 ★一切从简
★一切从简
在前面, 我们总结了panda相关的很多很多知识点..
哪怕当时理解记住了,不经常用的话, 随着时间的推移也会忘记..
回头复习也会花费很多时间.. 单纯的记忆过程也是很枯燥很痛苦不快乐的,违背人性..
为了解决这一问题,该篇博文总结了pandas学习过程中 [练习的项目] 中所涉及的知识点..
要习惯八二原则,在以后的实战中,用自己已经掌握的知识去解决80%的问题, 并推动自己去学习新知识解决剩下的20%问题..
(其实,最核心的要素是 内驱力,执行力..
★ 环境:
python3.9
jupyter==1.1.1 numpy==1.26.4
pandas==1.4.4 jieba==0.42.1 matplotlib==3.9.2 seaborn==0.13.2 plotly-express==0.4.1
2
3
4
# 创建
Series对象和DataFrame对象的创建都有三种方式: 列表、numpy数组、字典!!
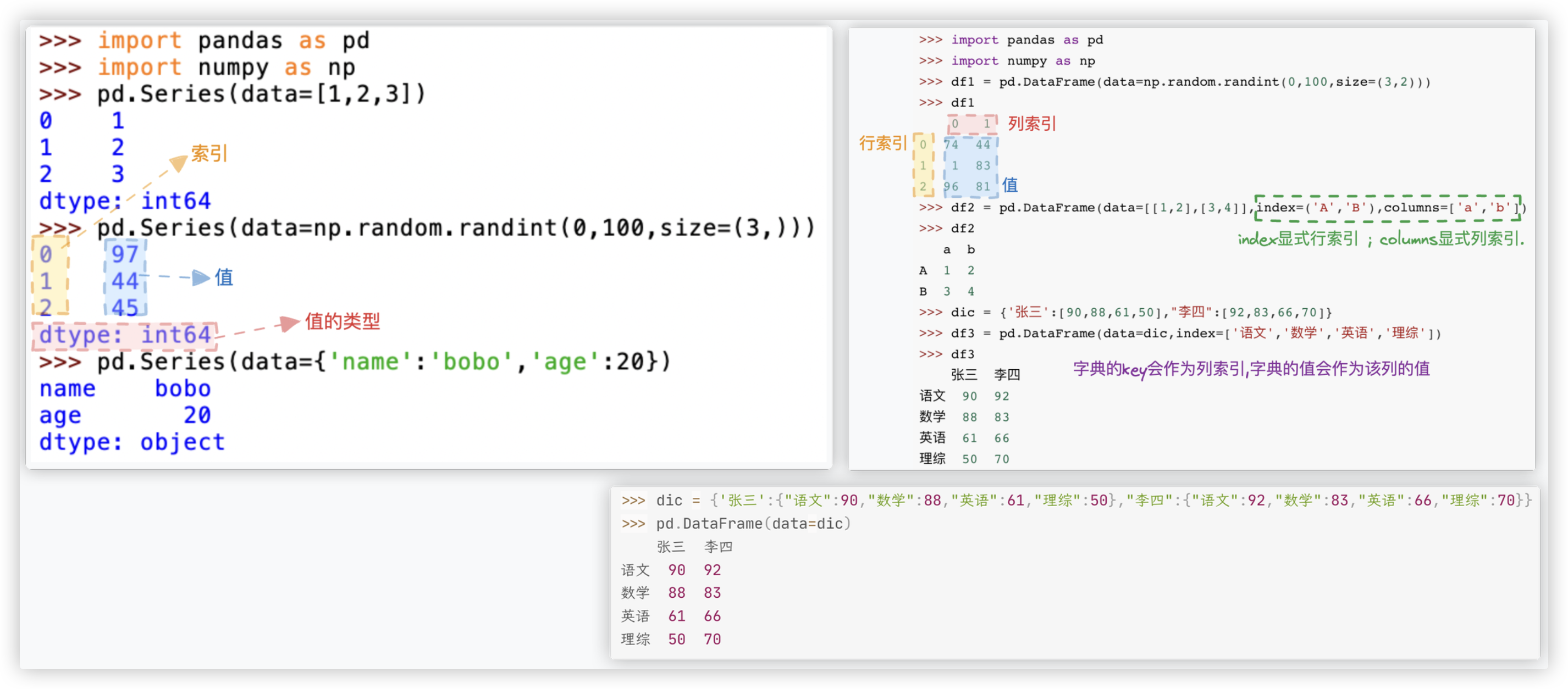
# Series
★ 关键词:
Series对象组成元素、数组运算、bool数组充当索引、索引取值、切片后被赋值会改变原数组、调用数学函数
返回去重后的结果、返回去重后元素的个数、返回元素出现的次数、空值判断、非空判定、保留空值、过滤空值
最小值的索引、整体下移、窗口、通道、长度、索引、值、头n个、尾n个
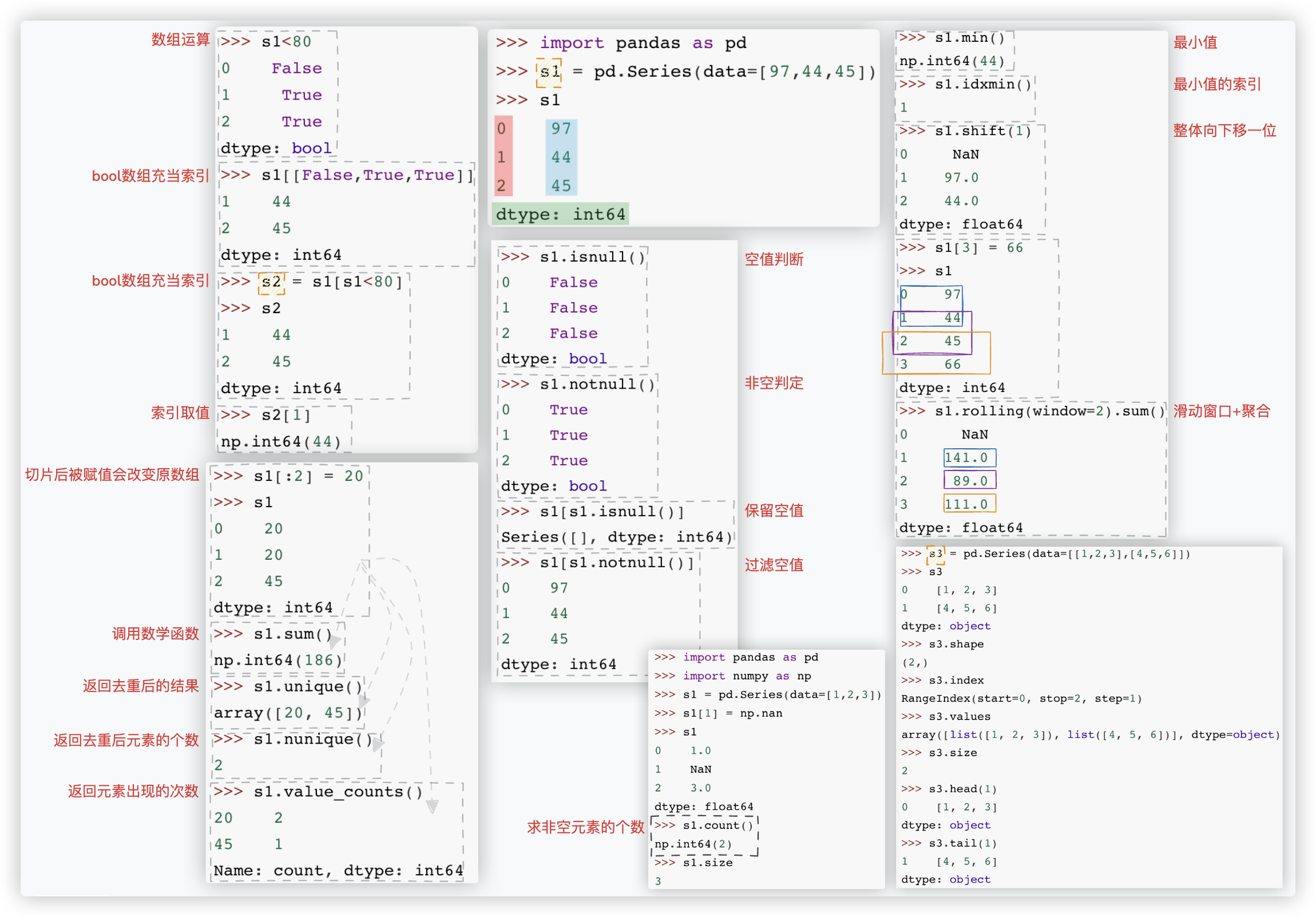
补充:
s1.cumsum() 累加和. eg - 计算销售额的累积占比.
s1.round(2) 保留小数点后两位.
