 源码知识点
源码知识点
该篇博文归纳在剖析源码过程中, 遇到的/需掌握的 py知识点.
我想做减法来着, 结果发现总结的过程中一边减也在一边增加(¯﹃¯)
# ☆ 源码py知识点
一定一定要理清楚self到底是谁!!
我们现阶段旨在学习py知识点, 不用特别深究为何这样设计, 等项目经验多了, 再学习设计模式, 回头来看应该会有不一样的体会!
- 一般是 import 模块 ; from xx.xx.模块 import 模块中的成员
若是 import 包 我们可以在__init__.py文件中将本模块的所有文件都导入,在外部直接导入包就相当于导入了其中定义的所以 文件/模块
- 属性查找规则 self-父类-..-object
变量查找规则 作用域LEGB依次找 <不同的作用域相同的变量名不会引起冲突>
- 类方法、实例方法 前者自动传值cls,后者自动传值self;实例可调用类方法,自动传cls、类调用实例方法,需手动传self
- 静态方法就是一普通函数
- 闭包 函数嵌套,内部函数引用外部函数的变量,并将内部函数返回
- super(不写就是当前类,谁的继承链self/cls).__init__() super是会自动传值的
简而言之,super不一定就是父类,而是要看里面的self是谁. super(xxx, self)一定是type(self)对应的mro中, xxx的下一个类.
- 反射
通过字符串动态获取对象的类型、属性和方法等信息 getattr、setattr 写的是字符串,可设置默认值
- 形参 **args接收额外的位置参数并以元祖的形式给args;**kwargs接收额外的关键字参数并以字典的形式给kwargs
形参 位置形参 eg: def func1(a):pass 可以func1(1)或func1(a=1)
- 类实例化时 会自动调用 __init__
- 封装 就是在前面加"__",eg: 类变量__country,__init__里的实例属性self.__name,实例方法__run
效果: 在类内部这些否可以相互调用,但在外面 类.它们 实例.它们 皆会报错.
场景:
关于封装好的实例属性,比如外部想修改它,可以提供一个接口让使用者间接修改,对修改进行一点限制.
关于封装好的实例方法,以取款为例,使用者只需知道取款接口即可,取款这个接口里 会依次调用封装好的 插卡、输入密码、输入取款金额等.
- oop的继承,属性查找顺序 实例自身-实例所在的类-父类--直到object
- 多态 抽象类可约束 多个类中名字相同的函数
- 组合 将A实例作为B实例的一个属性 、在B实例所在类的__init__方法中实现
- 对象.属性 或者 getattr(对象,"属性") 时
"自动"调用__getattribute__,该方法会按照属性查找顺序找,找到就返回,没找到的话会抛出AttributeError的异常
若未在__getattribute__内主动捕获该错误,后续该异常后续会"自动"触发__getattr__函数的执行!!当然,主动捕获了就不触发了呗.
注意:"主动"调用__getattribute__,抛出的异常后不会有__getattr__函数兜底.
- __setattr__()
在对类实例化对象的属性进行 赋值/修改 实例.属性=值 时,首先会调用该方法
在该方法中会默认将属性名和属性值添加到实例的 __dict__ 属性中
- raise向上抛出异常
- @property 将方法变成属性,不加括号就能被调用!
@property装饰user方法 >> 调用时自动执行;
"★"细品一个巧妙的设计!相当于把结果存储了起来,第二次调用request.user时,直接取就好! 这种方式的学名: "延迟加载"!!
@user.setter装饰user方法 >> 赋值时自动执行 -- self.user, self.auth = user_auth_tuple
- 这个关乎源码中不进行认证、不进行权限的情况时,对源码的剖析理解!!
my_list = [] # -- 1
for i in my_list: # -- 2
print(i)
print("Hello") # -- 3
- "★" 若很多视图类都需要重写某方法来自定义或逻辑, 那么可以通过继承来简化代码!!
- for-else else子句在for循环正常完成时执行
- ※ 元类
- 实例.__dict__ 类.__dict__ 分别得到的是实例和类的属性字典, 里面的值都可通过 self. 的方式进行获取!
- type(obj) 找到obj的直接父类
isinstance(obj,cls) 检查obj是否是 类cls或类cls的子类 的一个实例, 是, 则返回True;
issubclass(sub,super) 检查sub类是否是 super类的 子类, 是, 则返回True.
- is和==的区别, is在判断两个对象的id是否相同
- 代码从上往下执行,遇到class关键字类定义代码,类中的代码在类定义阶段就会执行.
