 Serializer总结
Serializer总结
关于序列化器里的上下文
- ser的context上下文在Field类的context方法里.(从这里开始分析!)
class Field:
@property
def root(self):
root = self
while root.parent is not None:
root = root.parent
return root
@property
def context(self):
return getattr(self.root, '_context', {})
- 在BaseSerializer的__init__里有这行代码,意味着序列化器类的实例可以传context参数!!
self._context = kwargs.pop('context',{}) # ★ 看到没,一开始它就是个字典!
eg: 阅读视图类GenericAPIView的get_serializer方法的源码,该方法中的context上下文就是这样使用的!!!
- 如何使用呢?伪代码如下:
# 序列化器类里
class LoginSerializer(serializers.ModelSerializer):
class Meta:
model = models.User
fields = ['username', 'password']
def validate(self, attrs):
token = "..."
self.context['token'] = token # ★★★ 给context字典赋值
return attrs
# 视图类里
class LoginView(ViewSet):
def login(self, request):
ser = serializer.LoginSerializer(data=request.data)
if ser.is_valid():
token = ser.context.get('token') # ★★★ 在context字典中取值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
另外需注意的点
- ser.validated_data 是在ser.is_valid 校验通过后使用的, 若在钩子函数中使用ser.validated_data 会报错!!
- 若想在某个字段钩子函数中使用上一个字段钩子校验通过的值,可以从 ser.initial_data中取到上一个字段的值!!
虽然ser.initial_data是前端传过来的原始数据,但能执行到某个字段的钩子,那么证明上一个字段的校验肯定通过了的,
所以直接用ser.initial_data里面那么“对应上一个字段”的值,是没有任何问题的!
1
2
3
4
2
3
4
# 序列化Demo
# 示例代码
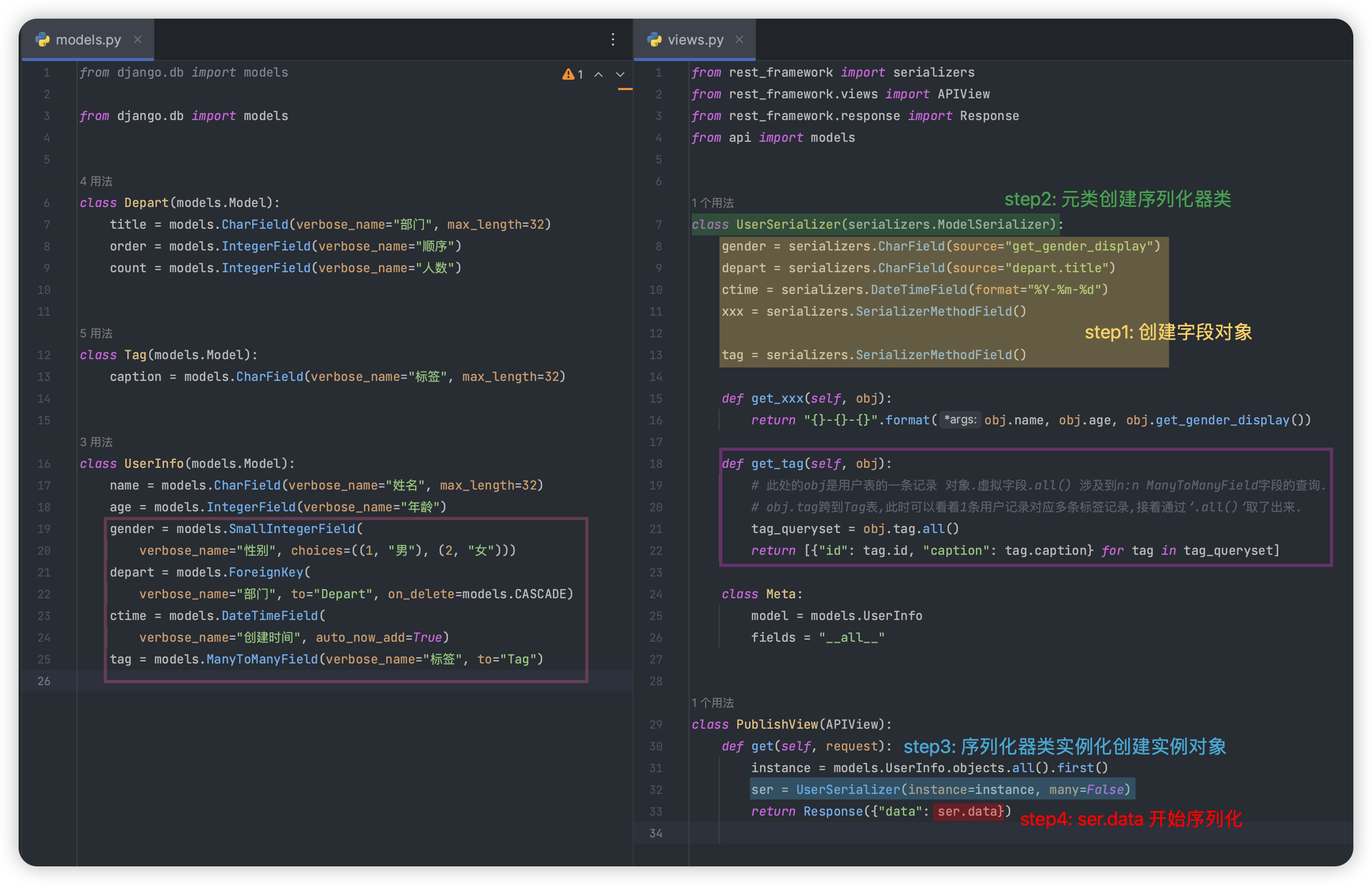
# 添加实验数据
你把ORM表给ChatGpt, 它会自动帮你生成, 哈哈哈哈!太省事了.
