 数据类型之序列
数据类型之序列
# 字符串
# 可变类型与不可变类型
字 列 元 典集
可变与不可变的区别在于里面元素的个数以及元素的内存地址是否可以发生变化
可变: list、dict、set
里面元素的个数以及元素的内存地址可以发生变化.. 即可以对容器内的元素删改以及容器元素的增加
不可变: 数字、tuple、str、frozerset、bool
里面元素的个数以及元素的内存地址都不可以发生变化.. 对不可变对象来说,调用自身的任意方法都不会改变该对象自身的内容.即字符串的独有功能都是新创建一份数据..
# 字符串的格式化
格式化操作符--format--f
'%d,%x'%(65,65)
'%s'%((1,2,4),)
a = '%s'%14 a = '%s'%(14) a = '%s'%(14,)
b = (14,)
a = '%s'%b
注意:
1> 只有一个%s,所以只能接受一个参数
2> %s 接受任意类型的值; %d 只接受int类型数字; %x 十六进制的数据 ; %f 接收浮点数
'my name is {0}, my age is {1:.2f}!'.format('圆周率', 3.1415926)
# -- 左对齐< 右对齐> 居中^
a = 'abc'
format(a,'<10') # 'abc '
format(a,'>10') # ' abc'
format(a,'^10') # ' abc '
format(a,'*^10') # '***abc****'
format(5, '>10') # ' 5'
# --等同于
n = 5
n.__format__('>10') # ' 5'
# -- `+`代表总是打印正负号
>>> format(123,'+')
'+123'
>>> format(-123,'+')
'-123'
>>> format(-123,'>+10')
' -123'
>>> format(-123,'=+10')
'- 123'
>>> format(-123,'0=+10')
'-000000123'
>>> format(546,'0=+10')
'+000000546'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 字符串的驻留机制
字符串驻留是一种在内存中仅保存一份相同且不可变字符串的方法
"""
★ --驻留规则
"""
1> 字符串长度为0或1时,默认采用驻留机制;
2> 字符串长度大于1时,且字符串中只包含大小写字母、数字、下划线(_) 时,采用驻留机制;
3> 对于 [-5,256]之间的整数数字,Python默认驻留;
4> 字符串 只在编译成字节码的过程中进行驻留,而非pvm解释运行时
5> 用乘法得到的字符串,若长度 <=20且字符串只包含数字、字母大小写、下划线,支持驻留;
长度>20,不支持驻留. 这样的设计目的是为了保护.pcy文件不会被错误代码搞的过大.
"""
★ --实验验证
"""
>>> a = "hello"
>>> b = "hello"
>>> a is b
True
>>> a = "hello$"
>>> b = "hello$"
>>> a is b
False
>>> a = -5
>>> b = -5
>>> a is b
True
>>> c = -6
>>> d = -6
>>> c is d
False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
特别注意小整数池
Python提前建立好范围在[-5, 256]的整数对象, 且不会被垃圾回收..无论这个整数处于LEGB中的哪个位置, 所有位于这个范围内的整数使用的都是同一个对象.
主要目的是为了避免频繁申请和销毁小整数的内存空间, 提高程序的运行效率..
# 字符串常见内置方法
字符串 无lindex lfind lsplit方法
拼接 -- join
大小写 -- swapcase upper lower casefold title
字符串组成 -- isdigit isdecimal isalnum isalpha
开头结尾 -- startswith endswith
找位置 -- index rindex find rfind
排版 -- center ljust rjust
分割 -- partition split rsplit
去除 -- strip lstrip rstrip
替换 -- replace
映射 -- maketrans、translate
---
★ --拼接
---
"".join(可迭代对象) # -- 切记这里的可迭代对象中的每一个元素必须是str类型
''.join(list("Hello World")) # -- "Hello World"
---
★ --大小写
---
my_str.swapcase() # -- 大小写互换
my_str.upper() my_str.lower() # -- 全变大写
my_str.casefold() # -- 全变小写
my_str.title() # -- 首字母大写
my_str.islower() # -- 是否由小写字母组成
---
★ --字符串组成判断
---
'abc10'.isdigit() # False -- 判断字符串是否是纯数字组成
"""
isdecimal 只包含十进制字符,这种方法通常用于unicode对象..
