C中“A和B都没有的”
3> 其它,保留原样 比如:Meta
# InfoSerializer = SerializerMetaclass(,"",{})
class SerializerMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['_declared_fields'] = cls._get_declared_fields(bases, attrs)
return super().__new__(cls, name, bases, attrs)
@classmethod
def _get_declared_fields(cls, bases, attrs):
fields = [(field_name, attrs.pop(field_name))
for field_name, obj in list(attrs.items())
if isinstance(obj, Field)]
fields.sort(key=lambda x: x[1]._creation_counter)
known = set(attrs)
def visit(name):
known.add(name)
return name
base_fields = [
(visit(name), f)
for base in bases if hasattr(base, '_declared_fields')
for name, f in base._declared_fields.items() if name not in known
]
return OrderedDict(base_fields + fields)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
先理清,大体结构是这样的:
class SerializerMetaclass(type):
pass
class BaseSerializer(Field):
pass
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
pass
class ModelSerializer(Serializer):
pass
class InfoSerializer(serializers.ModelSerializer):
"""
此处继承的是serializers.ModelSerializer
并且里面写了ORM数据表中的相对于名字的一些字段,又使用了Meta!
无需担心 源码分析到res.data真正进行序列化的时候,你会知道ModelSerializer会根据Meta中指定的字段自动去匹配并生成字段对象
但若在创建序列化器时,该字段已经创建了,那么会以先创建的那个为准!
"""
id = serializers.IntegerField()
title = serializers.CharField()
order = serializers.IntegerField()
class Meta:
model = models.User
fields = ["id", 'title',"order"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
阐述元类时说过, 此处再次强调:
一个类在没有指定的metaclass的时候, 如果它的父类指定了, 那么这个类的metaclass等于父类的metaclass!!
So, 根据继承关系, InfoSerializer类是由元类SerializerMetaclass类实例化创建的.
既然涉及到了元类, 条件反射应该想到, InfoSerializer类在被创建的过程中会向元类SerializerMetaclass的 __new__ 中传递三个值
类名name: "InfoSerializer"
父类bases: (serializers.ModelSerializer)
成员attrs: {'id': IntegerField(), 'title': CharField(), 'order' : IntegerField(), 'Meta': '...'}
2
3
接下来我们来细细分析, 元类 SerializerMetaclass!
InfoSerializer = SerializerMetaclass(,"",{"id"})
class SerializerMetaclass(type):
def __new__(cls, name, bases, attrs):
"""
-- 看到下面代码,第一反应,往序列化器类InfoSerializer的命名空间里添加了一个成员_declared_fields
即在创建类之前, 元类的`__new__`方法在类成员中添加了一个 `_declared_fields` (类变量).
-- 该成员_declared_fields的值是多少? 是_get_declared_fields的返回值, 分析该方法,可知:
_get_declared_fields方法返回的是当前序列化器类中所有自己写的字段对象 (自己+父类'继承的其他序列化器类')
"""
attrs['_declared_fields'] = cls._get_declared_fields(bases, attrs)
return super().__new__(cls, name, bases, attrs)
# 返回的是当前序列化器类中所有的字段对象 (自己+父类'继承的其他序列化器类')
@classmethod
def _get_declared_fields(cls, bases, attrs):
"""举个例子:
attrs --> {'id': IntegerField(), 'title': CharField(), 'order' : IntegerField(), 'Meta': '...'}
IntegerField、CharField都继承Field,所以 isinstance(CharField(), Field)为True!
So, id、title、order都是字段对象
fields --> [('id', IntegerField()), ('title', CharField()), ('order', IntegerField())]
"""
# step1> 循环获取类中定义所有的成员(类变量、方法), 筛选出继承自Fields的类的字段对象,
# 同时会将字段对象在当前类成员中移除!!
# 注意: list(attrs.items())是浅拷贝,之所以拷贝, 因为对迭代对象循环的同时剔除迭代对象里面的元素,会遗漏一些元素!!
fields = [(field_name, attrs.pop(field_name))
for field_name, obj in list(attrs.items())
if isinstance(obj, Field)]
""" 上面这个列表推导式等同于
fields = []
for field_name, obj in list(attrs.items()):
if isinstance(obj, Field):
fields.append((field_name, attrs.pop(field_name)))
"""
"""
在第一步创建字段对象中,我们知道序列化器类中的每个字段对象都有成员_creation_counter,表明先后顺序.
列表的sort方法原地排序.返回值为None.
Ps:之所以排序,是因为python3.7以前字典是无序的.
"""
# step2> 根据字段对象的_creation_counter排序
fields.sort(key=lambda x: x[1]._creation_counter)
# Ensures a base class field doesn't override cls attrs, and maintains
# field precedence when inheriting multiple parents. e.g. if there is a
# class C(A, B), and A and B both define 'field', use 'field' from A.
# 翻译源码中的这段注释,阐述的很明白了!
known = set(attrs)
def visit(name):
known.add(name)
return name
# step3> 读取该序列化器类继承的其他序列化器类中的_declared_fields字段(★序列化类支持继承,父类先于子类创建)
# 往下会分为两种情况进行详细的分析.
base_fields = [
(visit(name), f)
for base in bases if hasattr(base, '_declared_fields')
for name, f in base._declared_fields.items() if name not in known
]
""" 上面这个列表推导式等同于
base_fields = []
for base in bases:
if hasattr(base, '_declared_fields'):
for name, f in base._declared_fields.items():
if name not in known:
base_fields.append((visit(name), f))
return OrderedDict(base_fields + fields)
"""
# step4> 返回当前序列化器类中所有的字段对象 (自己+父类'继承的其他序列化器类')
return OrderedDict(base_fields + fields) # OrderedDict是有序字典
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
关于元类 SerializerMetaclass 中的 _get_declared_fields 中的 base_fields, 需要分两种情况细细讨论!!
-情况1-
像这里,我们写的序列化器类InfoSerializer没有继承其他序列化器类.所以base_fields为空.
_get_declared_fields方法的返回值为
OrderedDict([('id', IntegerField()), ('title', CharField()), ('order', IntegerField())])
最终该返回值会赋值给InfoSerializer类的_declared_fields成员!
<敲黑板!!
严谨点,InfoSerializer没有继承我们自己写的其他序列化器类
但它是继承了ModelSerializer的,ModelSerializer又继承了Serializer.
不管是ModelSerializer还是Serializer,都是通过元类创建的,创建过程中都会执行_get_declared_fields方法
值得注意的是,ModelSerializer和Serializer的源码中都没有定义字段对象
所以,执行_get_declared_fields方法的方法返回为[]
意味着,ModelSerializer的_declared_fields成员的值为OrderedDict()>
-情况2-
那如果,我们写的序列化器类InfoSerializer继承了自己写的其他序列化器类呢?
假如继承了FaSerializer,该FaSerializer类是先于InfoSerializer创建的
在FaFaSerializer中定义了两个字段对象id和more
所以,FaSerializer._declared_fields的值为
OrderedDict([('id', IntegerField()),('more', CharField())])
继续分析这段代码.
★ 关键在于,第二个for循环体!
它用来解决了 InfoSerializer和FaSerializer字段对象重名的情况.它会保留InfoSerializer中的!!
具体过程是这样的
- known = set(attrs) 即 known = {'id','title','order'}
- 为啥要visit(name)? 为了解决InfoSerializer继承了多个序列化器类. 关键就在于known.add(name)
字段对象名字重复时,它是按照继承顺序保留字段对象的!!
转个弯, A(B,C) 就字段对象而言 => B中“A没有的” + C中“A和B都没有的”
So,InfoSerializer(FaFaSerializer) base_fields的值为 [('more', CharField())]
So,该情况,_get_declared_fields方法的返回值为
“InfoSerializer中的字段对象加FaFaSerializer中InfoSerializer没有的字段对象”
OrderedDict([('id', IntegerField()), ('title', CharField()),
('order', IntegerField()), ('more', CharField())])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# step3: 创建对象
对序列化器类实例化的过程进行分析. 以many参数的bool值为参考, 需分两种情况讨论!