★ 关键词:
Series对象的.to_list()、.to_dict()、.str 、.map(func)、.astype(int)
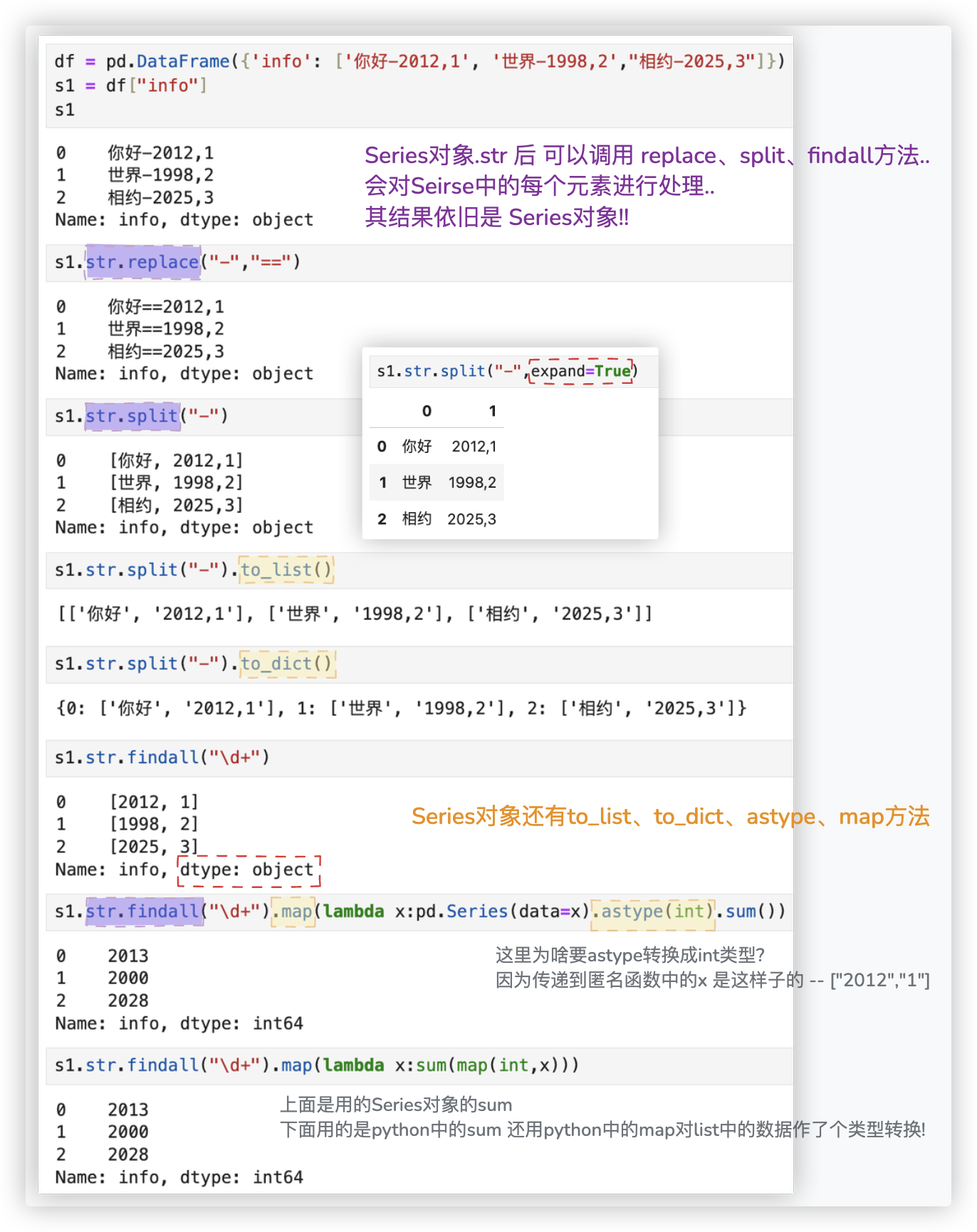
# DataFrame
- 组成: 行索引 index + 列索引 columns + 值 values.
- DataFrame把它看作是一个字典
{'列索引A':{'行索引b':值,'行索引p':值},'列索引B':{'行索引b':值,'行索引p':值}}外层字典的value值/里层的字典 就是一个Serise对象, 多个Serise对象使用共同的索引. 基于这个理解.df['debt']取列 ;df['debt']=2有则改,没有则新增列 就很容易想通啦!
# 取行和列
注意哈 -- df['A'] 取列; df[:-1] 取行; df[0] 取列,仅隐式索引时使用

PS: iloc适配下标索引,loc适配显式索引,并且loc中使用显式索引切片是包含最后一个的!
"""
一点补充
"""
ex = df.columns != 'Y house price of unit area' # array([ True, True, True, True, True, True, False])
feature = df.loc[:,ex] # ★★★ 取除了标签列的其它列 也可以 df.iloc[:,:-1]
2
3
4
5
# 对单列和多列赋值
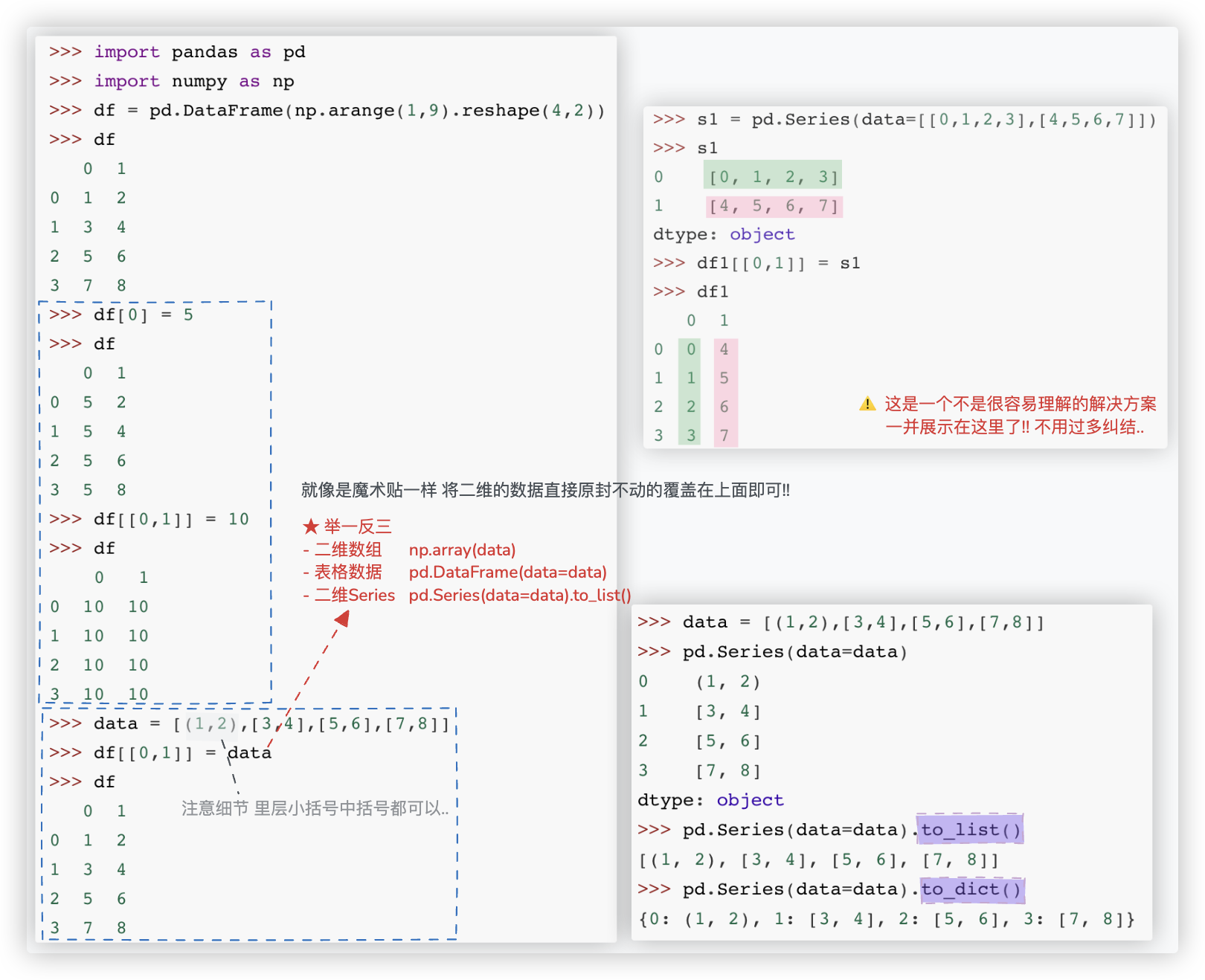
# 对某列的Nan值赋预测值
# ret array([0.18, 0.16, 0.24, ..., 0.16, 0.14, 0. ])
data.loc[data['MonthlyIncome'].isnull(),'MonthlyIncome'] = ret
2
# bool取True对应的行
>>> df = pd.DataFrame(np.arange(1,9).reshape(4,2))
>>> df
0 1
0 1 2
1 3 4
2 5 6
3 7 8
>>> df1[1] > 4
0 False
1 False
2 True
3 True
Name: 1, dtype: bool
>>> df1[1][df1[1]>4]
2 6
3 8
Name: 1, dtype: int64
>>> df1[df1[1]>4] # 取True对应的那些行
0 1
2 5 6
3 7 8
>>> df1[[False,False,True,True]]
0 1
2 5 6
3 7 8
>>> df1[~(df1[1]>4)] # ~取反
0 1
0 1 2
1 3 4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 数据清洗/预处理
- df.shape
- df.info()
- 列名不符合规范的,可以改一下(该操作是可选的 - 详看后面的"索引替换"小节内容
- 看类型
- 根据需求转换成时间类型
- 根据需求对字段进行扩展,比如:提取月份和年份等操作 - 详看后面的"时间序列"小节内容
- 像ID字段,为了聚合时不运算它,将其转换成字符串类型或直接删除
- 缺失值/空值 清洗 > 删除或者填充
- 重复值清洗
- 异常值筛选
- 数值型数据 > df.describe() 初步看下有无异常值、画箱型图
- 非数值型数据 > 查看object类型的列有多少个不同元素组成
将object类型转换为category类型(可选)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
展开说一下:
# 查看字段类型并转换
■ 看是否有空值和每列的数据类型
df.shape
df.info()
df.dtypes # 也可以快速查看每列的数据类型
■ 转换成时间类型数据
df['order_dt'] = pd.to_datetime(df['order_dt'], format="%Y%m%d")
df['month'] = df['order_dt'].astype('datetime64[M]')
■ 将object类型的字段全部转换成category类型
category_columns = df.select_dtypes(include=['object']).columns.to_list()
df[category_columns] = df[category_columns].astype('category')
■ 像ID字段,为了聚合时不运算它,将其转换成字符串类型或直接删除
df['EmpID'] = df['EmpID'].astype(str)
df.drop('EmpID', axis=1,inplace=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
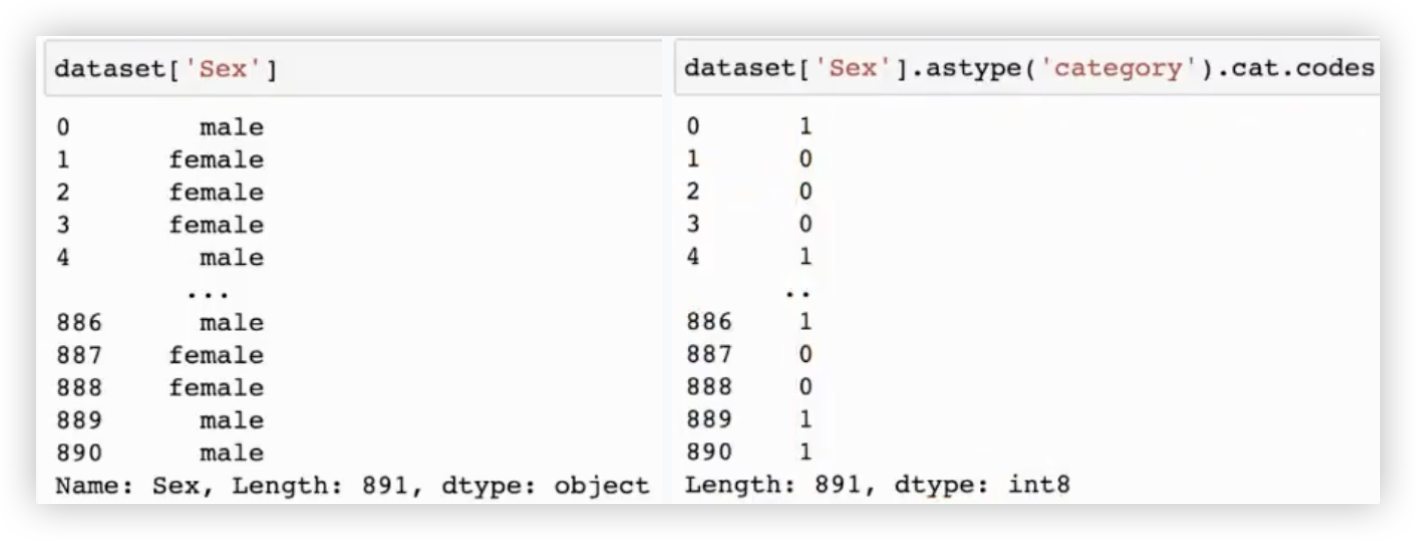
补充: 何为category类型?
Pandas中的category数据类型是一种特殊的数据类型,用于处理具有有限且固定数量的可能值(类别)的数据.
这种数据类型在统计学中被称为分类变量. 与Python中的原生类型不同, category是Pandas特有的类型. 该类型具备如下优势:
- 内存效率:
对于重复值很多的字符串列, 使用category类型可以大大减少内存占用.
这是因为category类型在内部使用整数编码来表示类别,而不是存储每个字符串的值.
- 提高性能:
某些操作在category类型上执行速度更快,因为Pandas对这些操作进行了优化.
例如,对分类数据进行排序、过滤等操作时, Pandas可以利用整数编码的优势来提高性能.
2
3
4
5
6
7
8
# 查看统计信息,处理异常
# 数值型
■ 根据数据统计描述.查找方差为0的列!! > 某列方差为0,证明该列的值都是一样的,携带的信息量少,该列对分类没啥作用.
desc_df = df.describe()
zero = desc_df.loc['std',:] == 0
zero[zero].index.to_list() # 方差为0的列名 ['StandardHours']
# 利用去重验证方差为0的StandardHours列是否为一样的值
df['StandardHours'].nunique()
# 后续处理: StandardHours列为常数列,对分析没有用,可以直接删除.
df.drop('StandardHours', axis=1, inplace=True)
2
3
4
5
6
7
8
9
10
根据箱型图查看每一列离散值占比
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def check_outliers_and_proportion(df, columns, lower_factor=1.5, upper_factor=1.5):
"""
检查给定列的异常值,并计算离群值的占比.
参数:
- df: pandas DataFrame,包含数据。
- columns: list,列名的列表,表示需要检查的列。
- lower_factor: 异常值下限系数,通常为1.5,表示低于此范围的数据为异常值.
