 pandas基本操作
pandas基本操作
在前面我们学习了numpy的使用, 意犹未尽.
今天我们来学习一个数据分析领域更强大的一个库, pandas, 它具有怎样的特性, 跟numpy有何不同呢?
请听我娓娓道来.
Pandas用来处理表格型或异质型数据; Numpy则相反,更适合处理同质型的数值类数组数据.
| 库 | 功能 | 数据类型 |
|---|---|---|
| numpy | 处理一维多维的数值型数据 | ndarray |
| pandas | 处理各种类型(数值、文本、时间序列等)的数据 | Series(类似一维数组结构) DataFrame(类似二维数组结构) |
PS: 一些简单理解: 二维数据结构 - 数据库表、excel表; 多个一维组成一个二维.
★ 注意一点, 在前面numpy的通用函数小节, 所涉及到的知识点, pandas中也能使用!!
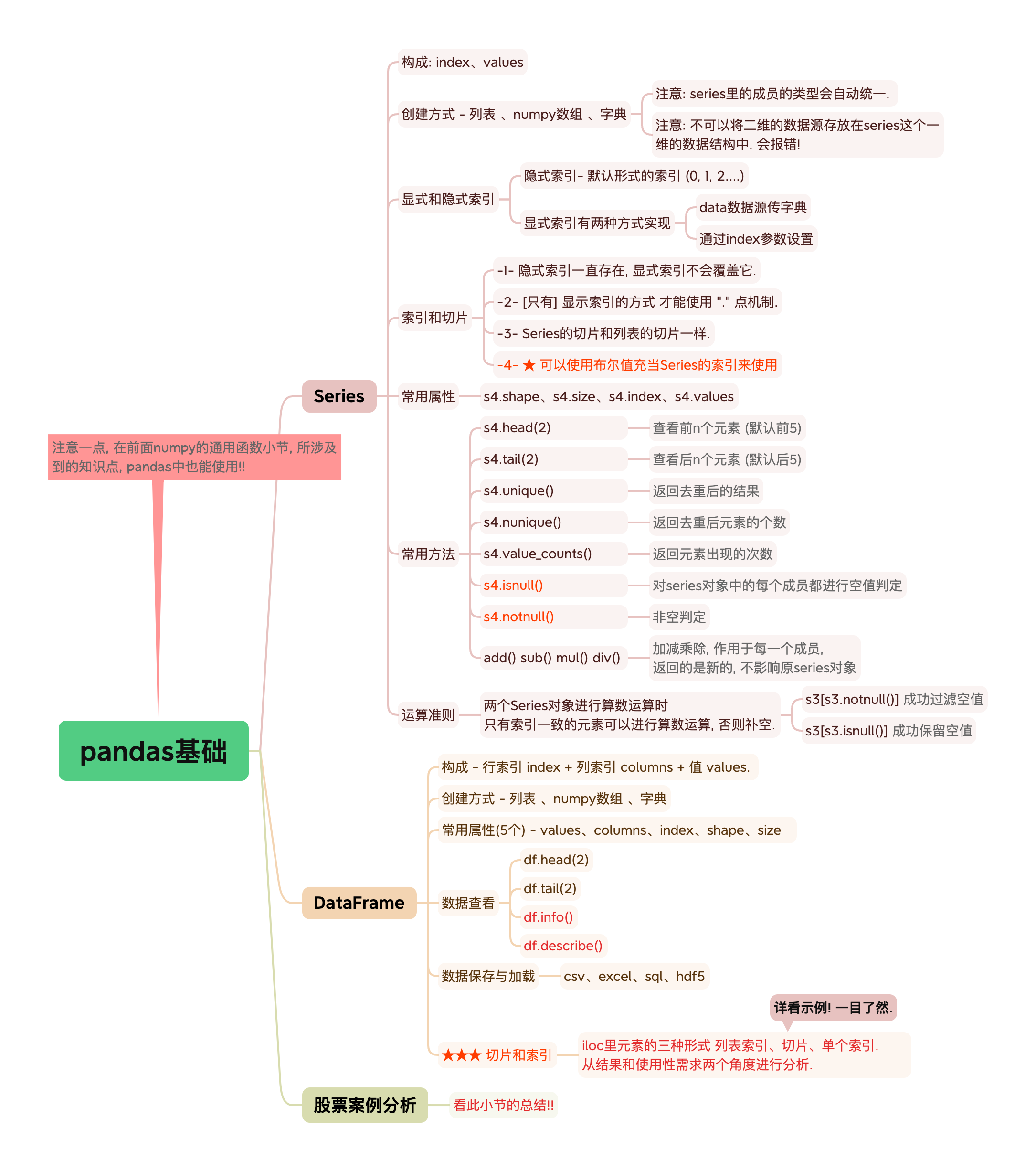
# 总结
Series
■ 三部分组成: index、value、dtype
■ pd.Series(data=xxx,index=yyy)
- data参数值可以是列表、numpy数组、字典
- index参数值用于指明显式索引.
1> 使用列表和numpy数组构建Serise,其默认索引是 0,1,2,3.
2> 使用字典构建Series,其默认索引是 字典的keys().
我们可以通过index参数让字典键按照我们想要的顺序传递给构造函数.
>>> pd.Series(data={'name':'bobo','age':20},index=["age","hight"])
age 20
hight NaN
dtype: object
■ 可以简单的将Serise看作是一维的Numpy数组
★ 像Numpy数组的 数组运算、bool数组充当索引、调用数学函数等用法、切片后被赋值会改变原数组. Serise对象都适用!!
s1*2 s1[s1>3] s1.mean() s1[:3]=5
■ 索引和切片
s4['语文'] s4[0] s4[[True,False,True]] 切片跟列表切片一样的
■ 查看Series对象
s4.shape s4.size s4.index s4.values
s4.head(2)
s4.tail(2)
s4.unique() 返回去重后的结果, 并将值放到了一个numpy对象中
s4.nunique() 返回去重后元素的个数
s4.value_counts() 返回元素出现的次数
s4.isnull() 会对series对象中的每个成员都进行空值判定
s4.notnull()
>> s3[s3.notnull()] 过滤空值
>> s3[s3.isnull()] 保留空值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
DataFrame
■ DataFrame的组成: 行索引 index + 列索引 columns + 值 values.
