 分页
分页
在Django中,Django自带的分页器不好用,于是我们自定义了分页器;
在DRF中, DRF自带的分页器还可以, 该篇博文将阐述其中两种最常用的分页器 PageNumberPagination、LimitOffsetPagination.
# 准备工作
创建实验数据, 为后面的分页做准备!! 可以看到,我们查看book列表,一共有10条数据!
数据库表
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
2
3
4
5
6
路由配置
from django.urls import path
from api import views
urlpatterns = [
path("api/<str:version>/book/",views.BookView.as_view())
]
2
3
4
5
6
视图相关逻辑
from rest_framework.views import APIView
from rest_framework import serializers
from rest_framework.response import Response
from api import models
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
class BookView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Book.objects.all()
ser = BookSerializer(instance=queryset, many=True)
return Response({"code": 200, "data": ser.data})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
GET请求 http://127.0.0.1:8000/api/2/book/
{
"code":200,
"data":[
{"id":1,"name":"第1本书.","price":10},
{"id":2,"name":"第2本书.","price":20},
{"id":3,"name":"第3本书.","price":30},
{"id":4,"name":"第4本书.","price":40},
{"id":5,"name":"第5本书.","price":50},
{"id":6,"name":"第6本书.","price":60},
{"id":7,"name":"第7本书.","price":70},
{"id":8,"name":"第8本书.","price":80},
{"id":9,"name":"第9本书.","price":90},
{"id":10,"name":"第10本书.","price":100}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 基本分页
PageNumberPagination 我们一般就使用默认的.
查看PageNumberPagination的源码, 得理清楚它的几个类变量:
class PageNumberPagination(BasePagination):
page_size = api_settings.PAGE_SIZE # -- 默认每页显示的条数
django_paginator_class = DjangoPaginator
page_query_param = 'page' # -- 第几页
page_query_description = _('A page number within the paginated result set.')
"""若想动态的设置每页展示的条数!! (注意,是每页不是当前页.)
page_size_query_param和max_page_size都得一块设置!!
比如:
page_size_query_param=ps
max_page_size = 5
那么
/books/?page=3&ps=2 第3页,每页显示2条数据
/books/?page=3&ps=100 第3页,每页显示5条数据
Ps: 若一共10条数据,那么访问/books/?page=3&ps=100时会报错.
因为ps>max_page_size,So,使用max_page_size 第3页 3*5=15>10 所以报错!!
"""
page_size_query_param = None
page_size_query_description = _('Number of results to return per page.')
max_page_size = None # -- 限制的动态的显示每页的条数的最大值,不会限制默认每页展示的条数.
last_page_strings = ('last',)
template = 'rest_framework/pagination/numbers.html'
invalid_page_message = _('Invalid page.')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 快速使用
利用 PageNumberPagination 里自带的 方法快速实现分页功能!!
配置文件
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None,
"PAGE_SIZE": 2, # - 默认每页显示多少条
}
2
3
4
视图相关逻辑
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.pagination import PageNumberPagination
from api import models
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
class BookView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Book.objects.all()
# PageNumberPagination、以及它的父类BasePagination都没有__init__,没有初始化处理.
# 所以就是单纯的创建了一个实例.
pager = PageNumberPagination()
# 参数: 从db中取到的数据、request、当前视图类的实例对象.
# 传入request就是为了取url中的那些get参数!
# 返回: 包含对象的列表
# eg: [<Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (6)>]
p_list = pager.paginate_queryset(queryset, request, self)
# 注意,此处传入的是p_queryset
ser = BookSerializer(instance=p_list, many=True)
"""
- pager.get_paginated_response(ser.data) 该方法返回的也是一个Response的对象/实例
- Response("Hello")
- Response(queryset)
打印他们,结果都是<Response status_code=200, "text/html; charset=utf-8">
只有在视图函数中,将其返回前端时,才会校验传给Response的对象是否是可序列化的数据.
所以仅管queryset对象不可被序列化,print(Response(queryset))时也不会报错!
'看了下源码,Response类实例化过程中只有init,里面也没有判断传入的数据是否可序列化.'
<我又从后面的学习回来了> 这里解释下,回顾下drf CBV的执行流程,视图函数的返回值在disptch里还要做处理的!