<了解即可>
※ 解释器具有退化功能, 会优先寻找某个方法, 但如果没有, 那么会退化寻找替代方法.
eg: Python的for循环本质上会调用内部的`__iter__`, 但如果内部没有定义, 那么解释器会退化寻找`__getitem__`..
def func1(*args, **kwargs): # 不定长关键字形参接受多余的关键字实参 kwargs是字典-->{'id':2,'age':20}
return func2(*args, **kwargs) # **kwargs拆包-->id=2,age=20
def func2(id, **kwargs):
return id, kwargs
res = func1(id=2, age=20)
print(res) # (2, {'age': 20})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 痛的领悟
内心OS: 下午的时候, 我独自一人坐在客厅沙发上, 发呆似的, 回顾整个drf源码流程, 就突然感觉某某设计很奇妙, 就继承而言, 我一直是大抵知道这个东西的, 但在沙发上回顾时, 似乎对 继承 就有了不一样的理解和顿悟. 飘忽不定的一种感觉吧. 于是乎, 我走进了书房, 想抓它们, 所以有了 "痛的领悟".
- 路由层那, UserInfo.as_view() 本质跟 "装饰器语法糖"是一样的.
- UserInfo继承APIView, APIView里放了好多好多的 功能(方法) - 继承基类的方法,并且做出自己的改变或者扩展(代码重用)
"你可以想象,UserInfo可以直接把这些方法全部拿过来放到自己类里,就不用再继承APIView了." - 属性查找的规则
- 二次封装的request 新的旧的都可以用,新的里面没有就用旧的 组合 + __getattr__ 来实现 - 江湖人称作:"伪装术"
- drf 认证组件的入口 代码 `request.user` - 背后的技术 "@property+延迟加载"
2
3
4
5
# 常见的魔法方法
# 构建及初始化
| 魔法方法 | 作用 |
|---|---|
__new__ | 创建实例化对象, 该方法的第一个参数传递过来的实例一般是 类! |
__init__ | 为实例定制独有的特征. |
__del__ | 析构函数, 当一个实例对象被销毁之后会调用该函数. 如果没有销毁, 那么程序结束时也会调用. |
class Girl:
# 创建Girl的实例,So,cls是Girl
def __new__(cls, *args):
print("__new__")
return object.__new__(cls)
def __init__(self):
print("__init__")
def __del__(self):
print("__del__")
Girl()
"""
__new__
__init__
__del__
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 序列操作
可以让我像操作字典一样, 操作实例对象
class Test:
def __getitem__(self, item):
print(item)
def __setitem__(self, key, value):
print(key, value)
def __delitem__(self, key):
print(key)
t = Test()
t["xx"] # xx
t["xx"] = 20 # xx 20
del t["xx"] # xx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 属性访问
| 魔法方法 | 作用 |
|---|---|
__getattribute__ | 类的实例对象.属性 时, 会触发它, 按照属性查找顺序找 |
__getattr__ | 类的实例对象.属性 按照属性查找规则都找不到时, 触发它! |
__setattr__ | 类的实例对象.属性 = 值 进行赋值(增加/修改)时, 触发它! |
__delattr__ | def obj.attr 时, 触发它 |
class A:
def __getattr__(self, item):
print("__getattr__ >>", item)
def __setattr__(self, key, value):
print(key, value)
"""注:
-- 错误的方式.
反射setattr的本质是 self.key = value
所以会递归的调用魔法方法__setattr__
-- 正确的方式一: 通过操作属性字典!
self.__dict__[key] = value
-- 正确的方式二: 在子类派生出来的功能中重用父类功能,下面两个皆可
1> 类来调用对象的绑定方法,有几个值就传几个值
A.__setattr__(self, key, value)
2> super()
super().__setattr__(key, value)
"""
def __delattr__(self, item):
print(item)
def __getattribute__(self, item):
print("__getattribute__ >>", item)
return super().__getattribute__(item)
a = A()
a.name
a.name = "夏色祭"
del a.age
"""
__getattribute__ >> name
__getattr__ >> name
name 夏色祭
age
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 对象显示
__str__ 在对象self被打印时,自动触发 在顶级父类object中有__str__方法,返回的是self的内存地址
# @property & 描述符
需求: 我想限制用户对属性的操作行为. 比如:年龄不能输入负数.
原先 >> 用户通过 `self.age` `self.age = 10` 可直接进行取值和赋值.
方式一: [封装age属性 -- __age] + [暴露两个方法用于取值和赋值] >> 改变了用户原来的取值和赋值的方式
方式二: [封装age属性 -- __age] + @property
- 用户的取值和赋值方式未改变
- 但 类中有n个这样的属性,就要写2n个方法,类会变得很臃肿!需要进行解耦操作.
方式三: 描述符
你可以再细想下.
