 开篇
开篇
# 机器学习是什么?
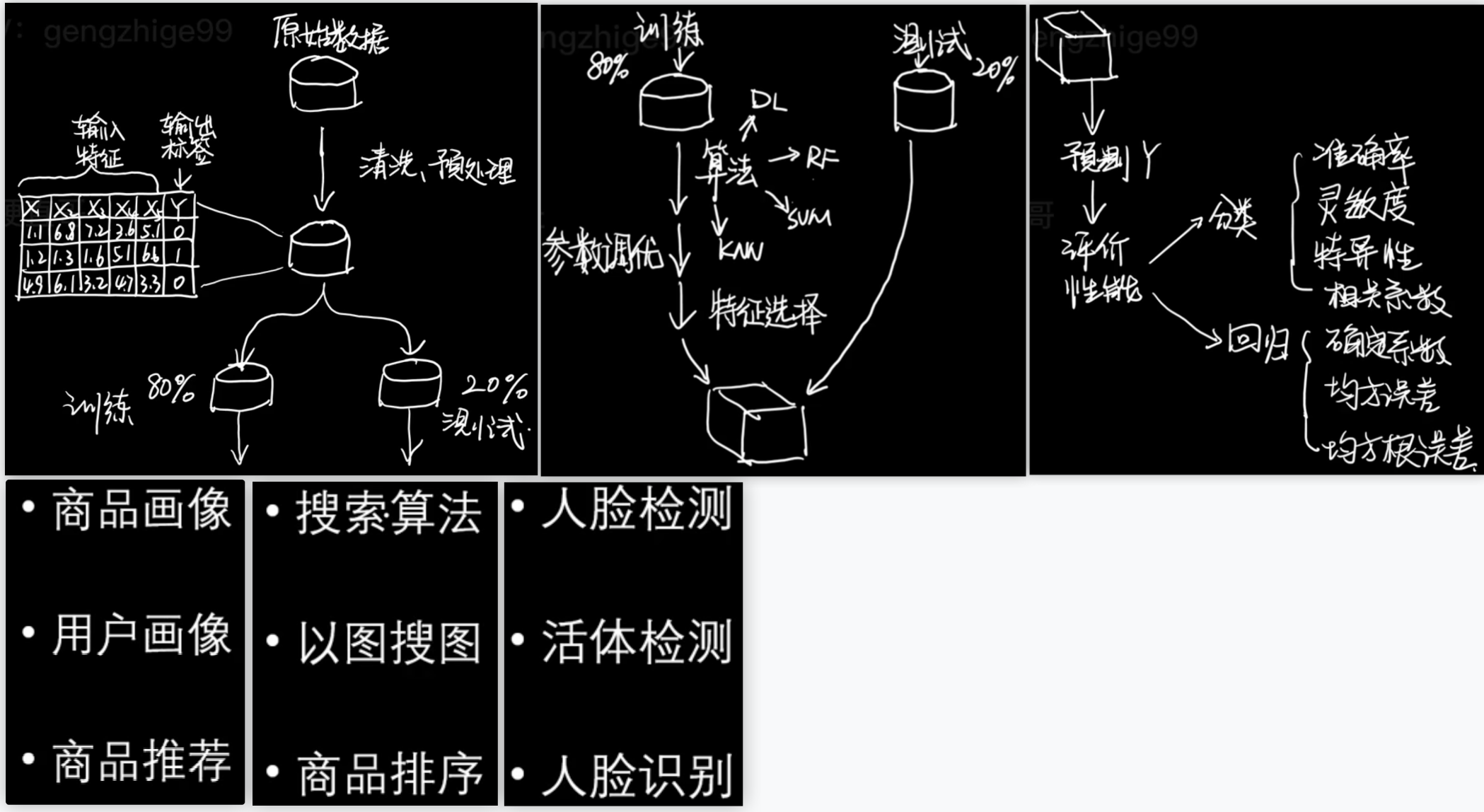
# 机器学习概述
