pandas时间序列
pandas时间序列
时间序列用的比较少, 但有些场景下使用它会有妙用. (*≧ω≦)
时间序列包含三种应用场景, 分别是:
| 时间类型 | Python中的类型 |
|---|---|
| 时间范围 | DatetimeIndex |
| 时期 | period |
| 时期范围 | PeriodIndex |
# 时间范围
# date_range()
通过 date_range() 方法可以创建固定间隔的时间的时间段. 有四个参数:
1> start: 开始时间.
2> end: 结束时间.
3> freq: 时间频率. 默认为 "D"(天).
4> periods:表示产生多少个日期索引值.
>>> import pandas as pd
>>> # 每30min变化一次
>>> pd.date_range("9:00", "18:10", freq="30min")
DatetimeIndex(['2024-08-16 09:00:00', '2024-08-16 09:30:00',
'2024-08-16 10:00:00', '2024-08-16 10:30:00',
'2024-08-16 11:00:00', '2024-08-16 11:30:00',
'2024-08-16 12:00:00', '2024-08-16 12:30:00',
'2024-08-16 13:00:00', '2024-08-16 13:30:00',
'2024-08-16 14:00:00', '2024-08-16 14:30:00',
'2024-08-16 15:00:00', '2024-08-16 15:30:00',
'2024-08-16 16:00:00', '2024-08-16 16:30:00',
'2024-08-16 17:00:00', '2024-08-16 17:30:00',
'2024-08-16 18:00:00'],
dtype='datetime64[ns]', freq='30min')
>>> # 每1h变化一次
>>> pd.date_range("6:10", "11:45", freq="h")
DatetimeIndex(['2024-08-16 06:10:00', '2024-08-16 07:10:00',
'2024-08-16 08:10:00', '2024-08-16 09:10:00',
'2024-08-16 10:10:00', '2024-08-16 11:10:00'],
dtype='datetime64[ns]', freq='h')
>>> # 若配合periods参数使用则不能有end结束时间
>>> pd.date_range("2010-01-10",freq='W',periods=5)
DatetimeIndex(['2010-01-10', '2010-01-17', '2010-01-24', '2010-01-31',
'2010-02-07'],
dtype='datetime64[ns]', freq='W-SUN')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# to_datetime()
可以使用 to_datetime() 函数将 series或者字符串 转换为日期对象/时间戳。
import pandas as pd
s1 = pd.Series(['Jun 3, 2020', '2020-12-10', None])
s1_converted = pd.to_datetime(s1, errors='coerce') # 进行时间处理
print(s1_converted)
"""
pd.to_datetime(s1, errors='coerce'):
这个方法会自动识别 Series 中的不同日期格式并进行转换.
参数 errors='coerce' 表示如果遇到无法解析的日期,将其转换为 NaT(缺失值).
0 2020-06-03
1 2020-12-10
2 NaT
dtype: datetime64[ns]
"""
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 时期 Period
import pandas as pd
# ★ 这个Period对象表示的是从2023年1月1日到2023年12月31日之间的整段时间
x = pd.Period('2023', freq='A')
print(x) # 2023
# 时期运算,就表示时期的频率freq运算
print(x + 3) # 2026
y = pd.Period('2023', freq='M')
print(y) # 2023-01
print(y + 3) # 2023-04
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 时期范围 period_range
import pandas as pd
import numpy as np
# 1> period_range函数可用于创建规则的时期范围
rng = pd.period_range('2010-1-1', '2010-6-30', freq='M')
# PeriodIndex(['2010-01', '2010-02', '2010-03', '2010-04', '2010-05', '2010-06'], dtype='period[M]')
print(rng) # 返回了PeriodIndex,其内部保存了一组Period
# 2> ★ PeriodIndex可以直接作为pandas中的索引被使用
ped = pd.Series(np.random.randn(len(rng)), index=rng)
"""
2010-01 -2.053321
2010-02 -0.384279
2010-03 0.468803
2010-04 0.174967
2010-05 0.408989
2010-06 -0.369708
Freq: M, dtype: float64
"""
print(ped)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 应用案例 resample分组
Pandas中的resample (重新采样), 是一个时间序列数据重新采样和频率转换的便捷的方法.