方式一不封装,暴露的两方法压根没用,就跟没改变一样;
方式二不封装,你在@property装饰的age方法里 return self.age, 不就无限递归了嘛!也不得劲.
PS: 封装属性只是语法上的变形,只要不是故意找事,就不碍事.
2
3
4
5
6
7
8
9
10
11
先来看一个例子:
class People:
def __init__(self):
self.age = 3
if __name__ == '__main__':
dc = People()
print(dc.age) # 3
dc.age = 100
print(dc.age) # 100
dc.age = -10
print(dc.age) # -10
2
3
4
5
6
7
8
9
10
11
12
类 People 的实例 dc 有一个实例属性 age , 表示实例的年龄, 我们可以任意设置其年龄, 即使有些数字根本就不合理.
这就是我们这篇文章要解决的问题, 如何在不改变操作习惯的前提下限制对属性的合理赋值范围?, 例如年龄age不能为负值!
# 封装+暴露方法
既然要限制用户对属性操作的行为, 一般我们都会想到 封装该属性 , 然后暴露两个方法分别用于赋值和取值 给用户.
用户通过这两个方法间接的对封装好的属性进行操作, 我们在暴露的方法中实现对用户操作的限制!
★ 何为封? 属性对外是隐藏的, 对内是开放的.
class People:
def __init__(self):
self.__age = 3
def set_age(self, value):
if value >= 0:
self.__age = value
else:
print('Age can not be negative value')
def get_age(self):
return self.__age
if __name__ == '__main__':
dc = People()
print(dc.get_age()) # 3
dc.set_age(-10) # Age can not be negative value
print(dc.get_age()) # 3
dc.set_age(10)
print(dc.get_age()) # 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
咦, 看样子我们已经完美解决了这个问题. No,no,no. 远远不够.
第一点: 改变了用户操作习惯 需要格外记住两个方法来 取值和赋值.
第二点: 大家都知道 python的封装是个笑话, 只是 变换了属性名/语法上的变形操作 曲线救国罢了.
print(dc.__dict__) # {'_People__age': 10}
print(dc._People__age) # 10
dc._People__age = -20
print(dc._People__age) # -20
2
3
4
根据测试结果, 可以看出, 可以直接对变形的属性名进行操作, 暴露的两个方法压根没有用.
# 封装+@property
通过 @property 装饰器将其中一个方法变成了属性, 方法的名字变成了属性可以被直接访问.
还对一个同样名字的方法用装饰器变成了setter, 当向该属性赋值的时候会调用该方法.
class People:
def __init__(self):
self.__age = 3
@property
def age(self):
return self.__age
@age.setter
def age(self, value):
if value >= 0:
self.__age = value
else:
print('Age can not be negative value')
if __name__ == '__main__':
dc = People()
print(dc.age) # 3
dc.age = -10 # Age can not be negative value
print(dc.age) # 3
dc.age = 100
print(dc.age) # 100
print(dc.__dict__) # {'_People__age': 100}
print(dc._People__age) # 100
dc._People__age = -20
print(dc._People__age, dc.age) # -20 -20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
通过打印的结果看, 恢复了原先的属性的调用方式, 而不再是两个难记的方法.
所以, 使用 @property装饰器 后能很好的解决 前面那个方式的 第一点 的弊端. 用户的操作习惯是没有改变的. (*≧ω≦)
尽管用户还是可以通过__dict__查看到真正的属性, 但是只要不是有人故意找事, @property 的方式已经比较优雅啦!
对于我们开发者而言, 通过对两个方法添加装饰器来达到对外地统一接口, 使用起来很舒服.
但假设有10个这种属性, 就得创造20个这种方法, 这么臃肿的一个类想想就很头疼.
如何是好? 必须得把这两种方法单独提出来, 去耦合!
# 描述符
描述符到底是什么? 先来看一个示例简单了解下!
class Descriptor:
def __get__(self, instance, owner):
print("__get__", instance, owner)
def __set__(self, instance, value):
print("__set__", instance, value)
class Cls:
age = Descriptor()
def __init__(self, name, age):
self.name = name
self.age = age
if __name__ == '__main__':
c = Cls("dc", 16) # __set__ <__main__.Cls object at 0x10d770fa0> 16
print(c.__dict__) # {'name': 'dc'}
c.age # __get__ <__main__.Cls object at 0x10d770fa0> <class '__main__.Cls'>
c.age = 10 # __set__ <__main__.Cls object at 0x10d02afa0> 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
一个类中, 只要出现了__get__ 或者 __set__ 方法, 就被称之为描述符. 上述程序中, Descriptor类就是描述符!
age = Descriptor() age是描述符的实例,也可以说age属性被描述符给代理啦.