■ ★★★ DataFrame可以看作是由多个共享相同索引的Serise对象构成的!!
某种意义上,你可以把DataFrame看作是一个字典.因为它的很多操作跟字典是相似的.
>>> # 字典的键作为列,内部字典的键作为行索引.
>>> # {列索引: 内部kv就是Series对象,k是Serise对象的索引,此处充当DataFrame的行索引}
>>> dic = {'张三':{"语文":90,"数学":88,"英语":61,"理综":50},"李四":{"语文":92,"数学":83,"英语":66,"理综":70}}
>>> pd.DataFrame(data=dic)
张三 李四
语文 90 92
数学 88 83
英语 61 66
理综 50 70
■ 和Series对象一样, 有三种创建方式: 列表 、numpy数组 、字典
- pd.DataFrame(data=[[1,2],[3,4]],index=('A','B'),columns=['a','b'])
- pd.DataFrame(data=dic,columns=['李四','张三'])
通过columns参数指定了列的顺序,DataFrame的列会按照指定顺序排列.
■ 你将DataFrame对象看作是一个字典.那么!!
- df1['debt'] 就是取debt这一列 -- 就像字典取值一样,只不过这里取的值是Serise对象,是一列
- 给一列赋值,该列存在则修改.不存在则给DataFrame对象新增一列.
df1['debt'] = 16.5 # 标量会自动向量化. 不管是新增还是修改.
df1['debt'] = np.arange(6)
df1['debt'] = pd.Series([1,2,3],index=['a','b','d'] # f1有行索引'a','b','c' 那么,d被舍弃,c处以Nan值填充.
df1['debt'] = df1['score'] > 80
- 从DataFrame中选取的列是数据的视图,而不是拷贝.因此,对Serise的修改会映射到DataFrame中!!
■ 查看DataFrame对象
df1.values df1.columns df1.index df1.shape df1.size
df1.head(2)
df1.tail(2)
df.info() # 可以通过它判定某列有没有空值
df.describe()
■ Bool值充当索引 -- 用法跟numpy二维数组一模一样!!
data[data['three']>5] 里面是一维的,取符合条件的行
data[data<5] = 0 里面是二维的,修改值
■ DataFrame对象的索引和切片iloc、loc的用法跟二维的numpy对象差不多. (索引列表的情况有些许区别.
DataFrame中所说的降维是得到一个Serise对象.
iloc适配下标索引,loc适配显式索引,并且loc中使用显式索引切片是包含最后一个的!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Series
Series是一种类似与一维数组的对象, 由三个部分组成: values 和 index 和 dtype.
-1- values: 一组数据.
-2- index: 相关的数据的 索引/标签
-3- dtype: 值的类型
# 创建方式
有三种创建方式: 列表 、numpy数组 、字典
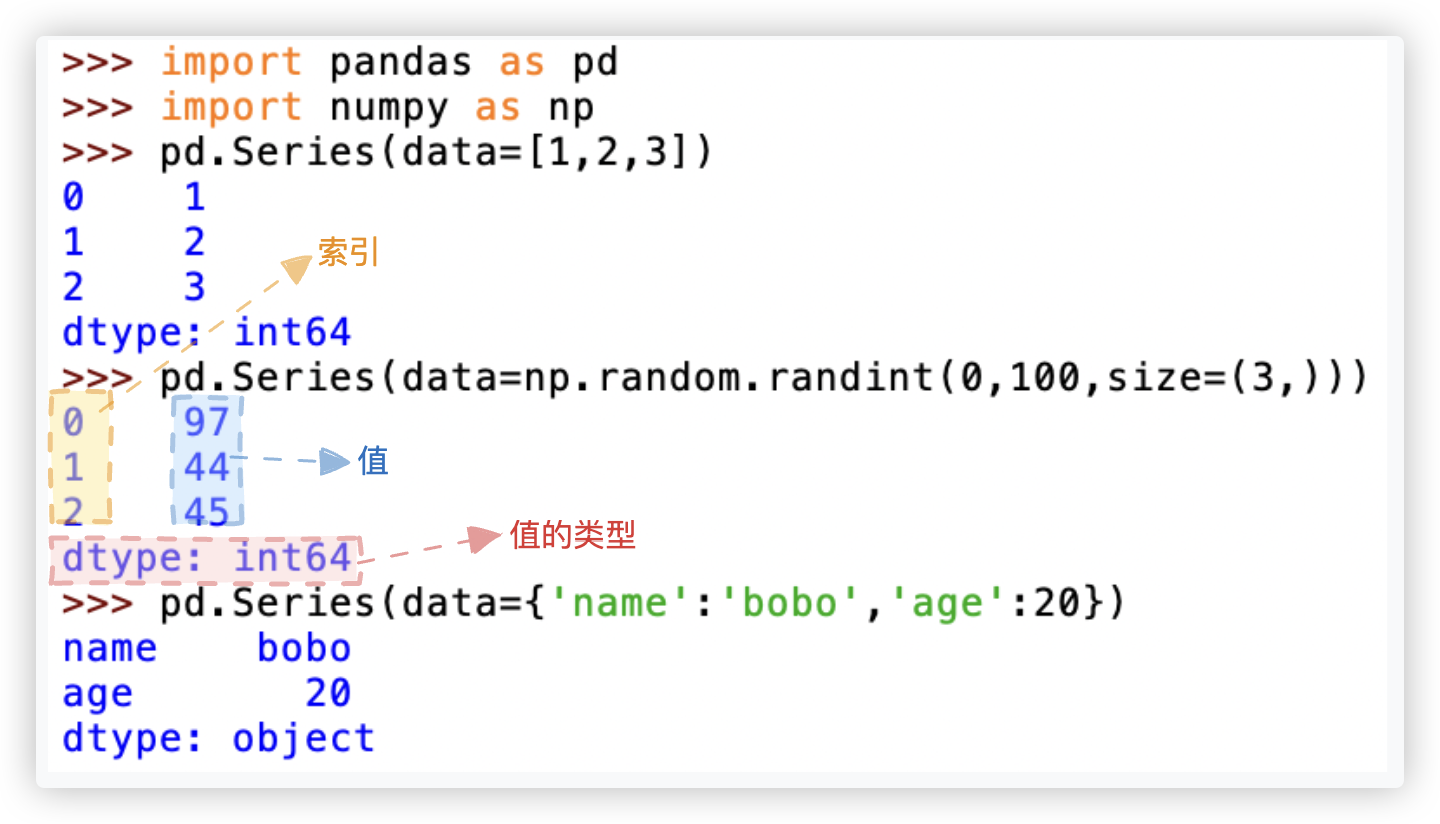
注意点1: series里的成员的类型会自动统一. 注 - 下方示例中, 此处的object指代的是字符串. 但并不是说 object就只能是字符串哦!