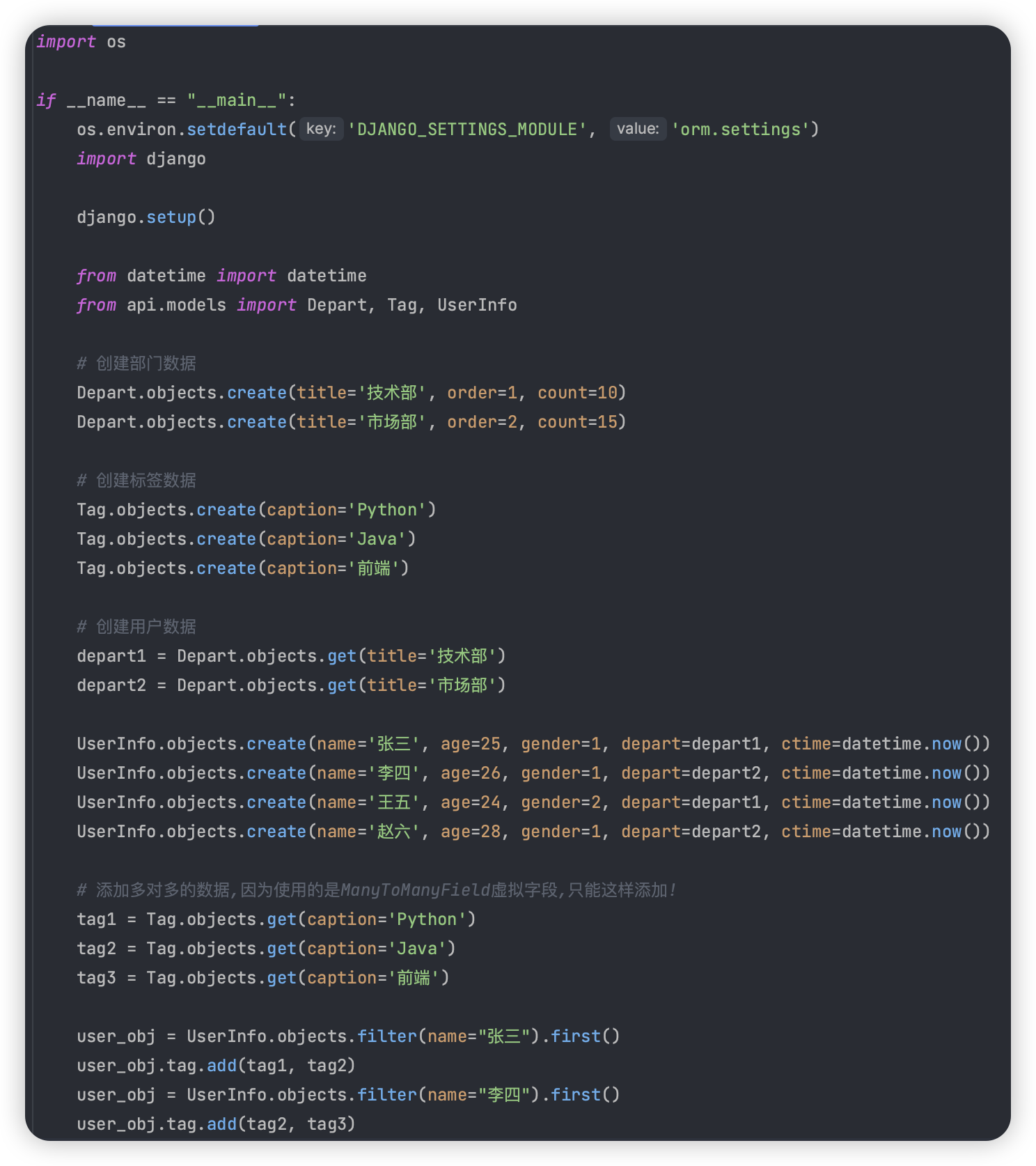
# 数据库数据
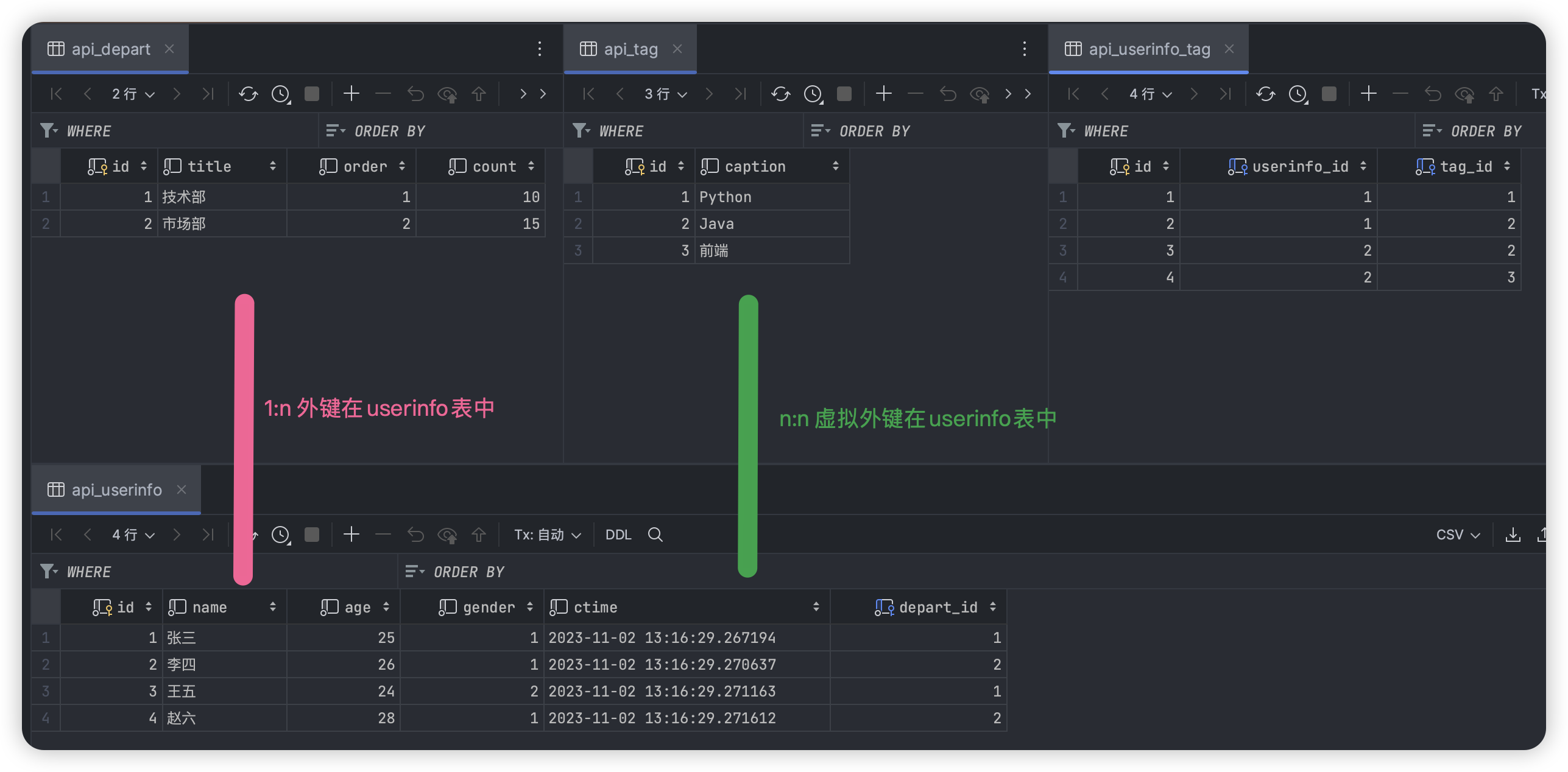
# 实验结果
查询一条数据, 这样写接口是不规范的.. 但这里不是重点探究这个,将就下吧.
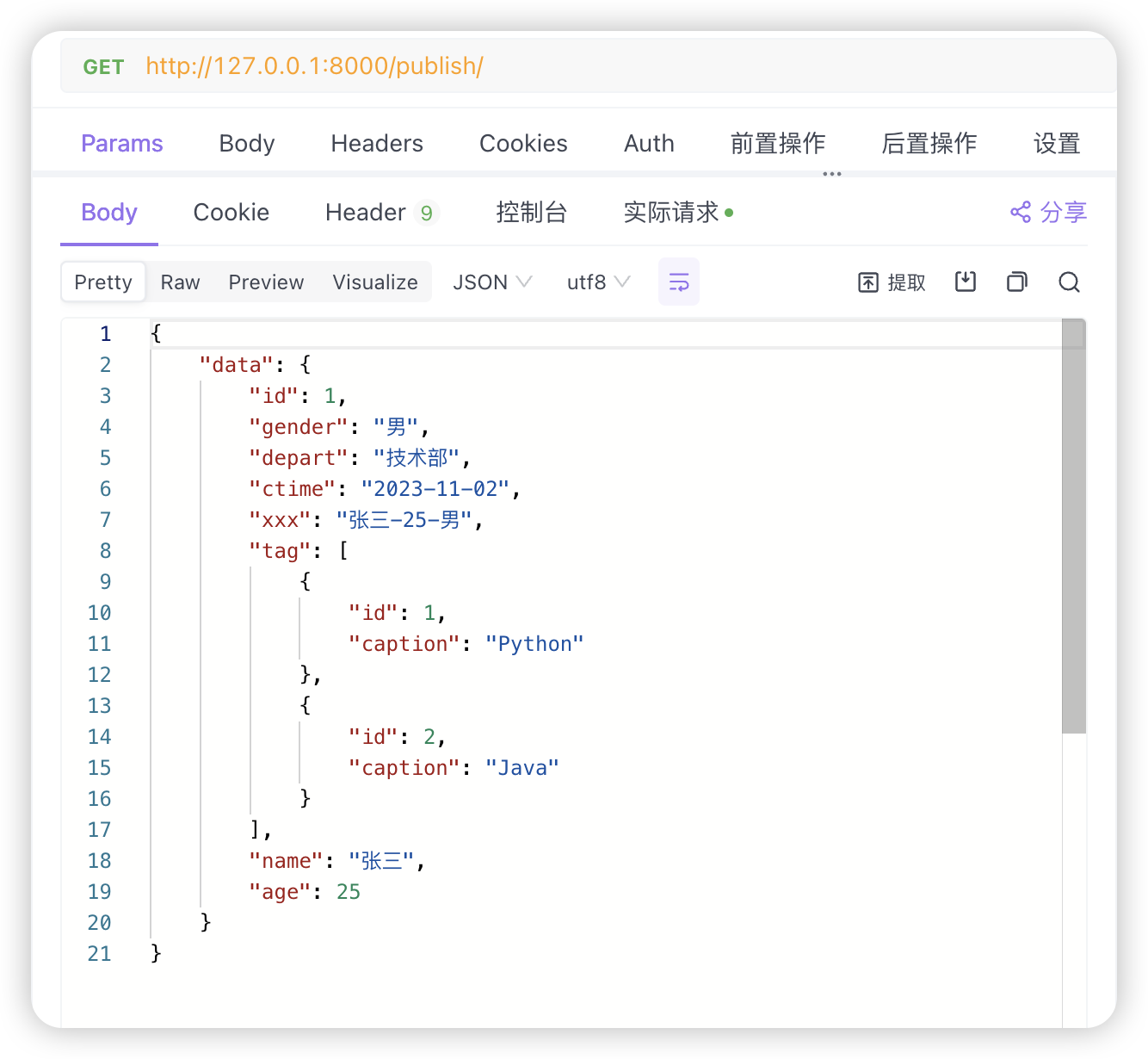