具体体现在,c.__dict__ 中没有age,证明执行self.age = age语句时,并没有把值设置到 self 的属性字典里面.
而是执行了描述符的 __set__ 方法,参数 instance 是调用的实例对象, 也就是我们这里的 c.
c.age 根据打印结果可以看到,由于 age 属性被代理了, 那么获取的时候, 会触发描述符的 __get__ 方法.
c.age = 10 同理, 会触发描述符的 __set__ 方法!
至此, 描述符最基本的使用我们就掌握了, 那么 如何实现 年龄输入不能为付数呢? 看下面的程序!
class Descriptor:
def __init__(self, key):
self.key = key
def __get__(self, instance, owner):
# print("__get__", instance, owner)
return instance.__dict__[self.key]
def __set__(self, instance, value):
# print("__set__", instance, value)
if value >= 0:
instance.__dict__[self.key] = value
else:
print('Negative value is not allowed')
class Cls:
age = Descriptor("age")
def __init__(self, name, age):
self.name = name
self.age = age
if __name__ == '__main__':
c = Cls("dc", 16)
print(c.__dict__) # {'name': 'dc', 'age': 16}
print(c.age) # 16
c.age = 10
print(c.age) # 10
c.age = -10 # Negative value is not allowed
print(c.age) # 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
描述符更深层次的使用, 请阅读参考文档:
https://www.cnblogs.com/traditional/p/11714356.html
https://blog.csdn.net/Victor2code/article/details/107368696
# 类变量
# 类变量值是函数
# 当时我突然思考一个问题,若每次类实例化都需要调用一个很复杂的函数得到其返回的值,eg: self.xx = foo()
# 那么该foo函数的执行其实可以放到类变量中,执行类定义代码时,该函数是会自动执行的.因为 Foo = type(Foo,object,{xx:func1()})
def func1():
return 123
class Foo:
xx = func1()
print(Foo.__dict__.get("xx", "无")) # 123
2
3
4
5
6
7
8
9
# 计数器
需求: 表明 这些实例 进行类实例化 的 先后顺序.
思路: Field类每实例化一次, 其类变量count的值就会加1!! 所有的对象都看得到的且值都是一样的,这得是个类属性.
class Field:
count = 0
def __init__(self, read_only=False, write_only=False):
self.count = Field.count
Field.count += 1
class IntegerField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
class CharField(Field):
def __init__(self, **kwargs):
super().__init__(**kwargs)
if __name__ == '__main__':