bytes类型无isdecimal方法
python3会自动将变量转变为unicode,加不加u都可
"""
u'123'.isdecimal() # True
'abc10'.isalnum() # True -- 只有字母和数字 'saf哈哈哈'.isalnum() 结果居然为True Amazing🤔
'abc10'.isalpha() # False -- 只有字母和文字
---
★ --开头结尾
---
my_str.startswith(子字符串,起始位置"默认为0",结束位置"默认为字符串长度") # -- 判断是否以指定数据开头
my_str.endswith(子字符串,起始位置,结束位置) # -- 判断是否以指定数据结尾
fn.endswith(('.py', '.sh'))
---
★ --找位置
index与find的区别 若未找到 前者报错 后者返回-1
---
my_str.index(substring, beg=0, end=len(string)) # -- 返回指定子字符串第一次出现的索引值,否则抛出异常
"im is boy is good".index("is") # 3
"im is boy is good".rindex("is") # 10
'I like Python!!!'.rfind('python') # -1
---
★ --排版
---
# center居中
# 20为字符长度,字符本身长度大于20以字符长度本身为准;'-'占位符
# 总宽度为20,字符串居中显示,不够用-填充
'abc def'.center(9,"-") # '-abc def-'
'abc def'.ljust(9,"-") # 'abc def--' -- 居左
'abc def'.rjust(9,"-") # '--abc def' -- 居右
---
★ --分割
以指定字符串为单位(可以是只由一个字符组成的字符串)进行分割
---
# -- partition第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
'abcark'.partition('a') # ('', 'a', 'bcark') -- 分割,返回一个3元的元组
'arbcark'.split('ar') # ['', 'bc', 'k'] -- 从左开始分割,返回的是一个列表
# -- split和rsplit都有个可选参数num代表分割次数 默认是-1 代表分隔所有
'abcark'.rsplit('a',1) # ['abc', 'rk'] -- 从右开始分隔
' arb \n \n '.split() # ['arb'] -- 多个/n和空格会算作一个
''.join('abcark'.split('a')) # 'bcrk' -- 达到去除字符串中所有指定的字符的效果
---
★ --去除
去除是以字符为单位
匹配不是按照整个字符串'as'匹配的,而是一个一个匹配的'a' 's'!!!
Ps: my_str.replace()和re.sub()都能达到去除字符的效果.
---
'aaastaarfsfa'.strip('as') # 'taarfsf' -- 去除字符串头尾指定字符
'aaastaarfsfa'.lstrip('as') # 'taarfsfa' -- 去除字符串左边指定字符
'aaastaarfsfa'.rstrip('as') # 'aaastaarfsf' -- 去除字符串右边指定字符
# 'arbcark'
# 若不写参数,默认以空格为标准,包含\n,多个空格和\n连在一起会算成一个
' arbcark \n \n '.strip()
---
★ --替换
---
my_str.replace(old需要替换的字符串, new替换成的字符串,从左到右替换多少个"默认全部") # -- 替换
"this is strising..is..!!!".replace('is','IS',2) # 'thIS IS strising..is..!!!'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
# +、+=、join
"""
Python的字符串是不可变(immutable)的 若想改变字符串,只能通过创建新的字符串来实现.
将字符串hello中的l改为大写的L,有两个解决方案:
1> 使用字符串的拼接
2> 使用字符串的内置函数replace
两种方案都会得到新的字符串,且时间复杂度皆为O(n). n为新字符串的长度.
Ps:
时间复杂度 大O表示法: T(n) = O( f(n) ),其中f(n) 表示每行代码执行次数之和
列表切片时间复杂度O(k),k为切片长度,相当于要执行7次取元素;列表根据下标取元素是O(1)
补充: Java中有可变的字符串类型,比如 StringBuilder,每次添加、改变或删除字符(串),无需创建新的字符串..