1> InfoSerializer(instance=instance, many=Fasle)
2> InfoSerializer(instance=queryset, many=True)
★先说结论:.
step3: 创建序列化器类的对象
根据情况,将从数据库中查到的数据封装到不同的实例对象中.
-情况1- ser = InfoSerializer(instance=instance, many=False)
type(ser) --:> <class 'api.views.UserSerializer'> 返回InfoSerializer类实例化对象!
-情况2- ser = InfoSerializer(instance=queryset, many=True)
type(ser) --:> <class 'rest_framework.serializers.ListSerializer'> 返回ListSerializer类实例化对象!
注: ★ 该实例对象里有InfoSerializer类的实例化对象,这个要特别注意!
why?为何如此设计.
利用ListSerializer处理queryset对象,会对其循环.对循环出的每一项再用InfoSerializer的类实例化对象进行序列化操作.
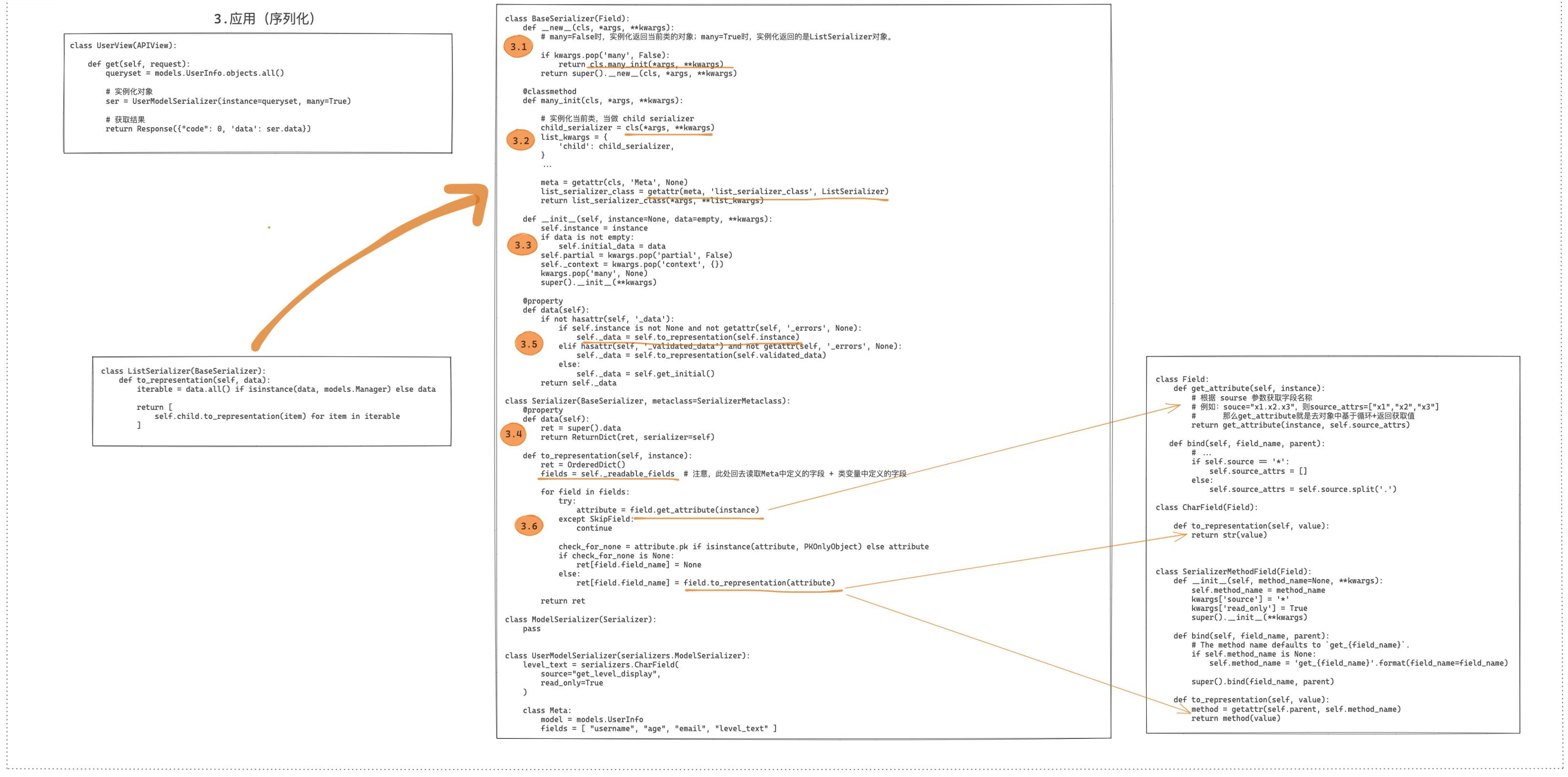
class BaseSerializer(Field):
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
super().__init__(**kwargs)
@classmethod
def many_init(cls, *args, **kwargs):
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
meta = getattr(cls, 'Meta', None)
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
return list_serializer_class(*args, **list_kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 源码结构
序列化器类创建好后, 自然而然, 我们会想到进行类实例化创建实例对象.
何处进行序列化器类的实例化操作呢? 这就不得不再来看看视图类代码!
当我们GET请求访问 http://127.0.0.1:8001/api/v1/user/ 时, 会触发下述代码get方法的执行..
class UserView(APIView):
def get(self, *args, **kwargs):
"""获取数据-序列化-返回"""
# 情况1.数据库获取单条数据进行序列化 默认many=False
# instance = models.UserInfo.objects.all().first()
# ser = InfoSerializer(instance=instance) # ★ 实例化操作 !!
# 情况2.数据库获取多条数据进行序列化 many=True
queryset = models.UserInfo.objects.all()
ser = InfoSerializer(instance=queryset, many=True) # ★ 实例化操作 !!
context = {"status": True, "data": ser.data}
return Response(context)
2
3
4
5
6
7
8
9
10
11
12
13
先理清大体结构 (在第二步,创建类时也有提及)..
提到类实例化, 条件反射应该想到, 需要找new方法、init方法!!
优先在序列化器类InfoSerializer中找,没有,根据继承关系, 最终在BaseSerializer类中找到啦!!
class SerializerMetaclass(type):pass
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):pass
def __new__(cls, *args, **kwargs):pass
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):pass
class ModelSerializer(Serializer):pass
class InfoSerializer(serializers.ModelSerializer):pass
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
接着进行分析之前,不得不着重提醒一点,切记: new返回什么, 当前类实例化对象就是什么.
(务必翻看上一篇元类中 "类的实例化" 小节阐述的内容,里面有new和init这两个方法的注意事项)
# many=False
当前序列化器类实例化后 得到的是 序列化器类实例对象!
InfoSerializer(instance=instance, many=Fasle) 关键源代码如下:
class BaseSerializer(Field):
def __new__(cls, *args, **kwargs):
"""
cls --:> 序列化器类InfoSerializer
kwargs --:> {"instance":instance, "many":False}
"""
# 当many=False时,不会执行return cls.many_init(*args, **kwargs).
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
# 创建当前序列化器类InfoSerializer进行类实例化后的空实例对象 并返回
return super().__new__(cls, *args, **kwargs)
def __init__(self, instance=None, data=empty, **kwargs):
# 做了一系列初始化的操作
# ... ...
self.instance = instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# many=True
当前序列化器类实例化后 得到的是 ListSerializer类实例对象!
注意: 该实例对象中有当前序列化器类的实例对象!