f = Field()
print(f.count, Field.count) # 0 1
f = Field()
print(f.count, Field.count) # 1 2
class TextSerializer:
f_int = IntegerField()
f_char = CharField()
t = TextSerializer()
print(t.f_int.count, Field.count) # 2 4
print(t.f_char.count, Field.count) # 3 4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 动态导入
需求: 动态的导入自己写的插件! -- import_module + 反射 即可解决.
采用动态导入使得程序的可扩展性变得很高, 插件的加减完全由配置文件来控制,不需要对业务代码进行任何修改, 符合开闭原则!!
# import_module
# -- 补充一个知识点,便于看include的源码.
path = "apps.api.urls"
import importlib
md = importlib.import_module(path) # 等同于 from apps.api imort urls 动态导入模块!!
md.app_name # 等同于 urls.app_name
2
3
4
5
# 反射的应用
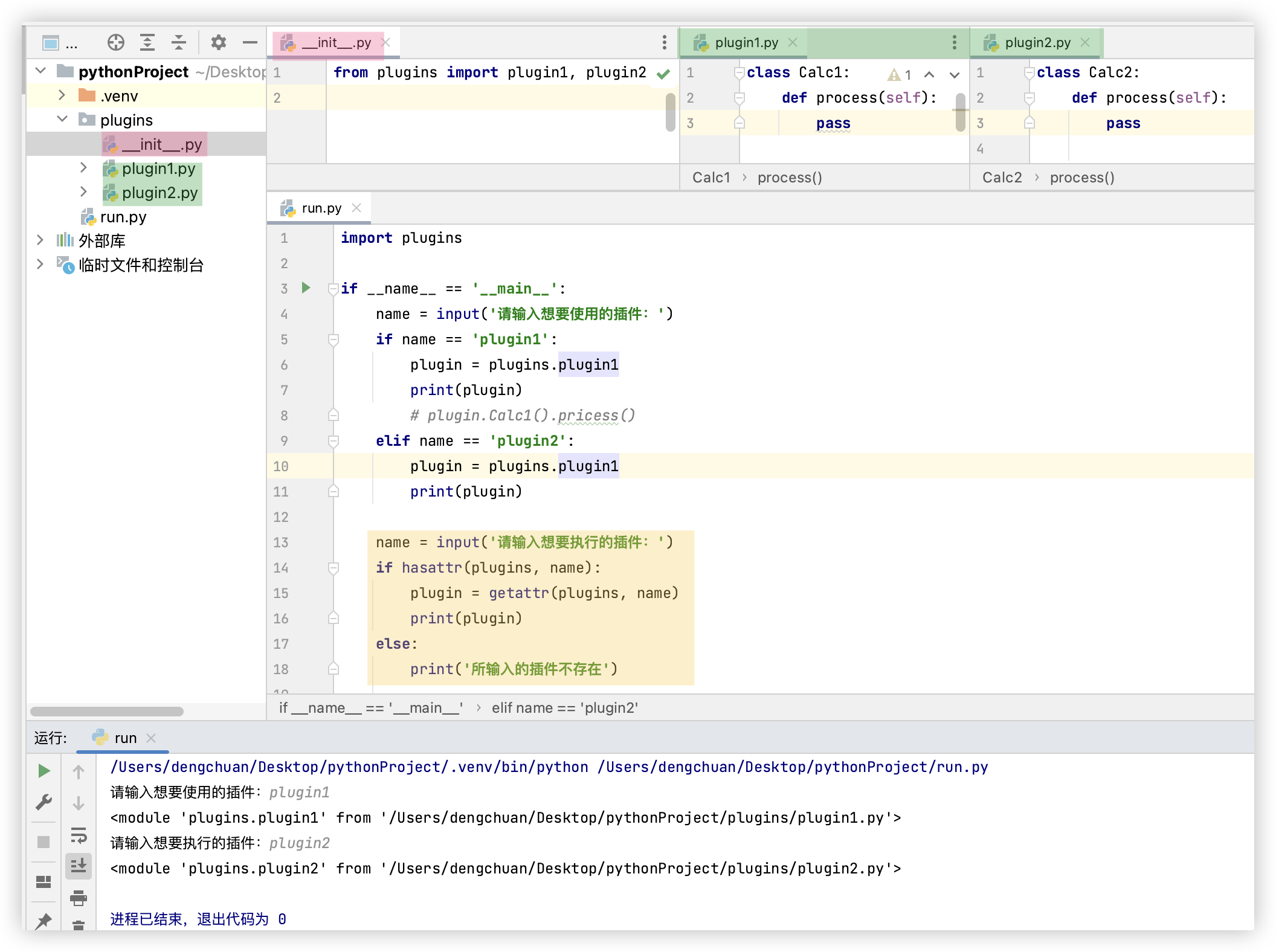
在Django中如何使用呢?
-1- 首先在配置文件settings.py中定义如下列表, 分别将两个插件类的地址放在这里, 注意是 用点号来连接路径
PLUGINS = [
'plugins.plugin1.Calc1',
'plugins.plugin2.Calc2',
]
2
3
4
-2- 然后修改业务代码如下
from importlib import import_module
import settings
if __name__ == '__main__':
for plugin in settings.PLUGINS:
module_name, class_name = plugin.rsplit('.', maxsplit=1)
module = import_module(module_name)
if hasattr(module, class_name):
obj = getattr(module, class_name)()
obj.process()
# 注: 值得注意的是, 因为采用了动态导入, 不需要再导入plugins模块了, 也就避免了__init__.py文件书写错误导致的模块导入问题.
2
3
4
5
6
7
8
9
10
11
12
# 偏函数
# -- 学会偏函数,便于看源码eg:path和re_path -- 包裹一个函数,并默认传递一个值
from functools import partial
def _xx(a, b):
return a + b
xx = partial(_xx, b=100)
print(xx(1)) # 101
2
3
4
5
6
7
8
# 装饰器
下面知识装饰器的最简单的样子, 高级用法相见 附录:装饰器!★
# -- 回顾下装饰器的原理. @auth语法糖的本质就是 test=auth(test)
def auth(func):
def inner(*args, **kwargs):
print('装饰器开始啦!')
res = func(*args, **kwargs)
return res
return inner
@auth
def test():
print('hello')
def test_1():
print('hello')
test()
print('-' * 10)
test_1 = auth(test_1)
test_1()
"""
装饰器开始啦!
hello
----------
装饰器开始啦!