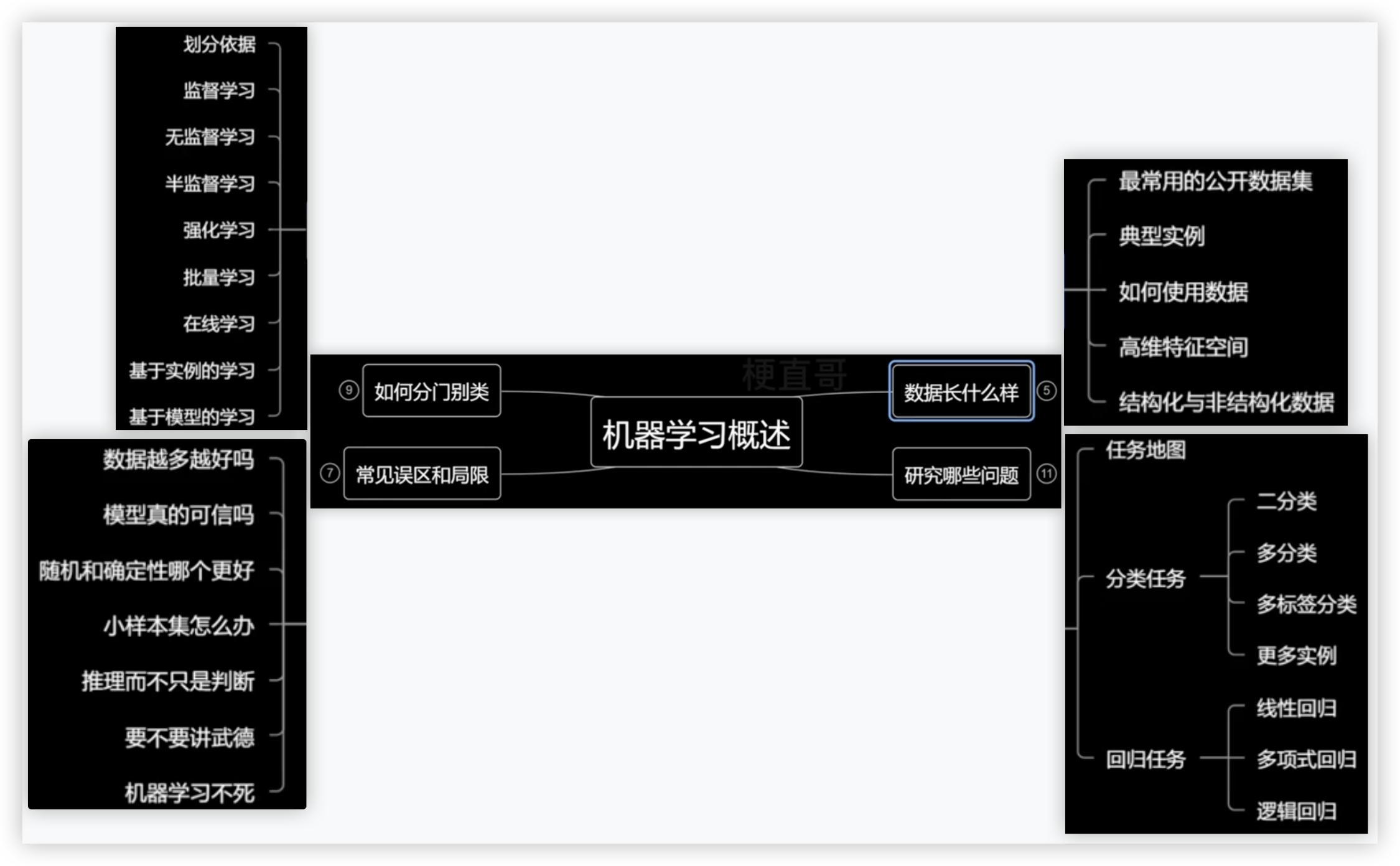
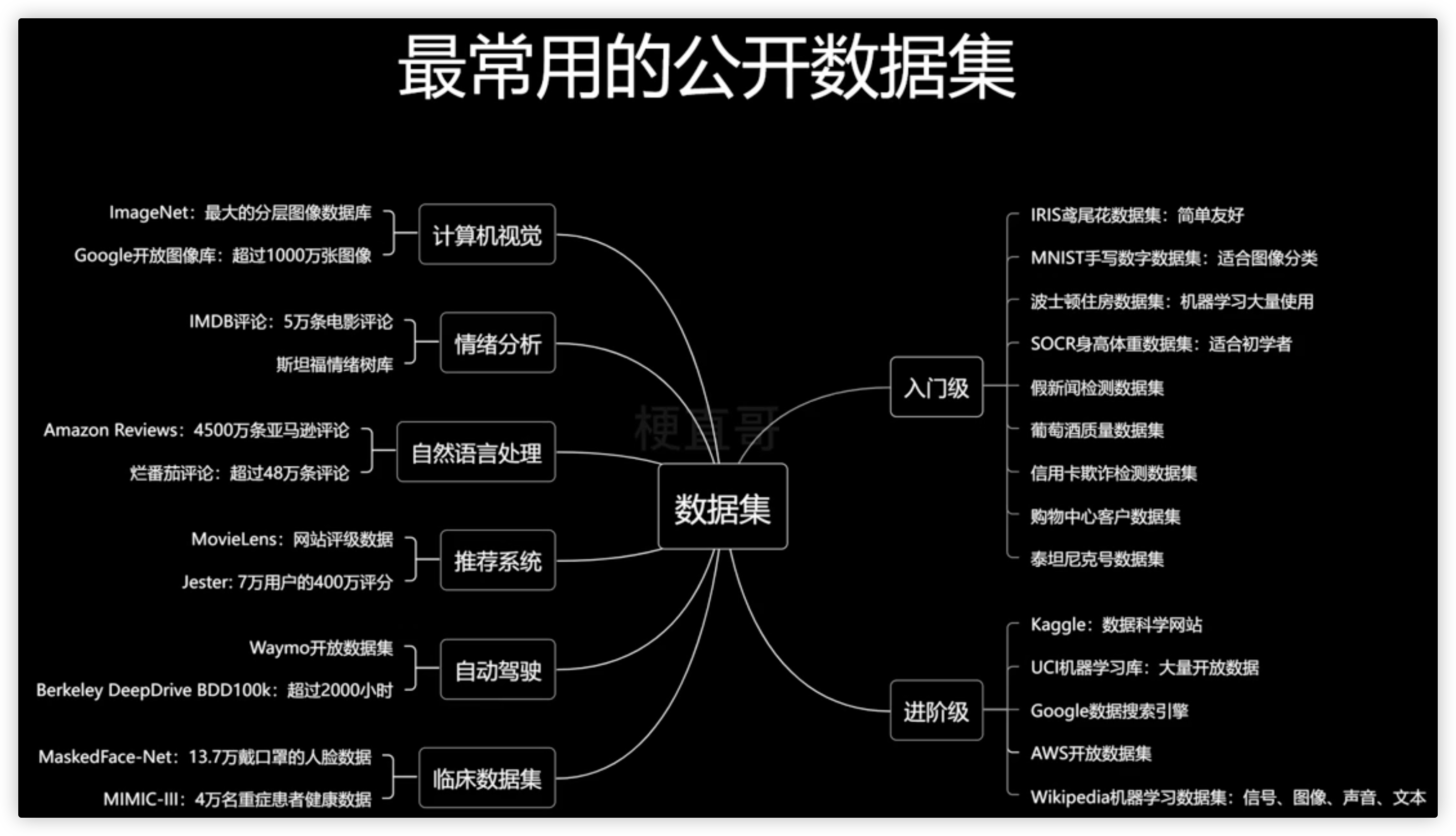
# 数据集在哪
# 