 序列化使用
序列化使用
前言
序列化器有两大主要功能! 序列化 + 数据校验.
当前篇幅主要阐述序列化, 序列化的 核心奥义 就是从数据库获取 QuerySet"多条"或数据对象"单条" 转换成 Json格式 的数据!!
该篇博文就是单纯的进行序列化!!
注: - 在学习分页的时候领悟意识到的.BookSerializer(instance=xxx, many=True)
当many=True时, 填入的 xxx 只要是可迭代的 里面包含着一个或多个对象 即可. 也就是说:
1> xxx的值可以是queryset对象
(但一定要注意 Book.object.filter(id=1) 虽然只有一条数据,但结果也是queryset对象)
2> xxx的值也可以是 [obj,obj,obj] 包含一个或多个obj的列表.
# 快速使用
牢记! drf序列化器序列化的三大步骤:
step1: 从数据库中获取数据
step2: 转换成json格式
step3: 返回给前端
# Serializer
在序列化器中需自己写需要序列化的字段.
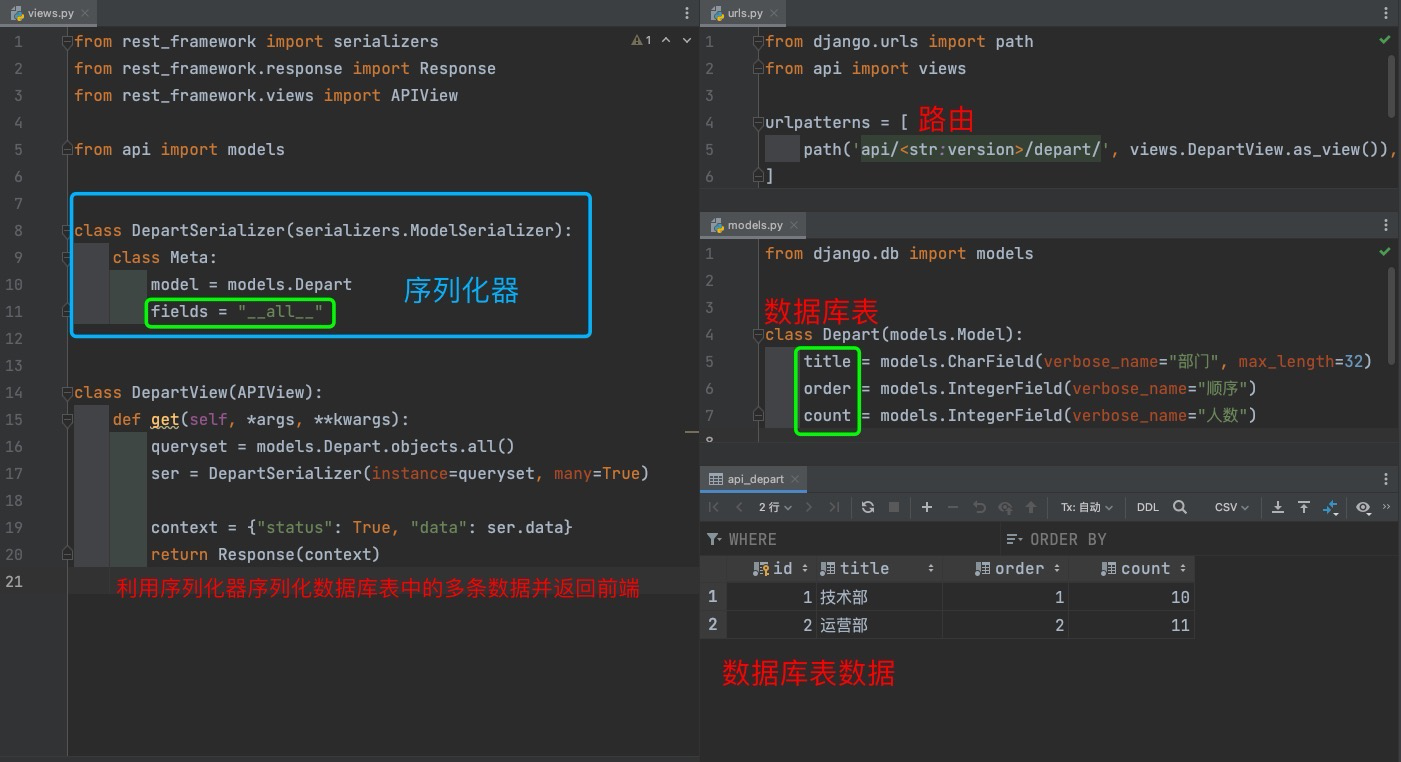
urls.py 根路由
from django.urls import path, re_path
from api import views
urlpatterns = [
path('api/<str:version>/depart/', views.DepartView.as_view()),
]
2
3
4
5
6
api/models.py
from django.db import models
class Depart(models.Model):
title = models.CharField(verbose_name="部门", max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
"""
手动往该表中添加两条数据
title order count
1 技术部 1 10
2 运营部 2 11
"""
"""
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
回顾一点知识. Django ORM的单表查询.