InfoSerializer(instance=queryset, many=True) 关键源代码如下:
class BaseSerializer(Field):
def __new__(cls, *args, **kwargs):
"""
cls --:> 序列化器类InfoSerializer
kwargs --:> {"instance":instance, "many":True}
"""
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs) # 当many=True时,执行该行代码
return super().__new__(cls, *args, **kwargs) # 前面已return,此行代码不会执行
""" kwargs.pop('many', False) 很有意思:
>>> my_dict = {"a":1,"b":2}
>>> my_dict.pop("a")
1
>>> my_dict.pop("a",False)
False
>>> my_dict.pop("a")
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
my_dict.pop("a")
KeyError: 'a'
"""
def __init__(self, instance=None, data=empty, **kwargs):
# 做了一系列初始化的操作
# ... ...
self.instance = instance
# ... ...
super().__init__(**kwargs)
@classmethod
def many_init(cls, *args, **kwargs):
.. .. ..
# 该行代码会再次实例化序列化器类InfoSerializer, InfoSerializer(*args, **kwargs)
# 当然,它也会去BaseSerializer里执行new方法和init方法!
# 但需注意,它第一次实例化时,执行了kwargs.pop('many', False),此次实例化kwargs里就没有many啦!
# So,第二次实例化过程跟many=False时一样.
child_serializer = cls(*args, **kwargs)
# 将类实例化对象InfoSerializer()加入了这个字典中!
list_kwargs = {
'child': child_serializer,
}
.. .. ..
""" 下面两行代码意味着,Meta中还可以设置变量list_serializer_class,不设置的话,其默认是ListSerializer
举个栗子
class InfoSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["id", 'title',"order"]
# list_serializer_class = ListSerializer
"""
meta = getattr(cls, 'Meta', None) # 读取序列化器类InfoSerializer的Meta成员
# 相当于list_serializer_class = ListSerializer
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
# 相当于 ListSerializer(*args, {'child': InfoSerializer(),..,..})
return list_serializer_class(*args, **list_kwargs)
"""
提前说:
利用ListSerializer处理queryset对象,会对其循环.对循环出的每一项再用InfoSerializer的类实例化对象进行序列化操作.
ListSerializer()的类实例化过程,暂且不看,后面篇幅会进行分析.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# step4: 序列化 - 单条
ser.data 触发序列化
在step3中我们知道创建的序列化器类的对象ser的类型有两种.
1> 当前序列化器类InfoSerializer类,该类的实例化对象. -- 对应many=False 单条数据 2> ListSerializer类的实例化对象 -- 对应many=True 多条数据该小节 将针对 单条数据 的序列化过程进行讨论.
ser是当前序列器类的实例化对象 / 从数据库中取到的是单条数据 / many=False
★先说结论: 结论不了一点,太绕了,根据下面这张我画的流程图慢慢理.
依照这张流程图能很好的理解我接下来剖析源码的思路. ψ(`∇´)ψ
# ser.data
查看源码, ModelSerializer里没有data, 先是在Serializer中找到啦,
Serializer的data方法里面有代码super().data, 再往上找, 最后定位到了BaseSerializer中的data.
作用是啥呢? 简单来说, 就是触发 to_representation方法的执行!!
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance # instance是从数据库中取到的数据. 此处是单条数据
if data is not empty:
self.initial_data = data. # 它跟验证有关,暂且不用关心.
super().__init__(**kwargs)
@property
def data(self): # 注意,此处的self是 序列化器类InfoSerializer的实例对象!
# 此处有个判断raise异常是跟验证有关的,暂且省略了!
if not hasattr(self, '_data'):
"""
说明: 条件1 and not 条件2
1> InfoSerializer(instance=instance, many=Fasle)
2> 执行ser.is_valid验证时,若验证不通过,才会新增_errors成员并将错误信息添加到里面!!
该篇博文只单纯的进行序列化,不涉及验证,所以getattr(self, '_errors', None)为None!!
So,该if条件成立!
"""
if self.instance is not None and not getattr(self, '_errors', None):
# ★ 序列化功能!将instance数据序列化成支持json格式的数据.
# PS: 此处调用了序列化器类实例的to_representation方法,回顾上面的知识,字段对象也有to_representation方法!
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
@property
def data(self):
ret = super().data # -- 调用父类BaseSerializer中的data
return ReturnDict(ret, serializer=self)
class ModelSerializer(Serializer):pass
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
***接下来关键在于 self.to_representation(self.instance) !!***
# ser.to_representation
BaseSerializer.data中有一行关键代码:
self._data = self.to_representation(self.instance)
根据属性查找关系, 在Serializer类中找到了to_representation方法.
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
def to_representation(self, instance):
ret = OrderedDict()
# 第一部分:获取所有字段,并筛选出可序列化的字段对象!! ★
fields = self._readable_fields
# 第二部分:循环这些可序列化的字段对象!! ★
for field in fields:
try:
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute)
return ret # 返回的是一个有序字典
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
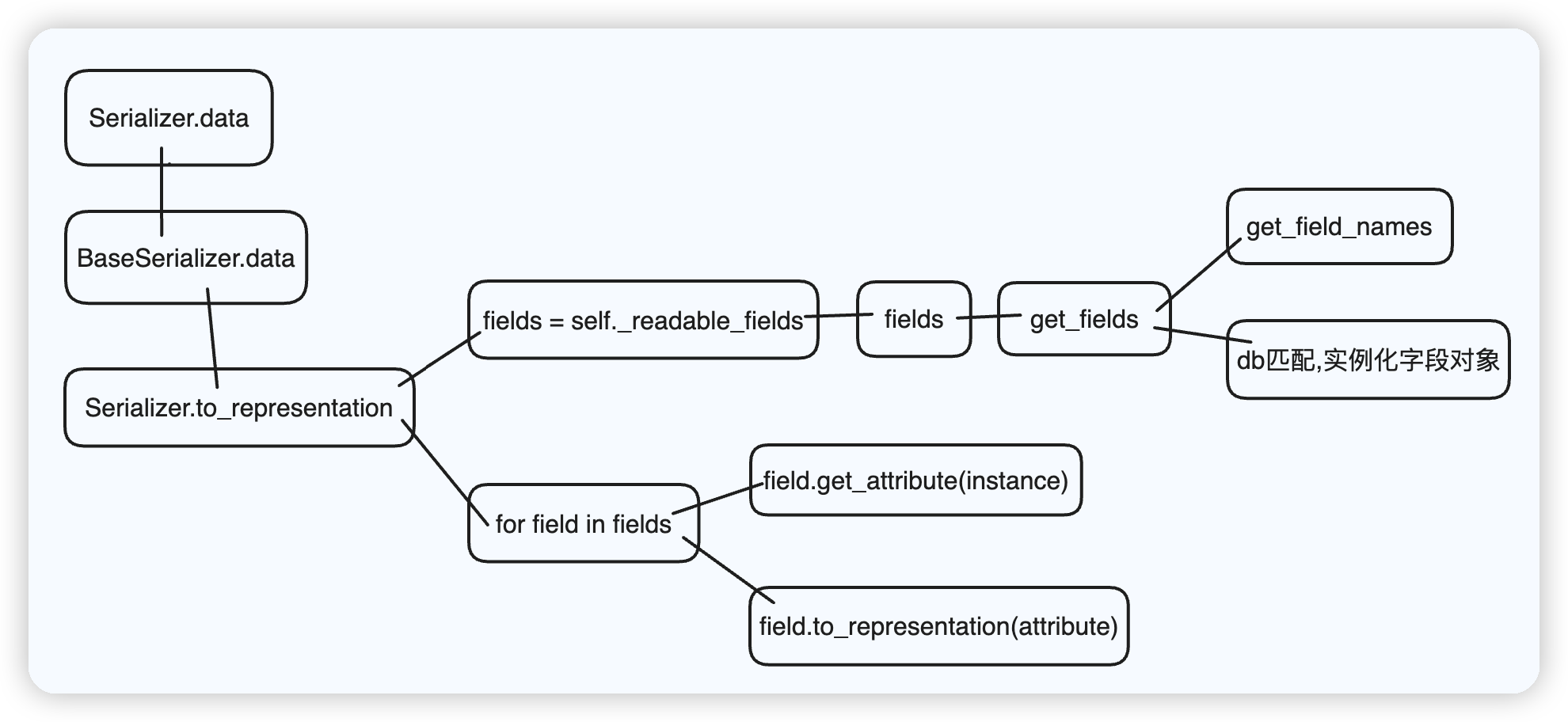
接下来会详细阐述to_representation方法中的两个部分!! 一部分是 _readable_fields ; 一部分是循环.
