 美妆数据分析
美妆数据分析
测试数据提取链接: https://pan.baidu.com/s/1Lw6gSxFK73LARYb9ORVgcA?pwd=dcqz 提取码: dcqz
导言: 双十一期间, 美妆产品可谓是针对大众消费者的一大买点, 不管是销售额还是销量都是很可观的一个现象.
那么在如此庞大的销售数据中, 我们能否在其中总结分析出一些结论或者现象呢?
# ※ 项目的完整代码
内心os,有点折磨.. 一开始 我是一股脑的所有代码都写在py文件里.. 就写了注释;
后来我觉得太乱了 就函数式编程了一下 同时重新理了下逻辑. 然后 发现 变量名起名、调试啥的很难受..
往后的项目分析, 我再试试 ipynb+markdown的形式.. 应该会舒服很多.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import jieba
def basic_config():
# 在pycharm中打印pandas读取的excel表格数据, 为了显示的工整完整, 会进行以下配置:
pd.set_option('display.unicode.east_asian_width', True) # 使得 Pandas 在计算列宽时考虑东亚字符的实际宽度
pd.set_option("display.width", None) # 自动调整显示宽度,消除打印不完全中间的省略号
pd.set_option("display.max_columns", None) # 显示所有列
pd.set_option("display.max_rows", None) # 显示所有行
pd.set_option('display.max_colwidth', None) # 显示列宽度
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False
def read_data(path):
return pd.read_csv(path)
def data_clean(df):
"""进行数据清洗"""
# - 重复值清洗
if df.duplicated().sum() > 0:
df.drop_duplicates(inplace=True)
df.reset_index(drop=True, inplace=True)
# - 缺失值清洗
# print(df.isnull().sum(axis=0))
# 因为我们观察到缺失值全部是关于sale_count(销售数量)和comment_count(评论数量)的,所以我们可将缺失值全部填充为0
df.fillna(value=0, inplace=True)
def title_makeup_txt():
"""对化妆品文本进行处理"""
basic_data = """
护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
护肤品 眼部护理类 眼霜 眼部 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素 精华
护肤品 防晒类 防晒
护肤品 补水类 补水
化妆品 口红类 唇釉 口红 唇彩 唇膏
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 眉笔
化妆品 修容类 鼻影 修容粉 高光 腮红
"""
dcatg = {} # eg: {'乳液': ('护肤品', '乳液类'), '美白乳': ('护肤品', '乳液类'),..}
# ★ 一定要注意空格和换行符的处理!!
for line in basic_data.strip().split('\n'):
parts = line.strip().split(' ')
if len(parts) < 3:
continue # 忽略格式不正确的行
main_catg = parts[0]
sub_catg = parts[1]
keywords = parts[2:]
# 你可能会担心文本中有相同的关键字,no,你细看一下,是没有的,Hhhh
dcatg.update({keyword: (main_catg, sub_catg) for keyword in keywords})
return dcatg
def title_jieba(df):
"""对title列进行jieba分词"""
subtitle = [] # 将title分词的结果保存到该列表中
for title in df['title']:
ret = list(jieba.cut(title))
subtitle.append(ret)
df['subtitle'] = subtitle
def add_two_column(df, dcatg):
"""给df添加大类和小类两列"""
def get_type(s_list):
# 遍历字幕中的每个元素,找到第一个匹配的关键字
for keyword in s_list:
if keyword in dcatg:
return dcatg[keyword]
return '其他', '其他'
df[['main_type', 'sub_type']] = pd.DataFrame(df['subtitle'].apply(get_type).tolist())
def add_man_use_column(df):
"""添加 是否是男性专用 列"""
def is_man_use(s_list):
if '男士' in s_list or '男生' in s_list:
return '是'
elif '男' in s_list and '女' not in s_list and '斩男' not in s_list:
return '是'
else:
return '否'
df['是否男生专用'] = df['subtitle'].apply(is_man_use)
def add_sale_money_column(df):
"""添加销售额列"""
df['销售额'] = df['price'] * df['sale_count']
def add_avg_price_class_column(df):
"""添加店铺所属单价区间列"""
# 各店铺平均每单价=店铺销售总额/店铺销售总数量 --> 得一Series对象 > index店名 value店铺平均每单价
shop_avg_price = (df.groupby('店名')['销售额'].sum() / df.groupby('店名').sale_count.sum()).sort_values()
# 按照平均每单价 0-100,100-200,200-300,300的区间给 店铺 划分成四类 分别对应 ABCD
A = shop_avg_price[(shop_avg_price <= 100) & (shop_avg_price > 0)].index
B = shop_avg_price[(shop_avg_price <= 200) & (shop_avg_price > 100)].index
C = shop_avg_price[(shop_avg_price <= 300) & (shop_avg_price > 200)].index
D = shop_avg_price[shop_avg_price > 300].index
# 创建一个字典将类别映射到对应的店名,并将信息添加到df表格中
category_map = {}
category_map.update({name: 'A' for name in A})
category_map.update({name: 'B' for name in B})
category_map.update({name: 'C' for name in C})
category_map.update({name: 'D' for name in D})
df['单价区间分类'] = df['店名'].map(category_map) # 将类别映射到 df 中的新列
def column_process(df):
"""进行列的处理"""
dcatg = title_makeup_txt() # - 化妆品文本处理 eg: {'乳液': ('护肤品', '乳液类'), '美白乳': ('护肤品', '乳液类'),..}
title_jieba(df) # - 对title列进行jieba分词
add_two_column(df, dcatg) # - 结合前两步的结果给df添加大类和小类两列
add_man_use_column(df) # - 添加 是否是男性专用 列
add_sale_money_column(df) # - 添加销售额列
add_avg_price_class_column(df) # - 添加店铺所属单价区间列
def draw_bar_of_shop_category(df):
"""各店铺商品大类别的数量"""
# - 数据分析
shop_count_s = df.groupby(by='店名')['sub_type'].nunique().sort_values()
# - 画图数据准备
# eg: ["新中国","全世界"] 变成 ["新\n中\n国","全\n世\n界"]
x = list(map(lambda s: '\n'.join(s), shop_count_s.index))
y = shop_count_s.values
# - 画图
plt.figure(figsize=(10, 8), dpi=200)
plt.bar(x, y)
for i, v in enumerate(y):
plt.text(i, v + 0.2, v, ha='center')
plt.xlabel('店铺名')
plt.ylabel('化妆品大类别数量')
plt.title('各店铺商品大类别的数量')
plt.show()
def tool_by_add_bar_txt(y, rotation=0):
"""当y轴上的刻度用了科学记数法时,我们在柱子上的标注也用科学记数法"""
# 比如销量上百万了,肯定用会用科学计数法
# 1. 获取画图时,y轴上的自动标注的单位 eg:科学记数法的 e7 """
ax = plt.gca() # 获取当前图形的坐标轴对象
yticks = ax.get_yticks() # 获取纵坐标的刻度值
top_tick = yticks[-1] # 选择最上方的刻度值
exponent = int(np.log10(top_tick)) # eg: 7
# 2. 在柱子上进行标注
for i, v in enumerate(y):
if v == 0:
continue
# eg: 你可以观察图的纵坐标的单位,自动转换成了1e7, 那么我们将v的值除以 1e7 并格式化保留2位小数
plt.text(i, v + 0.1 * (10 ** exponent), f'{v / 10 ** exponent:.2f}', ha='center', rotation=rotation)
# 调整 y 轴范围,增加上限
plt.ylim(0, max(y) * 1.15) # 将 y 轴的上限设置为最大值的 1.15 倍
def draw_of_sale_money_and_sale_number_by_shop(df):
"""各店铺商品的销量以及销售额之间的关系"""
# - 数据分析和画图数据准备
shop_sale_number = df.groupby(by='店名')['sale_count'].sum().sort_values()
x1 = list(map(lambda s: '\n'.join(s), shop_sale_number.index))
y1 = shop_sale_number.values
shop_sale_money = df.groupby(by='店名')['销售额'].sum().sort_values()
x2 = list(map(lambda s: '\n'.join(s), shop_sale_money.index))
y2 = shop_sale_money.values
x3 = shop_sale_number
y3 = shop_sale_money
# - 画图 bar、bar、scatter
plt.figure(figsize=(12, 8), dpi=200)
plt.subplot(2, 2, 1)
plt.bar(x1, y1)
tool_by_add_bar_txt(y1, 270) # 科学计数法添加柱子文字
plt.xlabel('店铺名')
plt.ylabel('销售量')
plt.title('各店铺的销售量')
plt.subplot(2, 2, 2)
plt.bar(x2, y2)
tool_by_add_bar_txt(y2, 270) # 科学计数法添加柱子文字