数据集常用概念
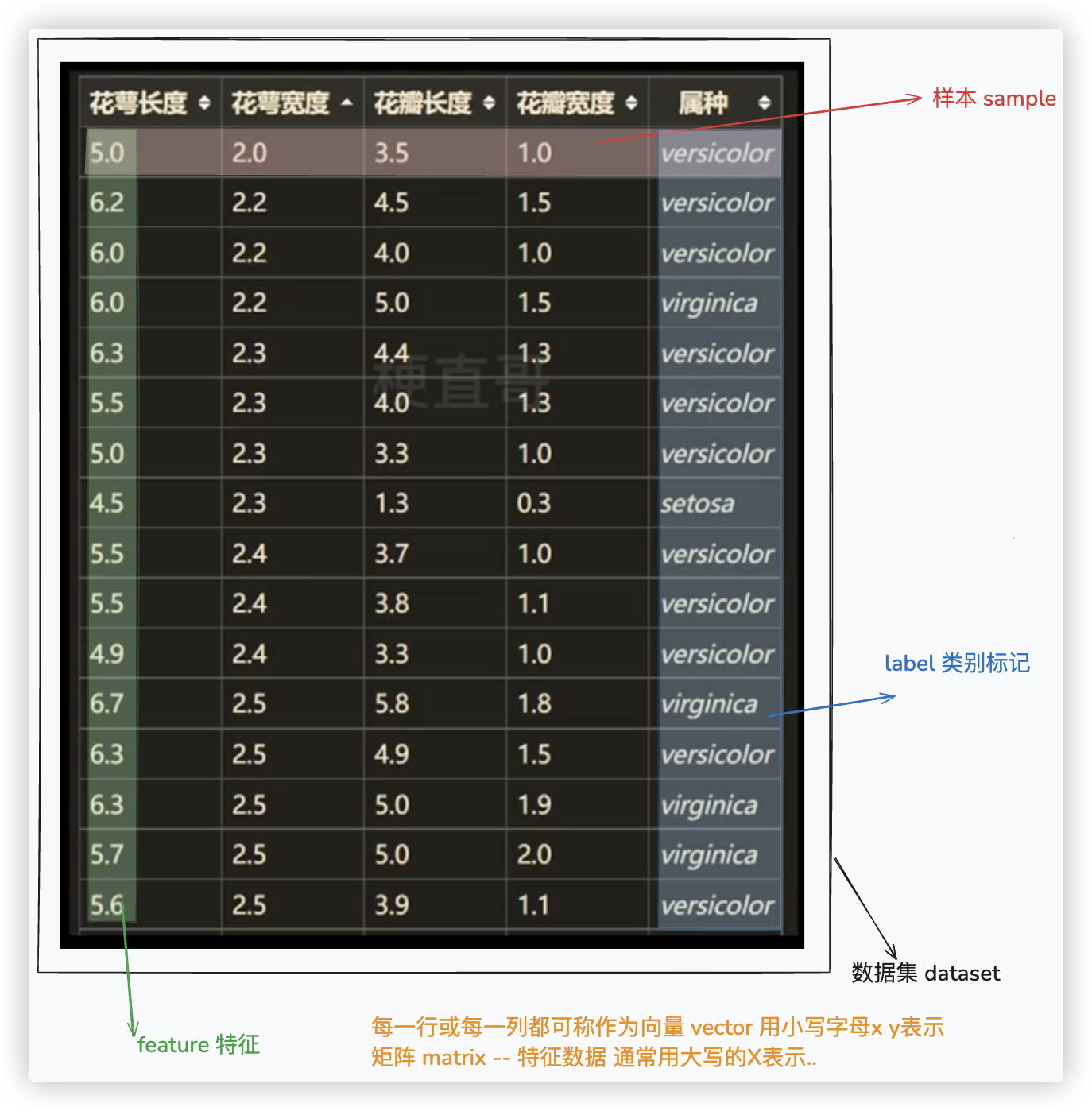
上图表格中的就是鸢鸟花的结构化数据, 声音、视频之类的是非结构化数据..