若通过这种方式返回前端数据,不会有总页数,上一页下一页的链接.
return Response({"code": 200, "data": ser.data})
"""
return pager.get_paginated_response(ser.data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
利用postman模拟前端发送GET请求, http://127.0.0.1:8000/api/2/book/?page=2
{
"count": 10,
"next": "http://127.0.0.1:8000/api/2/book/?page=3",
"previous": "http://127.0.0.1:8000/api/2/book/",
"results": [
{
"id": 3,
"name": "第3本书.",
"price": 30
},
{
"id": 4,
"name": "第4本书.",
"price": 40
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 动态显示每页条数
可以写个类继承PageNumberPagination, 里面的类变量就可以自定义啦!!
from rest_framework import serializers
from rest_framework.pagination import PageNumberPagination
from rest_framework.views import APIView
from api import models
class MyPageNumberPagination(PageNumberPagination):
# - 默认每页显示多少条
page_size = 2
# - url传递ps参数,动态的显示每页多少条
page_size_query_param = 'ps'
max_page_size = 6
""" 在PageNumberPagination的源码中,get_paginated_response方法是这样写的
若对该封装的数据结构不太满意,可以在我们自己写的子类MyPageNumberPagination中重写get_paginated_response方法!!
def get_paginated_response(self, data):
return Response(OrderedDict([
('count', self.page.paginator.count),
('next', self.get_next_link()),
('previous', self.get_previous_link()),
('results', data)
]))
该源码其实跟下述的写法效果一样的!!(已实验过了,放心食用.)
def get_paginated_response(self, data):
return Response({
'count': self.page.paginator.count,
'next': self.get_next_link(),
'previous': self.get_previous_link(),
'results': data,
})
"""
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
class BookView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Book.objects.all()
pager = MyPageNumberPagination() # 改成我们自定义的分页组件
p_list = pager.paginate_queryset(queryset, request, self)
ser = BookSerializer(instance=p_list, many=True)
return pager.get_paginated_response(ser.data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
Get请求 http://127.0.0.1:8000/api/2/book/?page=2&ps=100
分析: db中一共10条数据, ps值超过了max_page_size, 所以每页展示6条, 第一页展示了6条, 第二页只能展示4条数据了..
按照该逻辑, 若get请求访问, http://127.0.0.1:8000/api/2/book/?page=3&ps=100 就会报错.
注意一点:
仅管many=True,但是ps=1,每页展示1条数据也是没问题的!
突然提醒我了,灵活点,many=True时,传入的是queryset对象就行! 不一定非是多条数据.
models.Book.objects.filter(id=1)的结果也是queryset对象哒.虽然只有一条数据.
Ps: many=True时, instance传入包含对象的列表也都可以!!!
{
"count": 10,
"next": null,
"previous": "http://127.0.0.1:8000/api/2/book/?ps=100",
"results": [
{
"id": 7,
"name": "第7本书.",
"price": 70
},
{
"id": 8,
"name": "第8本书.",
"price": 80
},
{
"id": 9,
"name": "第9本书.",
"price": 90
},
{
"id": 10,
"name": "第10本书.",
"price": 100
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 偏移分页
LimitOffsetPagination 适用于滚动页面的翻页.
# 简单使用
取出来的数据, 不管正序还是倒序取, 都会依次放到一个 容器里.
offset其实指的是 容器里的某个下标位置..(位置是从0开始数的) limit是从该位置开始从容器中取几条数据.分页是拿容器里的记录分页.
配置文件
REST_FRAMEWORK = {
"UNAUTHENTICATED_USER": None,
"PAGE_SIZE": 3,
}
2
3
4
视图函数
from rest_framework import serializers
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
class BookView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Book.objects.all().order_by("-id")
pager = LimitOffsetPagination()
p_list = pager.paginate_queryset(queryset, request, self)
ser = BookSerializer(instance=p_list, many=True)
return pager.get_paginated_response(ser.data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
实验结果
取出来的数据, 不管正序还是倒序取, 都会依次放到一个 容器里.
offset其实指的是 容器里的某个下标位置(从0开始).. limit是从该位置开始从容器中取几条数据.
现在,一共从表中倒序取了10条数据,放到了一个容器中 默认每次取3条数据.
就像这样 [ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
△ △ △ △ ..
位置0 位置1 位置2 位置3 ==> 将容器看成一个列表,位置就是下标
So, /api/2/book/?limit=3&offset=0 取容器中第0个位置到第2个位置的数据!即ID10、ID9、ID8 -- /api/2/book/
/api/2/book/?limit=3&offset=3 取容器中第3个位置到第5个位置的数据!即ID7、ID6、ID5
/api/2/book/?limit=3&offset=6 取容器中第6个位置到第8个位置的数据!即ID4、ID3、ID2
2
3
4
5
6
7
8
9
10
11
12
# 复现bug
使用原生态的偏移分页的话,正序取的时候还好,倒序取的话,会出现BUG.
什么BUG呢?
queryset = models.Book.objects.all().order_by("-id")
现在,一共从表中倒序取了10条数据,放到了一个容器中 就像这样 [ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
默认每次取3条数据.
