 ★逻贝SH决
★逻贝SH决
# 逻辑回归
# 模型参数和使用
from sklearn.linear_model import LogisticRegression
超参数介绍:
penalty
- 可以输入l1 或者 l2 来指定使用哪一种正则化方式. 不填写默认"l2".
注意, 若选择"l1"正则化, 参数solver仅能够使用求解方式 "liblinear"和"saga";
若使用"l2" 正则化, 参数solver中所有的求解方式都可以使用.
- 可以输入l1 或者 l2 来指定使用哪一种正则化方式. 不填写默认"l2".
C
- 惩罚项, 也就是正则化公式中的λ, 用来控制正则化力度的大小. 值0~1 1~+∞
- 增大 C 会使得系数更加趋向于 0, 从而降低训练集性能, 但可能会提高泛化性能;
- 减小 C 可以让系数受到的限制更小.
max_iter
- 梯度下降中能走的最大步数, 默认值为100.
步数的不同取值可以帮助我们获取不同的损失函数的损失值.
目前没有好的办法可以计算出最优的max_iter的值, 一般是通过绘制学习曲线对其进行取值.
- 梯度下降中能走的最大步数, 默认值为100.
solver
- sklearn为我们提供了多种选择, 让我们可以使用不同的求解器来计算逻辑回归的最小损失.
求解器的选择, 由参数"solver"控制, 共有五种选择. - solver选值的经验分享:
- 常见选择可以是使用 "liblinear二分类" 或 "lbfgs多分类" 算法作为初始选择.
- 对于大规模数据集, "lbfgs"、"sag" 或 "saga" 可能更适合.
- sklearn为我们提供了多种选择, 让我们可以使用不同的求解器来计算逻辑回归的最小损失.
| 求解器 | liblinear | lbfgs | newton-cg | sag | saga |
|---|---|---|---|---|---|
| 求解方式 | 梯度下降 | 似牛顿法的一种, 利用损失函数二阶导数矩阵来迭代优化损失函数 | 牛顿法的一种, 利用海森矩阵来迭代优化损失函数 | 随机平均梯度下降, 与普通梯度下降的区别是, 每次迭代仅仅用一部分样本来计算梯度 | 随机平均梯度下降的进化 |
| 支持的惩罚项 | L1, L2 | L2 | L2 | L2 | L1, L2 |
| 应用场景 | 适用于二分类问题 | 可以有效地解决多类别分类问题, 尤其在大规模数据集上表现优秀 | 可用于求解多类别分类问题 | 适用于大规模数据集的二分类问题中 | 用于多类别分类问题 |
multi_class
- 输入"ovr", "multinomial", "auto"来告知模型, 我们要处理的分类问题的类型.
- "ovr"(One-vs-Rest): 这是最常用的一种multi_class策略.
它将多类别分类问题转化为多个二分类问题, 每个类别与其他类别进行区分.
它在多类别问题上的表现良好,并且适用于各种规模的数据集.
在sklearn中, 当solver为"liblinear"时, "ovr"是唯一可选的multi_class策略. - "multinomial":这是一种直接解决多分类问题的策略(softmax).
它在处理多类别分类问题上较为准确, 并且可以避免转化为多个二分类问题带来的问题.
在sklearn中, 当solver为"lbfgs"、"newton-cg"或"sag"时, "multinomial"是可选的multi_class策略. - "auto":这是根据数据集和模型情况自动选择multi_class策略的选项.
它会根据具体情况选择适合的策略, 通常会根据solver的值以及输入数据的特征维度等因素进行选择.
- "ovr"(One-vs-Rest): 这是最常用的一种multi_class策略.
- 输入"ovr", "multinomial", "auto"来告知模型, 我们要处理的分类问题的类型.
class_weight
- 表示样本不平衡处理的参数. 样本不平衡指的是在一组数据中, 某一类标签天生占有很大的比例或误分类的代价很高.
即我们想要捕捉出某种特定的分类的时候的状况. 什么情况下误分类的代价很高?- 例如, 我们现在要对潜在犯罪者和普通人进行分类, 如果没有能够识别出潜在犯罪者,
那么这些人就可能去危害社会造成犯罪, 识别失败的代价会非常高.
但如果, 我们将普通人错误地识别成了潜在犯罪者, 代价却相对较小.
所以我们宁愿将普通人分类为潜在犯罪者后再人工甄别, 但是却不愿将潜在犯罪者 分类为普通人.
有种"宁愿错杀不能放过"的感觉. - 再比如说, 在银行要判断 "一个新客户是否会违约".
通常不违约的人vs违约的人会是99:1的比例,真正违约的人其实是非常少的.
这种分类状况下, 即便模型什么也不做, 全把所有人都当成不会违约的人, 正确率也能有99%.
这使得模型评估指标变得毫无意义, 根本无法达到我们的"要识别出会违约的人"的建模目的.
- 例如, 我们现在要对潜在犯罪者和普通人进行分类, 如果没有能够识别出潜在犯罪者,
- balanced
- 我们要使用参数class_weight对样本标签进行一定的均衡, 给少量的标签更多的权重, 让模型更偏向少数类,
向捕获少数类的方向建模. 当误分类的代价很高的时候, 我们使用"balanced"模式, 可以解决样本不均衡问题.
- 我们要使用参数class_weight对样本标签进行一定的均衡, 给少量的标签更多的权重, 让模型更偏向少数类,
- None
- 此模式表示自动给与数据集中的所有标签相同的权重, 即自动1: 1
- 表示样本不平衡处理的参数. 样本不平衡指的是在一组数据中, 某一类标签天生占有很大的比例或误分类的代价很高.
