 pandas高级操作
pandas高级操作
该篇博客我们来康康pandas的高级操作!!
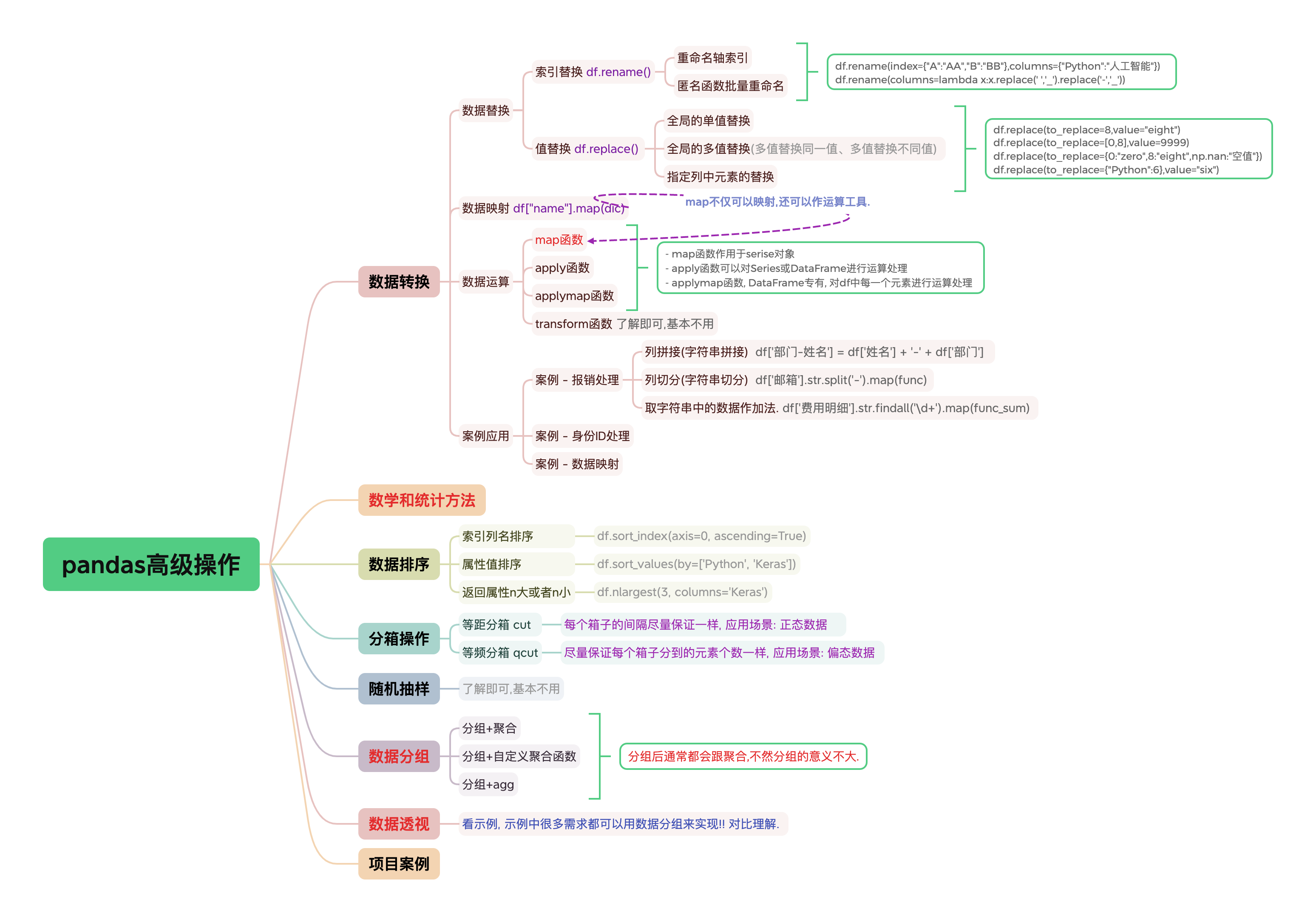
# 数据转换
# 数据替换
测试数据准备
>>> import numpy as np
>>> import pandas as pd
>>> df = pd.DataFrame(
data=np.random.randint(0,10,size=(5,3)),
index=list('ABCDE'),
columns=["Python","Tensorflow","Keras"])
>>> df.iloc[4,2] = None
2
3
4
5
6
7
# 索引替换
■ 重命名轴索引
>>> df
Python Tensorflow Keras
A 8 4 0.0
B 0 0 3.0
C 6 8 1.0
D 8 3 0.0
E 3 8 NaN
>>> # 需求: 将行索引"A"替换成"AA", "B"替换成"BB" ; 将列索引 "Python"替换成"人工智能".
>>> df.rename(index={"A":"AA","B":"BB"},columns={"Python":"人工智能"}) # 返回新对象,并未修改原df对象
人工智能 Tensorflow Keras
AA 8 4 0.0
BB 0 0 3.0
C 6 8 1.0
D 8 3 0.0
E 3 8 NaN
2
3
4
5
6
7
8
9
10
11
12
13
14
15
■ 匿名函数批量重命名
# -- 匿名函数应用索引替换
# 原始数据的列索引不符合Python的命名规范,给其进行重命名(例如: Row ID改为Row_ID,Sub-Category改为Sub_Category)
df = pd.read_csv('superstore_dataset2011-2015.csv')
df.rename(columns=lambda x:x.replace(' ','_').replace('-','_'))
2
3
4
# 值替换
■ 全局的单值替换
>>> df
Python Tensorflow Keras
A 8 4 0.0
B 0 0 3.0
C 6 8 1.0
D 8 3 0.0
E 3 8 NaN
>>> df.replace(to_replace=8,value="eight")
Python Tensorflow Keras
A eight 4 0.0
B 0 0 3.0
C 6 eight 1.0
D eight 3 0.0
E 3 eight NaN
2
3
4
5
6
7
8
9
10
11
12
13
14
■ 全局的多值替换
>>> df
Python Tensorflow Keras
A 8 4 0.0
B 0 0 3.0
C 6 8 1.0
D 8 3 0.0
E 3 8 NaN
>>> # 多个值替换成同一个值
>>> df.replace(to_replace=[0,8],value=9999)
Python Tensorflow Keras
A 9999 4 9999.0
B 9999 9999 3.0
C 6 9999 1.0
D 9999 3 9999.0
E 3 9999 NaN
>>> # 多个值替换成不同的值
>>> df.replace(to_replace={0:"zero",8:"eight",np.nan:"空值"})
Python Tensorflow Keras
A eight 4 zero
B zero zero 3.0
C 6 eight 1.0
D eight 3 zero
E 3 eight 空值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
■ 指定列中的元素进行替换
>>> df
Python Tensorflow Keras
A 8 4 0.0
B 0 0 3.0
C 6 8 1.0
D 8 3 0.0
E 3 8 NaN
>>> # 将Python这一列中等于6的,替换为"six"
>>> df.replace(to_replace={"Python":6},value="six")
Python Tensorflow Keras
A 8 4 0.0
B 0 0 3.0
C six 8 1.0
D 8 3 0.0
E 3 8 NaN
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 数据映射
★ 只能针对一组数据/serise对象/某一行或某一列
通过map函数对DataFrame表格中的某一列或某一行所对应的这一组数据当中的每一个元素都绑定一个固定形式的标签(eg:字符串).
>>> import numpy as np
>>> import pandas as pd
>>> dic_data = {
'name':['zhangsan','lisi','wangwu','lisi'],
'salary':[10000,12000,8000,12000]
}
>>> df = pd.DataFrame(data=dic_data)
>>> df
name salary
0 zhangsan 10000
1 lisi 12000
2 wangwu 8000
3 lisi 12000
>>> # 字典充当关系映射表
>>> dic = {'zhangsan':"张三",'lisi':'李四'}
>>> # 根据关系映射表将'zhangsan'绑定成'张三','lise'绑定成'李四'. 最后将map的结果作为原始数据新的一列!!
>>> df['e_name'] = df['name'].map(dic)
>>> df
name salary e_name
0 zhangsan 10000 张三
1 lisi 12000 李四
2 wangwu 8000 NaN # 注:关系映射表中没有wangwu的映射,就用NaN值进行了填充!