时间复杂度仅为O(1)..这样就大大提高了程序的运行效率
"""
>>> s = "hello" # -- s[-1:]与s[-1]的结果都是'o'
>>> new_s = s[:2] + "LL" + s[-1:] # -- 字符串的拼接
>>> new_s
'heLLo'
>>> new_s2 = s.replace('l','L')
>>> new_s2
'heLLo'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
+= 相较于+ 性能得到了一定的提升.. python在底层对+=做了优化操作. 字符串拼接更推荐用join().
s = ""
for n in range(0, 100000):
# print(id(s))
s += str(n)
"""
分析:
for循环会执行n次,循环体内的拼接操作每次都会创建新的字符串,字符串的长度依照循环的次数依次增加
所以,该程序的时间复杂度为 O(1)+O(2)+...+O(n) = (n^2+n)/2 即时间复杂度为O(n^2)
真实分析:
+=操作的优化,在这10万次字符串拼接操作中,不会每次拼接操作都创建新的字符串.
比如100到200的字符拼接的id(s)都为4352190976, 200-270的字符拼接的id(s)都为1403247265..
"""
2
3
4
5
6
7
8
9
10
11
12
13
Q: 下面两种字符串拼接方式谁更高效?
s = ''
for n in range(0, 100000):
s += str(n)
l = []
# -- 该程序的时间复杂度为O(2n)
for n in range(0, 100000):
l.append(str(n)) # -- append操作的时间复杂度为O(1),So,for循环整体的时间复杂度为O(n)
s = ' '.join(l) # -- join操作的时间复杂度为O(n)
# -- 简写: ''.join([str(i) for i in range(0,100000)])
# -- 一个更加pythonic的写法,s = " ".join(map(str, range(0, 10000)))
2
3
4
5
6
7
8
9
10
11
12
13
14
A: 1> 如果字符串拼接的次数较少, 比如range(100), 那么方法一更优.
2> 如果字符串拼接的次数较多, 比如range(1000000), 方法二稍快一些..
# 列表
# extend、+=、+
my_list.extend() 是将可迭代对象的元素逐一加入列表中.
my_list.extend([4,5,6])等同于my_list += [4,5,6] 原地改变;
my_list = my_list + [4,5,6] 在my_list的基础上添加新的元素并返回一个新的对象. id会变
>>> my_list = [1,2,3]
>>> id(my_list)
140685461974272
>>> my_list += [4]
>>> id(my_list)
140685461974272
>>> my_list.extend([5])
>>> id(my_list)
140685461974272
>>> my_list = my_list + [6]
>>> id(my_list)
140685461892032
"""
列表嵌套的问题:
"""
my_list = [[0] * 3 for _ in range(5)]
my_list2 = [[0] * 3] * 5
for i in my_list:
print(id(i))
for i in my_list2:
print(id(i))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# range
联想记忆: range()内置函数与切片一样顾头不顾尾,range可与切片搭配.
range(10)[-1] # 9
range(10)[:-4] # range(0,6)
range(10)[::2] # range(0,10,2)
2
3
# 赋值、切片
记住一个原则,可以使用下标的(即序列), 比如my_str[2], 就可以使用切片
注意一点: 赋值操作结合列表切片
b = a[:] 切片在右侧,是对a列表进行浅拷贝
a[:] = b 切片在左侧,是对a列表进行原地修改
---
★ --列表切片的奇妙技巧
---
1.在列表对象my_list的开始处增加一个元素为3的代码.