# 逻辑回归的应用
逻辑回归在乳腺癌数据集的应用
model.predict_proba() 样本在每个类别上的概率
model.score() 是准确率
可通过log_loss函数求交叉熵的值!
2
3
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import pandas as pd
import sklearn.datasets as dt
data = dt.load_breast_cancer()
feature = data.data
target = data.target
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
model = LogisticRegression(penalty='l2',
max_iter=100,
solver='liblinear',
C=1,
multi_class='auto',
class_weight=None)
model.fit(x_train,y_train)
print(model.score(x_test,y_test)) # 0.9736842105263158
model = LogisticRegression(multi_class='auto')
model.fit(x_train,y_train)
print(model.score(x_test,y_test)) # 0.9736842105263158 准确率
"""逻辑回归与knn分类进行对比!! 逻辑回归胜出!!"""
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)
print(knn.score(x_test,y_test)) # 0.9298245614035088
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 中文新闻分类(贝叶斯)
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import GaussianNB
model = MultinomialNB().
mmodel.theta_ : 一个数组,形状为(n_class,n_features),是每个类别上每个特征的均值.
model.sigma : 一个数组,形状为(n_class,n_features),是每个类别上每个特征的标准差.
model.predict_proba() : 给出每一个测试集样本属于每个类别的概率,最大的就是分类结果.
model.predict_log_proba() : predict_proba的对数转化,最大的就是分类结果.
2
3
4
# 测试过程
# 建模完整实现
其实在该案例中,对新闻进行朴素贝叶斯分类, 标签不用特征值化也是可以的!!
"""文本分类模型"""
import jieba
import joblib
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
class TextClassifier:
def __init__(self, vectorizer=TfidfVectorizer, classifier=MultinomialNB,
vectorizer_params=None, classifier_params=None, stopwords_file=None):
"""
:param vectorizer: 文本向量化器 (CountVectorizer 或 TfidfVectorizer)
:param classifier: 分类器(如 MultinomialNB, LogisticRegression 等)
:param vectorizer_params: 向量化器的参数字典
:param classifier_params: 分类器的参数字典
:param stopwords_file: 停用词文件路径
"""
self.vectorizer = lambda: vectorizer(**(vectorizer_params or {})) # self.vectorizer() 才会得到实例!
self.classifier = lambda: classifier(**(classifier_params or {}))
self.stopwords_set = self._load_stopwords(stopwords_file) if stopwords_file else set()
def _load_stopwords(self, stopwords_file):
"""
加载停用词表,返回停用词集合
:param stopwords_file: 停用词文件路径
:return: 停用词集合
"""
# quoting=3 去除读取数据时,数据内容出现的引号对读取的影响
stopwords = pd.read_csv(stopwords_file, sep="\t", quoting=3, names=['stopword'], encoding='utf-8')
return set(stopwords['stopword'].tolist()) # 使用集合hash结构,过滤停用词时更快!!
def preprocess_text(self, contents):
"""
对输入文本进行jieba分词,jieba分词后,去除停用词
:param contents: 输入文本 (series对象,其元素是一篇篇文章)
:return: 经过停用词过滤后的一维列表
"""
jieba_contents = [jieba.lcut(content) for content in contents] # 分词后的文本二维列表 (eg:[['','',''],['','','']])
# 经过停用词过滤后的二维列表
contents_clean_ = [[word for word in line if word not in self.stopwords_set] for line in jieba_contents]
# 通过join对中文进行拼接,返回一维列表 > 转换成文本向量化要求的格式 eg: ["你好 世界","我 爱 中国"]
contents_clean = [" ".join(item) for item in contents_clean_]
return contents_clean
def label_map(self, labels):
"""
标签映射成数字
:param labels: 标签向量 (series对象,其元素是一篇篇文章的标签)
:return: 经过映射后的一维列表 [0,0,0,1,1,1,2,...]
"""
unique_labels = list(labels.unique()) # 去重后获取有哪些类别
label_mapping = {label: idx + 1 for idx, label in enumerate(unique_labels)} # 使用字典推导式生成类别到编号的映射
return labels.map(label_mapping).to_list(), label_mapping
def split_data(self, contents_series, labels_series, test_size=0.2, random_state=1):
"""
切分数据集 并将label_mapping保存到本地
:param contents_series: 从df中获取到文本向量 (series对象,其元素是一篇篇文章的文本/字符串)
:param labels_series: 从df中获取到标签向量 (series对象,其元素是一篇篇文章的标签)
:param test_size: 测试集比例 (默认0.2)
:param random_state: 随机种子 (默认1)
:return: 包含训练集和测试集的文本向量和标签向量的对象
"""
contents_clean_ = self.preprocess_text(contents_series)
labels_map_, label_mapping = self.label_map(labels_series)
joblib.dump(label_mapping, 'label_mapping.pkl')
return train_test_split(contents_clean_, labels_map_, test_size=test_size, random_state=random_state)
def train_and_save_model(self, x_train, x_test, y_train, y_test, save=False):
"""
训练模型并保存模型到本地
:param x_train: 训练文本
:param x_test: 测试文本
:param y_train: 训练标签
:param y_test: 测试标签
:param max_features: 文本向量化的最大特征数
:return: 返回模型训练的得分
"""
vectorizer = self.vectorizer()
X_train = vectorizer.fit_transform(x_train) # -- fit找寻规律再transform特征值化
X_test = vectorizer.transform(x_test)
classifier = self.classifier()
classifier.fit(X_train, y_train)
train_score = classifier.score(X_train, y_train)
test_score = classifier.score(X_test, y_test)
if save:
joblib.dump(vectorizer, 'vectorizer.pkl')
joblib.dump(classifier, 'model.pkl')
return train_score, test_score
def evaluate(self, contents_series, labels_series):
"""
传入新样本数据,加载已训练好的模型,进行评估
:param contents_series: 从df中获取到文本向量 (series对象,其元素是一篇篇文章的文本/字符串)
:param labels_series: 从df中获取到标签向量 (series对象,其元素是一篇篇文章的标签)
:return: 预测的标签列表
"""
vectorizer = joblib.load('vectorizer.pkl')
classifier = joblib.load('model.pkl')
label_mapping = joblib.load('label_mapping.pkl')
X = self.preprocess_text(contents_series)
y = [label_mapping[label] for label in labels_series.values]
X = vectorizer.transform(X) # 用模型中已经找到的规律直接transform特征值化
print("模型分类结果:", classifier.predict(X))
print("样本真实结果:", y)
print("评分:", classifier.score(X, y))
print(classifier.predict_proba(X)) # 给出每一个测试集样本属于每个类别的概率,最大的就是分类结果.