plt.xlabel('店铺名')
plt.ylabel('销售额')
plt.title('各店铺的销售额')
plt.subplot(2, 1, 2)
plt.scatter(x3, y3)
# 为散点图的每个点添加标注
for i, shop_name in enumerate(y3.index):
if y3[i] == 0:
continue
plt.text(x3[i], y3[i], shop_name, fontsize=8, ha='right', va='bottom')
plt.xlabel('销量')
plt.ylabel('销售额')
plt.title('销量与销售额的关系')
plt.tight_layout()
plt.show()
def draw_bar_of_shop_avg_price(df):
"""店铺和店铺平均每单价格的柱状图"""
# 各店铺平均每单价=店铺销售总额/店铺销售总数量 --> 得一Series对象 > index店名 value店铺平均每单价
shop_avg_price = (df.groupby('店名')['销售额'].sum() / df.groupby('店名').sale_count.sum()).sort_values()
x = shop_avg_price.index
y = shop_avg_price.values
plt.figure(figsize=(12, 8), dpi=200)
plt.bar(x, y)
for i, v in enumerate(y):
plt.text(i, v + 10, f"{v:.2f}", ha='center')
plt.xticks(rotation=50)
plt.title('各品牌平均每单单价', fontsize=20)
plt.xlabel('店铺', fontsize=15)
plt.ylabel('售出商品的平均单价', fontsize=15)
plt.show()
def draw_pie_of_price_class_with_sale_money(df):
"""单价区间分类 的销售额所占比例 的饼图"""
avg_price_class_sale_money = df.groupby(by='单价区间分类')['销售额'].sum()
x = avg_price_class_sale_money
plt.figure(figsize=(12, 8), dpi=200)
plt.pie(x=x,
labels=x.index,
colors=["gray", "orange", "yellow", "blue"],
autopct='%.2f%%',
pctdistance=0.9,
wedgeprops={'linewidth': 1.2, 'edgecolor': '#636e72', 'alpha': 0.7})
legend_labels = ['A 0-100', 'B 100-200', 'C 200-300', 'D >300']
plt.legend(legend_labels, loc='best', title='平均每单单价')
plt.show()
def draw_pie_of_shop_sale_money_with_avg_price(df):
"""店铺的销售额所占比例的饼图, 但加上了颜色和图例用于区分店铺所属的单价区间"""
sales_sum = df.groupby('店名')['销售额'].sum() # 计算每个店铺的销售额总和
price_category = df.groupby('店名')['单价区间分类'].first() # 获取每个店铺的单价区间
# 合并销售额和单价区间数据
sales_and_category = pd.DataFrame({
'销售额': sales_sum,
'单价区间分类': price_category
}).reset_index()
sales_and_category.dropna(inplace=True)
sales_and_category.reset_index(drop=True, inplace=True)
# 定义颜色映射
color_map = {'A': 'gray', 'B': 'orange', 'C': 'yellow', 'D': 'blue'}
sales_and_category['颜色'] = sales_and_category['单价区间分类'].map(color_map)
sales_and_category.sort_values(by=['单价区间分类'], inplace=True)
# 绘制饼图
plt.figure(figsize=(12, 8), dpi=200)
plt.pie(
sales_and_category['销售额'],
labels=sales_and_category['店名'],
colors=sales_and_category['颜色'],
autopct='%.2f%%',
wedgeprops={'linewidth': 1.2, 'edgecolor': '#636e72', 'alpha': 0.7}
)
# 自定义饼图的图例文本
legend_labels = ['A 0-100', 'B 100-200', 'C 200-300', 'D >300']
colors = ["gray", "orange", "yellow", "blue"]
handles = []
for color in colors:
temp = plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=color, markersize=10)
handles.append(temp)
plt.legend(handles, legend_labels, loc='best', title='平均每单单价')
plt.title("店铺的销售额所占比例")
plt.show()
def draw_bar_of_shop_sales_mean_by_price_class(df):
"""单价区间的销售额的均值的柱状图"""
# 本质就是单价区间的所属店铺的销售额汇总 除以 单价区间所属店铺的数量
mean_sale = df.groupby(by='单价区间分类')['销售额'].mean()
plt.figure(figsize=(12, 8), dpi=200)
plt.bar(mean_sale.index, mean_sale.values, color=["gray", "orange", "yellow", "blue"], alpha=0.8)
tool_by_add_bar_txt(mean_sale.values) # 科学计数法添加柱子文字
plt.title('不同单价区间里平均每个店的销售额', fontsize=20)
plt.xlabel('单价区间', fontsize=15)
plt.ylabel('平均销售额', fontsize=15)
plt.show()
def draw_big_small_of_sales(df):
"""查看各大类和小类商品的销售额和销量之间的关系"""
plt.figure(figsize=(12, 8), dpi=200)
# 各大类销售量占比
plt.subplot(2, 2, 1)
df.groupby('main_type')["sale_count"].sum().plot.pie(autopct='%.2f%%', title='各大类销售量占比')
# 各大类销售额占比
plt.subplot(2, 2, 2)
df.groupby('main_type')['销售额'].sum().plot.pie(autopct='%.2f%%', title='各大类销售额占比')
# 各小类销售量占比
plt.subplot(2, 2, 3)
df.groupby('sub_type')["sale_count"].sum().plot.pie(autopct='%.2f%%', title='各小类销售量占比')
# 各小类销售额的占比
plt.subplot(2, 2, 4)
df.groupby('sub_type')['销售额'].sum().plot.pie(autopct='%.2f%%', title='各小类销售额占比')
plt.tight_layout()
plt.show()
def draw_isman_small_with_sale(df):
"""男士专用和非男士专用 小类销售量占总销售量 """
isMan = df.loc[df['是否男生专用'] == '是']
notMan = df.loc[df['是否男生专用'] == '否']
isMan_s_count = isMan.groupby(by='sub_type')['sale_count'].sum()
notMan_s_count = notMan.groupby(by='sub_type')['sale_count'].sum()
plt.figure(figsize=(20, 20))
plt.subplot(1, 2, 1)
plt.pie(isMan_s_count.values, labels=isMan_s_count.index, autopct='%0f%%')
plt.title('男士各小类销售量占比')
plt.subplot(1, 2, 2)
plt.pie(notMan_s_count.values, labels=notMan_s_count.index, autopct='%0f%%')
plt.title('非男士各小类销售量占比')
plt.tight_layout()
plt.show()
def run():
basic_config() # 基本配置
df = read_data('./双十一淘宝美妆数据.csv') # 读取数据
data_clean(df) # 进行数据清洗
column_process(df) # 进行相关列的处理
# draw_bar_of_shop_category(df) # x店铺名 y商品大类别数量 的柱状图
# # -1- 以店名进行group by > x店铺名 y销售量 - 柱状图
# # -2- 以店名进行group by > x店铺名 y销售额 - 柱状图
# # -3- x销售量 y销售额 - 散点图
# draw_of_sale_money_and_sale_number_by_shop(df)
# # - 各店铺的平均每单价与销售额的关系
# # 1. x店铺名 y店铺平均每单价格 的柱状图
# draw_bar_of_shop_avg_price(df)
# # 2. 单价区间分类 的销售额所占比例 的饼图
# draw_pie_of_price_class_with_sale_money(df)
# # 3. 店铺的销售额所占比例 的饼图,但加上了颜色和图例用于区分 店铺所属的单价区间
# draw_pie_of_shop_sale_money_with_avg_price(df)
# # 4. 单价区间的销售额的均值的柱状图
# draw_bar_of_shop_sales_mean_by_price_class(df)
# - 查看各大类和小类商品的销售额和销量之间的关系
draw_big_small_of_sales(df)
# - 查看男士专用和非男士专用 小类销售量占总销售量
draw_isman_small_with_sale(df)
if __name__ == '__main__':
run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
# 数据清洗
我们先来看看数据集长什么样子. (・_・;
import pandas as pd
df = pd.read_csv('./双十一淘宝美妆数据.csv')
print(df.head(2))
2
3
4
| update_time | id | title | price | sale_count | comment_count | 店名 |
|---|---|---|---|---|---|---|
| 2016/11/14 | A18164178225 | CHANDO/自然堂 雪域精粹纯粹滋润霜50g 补水保湿 滋润水润面霜 | 139.0 | 26719.0 | 2704.0 | 自然堂 |
| 2016/11/14 | A18177105952 | CHANDO/自然堂凝时鲜颜肌活乳液120ML 淡化细纹补水滋润专柜正品 | 194.0 | 8122.0 | 1492.0 | 自然堂 |
对数据集中的字段作如下说明:
-1- update_time(更新时间): 记录产品数据的更新时间, 以日期格式表示.