进行以下步骤:
step1: 访问/api/2/book/ - 依次取到了ID为10、9、8的记录
step2: 往表中新增一条记录
step3: 访问/api/2/book/?limit=3&offset=3
注意:
表中此时有11条数据,倒序取出. 容器变成了这样 [ID11,ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
(每次访问都会重新执行视图函数!)
offset=3 表明是从容器的第3个位置开始.limit=3,取3条数据, 即 依次取到ID为8、7、6的记录.
神奇吧,ID为8的记录重复出现了!!
2
3
4
5
6
7
8
9
10
11
12
13
14
step1:

step2: models.Book.objects.create(name="11_11",price=11)
step3:
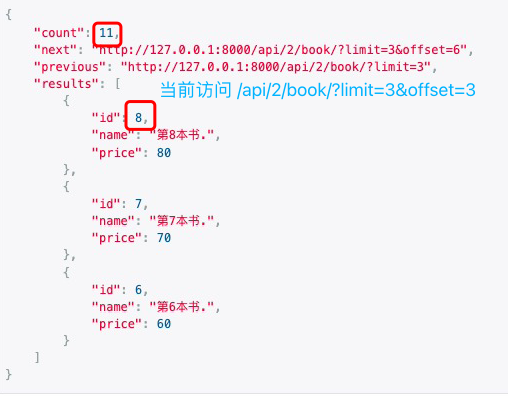
# 生活常用
在原生态的偏移分页上, 添加一个参数 lastid !! 即 最后取到的那个位置/最后取到的那条记录的ID!!
怎么个逻辑呢?
表中一共有11条记录,倒序取出. 放到某个容器中,就像这样 [ID11,ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
默认每页展示3条数据
前端访问接口 /api/2/book/?limit=3&offset=0 -- 等同于 /api/2/book/
"后端返回前端 ID为11、10、9的记录"
前端得到数据后,记录得到的最后一条记录的ID值存储起来.即 9. 该值会在下一次访问时作为URL的lastid参数的值.
接着,
前端访问接口 /api/2/book/?limit=3&offset=0&lastid=8 -- 等同于 /api/2/book/?lastid=9
若该访问之前新增了一条数据,因为再次访问了该API,会重新执行视图函数.虽然表中多了一条ID12.
[ID12,ID11,ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
但后端会先筛选,先将表中ID小于9的那些记录找到. 容器变成了这样,[ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1]
调用offset=0,limit=3 "后端返回前端 ID为8、7、6的记录"
前端得到数据后,记录得到的最后一条记录的ID值存储起来.即 6. 该值会在下一次访问时作为URL的lastid参数的值.
接着..
以此类推. ★分页是以容器里的记录进行的分页!!
看实验过程,中途增加了数据也没关系啊,前端已经把得到的最后一条记录的ID保存下来了.新增数据的ID肯定是大于该ID的.
那又出现了新的问题.最新的数据获取不到啊?!
场景: 生活中有这样的场景,你往下滑,不停的进行偏移分页,然后在页面的顶端提示你 有1条新数据,点击查看. -- “抽屉新热榜”网站就是这样的
解决思路: 这就需要,在一开始,得记录下最先展示的那条数据的ID,该示例中是 ID11.
往下滑的过程,不停偏移分页. 中途表中新增了ID12的记录.
点击想查看最新的,这时只需筛选出 容器中 大于11的ID的数据集成到页面最上方展示.
So.针对偏移分页,前端要记录两个ID.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
具体实现
from rest_framework import serializers
from rest_framework.pagination import LimitOffsetPagination
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
class BookView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Book.objects.all().order_by("-id")
last_id = request.query_params.get("last_id")
if last_id:
queryset = queryset.filter(id__lt=last_id)
pager = LimitOffsetPagination()
p_list = pager.paginate_queryset(queryset, request, self)
ser = BookSerializer(instance=p_list, many=True)
# return pager.get_paginated_response(ser.data) # - 感觉滚动翻页没必要上一页下一页
return Response(ser.data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
实验结果
==> limit=3&offset=0默认的 <==
http://127.0.0.1:8000/api/2/book/
倒序取所有数据,一共11条放到容器中 [ID11,ID10,ID9,ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1] -- ID11,ID10,ID9
http://127.0.0.1:8000/api/2/book/?last_id=9
倒序取所有数据,一共11条,筛选出id小于9的,放到容器中 [ID8,ID7,ID6,ID5,ID4,ID3,ID2,ID1] -- ID8,ID7,ID6
△ △ △
http://127.0.0.1:8000/api/2/book/?last_id=6
倒序取所有数据,一共11条,筛选出id小于6的,放到容器中 [ID5,ID4,ID3,ID2,ID1] -- ID5,ID4,ID3
http://127.0.0.1:8000/api/2/book/?last_id=3
倒序取所有数据,一共11条,筛选出id小于3的,放到容器中 [ID2,ID1] -- ID2,ID1
2
3
4
5
6
7
8
9
10
11
12
13
14