if __name__ == '__main__':
# - 训练模型并保存模型到本地!!
model = TextClassifier(
vectorizer=TfidfVectorizer,
classifier=MultinomialNB,
vectorizer_params={"max_features": 5000},
classifier_params={"alpha": 0.5},
stopwords_file="停用词/stopwords.txt"
)
df_news = pd.read_table('data.txt', names=['category', 'theme', 'URL', 'content'], encoding='utf-8')
x_train, x_test, y_train, y_test = model.split_data(df_news['content'], df_news['category'])
train_score, test_score = model.train_and_save_model(x_train, x_test, y_train, y_test, save=True)
print("训练集准确率:", train_score, "测试集准确率:", test_score)
# - 加载已训练好的模型,用新数据进行评估!!
model = TextClassifier(
vectorizer=TfidfVectorizer,
classifier=MultinomialNB,
vectorizer_params={"max_features": 5000},
classifier_params={"alpha": 0.5},
stopwords_file="停用词/stopwords.txt"
)
df_news_test = pd.read_table(
'data_test.txt', names=['category', 'theme', 'URL', 'content'], encoding='utf-8')
model.evaluate(df_news_test['content'], df_news_test['category'])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
# 分类模型评价指标
看结果这几个指标的值都差不多,证明标签分布并非不平衡, 求证了下 357:212 分布较均匀..
如果你没有明确指定 f1_score 的 pos_label 参数, Scikit-learn 会将类别标签中的较大的那个值(通常是 1)视为正类.
如果你想明确指定, 可以设置 pos_label=1.. eg: f1_score(y_true, y_pred, pos_label=1)
from sklearn.metrics import recall_score,f1_score,accuracy_score
from sklearn.linear_model import LogisticRegression
import sklearn.datasets as dt
from sklearn.model_selection import train_test_split
data = dt.load_breast_cancer()
feature = data.data
target = data.target
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
model = LogisticRegression(solver='liblinear')
model.fit(x_train,y_train)
pd.Series(target).value_counts()
"""
1 357
0 212
dtype: int64
"""
model.score(x_test,y_test) # 正确率 0.9736842105263158
y_true = y_test
y_pred = model.predict(x_test)
accuracy_score(y_true,y_pred) # 精确率 0.9736842105263158
recall_score(y_true,y_pred) # 召回率 0.9848484848484849
f1_score(y_true,y_pred) # f1_score 0.9774436090225563
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 分类模型评价分析报告
classification_report是sklearn.metrics模块中的一个函数. 用于生成基于混淆矩阵的分类模型评价指标分析报告.
该函数根据模型的实际分类结果和预测结果,
计算并生成包括准确率(accuracy)、召回率(recall)、精确率(precision)、F1-score和支持数量(support)等指标!
from sklearn.metrics import classification_report
# 实际分类结果
y_true = [0, 1, 0, 1, 1, 0, 0, 1]
# 模型预测结果
y_pred = [0, 0, 0, 1, 1, 0, 1, 1]
# 根据混淆矩阵生成分类模型评价指标分析报告
report = classification_report(y_true, y_pred)
print("Classification Report:")
print(report)
"""
Classification Report:
precision recall f1-score support
0 0.75 0.75 0.75 4
1 0.75 0.75 0.75 4
accuracy 0.75 8
macro avg 0.75 0.75 0.75 8
weighted avg 0.75 0.75 0.75 8
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# SVM的API - 分类
- sklearn.svm.SVC()
- 常用的模型超参数:
- C: 控制松弛系数 ζ 的大小.
较小的C值会导致较大的松弛系数 ζ, 反之亦然.
当C值较大时. 模型更加注重将样本正确分类, 而当C值较小时, 模型相对更容忍错误分类和间隔. - kernel: 选择核函数
- degreeL: 专用于poly多项式核函数, 控制了多项式的度, 较高的度数意味着更复杂的决策边界.
- gamma: 专用于rbf高斯核函数. 用于调整高斯核函数的效果, 0-1之间的取值.
- max_iter: 用于设置迭代的最大次数. 它的作用是限制算法在训练过程中迭代的最大次数, 以防止算法在某些情况下无限迭代.
如果max_iter取值过小, 可能导致算法不能充分优化模型, 导致模型的性能下降.