-2- id(产品ID): 每个美妆产品的唯一标识符.
-3- title(产品标题): 包含了美妆产品的名称和描述信息.
-4- price(产品价格): 产品的价格, 以人民币(RMB)为单位.
-5- sale_count(销售数量): 产品的销售数量, 表示已售出的产品数量.
-6- comment_count(评论数量): 产品收到的评论数量.
-7- 店名(店铺名称): 销售该美妆产品的店铺名称.
# 重复值清洗
>>> df.duplicated().head() # 检测重复的行数据
0 False
1 False
2 False
3 False
4 False
dtype: bool
>>> df.duplicated().sum() # 获取重复行的个数
86
>>> df.drop_duplicates(inplace=True) # 删除重复行的数据,注:会保留第一个重复行
>>> # 解决删除重复行后,行索引不是连续的问题. drop=True表明不要将乱序的行索引作为一列
>>> df.reset_index(drop=True,inplace=True)
2
3
4
5
6
7
8
9
10
11
12
# 缺失值清洗
我们通过df.shape 、 df.info() 命令来看看每个字段数据的数据类型以及判断是否存在缺失值:
>>> df.shape
(27598, 7)
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27512 entries, 0 to 27511
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 update_time 27512 non-null object
1 id 27512 non-null object
2 title 27512 non-null object
3 price 27512 non-null float64
4 sale_count 25162 non-null float64 # 27512-25162==2350
5 comment_count 25162 non-null float64 # 27512-25162==2350
6 店名 27512 non-null object
dtypes: float64(3), object(4)
memory usage: 1.5+ MB
>>> df.isnull().sum(axis=0) # 统计每一列有多少个缺失值
update_time 0
id 0
title 0
price 0
sale_count 2350
comment_count 2350
店名 0
dtype: int64
>>> # 因为缺失值全部是关于sale_count(销售数量)和comment_count(评论数量)的,所以我们将缺失值全部填充为0
>>> df.fillna(value=0,inplace=True)
>>> df.isnull().sum(axis=0).sum()
0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 列处理
# title列相关
title是对商品进行描述, 并没有特指出商品的属性、类别等信息..
为了后续方便 剖析 "对于美妆产品大多数人购买的产品类别是什么" 这一个问题, 我们需要对title类进行处理..
# Step1: 化妆品文本处理
去网上找 关于"化妆品的大类别小类别以及关键词"的文本
# 化妆品相关文本 第一列是大类,第二列是小类,后面的都是关键词
basic_data = """
护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
护肤品 眼部护理类 眼霜 眼部 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素 精华
护肤品 防晒类 防晒
护肤品 补水类 补水
化妆品 口红类 唇釉 口红 唇彩 唇膏
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 眉笔
化妆品 修容类 鼻影 修容粉 高光 腮红
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
化妆品文本处理代码如下:
""" 需求: 想达到的效果是这样的
以basic_data的第一行数据为例 - 护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
转换成
{'乳液': ('护肤品', '乳液类'), '美白乳': ('护肤品', '乳液类'),..}
"""
import jieba
dcatg = {} # eg: {'乳液': ('护肤品', '乳液类'), '美白乳': ('护肤品', '乳液类'),..}
for line in basic_data.split('\n'):
parts = line.split(' ')
if len(parts) < 3:
continue # 忽略格式不正确的行
main_catg = parts[0]
sub_catg = parts[1]
keywords = parts[2:]
# 你可能会担心文本中有相同的关键字,no,你细看一下,是没有的,Hhhh
dcatg.update({keyword: (main_catg, sub_catg) for keyword in keywords})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Step2: jieba分词
subtitle = [] # 将title分词的结果保存到该列表中
for title in df['title']:
ret = list(jieba.cut(title))
subtitle.append(ret)
df['subtitle'] = subtitle
"""
0 [CHANDO, /, 自然, 堂, , 雪域, 精粹, 纯粹, 滋润霜, 50g, , 补水, 保湿, , 滋润, 水润, 面霜]
1 [CHANDO, /, 自然, 堂, 凝, 时鲜, 颜肌活, 乳液, 120ML, , 淡化, 细纹, 补水, 滋润, 专柜, 正品]
2 [CHANDO, /, 自然, 堂, 活泉, 保湿, 修护, 精华, 水, (, 滋润, 型, 135ml, , 补水, 控油, 爽肤水]
Name: subtitle, dtype: object
"""
print(df['subtitle'].head(3))
2
3
4
5
6
7
8
9
10
11
12
# Step3: 添加大类列小类列
结合第一步和第二步的结果给df添加大类和小类两列.
def get_type(subtitles):
# 遍历dcatg中的每个元素,找到第一个匹配的关键字
for keyword in subtitles:
if keyword in dcatg:
return dcatg[keyword]
return '其他', '其他'
temp = df['subtitle'].apply(get_type)
"""
0 (护肤品, 面霜类)
1 (护肤品, 乳液类)
2 (护肤品, 精华类)
3 (护肤品, 清洁类)
4 (护肤品, 面霜类)
Name: subtitle, dtype: object
"""
print(temp.head())
# [('护肤品', '面霜类'), ('护肤品', '乳液类'), ('护肤品', '精华类')]
print(temp.tolist()[:3])
"""
0 1
0 护肤品 面霜类
1 护肤品 乳液类
2 护肤品 精华类
3 护肤品 清洁类
4 护肤品 面霜类
"""
# 等同于 temp.apply(pd.Series).head()
print(pd.DataFrame(temp.tolist()).head())
df[['main_type', 'sub_type']] = pd.DataFrame(temp.tolist())
"""
main_type sub_type
0 护肤品 面霜类
1 护肤品 乳液类
"""
print(df[['main_type', 'sub_type']].head(2))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# Step4: 是否是男性专用列
def is_man_use(s_list):
if '男士' in s_list or '男生' in s_list:
return '是'
elif '男' in s_list and '女' not in s_list and '斩男' not in s_list:
return '是'
else:
return '否'
df['是否男生专用'] = df['subtitle'].apply(is_man_use)
2
3
4
5
6
7
8
9
# 添加销售额列
df['销售额'] = df['price'] * df['sale_count']
# 添加店铺所属单价区间列
# 各店铺平均每单价=店铺销售总额/店铺销售总数量 --> 得一Series对象 > index店名 value店铺平均每单价
shop_avg_price = (df.groupby('店名')['销售额'].sum() / df.groupby('店名').sale_count.sum()).sort_values()
# 按照0-100,100-200,200-300,300的区间给 店铺平均每单价 划分成四类 分别对应 ABCD
A = shop_avg_price[(shop_avg_price <= 100) & (shop_avg_price > 0)].index
B = shop_avg_price[(shop_avg_price <= 200) & (shop_avg_price > 100)].index
C = shop_avg_price[(shop_avg_price <= 300) & (shop_avg_price > 200)].index
D = shop_avg_price[shop_avg_price > 300].index
# 创建一个字典将类别映射到对应的店名,并将信息添加到df表格中
category_map = {}
category_map.update({name: 'A' for name in A})
category_map.update({name: 'B' for name in B})
category_map.update({name: 'C' for name in C})
category_map.update({name: 'D' for name in D})
df['单价区间分类'] = df['店名'].map(category_map) # 将类别映射到 df 中的新列
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我还想了个办法,更简单
shop_avg_price = (df.groupby('店名')['销售额'].sum() / df.groupby('店名')["sale_count"].sum())
def func(x):
if 0<x<=100:
return "A"
elif 100<x<=200:
return "B"
elif 200<x<=300:
return "C"
elif x>300:
return "D"
new_dict = shop_avg_price.apply(func).to_dict()
df['单价区间分类'] = df['店名'].map(new_dict)
df
2
3
4
5
6
7
8
9
10
11
12
13
14
# 数据分析及可视化
由于数据篇幅原因, 我们取一行数据, 转置后先来看看现目前数据是咋样的. df.head(1).T
看完后,接下来进行的数据分析及可视化就有底了.