# 序列化
每一步详细的源码过程可以翻阅 序列化源码.md !!
我只能说, 总结的很完美!! 哈哈哈哈哈.
下方是单条数据序列化的流程图!!
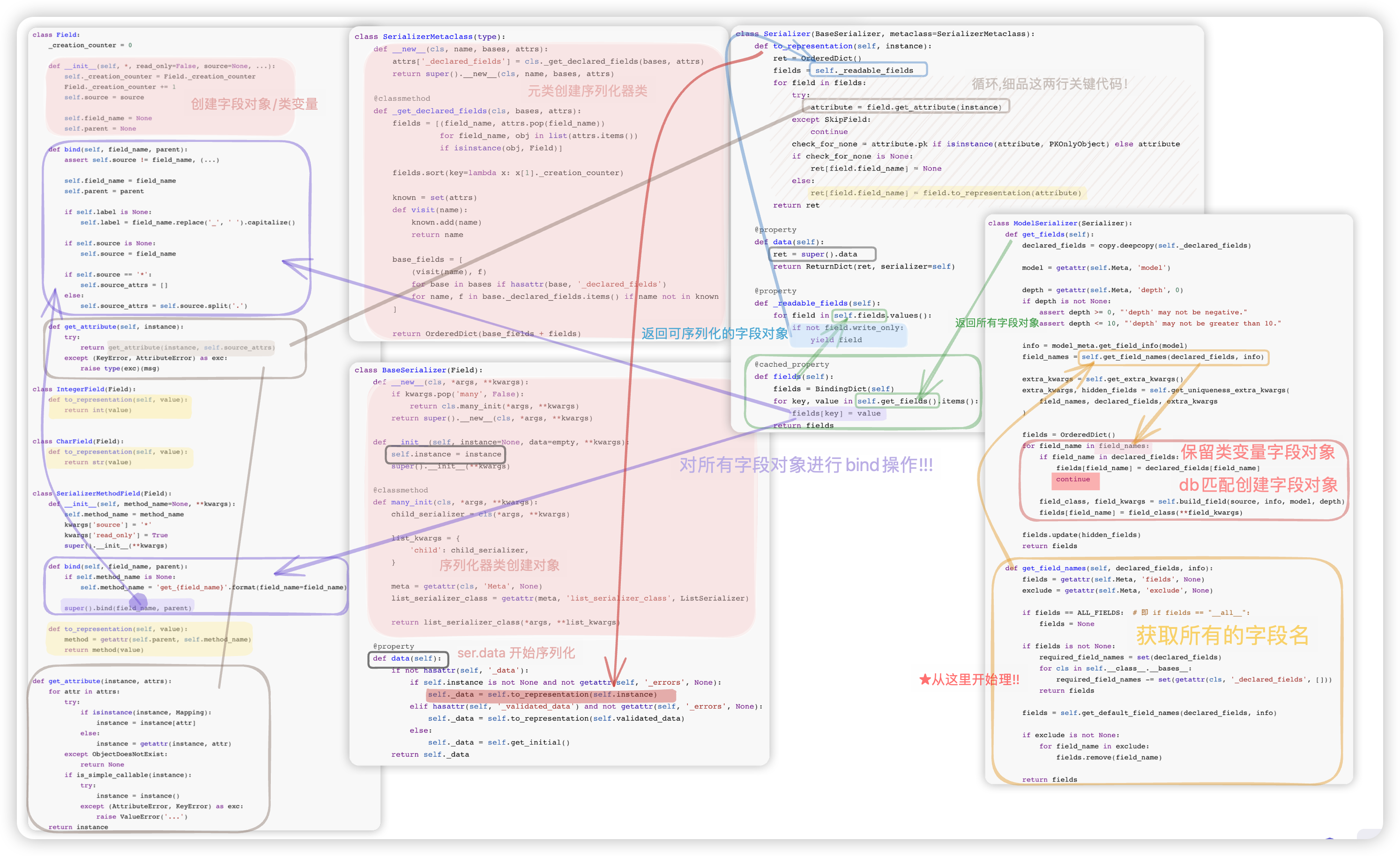
详细说明如下:
1. 创建字段对象
- _creation_counter 计数器
2. 元类创建序列化器类
- 剔除 类成员“字段类型的类变量” 加到 新增的类成员_declared_fields中, 其余类成员Meta等不变
3. 序列化器类实例化创建对象
- instance=instance many = False => UserSerializer类的实例
- instance=queryset many = True => ListSerializer类的实例,该实例有成员UserSerializer类的实例!!