3 lisi 12000 李四
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 数据运算
# ★★★ map函数
map函数对Series数据的运算处理(map作为Series对象的运算工具)
>>> dic_data = {
'name':['zhangsan','lisi','wangwu','lisi'],
'salary':[10000,12000,8000,12000]
}
>>> df = pd.DataFrame(data=dic_data)
>>> df
name salary
0 zhangsan 10000
1 lisi 12000
2 wangwu 8000
3 lisi 12000
>>> # map不仅可以映射,还可以作运算工具. 给df['salary']这一组数据的每一个元素作运算!示例中是算稅后薪资.
>>> def after_sal(s):
return s-(s-3000)*0.5
>>> df['after_sal'] = df['salary'].map(after_sal)
>>> df
name salary after_sal
0 zhangsan 10000 6500.0
1 lisi 12000 7500.0
2 wangwu 8000 5500.0
3 lisi 12000 7500.0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# apply函数
apply也可以像map一样充当运算工具, 不过apply运算效率要远远高于map. 因此在数据量级较大的时候可以使用apply.
★ apply函数可以对Series或DataFrame进行运算处理
测试数据准备
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(0, 10, size=(6, 3)),
index=list('ABCDEF'),
columns=['Python', 'Tensorflow', 'Keras'])
df.iloc[4, 2] = None
2
3
4
5
6
7
■ apply可作用在Series中/可以对Series中的每一个元素进行运算处理
df['Keras_res1'] = df['Keras'].apply(lambda x: True if x > 3 else False)
df['Keras_res2'] = df['Keras'] > 3
print(df)
"""
Python Tensorflow Keras Keras_res1 Keras_res2
A 4 6 1.0 False False
B 3 9 1.0 False False
C 2 2 4.0 True True
D 5 4 8.0 True True
E 0 5 NaN False False
F 1 0 7.0 True True
"""
2
3
4
5
6
7
8
9
10
11
12
13
■ apply作用在DataFrame中:可以对df中的行或列进行运算处理
def convert(x): # 自定义方法
return x.mean(), x.count()
df["apply_res"] = df.apply(convert, axis=1)
print(df)
"""
Python Tensorflow Keras apply_res
A 4 4 3.0 (3.6666666666666665, 3)
B 6 7 4.0 (5.666666666666667, 3)
C 8 6 2.0 (5.333333333333333, 3)
D 5 8 9.0 (7.333333333333333, 3)
E 9 0 NaN (4.5, 2)
F 9 8 3.0 (6.666666666666667, 3)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# applymap函数
★applymap函数, DataFrame专有, 对df中每一个元素进行运算处理
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(0, 10, size=(4, 3)),
index=list('ABCD'),
columns=['Python', 'Tensorflow', 'Keras'])
df.iloc[2, 2] = None
print(df)
res1 = df.applymap(lambda x: x + 100)
print(res1)
res2 = df + 100
print(res2)
"""
Python Tensorflow Keras
A 8 5 0.0
B 4 2 1.0
C 6 1 NaN
D 8 4 6.0
Python Tensorflow Keras
A 108 105 100.0
B 104 102 101.0
C 106 101 NaN
D 108 104 106.0
Python Tensorflow Keras
A 108 105 100.0
B 104 102 101.0
C 106 101 NaN
D 108 104 106.0
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# transform函数
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,10,size = (10,3)),
index = list('ABCDEFHIJK'),
columns=['Python','Tensorflow','Keras'])
# ■ 功能1: 对Series/一组数据的每个元素作多种运算,执行多项计算
# 注!!只能传入对单个元素可作的运算(非聚合运算),聚合不行(eg:np.main就不行)
df['Python'].transform([np.sqrt,np.exp]) # Series处理
# ■ 功能2:对数据表格的多列作不同形式的运算
def convert(x):
if x.mean() > 5:
x *= 10
else:
x *= -10
return x
df.transform({'Python':convert,'Tensorflow':lambda x:np.min(x),'Keras':lambda x:np.max(x)}) # DataFrame处理
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 案例应用
在pycharm中打印pandas读取的excel表格数据,为了显示的工整完整,会进行以下配置:
pd.set_option('display.unicode.east_asian_width', True) # 使得 Pandas 在计算列宽时考虑东亚字符的实际宽度
pd.set_option("display.width", None) # 自动调整显示宽度,消除打印不完全中间的省略号
pd.set_option("display.max_columns", None) # 显示所有列
pd.set_option("display.max_rows", None) # 显示所有行
pd.set_option('display.max_colwidth', None) # 显示列宽度
2
3
4
5
6
7
# 报销处理

测试代码如下:
★ df['邮箱'].str 变成StringMethods类型,就可使用str、findall等方法!!
import pandas as pd
df = pd.read_excel('报销处理-Python版.xlsx').head()
print(df)
# 需求1: 将部门列的数据和姓名列的数据合并到一起显示在部门-姓名列中 -- 列拼接(字符串拼接)
# ps: 若部门和姓名里有空值,那么就先做数据清洗,得保证这两列都是字符串,因为要做加法的字符串拼接!
df['部门-姓名'] = df['姓名'] + '-' + df['部门']
# 需求2: 将邮箱列中的用户名和密码提取出来填充到用户名列和密码列中 -- 列切分(字符串切分)
userNameList = []
pwdList = []
def func(x):
user_name = x[0]
pwd = x[1]
userNameList.append(user_name)
pwdList.append(pwd)
df['邮箱'].str.split('-').map(func) # df['邮箱'].str 变成StringMethods类型,就可使用str、findall等方法!!
df['用户名'] = userNameList
df['密码'] = pwdList
# 需求3: 提取费用明细列中的数字,相加到合计列中 -- 取字符串中的数据作加法.
def func_sum(alist):
# 取出来的数字可能是字符串类型,所以相加时,做个类型转换会更保险!!
return pd.Series(data=alist).astype('int').sum()
df['合计'] = df['费用明细'].str.findall('\d+').map(func_sum) # 取出列表中的数字作加法.
