小项目之手撸ORM
小项目之手撸ORM
# 知识储备
# 拦截点号运算
__setattr__():
在对类实例化对象的属性进行 赋值/修改 实例.属性=值 时,首先会调用该方法
并在该方法中将属性名和属性值添加到实例的 __dict__ 属性中
__getattr__():
实例引用属性 实例.属性 时,按照正常的规则进行属性查找, 没找到时的兜底函数.
Ps: 类的属性引用和赋值稍微实验了下,有些许不同,不想深究啦,遇到了再说.
目前,可以确定一点,类在调用自身属性的时候, 是不会触发__getattribute__方法
class Foo:
a = 0
def __setattr__(self, key, value):
self.__dict__[key] = value
def __getattr__(self, key):
raise AttributeError("'%s' object has no attribute '%s'" \
% (self.__class__.__name__, key))
f = Foo()
f.name = 'dc' # -- 赋值操作直接调用__setattr__
setattr(f, 'age', 18) # -- 同上
print(f.a, f.age, f.name) # 0 18 dc
print(getattr(f, "a", None)) # 0
print(getattr(f, "xxx", None)) # None -- xxx在f中没有,在Foo中也没有,调用__getattr__
# 只不过,调用__getattr__得到error后,会自动处理返回None
print(f.xxx) # -- 同上 按照属性查找顺序没找到,会调用__getattr__,报错
print(f.__dict__) # {'name': 'dc', 'age': 18}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 元类的复习
metaclass元类对类的操作一般都会在元类new方法里实现
注意理解这一句话:
在__init__的时候, 类已经被创建了, 在元类的__init__方法中对类的命名空间的修改操作并不会生效.
# -- type的伪代码!
class type:
def __call__(self, *args, **kwargs):
obj = self.__new__(self, *args, **kwargs)
self.__init__(obj, *args, **kwargs)
return obj
2
3
4
5
6
需求: 在自定义元类Mymeta中把自定义类People的数据属性都变成大写
解决方案: 在 __new__中对未实例化的类进行修改
class Mymeta(type):
def __new__(mcs, name, bases, attrs):
update_dic = {}
for k, v in attrs.items():
# -- 数据属性不可被调用且不以双下划线开头
if not callable(v) and not k.startswith('__'):
update_dic[k.upper()] = v
else:
update_dic[k] = v
return super().__new__(mcs, name, bases, update_dic)
def __init__(cls, name, bases, attrs):
# -- 可以看到在__new__中创建对象时,修改了attrs,但__init__收到的是修改前的.
# 这可以使用type的伪代码来解释!
# {'__module__': '__main__', '__qualname__': 'People', 'country': 'china'}
print(attrs)
super().__init__(name, bases, attrs)
class People(object, metaclass=Mymeta):
country = "china"
if __name__ == '__main__':
p = People()
print(p.__dict__) # {}
print(hasattr(People, 'country')) # False
print(hasattr(People, 'COUNTRY')) # True
print(getattr(p, "COUNTRY", None)) # china
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
一点小想法:
曲线救国, 在 __init__ 中, 给People类的命名空间添加大写的数据属性, 但小写的数据属性依然存在..
from copy import deepcopy
class Mymeta(type):
def __init__(cls, name, bases, attrs):
# -- 单个下划线是一个Python命名约定,表示这个名称是供内部使用的
_attrs = deepcopy(attrs)
# -- 用_attrs,是因为在循环体里会对attrs进行改变
for k, v in _attrs.items():
if not callable(v) and not k.startswith('__'):
"""
super(Mymeta, cls).__setattr__(k.upper(), v) -- 可以得到正确结果,很神奇.
那么上面这个super().__setattr__()语句又等同于什么?想了想.不深究了.
错误的实践
attrs[k.upper()] = v # -- 不会在People的__dict__中生效
cls.__setattr__(k.upper(), v) # -- 报错
cls.__dict__[k.upper()] = v # -- 报错
但知道了 实例使用反射setattr会调用__setattr__,但类使用反射setattr不会..
(在拦截点号运算中打断点实践出来的!)
累了,记住一点就好,对类的操作在元类的__new__中实现!(つД`)ノ 我直接反手一个躺平.