4. ser.data开始序列化 以单条数据为例 <下面总结顺序跟看源码的流程相反,逆向思维,更容易理解>
1> @cached_property ★ 该方法被它装饰了哦!!
ser.fields 获取所有经过bind处理后的字段对象
[1] ser.get_fields 获得所有字段对象
注: 在获取所有字段对象阶段, 你序列化器类里定义了啥字段类型的类变量都可以,都不会报错..
[1-1] ser.get_field_names 获取所有的字段名 (请翻阅,该小节总结的规则)
特地说下filed和exclude
- filed = [类变量名些“必须写进来”、ORM表中的字段名 无其他选择]
- exclude = ORM表中的一些字段名(需排除通过类变量重写的字段名) 无其他选择
★ ser.get_field_names返回的字段名集合 必定 小于等于/包含于等于 [字段类型的类变量+ORM表中的字段名]
[1-2] 将上一步获得的字段名分为两组 注:第一组优先级高于第二组,因为类变量可能会跟ORM表中的字段名重名.
- 第一组, 字段类型的类变量 保留该字段对象
- 第二组, ORM表中的字段名 db匹配自动创建字段对象 (PS,ORM表中字段的verbose_name对应创建的字段对象的label属性)
[2] bind 将所有字段对象经过bind处理
[2-1] bind操作 处理字段对象的一些属性 field_name、parent、label、source、source_attrs
- 如何处理的? (请翻阅,该小节总结的规则)
2> ser._readable_fields 筛选出not write_only,即可序列化的字段对象
3> 对筛选后的这些字段对象进行循环
ret = OrderedDict()
for field in fields:
# eg1: attribute = <UserInfo object>.depart.title
# eg2: attribute = instance
# 特别注意,它使用的是source_attrs !!!
attribute = field.get_attribute(instance) # 得到的结果 可能是数据库中字段对应的值、也可能是instance一条记录.
# eg1: ret["depart"] = str(<UserInfo object>.depart.title)
# eg2: ret["Xxx"] = SerializerMethodField().to_representation(instance)
ret[field.field_name] = field.to_representation(attribute)
- 需要特别注意的是 SerializerMethodField 类型的字段对象!!序列化的自定义字段绑定的方法的value参数是数据库中的一条记录.
==||++ 若是多条数据,就多了个循环,注意ListSerializer类的实例里child成员!!
- ser.get_fields的结果/返回值 "获得的所有字段对象"
OrderedDict([
('id', IntegerField(label='ID', read_only=True)),
('gender', CharField(source='get_gender_display')),
('depart', CharField(source='depart.title')),
('ctime', DateTimeField(format='%Y-%m-%d')),
('xxx', SerializerMethodField()),
('tag', SerializerMethodField()),
('name', CharField(label='姓名', max_length=32)),
('age', IntegerField(label='年龄'))
])
- ser.fields的结果/返回值 "经过bind处理后的所有字段对象" “字段对象里的field_name就是字段名!”
{
'id': IntegerField(label='ID', read_only=True),
'gender': CharField(source='get_gender_display'),
'depart': CharField(source='depart.title'),
'ctime': DateTimeField(format='%Y-%m-%d'),
'xxx': SerializerMethodField(),
'tag': SerializerMethodField(),
'name': CharField(label='姓名', max_length=32),
'age': IntegerField(label='年龄')
}
你别看上面打印的结果没啥改变,循环打印每个字段对象中的这些属性field_name、label、source、source_attrs,就原形毕露了!
(PS:打印字段对象的parent属性会一直递归,不知啥原因,暂且不管.)
IntegerField(label='ID', read_only=True) id ID id ['id']
CharField(source='get_gender_display') gender Gender get_gender_display ['get_gender_display']
CharField(source='depart.title') depart Depart depart.title ['depart', 'title']
DateTimeField(format='%Y-%m-%d') ctime Ctime ctime ['ctime']
SerializerMethodField() xxx Xxx * []
SerializerMethodField() tag Tag * []
CharField(label='姓名', max_length=32) name 姓名 name ['name']
IntegerField(label='年龄') age 年龄 age ['age']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# 验证+存储

来抓一抓错误
class ValidationError(APIException):
status_code = status.HTTP_400_BAD_REQUEST
default_detail = _('Invalid input.')
default_code = 'invalid'
# 看到没,detail可以位置传参传过去!
def __init__(self, detail=None, code=None):
if detail is None:
detail = self.default_detail
if code is None:
code = self.default_code
if isinstance(detail, tuple):
detail = list(detail)
elif not isinstance(detail, dict) and not isinstance(detail, list):
detail = [detail]
self.detail = _get_error_details(detail, code)
先看图中的右下角的run_validators函数, errors=[] 字段自身的校验,有多个规则不满足,不满足的都会收集到
然后该函数 raise ValidationError(errors) 在Serializer类中的to_internal_value被捕获
特别注意的是, errors[field.field_name] = exc.detail ★看到没,错误信息的key是字段名!! 而且try..except..处于for循环里.