特别注意: 下述的queryset对象以及depart_object对象都不能直接通过json.dumps进行序列化!!
因为json模块的序列化,只支持python内置的数据类型, eg:int/str/list/dict支持 哪怕是datatime/decimal也不支持
1. 所有数据
queryset = models.Depart.objects.all()
queryset --> <QuerySet [<Depart: Depart object (1)>, <Depart: Depart object (2)>]>
type(queryset) --> <class 'django.db.models.query.QuerySet'>
2. 单条数据
depart_object = models.Depart.objects.all().first()
depart_object --> Depart object (1)
type(depart_object) --> <class 'api.models.Depart'>
2
3
4
5
6
7
8
9
api/views.py
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
class DepartSerializer(serializers.Serializer):
# ★ 此处的title、count与ORM数据表中的字段名是对应的!! (SerializerMethodField类型的字段对象除外)
# 这里写了ORM数据表中的哪些字段,利用该序列化器序列化后展示的结果就只有这些字段.
# !! 不是数据库中的数据表的字段名哈,是ORM数据表中的! 为啥?
# 1> 这两个地方的字段名有些是不一样的. 一对多外键字段,会字段加_id,多对多是虚拟字段,自动创建第三张表..等
#. 2> 序列化可以直接用多对多的虚拟对象 (后面会讲到的!)
title = serializers.CharField()
count = serializers.IntegerField()
class DepartView(APIView):
def get(self, *args, **kwargs):
# 情况1. 数据库获取单条数据进行序列化 默认many=False
"""
type(ser.data) --:> <class 'rest_framework.utils.serializer_helpers.ReturnDict'>
ser.data --:> {'title': '技术部', 'count': 10}
"""
# depart_object = models.Depart.objects.all().first()
# ser = DepartSerializer(instance=depart_object)
# 情况2. 数据库获取多条数据进行序列化 many=True
"""
type(ser.data) --:> <class 'rest_framework.utils.serializer_helpers.ReturnList'>
# OrderedDict 本质就是一个字典
ser.data --:> [OrderedDict([('title', '技术部'), ('count', 10)]),
OrderedDict([('title', '运营部'), ('count', 11)])]
"""
queryset = models.Depart.objects.all()
ser = DepartSerializer(instance=queryset, many=True)
context = {"status": True, "data": ser.data}
return Response(context)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
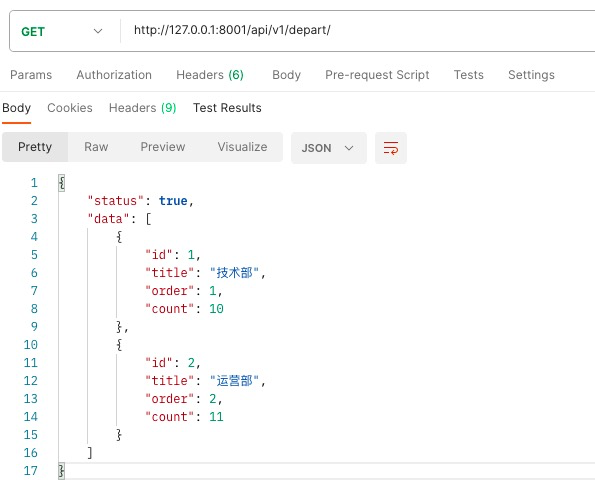
POSTMAN GET请求 http://127.0.0.1:8001/api/v1/depart/ . 结果如下:
{
"status": true,
"data": [
{
"title": "技术部",
"count": 10
},
{
"title": "运营部",
"count": 11
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
# ModelSerializer
Serializer字段得自己写,不方便 就有了ModelSerializer.