print()
print(df)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 身份ID处理
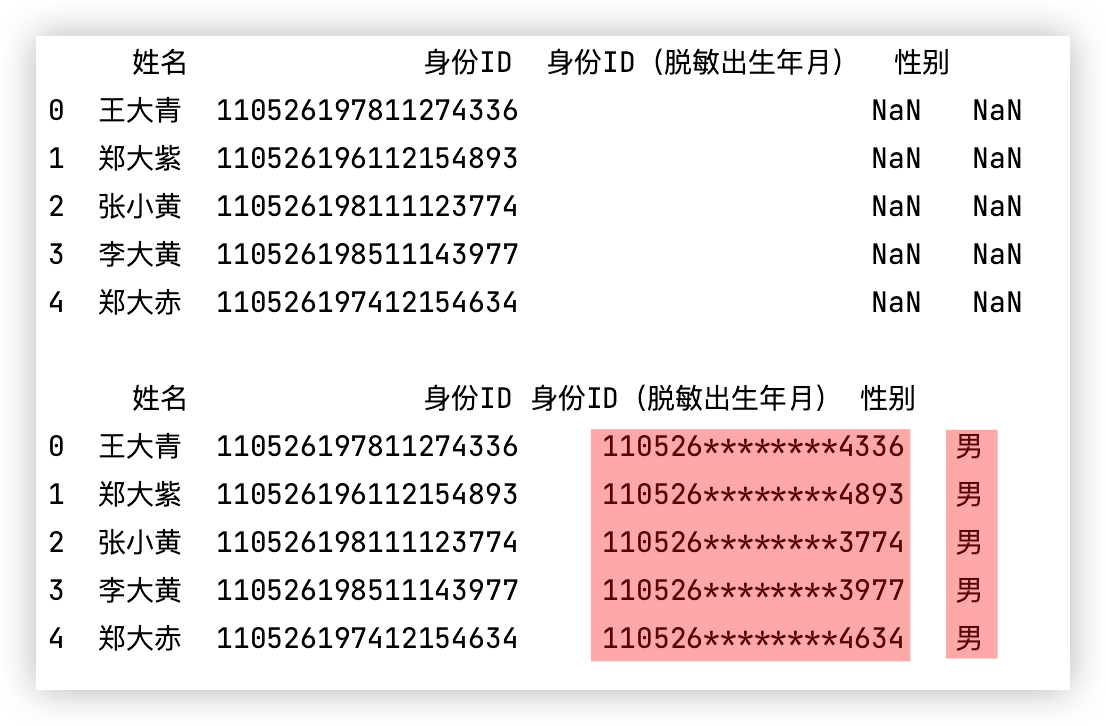
测试代码如下:
import pandas as pd
df = pd.read_excel('身份ID处理-Python版.xlsx').head()
print(df)
# 需求1: 身份证号是数字类型,将其转换成字符串类型,并进行脱敏处理
df['身份ID(脱敏出生年月)'] = df['身份ID'].astype('str').map(lambda x: x.replace(x[6:14], '*' * 8))
# 需求2: 性别填充
df['性别'] = df['身份ID'].astype('str').map(lambda x: "女" if int(x[-2]) % 2 == 0 else "男")
print()
print(df)
2
3
4
5
6
7
8
9
10
11
12
13
# 数据映射
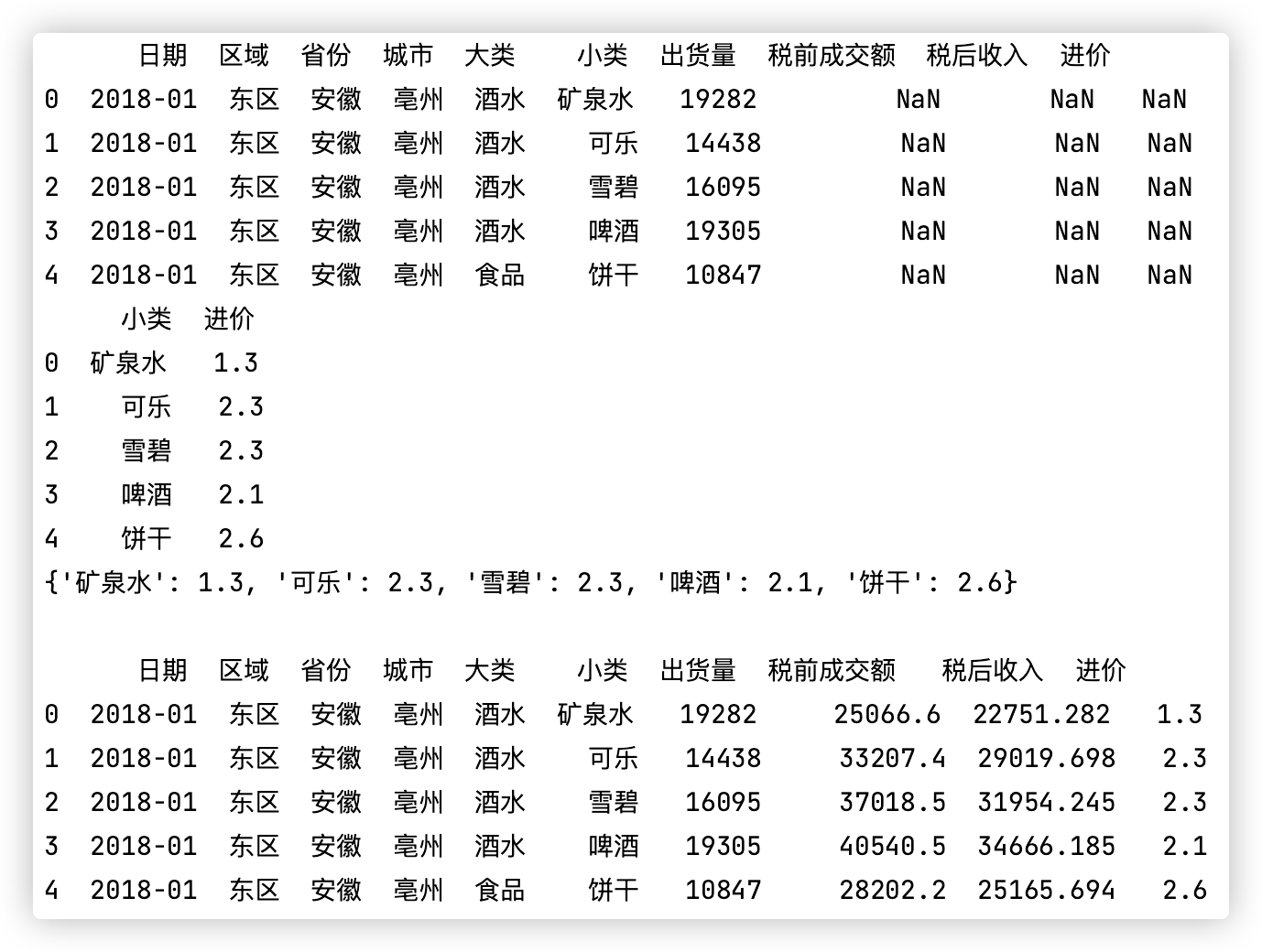
测试代码如下: (该示例是map作映射的典型案例.)
import numpy as np
import pandas as pd
df_data = pd.read_excel('数据映射-Python版.xlsx', sheet_name='源数据').head()
df_price = pd.read_excel('数据映射-Python版.xlsx', sheet_name='进价单').head()
print(df_data)
print(df_price)
dic = {}
for index in df_price.index:
row = df_price.iloc[index] # 降维取第n行,取到series对象
dic[row[0]] = row[1]
print(dic)
df_data['进价'] = df_data['小类'].map(dic) # map作映射
df_data['税前成交额'] = df_data['出货量'] * df_data['进价']
df_data['税后收入'] = df_data['税前成交额'].map(lambda x: x - (x - 15000) * 0.23)
print()
print(df_data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 数学和统计方法
准备测试数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(0, 100, size=(6, 3)),
index=list('ABCDEF'),
columns=['Python', 'Tensorflow', 'Keras'])
df.iloc[0, 1] = None
df.iloc[2, 2] = None
print(df)
"""
Python Tensorflow Keras
A 7 NaN 74.0
B 43 59.0 52.0
C 34 18.0 NaN
D 41 42.0 87.0
E 89 72.0 14.0
F 75 34.0 28.0
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
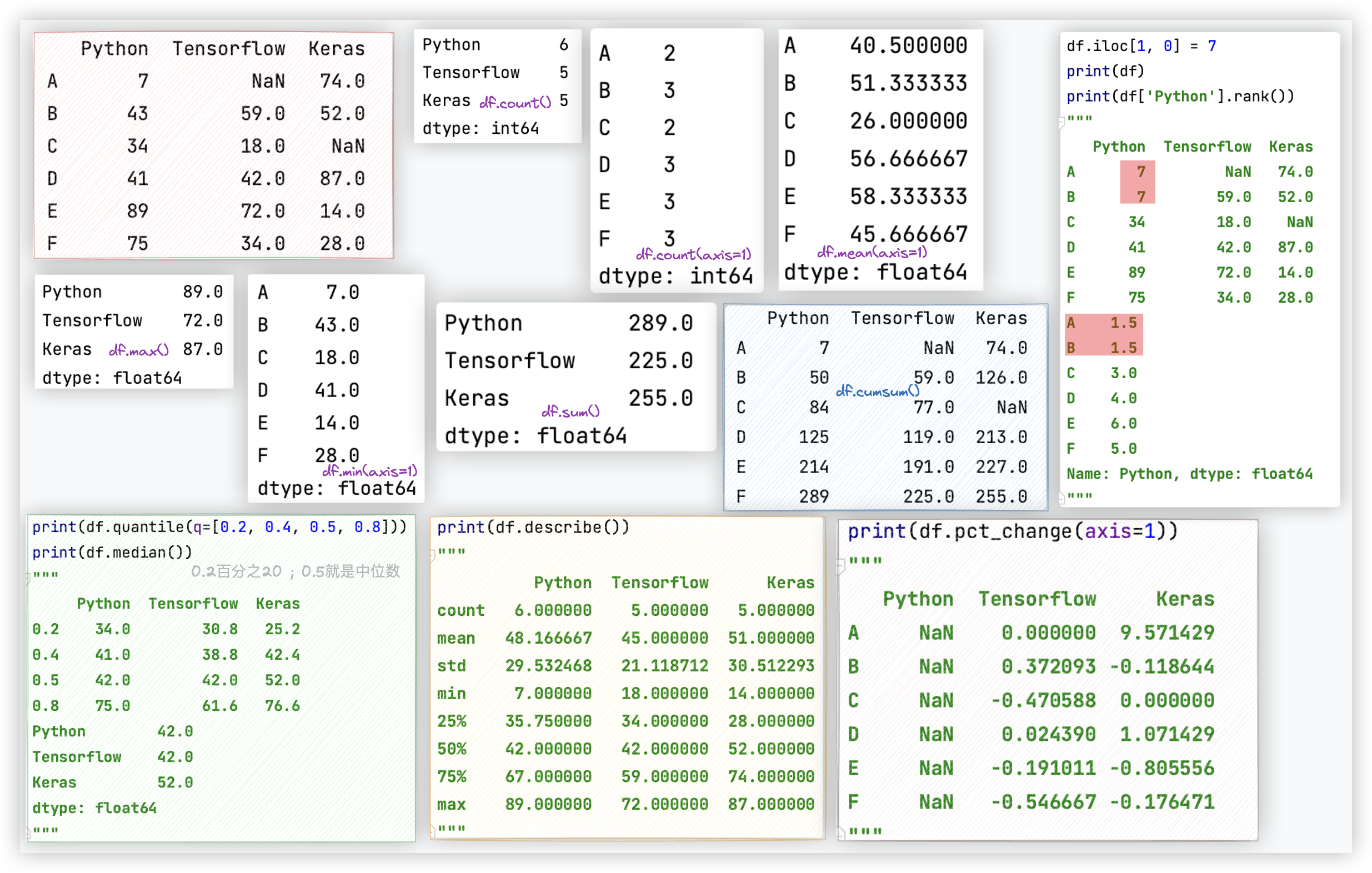
常用方法如下:
| 方法 | 作用 | 参数 | 结果 |
|---|---|---|---|
| df.count() | 沿着 某轴 求非NaN值的数量 | axis 默认为0 | Serise对象 |
| df.max() | 沿着 某轴 求最大值 | axis 默认为0 | Serise对象 |
| df.min() | 沿着 某轴 求最小值 | axis 默认为0 | Serise对象 |
