 ModelSerializer
ModelSerializer
!!本篇将阐述序列化类ModelSerializer的使用!!
Book表和Publish表中都有name字段,现有一个自定义的序列化类BookSerializer,里面指定了需要序列化的字段name.
我既可以用BookSerializer序列化Book表,也可以用它来序列化Publish表!!
So,我想说的是 序列化类Serializer跟models里的表模型没有必然的联系!
下面我们要学习的序列化类ModelSerializer是跟表模型有对应关系的!! o(^▽^)o .
# ModelSerializer*****
序列化类ModelSerializer, 项目中基本上用的都是它! ModelSerializer继承Serializer.
# 准备工作
路由配置
from django.urls import path
from django.contrib import admin
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BookView.as_view()), # -- 获取所有图书
path('books/<int:pk>', views.BookDetailView.as_view()), # -- 获取单个图书
path('publish/', views.PublishView.as_view()), # -- 获取所有出版社
path('publish/<int:pk>', views.PublishDetailView.as_view()), # -- 获取单个出版社
]
2
3
4
5
6
7
8
9
10
11
为出版社的Publish表写5个接口(与书Book表的五个接口相比,没有什么区别,就改了改类名)
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book, Publish
from .serializer import BookSerializer, PublishModelSerializer
class BookView(APIView):pass
class BookDetailView(APIView):pass
class PublishView(APIView):
def get(self, request):
qs = Publish.objects.all()
ser = PublishModelSerializer(instance=qs, many=True)
return Response(ser.data)
def post(self, request):
ser = PublishModelSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功', 'data': ser.data})
else:
return Response({'code': 999, 'msg': ser.errors})
class PublishDetailView(APIView):
def get(self, request, *args, **kwargs):
book = Publish.objects.all().filter(pk=kwargs['pk']).first()
ser = PublishModelSerializer(instance=book)
return Response(ser.data)
def put(self, request, *args, **kwargs):
book = Publish.objects.all().filter(pk=kwargs['pk']).first()
ser = PublishModelSerializer(instance=book, data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '修改成功', 'data': ser.data})
else:
return Response({'code': 999, 'msg': ser.errors})
def delete(self, request, *args, **kwargs):
res = Publish.objects.filter(pk=kwargs['pk']).delete()
if res:
return Response({'code': 100, 'msg': '删除成功'})
else:
return Response({'code': 999, 'msg': '数据不存在'})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 需求实现
class PublishModelSerializer(serializers.ModelSerializer):
# -- 在内部类Meta中指定跟表的对应关系.
class Meta:
model = Publish # -- 跟哪个表有关系
# fields = '__all__' # -- 表中的所有字段都做序列化,★注意是不包括表模型里的方法的!
# ★ 这些字段的字段类是通过表模型映射过来的!!并且把表模型里那些属性像什么max_length=64,null=True也映射过来啦!!
# 也就意味着反序列化验证时,该字段不能超过64位,且可以为空.
# -- 指定字段或者方法做序列化/反序列化
fields = ['name', 'addr']
# -- 在该序列化类里不用再重写create和update方法!!!
# 因为使用Serializer类时,是不知道要存哪个表,但使用ModelSerializer时,有表的对应关系啦!
2
3
4
5
6
7
8
9
10
11
12
# 指定字段
指定某个字段序列化的格式!!
需求: 序列化时,在出版社的名字后加上 _vip
解决方案: 重写字段, 具体来说,就是指序列化时指定字段格式的三种方式!!我们掌握前两种即可.
注意, 在ModelSerializer中会优先使用重写的字段序列化
方式一: 使用SerializerMethodField
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
fields = ['name', 'addr']
name = serializers.SerializerMethodField()
def get_name(self, obj):
return obj.name + '_vip'
2
3
4
5
6
7
8
方式二: 在表模型中定义一个name_suffix的方法,并写入内部类的fields列表中.
注意思考下,使用该方式时,要结合这read_only使用!!