# 获取可序列化的字段对象
该段源码查看顺序, 我用
[1][2][3]进行了标注!
_readable_fields-fields-get_fields
# ser._readable_fields
_readable_fields方法 的作用是啥呢? 它会获取所有字段对象,并筛选出可序列化的字段对象!
筛选过程是通过 if not field.write_only 实现的!
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
# 需明确此处self是序列化器类InfoSerializer的实例对象;instance是"数据库中的单条记录"
def to_representation(self, instance):
ret = OrderedDict()
# 获取所有字段,并筛选出可序列化的字段对象!! ★
fields = self._readable_fields # 【1】
for field in fields:
... .. ..
return ret
@property
def _readable_fields(self):
for field in self.fields.values(): # 【2】
if not field.write_only: # 筛选可用于序列化的字段对象
yield field # 注意:返回的是一个generator生成器对象,按需取!
@cached_property
def fields(self):
fields = BindingDict(self)
for key, value in self.get_fields().items(): # 【3】
fields[key] = value
return fields
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# ser.fields
ser.fields的作用: 对获取到的所有字段对象进行了加工!!
具体获取所有字段对象的过程需要剖析get_fields才可得知!get_fields的源码下一部分会详细阐述!
fields = BindingDict(self) 这行代码很有意思, 值得你细品!!
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
def to_representation(self, instance):
ret = OrderedDict()
fields = self._readable_fields # 【1】
for field in fields:
... .. ..
return ret
@property
def _readable_fields(self):
for field in self.fields.values(): # 【2】
if not field.write_only:
yield field
@cached_property
def fields(self):
""" ★★★ 一开始还没注意.通过pycharm的右键查找用法才观察到Field类的bind在这里调用啦!! (つД`)ノ
# MutableMapping抽象类里规定了自定义的BindingDict里必须重写哪些方法!
class BindingDict(MutableMapping):
def __init__(self, serializer):
self.serializer = serializer
self.fields = OrderedDict() # 有序字典
# ▲ 务必理清楚: key 字段名 ; field字段名对应的字段对象 ; serializer 序列化器类的实例对象
def __setitem__(self, key, field):
self.fields[key] = field # 存
field.bind(field_name=key, parent=self.serializer)
def __getitem__(self, key):
return self.fields[key] # 取
假设self.get_fields()的返回值等于:
OrderedDict([
('id', IntegerField(label='ID', read_only=True)),
('name', CharField(label='姓名', max_length=32)),
('age', IntegerField(label='年龄'))
])
"""
# 简单来说,BindingDict(self)这个实例里有个有序字典.
# 中括号赋值时调用__setitem__往这个有序字典里存、中括号取值时调用__getitem__从这个有序字典里取.
# ★ 在fields[key] = value进行赋值操作时,就会调用BindingDict.__setitem__方法, !!该方法里面会触发bind方法!!
fields = BindingDict(self)
for key, value in self.get_fields().items(): # 【3】
fields[key] = value
return fields
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
需要单独拿出来补充的点
需要注意的点!!我花了两个小时才意识到的. ╮( ̄▽ ̄"")╭
- Django的@cached_property 会将被装饰的方法的运行结果放到实例的__dict__中,
再次调用该方法时,不会重复执行该方法,而是会去实例的__dict__中取.
- @cached_property 的做法等同于
“执行方法A时” 通过 getattr(self,'_data') 判断实例有无_data成员,没有就执行if 语句体的内容 self._data = "xxx"
最后return self._data, “再次执行方法A时”, 因为self中有'_data'啦 所以直接return
- 关于上面源码中的fields方法中的这行代码, fields = BindingDict(self) 需特别注意!! 还挺有意思的.
补充说明:
__getitem__ 和 __setitem__, 与 obj[key] 相关 !! -- 可以写个类不继承字典但可以实现字典的取赋值的方式!(上述的源码就是)
__setattr__ 和 __getattr__, 与 obj.key 相关 !!
-- 可以写个类继承字典,让字典同时支持 点和中括号 的取值、赋值!
简单来说,类继承字典,那么该类实例就是字典,字典本身是支持中括号取值,但字典本事是不支持点取值的.
让字典支持点取值: 通过点取值时,调用__getattr__(self,key)方法,该方法里再return self[key]
顺手提醒一下,在__getattr__里面可千万不能通过.来访问一个不存在的属性, 因为那样会陷入无限递归
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@cached_property 的应用 举例
import datetime
from django.utils.functional import cached_property
class Person:
def __init__(self, birth_year):
self.birth_year = birth_year
@cached_property
def age(self):
print("Calculating age...")
current_year = datetime.datetime.now().year
return current_year - self.birth_year
john = Person(1990)
print(john.age) # 第一次访问,需要计算年龄,输出 "Calculating age..." 和计算结果
print(john.age) # 第二次访问,直接返回缓存的结果/return的值,无需再次计算
"""
Calculating age...
33
33
"""
# 要注意一点,我访问`http://127.0.0.1:8000/publish/`,底层多次用到了@cached_property修饰的A方法.A方法只会执行一次.
# 但是,我多次访问`http://127.0.0.1:8000/publish/`这个接口,每次访问都是一个新的请求,都会执行一下@cached_property修饰的方法!
# So,一定要注意,是否是同一个请求!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# field.bind
特别阐述下bind过程, 这个过程蛮重要的!!
简单来说,处理字段对象的一些属性 field_name、parent、label、source、source_attrs.
★★ 一些规则
source
my_field = serializer.CharField(source='my_field') 报错
但若你不写source,像这样 my_field = serializer.CharField() Source默认为与字段名相同
field_name
就是字段名!!!
label
当字段类型的类变量 在Fiels的__init__初始化时,没有传label值进去 or
db匹配自动创建字段对象时,ORM数据表中的该字段没有设置verbose_name
采用规则, label = 字段名.replace('_','').capitalize()
source_attrs 与 source的一些对应关系
- source "字段名" <==> source_attrs ["字段名"]
- sourse "depart.title" <==> source_attrs ['depart','title']
- sourse "get_gender_display" <==> source_attrs ["get_gender_display"]
- source "*" <==> source_attrs []
2
3
4
5
6
7
8
9
10
11
12
13
14
源码如下:
class Field:
_creation_counter = 0
def __init__(self, *, read_only=False, source=None, ...):
self._creation_counter = Field._creation_counter
Field._creation_counter += 1
self.source = source
# These are set up by `.bind()` when the field is added to a serializer!!
self.field_name = None
self.parent = None
# ★★★ Serializer类的fields方法里的BindingDict类型的数据在进行赋值操作时会涉及到对它的调用!!!
# 也就是说bind操作不是在 `for field in fields`小节做的, 而是在 `ser.fields` 小节做的!!
# ▲ 务必理清楚: field_name字段名 ; self字段名对应的字段对象 ; parent序列化器类的实例对象
def bind(self, field_name, parent):
"""
★ 为了保证风格的一致性,如果使用了冗余的'source'参数,就会报错..
比如: my_field = serializer.CharField(source='my_field') 这种写法就会报错!
报错信息:
在序列化程序“PublishSerializer”中的字段“CharField”上指定“source='title”是多余的,
因为它与字段名称相同,删除“source”关键字参数.
"""
# field_name 字段名 ;
# self.__class__.__name__ 字段对象所在类的名字 ;
# parent.__class__.__name__ 序列化器类实例所在类的名字 ;
assert self.source != field_name, (
"It is redundant to specify `source='%s'` on field '%s' in "
"serializer '%s', because it is the same as the field name. "
"Remove the `source` keyword argument." %
(field_name, self.__class__.__name__, parent.__class__.__name__)
)
self.field_name = field_name # field_name是字段名
self.parent = parent # 序列化器类的实例
"""label何时为空?