- upper_factor: 异常值上限系数,通常为1.5,表示高于此范围的数据为异常值.
返回:
- 每列的异常值占比
"""
result = {}
for column in columns:
# 计算Q1、Q3和IQR
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
# 计算异常值上下限
lower_bound = Q1 - lower_factor * IQR
upper_bound = Q3 + upper_factor * IQR
# 计算异常值的数量
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]
outlier_count = len(outliers)
total_count = len(df[column])
# 计算异常值占比
outlier_proportion = outlier_count / total_count
# 保存每列的异常值占比
result[column] = outlier_proportion
# 绘制箱型图
plt.figure(figsize=(6, 4))
sns.boxplot(x=df[column])
plt.title(f"Boxplot of {column}")
plt.show()
return result
columns = op_data.describe().columns.to_list()
check_outliers_and_proportion(df, columns)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 非数值型
■ 查看object类型"即字符串类型的数据"的列有多少个不同元素组成
df.select_dtypes(include=['object']) # df筛选出object类型的列,组成一个新的df
df.select_dtypes(include=['object']).nunique() # 看新df每一列的不同组成元素的个数
d = df.select_dtypes(include=['object'])
for item in d.columns:
print(df[item].unique())
# - 还可以用df表格来展示
def func(x):
return pd.Series({
'unique_values': list(x.unique()),
'n_unique': x.nunique()
})
pd.options.display.max_colwidth = 200 # 设置df表格展示时列最大显示宽度
df.select_dtypes(include=['object']).apply(func,axis=0).T
# - 在表格展示时,我们发现BusinessTravel列中同时出现了TravelRarely和Travel_Rarely,这两者含义是一样,需要替换!
df['BusinessTravel'] = df['BusinessTravel'].replace('TravelRarely', 'Travel_Rarely')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 空值处理
某列的空值还可以通过随机森林作回归预测, 预测值作空值的填充..
■ 看有多少个空值
df.isnull().sum(axis=0) 查看列缺失值的个数 等同于 data.isna().sum()
df.isnull().sum(axis=0).sum() df.isnull().sum(axis=1).sum() 都可以
第一个sum是df的,第二个sum是series对象的. 相加时,True为1,False为0
■ 查看每一列的空值占比
> 列空值占比少可直接删除空值对应的行,列空值占比多则进行空值填充.
> ※ 若只有一列有空值且占比多,我们可以通过随机森林根据该字段的类型(连续、离散)作回归或分类任务进行空值填充..
-方案一-
df.isnull().sum() / df.shape[0]
-方案二-
def find_nan_field(df):
for col in df.columns:
if df[col].isnull().sum() > 0:
null_count = df[col].isnull().sum()
total_count = df[col].size
p = null_count / total_count * 100
print(f"%s列存在的缺失值,缺失占比为: %.2f"%(col,p))
find_nan_field(df)
■ 删除有空值的行 - 根据行来
-方案一-
ex1 = df.isnull().any(axis=1) > 快速查看哪些行有空值! True表示这一行有空值
df[~ex1]
-方案二-
ex2 = df.notnull().all(axis=1) > 快速查看哪些行没有空值! True表示这一行没有空值
df[ex2]
-方案三-
df.dropna(axis=0)
■ 删除有空值的行 - 根据列来
df.dropna(axis=1) # 不管空值在这条记录的哪个字段,有就删除
df.dropna(subset=['YearsWithCurrManager'],inplace=True) # 只删除YearsWithCurrManager列空值对应的行
■ 删除指定的行列
df.drop(index=['row2'],columns=['A'],inplace=True)
df.drop(index=ex1[~ex1].index,inplace=True) # 删除有空值的行!
■ 空值填充
- df.fillna(0) > 用0替换所有空值
- df.fillna(method='bfill',axis=0) > 在竖直方向上,选择空值后面的元素进行填充
- 统计指标填充
def func(x): # 传进来的x是Series对象哦!
if x.isnull().sum() == 0:
return x
avg = x.mean() # 指标-均值
return x.fillna(value=avg) # 选择后面的元素进行填充
df.apply(func,axis=1) # func函数不用改,该axis的值控制行和列即可!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 重复行处理
■ 重复值清洗
>>> df.duplicated() # 检测重复的行数据/行是否重复 返回一个bool值的Serise对象,为True表明该行是重复行
0 False
1 False
2 False
3 False
4 False
dtype: bool
>>> df.duplicated().sum() # 获取重复行的个数
86
>>> df.drop_duplicates(inplace=True) # 删除重复行的数据,注:会保留第一个重复行
>>> # !!!通过重置索引,解决删除重复行后,行索引不是连续的问题. drop=True表明不要将乱序的行索引作为一列
>>> # ps:你去看看Series变DataFrame的解决方案,也用到了该方法!!只不过那里是Series对象调用的该方法!!