my_list.insert(0,3)
my_list[0:0] = [3] 同理(下标为1的地方)-->my_list[1:1] = [3]
2.x = [3,5,7]
x[10:] --> []
x[len(x):] = [1,2] --> x值为[3,5,7,1,2]
x[len(x)-1:] = [1,2] --> x值为[3,5,1,2]
3.x = [1,2]
x[0:0]= [3,3] --> x值为[3,3,1,2] # 添加
x[0:1]= [3,3] --> x值为[3,3,2] # 替换
x[0]= [3,3] --> x值为[[3,3],2] # 修改
2
3
4
5
6
7
8
9
10
11
12
13
14
# 列表常见内置方法
创建 -- []、list()
增 -- append、extend、insert
删 -- del、remove、pop、clear
查 -- 通过索引查找、切片查找
改 -- 对查找的内容进行赋值操作就可以更改(注意一一对应)、sort、reverse
因为列表是可变对象,所以列表调用自身的方法会原地进行改变...
---
★ --增加
---
结论: 用[]创建空列表的效率是高于list()的!!!
区别主要在于list()是一个function call函数调用,Python的function call会创建stack堆栈,并且进行一系列参数检查的操作,反观[]是一个内置的C函数,可以直接被调用,因此效率高!!
---
★ --增加
---
my_list.append([1,2,3]) # -- 列表整体加入列表末尾,原地改变
my_list.extend([1,2,3]) # -- 列表元素逐个加入列表末尾,原地改变
my_list.insert(0,"new") # -- 指定位置插入元素,等同于 my_list[0:0] = ["new"]
---
★ --删除
---
x = list(range(10)) del x[::2] # -- x的值为[1,3,5,7,9]
my_list.remove(2) # -- 移除的是列表中的第一个匹配项,无返回值,若没有,会报错
my_list.pop() # -- pop()默认删除列表最后一个元素并将删除的值返回;
# 括号内可以通过加索引值来指定删除元素
my_list.clear() # -- 清空列表
---
★ --排序翻转
my_list.sort() 和 my_list.reverse() 的返回值都为None!且只适用于列表.原地改变.
---
my_list.sort(reverse=True) # -- 给列表内所有元素排序
# 注意哦,排序时列表元素之间必须是相同数据类型,不可混搭,否则会报错
my_list.reverse() # -- 颠倒列表内元素顺序
---
★ --步长
---
list(range(10))[::2] # 正向步长 -- [0, 2, 4, 6, 8]
list(range(10))[-2::-2] # 反向步长 -- [8, 6, 4, 2, 0]
[] or list() ; () or tuple()
my_list = [i**2 for i in range(1,11) if i > 3] # -- 列表生成式
`x = [[1]]*3` `x[0][0] = 5` `x` --> [[5],[5],[5]]
`x = [1,3,2]` `a,b,c = map(str,sorded(x))` b-->'2'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 分离式顺序表
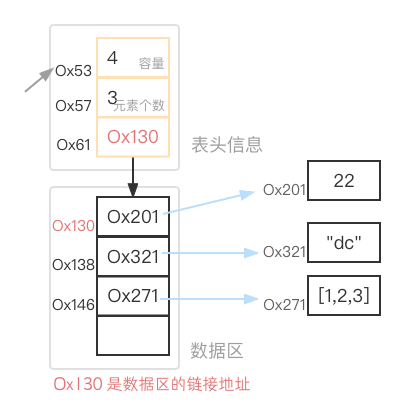
Ps: 上图的分离式顺序表的数据区的数据采用的是 元素外置 的形式进行的存储!!连续存储的是元素的地址(即对实际数据的索引/引用),每个空间占据的大小都为8字节..
列表本质上是分离式的顺序表..
顺序表的结构包括表头和数据区. 分离式顺序表比一体式的顺序表多了一个数据区链接地址...
对列表的元素存储区进行扩充需要经历三个步骤:
1> 重新申请空间
2> 数据搬迁
3> 释放原来的数据
So, 一体式若需扩充的话,整体都要改,变量的指向(起始地址)也会随之改变..
但分离式的起始地址不会改变,只需要更新表头信息中数据区链接地址即可!!
列表 下标/索引定位元素 的时间复杂度为 O(1) -- 利用数据链接区的地址和偏移量(下标)瞬间定位到..