0
update_time 2016/11/14
id A18164178225
title CHANDO/自然堂 雪域精粹纯粹滋润霜50g 补水保湿 滋润水润面霜
price 139.0
sale_count 26719.0
comment_count 2704.0
店名 自然堂
subtitle [CHANDO, /, 自然, 堂, , 雪域, 精粹, 纯粹, 滋润霜, 50g, , 补水, 保湿, , 滋润, 水润, 面霜]
main_type 护肤品
sub_type 面霜类
是否男生专用 否
销售额 3713941.0
单价区间分类 B
-1- update_time(更新时间): 记录产品数据的更新时间, 以日期格式表示.
-2- id(产品ID): 每个美妆产品的唯一标识符.
-3- title(产品标题): 包含了美妆产品的名称和描述信息.
-4- price(产品价格): 产品的价格, 以人民币(RMB)为单位.
-5- sale_count(销售数量): 产品的销售数量, 表示已售出的产品数量.
-6- comment_count(评论数量): 产品收到的评论数量.
-7- 店名(店铺名称): 销售该美妆产品的店铺名称.
-8- subtitle: title的jieba分词结果.
-9- main_type: 大类别
-10- sub_type: 小类别
-11- 是否男生专用
-12- 销售额
-13- 单价区间分类: 各店铺平均每单价=店铺销售总额/店铺销售总数量
按照平均每单价 0-100,100-200,200-300,300的区间给 店铺 划分成四类 分别对应 ABCD
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 各店铺商品大类别的数量
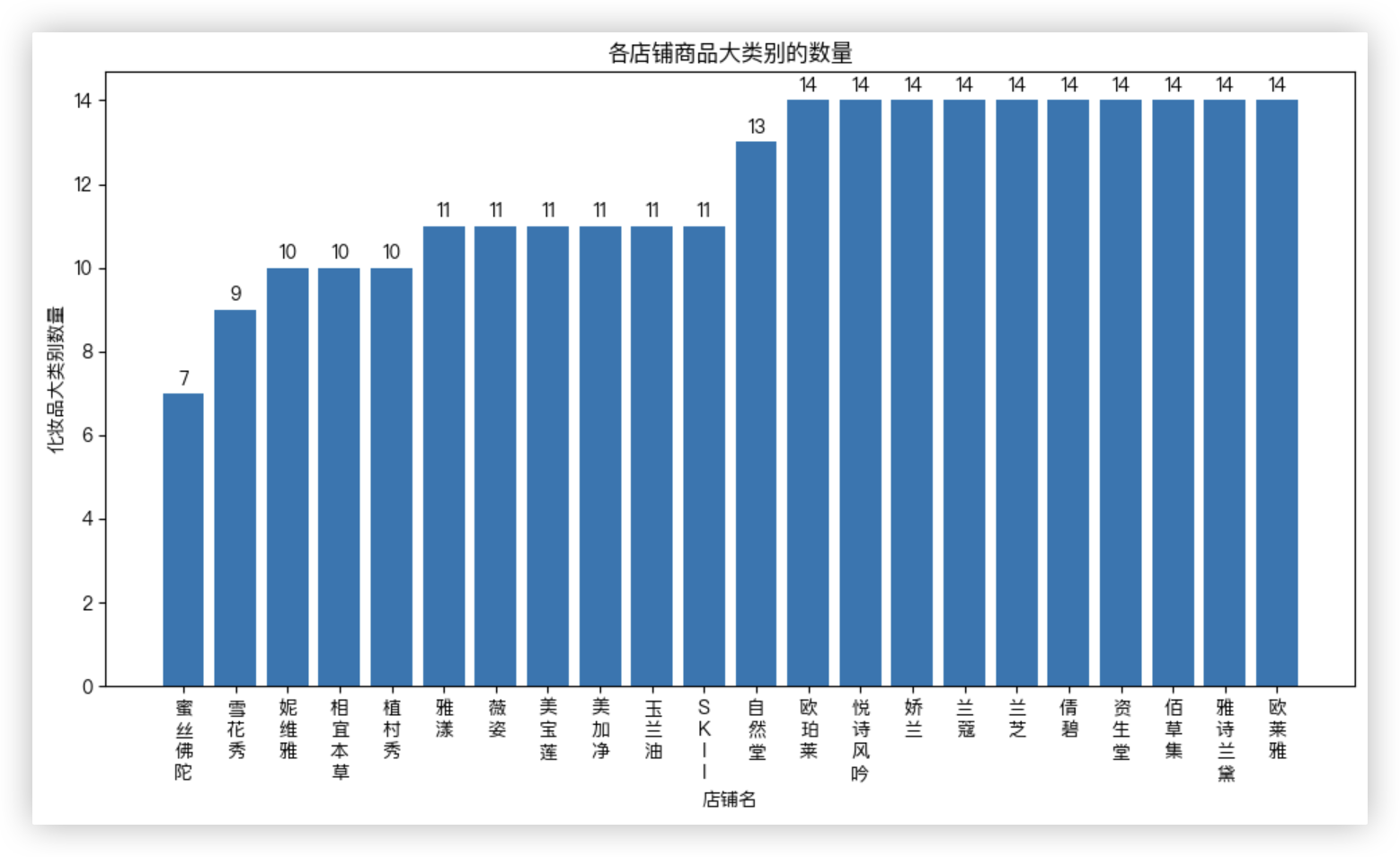
解决思路
针对店名这一列进行进行分组,拿到每个小组里的sub_type大类别这一列,求其去重后的数量..
接着通过sort_values对上一步得到的series对象根据值进行排序.
画柱状图时,注意,横坐标上的文字重叠问题可以通过旋转坐标标签来解决, 但该方法的文字会躺平.
因此 我在画图之前 对店名进行了处理 给每个店名文字中间都加上了换行符 \n . 曲线救国. Hhhh.
shop_count_s = df.groupby(by='店名')['sub_type'].nunique().sort_values()
"""
店名
蜜丝佛陀 7
雪花秀 9
妮维雅 10
相宜本草 10
植村秀 10
Name: sub_type, dtype: int64
"""
print(shop_count_s.head())
# eg: ["新中国","全世界"] 变成 ["新\n中\n国","全\n世\n界"]
x = list(map(lambda s: '\n'.join(s), shop_count_s.index))
y = shop_count_s.values
plt.bar(x, y)
for i, v in enumerate(y):
plt.text(i, v + 0.2, v, ha='center')
plt.xlabel('店铺名')
plt.ylabel('化妆品大类别数量')
plt.title('各店铺商品大类别的数量')