可以发现, 对数据表中的字段进行序列化, 使用ModelModelSerializer是要比Serializer更简洁一些的!
同样的, 利用PostMan模拟前端发送请求. 结果如下:
# 应用场景
在上面快速使用中,数据库中的Depart表的字段都是些很简单的CharField、IntegerField.
在真实的业务场景中, 序列化器序列化数据常见场景示例是远不止这一点!
■ choices属性的字段、时间字段、一对多的外键字段、多对多的外键字段 在经过序列化后,如何按照我们的心意进行展示?
■ 如果还要格外展示一些数据库表中没有的字段,我们又该如何在序列化器中自定义该字段?
"快速使用"小节 只是序列化知识的抛砖引玉. 带着上述的疑问, 继续我们苦逼的探究! OS: 学到现在是真的困.
★ 此小节的知识点学完,我们就能处理数据库中的任何表结构.
也就是说,当我们获取到 对象 or QuerySet 时,就可以利用这些知识将其换换成Json格式的数据并返回!
说明一点, 该“应用场景”小节中的示例 使用的视图类的代码都是一样的, 有些示例省略了, 望周知.
class UserView(APIview):
def get(self, *args, **kwargs):
"""获取数据-序列化-返回"""
queryset = models.UserInfo.objects.all()
ser = UserSerializer(instance=queryset, many=True)
context = {"status": True, "data": ser.data}
return Response(context)
2
3
4
5
6
7
# 朴实的序列化
数据库中存的是啥就展示啥. 是多么的朴实无华.
- Depart部门表
id title order count
- UserInfo用户表
id name age gender depart_id ctime
Depart:UserInfo = 1:n ForeignKey外键在UserInfo中,外键字段名为depart
2
3
4
5
6
7
数据库 - 路由 - 视图(序列化器、drf视图类)
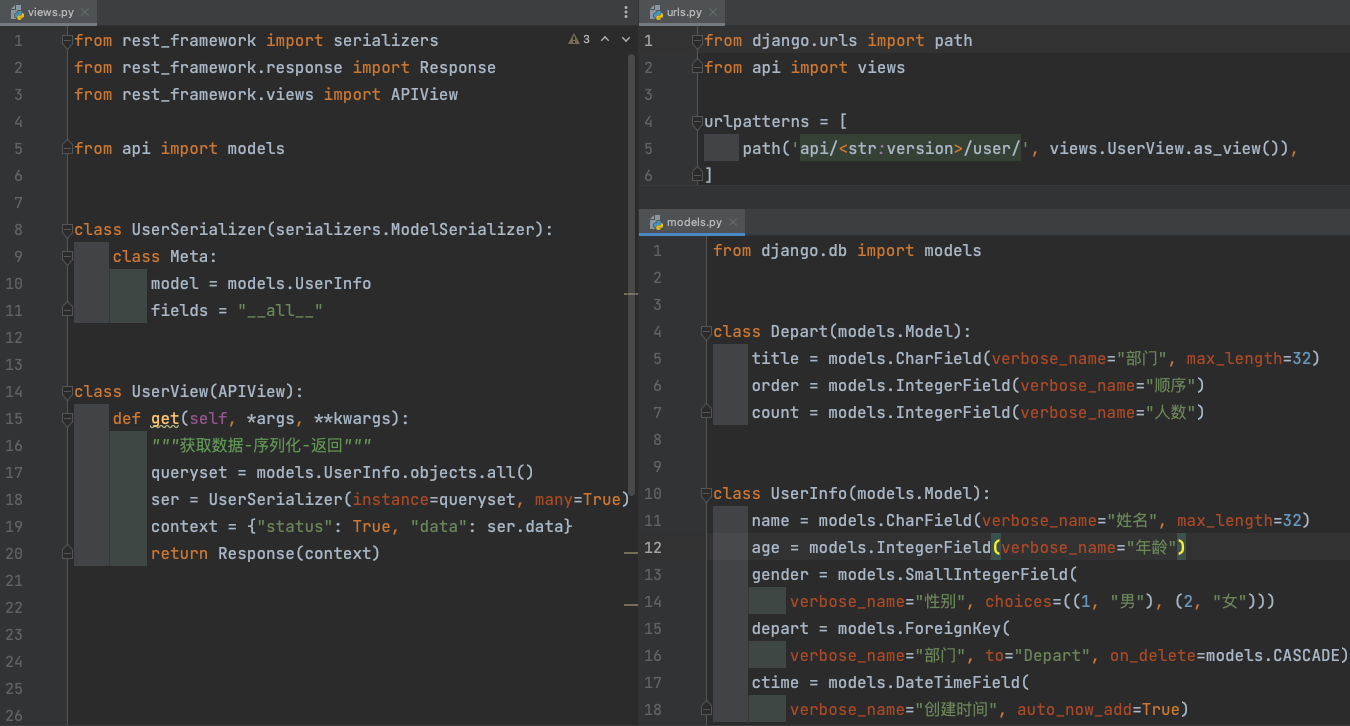
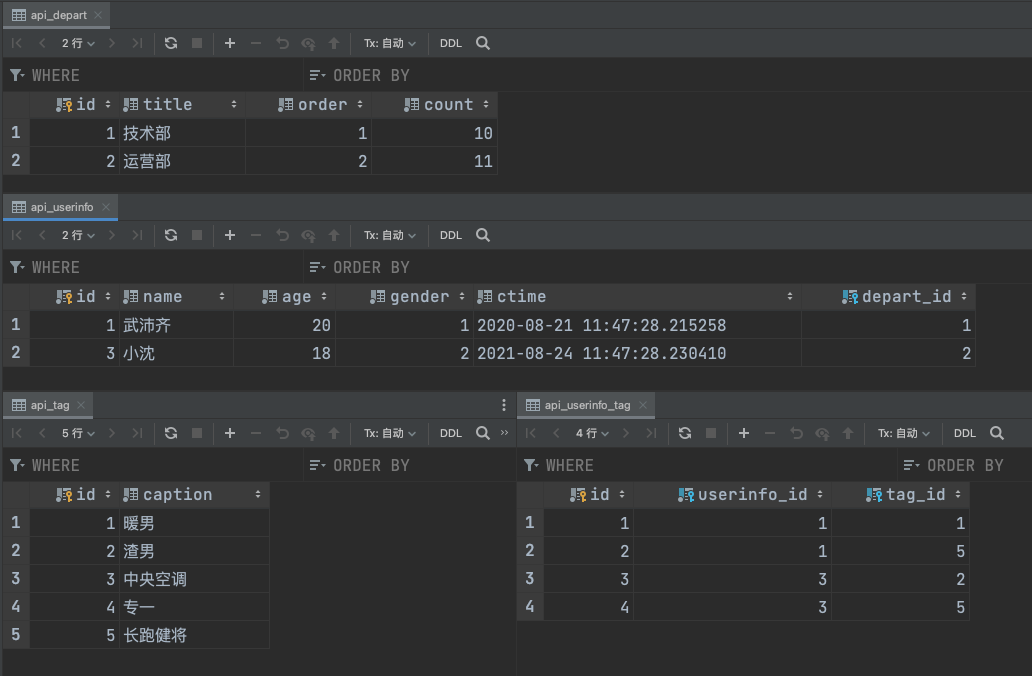
Depart表和UserInfo表中添加的数据
注意: 如果通过pycharm连接sqlite数据库手动添加数据的话, 时间数据会被sqlite自动转换成时间戳, 是sqlite的问题不是代码的问题.