列表 指定值查找 的 时间复杂度为 O(n) -- 需要遍历列表
列表 末尾增加和删除 的时间复杂度为 O(1), 在 指定位置添加和删除 元素的时间复杂度为 O(n) ..
列表 切片 的时间复杂度为 O(k), k为切片的长度. 相当于根据下标定位了k次元素..
Ps: 元祖的也采用的顺序表的实现方式..但元祖是不变的顺序表,因而不支持任何改变其内部状态的操作..
# 序列
何为序列?(列表、元祖、字符串) 可以通过下标偏移量访问到它的一个或多个成员..
序列常见方法 不会改变原序列的值
# 序列通常使用方法
序列(列表、元祖、字符串)都能用操作符(比较>、连接+、重复*、复合赋值*=、成员in)以及 切片
>>> tup = (1,2,3)
>>> new_tup = tup + (4,5) # -- 创建新的元组new_tup,并依次填充两个元组的值
>>> new_tup
(1, 2, 3, 4, 5)
# -- 首先比较下标为0的对应元素,如果相等,再比较下标为1的对应元素,以此类推..
>>> a = [(0,5),(1,4),(0,2),(1,1),(1,3)]
>>> list(sorted(a))
[(0, 2), (0, 5), (1, 1), (1, 3), (1, 4)]
2
3
4
5
6
7
8
9
删除一个list里重复元素并保持它们原来的排序 key=l1.index
>>> l1 = ['b','c','d','b','c','a','a']
>>> sorted(set(l1))
['a', 'b', 'c', 'd']
>>> sorted(l1,key=l1.index)
['b', 'b', 'c', 'c', 'd', 'a', 'a']
>>> sorted(set(l1),key=l1.index)
['b', 'c', 'd', 'a']
2
3
4
5
6
7
口诀: 长大小,和排翻,二元祖,三转换,z次查
len() max() min()
sum() sorted() reversed()
enumerate()
str() tuple() list()
zip() obj.count() obj.index()
# 详见 https://blog.csdn.net/weixin_42444693/article/details/104203479
x = ['11','2','3'], max(x,key=len) # -- 判断列表中最长的项
# 前者返回的是列表;后者返回的是一个翻转后的iterable可迭代对象.
sorted([1,2,3],reverse=True) == reversed([1,2,3]) # -- False
# enumerate返回一个迭代器对象. 此对象的元素是由可迭代参数的索引号及其对应的元素构成的二元祖.
# list()将一个可迭代对象转换为列表!
list(enumerate('one')) # [(0, 'o'), (1, 'n'), (2, 'e')]
# zip返回一个迭代器对象. 此对象的元素是由iterable对象们中的元素一一对应构成的元祖.
list(zip([1,2],[3,4])) # -- [(1, 3), (2, 4)]
list(zip([1,2],{3:1,4:2})) # -- [(1, 3), (2, 4)]
2
3
4
5
6
7
8
9
10
11
12
13
# 列表与元祖
# 存储方式的差异
可以发现存储相同的元素,列表会比元祖多开销16字节的空间..why?
# -- obj.__sizeof__() 返回对象的内存大小
>>> a = [1,2,3]
>>> a.__sizeof__()
64
>>> b = (1,2,3)
>>> b.__sizeof__()
48
"""
此处int整型为8字节.. 3*8=24, 所以初始的空列表和空元祖分别需要40字节和24字节的空间.
列表比元祖多的16字节,有两方面原因:
1> 8字节用于存储指针 -- 便于数据动态变化,动态的改变分离式顺序表的数据区
(大胆猜测,因为列表是分离式的顺序表,so此指针指的是表头中指向数据区的链接地址)
2> 8字节用于存储已经分配的长度大小,实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间
列表是动态的,长度可变,可以随意的增加、删减或改变元素;
元组是静态的,长度大小固定,不可以对元素进行增加、删减或者改变操作.