>>> df.reset_index(drop=True,inplace=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Pandas高级用法
补充: applymap函数, DataFrame专有, 对df中每一个元素进行运算处理.
eg: df.applymap(lambda x: x + 100) 等同于 df + 100
# map以及apply运算
先来看看关于apply对DataFrame对象的行和列进行处理时最最基本的用法..
>>> df1
Python Tensorflow Keras
A 2 3 4
B 6 7 8
C 2 2 4
>>> df1.apply(lambda x:x.mean(), axis=1)
A 3.000000
B 7.000000
C 2.666667
dtype: float64
>>> df1.apply(lambda x:x.mean(), axis=0)
Python 3.333333
Tensorflow 4.000000
Keras 5.333333
dtype: float64
"""
针对apply对DataFrame对象的行和列进行处理最基本的用法,我们可以这样理解:
- 传进函数的值是每一行或每一列,是一个Series对象,每次返回的结果是一个值.所有的返回结果拼凑到一起就是一个新的Series对象!!
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
进阶版 - 如果对行和列处理时, 返回的是一个元祖呢? 对每一行或列进行的是 value_counts的处理呢?
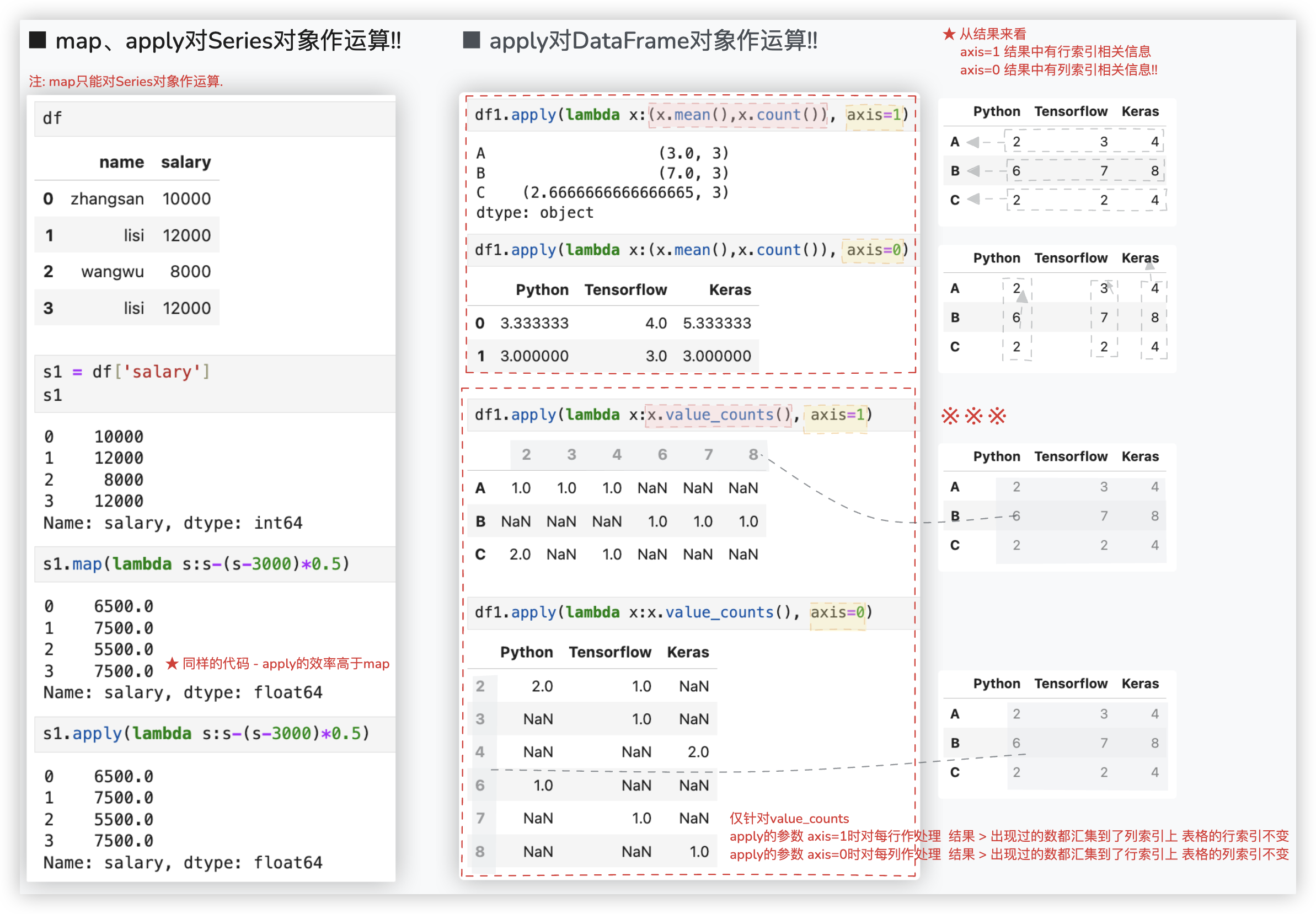
注意: 这里的apply跟groupby后面接apply不一样哈, 你打印下自动func的参数x就知道func函数处理的是什么了!!
# groupby和map映射

※ 补充: 分组后,求每组的行数/个数 df.groupby('列名').size() 、df.groupby('列名')['某列'].count()
一定要注意区分, df.size是里面元素个数,eg: shape为(4,5) 则df.size的值是20
Ps: 关于 df.groupby('列名').apply(func) 的应用场景, 详看 人货场分析模型中的 客单价分析的示例..
为了深刻理解transform和apply的区别, 举一个栗子阐述下.
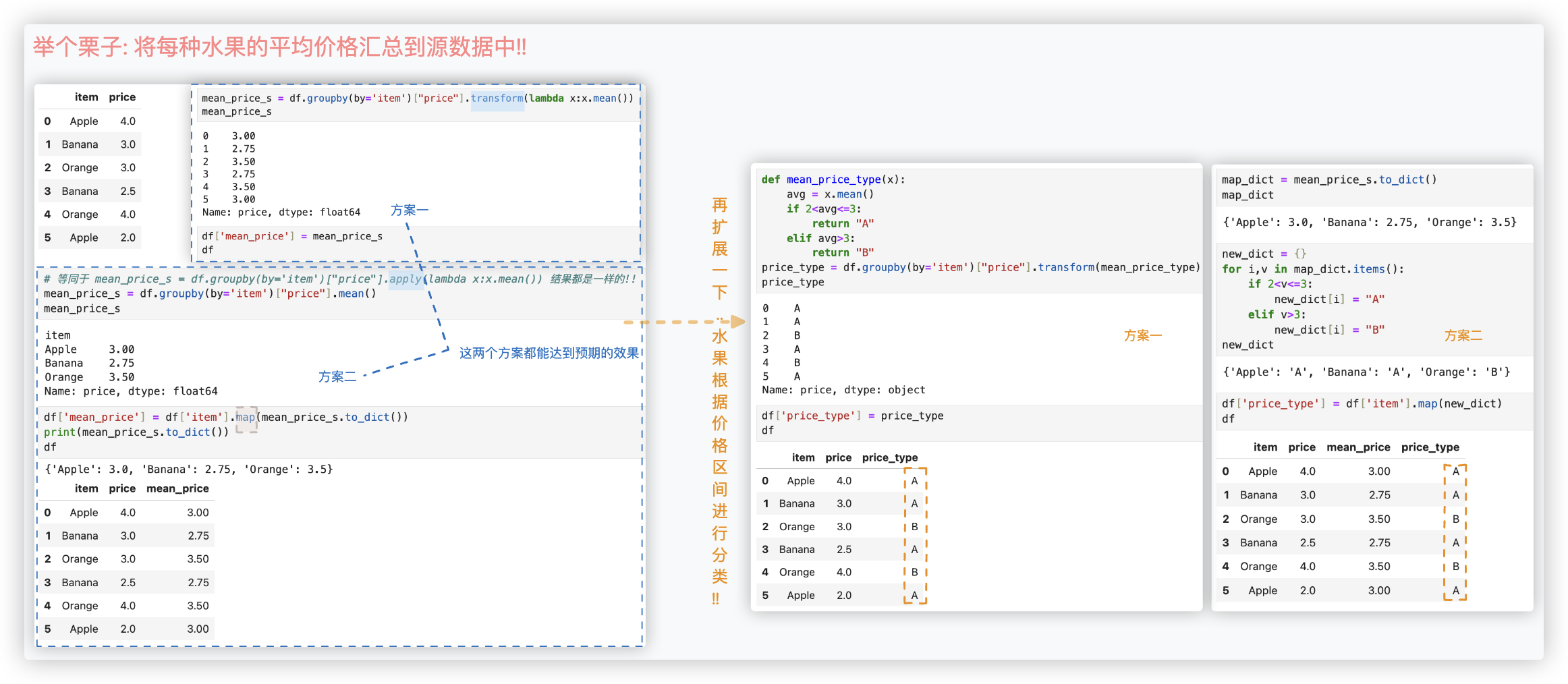
其实上图中的那个new_dict都可以不用创建, 对mean_price_s作apply, 然后to_dict, 其结果作为映射字典就行了..