>>> import pandas as pd
>>> pd.Series(data=[1,2,'three',4])
0 1
1 2
2 three
3 4
dtype: object
>>> pd.Series(data=['hello','world'])
0 hello
1 world
dtype: object
2
3
4
5
6
7
8
9
10
11
注意点2: 不可以将二维的数据源存放在series这个一维的数据结构中. 会报错!
>>> import pandas as pd
>>> pd.Series(data=[[1,2,3],[4,5,6]])
0 [1, 2, 3]
1 [4, 5, 6]
dtype: object
>>> pd.Series(data=np.random.randint(0,100,size=(2,3)))
ValueError: Data must be 1-dimensional, got ndarray of shape (2, 3) instead # 报错啦!!
2
3
4
5
6
7
# 显式和隐式索引
隐式索引- 默认形式的索引 (0, 1, 2....) 显式索引有两种方式实现 - data数据源传字典 、通过index参数设置
显示索引的作用: 增加了数据的可读性
>>> import pandas as pd
>>> pd.Series(data={'name':'bobo','age':20})
name bobo
age 20
dtype: object
>>> pd.Series(data=['bobo',20],index=['name','age'])
name bobo
age 20
dtype: object
>>> pd.Series(data=['bobo',20])
0 bobo
1 20
dtype: object
2
3
4
5
6
7
8
9
10
11
12
13
# 索引和切片
-1- 隐式索引一直存在, 显式索引不会覆盖它.
-2- [只有] 显示索引的方式 才能使用 "." 点机制.
-3- Series的切片和列表的切片一样. 😃
-4- 可以使用布尔值充当Series的索引来使用
>>> import pandas as pd
>>> s4 = pd.Series(data=[97,80,90],index=['语文','数学','英语'])
>>> s4
语文 97
数学 80
英语 90
dtype: int64
>>> s4[1:]
数学 80
英语 90
dtype: int64
>>> s4['语文']
np.int64(97)
>>> s4[0]
np.int64(97)
>>> s4.语文
np.int64(97)
>>>
>>>
>>> s4[[True,False,True]]
语文 97
英语 90
dtype: int64
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 常用属性
| 属性 | 含义 |
|---|---|
| s4.shape | Series对象的形状 |
| s4.size | Series对象的长度 |
| s4.index | Series对象的索引 (优先显示显式索引,没有则显示隐式索引) |
| s4.values | Series对象的数据值 |
测试一下下:
>>> import pandas as pd
>>> s4 = pd.Series(data=[97,80,90],index=['语文','数学','英语'])
>>> s4.shape
(3,)
>>> s4.size
3
>>> s4.index
Index(['语文', '数学', '英语'], dtype='object')
>>> s4.values
array([97, 80, 90])
>>>
>>>
>>> s1 = pd.Series(data=[[1,2,3],[4,5,6]])
>>> s1
0 [1, 2, 3]
1 [4, 5, 6]
dtype: object
>>> s1.shape
(2,)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 常用方法
| 方法 | 含义 |
|---|---|
| s4.head(2) | 查看前n个元素 (默认前5) |
| s4.tail(2) | 查看后n个元素 (默认后5) |
| s4.unique() | 返回去重后的结果, 并将值放到了一个numpy对象中 |
| s4.nunique() | 返回去重后元素的个数 |
| s4.value_counts() | 返回元素出现的次数 |
| s4.isnull() | 会对series对象中的每个成员都进行空值判定 |
| s4.notnull() | 会对series对象中的每个成员都进行非空判定 |
| add() sub() mul() div() | 加减乘除, 作用于每一个成员, 返回的是新的, 不影响原series对象 |
测试一下下:
>>> import pandas as pd
>>> s4 = pd.Series(data=np.random.randint(90,100,size=(6,)))
>>> s4
0 93
1 97
2 96
3 90
4 97
5 93
dtype: int64
>>> s4.head(2)
0 93
1 97
dtype: int64
>>> s4.tail(2)
4 97
5 93
dtype: int64
>>> s4.unique()
array([93, 97, 96, 90])
>>> s4.nunique()
4
>>> s4.value_counts()
93 2
97 2
96 1
90 1
Name: count, dtype: int64
>>> s4.add(2) # 等同于 s4 + 2
0 95
1 99
2 98
3 92
4 99
5 95
dtype: int64
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 运算法则
★运算法则: 两个Series对象进行算数运算时, 只有索引一致的元素可以进行算数运算, 否则补空.
(´・Д・)」 NaN 表示为空.
>>> s1 = pd.Series(data=[1,2,3],index=['a','b','c'])
>>> s2 = pd.Series(data=[1,2,3],index=['a','d','c'])
>>> s3 = s1 + s2
>>> s3
a 2.0
b NaN
c 6.0
d NaN
dtype: float64
>>>
>>>
>>> # Q:若一个Series对象有几万个成员,为了过滤空值,手写几万个True和False?
>>> # A:NO!解决方案 - 布尔值充当Series的索引 + isnull方法
>>> s3.isnull()
a False
b True
c False
d True
dtype: bool
>>> s3.notnull()
a True
b False
c True
d False
dtype: bool
>>> s3[s3.notnull()] # 成功过滤空值
a 2.0
c 6.0
dtype: float64
>>> s3[s3.isnull()] # 成功保留空值 Hhh
b NaN
d NaN
dtype: float64
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# DataFrame - 基本
DataFrame是一个 [表格型] 的数据结构.