# - 旋转横坐标标签 尽管解决了文字重叠的问题,但文字会躺平.
# plt.xticks(rotation=90)
# - 自动调整子图参数以给标签留出足够的空间
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 各店铺的销量和销售额
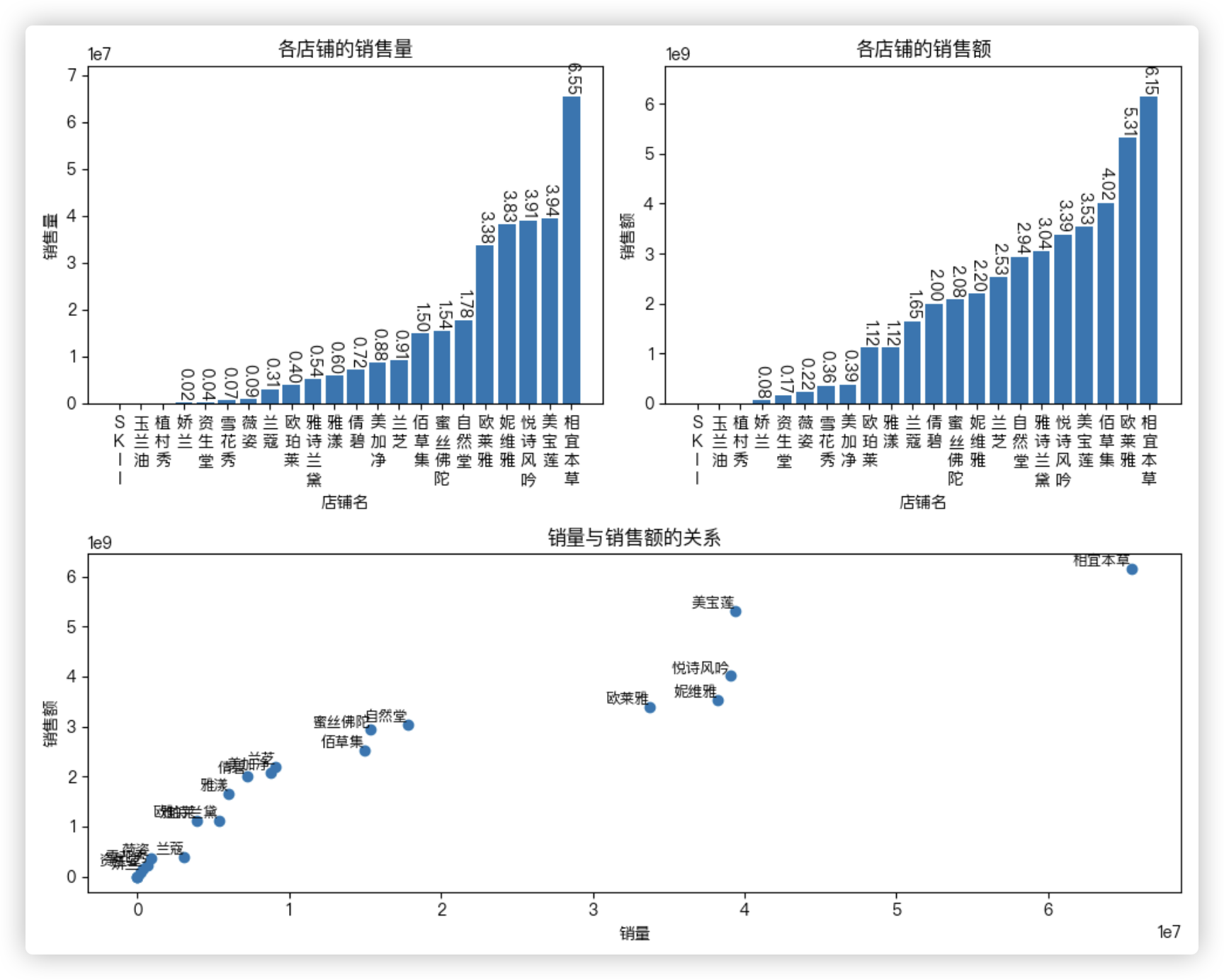
我们观察销量和销售额的散点图,发现 悦诗风吟和美宝莲 的销量差不多的情况下,美宝莲的销售额比悦诗风吟高.
借此,我们可以推断 美宝莲的平均每单单价 应该比 悦诗风吟 的高. (平均每单单价=店铺总销量额/店铺总销量
再结合上面画的各店铺商品大类别数量的柱型图.我们可以得到更多的信息.
eg:相宜本草的大类别数在中游,但其销量和销售额都位列前茅!
2
3
4
5
探究下各店铺销量和销售额的关系, 销量和销售额的求解跟求各店铺大类别的数量 的思路一致, 不再赘述.
但在画图时, 在原有基础上多注意几点, 以销售量为例:
1> 因为销量数字太大, 可以看到纵坐标自动变成了科学记数法, 那么我们在给柱子标注文字时也用科学记数法且只保留数字.
2> 标注时超出了图型最上面的那个框框, 不是很美观, 那么就调整下 y 轴范围,增加上限..
3> for循环里写了个continue, 销量为0的柱子就不标注了.
def add_bar_txt(y):
"""当y轴上的刻度用了科学记数法时,我们在柱子上的标注也用科学记数法"""
# 比如销量上百万了,肯定用会用科学计数法
# 1. 获取画图时,y轴上的自动标注的单位 eg:科学记数法的 e7 """
ax = plt.gca() # 获取当前图形的坐标轴对象
yticks = ax.get_yticks() # 获取纵坐标的刻度值
top_tick = yticks[-1] # 选择最上方的刻度值
exponent = int(np.log10(top_tick)) # eg: 7
# 2. 在柱子上进行标注
for i, v in enumerate(y):
if v == 0:
continue
# eg: 你可以观察图的纵坐标的单位,自动转换成了1e7, 那么我们将v的值除以 1e7 并格式化保留2位小数
plt.text(i, v + 0.1 * (10 ** exponent), f'{v / 10 ** exponent:.2f}', ha='center', rotation=270)
# 调整 y 轴范围,增加上限
plt.ylim(0, max(y) * 1.1) # 将 y 轴的上限设置为最大值的 1.1 倍
plt.subplot(221)
shop_product_s = df.groupby(by='店名')['sale_count'].sum().sort_values()
x = list(map(lambda s: '\n'.join(s), shop_product_s.index))
y = shop_product_s.values
plt.bar(x, y)
add_bar_txt(y) # 科学计数法添加柱子文字
plt.xlabel('店铺名')
plt.ylabel('销售量')
plt.title('各店铺的销售量')
plt.subplot(222)
shop_amount_s = df.groupby(by='店名')['销售额'].sum().sort_values()
x = list(map(lambda s: '\n'.join(s), shop_amount_s.index))
y = shop_amount_s.values
plt.bar(x, y)
add_bar_txt(y) # 科学计数法添加柱子文字
plt.xlabel('店铺名')
plt.ylabel('销售额')
plt.title('各店铺的销售额')
plt.subplot(212)
plt.scatter(shop_product_s, shop_amount_s)
# 为散点图中的每个点添加标注
for i, shop_name in enumerate(shop_product_s.index):
if shop_amount_s[i] == 0:
continue
plt.text(shop_product_s[i], shop_amount_s[i], shop_name,
fontsize=9, ha='right', va='bottom')
plt.xlabel('销量')
plt.ylabel('销售额')
plt.title('销量与销售额的关系')
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 店铺平均每单价格
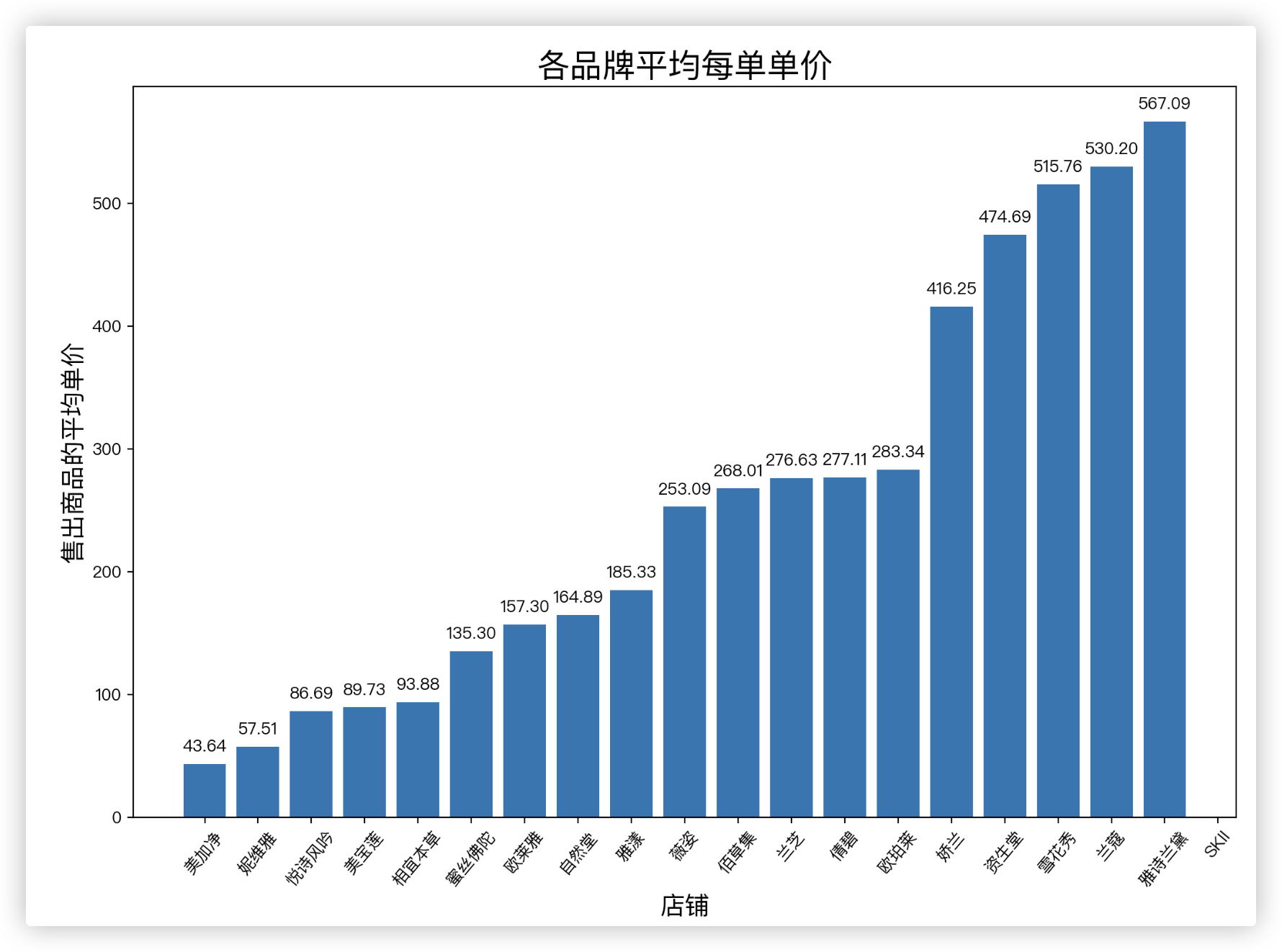
x店铺名 y店铺平均每单价格 的柱状图
# 各店铺平均每单价=店铺销售总额/店铺销售总数量 --> 得一Series对象 > index店名 value店铺平均每单价
shop_avg_price = (df.groupby('店名')['销售额'].sum() / df.groupby('店名').sale_count.sum()).sort_values()