"""
>>> [].__sizeof__()
40
>>> ().__sizeof__()
24
"""
再次说明:列表和元祖存储元素,采用的是元素外置的形式,连续存储的是元素的地址(即对实际数据的索引/引用)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
列表在扩充空间时具备 over-allocating 机制.. 即扩充容量的时候会多分配一些存储空间..
此机制优化了存储结构, 避免每次增加元素都要重新分配内存
>>> a = []
>>> a.__sizeof__() # -- 空列表的存储空间为40字节
40
>>> a.append([1,2,3])
>>> a.__sizeof__() # -- 加入了元素[1,2,3]之后,列表为其分配了可以存储4个元素的空间(72 - 40)/8 = 4
72 # -- 每个空间8字节,一共有4个,连续存储的是对实际数据的引用(内存地址)
>>> a.append(4)
>>> a.__sizeof__() # -- 由于之前分配了空间,所以加入元素4,列表空间大小不变
72
>>> a.append(4)
>>> a.__sizeof__() # -- 同上
72
>>> a.append(5)
>>> a.__sizeof__() # -- 同上,这是加入的第四个元素
72
>>> a.append(1.2) # -- 加入元素1.2,列表的空间不足,所以又额外分配了可以存储4个元素的空间
>>> a.__sizeof__()
104
>>> a.append("12")
>>> a.__sizeof__()
104
>>> a
[[1, 2, 3], 4, 4, 5, 1.2, '12']
>>> a.append("12")
>>> a.append("12")
>>> a.__sizeof__()
104
>>> a.append("12")
>>> a.__sizeof__()
168 # -- 列表每次分配空间的大小遵循: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 性能差异
1> 因为列表over-allocating机制的存在,元组占用的空间肯定是小于列表的..
2> 一般来说,垃圾回收机制会进行内存回收给OS,但 python在后台会对静态数据做一些资源缓存 ,比如元祖.
元祖的空间大小固定,本质上也是一个array,但Python 的 tuple 做了许多优化..
如果它不被使用并且占用空间不大时,Python 会将其缓存到内部的一个free list(空闲列表)中.
这样,下次我们再创建同样大小的元组时,Python 就可以不用再向操作系统发出请求,去申请内存.
而是可以直接分配缓存的内存空间,提高程序的运行效率...
3> 若想增加删除改变元素,列表显然更优.. 因为元祖需要通过建立一个新的元祖来实现..
>>> a = (1,2,3)
>>> id(a)
140324726613952
>>> del a
>>> b = (1,2,3)
>>> id(b)
140324726605952
>>> c = (1,2,3)
>>> id(c)
140324726600768
# -- 可以看到因为python资源缓存的存在,初始化相同数据的元祖要比列表快的多!!
# -- 使用timeit会自动关掉垃圾回收机制,让程序的运行更加独立,时间计算更加准确
One_Piece@DCdeMacBook-Air ~ % python3 -m timeit 'x=[1,2,3,4,5,6]'
5000000 loops, best of 5: 78.3 nsec per loop
One_Piece@DCdeMacBook-Air ~ % python3 -m timeit 'x=(1,2,3,4,5,6)'
20000000 loops, best of 5: 13.6 nsec per loop
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 应用场景
1> 若存储的数据和数量不变 , 用元组..
比如你有一个函数,需要返回的是一个地点的经纬度,然后直接传给前端渲染.
2> 若存储的数据或数量是可变的, 用列表..
比如社交平台上的一个日志功能,是统计一个用户在一周之内看了哪些用户的帖子.