需要注意的是, 数据必须具有DatetimeIndex 或 PeriodIndex的索引.
在前面pandas基本操作一文的 股票分析案例中也用到啦!
# 案例一
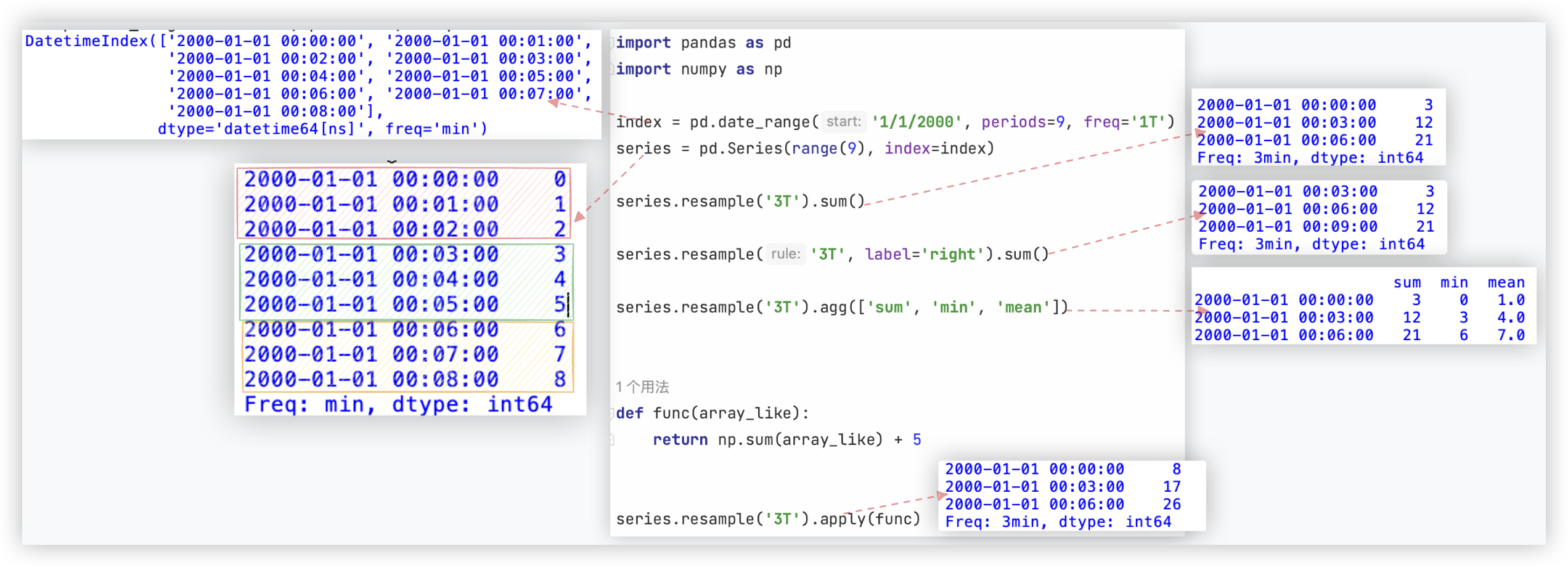
示例测试代码如下:
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=9, freq='1T') # 生成一组时间序列数据,频率为T(1分钟)
series = pd.Series(range(9), index=index)
series.resample('3T').sum() # 获得每3分钟一组的数据,组内数据的累加和
# 使用label参数设置聚合值的标签为每组采样数据的左/右标签
# 例如.00:00:00-00:03:00 left会被标记成00:00:00,right会被标记成00:03:00
series.resample('3T', label='right').sum()