| df.median() | 沿着 某轴 求中位数 | axis 默认为0 | Serise对象 |
| df.sum() | 沿着 某轴 求和 | axis 默认为0 | Serise对象 |
| df.mean() | 沿着 某轴 求平均值 | axis 默认为0 | Serise对象 |
| df.cumsum() | 沿着 某轴 作累加 | axis 默认为0 | DataFrame对象 |
| df.cumprod() | 沿着 某轴 作累乘 | axis 默认为0 | DataFrame对象 |
| df.std() | 沿着 某轴 求标准差 | axis 默认为0 | Serise对象 |
| df.var() | 沿着 某轴 求方差 | axis 默认为0 | Serise对象 |
| df.quantile(q = [0.2,0.4,0.8]) | 沿着 某轴 求分位数 | axis 默认为0 | DataFrame对象 |
| df.describe() | 查看数值型列的汇总统计计数 平均值、标准差、最小值、四分位数、最大值 | 无axis参数! | DataFrame对象 |
| df.pct_change() | 将每个元素与其前一个元素进行比较 并计算前后数值的百分比变化 | axis 默认为0 | DataFrame对象 |
| df.idxmax() | 沿着 某轴 求最大值的索引标签 | axis 默认为0 | Serise对象 |
| df.idxmin() | 沿着 某轴 求最小值的索引标签 | axis 默认为0 | Serise对象 |
| df['Python'].rank() | 对序列中的元素值排名 | Serise对象 | |
| df['Python'].argmin() | 计算最小值位置 | 一个数 | |
| df['Python'].argmax() | 计算最大值位置 | 一个数 |
ps: df['Python'].rank()对序列中的元素值排名,该函数的返回值的也是一个序列,包含了原序列中每个元素值的名次.
如果序列中包含两个相同的的元素值,那么会为其分配两者的平均排名.
# 数据排序
测试截图如下:
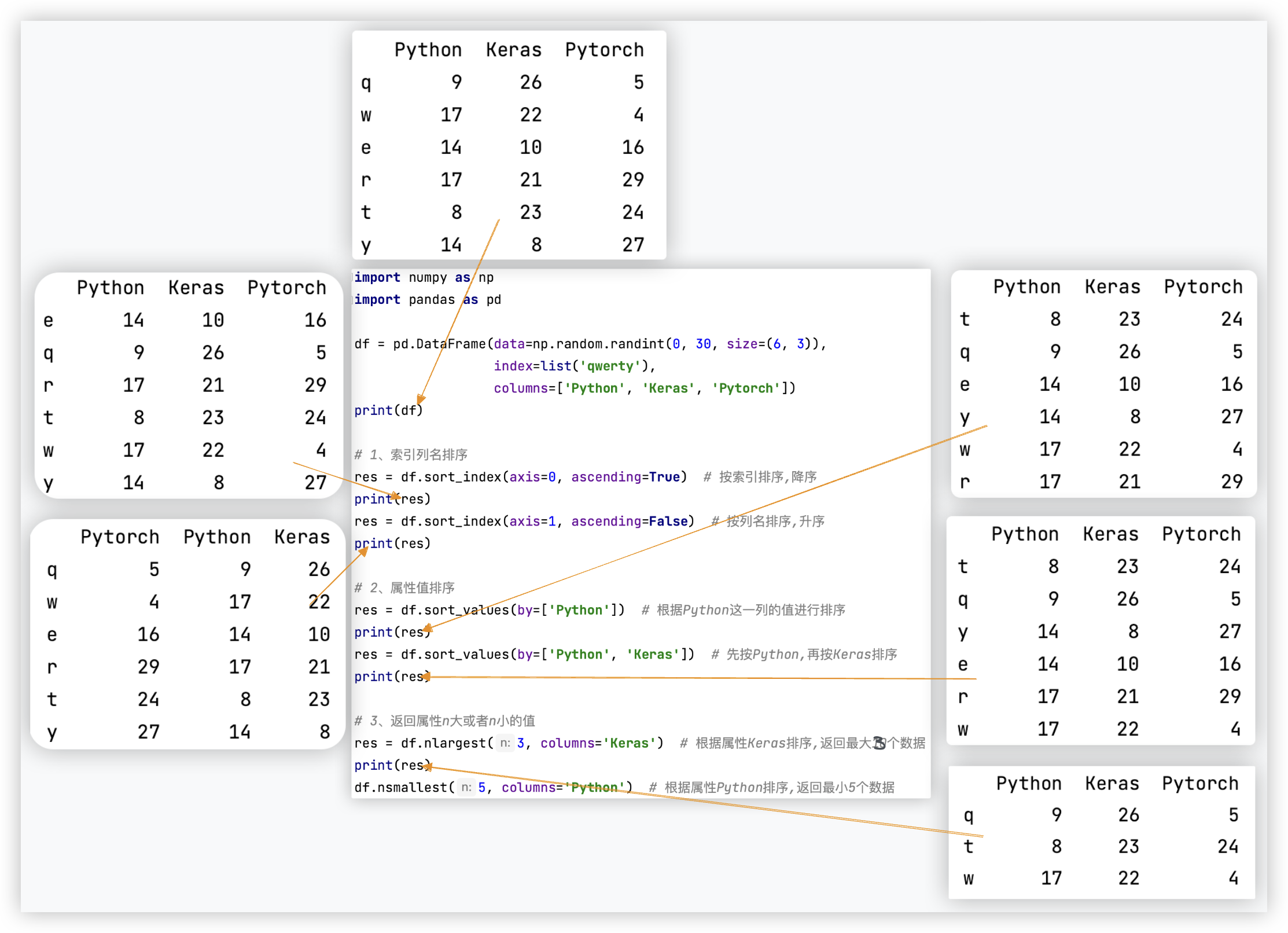
测试代码如下:
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(0, 30, size=(6, 3)),
index=list('qwerty'),
columns=['Python', 'Keras', 'Pytorch'])
print(df)
# 1、索引列名排序
res = df.sort_index(axis=0, ascending=True) # 按索引排序,降序
print(res)
res = df.sort_index(axis=1, ascending=False) # 按列名排序,升序
print(res)
# 2、属性值排序
res = df.sort_values(by=['Python']) # 根据Python这一列的值进行排序
print(res)
res = df.sort_values(by=['Python', 'Keras']) # 先按Python,再按Keras排序
print(res)
# 3、返回属性n大或者n小的值
res = df.nlargest(3, columns='Keras') # 根据属性Keras排序,返回最大10个数据
print(res)
df.nsmallest(5, columns='Python') # 根据属性Python排序,返回最小5个数据
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 分箱操作
在数据分析和机器学习、数据挖掘中都会广泛的使用, 在后续的学习中, 学习了特征工程后就明白了.