可以通过一些方法将非结构化数据转换为结构化数据.
1
2
2
# 机器学习干什么/主要任务
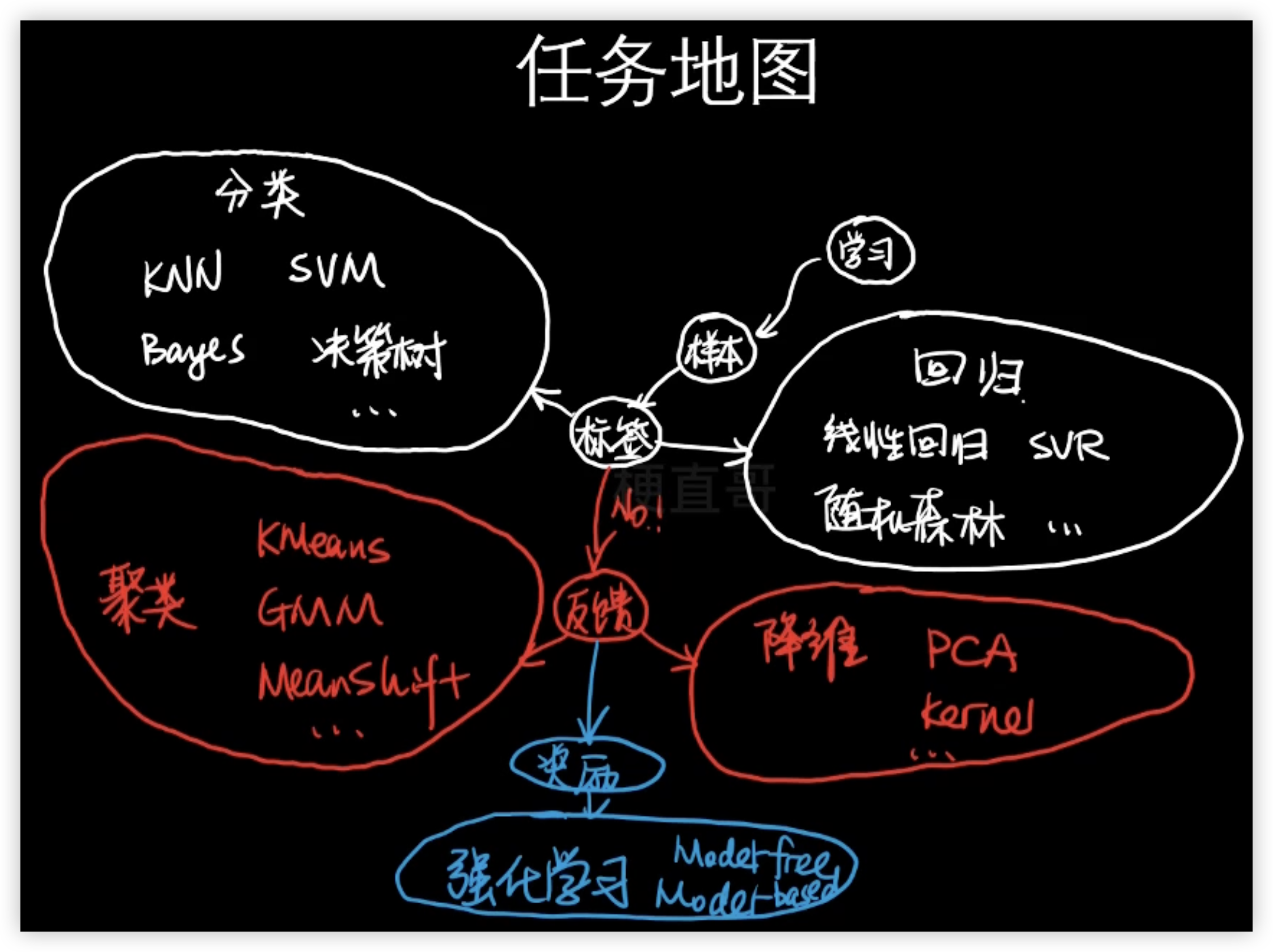
# 分类问题 Classification
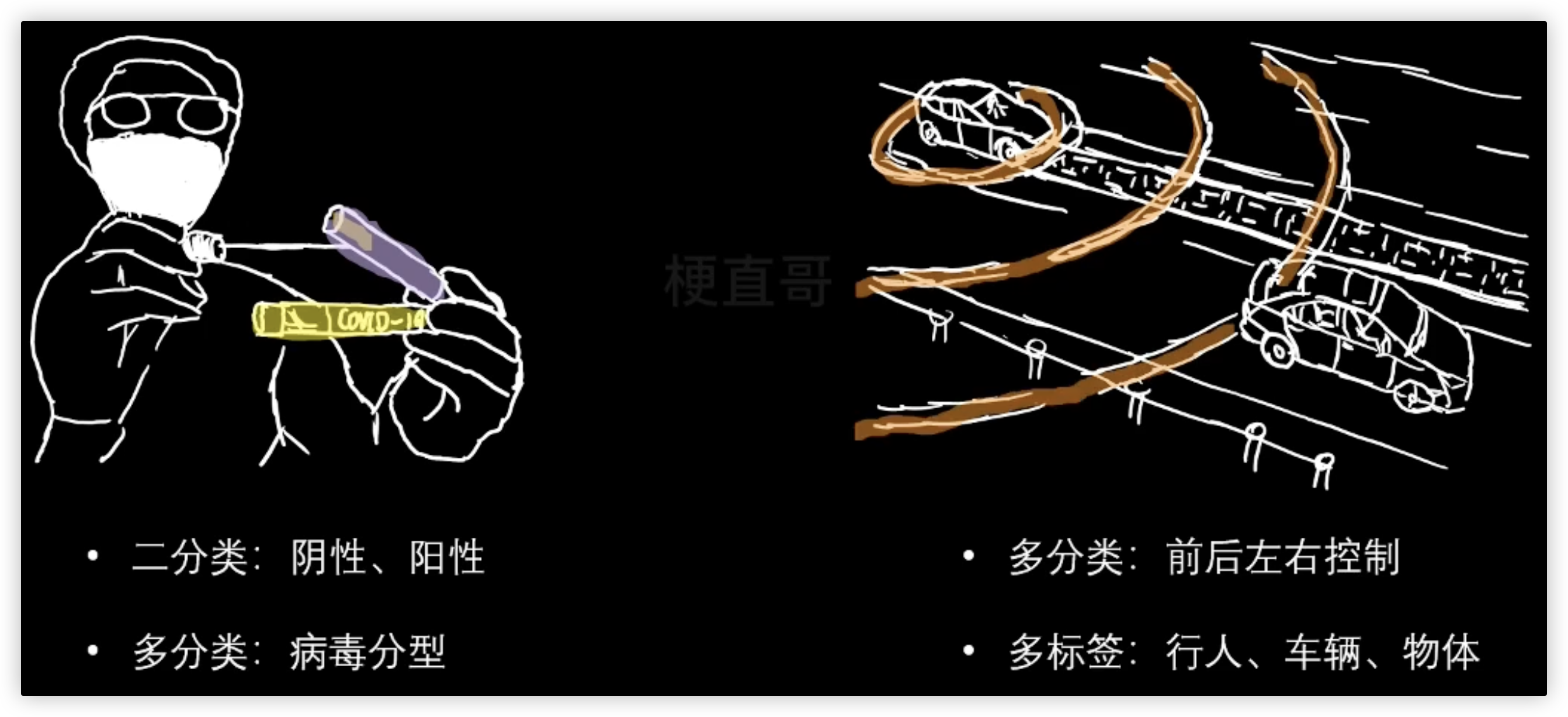
- 二分类 y = kx + b y的取值范围 0 1 eg:垃圾邮件的分类 即是否是垃圾邮件
- 多分类 y = f(x) y的取值范围 0-n eg:手写字体识别的分类
- 多标签分类
- 可简单理解为,多级或二级的分类问题 如-先判断它的类别,在判定类别的基础上再判断它的颜色!
- 还可以理解为,n个二分类问题
> 二分类、多分类、多标签分类之间的界限很多时候没有那么的明显,可以互相转化!