"""
setattr(cls, k.upper(), v) # -- 用反射就会生效 给People类添加属性
# -- 即type里的__init__不会对attrs有任何的操作!!
super().__init__(name, bases, attrs)
class People(object, metaclass=Mymeta):
country = "china"
if __name__ == '__main__':
p = People()
print(p.__dict__) # {}
print(hasattr(People, 'country')) # True
print(hasattr(People, 'COUNTRY')) # True
print(getattr(p, "COUNTRY", None)) # china
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# ORM对象关系映射
参考链接: https://www.cnblogs.com/liuqingzheng/articles/9006025.html
需求:
数据库中的user表对应程序当中的User类.
user表中有条数据, id:1 name:lqz password:123
希望可以实现个select方法,通过User.select(id=1)拿到这条数据..
因为User的一个实例应该对应user表中的一条数据, 所以返回的结果应当是User的一个实例.
也希望实例obj能通过 obj.name 、obj.password 拿到对应的字段值!
当然,希望通过User类实现对user表的查询、增加、修改.. ╮(╯▽╰)╭
这样一来, 就不用写sql来操作啦!!大体的初步思考:
1> 数据表中的每种字段类型都包含众多属性, 每种字段类型都映射一个字段类;
2> 数据表映射一个表类,该类会用类的数据属性表示这些字段类的实例,来映射数据表中的字段/每一列.
并且该表类的实例映射表中的一条数据;
简易的ORM框架,要实现的大体效果如下:
class User(ORM):
# -- 定义数据表的字段
name = CharField()
age = IntField()
if __name__ == '__main__':
# -- 根据条件查询到用户表中的某条数据
user0 = User.select(id=1)
print(user0.name)
# -- 修改
user0.name = 'lqz_0'
user0.update()
# -- 插入数据
# user = User(name='dc',name='dc',password='321') 可以拆分为以下三行代码.
user = User()
user.name = "dc"
user.password = 321
user.insert() # -- 调用insert函数自动将数据插入到数据库中
ps:字典可以天然的存储数据.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
原理看似也不简单,很绕,具体实现过程更绕.. orz 需谨慎,步步为营!!反复推敲! 培养思维模式尤为重要!
# Field类
定义一个Field类表示数据表的 字段/列 具有哪些属性.
(name 列名/字段名、column_type字段类型、primary_key该字段是否是主健、default字段的默认值)
并衍生出两个子类 StringField和IntegerField.
2
3
# Models类
定义了一个Models类
1> 继承了dict类.使得Model类具备字典的特性. 字典可以天然的存储数据.
再仔细想一想,一般类实例化有参数时,都会通过类中的__init__给实例增添独有的数据属性.
但这里通过Models(k1=v1,k2=v2)实例化得到对象obj,并不会有独有属性k1、k2
Models实例化的对象obj本质就是一个字典! 打印obj. 结果为{k1:v1,k2:v2}
但它也具备实例的特性,可以进行属性引用!(尽管obj.__dict__为空)
Ps: Models类里的__init__方法写不写都不影响,按照查找规则
继承Models的User类的实例都会去调用dict里的__init__完成初始化.
2> 字典是不能通过`.`取到value的!! 但这里的实例具备字典的特性,可以通过'.'进行属性引用..
`实例.属性`的操作属性查找失败(在实例和类的命名空间中都没有该属性),会自动访问类中的__getattr__方法!
在Models类中重写了__getattr__,"self[key]"会去看看字典实例本身有没有这个键!
使得Models的实例可以通过obj.k的形式取到obj字典对象本身对应的v try..except..
再次说明,字典实例的命名空间为空!
3> `实例.属性=值`的操作 会自动访问类中的__setattr__
在Models类中重写了__setattr__,"self[key] = value"
使得Models的实例可以通过 obj.k = v 的方式给字典对象自身添加键值对.
再次强调,继承了dict,重写了两个方法 ╮( ̄▽ ̄"")╭
会使得 "无论怎么对obj增删改查(两种方式 .、[]),obj.__dict__都为空!!操作的都是字典对象obj本身!"
4> Model类使用元类ModelsMetaclass,这样就可以拦截Model类以及继承Model类的子类的创建过程!!
简单来说:
Models继承dict字典类,重写__setattr__和__getattr__,是为什么?
★ 先要明白 类实例化对象obj[k]报错;字典my_dict.k报错
-- 前者是为了Model的子类User在实例化后,具备字典的特性,能像字典一样obj[k]=v往字典里添加k-v
也可以在User实例化时传递一堆 k=v 完成实例化.