若映射关系是一张表, 怎么转换成映射字典呢?
>>> import pandas as pd
>>> df = pd.DataFrame({
'小类': ['矿泉水', '可乐'],
'进价': [1.3, 2.3]
})
>>> df
小类 进价
0 矿泉水 1.3
1 可乐 2.3
>>> df.set_index('小类')['进价'].to_dict()
{'矿泉水': 1.3, '可乐': 2.3}
>>> dict(zip(df['小类'],df['进价']))
{'矿泉水': 1.3, '可乐': 2.3}
2
3
4
5
6
7
8
9
10
11
12
13
再补充一点, 有这样一个场景, 求消费日期人次数, (同一用户在一天消费多次只能算作一次.
针对该场景, 提供两个方案
-1-
total_num = year_data.groupby('Customer_ID')['Order_Date'].nunique().sum()
-2-
total_num = year_data.drop_duplicates(subset=['Customer_ID', 'Order_Date']).shape[0]
2
3
4
# pivot_table透视表
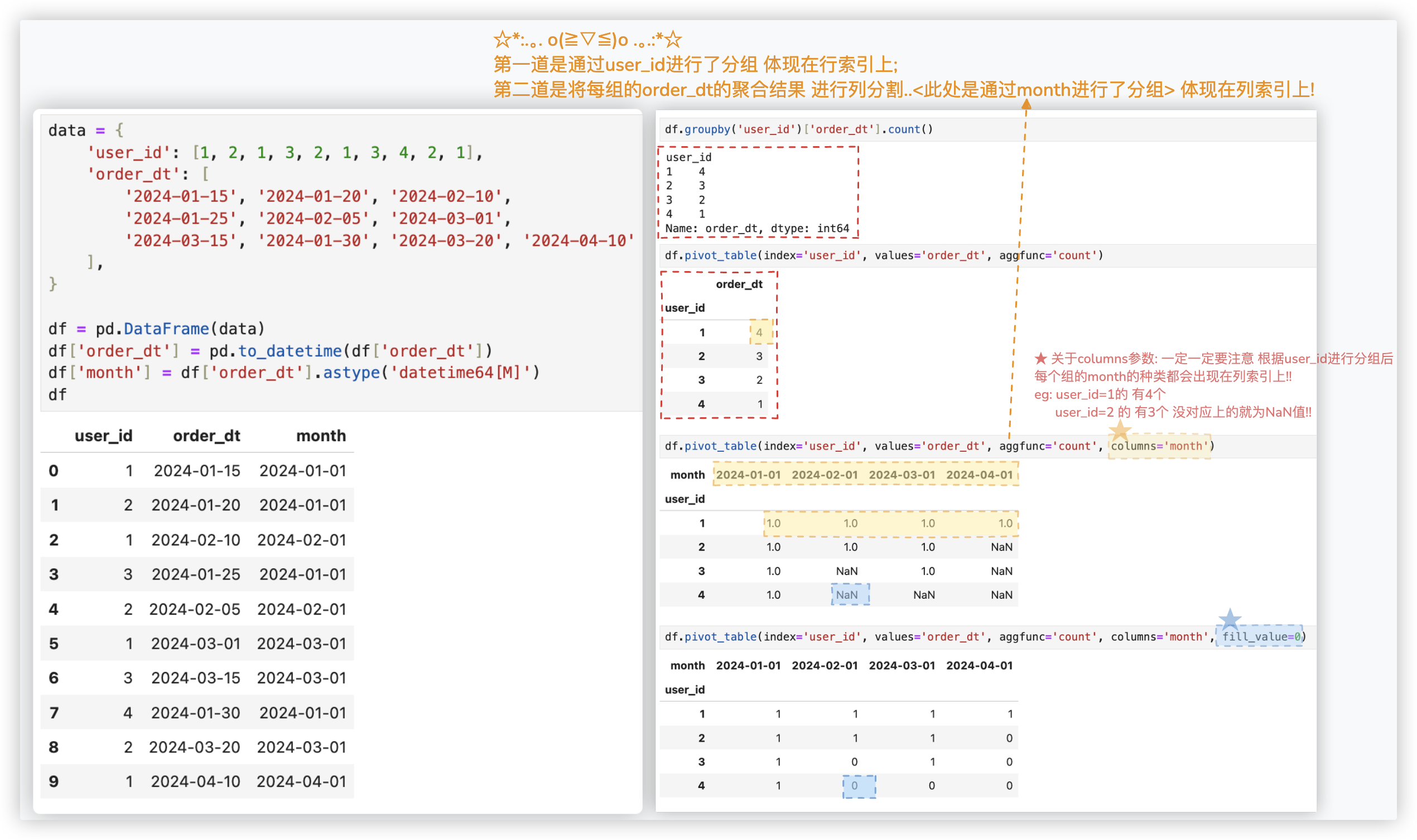
# - 补充一点
age_attrition = data.groupby('AgeGroup')['Attrition'].count()
age_attrition
"""
AgeGroup
18-25 123
26-35 611
36-45 471
46-55 228
55+ 47
Name: Attrition, dtype: int64
"""
age_attrition = data.groupby('AgeGroup')['Attrition'].value_counts()
age_attrition
"""
AgeGroup Attrition
18-25 No 79
Yes 44
26-35 No 495
Yes 116
36-45 No 428
Yes 43
46-55 No 201
Yes 27
55+ No 39
Yes 8
Name: Attrition, dtype: int64
"""
age_attrition = data.groupby('AgeGroup')['Attrition'].value_counts().unstack()
age_attrition
"""
Attrition No Yes
AgeGroup
18-25 79 44
26-35 495 116
36-45 428 43
46-55 201 27
55+ 39 8
"""
PS: data.pivot_table(index='AgeGroup',values='Attrition',aggfunc="value_counts") 报错!!
因为 pivot_table 需要每个分组的计算结果为一个标量!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# groupby+unstack
扩展下, groupby+unstack也能实现列分割!!
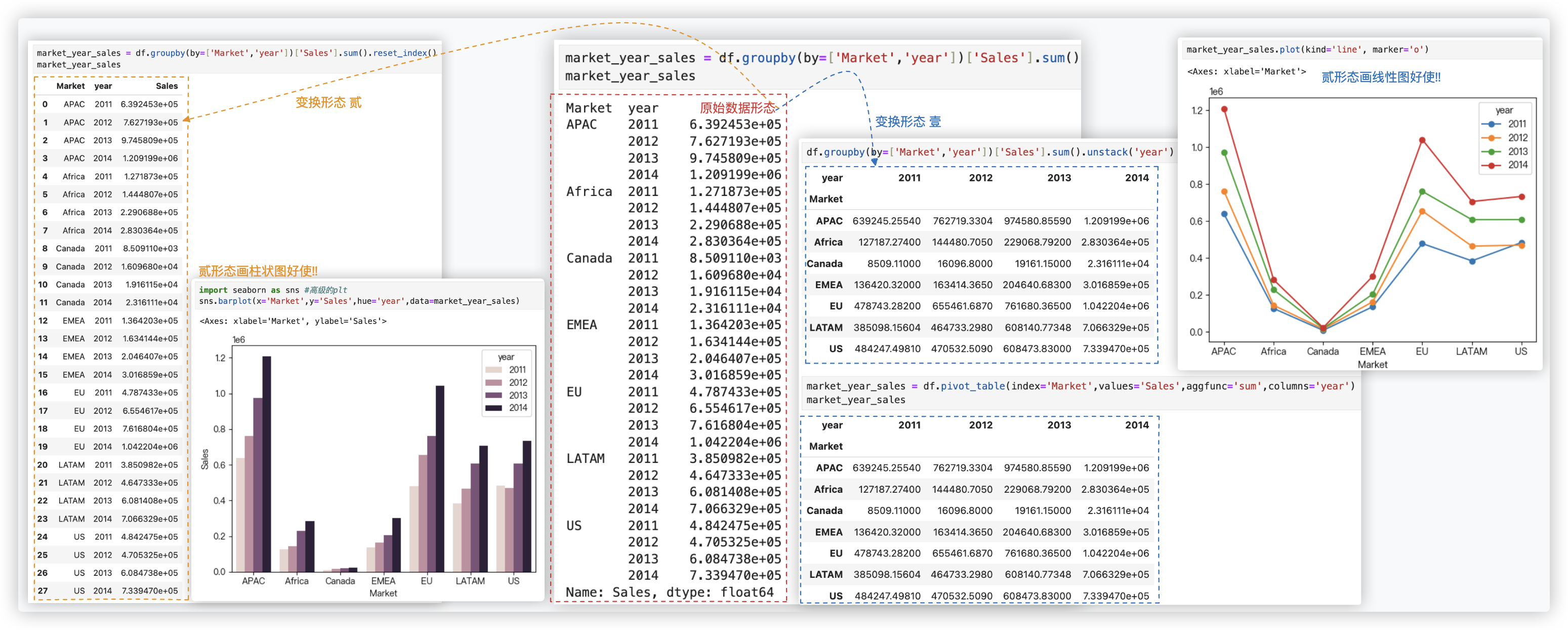
关于groupby+unstack,再举个常见的例子.
sales_data.pivot_table(index='year',values='Sales',aggfunc='sum',columns='m')
sales_data.groupby(by=['year', 'm'])['Sales'].sum().unstack(level='m')
"""
上面两行代码的效果是一样的.简单理解下group+unstack
year m
2011 1 100
2 200
3 150
2012 1 789
2 201
3 108
Name:sales, dtype:int
通过unstack后
1 2 3
2011 100 200 150
2012 789 201 108
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# crosstab数据交叉
unstack()数据重塑:
Pandas DataFrame中的unstack()函数用于将多个水平的行列索引旋转为新的列索引.