数据分箱 (也称为离散分箱或分段) 是一种数据预处理技术.
用于减少次要观察误差的影响, 是一种将多个连续值分组为较少数量的"分箱"的方法.
说白了就是将连续型特征进行离散化!!!
2
3
★ 关键词: 多个 [连续值] 分组, 这些连续值放入较小数量的箱子 (*≧ω≦) 等距比等频用的多.
# 等距分箱
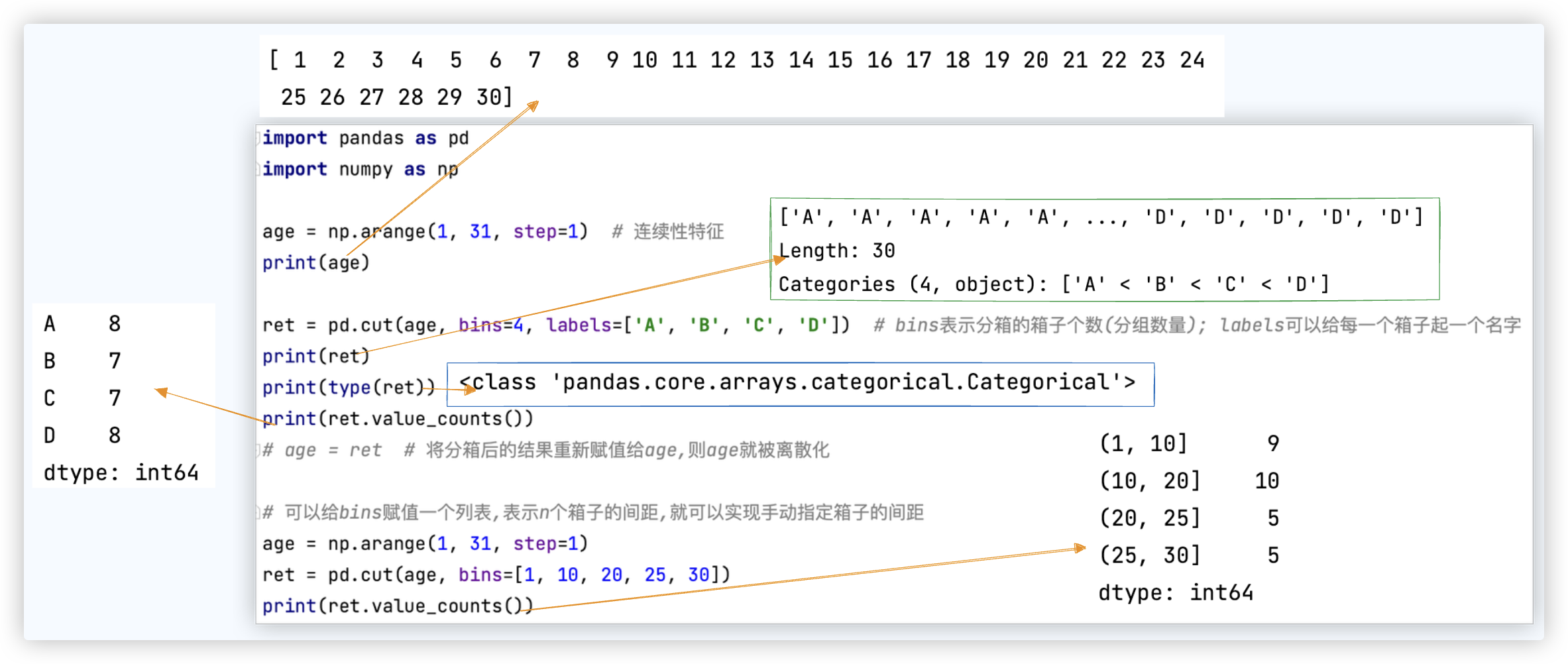
ret.value_counts() 查看每个箱子有多少个元素.
截图中的示例代码如下:
import pandas as pd
import numpy as np
age = np.arange(1, 31, step=1) # 连续性特征
print(age)
# bins表示分箱的箱子个数(分组数量); labels可以给每一个箱子起一个名字
ret = pd.cut(age, bins=4, labels=['A', 'B', 'C', 'D'])
print(ret)
print(type(ret))
print(ret.value_counts())
# age = ret # 将分箱后的结果重新赋值给age,则age就被离散化
# 可以给bins赋值一个列表,表示n个箱子的间距,就可以实现手动指定箱子的间距
age = np.arange(1, 31, step=1)
ret = pd.cut(age, bins=[1, 10, 20, 25, 30])
print(ret.value_counts())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 等频分箱
import pandas as pd
import numpy as np
x = np.random.random(size=(100,))
ret = pd.qcut(x, 4)
print(ret.value_counts())
ret = pd.qcut(x, 4, labels=['A', 'B', 'C', 'D'])
print(ret.value_counts())
"""
(0.010599999999999998, 0.364] 25
(0.364, 0.571] 25
(0.571, 0.78] 25
(0.78, 0.99] 25
dtype: int64
A 25
B 25
C 25
D 25
dtype: int64
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 应用场景
cut和qcut的区别:
-1- cut: 按连续数据的大小分到各个桶里,每个桶里样本量可能不同,但是,每个桶相当于一个等长的区间.
即以数据的最大和最小为边界,等分成p个桶.
-2- qcout: 与cut主要的区别就是每个桶里的样本数量是一定的.
给如下数据中的年龄制定对应的年龄段:
df = DataFrame(data=np.random.randint(10,70,size=(20,)),columns=['年龄'])
pd.cut(df['年龄'],bins=[9,20,40,70],labels=['9-20','20-40','40-70'])
Pandas提供了两种主要的分箱方法:cut和qcut.这一选择取决于数据的特点和分析的需求.
对于偏态分布的数据,由于数据不是均匀分布,而是倾向于在某一端聚集,使用qcut通常更为合适.
这是因为qcut方法会使得每个箱子中的样本数量大致相等,从而可以有效处理偏态分布造成的数据倾斜问题.
2
3
4
5
6
7
# 随机抽样
随机抽样不怎么用.
概念: 给定一组数据, 先随机打乱, 再将其中的局部数据切出来.
df = pd.DataFrame(data=np.random.random(size=(100,4)),columns=['A','B','C','D'])
df.take(indices=np.random.permutation(4),axis=1).take(indices=np.random.permutation(100),axis=0)[0:20]
"""
解释:
np.random.permutation(4) 返回一个0-3的索引
df.take(indices=np.random.permutation(4),axis=1) 将df的列索引打乱,按照np.random.permutation(4)来.
"""
2
3
4
5
6
7
8
# ★ 数据分组
groupby函数主要的作用是进行数据的分组以及分组后地组内运算!!