-- 后者是为了能通过obj.k=v 往字典里添加修改k-v; 当然也可以通过obj.k成功取值.
注意: 实例 obj.__dict__ 是空的!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# User类
创建一个User类继承Models类 -- 便于实验
该类定义了4个类属性
1> table_name表名 >> 字符串类型
2> id编号、name姓名、password密码 >> 都是Field字段类型,每个字段都包含多个属性(name、column_type等)
User类 -- 用户表
User类里类属性table_name -- 表名
User类里类属性id、name、password -- 用户表每一列的名字,也就是字段名
User类实例化得到的实例对象 -- 用户表里的一条/一行数据
(需要User类实例化的时候,可以传任意 k=v 的数据!这也就是为啥Models类要继承dict类!)
★ +++
<当时我特别疑惑,怎么就将User的实例obj变成用户表中的数据啦???怎么想都想不通.>
"破解的关键在于User类的实例obj,本质是一个字典",我们可以取到字典本身里的键值对构建sql语句,
通过第三方库pymysql实现对用户表数据的操作.
当然我们也可以反过来通过pymysql将查到的数据,构建User的实例! "一条数据 对应 一个实例"
简单来说,若pymysql的查询结果是[{id:1,name:'dc'},{id:2,name:'lqz'}]
对结果for循环,对循环得到的每一项拆包, [User(**item) for item in res]
列表中的两个元素是两个User类的实例 -- User(id=1,name='dc')、User(id=2,name='lqz')
即'★ 将一条条的数据转化成User类的实例对象!!''
==> 注意: 对实例的打印结果是{id:1,name:'dc'},{id:2,name:'lqz'} 看起来是字典,但不仅仅是字典!
思考?若User类的父类Models不继承dict能否实现这些功能?有何区别?暂且放下.做完整个项目后再思考!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
不同的实现:
https://seanlee97.github.io/2018/08/23/谈谈python中的元类以及实现一个简单的ORM框架/
(这个里面就没有用字典!! 它的解决方案是在Models类的__init__里使用了setattr完成了初始化)
# ModelsMetaclass元类
自定义一个ModelsMetaclass元类
需求: 数据库中的每个表,都有表名、每一列的列名、以及主键是哪一列
我们需要将数据库中的一张表与一个类相对应,类的命名空间中应该有属性来映射数据表中的这些属性
分析: 使用元类的类在创建完成后,类的命名空间里必须有table_name、primary_key、mappings属性!
table_name -- 表名
primary_key -- 主键名
mappings -- 表中的每一列/表中所有的字段 即一堆Field对象
"相当于将一张数据表的关键信息整理好!"
Ps:整理完毕后,类定义过程中执行类代码得到的放在类命名空间里的那些内容就可以丢弃啦.
解决: 需要重写元类里的__new__方法.
简单来说:
Q:设置Models的元类是ModelsMetaclass,是为什么?
A:是为了Model的子类User在创建时,被拦截.
整理好数据,将table_name、primary_key和一堆Field对象 放到User类的__dict__中
User可以通过.的方式可以对__dict__中的属性进行引用!!
具体实现过程:
1> 数据库表的父类Models不需要拦截,走正常的流程 `if name == "Models":`
2> -- 拿到表名
attrs是一个字典,里面存放的是类定义执行类代码的过程中产生的键值对
table_name = attrs.get('table_name') # -- 字典的获取值的方法,获取不到默认返回None
若attrs中没有键"table_name",用类名当作表名
3> -- 将数据表的每个字段放到mappings字典中 以及 拿到primary_key主键名/设置了主键的字段的名字
mappings字典中的k是User类中设置的字段名,v是该字段名对应的Field字段实例对象
{'id':<__main__.IntegerField object at 0x7..>,'name':<__main__.StringField ...>...}
attrs中还有__doc__、__module__..这些东西.不是我们需要的!
So,要对attrs中的k-v进行判断,v是Field类型的放进去,即把attrs中与数据库表字段有关的列提取出来.
若v是Field类型,还可以根据v的primary_key属性判断该字段是否是主键!
注意,健壮性的判断,只能有一个主键!一开始primary_key设置的初始值是None.
4> -- 一点优化
mappings字典会存入User.__dict__中的,So,放入mappings的属性,User.__dict__中没必要再存一份.