最后,与raise ValidationError(errors) 在BaseSerializer类中的is_valid被捕获
So,举个例子,字段自身校验不通过,ser.errors的值像这个样子:
{'mobile': [ErrorDetail(string='该字段不能为空。', code='blank')],
'password': [ErrorDetail(string='该字段不能为空。', code='blank')]}
只不过,后端通过Response处理后返回给前端,前端拿到的是 {'mobile': ['该字段不能为空。'], 'password': ['该字段不能为空。']}
那关于全局钩子中的报错呢?你看源码,关键在于这行语句
raise ValidationError(detail=as_serializer_error(exc)) 细看as_serializer_error
def as_serializer_error(exc):
assert isinstance(exc, (ValidationError, DjangoValidationError))
if isinstance(exc, DjangoValidationError):
detail = get_error_detail(exc)
else:
detail = exc.detail
if isinstance(detail, Mapping):
return {
key: value if isinstance(value, (list, Mapping)) else [value]
for key, value in detail.items()
}
elif isinstance(detail, list):
return {
api_settings.NON_FIELD_ERRORS_KEY: detail # ★★★
}
return {
api_settings.NON_FIELD_ERRORS_KEY: [detail] # ★★★
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
值得注意的点:
- 若ORM表中写了这样的字段
ext1 = models.CharField(verbose_name="格外1", max_length=11, blank=True, null=True)
ext2 = models.IntegerField(verbose_name="格外2", blank=True, null=True)
★ 通过db匹配后,会自动生成的这样的字段对象: !!
CharField(allow_blank=True, allow_null=True, label='格外1', max_length=11, required=False)
IntegerField(allow_null=True, label='格外2', required=False)
看到没,required=False意味检验的话,前端不是必传.
另外生成的字段对象的default值为<class 'rest_framework.fields.empty'>
★ 经过ser.data序列化后,ext1和ext2字段值的结果都是null
关于这个,有点模糊不清,做项目时再探究.(可先看下官方文档)
https://q1mi.github.io/Django-REST-framework-documentation/api-guide/fields_zh/#allow_null
https://q1mi.github.io/Django-REST-framework-documentation/api-guide/fields_zh/#charfield
- 若序列化器类写了额外字段 more = serializers.CharField(default="默认")
那么经过__init__实例化后,该字段required=False,default="默认"
- 若ORM表中写了这样的字段
ext3 = models.IntegerField(verbose_name="格外3",default=25)
★ 通过db匹配后,会自动生成的这样的字段对象: !!
IntegerField(label='格外3', required=False) 另我很疑惑的是,其default值是 <class 'rest_framework.fields.empty'>
- save操作
def create(self, validated_data):
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish = validated_data.get('publish', instance.publish)