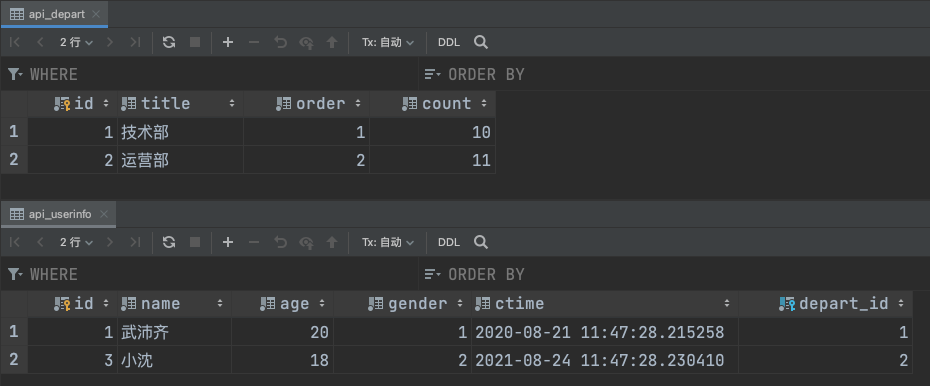
通过PostMan模拟前端请求接口, 得到后端返回的数据.
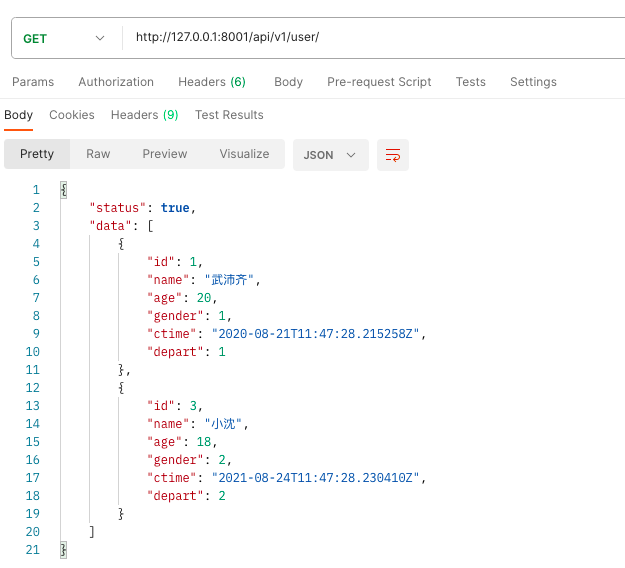
# 开始定制
fields、source、自定义方法
# fields - 指定字段
只展示UserInfo表中 name、age、gender字段. id、ctime、depart字段就不展示啦!
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
# fields = "__all__"
fields = ["name", "age", "gender"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"age": 20,
"gender": 1
},
{
"name": "小沈",
"age": 18,
"gender": 2
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# source - choices
显示有choices属性的字段的文本内容, 需要 <基于source> 做字段的自定制!
1> gender字段显示的不是数字, 是文本内容!!
class UserSerializer(serializers.ModelSerializer):
# 序列化过程中,拿到一个对象/一行记录 此处source的值是get_gender_display So,会执行 obj.get_gender_display()
# 注意:需要加括号时会自动帮忙加括号的.
# obj.get_gender_display() 拿到的是 字符串数据,"男"/"女" 所以,此处是CharField
"""初略的阐述下底层原理:
底层会 循环 从数据库拿到的 queryset对象/多条数据. 然后点语法拿到对象里的字段在数据库中的值.
for obj in queryset:
obj.name
obj.gender # 在数据库中真正存储的是整型
obj.get_gender_display() # 拿到gender字段对应存储在内存中的文本内容
"""
gender = serializers.CharField(source="get_gender_display")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"age": 20,
"gender": "男" # -- "gender": 1
},
{
"name": "小沈",
"age": 18,
"gender": "女" # -- "gender": 2
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2> 既想要gender字段在数据库中存储的数字又想要该字段在内存中的文本内容.
class UserSerializer(serializers.ModelSerializer):
gender_text = serializers.CharField(source="get_gender_display")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "gender_text"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"age": 20,
"gender": 1,
"gender_text": "男"
},
{
"name": "小沈",
"age": 18,
"gender": 2,
"gender_text": "女"
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# source - 外键
depart 外键字段在 数据库的api_userinfo表中 存储的是数字, 并不是关联表中的数据.