它能够改变数据框中行和列标签的顺序, 从而使得数据的组织方式更加符合分析需求.
crosstab()数据交叉:
创建交叉表来展示两个或多个分类变量之间的频率分布关系(两个或者多个分类变量之间元素的交叉计数统计)
"""
举个例子: 我们需要探究 AgeGroup字段和Attrition字段的相关性,即想知道有何关联?
AgeGroup字段、Attrition字段都是离散型数据
- AgeGroup字段 > 18-25, 26-35, 36-45, 46-55, 55+
- Attrition字段 > Yes, No
"""
# 等同于age_attrition1 = pd.crosstab(df['AgeGroup'], df['Attrition'])
age_attrition1 = df.groupby('AgeGroup')['Attrition'].value_counts().unstack().fillna(0)
# 若想把数值转化为百分比!使用div函数
age_attrition1 = age_attrition1.div(age_attrition1.sum(axis=1), axis=0) * 100
# 上述这两步可以用一行代码实现
age_attrition1 = pd.crosstab(df['AgeGroup'], df['Attrition'],normalize="index") * 100
age_attrition1
"""
Attrition No Yes
AgeGroup
18-25 63.247863 36.752137
26-35 81.058020 18.941980
36-45 90.848214 9.151786
46-55 88.235294 11.764706
55+ 81.818182 18.181818
"""
# * PS:这种数据结构可以用plt画线图,详见画图小节的内容!!
# 观察age_attrition1的格式,若用sns画图,AgeGroup每个类别上只能有一个柱子
# > 这种形式若用sns画柱状图 - 适用于 x轴df的标签. y轴yes或no其中一列.
sns.barplot(x=age_attrition1.index, y=age_attrition1['Yes'])
# > 当然,这种形式也可以画堆叠柱状图,注: sns不支持堆叠柱状图,需用plt来画
ax = age_attrition1.plot(kind='bar', stacked=True)
for p in ax.patches:
width, height = p.get_width(), p.get_height()
if height > 0: # 只对非零高度的柱子添加标签
x = p.get_x() + width / 2
y = p.get_y() + height / 2
ax.annotate(f'{int(height):.1f}%', (x, y), ha='center', va='center', fontsize=10, color='white')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
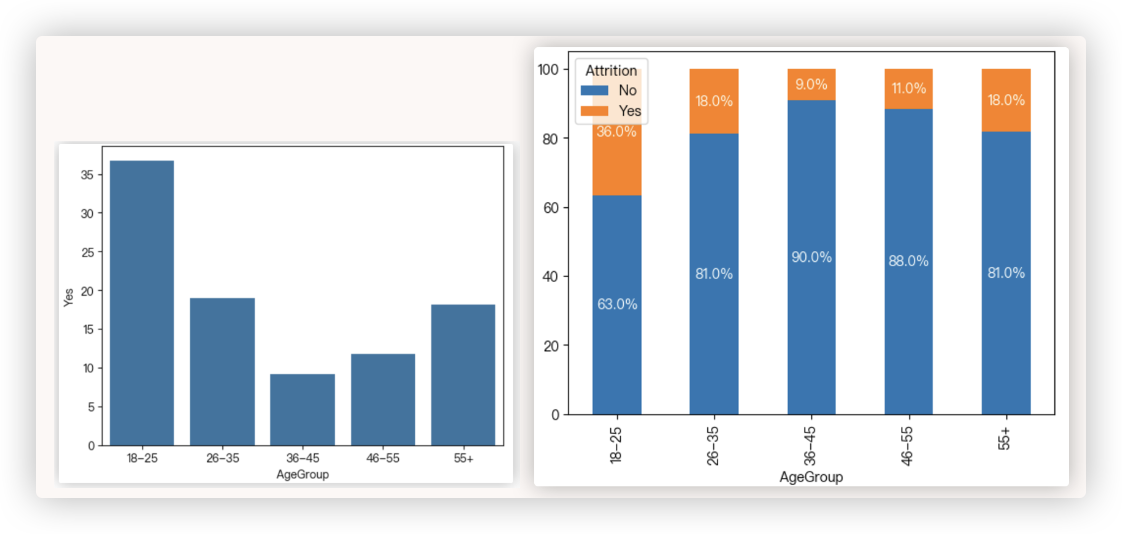
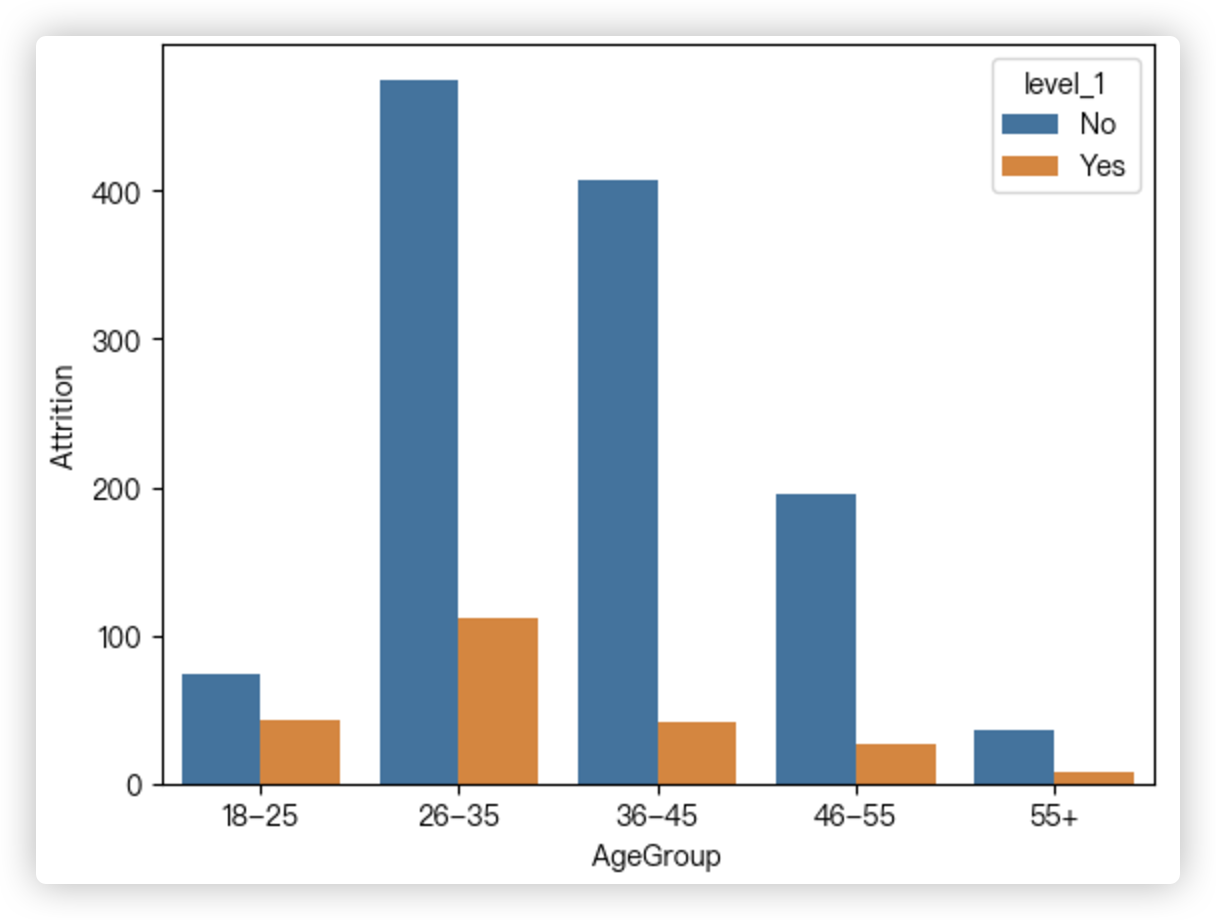
age_attrition2 = df.groupby('AgeGroup')['Attrition'].value_counts().reset_index()
age_attrition2
"""
AgeGroup level_1 Attrition
0 18-25 No 74
1 18-25 Yes 43
2 26-35 No 475
3 26-35 Yes 111
4 36-45 No 407
5 36-45 Yes 41
6 46-55 No 195
7 46-55 Yes 26
8 55+ No 36
9 55+ Yes 8
"""
# 观察age_attrition1的格式,若用sns画图,AgeGroup每个类别上可以有多个个柱子
# > 先根据AgeGroup分组作为x轴,每个分组里有多个Attrition值,再算每个分组里的level_1的类别个数
# 有多少个类别,每个分组下就有多少个柱子!
sns.barplot(data=age_attrition2, x="AgeGroup",y="Attrition",hue="level_1")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 索引替换
>>> df = pd.DataFrame(data=np.arange(1,7).reshape(2,3))
>>> df
0 1 2
0 1 2 3
1 4 5 6
>>> df.rename(index={0:"one"},columns={1:"壹"})
0 壹 2
one 1 2 3
1 4 5 6
>>> df.index = ["hello","world"]
>>> df.columns = ["a-1","b-1","c 1"]
>>> df
a-1 b-1 c 1
hello 1 2 3
world 4 5 6
>>> df.rename(columns=lambda x:x.replace(' ','_').replace('-','_'))
a_1 b_1 c_1
hello 1 2 3
world 4 5 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
补充: df.replace() 可以实现值替换.. 但没必要记.