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
# fields = '__all__' # -- 表中的所有字段都做序列化,★注意是不包括表模型里的方法的!
# -- 指定字段或者方法做 序列化/反序列化
# ★ 这些字段的字段类是通过表模型映射过来的!!并且把表模型里那些属性像什么max_length=64,null=True也映射过来啦!!
# 也就意味着反序列化验证时,该字段不能超过64位,且可以为空.
# name_suffix方法的返回值会同时映射到'name_suffix'和'name'上面
# 返回值是什么,它俩序列化后的值就是什么
fields = ['name', 'addr', 'name_suffix']
# -- 方式二:
""" 表模型中的代码如下
class Publish(models.Model):
name = models.CharField(max_length=64)
addr = models.CharField(max_length=64)
def name_suffix(self):
return self.name + '_vip'
"""
# 我们发现序列化展示的结果,'name_suffix'和'name'都展示了,且值都是一样的!只需要一个即可.
# ▲ 需求:序列化时使用name_suffix,反序列化时使用mame
# 该行代码可以不写,因为默认表模型里方法在反序列化时不需要有对应的值!
# name_suffix = serializers.CharField(read_only=True)
name = serializers.CharField(write_only=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 添加字段限制
需求: 反序列化时,限制addr,最大长度为8,最小长度为3
解决方案: 1) 重写该字段 2) 借助extra_kwargs
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
# fields = '__all__'
fields = ['name', 'addr']
# -- 给字段映射的字段类添加一些属性/为字段类设置字段参数!
# 比如name字段映射的字段类是CharField
extra_kwargs = {
'addr': {'max_length': 8, 'min_length': 3},
# 'name': {'write_only': True}
}
# -- 方式一:重写addr
# name = serializers.CharField(max_length=8, min_length=3)
# -- 方式二:在内部类的extra_kwargs中为addr字段设置参数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 局部钩子
需求: 反序列化时,addr字段的值最大长度为8,最小长度为3且不能以'sb'开头!
解决方案: 局部钩子 -- 给某个字段再增加一些校验! 固定用法def validate_校验的字段():pass
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
# fields = '__all__'
fields = ['name', 'addr']
extra_kwargs = {
'addr': {'max_length': 8, 'min_length': 3},
}
# -- 参数item,此形参名随便起,对应前端传过来的addr的值
def validate_addr(self, item):
if item.startswith('sb'):
# -- 抛出异常,但需要清楚的知道APIview里捕获了全局异常并进行了处理!!!
raise ValidationError('不能以sb开头!')
else:
return item # -- ★★★一定要记得return item!!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 全局钩子
需求: 反序列化时,限制出版社的名字不能等于出版社的地址.
解决方案: 全局钩子!方法名就叫做validate.
注意一点:
局部钩子在全局钩子之前执行,若局部钩子validate_addr方法return 'lqz'
那么在全局钩子validate里attrs.get('addr')拿到的addr就是'lqz',就不是前端提交过来的值啦!!
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
# fields = '__all__'
fields = ['name', 'addr']
extra_kwargs = {}
def validate(self, attrs):
name = attrs.get('name')
addr = attrs.get('addr')
if name == addr:
raise ValidationError('不能以sb开头!')
else:
return attrs # -- ★★★一定要记得return attr!!!
2
3
4
5
6
7
8
9
10
11
12
13
14
# Meta中其它变量
exclude 、depth
class PublishModelSerializer(serializers.ModelSerializer):
# -- 在内部类Meta中指定跟表的对应关系.
class Meta:
model = Publish # -- 跟哪个表有关系
# fields = '__all__' # -- 表中的所有字段都做序列化,★注意是不包括表模型里的方法的!
# -- 指定字段或者方法做序列化/反序列化
# ★ 这些字段的字段类是通过表模型映射过来的!!并且把表模型里那些属性像什么max_length=64,null=True也映射过来啦!!
# 也就意味着反序列化验证时,该字段不能超过64位,且可以为空.
# name_suffix方法的返回值会同时映射到'name_suffix'和'name'上面
# 返回值是什么,它俩序列化后的值就是什么
fields = ['name', 'addr', 'name_suffix']
