 imp_knowledge
imp_knowledge
# 数据库相关概念
数据库管理软件: 本质就是个c/s架构的 套接字程序 关系型 数据库管理软件
DBMS: 解决安全、并发的问题
DATA、DB、DBA、DBMS
简单理解:
关系型数据库需要有表结构 mysql、oracle、sqlserver
非关系型数据库是key-value存储的 没有表结构!redis、mongodb
| 名词 | 解释 |
|---|---|
| 数据 | 图片、文字、视频等 |
| 记录 | 文件中的一条信息 |
| 表 | 一个文件 |
| 库 | 文件夹 |
| 数据库管理系统软件 | 套接字程序:mysqld、mysql |
| 数据库服务器 | 运行mysql的计算机 |
创建数据库后 初始的四个库
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库. 主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
# 存储引擎
自己的理解:
数据库是文件夹,那么数据表就是文件.
文件有很多类型, 表格需要excel来处理,mp4视频需要播放器,So,不同类型的数据表需要不同东西来管理.
innodb类型的数据表就需要名叫innodb存储引擎来管理.再通俗一点 就是选择数据表的管理方式(CRUD 建立索引等).
具体来说,存储引擎 就是 如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术 的 实现方法. 因为在关系数据库中数据的存储是以表的形式存储的, 所以存储引擎也可以称为表类型.
<表类型(存储和操作此表的类型)是我们方便理解放在这里的名词 不是官方的>
create table t1 (id int) engine=innodb;
mysql有多种存储引擎. 而Orcle和SQL server等数据库中只有一种存储引擎,数据存储管理机制是一样的.
数据库中的表(说白了就是文件)有不同的类型, 表的类型不同, 会对应mysql不同的存取机制
innodb 索引组织表数据 myisam blackhole memory ....
| 存储引擎 | 生成文件 |
|---|---|
| myisam | t1.frm(表的结构) t1.MYD(表的数据) t1.MYI(存储索引) |
| innodb 索引组织表 | t2.frm(表的结构) t2.ibd(表的数据和索引) |
| blackhole | t3.frm(表的结构) |
| memory | t3.frm(表的结构) |
注意: innodb、myisam数据存在硬盘;blackhole压根不存数据;memory数据存在内存 重启服务端数据消失。
show engines; -- 查看mysql支持的存储引擎.
show variables like 'storage_engine%'; -- 查看正在使用的存储引擎
-- 可以在mysql的配置文件 my.cnf 中指定默认的存储引擎
2
3
4
图的上部分是客户端,下部分是服务端.
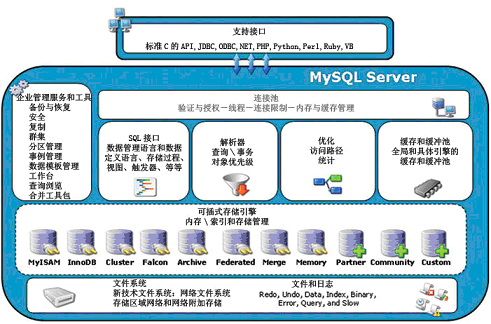
> 「服务端」
服务端的最底部是文件系统:
各种各样的文件,比如存在于硬盘上的t1.frm 、t1.ibd.
建表实际上就是在硬盘上生成文件.
服务端的倒数第二层是存储引擎:'大白话 不同文件的处理程序'
建表时默认的存储引擎(表的类型)是innodb. mysql会使用名叫innodb的程序去处理这张表.
>「客户端」
客户端里是mysql提供的各种各样语言的接口.
比如: python根据mysql提供的接口封装出一个叫pymysql的模块.来作为mysql的客户端连接mysql服务端.
>「过程」
服务端连接池里的一个线程就对应一个客户端请求连接.
它先调用sql接口(eg:若是select语句就找select接口)来处理传过来的sql语句;
再交给解析器解析这条sql语句是做什么的;
优化sql语句(利用explain查询sql语句的运行计划)选取最优的方案让其用尽量少的IO去完成这件事;
若需要的数据在缓存里,那就从缓存里面拿; 该往缓存里放的就放到缓存里面;
往后,用innodb存储引擎来具体的控制存取硬盘里的文件.
innodb 支持事务、行级锁、foreign key
# 表操作
一行内容就称为一条记录.
注意:
创建表时最后一个字段不要加逗号, 否则会报错
字段名和类型是必须有的
字段的类型大小(即宽度)可以不写 若不写会有个默认值
字段的约束可选
mysql> select host,user from mysql.user;
+-----------+------------------+
| host | user |
+-----------+------------------+
| % | luffy |
| % | wupeiqi4 |
| localhost | mysql.infoschema |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+------------------+
6 rows in set (0.00 sec)
-- 查询语句 将数据从硬盘读到内存然后格式化输出打印出来.