eg: 核酸检测 二分类-阴性、阳性 多分类-病毒分型
无人驾驶 二分类-是否需要刹车 多分类-前后左右控制 多标签-用摄像头去区分前方不同的物体时
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 回归问题 Regression
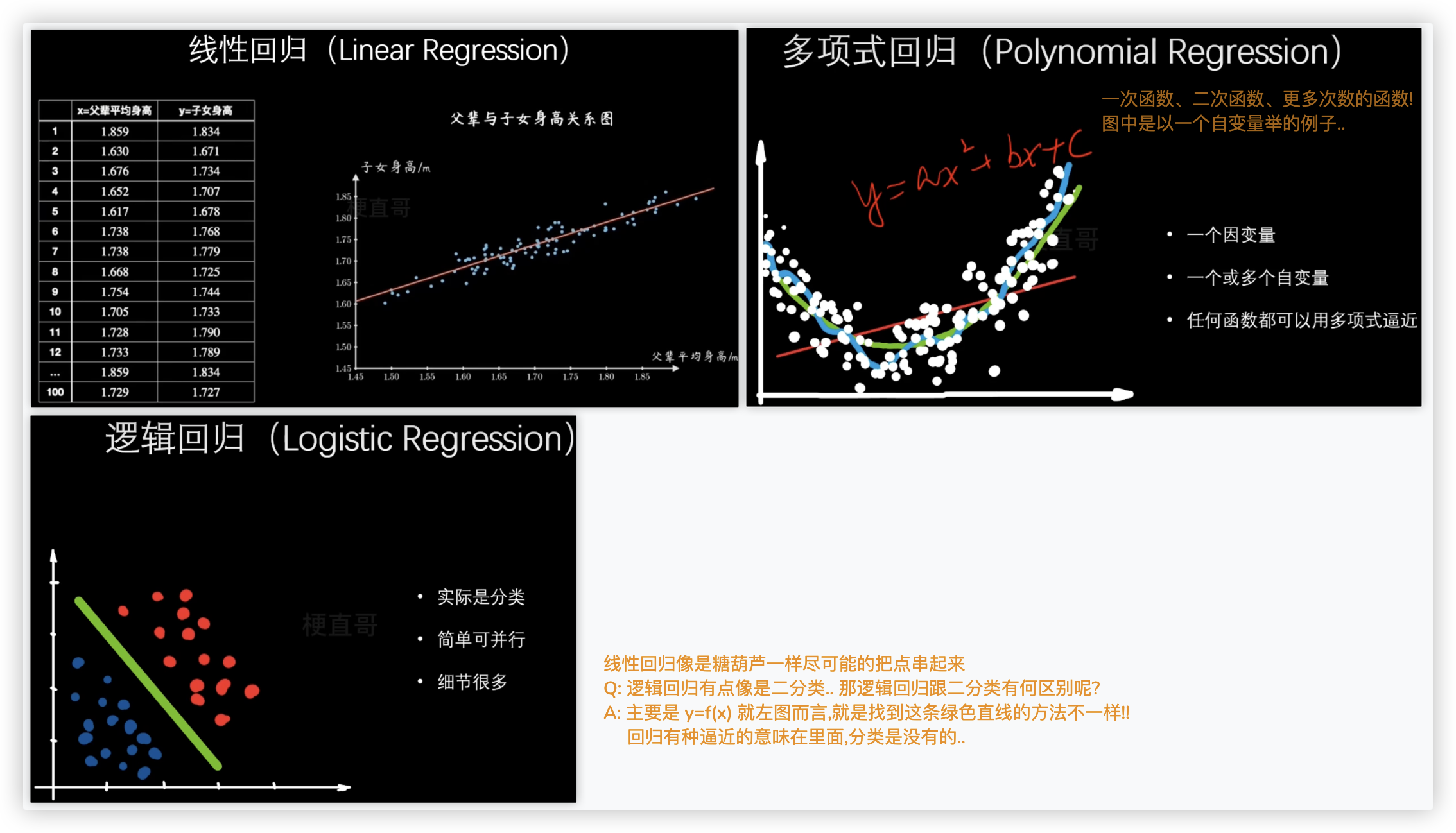
re回归+gression行走=让数据回归本来的规律 也就是作预测
往深的理解,分类和回归模型本质都是一样的
分类模型可以将回归模型的输出离散化; 回归模型也可以将分类模型的输出连续化..
eg: 预测明天气温多少度 就是典型的回归问题..
预测明天是阴、晴、下雨 就是典型的分类问题!!