因为全局值可以用 df.applymap(func)来完成. 某一列的值的替换可以用 df['列名'] = df['列名'].apply(func) 来实现.
# 排序
s1.sort_index()
s1.sort_values()
df.sort_index(axis=0, ascending=True) # 按索引排序,升序
df.sort_index(axis=1, ascending=False) # 按列名排序,降序
df.sort_values(by=['Python']) # 根据Python这一列的值进行排序
df.sort_values(by=['Python', 'Keras']) # 先按Python,再按Keras排序
2
3
4
5
6
7
8
使用sort_value排序时, 需要保证其是数值类型哦!! 你可以通过 df.info() 来查看, 得是int或者float.
# eg:
p['总历史成功借款金额'] = p['总历史成功借款金额'].astype(float)
p.sort_values(['总历史成功借款金额'])
2
3
# 时间序列
- 使用Pandas中的resample进行重新采样
前提:数据必须具有DatetimeIndex 或 PeriodIndex的索引!! (可通过df.index、s1.index方法查看是否是该类型的索引
> 举个栗子 df.resample('M').first()
df.resample('M') 按月进行分组,(H小时、W星期、M月、A年等)
.first取出每组的第一行数据; .last取出每组的最后一行数据. 取完后进行拼接,所以最后的结果依旧是DataFrame对象!!
> 当然也可以对 Series对象进行resample !!
- 若想把时间差转化成以"天"为单位
temp['R'] = (df["order_dt"].max() - temp["order_dt"]) / np.timedelta64(1, 'D')
2
3
4
5
6
7
8
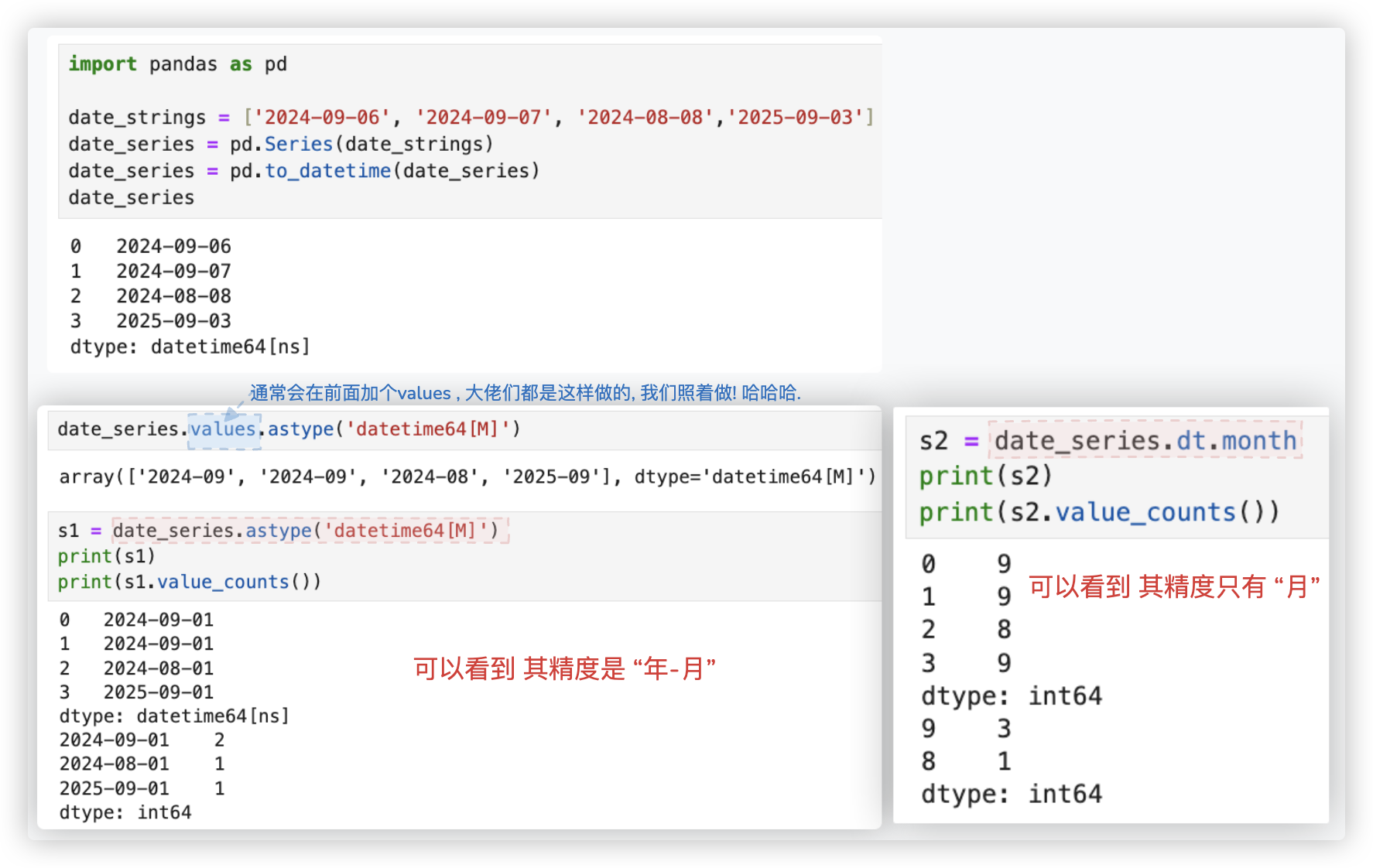
提取月份的操作, 有两种方式, 很有意思, 需细品一下:
你要注意哈, date_series.dt.month、date_series.dt.year 这些操作, 其结果的数据类型是 int ~
# 其它
# 浅谈一下axis
>>> n = np.array([[1,2,3],[4,5,6]])
>>> n
array([[1, 2, 3],
[4, 5, 6]])
>>> n.sum(axis=0)
array([5, 7, 9])
>>> n.sum(axis=1)
array([ 6, 15])
n.sum(axis=0) 它本质是将每一行[1,2,3]、[4,5,6]对应位置的元素,逐元素作加法.
★ 我们为了方便理解,会简单记忆成 axis=0对列作操作,axis=1对行作操作即可! eg: n.sum(axis=0) 对列作加法运算!
max、min聚合运算; apply运算; any()、all()空值判断 等这样记忆都没问题.
但有些要特别注意!!
-1- df.sort_index() 索引排序,axis=0是按行索引排,axis=1按列索引排.
-2- df.dropna() axis=0删除有空值的行,axis=1删除有空值的列.
-3- df.duplicated() axis=0重复行检查,axis=1重复列检查.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Series变DataFrame
>>> s1 = pd.Series(data=[1,2,'three',4])
>>> s1
0 1
1 2
2 three
3 4
dtype: object
>>> s1.to_frame()
0
0 1
1 2
2 three
3 4
>>> s1.reset_index() # ★
index 0
0 0 1
1 1 2
2 2 three
3 3 4
>>> s1.reset_index(drop=True)
0 1
1 2
2 three
3 4
dtype: object
>>> s1.reset_index().set_index('index')
0
index
0 1
1 2
2 three
3 4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 画图
# matplotlib绘图
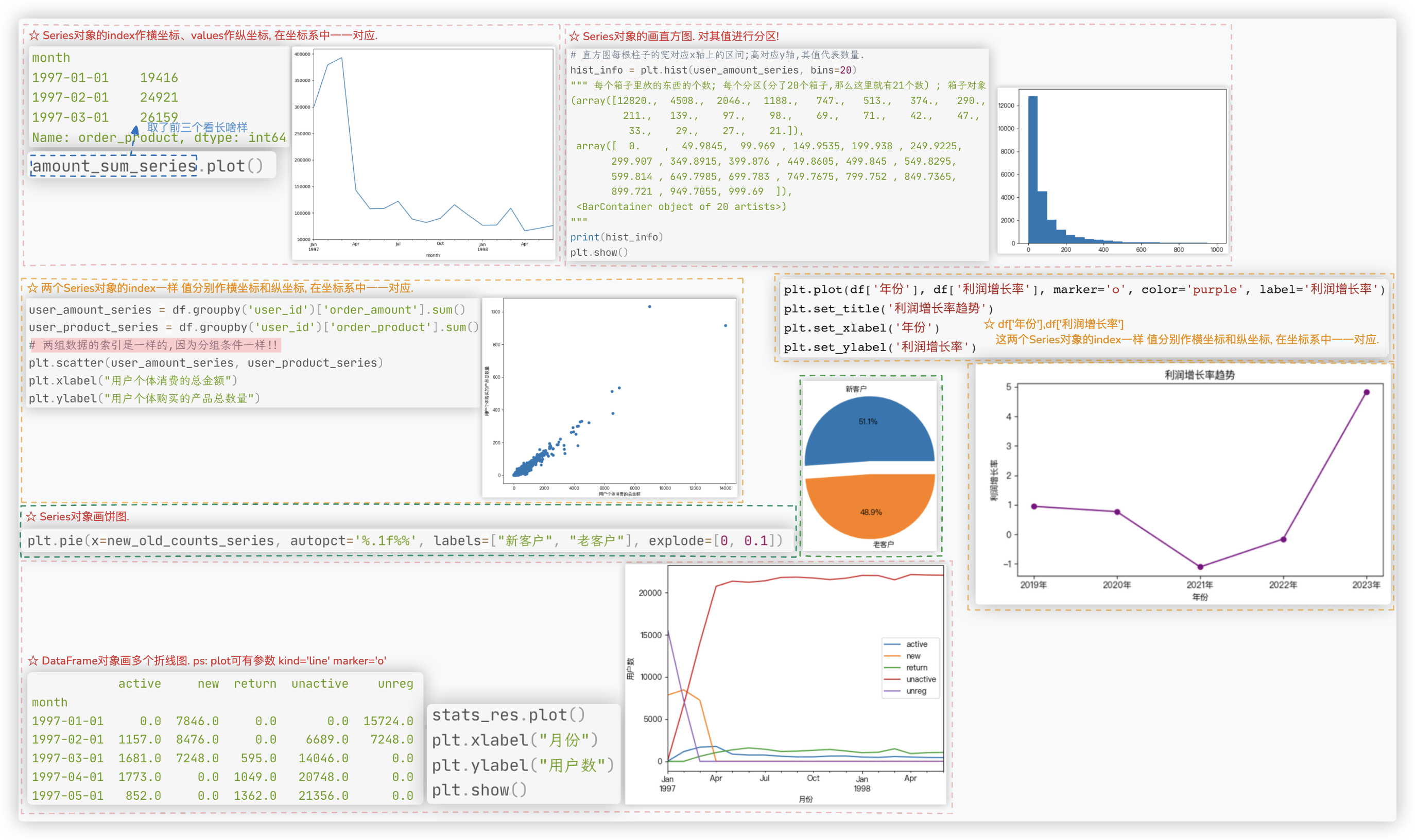
# seaborn绘图
通常用它来作柱状图 记住下面这个截图的例子please ! (可以跟 前面"crosstab数据交叉"小节的图 对比理解下!!