如果max_iter取值过大, 可能会增加算法的计算时间, 尤其是在大规模数据集上. - class_weight: 用于处理不平衡数据集的情况. 可以取值None或者balanced.
- None: 默认取值, 表示所有类别的样本具有相同的权重, 即不进行样本权重的调整.
- balanced: 表示自动调整样本权重, 使得不同类别的样本在训练过程中的权重与其在整个训练集中的比例成反比.
这个选项适用于类别不平衡的情况.
- C: 控制松弛系数 ζ 的大小.
在乳腺癌数据集(这是一个线性可分的简单数据集)中测试4种核函数的表现.
观察评价指标,你可以发现不管选哪个核函数,在该核函数下,那几个评价指标的值都差不多,证明 [数据标签] 的分布较均匀!!
然后 观察到linear比rbf 的f1指标要高.. (印象中哪怕数据是线性可分的,rbf的f1也应该比linear好,所以实际与理论是有出入的)
from sklearn import datasets as dt
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report
data = dt.load_breast_cancer()
feature = data.data
targt = data.target
x_train,x_test,y_train,y_test = train_test_split(feature,targt,test_size=0.2,random_state=2020)
kernel_list = ["rbf","linear","poly","sigmoid"]
for kernel in kernel_list:
model = SVC(kernel=kernel)
model.fit(x_train,y_train)
y_true = y_test
y_pred = model.predict(x_test)
print("核函数:",kernel)
print(classification_report(y_true, y_pred))
print(f1_score(y_true,y_pred,pos_label=1))
print("------------")
"""
核函数: rbf
precision recall f1-score support
0 0.95 0.83 0.89 48
1 0.89 0.97 0.93 66
accuracy 0.91 114
macro avg 0.92 0.90 0.91 114
weighted avg 0.92 0.91 0.91 114
0.927536231884058
------------
核函数: linear
precision recall f1-score support
0 0.98 0.98 0.98 48
1 0.98 0.98 0.98 66
accuracy 0.98 114
macro avg 0.98 0.98 0.98 114
weighted avg 0.98 0.98 0.98 114
0.9848484848484849
------------
核函数: poly
precision recall f1-score support
0 0.93 0.81 0.87 48
1 0.88 0.95 0.91 66
accuracy 0.89 114
macro avg 0.90 0.88 0.89 114
weighted avg 0.90 0.89 0.89 114
0.9130434782608695
------------
核函数: sigmoid
precision recall f1-score support
0 0.23 0.15 0.18 48
1 0.51 0.64 0.56 66
accuracy 0.43 114
macro avg 0.37 0.39 0.37 114
weighted avg 0.39 0.43 0.40 114
0.5637583892617449
------------
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
那有什么办法可以提升rbf的f1指标的值吗? 有!! 进行无量纲化, 统一每个特征的规格大小..
观察分析训练集的数据分布情况, 可以发现数据集的分布是不均匀的!! (前面我们说的是 数据标签的分布均匀,别混淆了!!)
看结果, 进行无量钢化后, 好了很多!!
from sklearn import datasets as dt
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.preprocessing import MinMaxScaler
data = dt.load_breast_cancer()
feature = data.data
targt = data.target
tool = MinMaxScaler()
m_feature = tool.fit_transform(feature)
x_train,x_test,y_train,y_test = train_test_split(m_feature,targt,test_size=0.2,random_state=2020)
kernel_list = ["rbf","linear","poly","sigmoid"]
for kernel in kernel_list:
model = SVC(kernel=kernel)
model.fit(x_train,y_train)
y_true = y_test
y_pred = model.predict(x_test)
print(f1_score(y_true,y_pred))
"""
0.9696969696969697
0.9696969696969697
0.9692307692307692
0.46258503401360546
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# SVM实现人脸识别
主要是想清楚,如何将人脸数据进行训练..
每张人脸上的每个像素点都是rgb三通道. 每张图片有n行m列个像素点.. 那么一张图片就是三维的, 形状 (n,m,3)..
我们取每张图片红色通道的数据, 一张图片就从三维变为二维的了.. 形状 (n,m)
但这还不够, 在训练集的特征矩阵上, 一张图片应该就是一行数据, 所以还需要reshape降维. 形状 (n*m, )
最后, 构建的特征矩阵的形状 (一共有多少张图片,n*m)
import numpy as np
import os
import matplotlib.pyplot as plt
from sklearn.svm import SVC
feature = [] # 保存特征数据
target = [] # 保存标签数据
# 获取每一个人名对应的文件夹名称,完整的图片路径 eg: './faces/刘梅/3.bmp'
# listdir作用是可以将一个文件夹下所有文件的名称获取
# faces文件夹里有40个文件夹,每个文件夹就是一个人的人脸数据,且里面包含有10张图片!!
names = os.listdir('./faces') # ['黄凤兰', '齐玉梅', '王娟', '刘梅', '张琳',...]