# -- 给字段映射的字段类添加一些属性/为字段类设置字段参数!
# 比如name字段映射的字段类是CharField
extra_kwargs = {
'addr': {'max_length': 8, 'min_length': 3},
# 'name': {'write_only': True}
# ps:简单介绍下,字段参数validators!使用指定的函数来校验字段.
# 将name字段抛到函数里,函数里校验不通过也会抛ValidationError
# ★ 跟局部钩子的区别在于,局部钩子只能用都在某个字段上,validators里的函数1、函数2可以用到多个字段上.
# 'name': {'validators': [函数1,函数2]}
}
# -- 内部类Meta中其它不重要的变量(用的很少)
# -- exclude 排除, exclude和fields只能有一个!
# 几乎不用!
# exclude = ['name'] # -- 排除name字段,其它字段都序列化
# -- depth 会自动将外键字段关联表的记录序列化出来.该记录中若还有外键,会继续序列化,数字代表几层.
# 不建议用,因为会将外键字段关联的表对应的记录的字段全部序列化展示出来!
# depth = 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
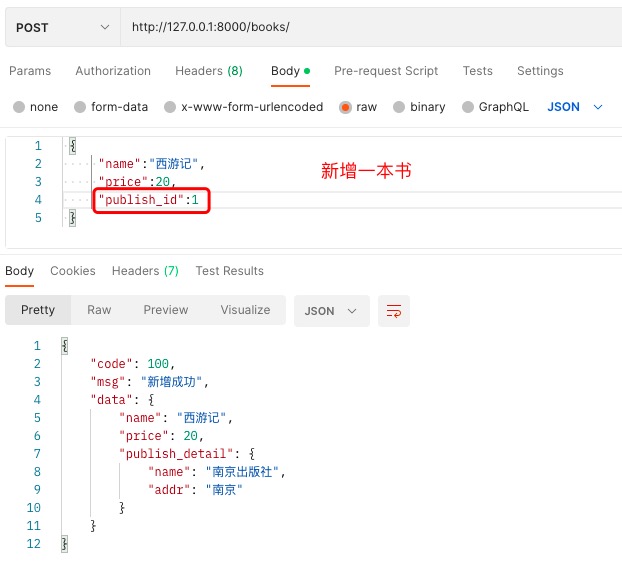
# 改写下Book
注意哦,Book模型表是写了该语句的
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
# 改写前
class BookSerializer(serializers.Serializer):
name = serializers.CharField(min_length=3, max_length=8)
price = serializers.IntegerField(min_value=3, max_value=30)
publish_detail = serializers.DictField(read_only=True)
publish_id = serializers.CharField(write_only=True)
def create(self, validated_data):
print(validated_data)
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
print(validated_data)
instance.name = validated_data.get('name', instance.name)
instance.price = validated_data.get('price', instance.price)
instance.publish_id = validated_data.get('publish_id', instance.publish_id)
instance.save()
return instance
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
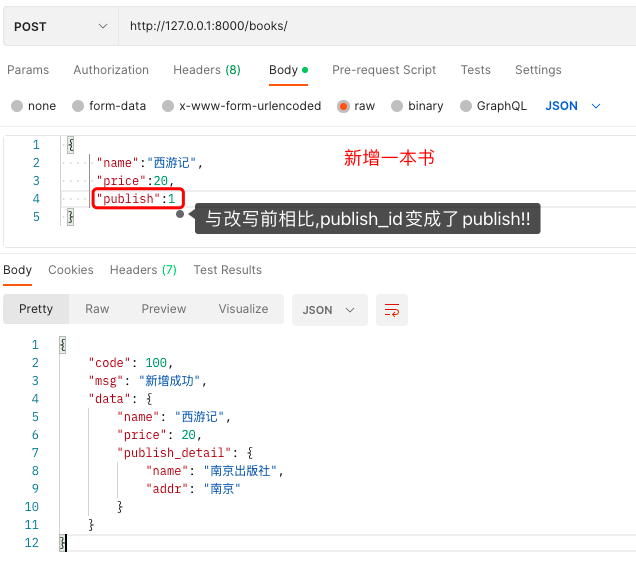
# 改写后
记得在views.py里将BookSerializer改为BookModelSerializer.
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = ['name', 'price', 'publish', 'publish_detail']
# -- 给字段映射的字段类添加一些属性/为字段类设置字段参数!
# 比如name字段映射的字段类是CharField
extra_kwargs = {
'addr': {'max_length': 8, 'min_length': 3},
'publish': {'write_only': True}
}
2
3
4
5
6
7
8
9
10
# 总结!!
-- 序列化类之Serializer
1) 跟表模型没有必然联系,必须重写create和update方法
2) 写出要序列化的字段
注意:Serializer类中序列化字段的类型尽量跟表模型当中字段的类型相对应
eg:
# -- Book表的price字段用的IntegerField类型
# -- 这里用CharField也是ok的,因为它可以从数据库中取到的数字用引号包起来弄成字符串.
# -- 但尽量还是用 serializers.IntegerField!!
price = serializers.CharField()
注意:若字段序列化后的值是字典或者列表,用CharField的话,前端接收到的是用引号包裹的字典或者列表.不是json.