hello
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 伪装术
class HttpRequest:
def __init__(self):
pass
def v1(self):
print("v1")
def v2(self):
print("v2")
class Request:
def __init__(self, req, xx):
self._request = req
self.xx = xx
def __getattr__(self, attr):
try:
return getattr(self._request, attr)
except AttributeError:
# 抛出异常说的是HttpRequest的request中没有,写了后,变成了Request的request中没有.
return self.__getattribute__(attr)
request = HttpRequest()
request.v1()
request.v2()
request = Request(request, 111)
# 伪装了一下,看似v1是request的成员,实则是request._request的成员!! crazy.
request.v1() # request._request.v1()
request.v2() # request._request.v2()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 延迟加载
延迟加载 - 资源仅在第一次调用时才会载入内存
class Lazy1(object):
@property
def first(self):
if not hasattr(self, '_first'):
self._load('Hello World')
return self._first
@first.setter
def first(self, v):
self._first = v
def _load(self, name):
self.first = name
lazy1 = Lazy1()
print(lazy1.first) # Hello World
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Django里的延迟加载
import datetime
from django.utils.functional import cached_property
class Person:
def __init__(self, birth_year):
self.birth_year = birth_year
@cached_property
def age(self):
print("Calculating age...")
current_year = datetime.datetime.now().year
return current_year - self.birth_year
john = Person(1990)
print(john.age) # 第一次访问,需要计算年龄,输出 "Calculating age..." 和计算结果
print(john.age) # 第二次访问,直接返回缓存的结果/return的值,无需再次计算
"""
Calculating age...
33
33
"""
# 要注意一点,我访问`http://127.0.0.1:8000/publish/`,底层多次用到了@cached_property修饰的A方法.A方法只会执行一次.
# 但是,我多次访问`http://127.0.0.1:8000/publish/`这个接口,每次访问都是一个新的请求,都会执行一下@cached_property修饰的方法!
# So,一定要注意,是否是同一个请求!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 抽象类
抽象类中有抽象方法, 该类不能被实例化, 只能被继承, 且子类必须实现抽象方法!!
首先, dict是MutableMapping的"虚拟子类", 所以 isinstance(a,MutableMapping) 结果为True.
>>> from collections.abc import Mapping, MutableMapping
>>> a = dict()
>>> isinstance(a,MutableMapping)
True
>>> isinstance(a,Mapping)
True
MutableMapping 类要求我们说明如何获取、删除和设置项,如何进行迭代以及如何获取字典的长度。但一旦我们完成这些,我们将免费获得 pop 、 clear 、 update 和 setdefault 方法!
2
3
4
5
6
7
我们可以写个类继承 抽象类 MutableMapping, 来自定义一个字典! 需求: 想让对象具备 dict -like的功能.
>>> from collections.abc import MutableMapping
>>> class TwoWayDict(MutableMapping):
pass
>>> d = TwoWayDict()
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
d = TwoWayDict()
TypeError: Can't instantiate abstract class TwoWayDict with abstract methods __delitem__, __getitem__, __iter__, __len__, __setitem__
※ 注:
不同于 dict, TwoWayDictde的实例d
使用 `update`、`setdefault`方法会调用`__setitem__`方法, `pop`、`clear`方法会调用`__delitem__`方法!!
2
3
4
5
6
7
8
9
10
11
12
13
报错告诉我们, 继承MutableMapping需要实现__delitem__、__getitem__、__iter__、__len__和__setitem__这些抽象方法!!
# 元类

题干: MyType()得到类A, A()得到实例a
1> 我们熟知 - python处处皆对象! 对象"加括号"调用会自动触发 "创建出该对象的类" 中的__call__方法!
(一个对象能否被调用,取决于它的类对象中是否定义了__call__)
因为 MyType = type(MyType, object, {}) , 所以 MyType()自动调用type中的__call__
因为 A = MyType(A, object, {}) , 所以 A()自动调用MyType中的__call__
2> __call__方法中的代码逻辑决定了 - "☆ 类加括号实例化会依次执行该类中的__new__、__init__" <无需深究>
eg: A() 依次执行 A中的 __new__'创建A的实例,so,cls是A'、__init__
MyType() 依次执行 MyType中的 __new__'创建MyType的实例,so,cls是MyType'、__init__
・_・; 必知必会:
- __new__ 中必须将类A的实例对象返回, 才会执行__init__, 并且执行的时候会自动将__new__ 的返回值作为参数传给self.
- 一个对象是什么, 取决于其类型对象的__new__返回了什么.
注: 你在MyType的__new__中对attr进行一点改变,影响了A这个实例,但在MyType的__init__中,你会发现attr并未改变.
因为MyType的__new__和__init__的参数值都来自于type中的__call__!
在代码截图里
- 执行语句A()时,我们找到创建出A的是MyType,那么A()会自动触发MyType中的__call__方法,并将A自动传递该__call__的第一个参数!
你别看MyType中的__call__方法的第一个参数是cls,只是参数名变了,它依旧是实例方法!
此处__call__方法里的代码逻辑,注意哦: ★ 类调用类里的实例方法,需手动传self
- 同理!MyType(A, object, {...})会自动执行MyType里的__new__和__init__
- 提醒: 从上往下运行到class定义的类代码,会立刻开辟一个类的namescope,将类中的变量和方法/函数往namescope中丢.