for name in names:
for index in range(10): # index的取值范围是0-9
img_path = './faces/'+name+'/'+str(index)+'.bmp'
# 根据图片路径将图片的像素点数据进行读取,它是三维的,每个像素点都有rgb三个通道
img_arr = plt.imread(img_path)
# 过滤图片的颜色通道 [:,:,0]提取红色通道,即只保留每个像素点的红色分量.
img_arr = img_arr[:,:,0] # 现在是二维的(64,64)
feature.append(img_arr)
target.append(name)
feature = np.array(feature)
target = np.array(target)
# 查看所有人脸图片 40人每人10张,也就是400张图片
plt.figure(figsize=(20,20))
i = 0
for img in feature:
plt.subplot(20,20,i+1)
i+=1
plt.imshow(img)
# 查看特征数据的形状
print(feature.shape) # (400, 64, 64)
# 发现样本的特征是三维:有问题吗? 有!!训练模型的时候,模型只可以接收二维形式的特征矩阵
feature = feature.reshape((400,4096)) # 64*64=4096
# 数据集切分
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
# 建模
model = SVC()
model.fit(x_train,y_train)
print(model.score(x_test,y_test)) # 正确率,即 结果是对的 / 样本总数
# 使用训练好的模型进行人脸识别任务
persons = x_test[10:15]
print('真实的名字:',y_test[10:15])
print('模型识别的人名:',model.predict(persons))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52

# SVM处理回归问题
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)
for i in np.arange(0.1,1,0.1):
model = SVR(kernel='linear',epsilon=i) # 创建SVR模型
model.fit(X_train, y_train) # 训练模型
y_pred = model.predict(X_test) # 预测
mse = mean_squared_error(y_test, y_pred) # 计算均方误差
print("均方误差:", mse)
""" >> 证明epsilon超参数还是起到了一定作用的!!
均方误差: 29.4359086090196
均方误差: 29.875121143114104
均方误差: 29.598469394250827
均方误差: 29.172024281367644
均方误差: 28.74317880203384
均方误差: 28.56298754658591
均方误差: 28.609459549461093
均方误差: 28.436580477456786
均方误差: 28.32837619969622
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# HOG代码实现
pip insall opencv-python
pip install scikit-image
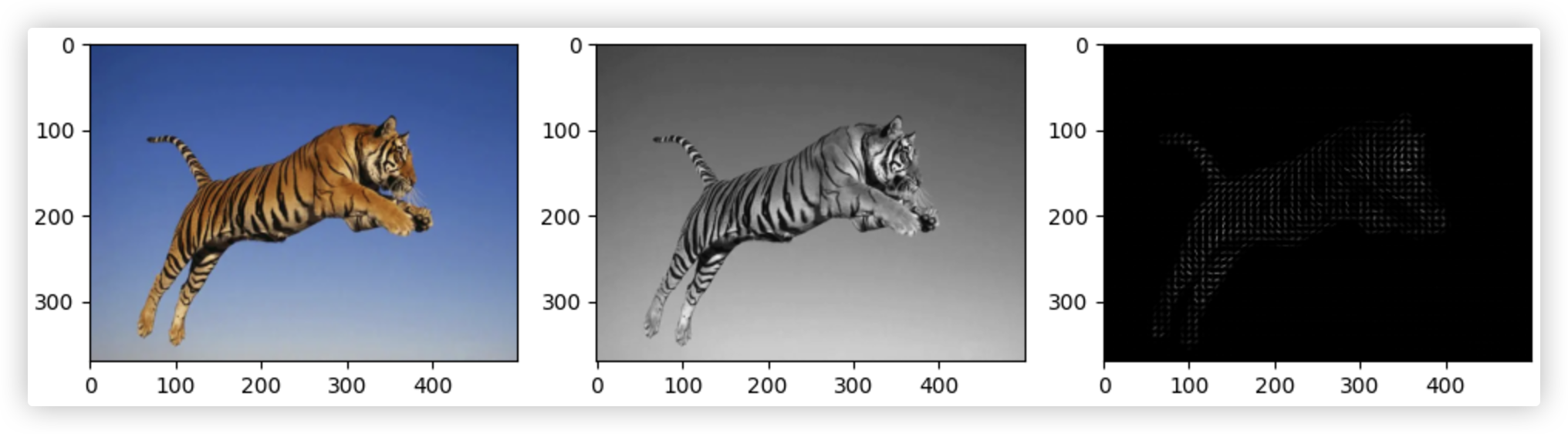
import cv2
import cv2
import matplotlib.pyplot as plt
import numpy as np
from skimage.feature import hog
img = cv2.imread('tigger.jpg') # 跟使用plt加载图片一样,返回的是一个三维数组
img = cv2.resize(img,(500,370)) # 重新制定图片的尺寸大小(建模时,数据集里的图片尺寸得统一)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) # 将图片的颜色通道变回成RGB
print(img.shape) # (370, 500, 3) 注意:370行500列 与上面的resize里是相反的
img_gray = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY) # 灰度处理,即过滤掉颜色通道
print(img_gray.shape) # (370, 500) 灰度化处理后,颜色通道就没有了.
""" Hog提取主要特征,hog函数参数
- image:输入图像
- orientations: 把180度分成几份,bin的数量
- pixels_per_cell: 元组形式,一个Cell内的有多少个像素点
- cells_per_block: 元组形式,一个Block内的Cell大小(滑动窗口
- visualize: 是否需要可视化,如果True,hog会返回numpy图像
- 返回值:fd表示hog后返回的图像特征向量,是一维的.hog_image表示可预览的hog图像,是二维的(主要对象的边缘图)
> ★ pixels_per_cell、cells_per_block
- 越小越细致,但可能会导致提取到的特征包含很多无用的特征
- 过大也可能导致有些重要特征没有提取出来!!