# 分组+聚合
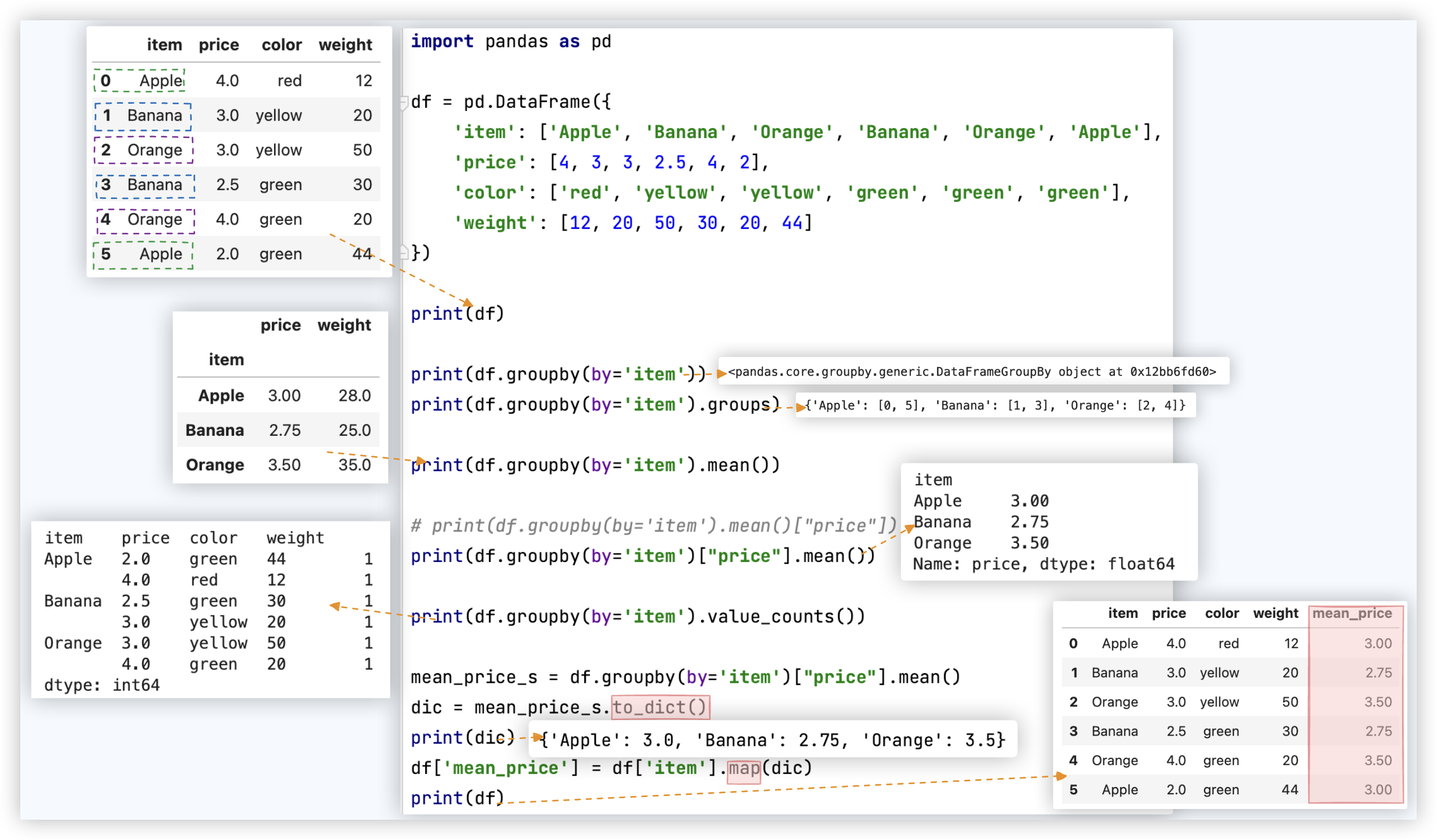
★ 注: 分组后通常都会跟聚合操作, mean聚合操作只会对数值型的数据进行聚合.
mean是聚合操作, values_counts是非聚合操作. 所以 前者的结果中没有color相关数据, 后者的结果中有color相关数据.
截图中的示例代码如下:
import pandas as pd
df = pd.DataFrame({
'item': ['Apple', 'Banana', 'Orange', 'Banana', 'Orange', 'Apple'],
'price': [4, 3, 3, 2.5, 4, 2],
'color': ['red', 'yellow', 'yellow', 'green', 'green', 'green'],
'weight': [12, 20, 50, 30, 20, 44]
})
# 需求:将每种水果的平均价格汇总到源数据中!!
mean_price_s = df.groupby(by='item')["price"].mean() # 注: [['price']]得到的就是一个DataFrame对象
dic = mean_price_s.to_dict()
df['mean_price'] = df['item'].map(dic)
print(df)
2
3
4
5
6
7
8
9
10
11
12
13
14
举一反三, 统计不同颜色水果的最大重量, 将其汇总到新表格中.
color_w_max = df.groupby(by="color")["weight"].max()
dic = color_w_max.to_dict()
df["color_w_max"] = df["color"].map(dic)
print(df)
"""
item price color weight color_w_max
0 Apple 4.0 red 12 12
1 Banana 3.0 yellow 20 50
2 Orange 3.0 yellow 50 50
3 Banana 2.5 green 30 44
4 Orange 4.0 green 20 44
5 Apple 2.0 green 44 44
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
# 分组+transform/apply
★ 我们可以使用自定义一个聚合函数作用于分组结果上.
使用groupby分组后, 也可以使用transform和apply提供自定义函数实现更多的运算
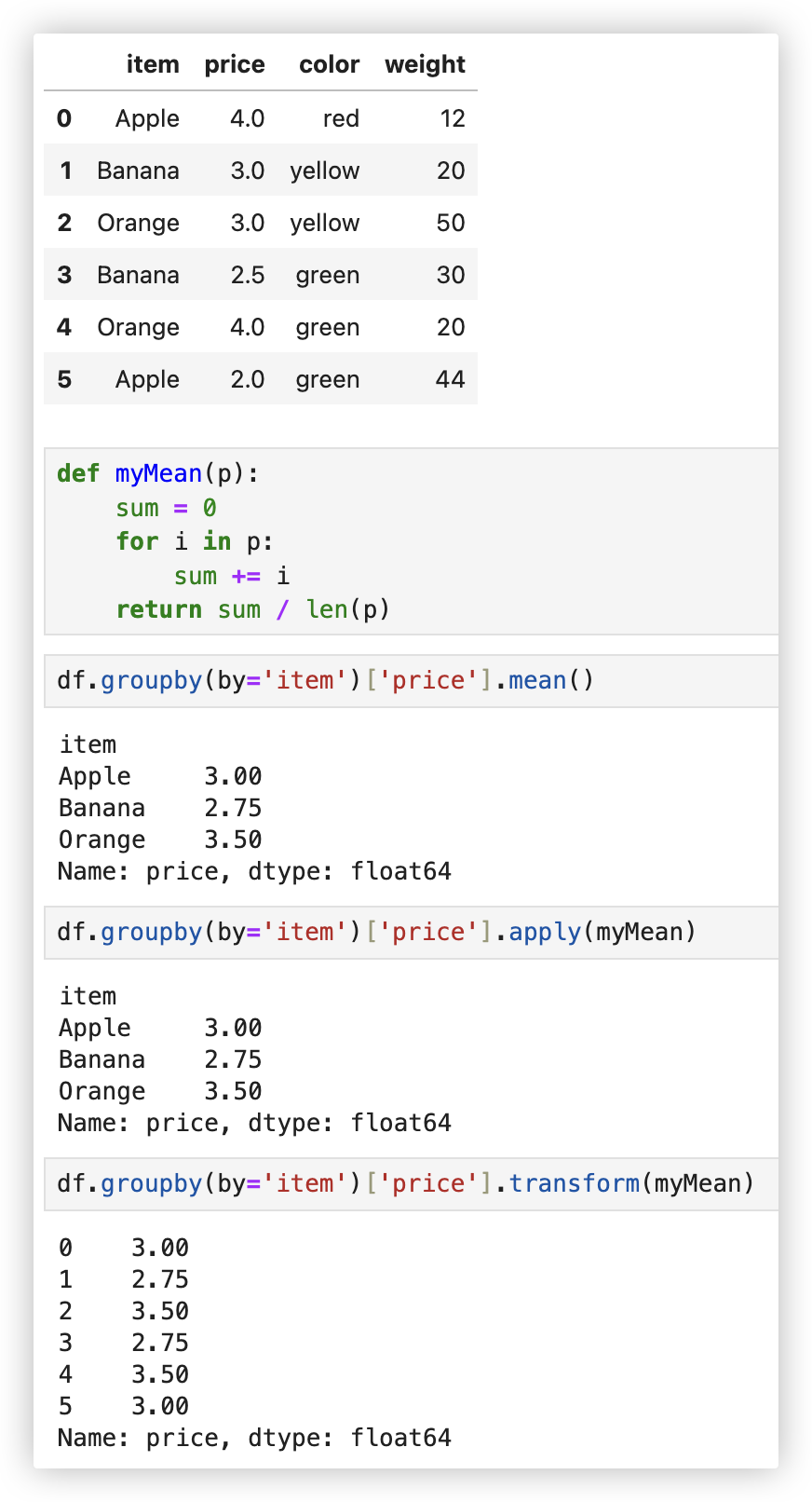
(´・Д・)」 通过截图中的代码,不难看出apply和transform的区别:
-1- transform返回的结果是经过映射后的结果.