★ (类中的代码/类体代码 在定义阶段就执行啦!!)
注:无需纠结MyType和A中的__new__方法体里的代码为何不一样.<我纠结过,无果,当做固定写法即可Hhh>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 单例模式
方式一
class Singleton:
_instance = None # 平替到 元类的__init__里实现
def __new__(cls, *args, **kwargs): # 平替到 元类的__call__里实现
if cls._instance is None:
cls._instance = object.__new__(cls)
return cls._instance
# 测试
singleton1 = Singleton(1, 2)
singleton2 = Singleton(1, 3)
print(singleton1 is singleton2) # 输出: True
2
3
4
5
6
7
8
9
10
11
12
13
方式二
# metaclass 用于继承没办法解决的问题的. type创建类;object创建实例
import random
class M(type):
def __new__(cls, name, bases, attrs):
"""class A 类定义阶段调用 该方法是返回创建的类; 在该方法里可操作attr/对类里的成员进行操作"""
for key in attrs.keys():
if key.startswith("_test"):
raise ValueError(f"{name}类中不能出现以_test开头的方法")
return type.__new__(cls, name, bases, attrs) # return super().__new__(cls, name, bases, attrs)
def __init__(self, name, bases, attrs):
"""class A 类定义阶段调用 此时有创建好的类啦,可以对新建的这个class做一点手脚eg:给新建的类添加几个类变量"""
type.__init__(self, name, bases, attrs) # super().__init__(name, bases, attrs)
self.random_id = random.randint(0, 100) # 它等价于在A类里直接写这一行代码.
self._instance = None # 单例
def __call__(cls, *args, **kwargs):
"""A()时调用/新建立的这个类在尝试产生实例的时候调用"""
if cls._instance is None: # 单例
cls._instance = type.__call__(cls, *args, **kwargs) # return super().__call__(*args, **kwargs)
return cls._instance
class C: pass
class B(C):
pass
class A(B, metaclass=M): # A = M(A,object,{k:v})
# def _test(self):
# pass
def __new__(cls, *args, **kwargs):
return object.__new__(cls)
def __init__(self, *args, **kwargs):
self.name = "xxx"
if __name__ == '__main__':
a1 = A()
a2 = A()
print(a1 == a2)
print(isinstance(a1, type))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
rbac的项目里“用户-角色-权限”,可以用django的中间件做登陆认证和权限的校验.
设置白名单,比如登陆接口,process_request和process_view直接返回None
登陆过程中会查询数据库将该用户的所有能访问的接口,登陆成功,将结果存放到session中.
比如:{"per_url_name":[...能访问的url的name]}
访问其他接口时,同样要经过中间件,
- process_request里判断session里有没有"per_url_name"这个key,有,则证明已经登陆成功啦;
- 路由匹配成功,到process_view时,request中已经有所有路由信息啦!!
request.resolver_match.url_name取到当前匹配成功的这个路由的name.
看该路由的name 是否在request.session["per_url_name"]中,有,该用户则有权限访问该接口!!
▼ 注:路由匹配不成功,不会执行process_view
2
3
4
5
6
7
8
9
10
# 其它的八股文
关于《程序员的自我素养》
尽管我很讨厌八股文, 但还是得复习下, 不求探究的多么深, 但起码在脑海里放着, 知道它是个啥. (´・Д・)」.
多问自己, 它是个啥, 听别人讲 哪怕听懂了,也跟自己想自己理解出来的 是两个概念..
Q:面试官问:你理解的装饰器是咋样的,你如何回答?
先抛出结论 装饰器的本质就是一个callable,可调用对象.
以函数装饰器举例, 语法糖@dec装饰my_func函数, 我们就认为dec就是decorator.
@dec + 被装饰的my_func函数 完全等价于 my_func = dec(my_func)
也就是说 decorator 是一个输入是函数,输出也是函数的一个函数.
有个细节,输出的函数的参数要和被装饰函数的参数一样,通常我们使用*args,**kwargs指代.
再进行一点扩展, 带参数的装饰器是怎么一回事呢?
其实就是在多嵌套了一层函数,返回的函数是 前面提到的无参装饰器.
eg: 计算程序运行n次的时间 my_func = @dec(1000)(my_func)
2
3
4
5
6
7
8
9
Q:面试官问:你理解的元类是咋样的,你如何回答?
类实例化创建对象,会调用类的new和init方法; new申请了一片内存用于创建对象,init用于为对象添加属于自己的属性.
