 分页和搜索
分页和搜索
# 创建模拟数据
用离线脚本创建多条客户数据
import os
import sys
import django
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'order.settings')
django.setup()
if __name__ == '__main__':
from web import models
from utils.encrypt import md5
for i in range(1, 302):
models.Customer.objects.create(
username=f'dc_{i}',
password=md5("dc1234"),
mobile='18954787888',
level_id=1,
creator_id=1
)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 分页(初始版)

1.一开始,在展示客户列表数据时,返回的是所有的客户数据.300多条数据一起展示在页面上,是不合理的,需要分页.
构造类似于 http://127.0.0.1:8000/customer/list/?page=2 的url.
后端通过request.GET.get("page")得知,需查询第2页的数据,可以计算出开始和结束的位置,将查询的所有数据进行分片.
★ queryset对象是可以分片的!! 访问第一页: 0-10; 第二页:10-20; 第三页: 20-30; (默认每页数据是10条)
So, start=(page-1)*10 end=page*10
2.运用bootstrap中的分页组件.
1
2
3
4
5
6
2
3
4
5
6
关键代码如下:
web/views/customer.py
def customer_list(request):
""" 获取客户数据 分页 """
page = request.GET.get("page") # 当前页
page = int(page)
per_page_count = 10 # 每页显示的个数
start = (page - 1) * per_page_count # 分片开始位置
end = page * per_page_count # 分片结束位置
queryset = models.Customer.objects.filter(active=1).select_related('level', 'creator') # 所有客户数据
total_count = queryset.count() # 总数据条数
total_page, mod = divmod(total_count, per_page_count) # 计算出总共有多少页
if mod:
total_page += 1
# 总页码小于11,直接全部显示
if total_page <= 11:
start_page = 1
end_page = total_page
else:
# 总页码比较多
if page <= 6: # 若当前页<=6 "左极值", 显示1~11
start_page = 1
end_page = 11
else:
if (page + 5) > total_page: # "右极值"
start_page = total_page - 10
end_page = total_page
else: # 中间
start_page = page - 5
end_page = page + 5
# 前端页面页码的生成逻辑
page_list = []
for i in range(start_page, end_page + 1):
if i == page:
item = f"<li class='active'><a href='?page={i}'>{i}</a></li>"
else:
item = f"<li><a href='?page={i}'>{i}</a></li>"
page_list.append(item)
pager_string = "".join(page_list)
context = {
"queryset": queryset[start:end],
"pager_string": mark_safe(pager_string),
}
return render(request, 'customer_list.html', context)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
web/templates/customer_list.html
<nav aria-label="Page navigation">
<ul class="pagination">
{{ pager_string }}
</ul>
</nav>
1
2
3
4
5
2
3
4
5
# 分页(封装版)
将分页的代码进行封装, 并进行一系列的优化!!
# QueryDict类型
用于后面分页组件 对原搜索条件的 保留!!
http://127.0.0.1:8000/customer/list/?filter=wupeiqi&age=19
request.GET对象 是 QueryDict类型 的数据!!
1.默认QueryDict不允许被修改 _mutable=False
设置request.GET._mutable = True后,就可以被修改啦!
2.设置值
print(request.GET) # <QueryDict: {'filter': ['wupeiqi'], 'age': ['19']}>
request.GET.setlist("name",[123])
print(request) # <QueryDict: {'filter': ['wupeiqi'], 'age': ['19'], 'name': ['123']}>
request.GET.setlist("name",[123,321])
print(request) # <QueryDict: {'filter': ['wupeiqi'], 'age': ['19'], 'name': ['123','321']}>
3.调用urlencode方法,可以拼接
import copy
query_dict = copy.deepcopy(request.GET) # 避免污染原本的request.GET!!
query_dict._mutable = True
query_dict.setlist("name",[123])
paramString = query_dict.urlencode()
print(paramString) # "filter=wupeiqi&age=19&name=123"
query_dict.setlist("name",[123,321])
paramString = query_dict.urlencode()
print(paramString) # "filter=wupeiqi&age=19&name=123&name=321"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 分页组件
可以不影响url已携带的参数,并在url中加上分页的参数!!!