"""
fd, hog_image = hog(image=img_gray,
orientations=9,
pixels_per_cell=(8, 8),
cells_per_block=(2, 2),
visualize=True)
# (500/8)*(370/8)个cell、每个cell有9个数; 共(500/8-1)*(370/8-1)个block、每个block4个cell,即每个block有4*9=36个数据
# 则fd.shape = [(500/8)-1]*[(370/8)-1]*36 ps:500/8取整数部分62 370/8取整数部分46 -- 61*45*36=98820
print(fd.shape,hog_image.shape) # (98820,) (370, 500)
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1) # 1行3列,位置1
plt.imshow(img, cmap='gray')
plt.subplot(1, 3, 2)
plt.imshow(img_gray, cmap='gray')
plt.subplot(1, 3, 3)
plt.imshow(hog_image, cmap='gray')
plt.tight_layout() # 自动调整子图间的间距
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# HOG+SVM 书法字体识别
import glob
import pickle
import random
import cv2
import numpy as np
from skimage.feature import hog
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
def read_china_path_img(filename):
"""若通过cv2读取包含中文的图像路径,img = cv2.imread(filename)报错了,则使用如下方式"""
raw_data = np.fromfile(filename, dtype=np.uint8)
img = cv2.imdecode(raw_data, -1)
return img
# 进行hog特征提取
def hog_feature(file_path):
"""对图片进行hog特征提取"""
img = read_china_path_img(file_path) # 读取图片
img = cv2.resize(img, (100, 100)) # 固定尺寸
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度处理
return hog(img, orientations=4, pixels_per_cell=(6, 6), cells_per_block=(2, 2))
style_list = ['篆书', '隶书', '草书', '行书', '楷书']
feature_list = [] # 标签
target_list = [] # 特征
for index, style in enumerate(style_list):
# glob用于查找符合特定模式(pattern)的文件路径名
# 该示例中 字体-什么字-该字的几张图片. 每张图片的命名也没有规律.
text_list = glob.glob(r"D:\工作相关\数据分析-AI\机器学习\datasets\书法文字数据\\" + style + "/*/*")
random.shuffle(text_list) # 打乱同一字体下的图片的顺序
selected_files = text_list[:1000] # 我们选择每个字体的前1000个图片作为训练集. 不足1000就全部取.
for path in selected_files:
fd = hog_feature(path) # 对图片进行hog特征提取
# feature_list和target_list是一一对应的!
feature_list.append(fd)
target_list.append(index)
feature = np.array(feature_list)
target = np.array(target_list)
# svm模型训练和保存
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2020)
model_1 = svm.SVC(kernel='rbf')
model_1.fit(x_train, y_train)
y_true = y_test
y_pred = model_1.predict(x_test)
print(accuracy_score(y_true, y_pred))
model_2 = svm.SVC(kernel='linear')
model_2.fit(x_train, y_train)
y_true = y_test
y_pred = model_2.predict(x_test)
print(accuracy_score(y_true, y_pred))
model_3 = svm.SVC(kernel='poly')
model_3.fit(x_train, y_train)
y_true = y_test
y_pred = model_3.predict(x_test)
print(accuracy_score(y_true, y_pred))
model_4 = svm.SVC(kernel='sigmoid')
model_4.fit(x_train, y_train)
y_true = y_test
y_pred = model_4.predict(x_test)
print(accuracy_score(y_true, y_pred))
# 模型保存,保存精准率最高的模型
with open('./hog_svm_best_score.pkl', 'wb') as fp:
pickle.dump(model_3, fp) # 将训练好的模型model保存到fp表示的文件中
# 模型加载
with open('./hog_svm_best_score.pkl', 'rb') as fp:
model = pickle.load(fp)
# 模型对书法图片进行识别 注:新图片需要经历一样的特征工程
path = r'./img/书法文字数据/楷书/啊/书法味_86678fe7a2ae313132525eaf0cf19d1f67003872.jpg'
fd = hog_feature(path)
print(model.predict([fd])) # 预测结果
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
# 决策树
# 分类树 - 模型参数和使用
sklearn.tree.DecisionTreeClassifier()
# 重要参数
- criterion(划分标准)
- 有两个参数 'entropy'(熵 - 默认c4.5) 和 'gini'(基尼系数 - 默认cart)可选, 默认为gini.
- max_depth(树的最大深度)
- 默认为None, 此时决策树在建立子树的时候不会限制子树的深度. 也可以设置具体的整数.
一般来说, 数据少或者特征少的时候可以不管这个值.
如果模型样本量多, 特征也多的情况下, 推荐限制这个最大深度, 具体的取值取决于数据的分布.
常用的可以取值10-100之间. - 理解: 默认不纯度为0时,停止生长.
设置了max_depth参数手,哪怕不纯度没有达到0, 但达到了最大深度,也会停止生长!!
- 默认为None, 此时决策树在建立子树的时候不会限制子树的深度. 也可以设置具体的整数.
- min_samples_split(分割内部节点所需的最小样本数)
- 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本, 否则分枝就不会发生.
一般搭配max_depth使用. 这个参数的数量设置得太小会引起过拟合, 设置得太大就会阻止模型学习数据.
一般来说, 建议从=5开始使用. - 理解: 该参数设置的是 节点分支后, 子节点应包含的最小样本数量是多少.
若没有达到该参数设置的值,那么该分支不会产生!
- 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本, 否则分枝就不会发生.
- min_samples_leaf(叶子节点上的最小样本数)
- 一个节点必须要包含至少min_samples_split个训练样本. 这个节点才允许被分枝, 否则分枝就不会发生.
这样可以去除一些明显异常的噪声数据. - 理解: 该参数设置的是 节点应包含的最小样本数量是多少,若数量没达到,该节点就不能产生分支!!