instance.save()
return instance
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 验证+存储+序列化

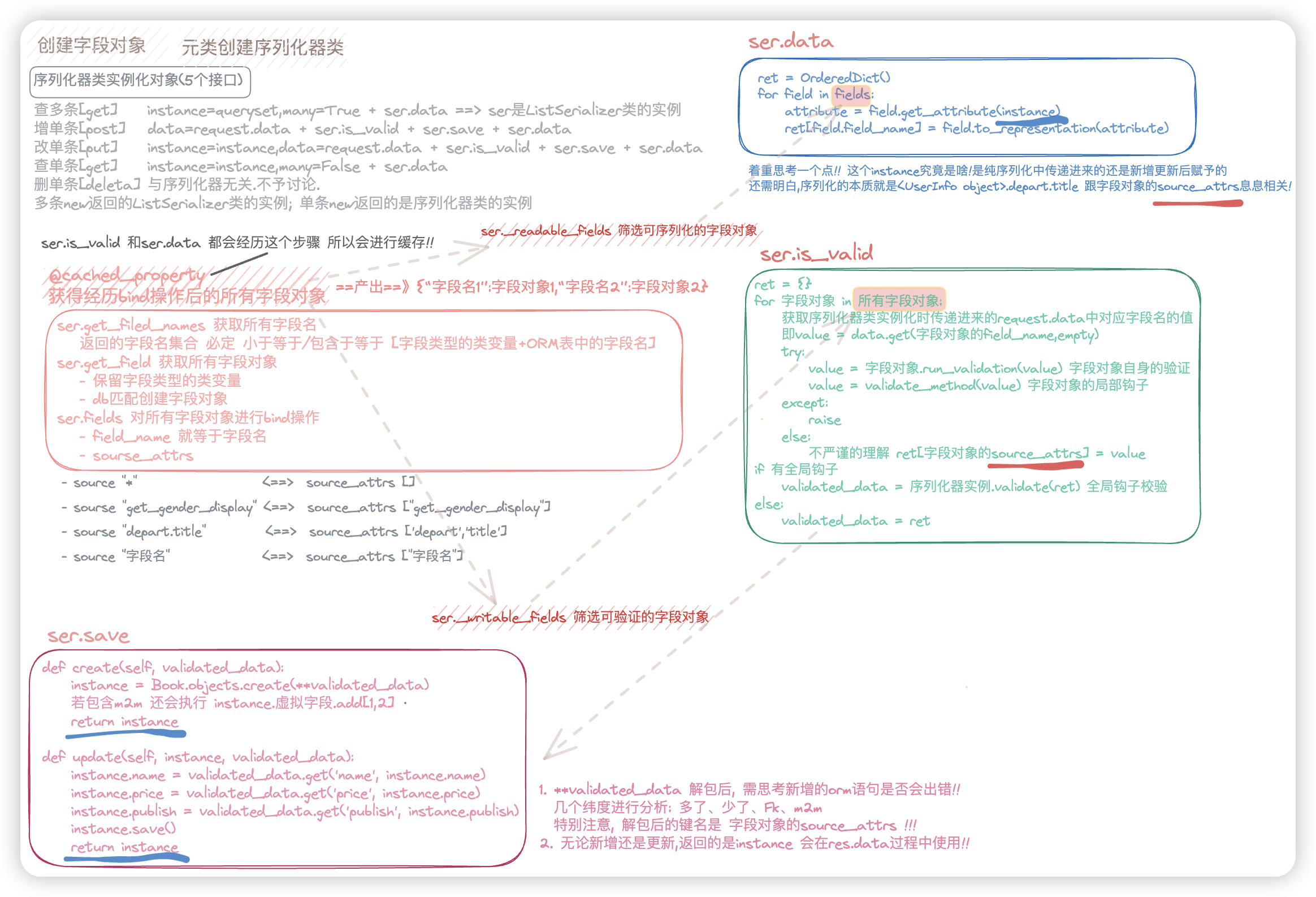
Ps: 上图的更新还有个奇淫技巧 instance.__dict__.update(**validated_data)
分析下整体过程
序列化器中类变量以及Meta中写的那些字段,只能决定 有哪些字段对象可以拿来用.
read_only和write_only才决定了哪些字段拿来序列化,哪些拿来验证. 拿来验证的字段才是必须要传的!
= 1.纯序列化单条记录 =
ser = ExampleModelSerializer(instance=instance)
ser.data
= 2.纯序列化多条记录=
ser = ExampleModelSerializer(instance=queryset,many=True)
ser.data
= 3.验证前端传递的数据 - 保存数据库 - 序列化 =
ser = ExampleModelSerializer(data=request.data)
ser.is_valid()
ser.data
= 4.验证前端传递的数据 - 更新数据库 - 序列化 =
ser ExampleModelSerializer(data=request.data,instance=instance)
ser.is_valid()
ser.data
【壹壹壹】
上述的4种情况,无论哪一种,都会先经历三步!
1> 创建字段对象
以前字典是无序的.所以里面有个计数器,表明先后创建的顺序.
2> 基于元类创建序列化器类
'_declared_fields' -> {'name':IntegerField字段对象,'age':CharField字段对象}
注意其key值是类变量的变量名,value值是该类变量名对应的值.
3> 创建序列化器的对象
主要是根据many=True和many=False创建的对象不同.毕竟new方法返回啥,该实例对象就是啥.
ExampleModelSerializer() or ListSerializer(child=ExampleModelSerializer())
【贰贰贰】
ok,前面三步进行完后,会执行ser.data或者ser.is_valid(),我们继续寻找共同点!
只要是执行ser.data或者执行ser.is_valid(),都会经历这三步.
★★★ 本质就是在执行Serializer类中被@cached_property装饰的fields方法!!
@cached_property会将fields方法的执行结果放到ser的__dict__中, 即ser.__dict__["fields"] = 结果
★★★ So, ser.is_valid()后再ser.data,不会再执行一遍 以下三步/fields方法! 而是会直接去__dict__中取.
1> 获得所有的字段名field_names = 获取序列化器类中类变量的变量名 + 序列化器类使用的model表中的所有字段名
注意:
若写"__all__",是 类变量名 + db中字段名, field_names列表中,还有可能重复
若fields指定了字段,[那么额外字段得写在里面],因为 field_names列表就是fields的值.
2> 会循环field_names获得所有的字段对象 =
'_declared_fields'中的字段对象原封不动 + 匹配数据库自动创建的字段对象(注:字段名与类变量重复了不会匹配创建)
所有字段对象 {'类变量变量名':字段对象,'数据库中的字段名':匹配自动创建字段对象}
3> 会循环所有字段对象,执行Field类里的bind方法!
bind(self, field_name, parent) field_name就是循环的每一项的key值,parent就是序列化器类实例
- 关于字段对象里的成员 field_name 等于 key值,就是字段名
- 关于字段对象里的成员 source
- 字段对象有source的 source值不变
- 字段对象有没有设置source的 字段对象的source等于field_name,即字段名
- 关于字段对象里的成员 source_attrs
- source_attrs = source.split('.')
'depart.title' -> ['depart','title'] 'get_gender_display' -> ["get_gender_display"] 'name' -> ['name']
ok,经过上述流程,提醒一点序列化器类实例化时候传入的 instance/data 里实参都还没有咋使用.