DataFrame由按一定顺序排列的多列数据组成. 设计初衷是将Series的使用场景从一维拓展到多维.
DataFrame由三部分组成 行索引 index + 列索引 columns + 值 values.
# 创建方式
和Series对象一样, 有三种创建方式: 列表 、numpy数组 、字典

一点小补充:
>>> dic = {'张三':{"语文":90,"数学":88,"英语":61,"理综":50},"李四":{"语文":92,"数学":83,"英语":66,"理综":70}}
>>> pd.DataFrame(data=dic)
张三 李四
语文 90 92
数学 88 83
英语 61 66
理综 50 70
2
3
4
5
6
7
# 常用属性
常用的有五个 values、columns、index、shape、size
>>> import pandas as pd
>>> df1 = pd.DataFrame(data=[[1,2],[3,4]],index=('A','B'),columns=['a','b'])
>>> df1
a b
A 1 2
B 3 4
>>> df1.values
array([[1, 2],
[3, 4]])
>>> df1.columns
Index(['a', 'b'], dtype='object') # 这里的object表明列索引是字符串类型
>>> df1.index
Index(['A', 'B'], dtype='object')
>>> df1.shape
(2, 2)
>>> df1.size
4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 数据查看
查看DataFrame的概览和统计信息
>>> import numpy as np
>>> import pandas as pd
>>> # 创建 shape(150,3)的二维标签数组结构DataFrame
>>> df = pd.DataFrame(data = np.random.randint(
0,151,
size = (150,3)),
index = None, # 行索引默认
columns=['Python','Math','En'])
>>> df.head(2) # 显示头部2行,默认5个
Python Math En
0 77 78 115
1 6 10 20
>>> df.tail(2) # 显示末尾2行,默认5个
Python Math En
140 101 117 141
141 132 44 12
>>> df.info() # 查看列索引、数据类型、非空计数和内存信息
<class 'pandas.core.frame.DataFrame'> # 数据表格的数据结构
RangeIndex: 150 entries, 0 to 149 # 行信息 150行 行索引0-149
Data columns (total 3 columns): # 列信息 一共有3列
# Column Non-Null Count Dtype # 列具体信息 non-null表示每一列非空元素的个数
--- ------ -------------- ----- # ★ 若该列的non-null个数等于行数,那么该列就没有空值!
0 Python 150 non-null int64
1 Math 150 non-null int64
2 En 150 non-null int64
dtypes: int64(3) # 3列数据的数据类型都是int64
memory usage: 3.6 KB # 所占空间大小
>>> # 若是数值型列,它返回的统计指标 - 计数、平均值、标准差、最小值、四分位数、最大值
>>> df.describe()
Python Math En
count 150.000000 150.000000 150.000000
mean 79.086667 74.760000 68.753333
std 42.817380 43.259119 43.206999
min 1.000000 0.000000 0.000000
25% 43.000000 38.250000 30.750000
50% 80.000000 75.500000 69.000000
75% 111.750000 114.750000 102.750000
max 148.000000 148.000000 148.000000
>>> # 若是非数值型列,它返回统计指标 - count非空元素个数;unique元素去重后的个数;top出现频率最高的元素;freq最大频率