这种情况常出现于 “指定字段” 的方式二里!! 解决方案,用DictField、ListField即可!
3) 字段类的source参数(用的很少)
这样的话,序列化的字段名就不需要等于表模型当中的字段名.会根据source参数的值映射过去!
eg: price_0 = serializers.CharField(source='price') # -- 注意,price_0改成price会报错.只有不为price就行!
-- 字段类
CharField
IntegerField
DateTimeField
DateField
-- 字段类参数
- 通用
read_only:
该字段只用于序列化,反序列化往里走的时候不需要该字段.(即便传了,也不会处理)
最直观的体现就是validated_data里没有!因为不识别该字段.
write_only:
该字段只用于反序列化,序列化往外走的时候不需要该字段.(即便传了,也不会处理)
PS:往里走指前端到后端,后端保存数据库;往外走指后端到前端!
Ps:使用这两个参数可以实现在一个序列化类里实现序列化和反序列化的操作!!
注意:一个字段类不能同时用这两个参数!既只读又只写?
- 独有
记不住也没关系,还可以用局部钩子来实现,不影响俺们做开发
-- 局部钩子和全局钩子
字段类可以设置一些自己的验证规则,但除此之外还想多加一点验证.
反序列化时,验证前端提交过来的数据!
验证顺序: 自己规则 - 局部钩子 - 全局钩子
- 局部钩子
# -- item拿到的是相对应字段的那一个数据
def validate_字段名(self,item):
# -- 格外的一些验证,写正则也可以
# 校验通过,直接return item;校验失败,抛ValidationError的异常!
pass
- 全局钩子
# -- attr拿到的是前端传过来的所有的数据
def validate(self,attrs):
# 校验通过,直接return attrs;校验失败,抛ValidationError的异常!
pass
-- 序列化类之ModelSerializer
ModelSerializer继承自Serializer,是Serializer的子类,Serializer有的,它都有
1) 跟表模型有必然联系,不需要重写create和update方法
(ModelSerializer帮我们写了)
create源码,会动态的获取模型表进行create,有需要的话,还可顺带存第三张表
update源码,通过反射的方式实现的,跟一个个取出来的方式效果一样.
注意:不是说一定不需要重写,有些情况还是需要的.
比如说,新增一个用户,与用户相关的有user表和userdetail表,前端往后端提交数据,提两次?一次基本信息一次详细信息?
No,都是一个表单一次性提交上来的,这种情况就需要重写create、update.把值取出来自己处理!
2) 需要写一个内部类Meta,Meta里再写一些类属性
class Meta:
model = 表模型
# -- fields需要序列化以及反序列化的字段
# ★ 这些字段的字段类是通过表模型映射过来的!!并且把表模型里那些属性像什么max_length=64,null=True也映射过来啦!!
# 也就意味着反序列化验证时,该字段不能超过64位,且可以为空.
# fields = '__all__'
fields = ['字段','方法'] # -- 这种方式既能拿表模型里的字段,也能拿表模型里的方法
extra_kwargs = {'字段':{}}
3) 可以重写要序列化的字段
一般来说,能通过extra_kwargs来达到目的的话,就不需要重写该字段啦
4) 指定某个字段序列化的格式 (有三种,记住前两种即可)
- 在表模型中写方法(可以包装成数据属性)
- 在序列化类中使用SerializerMethodField
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# 序列化类源码分析
# ser.is_valid()
反序列化的校验顺序:
for 字段 in 字段们:
字段自己的校验 - 字段局部钩子的校验
最后 全局钩子的校验通过校验后,ser.is_valid()的值就为True, 校验不通过, 值为false, 校验不通过,会抛异常(drf的APIView会捕获全局异常)
校验通过,调用了ser.save().. 新增触发create,更新触发update. . save()的源码分析前面有!
ser = BookSerializer(data=request.data)
ser.is_valid() # -- 校验字段是否合法!