# python的深浅拷贝
https://note-rtd.readthedocs.io/en/latest/source/2_语言/Python/深拷贝和浅拷贝/_content.html
# 直接赋值
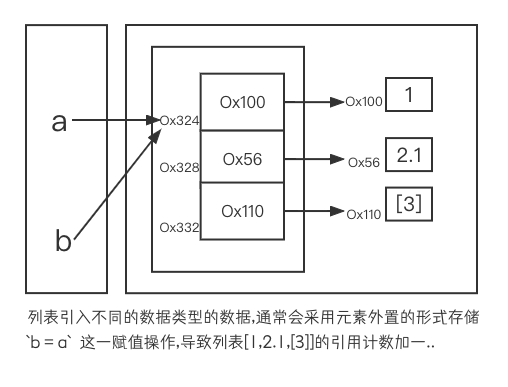
>>> a = [1,2.1,[3]]
>>> b = a # -- Python中对象的赋值都是在进行对象引用(内存地址)传递,实际上a和b指向的都是同一个对象.
>>> a[1] = 4 # -- 修改a的同时,b也会同样被修改
>>> a
[1, 4, [3]]
>>> b
[1, 4, [3]]
>>> a is b
True
2
3
4
5
6
7
8
9
# 浅拷贝
针对可变对象(以列表为例)的浅拷贝,
b = a[:],
仅仅是最顶层开辟了(列表内每个元素的引用计数都会变为2).
通过a对列表内的元素(不用管此元素是可变对象还是不可变对象)进行重新赋值,不会影响b
(因为列表内元素的引用计数不为0)反之同理..
若操作(增删改)列表中的可变对象..a、b都会受到影响..
可以产生浅拷贝的操作有以下几种:
1> 使用切片操作 (准确点说的是列表切片!! 字符串不存在拷贝一说,元祖切片也不会创建新对象..)
2> 使用工厂函数(list/dir/set)-- 即数据本身的构造器
3> 使用 copy 模块中的 copy() 函数
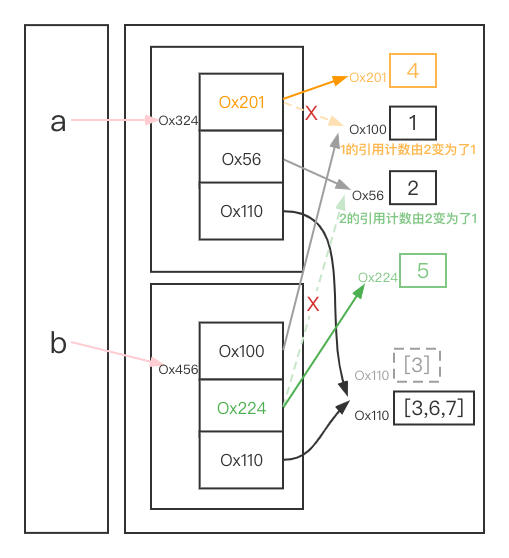
>>> a = [1,2,[3]]
>>> import copy
>>> b = copy.copy(a) # -- 浅拷贝会创建一个新的对象,然后把生成的新对象赋值给新变量
>>> b is a # -- 1、2、[3,]这三个对象并没有创建新的
# 新的对象是指 copy 创建了一个新的列表对象b
# 这样a和b这两个变量指向的列表对象就不是同一个
False
>>> a[0] is b[0] # -- 两个列表对象里面的元素依然是按引用传递的
# 所以a列表中的第一个对象和b列表中的第一个对象是同一个
True
"""
敲黑板,可变与不可变指的是容器里面的元素个数以及元素的内存地址能不能改变..
即除了不能对不可变的容器对象(比如元祖)里面的元素进行重新赋值外(若赋值,元素ID变).其余情况皆可重新赋值.
"""
>>> a[0] = 4 # -- 修改a列表中的不可变对象(重新赋值),b列表不会受到影响
>>> b[1] = 5 # -- 同理,修改b列表中的不可变对象(重新赋值),a列表不会受到影响
>>> a
[4, 2, [3]]
>>> b
[1, 5, [3]]
>>> a[2].append(6) # -- 修改列表中的可变对象,a、b都会受到影响
>>> b[2].append(7)
>>> a
[4, 2, [3, 6, 7]]
>>> b
[1, 5, [3, 6, 7]]
>>> a[2] = 111 # -- 重新赋值
>>> a
[4, 2, 111]
>>> b
[1, 5, [3, 6, 7]]
# -- 举个字典的例子
>>> my_dict = {'a':1,'b':[1,2,3]}
>>> a = copy.copy(my_dict)
>>> my_dict['b'].append(4)
>>> a
{'a': 1, 'b': [1, 2, 3, 4]}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 深拷贝
深拷贝除了顶层拷贝以外,还对子元素进行了拷贝,本质是 递归浅拷贝!