series.resample('3T').agg(['sum', 'min', 'mean']) # 对采样后的数据进行多种不同形式的聚合:agg函数
# 自定义采样后的聚合函数
def func(array_like):
return np.sum(array_like) + 5
series.resample('3T').apply(func)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 案例二
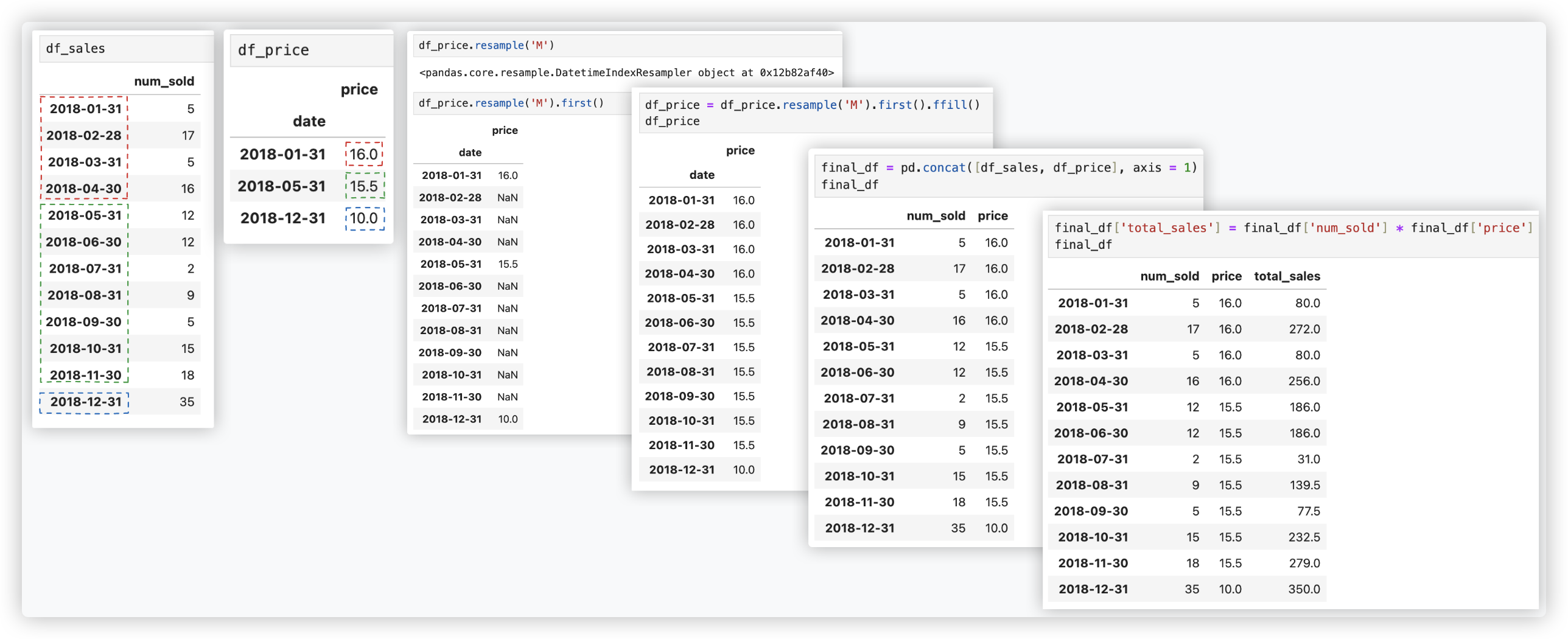
有两个数据集, 一个是月销销量df_sales, 另一个是价格df_price.
df_price中存储的是有关于价格变化的记录 (1月份单价为16, 一直到5月份单价变为15.5, 再到12月份再次修改为10)
我想计算一下每个月的销售总额.