"""
分页组件的使用,需要以下两个步骤:
-- 视图函数:
def customer_list(request):
queryset = models.Customer.objects.filter(active=1).select_related('level') # 查询所有数据
obj = Pagination(request, queryset) # 使用分页组件对查询出的所有数据进行分页
context = {
"queryset": obj.current_page_queryset,
"pager_string": obj.html,
}
return render(request, 'customer_list.html', context)
# ★ V2版本,在视图函数中传入pager对象,在模版中调用 pager.current_page_queryset 以及pager.html
# pager = Pagination(request, queryset)
# return render(request, 'customer_list.html', {"pager": pager})
-- 前端页面:
{% for row in queryset %} <!-- {% for row in pager.current_page_queryset %} -->
{{row.id}}
{{row.username}}
{% endfor %}
<nav aria-label="Page navigation">
<ul class="pagination">
{{ pager_string }} <!-- {{ pager.html }} -->
</ul>
</nav>
"""
import copy
from django.utils.safestring import mark_safe
class Pagination(object):
""" 分页 """
def __init__(self, request, query_set, per_page_count=10, pager_count=8):
self.query_dict = copy.deepcopy(request.GET)
self.query_dict._mutable = True
self.query_set = query_set # 要进行分页的所有数据(是一个queryset对象)
self.per_page_count = per_page_count # 每页显示的条数
self.pager_count = pager_count # 分页栏中最多显示的页码个数
self.total_count = query_set.count() # 一共多少条数据
self.pager_count_half = pager_count // 2 # 当前页向前向后展示的页码个数
self.total_page, div = divmod(self.total_count, per_page_count)
if div:
self.total_page += 1 # 计算出总共有多少页/最大的页码数 使用内置函数divmod
self.page = self.check_page(request) # 当前页
self.start = (self.page - 1) * per_page_count # 切片的开始位置
self.end = self.page * per_page_count # 切片的结束位置
def check_page(self, request):
"""对url中携带的page参数进行判断!!"""
page = request.GET.get('page')
if not page:
page = 1
else:
if not page.isdecimal():
page = 1
else:
page = int(page)
if page <= 0:
page = 1
else:
if page > self.total_page:
page = self.total_page
return page
def page_nav(self):
"""分页栏中的开始页码和结束页码"""
# 总页码小于11 (分页栏最多显示的页码个数默认是11)
if self.total_page <= self.pager_count:
start_page = 1
end_page = self.total_page
# 总页码大于11
else:
# 当前页如果<=11//2 "左极值 避免开始页码<=0"
if self.page <= self.pager_count_half:
start_page = 1
end_page = self.pager_count
else:
# 当前页如果>11//2 "右极值 避免结束页码>总页码"
if (self.page + self.pager_count_half) > self.total_page:
start_page = self.total_page - self.pager_count + 1
end_page = self.total_page
else:
start_page = self.page - self.pager_count_half
end_page = self.page + self.pager_count_half
return start_page, end_page
@property
def html(self):
"""前端分页栏代码(前端使用的是Bootstrap!)"""
pager_list = []
# 无数据,分页栏不展示
if not self.total_page:
return ""
# start_page、end_page 分页栏开始和结束页码
start_page, end_page = self.page_nav()
# 分页栏首页html
self.query_dict.setlist('page', [1])
pager_list.append('<li><a href="?{}">首页</a></li>'.format(self.query_dict.urlencode()))
# 分页栏上一页html
if self.page == 1:
pager_list.append('<li class="disabled"><a href="#">上一页</a></li>')
if self.page > 1:
self.query_dict.setlist('page', [self.page - 1])
pager_list.append('<li><a href="?{}">上一页</a></li>'.format(self.query_dict.urlencode()))
# 分页栏中间页html
for i in range(start_page, end_page + 1):
self.query_dict.setlist('page', [i])
if i == self.page:
item = '<li class="active"><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)
else:
item = '<li><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)
pager_list.append(item)
# 分页栏下一页html
if self.page == self.total_page:
pager_list.append('<li class="disabled"><a href="#">下一页</a></li>')
if self.page < self.total_page:
self.query_dict.setlist('page', [self.page + 1])
pager_list.append('<li><a href="?{}">下一页</a></li>'.format(self.query_dict.urlencode()))
# 分页栏尾页html
self.query_dict.setlist('page', [self.total_page])
pager_list.append('<li><a href="?{}">尾页</a></li>'.format(self.query_dict.urlencode()))
# 分页栏汇总
pager_list.append('<li class="disabled"><a>共{}页/{}条</a></li>'.format(
self.total_page,
self.total_count)
)
pager_string = mark_safe("".join(pager_list))
return pager_string
@property
def current_page_queryset(self):
"""当前页的数据"""
if self.total_count:
return self.query_set[self.start:self.end]
return self.query_set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
# 搜索
点击搜索按钮, 以get的请求方式将搜索的关键字提交到当前的url中.