>>> df = pd.DataFrame(data=[['a','b','c','d'],['小米','oppo','华为','华为']]).T
>>> df
0 1
0 a 小米
1 b oppo
2 c 华为
3 d 华为
>>> df.describe()
0 1
count 4 4
unique 4 3
top a 华为
freq 1 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 数据保存与加载
此处先简单讲解csv、excel的使用, sql、hdf5 暂略.
# CSV

测试代码如下:
import numpy as np
import pandas as pd
df = pd.DataFrame(
data=np.random.randint(0, 50, size=(3, 5)), # 薪资情况
columns=['IT', '化工', '生物', '教师', '士兵']
)
print(df)
df.to_csv('./salary.csv',
sep=';', # 文本分隔符,默认是逗号
header=True, # 是否保存列索引
index=True) # 是否保存行索引
res = pd.read_csv('./salary.csv', sep=';')
print(res)
res = pd.read_csv('./salary.csv', sep=';', header=[0], index_col=0)
print(res)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Excel
准备工作,安装几个python库:
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
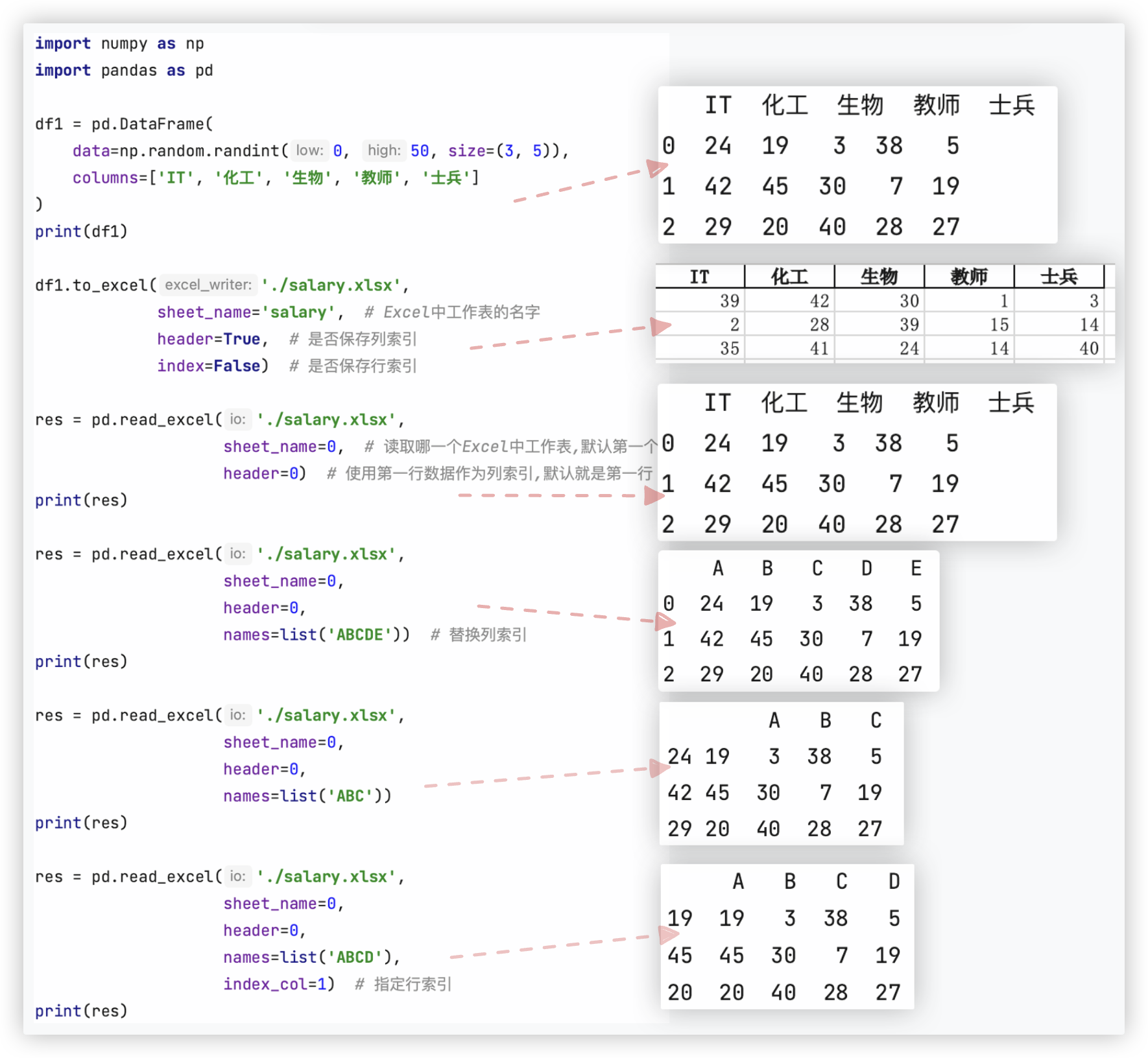
测试代码如下:
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
data=np.random.randint(0, 50, size=(3, 5)),
columns=['IT', '化工', '生物', '教师', '士兵']
)
print(df1)
df1.to_excel('./salary.xlsx',
sheet_name='salary', # Excel中工作表的名字
header=True, # 是否保存列索引
index=False) # 是否保存行索引
res = pd.read_excel('./salary.xlsx',
sheet_name=0, # 读取哪一个Excel中工作表,默认第一个
header=0) # 使用第一行数据作为列索引,默认就是第一行
print(res)
res = pd.read_excel('./salary.xlsx',
sheet_name=0,
header=0,
names=list('ABCDE')) # 替换列索引
print(res)
res = pd.read_excel('./salary.xlsx',
sheet_name=0,
header=0,
names=list('ABC'))
print(res)
res = pd.read_excel('./salary.xlsx',
sheet_name=0,
header=0,
names=list('ABCD'),
index_col=1) # 指定行索引
print(res)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# DataFrame - 切片和索引
DataFrame的索引和切片,你我都可能会感觉到别扭,那没办法,开发者就是这样设定的. (・_・;
>>> df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,4)),
index=['a','b','c','d','e'],columns=['A','B','C','D'])
2
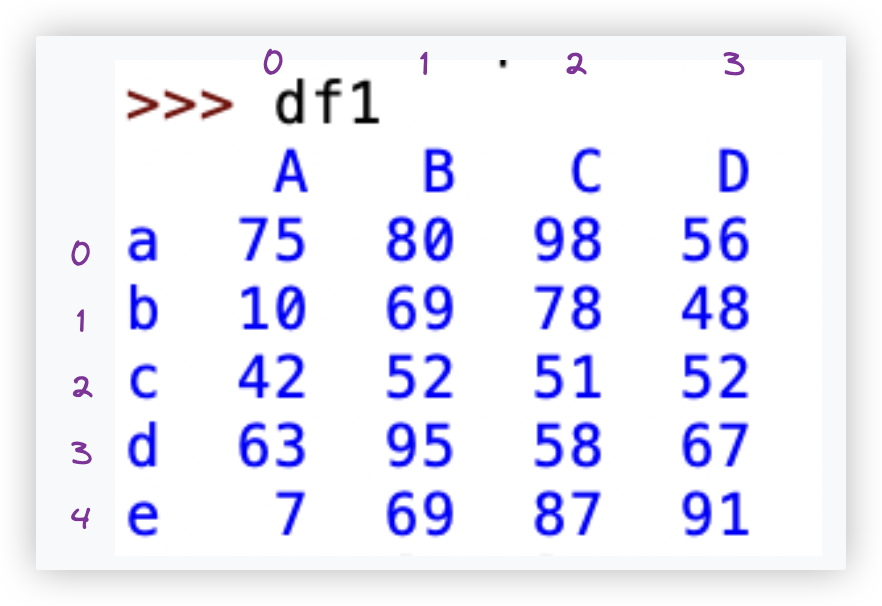
PS: 切记 - df['A'] 、df[0] 若df表格中存在显式的列索引, 那么就无法使用隐式列索引进行取值.
# ※ iloc - 结果类型
# iloc里有两元素
★ iloc的使用, 它是有规律可寻的.
iloc里可有两个元素, df1.iloc[元素1,元素2], 第一个元素行相关, 第二个元素列相关.
而元素的呈现形式可有三种, 其1是列表,列表里写索引、其2是 切片、其3是 单个索引.