# 创建数据集
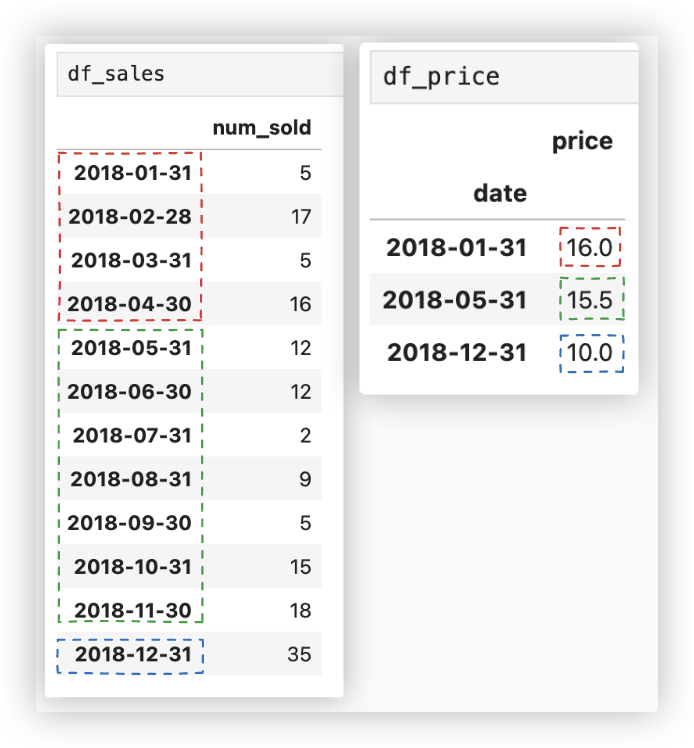
import pandas as pd
import numpy as np
# 月销销量df_sales -- 索引为时间序列
df_sales = pd.DataFrame(
data=[5, 17, 5, 16, 12, 12, 2, 9, 5, 15, 18, 35],
index=pd.date_range('2018-01-31', '2018-12-31', freq='M'),
columns=['num_sold']
)
# 需要将date转换为时间序列然后再作为数据的行索引
df_price = pd.DataFrame(
data=[['2018-01-31', 16.0], ['2018-05-31', 15.5], ['2018-12-31', 10.0]],
columns=['date', 'price']
)
df_price['date'] = pd.to_datetime(df_price['date']) # 将日期列转换为日期类型,便于时间类型数据的运算
df_price = df_price.set_index('date') # 将date列作为原数据的行索引,不用默认的0 1 2.
print(df_sales)
print(df_price)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 方案一
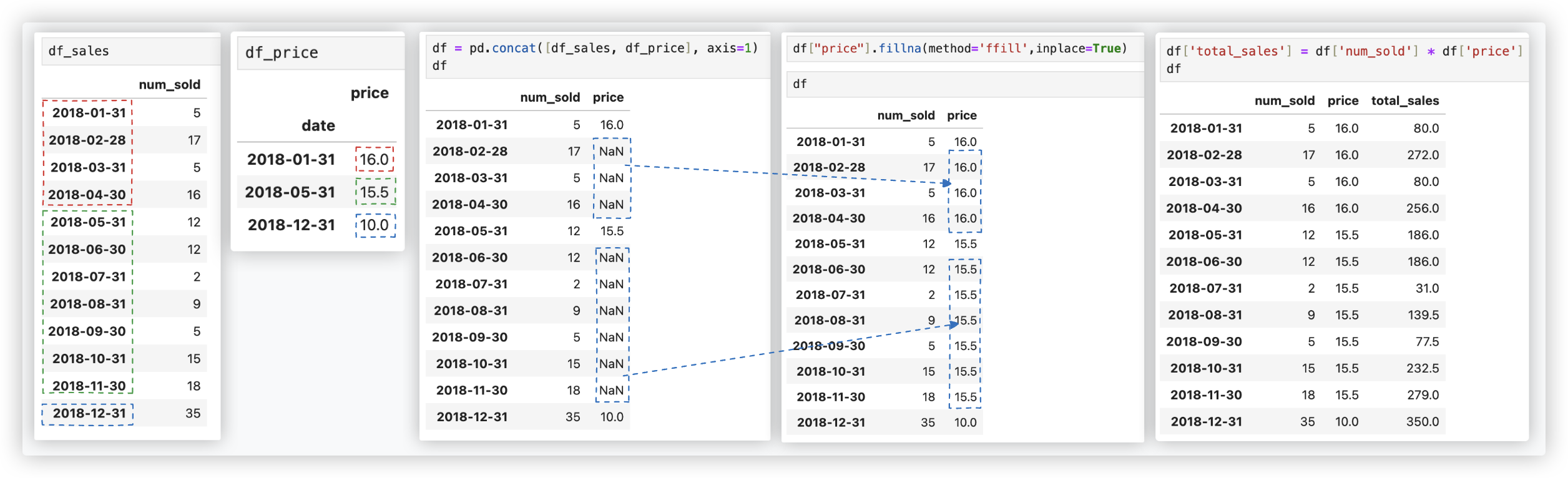
# 方案二
通过调用resample('M')来按月重新采样给定的时间序列, 在此之后, 调用ffill()来转发填充值.