想一想,不pop掉的话
new_user = User(name='egon', password='666')
getattr(user, name, None) 拿到的就是类的命名空间里name对应的Field对象啦,不是name的值!
若User类/表中没有主键,抛异常
5> -- 将table_name、 primary_key、mappings放入User.__dict__中!! 并完成User类的创建.
"提醒一点,User的命名空间里的东西,User类的实例是共享的!!" 为了后面的查询更新和插入功能的实现!
"这样一折腾,只要类被该元类一拦截,这些被拦截的类的命名空间里都有一样的key值!!"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# Mysql类
通过第三方pymysql模块,实现了Mysql类,为创建的sql链接提供了查询、更新的接口!
ms = Mysql()
查询接口 -- ms.select()
更新、保存接口 -- ms.execute()
注意几点:
1> 查询的结果集是列表嵌套字典的格式 [{k:v,k:v},{k:v}]
2> autocommit=True
3> 用类方法实现单例模式,避免每次查询都会Mysql()创建一个新的链接
查询、更新、插入的操作都用的同一个数据库链接!!
4> '★★★' 特别注意!! 用`cursor.execute(sql, [])`对sql自动进行拼接并执行,可以防止sql注入.
'但只会拼接字段值!!不会对表名和字段名进行拼接!!'
import pymysql
class Mysql:
__instance = None
def __init__(self):
self.conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
charset="utf8",
database="youku",
autocommit=True # -- 自动提交
)
self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
# -- 关闭
def close_db(self):
self.cursor.close()
self.conn.close()
# -- 查询
def select(self, sql, args=None):
pass
# -- 更新、保存 update、insert
def execute(self, sql, args):
pass
# -- 使用类方法实现单例模式
@classmethod
def singleton(cls):
if not cls.__instance:
cls.__instance = cls()
return cls.__instance
if __name__ == '__main__':
ms = Mysql()
res = ms.select("select * from user where id=%s", [1])
print(res)
ms.close_db()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 完善Model类
# -- 每个数据表都应该具备查询、插入、保存等方法!!
1> def select_res(cls, **kwargs): -- 静态方法<这里手动传了一个类对象进去 调用查询接口取到数据
2> def select_one(cls, **kwargs): -- 类方法 只会得到一条数据
该方法里面会调用静态方法select_res
拿到结果后,会将该条数据转化成User类的实例对象!!
3> def select_many(cls, **kwargs): -- 类方法 得到一条或者多条数据
同理,该方法也会调用静态方法select_res
'★ 拿到结果后,会将一条条的数据转化成User类的实例对象!!'
注意!该方法里有个判断,当kwargs为空时,会重新拼接一个sql语句,查询该表中的所有数据!
体会下,细品 `[cls(**r) for r in res]`
4> def update(self): -- 实例方法/对象的绑定方法 对数据进行更新 该方法是真的绕!!-_-
我们默认用主键进行更新!!
★ 注意:有了真正的实例/拿到一条数据才能真正的进行更新,应具体到某个实例对象,所以该方法不能是类方法!
思考分析,首先我们要拼接一个sql `update user set name='lqz',password=123 where id=1`
拆分开来,我们要拿到
>> 表名user
>> name='lqz',password=123
name、password这些数据库字段在User类的命名空间的mappings里放着呢!!
命名空间里的键mappings对应的值是一个字典. 该字典的键是字段名,值是Field对象.
User类的命名空间 User.__dict__ 是能被User的实例访问到的!!!
fields列表里放除了主键的所有字段,字段经过了处理 `字段 + '=?'`
>> 主键字段id以及该字段的值
注意这句代码! pr = getattr(self, k, None) -- 将主键的值给了pr变量
User实例和User类的命名空间中都没有名为id的键
'★★★'就会去调用Models里重写的__getattr__方法!! 通过 self[k] 拿到该条数据字段id对应的值!
都得到后,拼接成一个sql!!
ms.execute(sql, args) 需要args!
'★★★' `args.append(getattr(self, k, None))`其实就是取self这个字典本身除了主键外其它字段的值!!
update该方法怎么用?
user = User.select_one(id=3)
user.name = 'dc0'
user.update()
5> def insert(self): -- 实例方法/对象的绑定方法 插入新数据
注意一点,构建sql语句,sql语句中有多少个字段,sql语句的valuse后面就要跟多少个值.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# ORM框架思路总结
用户表 -- User类
用户表的一行数据 -- User类的一个实例obj
User类中的类属性, `字段名 = Field字段对象`
User类的基类Models继承dict,User的实例obj就是一个字典,User类实例化的过程里就会往字典里传值..