-- mysql.use这张表肯定是在硬盘里的,但打印出来的这张表在硬盘里没有,叫做虚拟表
-- 复制表
create table t6 select host,user from mysql.user; -- 表结构和数据
create table t6 select host,user from mysql.user where 1<0; -- 只有表结构 是张空表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 表字段的数据类型
所有的数据类型里面,字段的宽度代表的都是最大存储宽度,只有整型除外,指的是打印时候的显示宽度.
# 数字类型
<1> 整型:tinyinit、int、bigint
作用: 存储年龄, 等级, id, 各种号码等
int整数类型不需要指定宽度(没卵用 设置后超过了也会全显示)!! 加了的都是小垃圾.
int的存储宽度是4个字节Bytes
32bit 2^32 默认的显示宽度是11,最大数值是10位再加上符号共11位.
<2> 浮点型:
float(m,n)、double(m,n)、decimal(m,n) 三者精度从低到高 decimal最精准
代表此浮点数最大m位数,其中小数位可以保留n位.(意味整数位m-n位)
作用: 存储薪资、身高、体重、体质参数等
float(255,30) double(255,30) decimal(65,30)
一般情况下float够用了,有精度要求double也能满足99%的情况啦!
# 日期类型
DATE、TIME、DATETIME (最常用)、TIMESTAMP、YEAR
作用: 存储用户注册时间、文章发布时间、员工入职时间、出生时间、过期时间等.
create table student(
id int,
name varchar(16),
birth date, -- 年月日 出生日期
class_time, -- 时分秒 上课时间
reg_time datetime, -- 年月日时分秒 注册时间
born_year year -- 年 出生年份
);
insert student values (1,'egon','1993-01-23','08:30:00','2022-03-23 09:30:21','1993');
2
3
4
5
6
7
8
9
10
DATETIME与TIMESTAMP的区别
DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年
DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。
在mysql服务器,操作系统以及客户端连接都有时区的设置。
DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。空间小一点,IO次数更少.
TIMESTAMP会自动做约束,此日期类型不允许为空,若传空的话,它会用当前的时间自动填充,更新的时候也一样.
create table t1(x datetime not null default now()); # 需要指定传入空值时默认取当前时间
create table t2(x timestamp); # 无需任何设置,在传空值的情况下自动传入当前时间
insert into t1 values();
insert into t2 values();
2
3
4
5
6
7
8
9
10
11
12
# 字符类型
char、varchar
注意: 它两括号内的参数指的都是字符的长度 '存储宽度' . 不是字节!!
要晓得一点, 一个中文是一个字符, 一个英文字母也是一个字符. 在utf8编码下, 前者占3个字节. 后者占1个字节.
sql优化: 创建表是, 定长类型'eg sex'往前放, 变长的往后放'eg address'
-- char(4) [定长] 字符长度0-255
insert t1 values('你好啊哈哈') -- '你好啊哈'
insert t1 values('你') -- '你 '
-- varchar(4) [变长] 字符长度0-65535
insert t2 values('你好啊哈哈') -- '你好啊哈'
insert t2 values('你') -- '你'
-- 两者在存够的情况下都会显示规定长度的字符量.(非严格模式下!)
-- 没存够,char会自动向右填充空白字符, varchar不会.
2
3
4
5
6
7
8
9
10
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
|---|---|---|---|---|
'' | ' ' | 4 bytes | '' | 1 byte |
'ab' | 'ab ' | 4 bytes | 'ab' | 3 bytes |
'abcd' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
'abcdefgh' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
在没有存够的情况下,varchar比char更节省空间? 没有那么简单.
看上方表格. varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数.
如果真实的数据<255bytes 则需要1Bytes的前缀(1Bytes=8bit 2^8=255)
如果真实的数据>255bytes 则需要2Bytes的前缀(2Bytes=16bit 2^16=65535)
因而, 存储的宽度刚好达到或超过4, varchar反而是更加浪费空间的.
但开发过程中大多时候用的还是varchar.因为往往真实存储的都会比设置的存储宽度小.不会存的刚刚好.
有一个很有意思的点!看下方.
-- char(5),varchar(5)
-- 补充: 在检索时char很不要脸地将自己浪费的字符给删掉了,装的好像自己没浪费过空间一样(之所以隐藏是因为这是底层的),而varchar很老实,存了多少,就显示多少
-- 略施小计,让char现出原形
mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; -- 填充字符到完成的长度
-- length:查看字节数
-- char_length:查看字符数
mysql> select x,char_length(x),y,char_length(y) from t1;
+-------------+----------------+------------+----------------+
| x | char_length(x) | y | char_length(y) |
+-------------+----------------+------------+----------------+
| 你瞅啥 | 5 | 你瞅啥 | 4 |
+-------------+----------------+------------+----------------+
1 row in set (0.00 sec)
# char类型:3个中文字符+2个空格=11Bytes
# varchar类型:3个中文字符+1个空格=10Bytes
mysql> select x,length(x),y,length(y) from t1;
+-------------+-----------+------------+-----------+
| x | length(x) | y | length(y) |
+-------------+-----------+------------+-----------+
| 你瞅啥 | 11 | 你瞅啥 | 10 |
+-------------+-----------+------------+-----------+
1 row in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
注意: <等号匹配> 末尾空格并不影响查询会自动忽略 但like模糊匹配会有影响,它不会忽略空格
(char有这方面的困扰'自动填充空格',varchar没有)
其它字符系列, 比如TEXT、BLOB等可以将整篇文章的字符都存进去, 但这样做不好.