所以 朴实的序列化的结果中 该字段 展示的是数字.
如何让结果中, 该字段展示关联表中的数据呢? 同样的, 需要 <基于source> 做字段的自定制!
class UserSerializer(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
# depart.title 跨到api_depart表,拿到关联的一行数据 通过点语法拿到想要的值
# Ps:在进行数据库设计时, 部门表:用户表 = 1:n 不要纠结该设计是否合理.
# 提醒: A表外键字段跨到B表.B表外键字段跨到C表.C表字段 -- 连续跨多张表
depart = serializers.CharField(source="depart.title")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"age": 20,
"gender": "男",
"depart": "技术部" # -- "depart": 1
},
{
"name": "小沈",
"age": 18,
"gender": "女",
"depart": "运营部" # -- "depart": 2
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# source - 时间
朴实的序列化中 时间的显示 年-月-日 时:分:秒
若我只想显示 年月日, 如何操作? 同样的, 需要 <基于source> 做字段的自定制!
create_datetime = serializers.DateTimeField(format="%Y-%m-%d %H:%M:%S")
class UserSerializer(serializers.ModelSerializer):
gender = serializers.CharField(source="get_gender_display")
depart = serializers.CharField(source="depart.title")
# "%Y-%m-%d" 是时间里的占位符.
ctime = serializers.DateTimeField(format="%Y-%m-%d")
class Meta:
model = models.UserInfo
fields = ["name", "age", "gender", "depart", "ctime"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"age": 20,
"gender": "男", # -- "gender": 1,
"depart": "技术部", # -- "depart": 1,
"ctime": "2020-08-21" # -- "ctime": "2020-08-21T11:47:28.215258Z"
},
{
"name": "小沈",
"age": 18,
"gender": "女", # -- "gender": 2,
"depart": "运营部", # -- "depart": 2,
"ctime": "2021-08-24" # -- "ctime": "2021-08-24T11:47:28.230410Z"
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 自定义方法/额外字段
细品前面的 指定字段、choice、外键、时间这些定制的显示结果, 不难发现, 其与数据库字段是强关联的.
若现在我想随便定义一个字段返回, 如何操作呢? 通过 自定义方法 来实现!
自定义的xxx字段会自动触发get_xxx这个函数.该函数返回什么,xxx字段的值就是什么.
class UserSerializer(serializers.ModelSerializer):
xxx = serializers.SerializerMethodField()
"""
for obj in queryset:
obj.name
obj.gender
obj.get_gender_display()
obj.depart.title
get_xxx(obj) # -- obj中是没有xxx的,它底层会执行get_xxx方法,将obj当作参数传给该方法.
"""
def get_xxx(self, obj):
return "{}-{}-{}".format(obj.name, obj.age, obj.get_gender_display())
class Meta:
model = models.UserInfo
fields = ["name", "xxx"]
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"xxx": "武沛齐-20-男"
},
{
"name": "小沈",
"xxx": "小沈-18-女"
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 外键字段
学会前面的定制 + 此处的多对多字段的处理. 工作中序列化相关的常见业务就都能解决啦.
# 实验数据准备
在原来的基础上, 数据库添加一张Tag表.
# -- 部门:用户 = 1:n ForeignKey外键在用户表,外键字段名为depart
# 标签:用户 = n:n ManyToManyField外键在用户表,外键字段名为tag,是虚拟字段!
from django.db import models
class Depart(models.Model):
title = models.CharField(verbose_name="部门", max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class Tag(models.Model):
caption = models.CharField(verbose_name="标签", max_length=32)
class UserInfo(models.Model):
name = models.CharField(verbose_name="姓名", max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(
verbose_name="性别", choices=((1, "男"), (2, "女")))
depart = models.ForeignKey(
verbose_name="部门", to="Depart", on_delete=models.CASCADE)
ctime = models.DateTimeField(
verbose_name="创建时间", auto_now_add=True)
tag = models.ManyToManyField(verbose_name="标签", to="Tag") # 会自动帮忙生成第三张表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
先看看朴实无华的多对多字段结果是怎样的:
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ["name", "tag"]
2
3
4

敲黑板! tag字段虽说是虚拟字段, 但它是可以直接被fields属性指定进行序列化的!!