只是序列化器类实例的实例里躺着两个成员 self.instance 和 self.initial_data
开始分情况讨论
= 情况1/2,纯序列化 = 注:无论单条还是多条数据,本质都是一样的. 假如"instance是UserInfo表的一条记录<UserInfo object>"
ser = ExampleModelSerializer(instance=instance) # 1
ser.data # 2
○ 执行第1条语句ser = ExampleModelSerializer(instance=instance)时先执行【壹壹壹】
○ 执行第2条语句时ser.data先执行【贰贰贰】, 接着
step1> 接着,会再次循环所有字段对象, 不要write_only=True的字段对象.
得到可用于序列化的字段对象 [字段对象1,字段对象2,字段对象3...]
step2> 接着,循环 可用于序列化的字段对象 [字段对象1,字段对象2,字段对象3...]
关键在于执行两行代码.
"""假比,instance是UserInfo表的一条记录<UserInfo object>,该表的Fk字段depart,有choice属性的字段gender
ret["depart"] = str(<UserInfo object>.depart.title)
ret["gender"] = str(<UserInfo object>.get_gender_display())
"""
- attribute = field.get_attribute(instance)
- ret[field.field_name] = field.to_representation(attribute)
= 情况3,验证前端传递的数据 - 保存数据库 - 序列化 =
ser = ExampleModelSerializer(data=request.data) # 1
ser.is_valid() # 2
ser.data # 3
○ 执行第1条语句ser = ExampleModelSerializer(data=request.data)时先执行【壹壹壹】
○ 执行第2条语句时ser.is_valid()先执行【贰贰贰】,接着
step1> 接着,会再次循环所有字段对象, 不要read_only=True的字段对象.
得到可用于验证的字段对象 [字段对象1,字段对象2,字段对象3...]
step2> for 字段对象 in 可用于验证的字段对象 [字段对象1,字段对象2,字段对象3...]
先会通过伪代码 value = data[field.field_name] 拿到当前字段对象在前端传递的Json数据中对应的值!
校验字段自己的规则 - 检验成功,返回value
执行字段的钩子函数 - 上一步返回的value传递给字段钩子函数,检验成功,返回value
在最后,执行了set_value(ret, field.source_attrs, value)
上述过程,相当于 有个字典validated_data,每次循环都会执行 validated_data[field.source_attrs] = value
step3> 执行全局钩子函数 其参数是validated_data. - 校验通过,返回的也是validated_data
step4> 执行save() 也就是执行 self.instance = self.create(validated_data, **kwargs)
★ 注意啊!self是ser,所以ser中的instance成员有值啦!!!
就此,验证并存储数据库执行完毕
○ 执行第3条语句ser.data时不会重新执行[贰贰贰],它直接拿到ser.is_valid()执行[贰贰贰]时的结果!
step5> 开始 情况1/2 纯序列化中的 第一步和第二步.
= 情况4,验证前端传递的数据 - 更新数据库 - 序列化 =
ser ExampleModelSerializer(data=request.data,instance=instance) # 1
ser.is_valid() # 2
ser.data # 3
其实与情况3整体并无不同,仅仅只是在save时候
是self.instance = self.update(self.instance, {**validated_data, **kwargs})
也就是说,传入的instance只是在更新数据的时候使用了下!!
后续执行ser.data时使用的是 重新赋值后的 self.instance!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
★★★ 粘贴一下非常重要的源码.
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super().__init__(**kwargs)
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
# - 决定了序列化器类实例化时返回的实例是什么.
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
@property
def data(self):
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
# ser=A(instance=instance) ser.data
# ser=A(data=request.data) - ser.is_valid() - save() - ser.data
# ser=A(data=request.data,instance=instance) - ser.is_valid() - save() - ser.data
# 上面三个流程,执行ser.data时,都会执行这里.
# 只不过,self.instance不一样,分别是 传入的/新增的/更新的! 因为运行save时,将结果赋值给了self.instance.
# - ★ 跳转到Serializer的to_representation方法 里面有条重要语句 fields = self._readable_fields !!!
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
# ser=A(data=request.data) ser.is_valid() 没有save 直接ser.data时执行!!
self._data = self.to_representation(self.validated_data)
else:
# 其余情况 比如: ser=A() ser.data
self._data = self.get_initial()
return self._data
def is_valid(self, *, raise_exception=False):
# - 注意,重复多次校验,只会走一次
if not hasattr(self, '_validated_data'):
try:
# - ★ 开始校验 跳转到Serializer的run_validation方法
# 里面有个重要语句 self.to_internal_value(data)
# - 然后在to_internal_value方法中,fields = self._writable_fields!!!
self._validated_data = self.run_validation(self.initial_data)
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail
else:
self._errors = {}
if self._errors and raise_exception:
raise ValidationError(self.errors)
return not bool(self._errors)
def save(self, **kwargs):
validated_data = {**self.validated_data, **kwargs}
# ★该self就是ser,给ser.instance赋值啦!!
if self.instance is not None:
self.instance = self.update(self.instance, validated_data) # -- 更新
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data) # -- 新增
assert self.instance is not None, (
'`create() did not return an object instance.'
)
return self.instance
@property
def validated_data(self):
if not hasattr(self, '_validated_data'):
msg = 'You must call `.is_valid()` before accessing `.validated_data`.'
raise AssertionError(msg)
return self._validated_data # 返回所有校验通过的前端传递的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
方法的参数、返回值; 当前self是谁, 赋值操作时, 给它添加了啥成员;@cached_property; 这些就是我此次梳理源码后的心得!!