# 校验了三个地方:字段本身有的(包括validators参数列表里指定的那些函数)、局部钩子、全局钩子
ser.is_valid() -- 按照查找规则,最终执行的是BaseSerializer类里的is_valid方法
is_valid方法的源码如下:
def is_valid(self, raise_exception=False):
# -- 断言不用看
assert hasattr(self, 'initial_data'), (... ...)
# -- self是谁?Serializer类的实例化对象,这里是ser
# 刚开始的时候,ser里命名空间里是没有_validated_data这个键的,经过校验后才有的!!
# 注意,重复多次校验,只会走一次.
# 因为只要校验过一次,ser的命名空间里就有_validated_data这个key啦,其值是校验后的数据!
# 它就不会执行self._validated_data = self.run_validation(self.initial_data)啦!
# 直接return not bool(self._errors)
if not hasattr(self, '_validated_data'):
try:
# -- ★
self._validated_data = self.run_validation(self.initial_data)
except ValidationError as exc:
# -- 捕获的异常可以通过 ser.error取出来,是一个字典!!
errors[field.field_name] = exc.detail
... ...
else:
... ...
... ...
# -- 最终返回的是bool类型,校验成功返回True,失败返回False
return not bool(self._errors)
那 self.run_validation(self.initial_data) 执行的是 谁/哪个类 的run_validation方法?!
★这里有个小坑,用pycharm直接 command+b 跳转到的是Field类里的run_validation方法.因为BaseSerializer类继承了Field类.
这样找是错的,应该重新按照查找规则开始查找 不要过于相信pycharm!!(つД`)ノ
从self'这里是ser'所在类BookSerializer - Serializer - BaseSerializer - Field - ... -Object
在Serializer类中找到了run_validation方法!!
所以self.run_validation(self.initial_data) 执行的是Serializer类中的run_validation方法!!!
run_validation方法的源码如下:
def run_validation(self, data=empty):
(is_empty_value, data) = self.validate_empty_values(data)
if is_empty_value:
return data
value = self.to_internal_value(data) # -- 字段自己的规则以及局部钩子的校验!
try:
self.run_validators(value)
# -- 执行全局钩子
# 若我们自定义的序列化类里写了validate方法!!执行它!
# 若没有,按照查找规则,会执行Serializer类里的validate方法!! - 直接返回attrs
# def validate(self, attrs):
# return attrs
value = self.validate(value)
# -- assert 条件为false时抛出异常
# 这里是为了保证校验通过必须return attrs!!不然的话,默认return None.抛异常.
assert value is not None, '.validate() should return the validated data'
# -- 注意:在执行全局钩子时,出了异常抛出drf的ValidationError才会被捕获到!!
# 这里的ValidationError是drf的;DjangoValidationError是Django的,它导进来时起了个别名.
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value
局部钩子校验相关的to_internal_value方法的源码如下:
def to_internal_value(self, data):
if not isinstance(data, Mapping):... ...
... ...
# -- fields就是自定义序列化类里那些要序列化的字段类!!
# for循环一个个的判断!
for field in fields:
# -- ★ 通过反射 看自定义序列化类里有没有 validate_字段名 的方法!!
validate_method = getattr(self, 'validate_' + field.field_name, None)
primitive_value = field.get_value(data)
try:
# -- 校验字段自己的规则!
validated_value = field.run_validation(primitive_value)
# -- 反射有的话,就会执行该局部钩子函数 validated_value参数就是我们钩子函数里的item参数
if validate_method is not None:
validated_value = validate_method(validated_value)
except ValidationError as exc:
... ...
... ...
... ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
# many参数
# -- 序列化多条
ser = BookSerializer(instance=qs, many=True)
print(type(ser)) # <class 'rest_framework.serializers.ListSerializer'>
# ListSerializer相当于一个列表,里面套了一个个BookSerializer的实例对象!
# -- 序列化单条
ser = BookSerializer(instance=book) # -- 默认many=False
print(type(ser)) # <class 'app01.serializer.BookSerializer'>
神奇吧!!ser不一定就是BookSerializer实例化的对象,是由many参数决定的!!
如何办到的,这个涉及到元类啦!!不想深究,不清楚也不影响开发!!
2
3
4
5
6
7
8
9
10
11