1
2
3
4
5
6
2
3
4
5
6
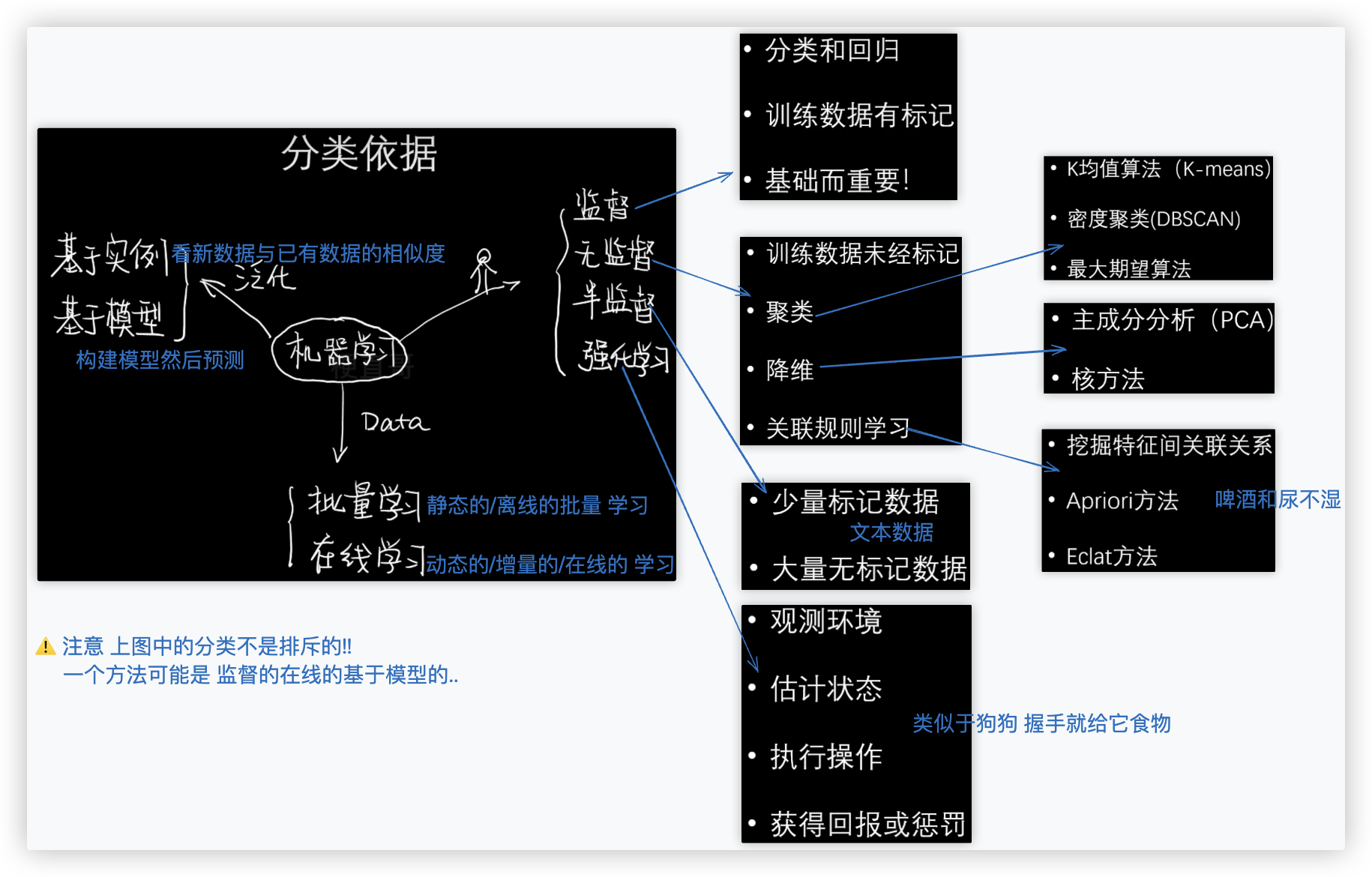
# 监督学习(分类、回归)
分类和回归在机器学习中都被统称为监督学习.
因为这两种任务都是从有类别标记的训练数据中来推导出预测函数 y=f(x)
PS:类别标记/标签/标签
除了监督学习,还有非监督学习、强化学习.暂且不表.
1
2
3
4
5
2
3
4
5
# 机器学习的种类
# 机器学习误区和局限
1. 数据越多越好吗?
- 数据的质量: 比如数据集都是白人女性的,训练出的模型对黑人女性是不靠谱的!
- 多不一定准确: 智能驾驶的视觉只能识别已知的物体,数据再多也不能识别未知的物体.
2. 模型真的可信吗?
- 可解释性是目前机器学习所面临的问题之一.
尤其是以神经网络为代表的深度学习往往是一个黑盒子.
扔进去数据得到一个模型,哪怕效果很好,但你并不知道中间发生了什么.应用的领域就变少了,因为你不知道成功或失败的原因!!
- 因而浅层的机器学习算法有更好的可解释性!应用范围更广!
3. 随机和确定哪个更好?
- 随机与确定之间的平衡往往是最好的,比如先告知它牛顿三定律,在此基础上开始随机.
4. 小样本集怎么办?
- 机器学习适合大数据;很多问题天然小数据;小样本学习是挑战也是机会!
5. 推理而不只是判断.
- 机器学习尚在判断阶段,像人类的抽象思维和逻辑推理远未实现
- 数学依然是汪洋大海 机器学习知识统计学加上计算机基础的小结晶.