- 一个节点必须要包含至少min_samples_split个训练样本. 这个节点才允许被分枝, 否则分枝就不会发生.
- class_weight:
- 指定类别权重, 默认取None, 可以取"balanced", 代表样本量少的类别所对应的样本权重更高.
该参数主要是为防止训练集某些类别的样本过多, 导致训练的决策树过于偏向这些类别.
除了此处指定class_weight, 还可以使用过采样和欠采样的方法处理样本类别不平衡的问题!!
- 指定类别权重, 默认取None, 可以取"balanced", 代表样本量少的类别所对应的样本权重更高.
min_samples_split、min_samples_leaf 这两参数解决过拟合的,手动决定树什么时候停止生长!!
# 不重要参数
这些参数一般无需自己手工设定, 只需要知道具体的含义, 在遇到特殊情况再有针对性地调节即可.
- max_features
在划分节点时所考虑的特征数量的最大值(从n个重要特征中分支构建树)默认取None.
可以传入int型或float型数据.如果是float型数据,表示百分数.
如果我们训练集的特征数量太多,用这个参数可以限制生成决策树的特征数量.
一般用该参数或者实现使用特征选择技术进行特征工程后再构建树模型.
- min_impurity_decrease(节点划分最小不纯度
这是树增长提前结束的阈值,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点.一般不推荐改动.
- max_leaf_nodes(最大叶子节点数)
默认是 None 即不限制最大的叶子节点数.
如果加了限制,算法会建立一个在最大叶子节点数内最优的决策树.
限制这个值可以防止过拟合,如果特征不多,可以不考虑这个值,但是如果特征多的话,可以加以限制.
- random_state(随机数种子)
当数据量较大,或特征变量较多时,可能在某个节点划分时,会碰上两个特征变量的信息熵增益或者基尼系数减少量是一样的情况.
那么此时决策树模型默认是随机从中选一个特征变量进行划分,这样可能会导致每次运行程序后生成的决策树不太一致.
如果设定random_state参数(如设置为2020)可以保证每次运行代码时,各个节点的分裂结果都是一致的.
这在特征变量较多,树的深度较深的时候较为重要!
- splitter
取值为 best 和 random
best在特征的所有划分点中找出最优的划分点,适合样本量不大的情况.
random随机地在部分划分点中找局部最优的划分点,适合样本量非常大的情况,默认选择 best.
random可以在一定程度上降低树对训练集的拟合程度,这也是防止过拟合的一种方式.
当然,这种防止过拟合的方法属于“伤敌一千自损八百”的方法,树的随机分枝会使得树因为含有更多的不必要信息而更深更大,
所以我们最好使用上边的剪枝参数来防止过拟合,这个参数一般不用动!
- min_weight_fraction_leaf(叶子节点最小的样本权重和)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会被剪枝.默认是0,就是不考虑权重问题.
一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们才会稍微注意一下这个值!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 应用
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
data = load_wine()
feature = data.data
target = data.target
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
# 若多次运行模型评估结果不一致,则可以使用random_state参数进行固定
model = DecisionTreeClassifier(criterion='entropy')
model.fit(x_train,y_train)
model.score(x_test,y_test) # 正确率、准确率 0.9722222222222222
# 返回特征的重要性:feature_importances_属性 >> 表明决策树可以实现 特征选择.
# 注: 这里的重要程度不是 信息熵的值哈. 别混淆了.
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜 色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
[*zip(feature_name,model.feature_importances_)]
"""
[('酒精', 0.0),
('苹果酸', 0.0),
('灰', 0.0),
('灰的碱性', 0.014793902271725548),
('镁', 0.0),
('总酚', 0.016180108413000136),
('类黄酮', 0.4874266009839064),
('非黄烷类酚类', 0.008964941814890645),
('花青素', 0.0),
('颜 色强度', 0.2763587955899273),
('色调', 0.031155237629119942),
('od280/od315稀释葡萄酒', 0.0),
('脯氨酸', 0.16512041329743)]
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
可以画图展示构建的树结构!!
window安装graphviz的参考文档: https://download.csdn.net/blog/column/12460558/119317706
mac只需要在anaconda中pip install graphviz 安装graphviz包,然后在 终端brew install graphviz
dot -version 看是否安装上了.. (记得重启jurpter. 重启终端..)