- 字段类型的类变量 在Fiels的__init__初始化时,没有传label值进去,label使用默认参数值None
- db匹配自动创建字段对象时,ORM数据表中的该字段没有设置verbose_name
同样在Fiels的__init__初始化时,label使用的是默认参数值None
"""
# "user_addr".replace('_','').capitalize() ==> 'Useraddr'
if self.label is None:
self.label = field_name.replace('_', ' ').capitalize()
"""★ 但若你不写source,像这样 my_field = serializer.CharField() Source默认为与字段名相同."""
if self.source is None:
self.source = field_name
""" 若设置类变量为SerializerMethodField字段类型,那么其source值为 “*”
(SerializerMethodField类的源码可佐证!) """
if self.source == '*':
self.source_attrs = []
else:
"""
举个例子, serializers.CharField(sourse="depart.title")
若 序列化器类中字段类型的类变量的sourse属性值为depart.title
那么 其source_attrs属性值为 ['depart','title']
"""
# !注意: "get_gender_display".split('.') 的结果是 ["get_gender_display"] !!
self.source_attrs = self.source.split('.')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
***接下来关键在于 self.get_fields() !!***
# ser.get_fields
根据属性查找关系, 在ModelSerializer类里找到了get_fields!!
(如果你在pycharm里直接通过command+b跳转过去,定位到的是Serializer中的get_fields方法, 直接拉闸! 哈哈哈)注意哦:
若序列化器类继承的是Serializer, 那么Serializer的get_fields方法, 会直接return copy.deepcopy(self._declared_fields).
ser.get_fields作用: 获取所有字段对象!
ser.get_fields 也分为两部分来阐述!! 一部分 ser.get_field_names ; 另一部分 db匹配实例化字段对象.
★★ 一些规则
若序列化器类继承ModelSerializer
1> 那么序列化器类里必须得写Meta,且Meta中必须有属性model!! '(出自get_fields中的assert)'
-- 关于Meta中的的fields属性和exclude属性. '(出自get_field_names中的raise和assert 里面一共有7个)'
2> fields、exclude的类型可以是列表和元祖;另外fields的值还可为"__all__" [1][2]
3> fields、exclude不可在Meta中同时存在 [3]
4> Meta中得设置fields或exclude [4]
5> 若使用fields,序列化器类中 字段类型的类变量的名字/自己写的字段对象 必须以 字符串的形式 写在fields中. [5]
6> 若使用exclude, exclude中不应该有跟序列化器类中同名的字段类型的类变量. [6]
即 exclude中的成员名字 应该 not in self._declared_fields !!
7> 若使用exclude, exclude中写的字段名必须是ORM数据表中的字段名.“★ 还应排除ORM表中和字段类型的类变量重名的字段名” [7]
源码中是这样的, exclude中的成员名字 需要 in (self._declared_fields+ORM数据库表中的字段名字)
但根据前面那一条, exclude中的成员名字 应该 not in self._declared_fields 上一条需先满足,还需考虑重名的时候.
2
3
4
5
6
7
8
9
10
11
12
# ser.get_field_names
★ 根据规则写fields或exclude的值,这是前提 分析这么多,get_field_names就干了这么点东西.Hhh.
1>field =["name","age","addr"]
提醒: 字段类型的类变量一定包含在里面 !! 里面还可以写啥,"db匹配创建字段对象"的源码里规定了得写ORM表中的字段名!!
get_field_names返回['name','age','addr']
2>field = "__all__"
get_field_names返回[ser._declared_fields中的字段对象的字段名 + ORM数据表中的字段名"包括id"]
3>exclude = ["name"]
get_field_names返回[相当于 __all__ - "name"]
★ 综上, get_field_names返回的字段名集合 必定 小于等于/包含于等于 [字段类型的类变量+ORM表中的字段名] !
# 源码中的raise和assert被我省略了.
class ModelSerializer(Serializer):
def get_fields(self):
"""
回顾:
基于元类创建的序列化器类有成员_declared_fields
里面是序列化器类中自己写的字段对象/字段对象类型的类变量 (自己+父类'继承的其他序列化器类') 是OrderedDict类型.
"""
# 1.获取序列化器类中 自己写的字段对象/字段对象类型的类变量. “进行了深拷贝”
declared_fields = copy.deepcopy(self._declared_fields)
"""
class InfoSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = fields = ["id", 'title',"order"]
"""
# 2. 获得序列化器类应用的是Django的哪张数据库表
model = getattr(self.Meta, 'model')
"""
depth深度,极少用. 了解即可.
它会自动将外键字段关联表的记录序列化出来.该记录中若还有外键,会继续序列化,数字代表几层.
"""
depth = getattr(self.Meta, 'depth', 0)
if depth is not None:
assert depth >= 0, "'depth' may not be negative."
assert depth <= 10, "'depth' may not be greater than 10."
# 3. 获取ORM中UserInfo表中定义的全部字段
info = model_meta.get_field_info(model)
# -- 第一部分: 4. 根据Meta中的fields或exclude属性,得到一些 字段名字.
field_names = self.get_field_names(declared_fields, info)
extra_kwargs = self.get_extra_kwargs()
extra_kwargs, hidden_fields = self.get_uniqueness_extra_kwargs(
field_names, declared_fields, extra_kwargs
)
# -- 第二部分: 5. db匹配实例化字段对象 后续会详细阐述!
fields = OrderedDict()
for field_name in field_names:
if field_name in declared_fields:
fields[field_name] = declared_fields[field_name]
continue
field_class, field_kwargs = self.build_field(source, info, model, depth)
fields[field_name] = field_class(**field_kwargs)
fields.update(hidden_fields)
return fields
# declared_fields: 序列化器类中自己写的字段对象/字段对象类型的类变量 (自己+父类'继承的其他序列化器类')
# info: ORM中UserInfo表中定义的全部字段
def get_field_names(self, declared_fields, info):
fields = getattr(self.Meta, 'fields', None)
exclude = getattr(self.Meta, 'exclude', None)
if fields == ALL_FIELDS: # 即 if fields == "__all__":
fields = None
if fields is not None:
required_field_names = set(declared_fields)
for cls in self.__class__.__bases__:
required_field_names -= set(getattr(cls, '_declared_fields', []))
return fields
"""举个例子
class UserSerializer(serializers.ModelSerializer):
name = serializers.CharField()
class Meta:
model = models.UserInfo
fields = "__all__"
def get_field_names(self, declared_fields, info):
res = super(UserSerializer, self).get_field_names(declared_fields, info)
# 列表中有两个name 类变量name和UserInfo表中的name
# res ==> ['id', 'name', 'name', 'age', 'gender', 'ctime', 'depart', 'tag']
return res
"""
# ★ 当序列化器类Meta.fields="__all__"时,会执行这行代码!!
# 那么 会将self._declared_fields中的 + 数据库表的所有字段 放到一个列表中
fields = self.get_default_field_names(declared_fields, info)
if exclude is not None:
for field_name in exclude:
fields.remove(field_name)
return fields
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
# db匹配创建字段对象
既然 get_field_names返回的字段名集合 必定 小于等于/包含于等于 [字段类型的类变量+ORM表中的字段名] !
那么返回的字段结果中, 若是字段类型的类变量 直接用; 若是ORM表中的字段名 就会db匹配自动创建字段对象!!
class ModelSerializer(Serializer):
def get_fields(self):
declared_fields = copy.deepcopy(self._declared_fields)
model = getattr(self.Meta, 'model')
depth = getattr(self.Meta, 'depth', 0)
if depth is not None:
assert depth >= 0, "'depth' may not be negative."
assert depth <= 10, "'depth' may not be greater than 10."
info = model_meta.get_field_info(model)
# -- 第一部分: 根据Meta中的fields或exclude属性,得到一些 字段名字.
"""
1> field =["name","age","addr"]
提醒: 字段类型的类变量一定包含在里面,还也可以写一些ORM表中的字段名进去!!