-2- apply返回的是没有经过映射的结果
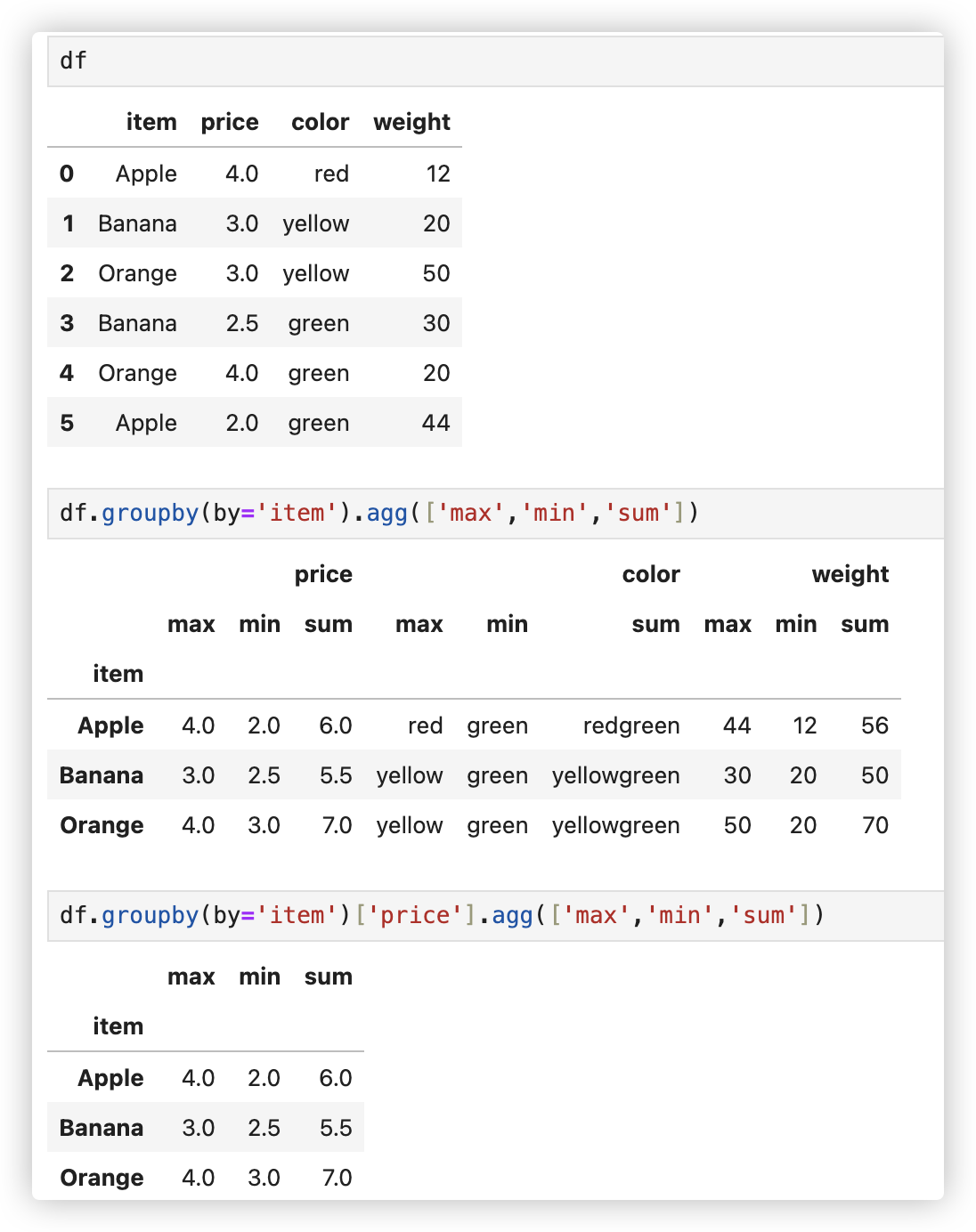
# 分组+agg
agg实现对分组后的结果进行多种不同形式的聚合操作.
df.groupby(by='item').agg(['max','min','sum'])
df.groupby(by='item')['price'].agg(['max','min','sum'])
2
# ★数据透视
示例数据长这样:
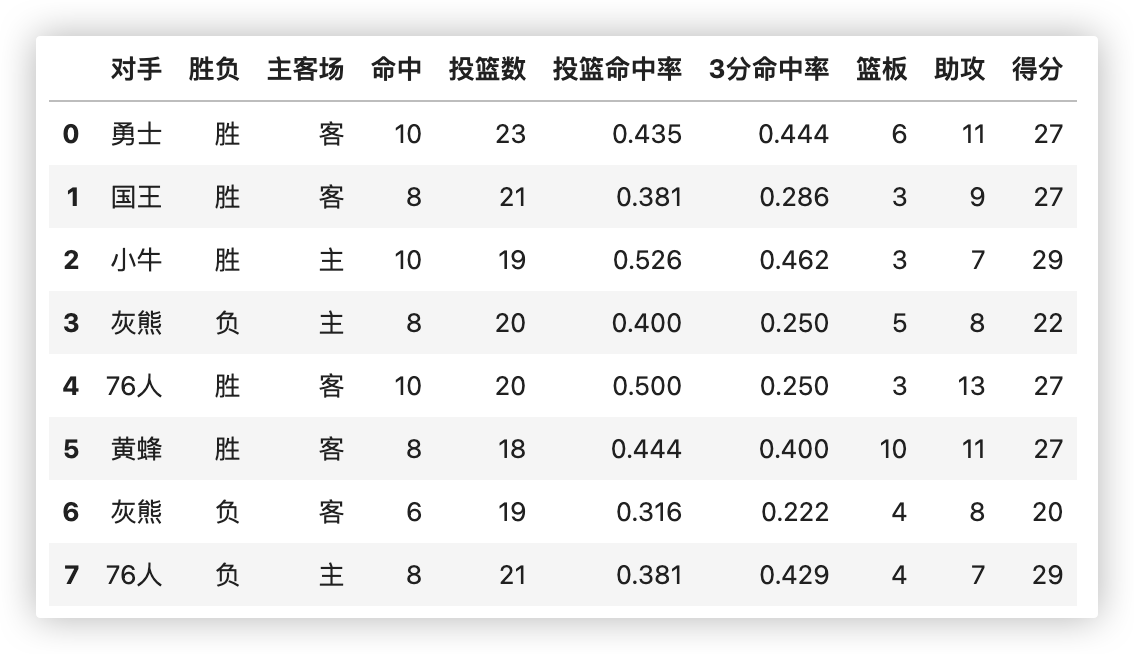
看示例, 示例中很多需求都可以用数据分组来实现!! 结果也是一致的.