我们通常会存这篇文章的地址.减少数据库的IO量. 大文件一般放到一台专门的文件服务器中!
标准:文件超过255个字符
场景: 客户端请求一个视频
客户端A 应用服务器B 数据库服务器C 文件服务器D 外部服务器E(接受请求 增大并发量的)
A ==req=> B ==req=> C ==res视频地址=> B ==res视频地址=> A ==req=> D ==res=> A
2
3
# 枚举与集合
前者实际上最多限制3000个不同元素 后者最多可以有64个不同元素
enum: 单选 只能在给定的范围内选一个值. eg 性别 sex 男male/女female
level enum('vip1','vip2','vip3','vip4','vip5')
sex enum('male','female')
set: 多选 在给定的范围内可以选择一个或一个以上的值. eg 爱好1,爱好2,爱好3...
hobby set('play','music','read','study')
非严格模式下,不会报错, 只会插范围之内的数据.
# 表字段的约束条件
UNSIGNED 无符号
eg : id int unsigned 表明id值不能为负数啦 一般不指定
ZEROFILL 使用0填充
AUTO_INCREMENT 标识该字段的值自动增长 默认整数类型 通常跟主键一起使用
必须有key约束它!!
eg : id int primary key auto_increment
DEFAULT 为该字段设置默认值
NOT NULL 标识该字段不能为空, 通常与default一起使用
字段默认允许为空, 若缺省默认值为NULL
eg : age int not null defaule 0
PRIMARY KEY (PK) 主键 标识该字段不能为空 并且唯一
以innodb为存储引擎的一张表 必须要有个主键 并且只能有一个 通常是id字段
若用联合主键 实际上查询加速效果不佳 通常不会建联合主键
若没有设置主键 innodb会自上而下去找一个不为空且唯一的字段,
若没找到innodb就会创建一个不为空且唯一的隐藏字段.
-- PRI
create table t1(
id int auto_increment primary key, -- 主键
/* 等同于
id int,
constraint uk_name primary key(id) -- 单独写
*/
host varchar(15) not null,
port int not null
-- primary key(host,port) -- 联合主键
)
alter table 表名 add primary key(列名); -- 表创建完后加主键索引
/* 表创建好后 格外添加一个字段 作为主键
ALTER TABLE demo.test
ADD COLUMN itemnumber int PRIMARY KEY AUTO_INCREMENT;*/
-- [删除]
alter table 表名 drop primary key;
# 注意: 删除索引时可能会报错 因为给某一列设置了自增auto_increment 那此列必须定义为键
-- ERROR 1075 (42000): Incorrect table definition; there can be only one auto column and it must be defined as a key
# 那此时的删除用修改约束的命令 相当于将主键和自增给去掉
alter table 表 change id id int not null;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
UNIQUE 表示该字段唯一,不能重复 (注意: 它除了本身的约束效果外 还是一个key可以提速)
eg : id int not null unique
注意: 若有两个null值也会被认为是重复!
很有意思的一点 : 设置某一字段不为空且唯一会产生化学反应 会被标识为主键
-- UNI
create table t1(
id int auto_increment primary key,
name varchar(20) unique, -- 唯一索引可以有多个
/* 等同于
name varchar(20),
constraint uk_name unique(name)
*/
host varchar(15) not null,
port int not null
-- unique(host,port) 可以联合唯一 即host或port字段值可以重复 但是host+port不能重复!
)
create unique index 索引名 on 表名(列名);
-- [删除]
drop unique index 索引名 on 表名;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
INDEX 普通索引 , 加速查找
-- MUL
create table 表名(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
index ix_email (email),
index ix_name (name),
);
create table 表名(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
index ix_email (name,email) -- 如果有多列,称为联合普通索引。
);
create index 索引名 on 表名(列名);
drop index 索引名 on 表名;
-- 看建的索引
show create table s1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
FOREIGN KEY (FK) 标识该字段为该表的外键 这就涉及表关系的建立啦!
sex enum('male','female') not null default 'male'
age int unsigned not null default 20 -- 必须为正值 不允许为空 默认值为20
2
3
-- AUTO_INCREMENT
# 可以指定id
mysql> insert into student values(4,'asb','female');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,'wsb','female');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values('ysb');
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)
-- 了解自增字段的起始值 步长等. 略..
-- 详见: https://www.cnblogs.com/linhaifeng/articles/7238814.html
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52