x = shop_avg_price.index
y = shop_avg_price.values
plt.figure(figsize=(12, 8), dpi=200)
plt.bar(x, y)
for i, v in enumerate(y):
plt.text(i, v + 10, f"{v:.2f}", ha='center')
plt.xticks(rotation=50)
plt.title('各品牌平均每单单价', fontsize=20)
plt.xlabel('店铺', fontsize=15)
plt.ylabel('售出商品的平均单价', fontsize=15)
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
# 单价区间的销售额所占比例
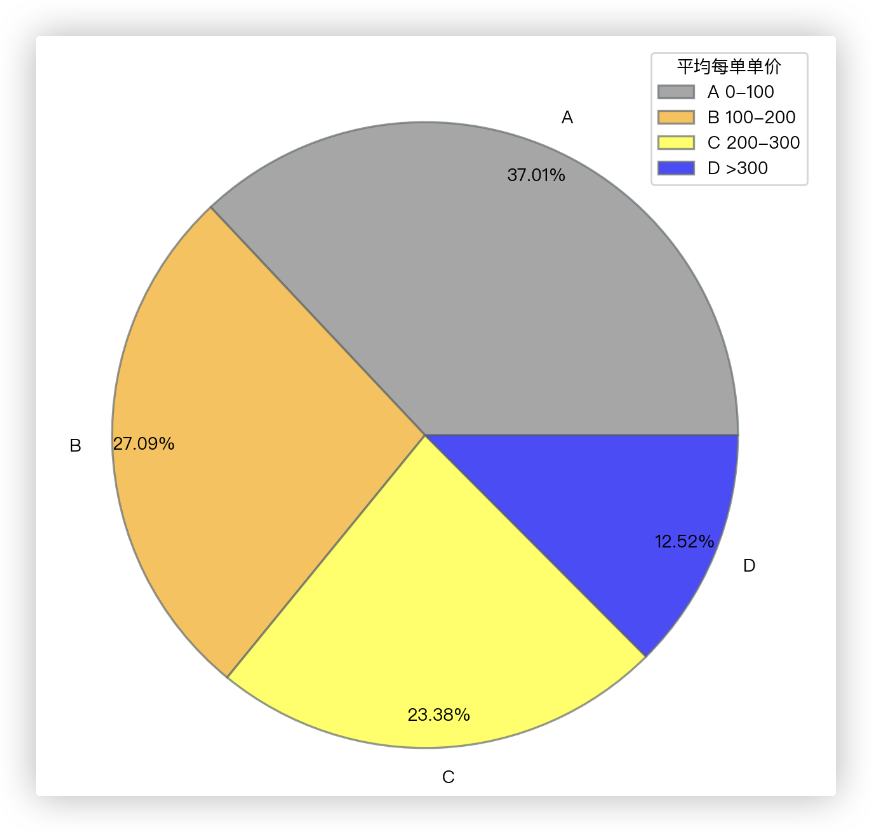
单价区间分类 的销售额所占比例 的饼图
avg_price_class_sale_money = df.groupby(by='单价区间分类')['销售额'].sum()
x = avg_price_class_sale_money
plt.figure(figsize=(12, 8), dpi=200)
plt.pie(x=x,
labels=x.index,
colors=["gray", "orange", "yellow", "blue"],
autopct='%.2f%%',
pctdistance=0.9,
wedgeprops={'linewidth': 1.2, 'edgecolor': '#636e72', 'alpha': 0.7})
legend_labels = ['A 0-100', 'B 100-200', 'C 200-300', 'D >300']
plt.legend(legend_labels, loc='best', title='平均每单单价')
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
# 店铺的销售额饼图+单价区间
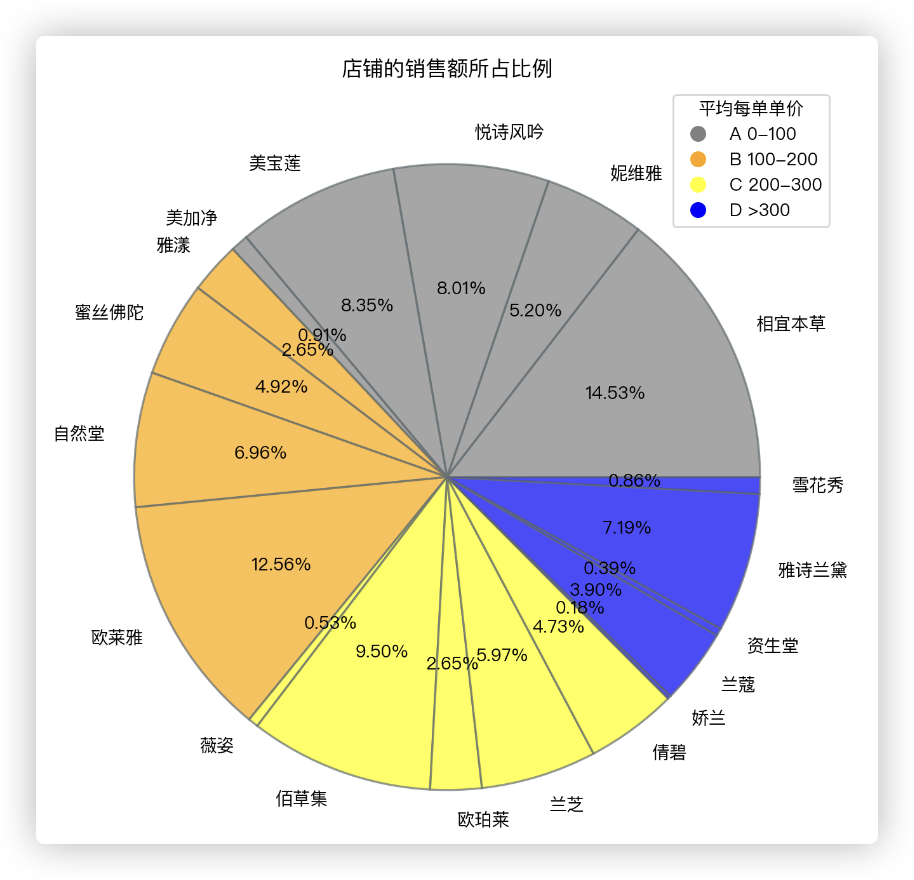
店铺的销售额所占比例 的饼图,但加上了颜色和图例用于区分 店铺所属的单价区间!
sales_sum = df.groupby('店名')['销售额'].sum() # 计算每个店铺的销售额总和
price_category = df.groupby('店名')['单价区间分类'].first() # 获取每个店铺的单价区间
# 合并销售额和单价区间数据 Ps:它两的index都是店名,是一样的,所以合并没毛病!
sales_and_category = pd.DataFrame({
'销售额': sales_sum,
'单价区间分类': price_category
}).reset_index()
sales_and_category.dropna(inplace=True)
sales_and_category.reset_index(drop=True, inplace=True)
# 定义颜色映射
color_map = {'A': 'gray', 'B': 'orange', 'C': 'yellow', 'D': 'blue'}
sales_and_category['颜色'] = sales_and_category['单价区间分类'].map(color_map)
sales_and_category.sort_values(by=['单价区间分类'], inplace=True)
# 绘制饼图
plt.figure(figsize=(12, 8), dpi=200)
plt.pie(
sales_and_category['销售额'],
labels=sales_and_category['店名'],
colors=sales_and_category['颜色'],
autopct='%.2f%%',
wedgeprops={'linewidth': 1.2, 'edgecolor': '#636e72', 'alpha': 0.7}
)
# 自定义饼图的图例文本
legend_labels = ['A 0-100', 'B 100-200', 'C 200-300', 'D >300']
colors = ["gray", "orange", "yellow", "blue"]
handles = []
for color in colors:
temp = plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=color, markersize=10)
handles.append(temp)
plt.legend(handles, legend_labels, loc='best', title='平均每单单价')
plt.title("店铺的销售额所占比例")
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
思考: 波sir在讲解时,不是这样做的.. 他的做法看起来更简单,但我不是很喜欢这样搞, 放在下面作为一个思考吧.