import pandas as pd
df = pd.read_csv('./data/透视表-篮球赛.csv').head(8)
# >>> df.groupby(by=["对手"]).mean()
# index参数: 分类汇总的分类条件
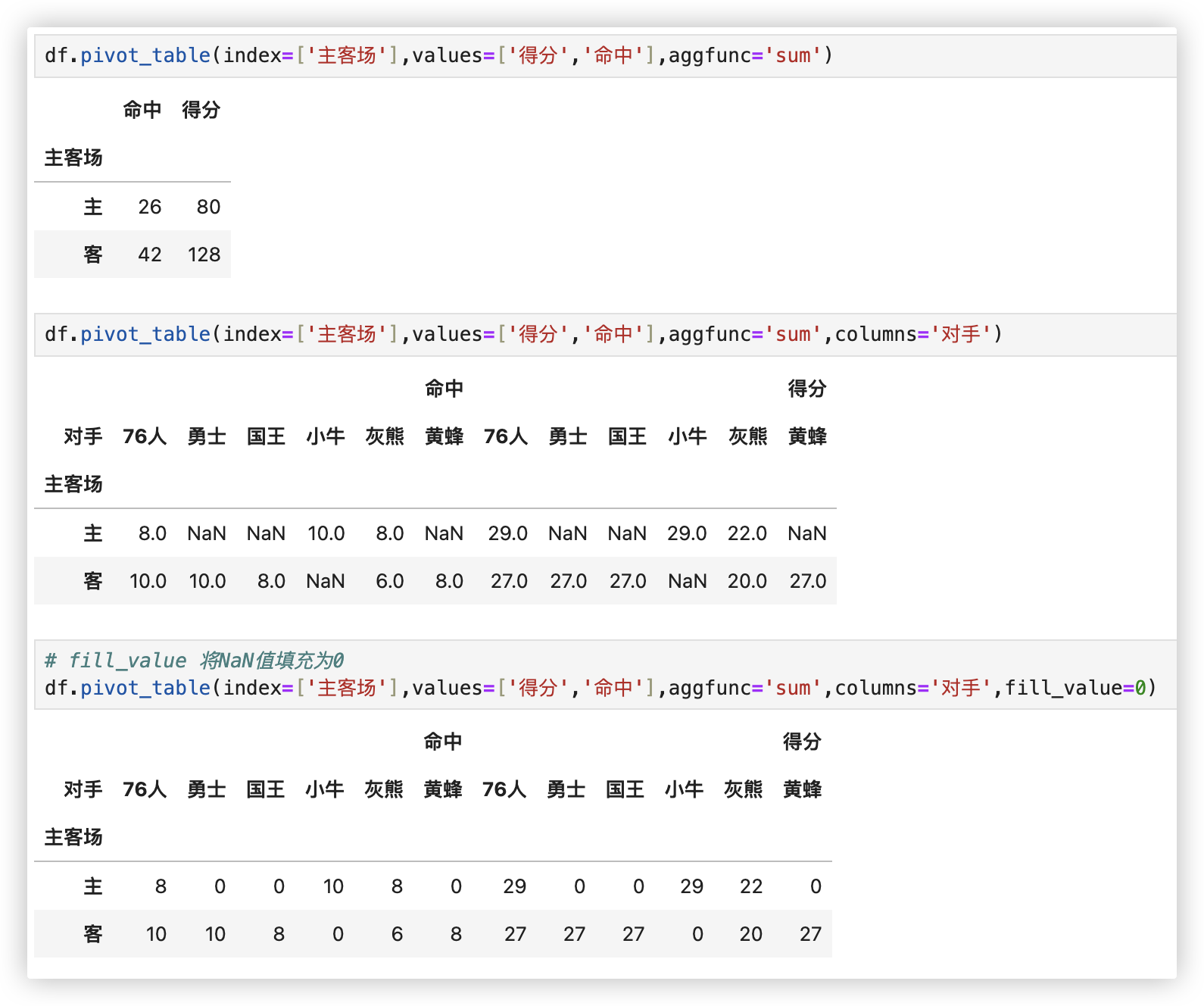
df.pivot_table(index=['对手'])
# >>> df.groupby(by=["对手","主客场"]).mean() -- 可理解, 勇士+客为一个分组、勇士+主为一个分组
df.pivot_table(index=['对手','主客场'])
# >>> df.groupby(by=['主客场','胜负'])[['得分','篮板','助攻']].mean()
# values参数: 需要对计算的数据进行筛选
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'])
# Aggfunc参数: 设置我们对数据聚合时进行的函数操作,默认aggfunc='mean'计算均值
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'],aggfunc='mean')
# >>> df.groupby(by=['主客场','胜负']).agg({'得分':'sum','篮板':'max'})
df.pivot_table(index=['主客场','胜负'],aggfunc={'得分':'sum','篮板':'max'})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注: Columns参数: 可以设置列层次字段, 感觉像是一种分割数据的可选方式..
# 项目案例
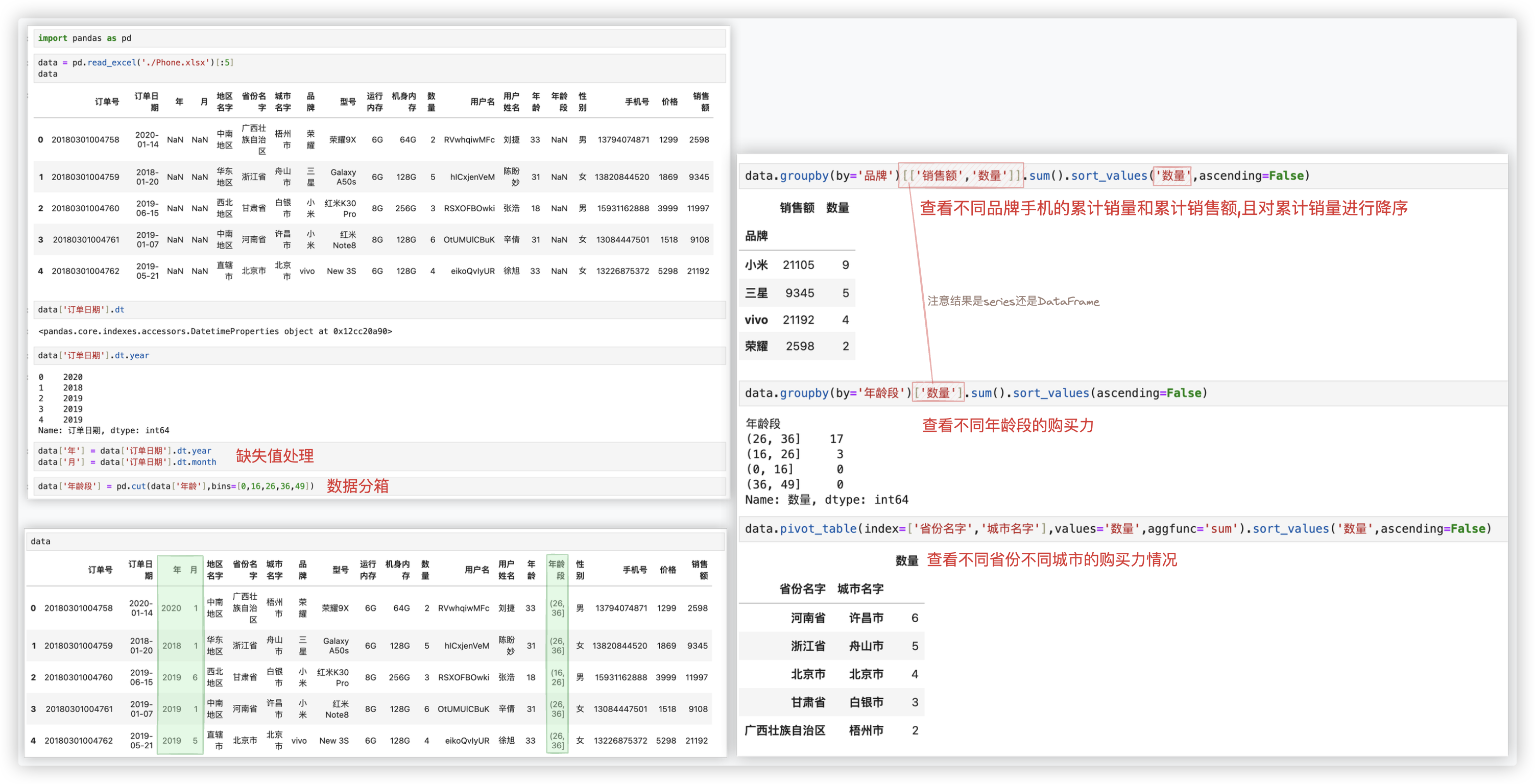
示例代码如下:
import pandas as pd
data = pd.read_excel('./Phone.xlsx')[:5]
data
data['订单日期'].dt
data['订单日期'].dt.year
data['年'] = data['订单日期'].dt.year
data['月'] = data['订单日期'].dt.month
data['年龄段'] = pd.cut(data['年龄'],bins=[0,16,26,36,49])
data
data.groupby(by='品牌')[['销售额','数量']].sum().sort_values('数量',ascending=False)
data.groupby(by='年龄段')['数量'].sum().sort_values(ascending=False)
data.pivot_table(index=['省份名字','城市名字'],values='数量',aggfunc='sum').sort_values('数量',ascending=False)
2
3
4
5
6
7
8
9
10
11
12
13
14