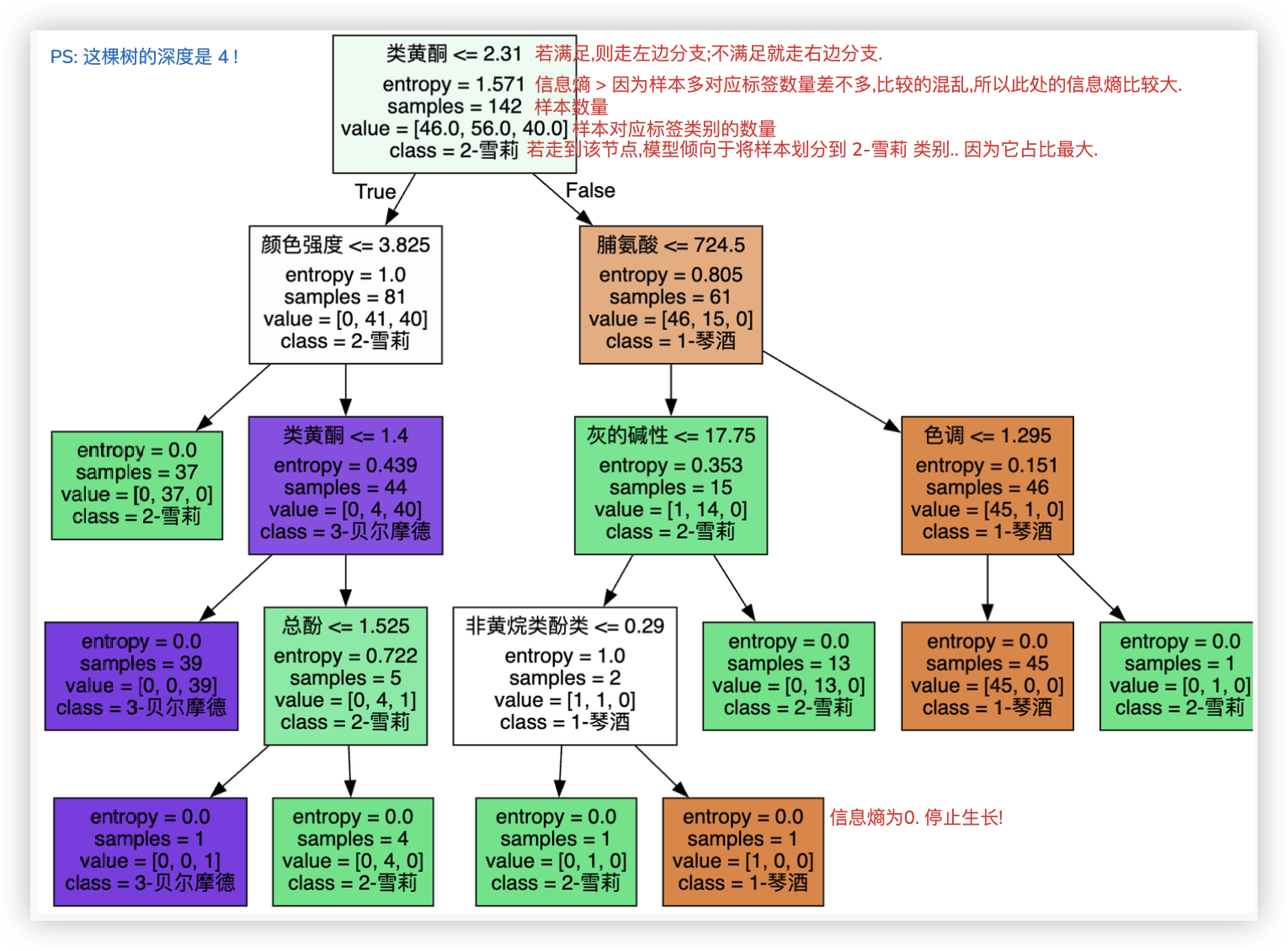
# 先看看data数据集长啥样 data['feature_names']特征名 、data['target_names'] 有哪些类别的标签
print(data.keys()) # dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
# 开始画图
import graphviz
from sklearn import tree
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(model
,out_file = None # 图片保存路径,None则不保存
,feature_names= feature_name
,class_names=["1-琴酒","2-雪莉","3-贝尔摩德"]
,filled=True # 使用颜色表示分类结果
)
graph = graphviz.Source(dot_data)
graph
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 回归树 - 模型参数和使用
sklearn.tree.DecisionTreeRegressor()
# 重要参数
- criterion
- 用于衡量节点纯度的度量标准, 可选值为 "mse"(均方误差) 和 "mae"(平均绝对误差). 默认值为"mse".
目前新版本中 可选的参数值是 'absolute_error', 'squared_error', 'poisson', 'friedman_mse'
- 用于衡量节点纯度的度量标准, 可选值为 "mse"(均方误差) 和 "mae"(平均绝对误差). 默认值为"mse".
- 剩下的和分类树参数含义一致
# 应用
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error as MSE
import pandas as pd
import numpy as np
# boston = load_boston()
# feature = boston.data
# target = boston.target
data_url = "http://lib.stat.cmu.edu/datasets/boston" # 波士顿房价数据集
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.2,random_state=2020)
# The 'criterion' parameter of DecisionTreeRegressor must be a str among
# {'absolute_error', 'squared_error', 'poisson', 'friedman_mse'}.
model = DecisionTreeRegressor(criterion='squared_error',max_depth=3,random_state=2020)
model.fit(x_train,y_train)
y_true = y_test
y_pred = model.predict(x_test)
score = MSE(y_true,y_pred)
print(score) # 50.220469114669136
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 网格搜索 Grid Search
若我想对 决策树的那些重要超参数 选出重要的值, 如何是好?
用前面学过的 交叉验证+学习曲线吗? No, 该方案只能找到一个超参数的最优值.
若想找多个(模型的参数与参数之间是可能会相互影响的), 就得用 网格搜索Grid Search!! -- 本质也是穷举的过程.
Grid Search是一种调参手段,也叫做穷举搜索.
> 在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果. 其原理就像是在数组里找最大值.
> 为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格
其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search!!
2
3
4
来瞅一瞅代码, 用决策树对红酒分类的示例..
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
data = load_wine()
feature = data.data
target = data.target
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
import numpy as np
from sklearn.model_selection import GridSearchCV
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10) # cv表明一次交叉验证10份
GS.fit(x_train,y_train)
print(GS.best_params_) # 最优参数
print(GS.best_score_) # 最优分值
"""
{'criterion': 'entropy', 'max_depth': 3, 'min_samples_leaf': 1, 'splitter': 'best'}
0.9223809523809525
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27