深度学习是有局限性的,它本质上是几何空间的变换; 很多问题用浅层的机器学习效果更好!! 机器学习不死!!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 四大工具
# Anaconda
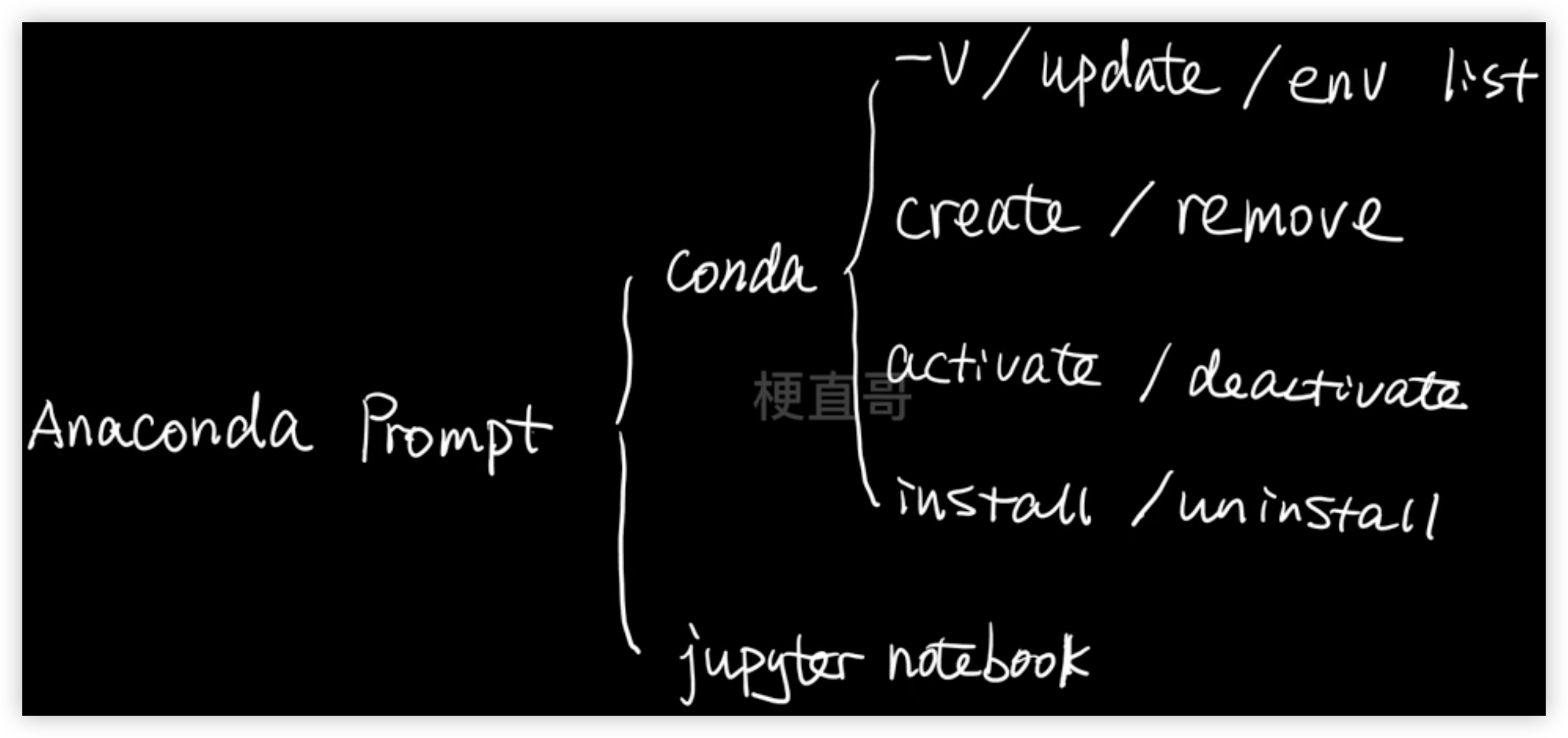
conda -V Anaconda的版本
conda env list 有哪些虚拟环境
conda list 该虚拟环境下安装了哪些包
conda create -n ML python 创建虚拟环境
conda activate ML 切换激活虚拟环境
conda deactivate 退出虚拟环境
conda remove -n ML --all 删除虚拟环境(注:需先退出这个虚拟环境,再删除它)
conda search numpy 查看要下载的相关的包的版本有哪些
conda install numpy 下载相关的包
conda uninstall numpy 删除相关的包
conda install jupyter notebook
jupyter notebook 启动它
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# Jupyter
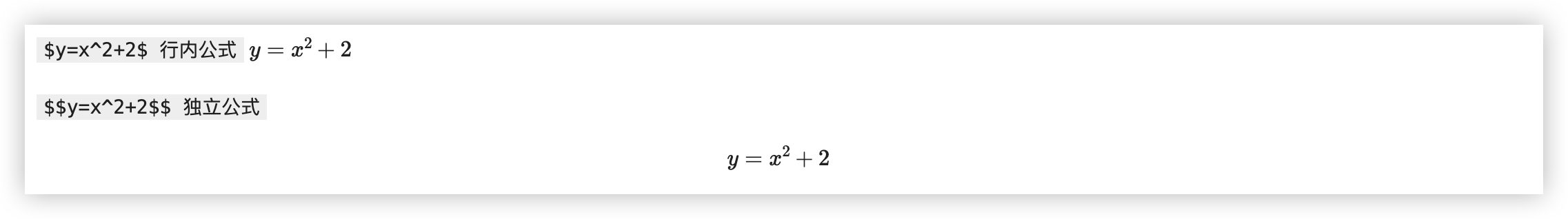
# Numpy
https://github.com/Gengzhige/Machine-Learning/tree/main/Chapter-03
# matplotlib
https://github.com/Gengzhige/Machine-Learning/tree/main/Chapter-03