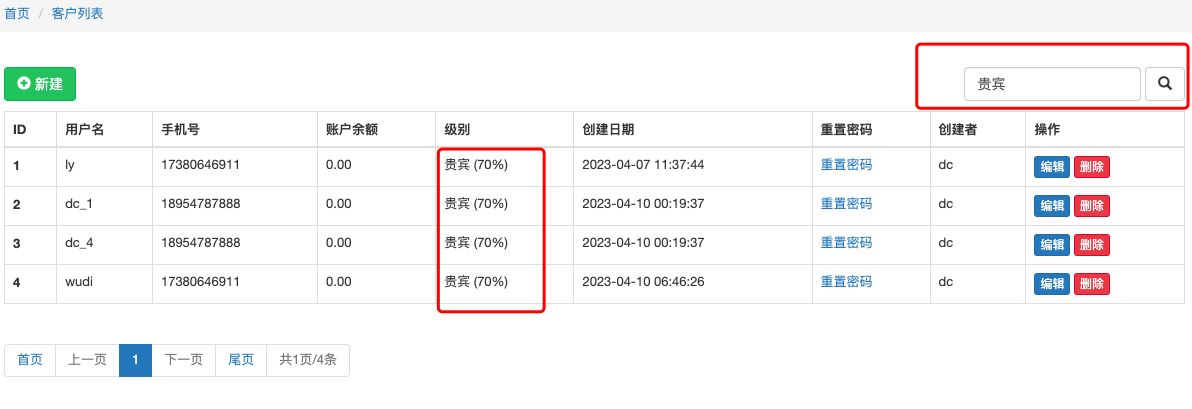
前端关键代码
<div style="margin-bottom: 10px" class="clearfix"> <!-- 注意:class="clearfix" -->
<a class="btn btn-success" href="{% url 'customer_add' %}">
<span class="glyphicon glyphicon-plus-sign"></span>
新建
</a>
<form class="navbar-form navbar-right" role="search" method="get">
<div class="form-group">
<input name="keyword" type="text" class="form-control" placeholder="请输入关键字" value="{{ keyword }}">
</div>
<button type="submit" class="btn btn-default">
<span class="glyphicon glyphicon-search"></span>
</button>
</form>
</div>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
后端关键代码
def customer_list(request):
""" 获取客户数据 分页、搜索 """
keyword = request.GET.get("keyword", "").strip()
con = Q()
if keyword:
# 名字 or 手机号 or 级别的标题中有关键字
con.connector = 'OR'
con.children.append(('username__contains', keyword))
con.children.append(('mobile__contains', keyword))
con.children.append(('level__title__contains', keyword))
queryset = models.Customer.objects.filter(con).filter(active=1).select_related('level', 'creator')
obj = Pagination(request, queryset)
context = {
"queryset": obj.current_page_queryset,
"pager_string": obj.html,
"keyword": keyword,
}
return render(request, 'customer_list.html', context)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
思考问题:
1> 编辑回来携带条件: 分页后, 加入点击第19页, 修改了某一条数据, 修改后返回的页面, 自动展示的是第一页的数据.. 不合理.
2> 权限控制按钮是否出现: 将权限的粒度控制在显示页面的按钮上.