sum_sale = df.groupby(by='店名')['销售额'].sum()
sum_sale_by_price = pd.concat([sum_sale[A].sort_values(),
sum_sale[B].sort_values(),
sum_sale[C].sort_values(),
sum_sale[D].sort_values()])
plt.figure(figsize=(10,7))
plt.pie(x=sum_sale_by_price,
labels =sum_sale_byprice.index ,
colors = ['grey']*len(A)+['orange']*len(B)+['yellow']*len(C)+['blue']*len(D),
autopct='%.2f%%',
pctdistance=0.9)
2
3
4
5
6
7
8
9
10
11
还有个方案:(我更喜欢这个方案!!)
# 单价区间的销售额的均值
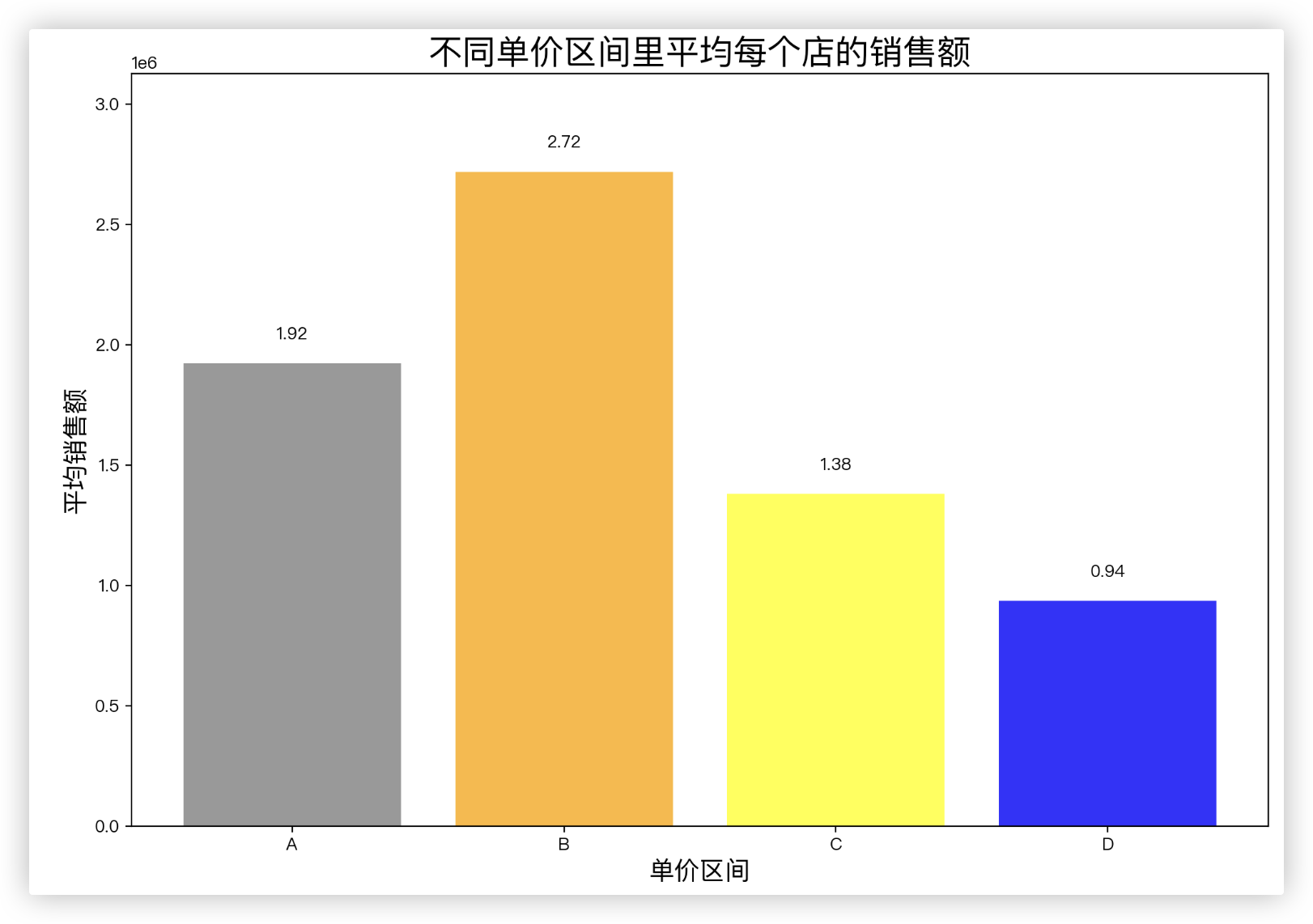
mean_sale = df.groupby(by='单价区间分类')['销售额'].mean()
plt.figure(figsize=(12, 8), dpi=200)
plt.bar(mean_sale.index, mean_sale.values, color=["gray", "orange", "yellow", "blue"], alpha=0.8)
add_bar_txt(mean_sale.values) # 科学计数法添加柱子文字
plt.title('不同单价区间里平均每个店的销售额', fontsize=20)
plt.xlabel('单价区间', fontsize=15)
plt.ylabel('平均销售额', fontsize=15)
plt.show()
2
3
4
5
6
7
8
9
# 一点分析结论
观察饼图,不难发现A类平均单价的品牌所占的销售额比例最高,D类最少.
- 最受欢迎的,相宜本草由于其价格便宜,销售额也最高.
- D类中的一半以上收入都来自于雅诗兰黛品牌.
观察单价区间的销售额的均值 的柱状图.可以大致看到: 定价越低则平均销售额越高.
- A类中的美加净,销售额很低.观察分析其是平均单价最低的品牌.为什么呢?可以考虑几点:
1.商品质量问题,虽然便宜但是是否产品质量过低降低了用户使用体验
2.知名度问题,是否需要提高知名度获取更多点击率以提高销量
3.定价问题,在质量过关的前提下,是否因为定价过低而降低了收益
4.能否在不大幅影响销量的情况下涨价
- 雅诗兰黛平均单价最高,然而销量却在D类中也最高的原因,为什么呢?
1.品牌效应,雅诗兰黛为人熟知,在推广营销方面做的很好,所以销量尚可
2.虽然相对价格较高,但是给使用者带来的使用体验非常好,所以很多消费者宁愿多花钱也要选择雅诗兰黛.