这三种呈现形式可以 混用 (比如元素1我使用列表索引, 元素2我使用切片.. ), 不同的搭配, 混用的结果是不同的:
这三种形式两两组合,以及各自于各自组合,共6种情况:
| 结果的数据类型格式 | 举例 | |
|---|---|---|
| 列表索引&切片 | DataFrame | df1.iloc[[1,3],:2] |
| 列表索引&单个索引 | Series | df1.iloc[[1,2,3],1] |
| 切片&单个索引 | Series | df1.iloc[1:-1,1] |
| 列表索引&列表索引 | DataFrame | df1.iloc[[1,3],[0,1]] |
| 切片&切片 | DataFrame | df1.iloc[:2,:-2] |
| 单个索引&单个索引 | 单个值 | df1.iloc[2,3] |
Ps: df1.iloc[[1,3],[0,1]] 这跟numpy那,arr2d[np.ix_([0,2],[1,4])]取一个方形区域交点的元素一样的道理
根据上方的表格, 我们可以简单总结出: (单个索引&单个索引的组合除外)
■ 只要元素的形式不含单个元素, 那么结果就是DataFrame对象
■ 只要有一个元素的形式是单个索引, 那么结果就是Series对象
是不是很有意思amazing啊. (*≧ω≦)
# iloc里只有一个元素
iloc中只有一个元素时, 相当于列全选.. 该元素代表的是行,同样的,有三种形式 列表索引、切片、单个索引
df1.iloc[[2,3]] 、df1.iloc[:2] -- 结果的数据类型是DataFrame
df1.iloc[2] -- 结果的数据类型是 Series
# ※ iloc - 实用性需求
前面我们是根据结果的数据结构类型进行的思考, 现在我们要根据实用性需求的角度进行思考.
首先, 明确 iloc里元素的三种形式 列表索引、切片、单个索引.
# 取多行多列
思考 - 取行, 列拉满 ; 取行, 列拉满 ; 取连续的多行或多列可用切片、取不连续的多行或多列可用列表索引
>>> df1.iloc[:3,:] # 取连续的多行 ★可简写成df1.iloc[:3]
A B C D
a 75 80 98 56
b 10 69 78 48
c 42 52 51 52
>>> df1.iloc[:,:3] # 取连续的多列
A B C
a 75 80 98
b 10 69 78
c 42 52 51
d 63 95 58
e 7 69 87
>>> df1.iloc[[1,3],:] # 取不连续的多行 ★可简写成df1.iloc[[1,3]]
A B C D
b 10 69 78 48
d 63 95 58 67
>>> df1.iloc[:,[1,3]] # 取不连续的多列
B D
a 80 56
b 69 48
c 52 52
d 95 67
e 69 91
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 取某一行某一列
>>> df1.iloc[[1],:] # 取第2行,结果为DataFrame ★可简写成df1.iloc[[1]]
A B C D
b 10 69 78 48
>>> df1.iloc[1,:] # 取第2行,结果为Serise ★可简写为df1.iloc[1]
A 10
B 69
C 78
D 48
Name: b, dtype: int64
>>> df1.iloc[:,[1]] # 取第2列,结果为DataFrame
B
a 80
b 69
c 52
d 95
e 69
>>> df1.iloc[:,1] # 取第2列,结果为Serise
a 80
b 69
c 52
d 95
e 69
Name: B, dtype: int64
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 取单个成员
>>> df1.iloc[2,3]
np.int64(52)
2
# 取多个成员
>>> df1.iloc[[1,3],[0,1]] # 取一个方形区域交点的元素,原理跟numpy那,arr2d[np.ix_([0,2],[1,4])]一样
A C
b 10 78
d 63 58
>>> df1.iloc[[1,2,3],[2]] # 取第3列的2,3,4位置的成员 - 结果为DataFrame
C
b 78
c 51
d 58
>>> df1.iloc[[1,2,3],2] # 取第3列的2,3,4位置的成员 - 结果为Serise
b 78
c 51
d 58
Name: C, dtype: int64
2
3
4
5
6
7
8
9
10
11
12
13
14
# 取一个区域
>>> df1.iloc[1:-1,1:-1] # 取一个区域里所有的成员
B C
b 69 78
c 52 51
d 95 58
2
3
4
5
# 当有显式索引时
当有显示索引时, 还可以通过显式索引取值! 举几个例子: (规律啥的不想总结了,看例子悟吧,累了)
>>> df1['A'] # 取单列
a 75
b 10
c 42
d 63
e 7
Name: A, dtype: int64
>>> df1[['A','C']] # 取多列
A C
a 75 98
b 10 78
c 42 51
d 63 58
e 7 87
>>> df1.loc['a'] # 取单行
A 75
B 80
C 98
D 56
Name: a, dtype: int64
>>> df1.loc[['a','c']] # 取多行
A B C D
a 75 80 98 56
c 42 52 51 52
>>> df1.loc['a','C'] # 取单个成员
np.int64(98)
>>> df1.loc['b',['A','B','C']] # 取多个成员
A 10
B 69
C 78
Name: b, dtype: int64
>>> df1.loc[:,'A':'C'] # 切列
A B C
a 75 80 98
b 10 69 78
c 42 52 51
d 63 95 58
e 7 69 87
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 股票分析案例
环境: python3.9.8 ; numpy 1.26.4 ; pandas 1.5.3 ; tushare 1.4.7
# 准备工作
1> 从接口获取股票数据,并以csv形式保存到本地.
import ssl
import pandas as pd
import tushare as ts
ssl._create_default_https_context = ssl._create_unverified_context
stock_code = '000001' # 股票代码:平安银行
start_date = '2021-01-01' # 开始日期
end_date = '2023-2-12' # 结束日期
# 获取股票历史交易数据
df = ts.get_k_data(code=stock_code, start=start_date, end=end_date)
print(df)
df.to_csv('./gupiao.csv') # 默认是保存行索引和列索引的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2> 对数据进行一点处理
import pandas as pd
""" 等同于效果index_col=0
df = pd.read_csv('./gupiao.csv')
df.drop(labels='Unnamed: 0', axis=1, inplace=True) # axis=0表示的行 1表示的是列
"""
# type(df['date']) --> Series ; df['date'].dtypes --> object
df = pd.read_csv('./gupiao.csv', index_col=0)
# 转换后 df['date'].dtypes --> datetime64[ns]
df['date'] = pd.to_datetime(df['date']) # 将日期列转换为日期类型,便于时间类型数据的运算
df.set_index('date', inplace=True) # 将date列作为原数据的行索引,不用默认的0 1 2.
print(df)
2
3
4
5
6
7
8
9
10
11
12
至此,我们得到的数据长这样:
open close high low volume code
date
2021-01-04 17.688 17.188 17.688 17.028 1554216.0 1
2021-01-05 16.988 16.758 17.068 16.388 1821352.0 1
2021-01-06 16.668 18.148 18.148 16.588 1934945.0 1
2021-01-07 18.108 18.488 18.568 17.818 1584185.0 1
2021-01-08 18.488 18.438 18.688 17.898 1195473.0 1
... ... ... ... ... ... ...