里面还可以写啥,db匹配创建字段对象的源码里规定了得写ORM表中的字段名!!
get_field_names返回 ['name','age','addr']
2> field = "__all__"
get_field_names返回 [ser._declared_fields中的字段对象的字段名 + ORM数据表中的字段名"包括id"]
3> exclude = ["name"] get_field_names返回 [相当于 __all__ - "name"]
"""
field_names = self.get_field_names(declared_fields, info)
extra_kwargs = self.get_extra_kwargs() # 这关乎Meta中的extra_kwargs属性.暂且不论.
extra_kwargs, hidden_fields = self.get_uniqueness_extra_kwargs(
field_names, declared_fields, extra_kwargs
)
"""declared_fields 的值假设是 OrderedDict([('name', CharField(source='age'))])
for i in declared_fields:
print(i) # 打印出来的值是 name
"""
# -- 第二部分: db匹配实例化字段对象.
fields = OrderedDict()
for field_name in field_names:
# If the field is explicitly declared on the class then use that.
# 如果字段是在类上显式声明的,那么使用它.
"★★★ 字段类型的类变量直接用!!"
if field_name in declared_fields:
fields[field_name] = declared_fields[field_name]
continue # 除了字段类型的类变量,field_names中的其他值会经历以下的步骤.
# 此行代码中规定了 field_names中除了字段类型的类变量名,只能是ORM表中的字段名!!
# 换个说法: get_field_names方法返回的字段名 小于等于/包含于等于 [字段类型的类变量+ORM表中的字段名] !!
# 具体过程就不分析了.实验下来确实如此!!
field_class, field_kwargs = self.build_field(source, info, model, depth)
# 开始db匹配自动创建字段对象
"""比如: field = "__all__"
ORM表InfoUser中有字段 name = models.CharField(verbose_name="姓名", max_length=32)
又得知匹配关系 ModelSerializer类里的serializer_field_mapping
serializer_field_mapping = {..:..,models.CharField: CharField,..:..}
那么就会自动执行语句 name = serializers.CharField(label='姓名', max_length=32)
“当然创建字段对象,肯定会执行 Field类的__init__方法!!这跟 step1:创建字段对象 一样!”
最后,InfoSerializer中就会多了name这个序列化字段对象!!
★ 敲黑板 verbose_name 对应 label !!!
"""
fields[field_name] = field_class(**field_kwargs)
return fields
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# ★ 分析源码的技巧
这是很重要的思维
我在看源码的过程中,无意的意识到了这个问题. 首先请务必理清楚运行过程的源码结构后,(理清源码结构是为了清楚的看到实例在调用某个方法时的查找顺序.)
# get_fields的返回值
就刚刚的get_fields而言,我想知道最后输出什么?
我可以这样操作:
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["id", 'name',"age"]
def get_fields(self): # -- 重写该方法
res = super().get_fields() # -- 利用super,保证源码的正常运行.
print(res) # -- 在此处打印
return res
get_fields最后输出: “可以看到label是数据库里的verbose_name..”
OrderedDict([
('id', IntegerField(label='ID', read_only=True)),
('name', CharField(label='姓名', max_length=32)),
('age', IntegerField(label='年龄'))
])
★★ 当然,你完全可以用pytcharm的debug模式,打断点.在控制台看这些变量的值!!
(现目前,我不大怎么会用打断点来查看源码的执行流程.或者说,pycharm提供的debug的很多功能我都不明白怎么用.)
内心OS:
其实我很早就知道这个用法,但就是..你知道那种感觉吧.
就类比于,你很早就知道某个道理,但是真正明白得很久.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# _readable_fields的返回值
我想知道Serializer.to_representation类里
fields = self._readable_fields这行语句执行完后, fields里是啥?
方式一: 重写方法.
# -- 数据库表
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
# -- 序列化器类
class UserSerializer(serializers.ModelSerializer):
id = serializers.IntegerField()
name = serializers.CharField()
class Meta:
model = models.UserInfo
fields = ["id", 'name', "age"]
def to_representation(self, instance):
fields = self._readable_fields
print(fields) # <generator object Serializer._readable_fields at 0x7fb37762c5f0>
print(list(fields)) # [IntegerField(), CharField(), IntegerField(label='年龄')]
return super().to_representation(instance)
# -- 视图类
class UserView(APIView):
def get(self, *args, **kwargs):
"""获取数据-序列化-返回"""
instance = models.UserInfo.objects.all().first()
ser = UserSerializer(instance=instance, many=False)
context = {"status": True, "data": ser.data}
return Response(context)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
方式二: pycharm debug模式打断点.
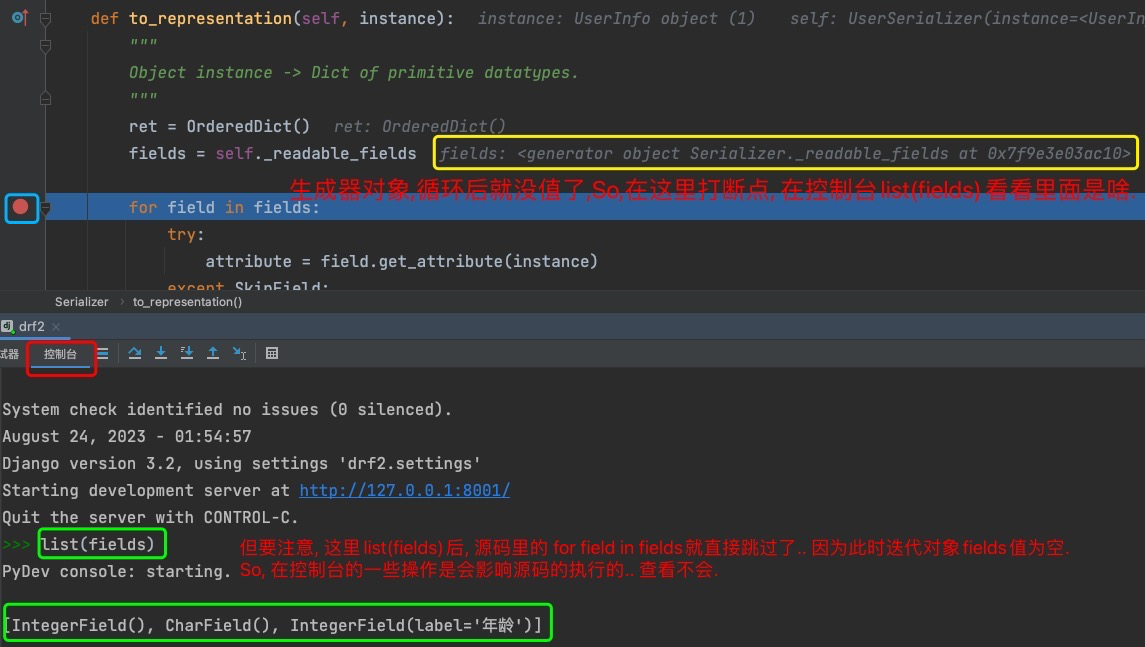
# 右键点查找用法
还有个小技巧, 在我查找bind哪里使用了的时候, 用到啦!!