# Plotly Express绘图
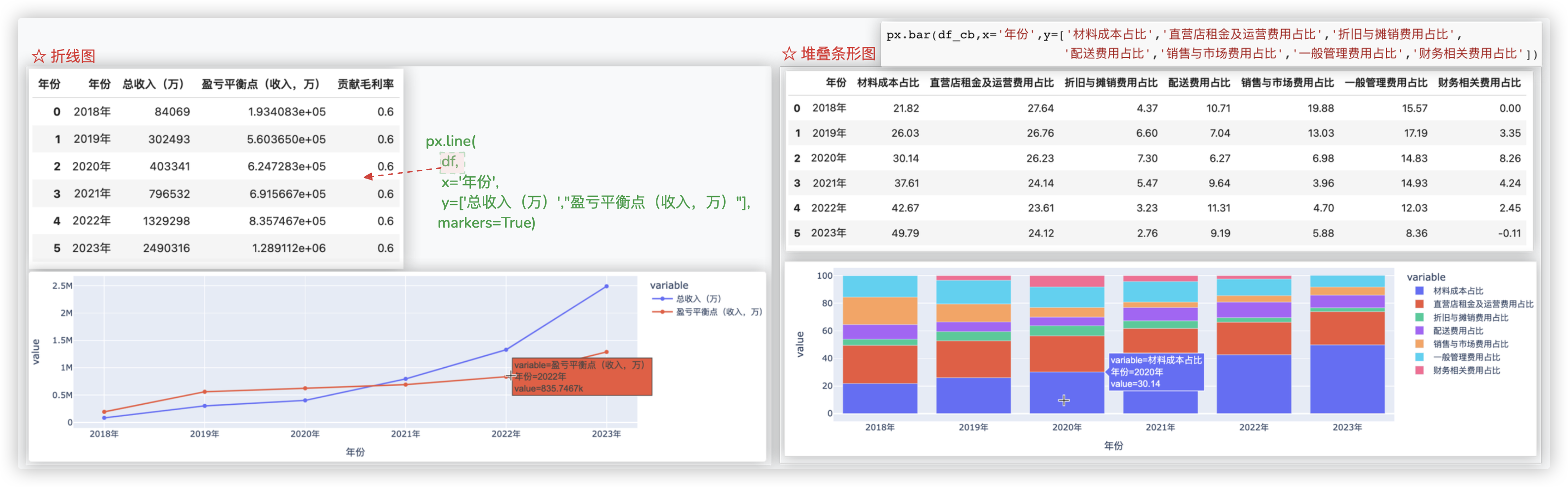
# 构建知识点的场景感
将做过项目的数据和需求放在这. 答案自行翻阅前面的博客..
# 商场销售分析
user_id order_dt order_product order_amount month
0 1 1997-01-01 1 11.77 1997-01-01
1 2 1997-01-12 1 12.00 1997-01-01
2 2 1997-01-12 5 77.00 1997-01-01
3 3 1997-01-02 2 20.76 1997-01-01
4 3 1997-03-30 2 20.76 1997-03-01
2
3
4
5
6
需求如下:
- 上面展示的数据是经过数据清洗后的样子,它经历了以下步骤
1> 加载数据集
2> 将order_dt转换成时间类型
3> 在源数据中添加一列表示月份
- 按月进行分析
1. 每个月的销售金额。 [月][销售额].sum
2. 每个月的产品购买量 [月][销售量].sum
3. 每个月的消费次数 <注:消费购买一次就是一条记录/一行数据 [月].size
4. 每个月的消费人数 <注:同一个人当月消费多次只能算一个人 [月][user_id].nunique
- 按用户个体进行分析
5. 各个用户消费金额和消费产品数量 画散点图 [user_id][order_amount].sum [user_id][order_product].sum
6. 各个用户消费总金额[筛选出金额数<=1000的] 画直方分布图
7. 各个用户购买产品总数[筛选出购买数量<=100的] 画直方分布图
- 用户消费行为分析
8. ※每月新增用户数 画折线图 <注:用户第一次消费的月份就代表该月新增了该用户 [user_id][month].min.value_counts
9. ※每月流失用户数 画折线图 <注:用户最后一次消费的月份就代表该月流失了该用户
10. 新老用户占比 画饼图 <注:老用户是指在多个日期进行了消费,在同一天消费多次,是不算老用户的.即老用户的消费日期数据>=2
/还可通过第一次购买和最后一次购买的日期对比是不是一样的 来区分新老用户
([user_id][order_dt].nunique > 2).value_counts
11. RFM模型设计 画饼图 <注:F表示客户购买商品的总数量; M表示客户交易的金额; R表示客户最近一次交易时间到最新订单日期的时间间隔.
- 用户的生命周期
12. 统计每个用户每个月的消费日期数 - 提示:用透视表列分割!!
13. 固定算法 判断是否为 新、活跃、不活跃、回流用户
14. 每月 [不同活跃] 用户的计数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 美妆数据分析
update_time id title price sale_count comment_count 店名
2016/11/14 A18164178225 CHANDO/自然堂 雪域精粹纯粹滋润霜50g 139.0 26719.0 2704.0 自然堂
补水保湿 滋润水润面霜
2016/11/14 A18177105952 CHANDO/自然堂凝时鲜颜肌活乳液120ML 194.0 8122.0 1492.0 自然堂
淡化细纹补水滋润专柜正品
-- id产品ID; title产品名字 ; price价格 ; sale_count销售量 ; comment_count评论数
2
3
4
5
6
7
需求如下:
- 数据清洗
1> 重复行清洗
2> 缺失值填充
- 列处理
1. 根据title列 和 网上找的化妆品文本 添加 两列 分别对应 每个产品的 大类和小类 (需jieba分词
2. 根据title列 添加该产品 是否是男生专用 列.
3. 添加销售额列
4. 某店铺所有产品加在一起的销售额/某店铺总的销售产品的数据得到 该店铺平均每单单价.
根据这个平均每单单价所处的范围 划分了 四个等级ABCD. 在原数据表格中添加一列 映射出该店铺的 等级!!
- 数据分析
1. 各店铺商品大类别的数量, 画直方图
2. 各店铺的销售量和销售额, 画销售量直方图、销售额直方图、销售量于销售额的散点图
3. 各店铺平均每单单价, 画直方图
4. 各单价区间销售额所占比例, 画饼图
5. 各店铺的销售额所占比例 画饼图,店铺所处平均每单单价区间用颜色区分
6. 平均每单单价区间里的店铺销售均值, 画直方图
7. 大类销量占比,大类销售额占比,小类销量占比,小类销售额占比 画4个饼图
8. 是否男生专用小类销售量占比 画两个饼图
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# ★ 人货场分析模型
详看对应的博客.. 都是学过的知识点. (人货场分析模型, 电商场景皆可复刻
- 数据预处理
缺失值、重复值和异常值探究和处理
数据类型转换处理
核心字段抽取和字段拓展
- 数据分析
- 场
整体销售情况分析
销售额分析
销量分析
利润分析
客单价分析
市场布局分析
- 货
分析销量、销售额和利润较高的产品有哪些、较低的有哪些和亏损的有哪些? 以便在后续经营中对这些商品进行针对性的策略优化。
- 人
不同类别客户的占比和每年贡献的销售额
客户下单行为分析
第一次下单的月份分布和人数统计
最近一次下单的月份分布和人数统计
新老用户数占比和回头率分析
RFM用户价值分层
复购率分析
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# ★ 财务经营分析
详看对应的博客..