这就可以反向证明序列化器类里写的那些字段是与ORM数据表中的字段名是对应的!!而不是数据库中数据表的字段.
需求: 上面的操作可以将每个用户关联的所有标签都拿到并展示, 但我并不想展示的是数字, 如何是好?
# 方式一: 自定义方法
基于SerializerMethodField自定义方法对关联表数据进行序列化 .
该示例中涉及到了正反向的查询. 还好我复习总结了.. (´▽`)
class UserSerializer(serializers.ModelSerializer):
tag = serializers.SerializerMethodField()
"""
- 用户表的depart字段是ForeignKey,跨到部门表拿到的是一条数据;
- 用户表的tag字段是ManyToManyField,跨到标签表拿到该用户所关联的所有标签数据,是一个queryset对象,可包含多条数据!
伪代码:
for obj in queryset: # 此处queryset是用户表的所有数据
obj.name
obj.gender
obj.get_gender_display() # choice类型的字段
obj.depart.title # depart
get_xxx(obj) # 自定义方法
obj.tag.all() # 当前用户关联的tag表的所有数据,其结果是一个queryset对象! <QuerySet [Tag对象,Tag对象]>
# 回顾下ORM的查询就知道咋回事了!
"""
def get_tag(self, obj):
# 此处的obj是用户表的一条记录
# 对象.虚拟字段.all() 涉及到n:n ManyToManyField字段的查询.
# obj.tag跨到Tag表,此时可以看着1条用户记录对应多条标签记录,接着通过‘.all()‘取了出来.
tag_queryset = obj.tag.all()
return [{"id": tag.id, "caption": tag.caption} for tag in tag_queryset]
class Meta:
model = models.UserInfo
fields = ["name", "tag"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
结果如下:
{
"status": true,
"data": [
{
"name": "武沛齐",
"tag": [
{
"id": 1,
"caption": "暖男"
},
{
"id": 5,
"caption": "长跑健将"
}
]
},
{
"name": "小沈",
"tag": [
{
"id": 2,
"caption": "渣男"
},
{
"id": 5,
"caption": "长跑健将"
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 方式二: 嵌套
基于嵌套的序列化类实现.
注意! 嵌套主要针对 fk、m2m, 只有这两个用嵌套才有意义!
# - 当然DepartSerializer、TagSerializer序列化器里也可以自定制,这里从简. 知识是固定的,业务是灵活的,根据需求自由搭配嘛.
class DepartSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = "__all__"
class TagSerializer(serializers.ModelSerializer):
class Meta:
model = models.Tag
fields = "__all__"
class UserSerializer(serializers.ModelSerializer):
# ★★★ 敲黑板!! 当前用户关联部门,对应的部门记录是一条,当前用户关联标签,对应的标签记录是多条.So,多条的需要加上many=True.
depart = DepartSerializer()
tag = TagSerializer(many=True)
class Meta:
model = models.UserInfo
fields = ["name", "depart", "tag"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
结果如下:
{
"status": true,
"data": [
{
"name": "武沛齐",
"depart": {
"id": 1,
"title": "技术部",
"order": 1,
"count": 10
},
"tag": [
{
"id": 1,
"caption": "暖男"
},
{
"id": 5,
"caption": "长跑健将"
}
]
},
{
"name": "小沈",
"depart": {
"id": 2,
"title": "运营部",
"order": 2,
"count": 11
},
"tag": [
{
"id": 2,
"caption": "渣男"
},
{
"id": 5,
"caption": "长跑健将"
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 继承
该知识点用的不多, 但得了解知道.
class Base(serializers.Serializer): # -- 注意这里是serializers.Serializer,不是ModelSerializer
more = serializers.SerializerMethodField()
def get_more(self, obj):
return "123"
class UserSerializer(serializers.ModelSerializer, Base):
class Meta:
model = models.UserInfo
fields = ["name", "more"] # -- "xx"是从父类Base中拿到的!
"""
{
"status": true,
"data": [
{
"name": "武沛齐",
"more": "123"
},
{
"name": "小沈",
"more": "123"
}
]
}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27