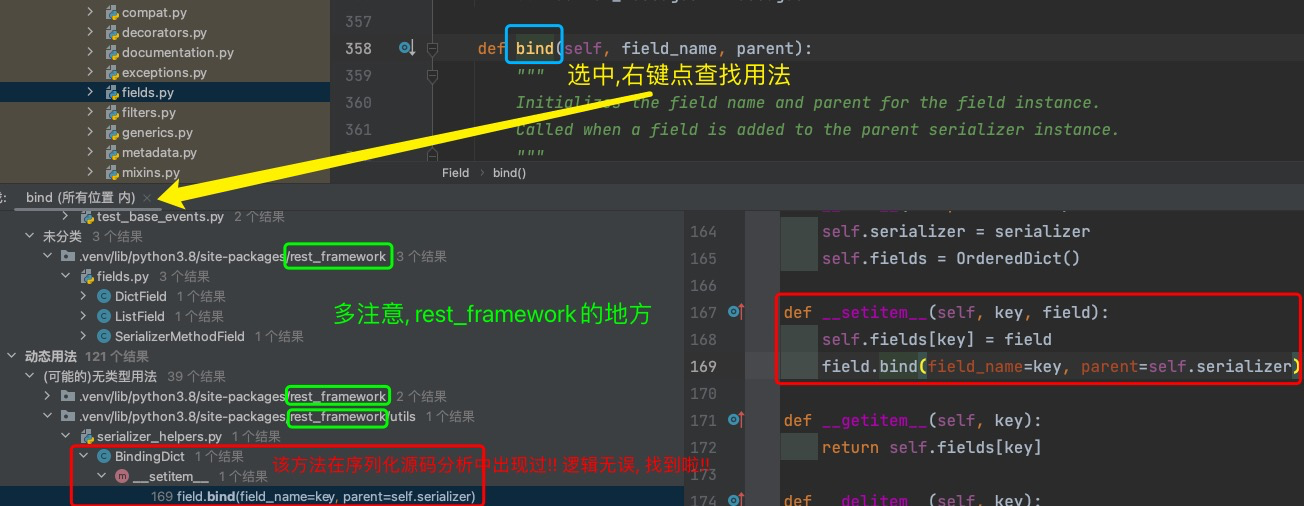
# for field in fields
这里循环的是 所有可序列化的字段对象 !!
关键在于这两个方法 get_attribute、to_representation
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
def to_representation(self, instance):
ret = OrderedDict()
# (◐‿◑) 获取到所有可用于序列化的字段对象!! 前面一大堆就是在分析这一码子事咋实现的,Hhh.
fields = self._readable_fields
"""循环所有可序列化的字段对象. 举个例子
fields ==> <generator object Serializer._readable_fields at 0x7fb37762c5f0>
list(fields) ==> [CharField(source="depart.title"), IntegerField(label='年龄')]
"""
for field in fields:
"""下面两行关键代码,大体逻辑如下:
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
xxx = serializers.SerializerMethodField()
经过,
<UserInfo object>.get_gender_display 拿到了gender在内存中的文本值
<UserInfo object>.depart.title 拿到了跨表后的值
xxx 拿到序列化器类中get_xxx的返回值
"""
# 按照查找关系,最后定位到Field类中的get_attribute方法.
attribute = field.get_attribute(instance)
# eg: ret["depart"] = str(<UserInfo object>.depart.title)
ret[field.field_name] = field.to_representation(attribute)
return ret # 返回的是一个有序字典
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# field.get_attribute
一切尽在源码中
field.get_attribute(instance) 得到的结果 可能是 数据库中字段对应的值、也可能是instance一条记录.
class Field:
_creation_counter = 0
def __init__(self, *, read_only=False, source=None, ...):
self._creation_counter = Field._creation_counter
Field._creation_counter += 1
self.source = source
# These are set up by `.bind()` when the field is added to a serializer!!
self.field_name = None
self.parent = None
def bind(self, field_name, parent):
pass # bind的源码在`ser.fields` 小节就已经阐述了,此处不再赘述.
def get_attribute(self, instance): # self是字段对象,instance是一行数据
"""
字段对象的source_attrs与source是有渊源. 这两属性有何渊源?
在Field里有bind方法,会对source值做处理!!将处理结果放到source_attrs当中! ★ 一些常见的对应关系如下:
- source "字段名" <==> source_attrs ["字段名"]
- sourse "depart.title" <==> source_attrs ['depart','title']
- sourse "get_gender_display" <==> source_attrs ["get_gender_display"]
- source "*" <==> source_attrs []
"""
try:
return get_attribute(instance, self.source_attrs) # 注:get_attribute是fields.py里单独的一个函数.
except (KeyError, AttributeError) as exc:
# 捕获异常,处理后,再向上抛出异常
... ...
raise type(exc)(msg)
# 这个操作很amazing!(⁎⁍̴̛ᴗ⁍̴̛⁎).
def get_attribute(instance, attrs): # 此处的attrs就是source_attrs
"""
- 若 attrs = ["字段名"] ,<UserInfo object>."字段名"
- 若 attrs = ['depart','title'],经过循环,<UserInfo object>.depart.title 就进行了跨表!!
意味着,它可以通过反射一直点点点下去,跨n张表.
- 若 attrs = ["get_gender_display"]
经过循环,<UserInfo object>.get_gender_display,然后判断它是不是可调用对象
是的话,自动加括号执行,<UserInfo object>.get_gender_display()
- 若 attrs = []
直接返回 instance一条记录
"""
for attr in attrs:
try:
if isinstance(instance, Mapping): # Mapping是映射之意
instance = instance[attr] # 没有的话抛出的异常是KeyError
else:
# instance是数据库中的一条记录,So,会执行此行语句
# 若instance中没有attr 那么会抛出异常AttributeError 向上在Field的get_attribute方法中会捕获到
instance = getattr(instance, attr)
except ObjectDoesNotExist: # 我不是很明白这里写个ObjectDoesNotExist有何用?不清楚也不影响大体的逻辑.
return None
if is_simple_callable(instance): # 若是可调用的对象,会自动加括号执行.
try:
instance = instance()
except (AttributeError, KeyError) as exc:
raise ValueError('...')
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# field.to_representation
一切尽在源码中
务必注意下 SerializerMethodField 的源码!
class IntegerField(Field):
def to_representation(self, value):
return int(value)
class CharField(Field):
def to_representation(self, value):
return str(value)
class SerializerMethodField(Field):
# - method_name=None 其实可以自己绑定一个方法,不用它默认指定的方法名!
def __init__(self, method_name=None, **kwargs):
self.method_name = method_name
kwargs['source'] = '*' # -- 特别注意此处,在Field.bind方法中,‘*’这个值决定了走哪个判断.
kwargs['read_only'] = True
super().__init__(**kwargs)
def bind(self, field_name, parent):
# The method name defaults to `get_{field_name}`.
if self.method_name is None:
self.method_name = 'get_{field_name}'.format(field_name=field_name)
super().bind(field_name, parent) # -- 还是会调用Field中的bind.
# 此处的value 是instance一条记录 ; self.parent 是序列化器类的实例 ; self.method_name是指定的方法
def to_representation(self, value):
method = getattr(self.parent, self.method_name)
return method(value)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 注意点
一点点小思考!也算是上面某些源码过程的一点回顾吧. 单独拎出来再说一说!
# continue
序列化器类中随便定义了
xxx = serializers.CharField()
因为 根据对应关系寻找并实例化字段对象的操作/db匹配创建字段对象 与它无关.
所以 哪怕该字段对象在数据库中对应不上, 在ser.get_fields获取所有字段对象的过程中也不会报错.
这么说的来源于源码.里面有个continue.
for field_name in field_names:
if field_name in declared_fields:
fields[field_name] = declared_fields[field_name]
continue
# -- 往下才是匹配数据库实例化字段对象的操作
# ... .. ..
2
3
4
5
6
什么时候报错呢?
在ser.data 对数据进行序列化的过程中, 会循环所有 可序列化的字段对象 (可序列化是前提) , 在循环体中会有这样一行代码:
attribute = field.get_attribute(instance)
因为数据库中没有xxx字段. 所以instance.xxx 报错. (instance对象指的是数据库表中的一条数据)
内心OS, 该思考的起源来于, 实现验证功能时, 随便在序列化器类里写了username字段, 该字段数据库里也没有啊..
也许你会说, 验证跟数据库无关, 但你知道吧, 就那种懵懂的感觉. 又想到了序列化过程.. 究竟咋回事. 就重新再研究了下源码.