>>> import copy
>>> a = [1, (1, 2), (2, [3]), [4]]
>>> b = copy.deepcopy(a)
>>> a is b
False
# -- 注意了,对象中的元素,若整体都是不可变对象,就会使用引用,因为没有为此生成新对象的必要
>>> a[0] is b[0]
True
>>> a[1] is b[1]
True
>>> a[2] is b[2] # -- (2, [3])虽是元祖,但里面包含有可变的列表.
False
>>> a[3] is b[3]
False
2
3
4
5
6
7
8
9
10
11
12
13
14
# 特殊情况!!
容器类型: 列表、元组、字典、集合 原子类型: 指所有的数值类型以及字符串
1> 对于非容器类型是没有拷贝这个说法的,无论是浅拷贝还是深拷贝都不会创建新的对象
2> 若元祖中只包含原子类型对象, 深浅拷贝都不会创建新的对象
元组本身是不可变对象, 如果元组里的元素也是不可变对象, 就没有进行拷贝的必要了.实测如果元组里面的元素是只包含原子类型对象的元组, 则也属于这个范畴.
>>> b = copy.copy(a) # -- 非容器类型(如数字、字符串、和其他'原子'类型的对象)是没有拷贝这个说法的
>>> c = copy.deepcopy(a)
>>> a is b
True
>>> a is c
True
>>> a=(1,2,3) # -- 元祖中只包含原子类型对象 深浅拷贝都不会创建新的对象
>>> b = copy.copy(a)
>>> c = copy.deepcopy(a)
>>> a is b
True
>>> a is c
True
>>> a = (1,2,(3,)) # -- 元组里的元素也是不可变对象 深浅拷贝都不会创建新的对象
>>> b = copy.copy(a)
>>> c = copy.deepcopy(a)
>>> a is b
True
>>> a is c
True
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
元祖拷贝真的麻烦.. 这样记, 元祖无论怎么写,浅拷贝都不会创建新对象; 观察整个元祖,递归包含的有可变对象时,深拷贝会创建新的对象.. 另外元祖切片不会产生新对象..
>>> a = (1,2,[3]) # -- 深拷贝成功
>>> b = copy.copy(a)
>>> c = copy.deepcopy(a)
>>> a is b
True
>>> a is c
False
>>> d = a[:] # -- 元祖切片不会产生新对象
>>> d is a
True
2
3
4
5
6
7
8
9
10
# 应用
1> x = [[1]]*3 x[0][0] = 5 x --> [[5],[5],[5]]
>>> x = [[1]]*3 # -- 内存地址被拷贝了!
>>> x
[[1], [1], [1]]
>>> assert x[0] is x[1] is x[2]
>>> x[0] = 5
>>> x
[5, [1], [1]]
>>> x[1][0] = 5
>>> x
[5, [5], [5]]
2
3
4
5
6
7
8
9
10
2> x为非空列表,执行语句 y = x[:] 后, id(x[0]) == id(y[0]) 的值为 True.
x[:] 是x列表的浅拷贝, x与y的id肯定不同, 但list是复杂的数据类型,里层元素的id它们是一致的.
>>> x = [1,2,[3,4,5],6]
>>> y = x[:3]
>>> y[0] = 11
>>> y[2].extend([55])
>>> y
[11, 2, [3, 4, 5, 55]]
>>> x
[1, 2, [3, 4, 5, 55], 6]
>>> del x[:3]
>>> x
[6]
>>> y
[11, 2, [3, 4, 5, 55]]
2
3
4
5
6
7
8
9
10
11
12
13