虽然obj是一个实例,但通过obj.attr是拿不到值的,因为obj以及User的__dict__中没有..
So,重写__getattr__和__setattr__方法!!
让obj.attr从obj这个字典本身里取值,以及obj.attr=value,往obj字典里添加值!!
Models不仅继承dict,还会使用自定义的元类ModelMetaclass..
使得User类在创建过程,就将数据组织好放到User类的__dict__中,并将那些重复的数据删除
(删除是为了保证使用反射时拿到的是字典本身的数据)!
组织的数据包含table_name、primary_key和一堆Field对象 -- 主要就是在操作元类的参数attrs
查询通过User类来查询,是类方法
更新的user类的实例,添加的也是user类的实例!!
查询、更新、添加 大体思路就是 构建sql语句,创建mysql链接,调用相应的接口!
有个需要特别注意的地方:
对User的实例obj使用反射 getattr 会调用__getattr__最终拿到的是obj这个字典本身的内容.
数据库接口的实现就是使用第三方模块pymysql构建的,返回结果是列表字典、用单例使得查询更新添加用的同一个链接!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 数据库连接池
程序操作数据库需要建立链接,来一个查询建立一个链接、来一个更新建立一个链接..
不一会,数据库的连接数就满了!所以我们使用了单例,使得该程序对数据库的查询更新添加等操作用的是同一个链接!
"数据库连接单例是指在项目运行期间,始终只有一个数据库链接!即这个链接在该项目程序中是复用的!"
但如果有1000个客户端并发过来,要建立1000个链接?依旧使用单例模式的数据库?
Ps:一点小思考
该场景下,若使用单例数据库,有点协程的味道! -- 该链接在多个客户端之间来回切,切换+保存状态
具体如何实现,不晓得 但一般情况下,协程的链接数没记错的话最好不超过500个.
解决方案:
建立数据库连接池控制网站最多连接数据库的数量,够了后来者就排队;
创建连接后不用此连接了但不断开暂时存起来,以便连接的重用!
2
3
4
5
6
7
8
9
10
11
12
dbutils是python的一个用于实现数据库连接池的模块!
dbutils提供了两种外部接口:
PersistentDB -- 提供线程专用的数据库连接,并自动管理连接;
PooledDB -- 提供线程间可共享的数据库连接,并自动管理连接. (我们一般使用这种模式!)
import pymysql
from dbutils.pooled_db import PooledDB
POOL = PooledDB(
creator=pymysql,
maxconnections=10,
mincached=3,
maxcached=5,
maxshared=3,
blocking=True,
maxusage=None,
setsession=[],
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='youku',
charset='utf8'
)
if __name__ == '__main__':
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute('select * from user')
result = cursor.fetchall()
print(result)
cursor.close()
conn.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 功能测试
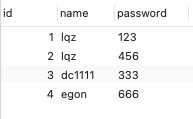
user用户表设计

user用户表数据
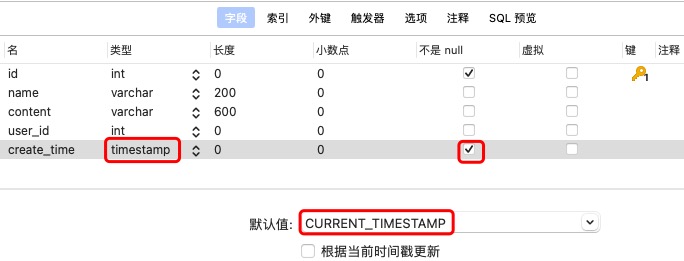
class Notic(Models):
table_name = "notice"
id = IntegerField('id',primary_key=True)
name = StringField('name')
content = StringField('content')
user_id = IntegerField('user_id')
# -- create_time 它会自动填充上, 这里省事就不写啦!
2
3
4
5
6
7
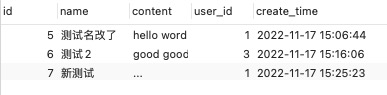
notice公告表设计
公告表数据