# SerializerMethodField
序列化的自定义字段绑定的方法的value参数为啥是数据库中的obj/一条记录, 就得根据源码弄明白它是如何执行的..
class UserSerializer(serializers.ModelSerializer):
yyy = serializers.SerializerMethodField()
def get_yyy(self, obj):
return "Hello World"
class Meta:
model = models.UserInfo
fields = ["yyy"]
2
3
4
5
6
7
8
9
分析过程阐述的很简漏, 大概就是那个意思, 按照执行过程来, 错不了.
class SerializerMethodField(Field):
# - method_name=None 其实可以自己绑定一个方法,不用它默认指定的方法名!
def __init__(self, method_name=None, **kwargs):
self.method_name = method_name
kwargs['source'] = '*' # -- 特别注意此处,在Field.bind方法中,‘*’这个值决定了走哪个判断.
kwargs['read_only'] = True
super().__init__(**kwargs)
def bind(self, field_name, parent):
# The method name defaults to `get_{field_name}`.
if self.method_name is None:
self.method_name = 'get_{field_name}'.format(field_name=field_name)
super().bind(field_name, parent) # -- 还是会调用Field中的bind.
# value 是instance一条记录 ; self.parent 是序列化器类的实例 ; self.method_name是指定的方法
def to_representation(self, value):
method = getattr(self.parent, self.method_name)
return method(value)
依旧的,这个字段对象是序列化类的类变量,所以 还是会经历那个continue!!进而跳过后面db匹配实例化的操作.
接着循环所有的字段对象.照着执行流程慢慢理不难.注意两处地方.
- 因为Serializer的bind函数中这行语句, if self.source == '*': self.source_attrs = []
- 所以 那个很amazing的一直通过反射跨表的那个函数 调用它时,参数attrs是[],所以这个amazing的函数直接返回的是instance.
# - 这个操作很amazing!(⁎⁍̴̛ᴗ⁍̴̛⁎).
def get_attribute(instance, attrs): # attrs = []
for attr in attrs:
if isinstance(instance, Mapping):
instance = instance[attr]
else:
instance = getattr(instance, attr)
if is_simple_callable(instance):
instance = instance()
return instance
- So,SerializerMethodField里的to_representation的value参数是instance啦!
也就能解释自定义字段对象绑定的那个方法的value参数是一个数据对象,代表的是数据库的一条记录.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# step4: 序列化 - 多条
ser.data 触发序列化
在step3中我们知道创建的序列化器类的对象ser的类型有两种.
1> 当前序列化器类InfoSerializer类,该类的实例化对象. -- 对应many=False 单条数据
2> ListSerializer类的实例化对象 -- 对应many=True 多条数据该小节 将针对 多条数据 的序列化过程进行讨论.
跟 上面 "序列化-多条" 部分的执行序列化过程 几乎一模一样!! 只不过多了一个循环罢了.
你细品这两句话: 不管单条还是多条,序列化都是Serializer里的to_representation在做!!
也就是说, 多条数据时,就是同一个InfoSerializer()实例在对多条数据进行序列化操作!!
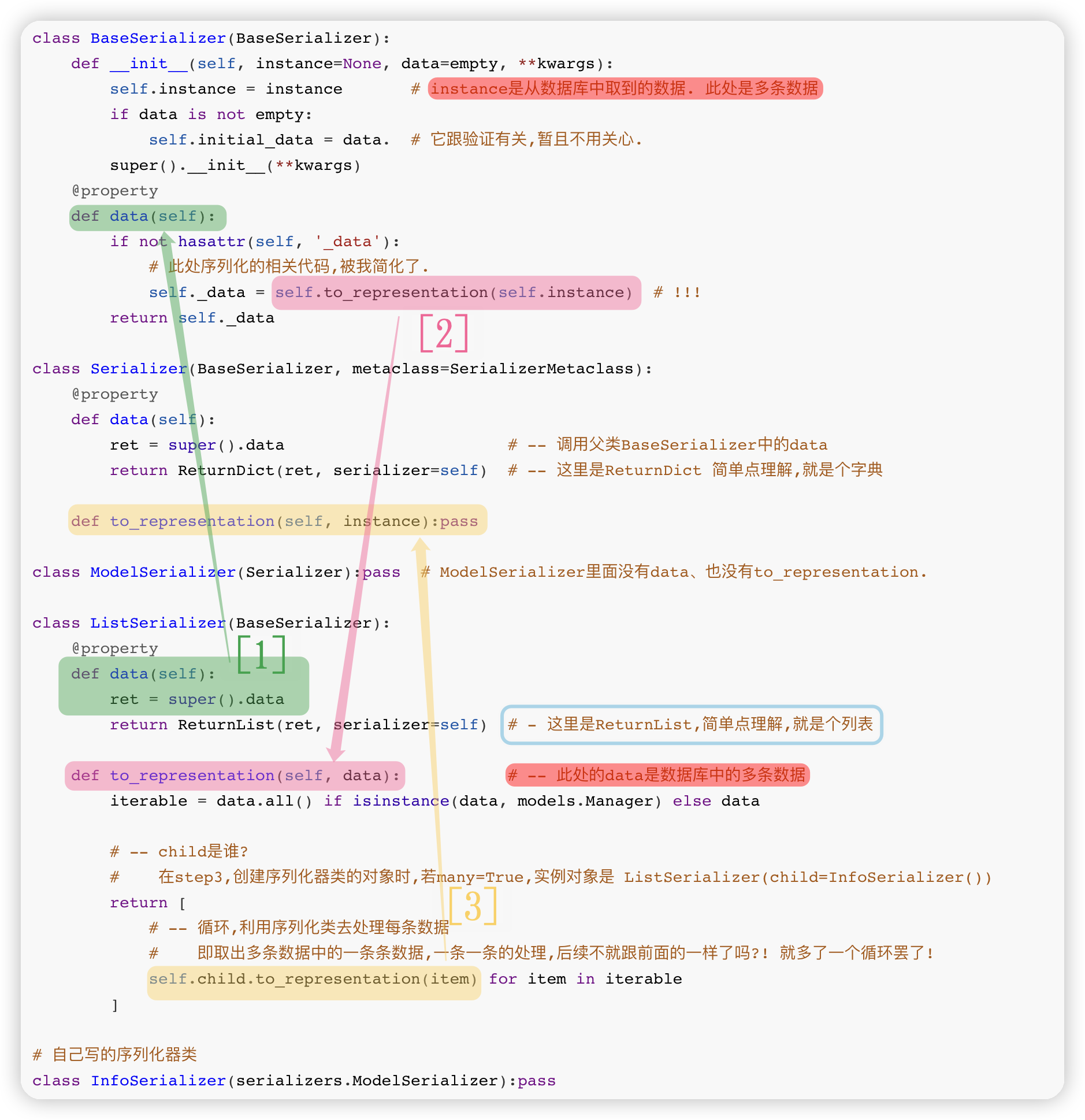
经历前面三步后,要清楚的知道
-情况1- ser = InfoSerializer(instance=instance, many=False)
type(ser) --:> <class 'api.views.UserSerializer'> 返回InfoSerializer类实例化对象!
-情况2- ser = InfoSerializer(instance=queryset, many=True)
type(ser) --:> <class 'rest_framework.serializers.ListSerializer'> 返回ListSerializer类实例化对象!
(´▽`) 开始ser.data序列化
<单条数据>. 从InfoSerializer开始找data
- 先执行BaseSerializer里的data,里面 self._data = self.to_representation(self.instance)
- 接着执行Serializer里的to_representation
<多条数据>. 从ListSerializer开始找data
- 先执行ListSerializer里的data,因为super,接着执行BaseSerializer里的data
关键代码依旧是 self._data = self.to_representation(self.instance)
- 但该to_representation用的是ListSerializer里面的to_representation
ListSerializer里面的to_representation
for 单条数据 in 多条数据:
每条数据都用 自己写的序列化器类InfoSerializer来进行序列化
(InfoSerializer.to_representation调用的是 Serializer里的to_representation)
每条数据的序列化结果都放到同一个列表里
★ 综上,不管单条还是多条,序列化都是Serializer里的to_representation在做!!
多条数据时,就是同一个InfoSerializer()实例在对多条数据进行序列化操作!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25