2023-12-25 8.461 8.471 8.481 8.421 413971.0 1
2023-12-26 8.471 8.381 8.481 8.351 541896.0 1
2023-12-27 8.381 8.401 8.411 8.301 641534.0 1
2023-12-28 8.391 8.731 8.751 8.361 1661592.0 1
2023-12-29 8.701 8.671 8.761 8.631 853853.0 1
[727 rows x 6 columns]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 收益率和波动率
Q: 计算股票的每日收益率和7日波动率: 通过计算收益率和波动率, 我们可以评估股票的风险和收益情况.
每日收益率: (当日收盘价 - 前一日的收盘价) / 前一日的收盘价.
7日波动率: 对 每日收益率 数据进行每7日滚动的方差计算
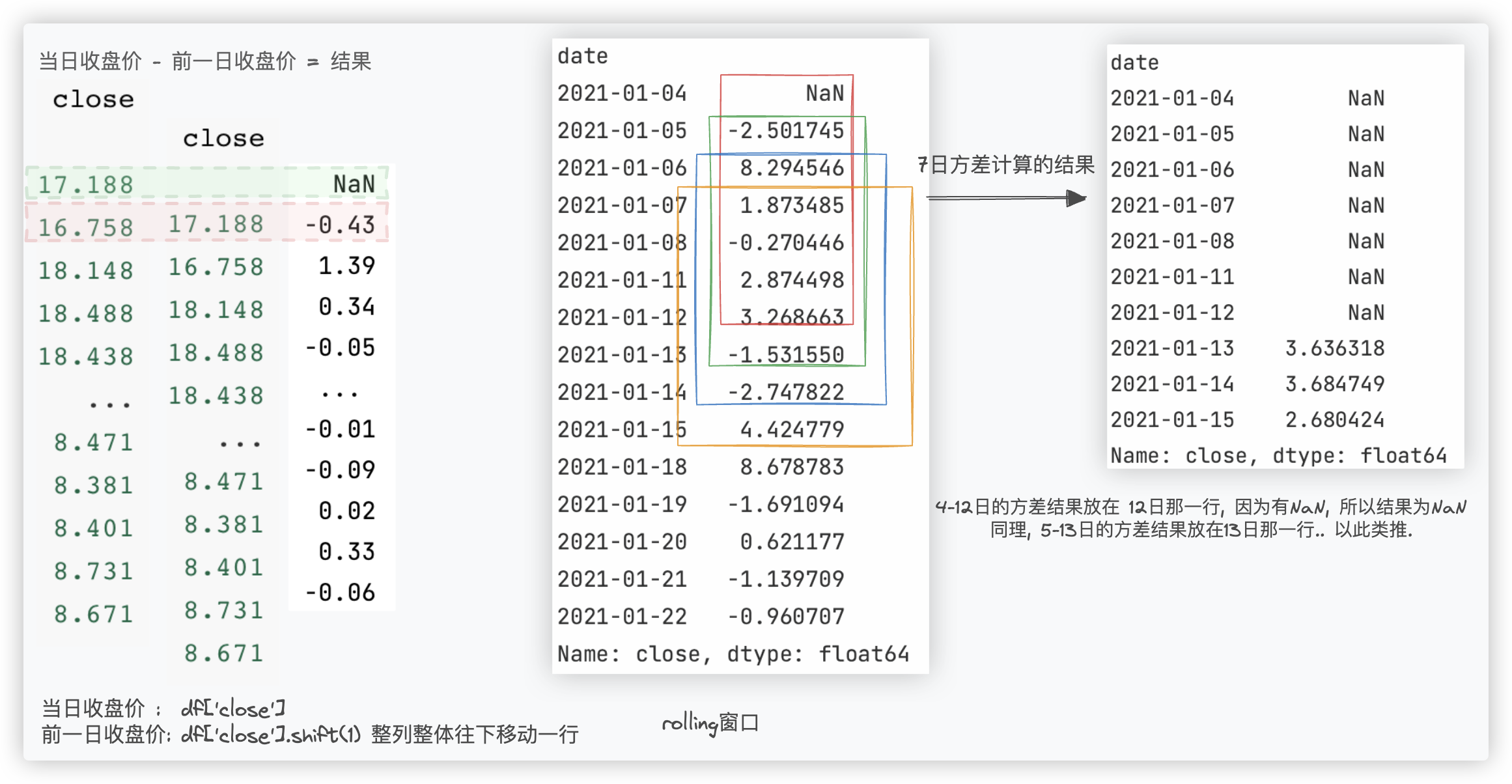
代码如下:
# (df['close'] - df['close'].shift(1)) / df['close'].shift(1) * 100
return_rate = df['close'].pct_change() * 100 # 收益率
volatility_rate = return_rate.rolling(window=7).std() # 波动率
print(volatility_rate.head(10))
2
3
4
# 最大和最小
Q: 查找股票的市值最大和最小日
# 市值 = 收盘价 * 成交量
market_value = df['close'] * df['volume'] # type(market_value) --> Series
# 找出市值数据中最大最小值下标(市值最大和最小日期)max()求的是最大值,idxmax求的是最大值的索引/下标
max_market_value_day = market_value.idxmax()
min_market_value_day = market_value.idxmin()
print(max_market_value_day)
print(min_market_value_day)
2
3
4
5
6
7
8
# 开盘和收盘
Q1: 输出该股票所有收盘比开盘上涨3%以上的日期
方案一
ex = ((df['close'] - df['open']) / df['open']) > 0.03
print(ex)
print(ex[ex].index) # ★ ps:ex[~ex] 取false
"""
date
2021-01-04 False
2021-01-05 False
2021-01-06 True
2021-01-07 False
2021-01-08 False
...