2
3
4
5
6
7
8
9
10
11
12
13
# 大类小类的销量与销售量
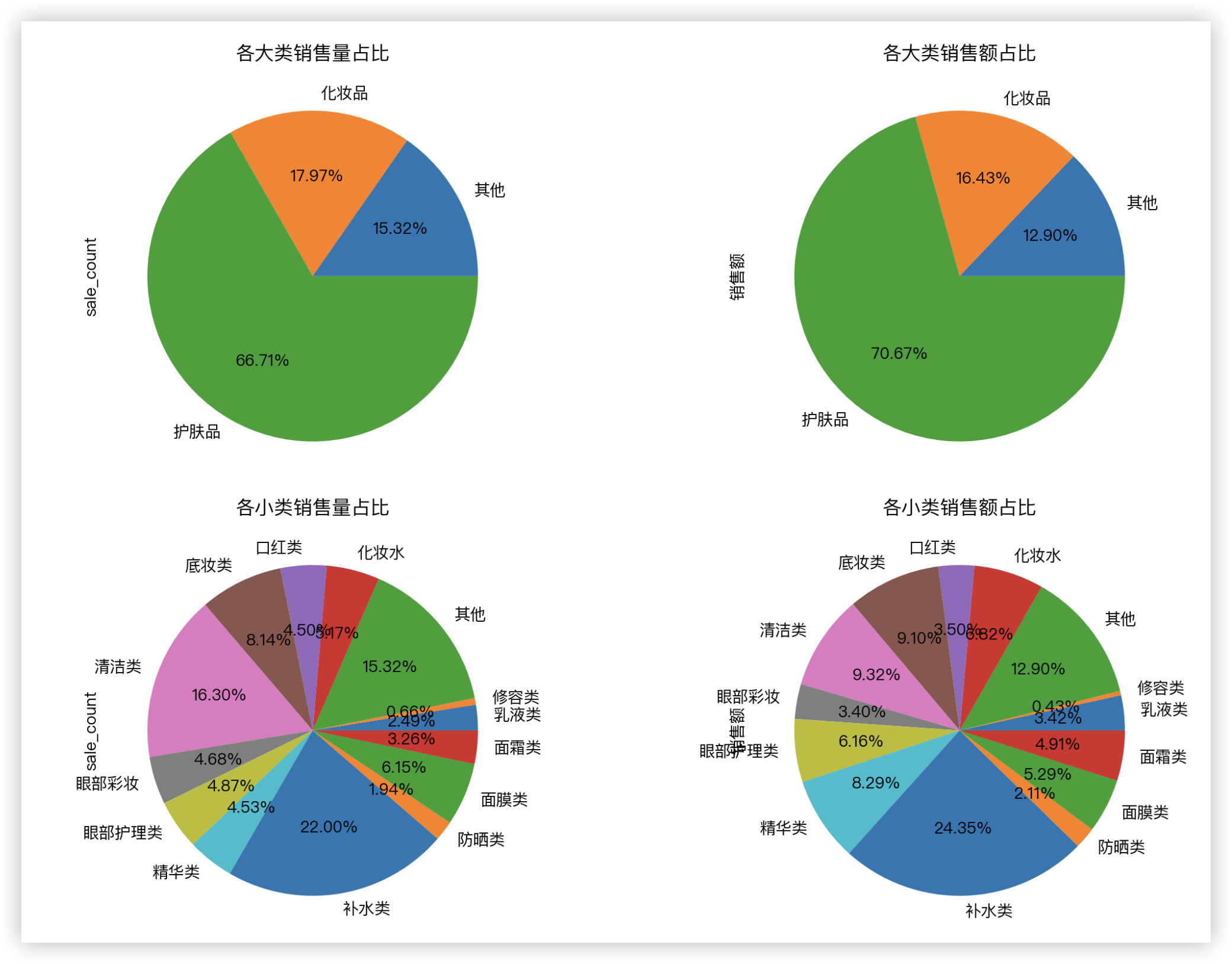
查看各大类和小类商品的销售额和销量之间的关系.
通过观察比较各个类销售量与销售额占比的关系, 基本可以判断他们是正相关的. 这也是符合常识的.
在大类中, 护肤品的销量远胜化妆品以及其他商品. 而在小类之中, 补水类的护肤品销量最高, 其次是清洁类的护肤品.
plt.figure(figsize=(12, 8), dpi=200)
# 各大类销售量占比
plt.subplot(2, 2, 1)
df.groupby('main_type')["sale_count"].sum().plot.pie(autopct='%.2f%%', title='各大类销售量占比')
# 各大类销售额占比
plt.subplot(2, 2, 2)
df.groupby('main_type')['销售额'].sum().plot.pie(autopct='%.2f%%', title='各大类销售额占比')
# 各小类销售量占比
plt.subplot(2, 2, 3)
df.groupby('sub_type')["sale_count"].sum().plot.pie(autopct='%.2f%%', title='各小类销售量占比')
# 各小类销售额的占比
plt.subplot(2, 2, 4)
df.groupby('sub_type')['销售额'].sum().plot.pie(autopct='%.2f%%', title='各小类销售额占比')
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 是否男生专用小类销售量占比
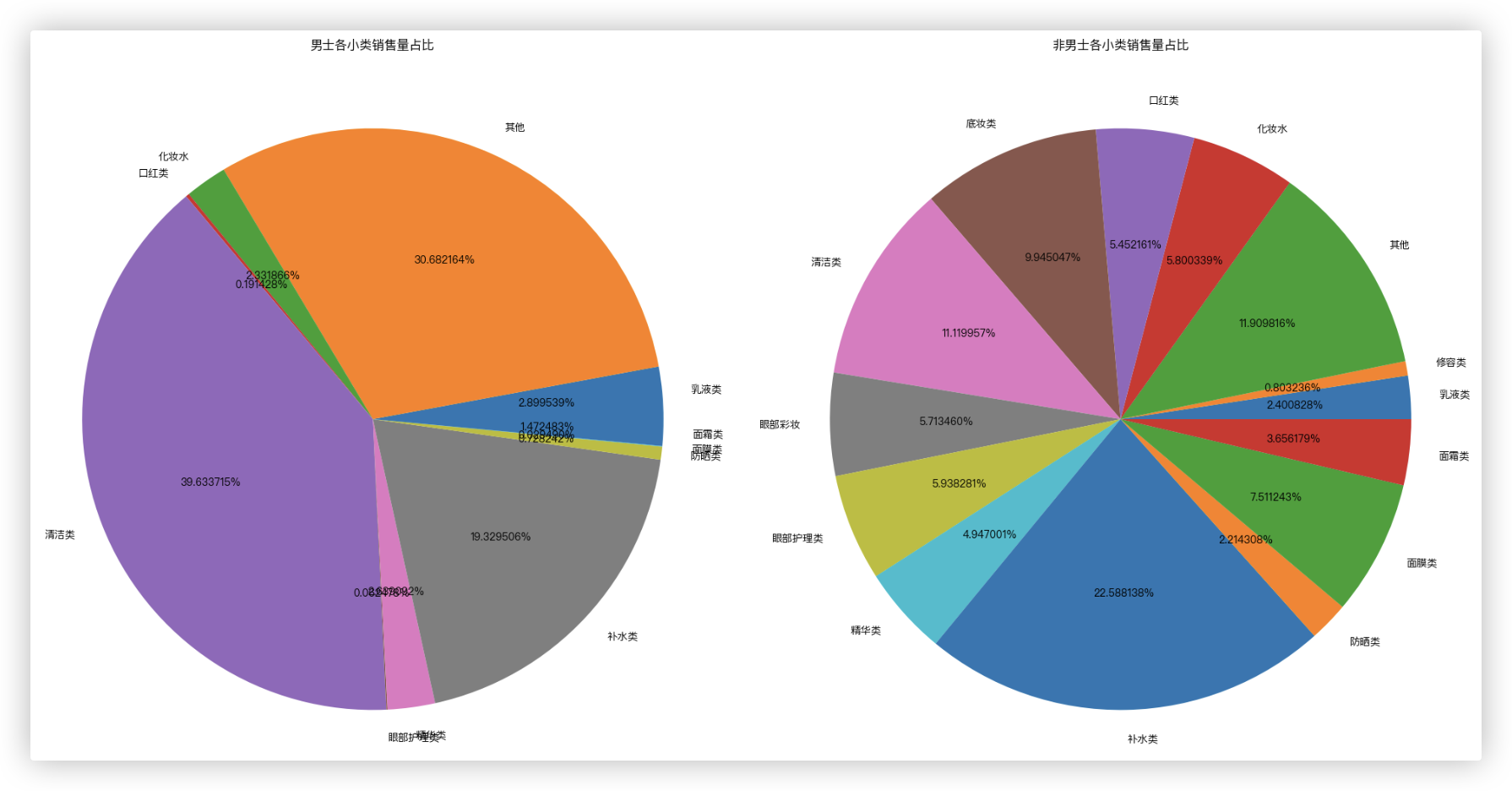
可以看到男士的销量基本来自于清洁类, 其次是补水类. 而这两类正是总销量中占比最高的两类.
非男士专用中, 补水类成为了销量最高的类别, 清洁类降到了第3位.
isMan = df.loc[df['是否男生专用'] == '是']
notMan = df.loc[df['是否男生专用'] == '否']
isMan_s_count = isMan.groupby(by='sub_type')['sale_count'].sum()
notMan_s_count = notMan.groupby(by='sub_type')['sale_count'].sum()
plt.figure(figsize=(20, 20))
plt.subplot(1, 2, 1)
plt.pie(isMan_s_count.values, labels=isMan_s_count.index, autopct='%0f%%')
plt.title('男士各小类销售量占比')
plt.subplot(1, 2, 2)
plt.pie(notMan_s_count.values, labels=notMan_s_count.index, autopct='%0f%%')
plt.title('非男士各小类销售量占比')
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16