2023-12-25 False
2023-12-26 False
2023-12-27 False
2023-12-28 True
2023-12-29 False
Length: 727, dtype: bool
"""
"""
DatetimeIndex(['2021-01-06', '2021-01-12', '2021-01-18', '2021-01-25',
'2021-01-27', '2021-02-01', '2021-02-03', '2021-03-03',
'2021-03-11', '2021-03-22', '2021-04-19', '2021-04-20',
'2021-04-21', '2021-05-25', '2021-07-06', '2021-07-15',
'2021-08-09', '2021-08-10', '2021-08-18', '2021-09-06',
'2021-09-07', '2021-09-10', '2021-09-28', '2021-10-15',
'2021-11-11', '2022-01-05', '2022-01-20', '2022-02-08',
'2022-03-10', '2022-03-11', '2022-03-16', '2022-03-22',
'2022-04-06', '2022-04-15', '2022-04-27', '2022-06-14',
'2022-06-15', '2022-08-31', '2022-11-01', '2022-11-04',
'2022-11-22', '2022-11-25', '2022-11-29', '2022-12-05',
'2023-01-03', '2023-01-04', '2023-02-20', '2023-05-08',
'2023-07-28', '2023-08-03', '2023-12-28'],
dtype='datetime64[ns]', name='date', freq=None)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
方案二
# 获取了True对应的行数据: 就是满足需求的行数据
df.loc[((df['close'] - df['open']) / df['open']) > 0.03]
# 基于index获取满足需求行数据的行索引
df.loc[((df['close'] - df['open']) / df['open']) > 0.03].index
2
3
4
Q2: 输出该股票所有开盘比前日收盘跌幅超过2%的日期
"""方案一"""
ex = ((df['open']-df['close'].shift(1))/df['close'].shift(1)) < -0.02
ex[ex].index
"""方案二"""
((df['open']-df['close'].shift(1))/df['close'].shift(1)) < -0.02 #(开盘-前日收盘)/前日收盘 < -0.02
df.loc[((df['open']-df['close'].shift(1))/df['close'].shift(1)) < -0.02].index
2
3
4
5
6
7
# 算收益
Q: 假如张三从2021年1月1日开始, 每月第一个交易日买入1手股票, 每年最后一个交易日卖出所有股票, 到2023-2-12, 收益如何?
分析: 1手股票等于100只股票,一个完整年要买12手,那就是1200只股票.
最后一年2023就是一个特殊的年, 因为每年的最后一天才卖, 但最后一年所买所花费的钱是需要计算到总收益中。
# print(df['2021':'2023'])
cost = df.resample('M').first()['open'].sum() * 100
print(cost) # 51961.399999999994
recv = df.resample('A').last()[:-1]['open'].sum()*1200
print(recv) # 33196.8
2
3
4
5
解释:
df是DataFrame的表格型数据. 该df的行索引是日期类型!!
首先我们可以通过df.resample('M')进行分组, (H小时、W星期、M月、A年等)
.first取出每组的第一行数据; .last取出每组的最后一行数据.
So, df.resample('M').first() 还是DataFrame对象
接着,df.resample('M').first()['open']取出open这一列,得到的是一个Series对象. 最后,进行sum运算.
df.resample('A').last()[:-1] 进行[:-1]操作,最后一行不要!!
PS: 因为该df的行索引是日期类型,所以还可以根据年来进行切片.
df['2021':'2023'] 整个数据集就只包含2021年到2023年的,所以切了个寂寞.
2
3
4
5
6
7
8
9
10
# 计算均线
Q: 计算该股票历史数据的5日均线和30日均线
对于每一个交易日, 都可以计算出前N天的移动平均值, 然后把这些移动平均值连起来, 成为一条线就叫做N日移动平均线.
移动平均线常用线有5天、10天、30天、60天、120天和240天的指标.
-1- 5天和10天的是短线操作的参照指标, 称做日均线指标;
-2- 30天和60天的是中期均线指标, 称做季均线指标;
-3- 120天和240天的是长期均线指标, 称做年均线指标.
ma5 = df['close'].rolling(5).mean()
ma30 = df['close'].rolling(30).mean()
# 将均线两列添加到原始数据中
df['ma5'] = ma5
df['ma30'] = ma30
# info看ma30、和ma5列有多少行的Nan值,然后将这些包含Nan值的行剔除掉!
print(df.info())
print(df.iloc[29:])
# To do: 利用matplotlib.pyplot画均值曲线,暂略.
2
3
4
5
6
7
8
9
10
11
12
# ★ 案例知识点汇总
★★★ 学会的新知识点:
■
df.to_csv('./gupiao.csv') # 默认是保存行索引和列索引的
■
df = pd.read_csv('./gupiao.csv', index_col=0)
的平替
df = pd.read_csv('./gupiao.csv')
★★★ df.drop(labels='Unnamed: 0', axis=1, inplace=True)
■
df['date'] = pd.to_datetime(df['date']) # 将日期列转换为日期类型,便于时间类型数据的运算
df.set_index('date', inplace=True) # 将date列作为原数据的行索引,不用默认的0 1 2.
■
(df['close'] - df['close'].shift(1)) / df['close'].shift(1)
等同于
df['close'].pct_change()
■
Serise对象.shift(1)
Serise对象.rolling(window=7)
Serise对象.std()
Serise对象 * Serise对象
Serise对象.max()
Serise对象.min()
Serise对象.idxmax()
Serise对象.idxmin()
Serise对象 > 0.03 # 结果是包含True、False的Serise对象
S4[S4 > 0.03 ]
S4[~(S4 > 0.03)]
df.loc[((df['close'] - df['open']) / df['open']) > 0.03] # 获取了True对应的行数据: 就是满足需求的行数据
--> ★★★ 解释下: df.loc[True和False组成的Serise对象] -- 保留True值对应的行!
其实可以直接 df[((df['close'] - df['open']) / df['open']) > 0.03] 一样的效果.
df.resample('A').last()[:-1] # 前提:dataframe的行索引是时间类型
df1.iloc[[True,True,False,False,True]]
df1.loc[[True,True,False,False,True]]
df1[[True,True,False,False,True]]
这三者是一样的效果.
注意:
iloc接受有返回值的函数作为参数,但要保证函数返回的是整数/整数list,布尔值/布尔list.
So,若是bool值的Serise对象,iloc不行,loc可以.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40