同理,元类实例化创建类,会调用元类的new和init方法; new用于创建类,init用于为类添加类变量. (处处皆对象嘛
那么我们就可以重载元类中的new方法,在元类创建类的过程中动一点手脚.
eg:比如不允许类中出现 test开头的方法名.
原理 >> A=type(A,object,{}) -- MetaClass=M -- A=M(A,object,{}) -- new里取attr值进行判断
- __new__ 中必须将类A的实例对象返回, 才会执行__init__, 并且执行的时候会自动将__new__ 的返回值作为参数传给self.
- 一个对象是什么, 取决于其类型对象的__new__返回了什么.
- __new__里面的参数一定要和__init__是匹配的, 除了第一个参数之外
类实例化创建的对象,若想加括号进行调用,则在类中得有__call__方法
同理,元类创建的类,若想加括号进行调用,则需要在元类里有__call__方法,该方法使得类实例化创建对象时,先new后init!
类里的new、init、call方法第一个参数分别是 当前类、当前类的实例、当前类的实例
- 注: 一个类在没有指定的metaclass的时候,如果它的父类指定了,那么这个类的metaclass等于父类的metaclass!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Q: 面试官问: 简单阐述下计算机的三层架构. 你如何回答?
冯诺依曼模型定义了计算机由什么构成(硬件)= 运算器 + 控制器 + 存储器 + 输入设备 + 输出设备
★ "运算器和控制器都在CPU里,前者负责运算(数学运算和逻辑运算)、后者计算机的指挥系统,负责控制其他硬件的运行."
计算机的三层架构: (用户)- 应用程序 - 操作系统 - 计算机硬件 为何如此设计呢? -- 总结:简化应用程序对计算机硬件的操作!
硬件CPU是其它所有硬件的老大,CPU内部集成的二进制指令集用于操作其它计算机硬件.
但CPU不会自发的控制其他硬件的运行.因为cpu本身也是硬件, 硬件都会受软件的支配
- OS这个软件分为内核(内核态)和系统接口(用户态)
"内核里是CPU内部集成的数不清的二进制指令集";系统接口将其进行封装 (做个比喻:OS内核功能十几万个,系统接口封装完可能就几万个
- 上层应用程序(eg:shell解释器),将OS系统接口进一步封装.(比如:shell解释器的命令 mkdir
★ 综上,说白了,用软件的某一个功能:
就是执行了某个程序(一堆代码eg:python代码open/shell命令eg:touch),进而去调用OS对应的系统接口,完成对计算机硬件的操作.
> 所以说, <应用程序调用硬件> 是需要经过操作系统的. 所有的应用程序都是运行在操作系统之上的.
我们通常听到的32/64位,是指cpu一个指令能处理多大的数据,即 每次/一次性 能从内存里读取的32/64个二进制数
我们规定32/64位会组成一个完整的指令,CPU有成千上万数不清的指令集
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Q: 面试官问:python解释器是如何运行一个py文件的 / python程序执行过程, 你如何回答?
将需用到的py源代码/需执行的py文件 --(进行编译)-- PyCodeObject对象,里面包含字节码 --(通过python的PVM虚拟机逐行解释字节码)
Python解释器 = Python编译器 + Python虚拟机
-1- 某段代码需要运行,先将该段代码加载进内存.
-2- Python编译器负责将Python源代码编译成字节码(包括文件读取、分词、建立AST、编译成字节码);
-3- Python虚拟机负责执行这些字节码,完成相应的功能.
何为字节码? 使用dis模块可以看到一段程序的字节码,是以 一堆 人类能看懂的英文单词 呈现的.
注:字节码可以跨平台,因为不同的平台都有自己适配的Python解释器.
(・_・; 再说细一点:
编译的结果"字节码"会放到内存的PyCodeObject中,若需持久化保存,会写入pyc文件
PyCodeObject对象中有一个成员co_code,其指向的就是该段程序的字节码.
什么时候需要pyc?
import的时候,会将import的模块编译成.pyc文件,便于下次运行加快效率
.pyc文件的过期:会跟import的模块最后的修改日期进行对比,若py文件/模块修改了,.pyc文件就会重新生成
注:语言的演变
机器码(二进制0101的高低电平) - 汇编语言(将一串串二进制数对应成英文单词) - 高级语言(通常会有编译的过程)
--- --- ---
※ 当时我在想,Python虚拟机本质就是一个软件,它负责执行这些字节码,那么py虚拟机执行字节码的过程如何与计算机的三层架构联系起来呢?
哇,当时我就懵了,努力回顾操作系统的五大功能,进程管理、存储管理、设备管理、文件管理、作业管理.
还是没明白,都怪自己上大学时没好好听讲,书到用时方恨少,暂且略过吧!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Q: 面试官问: frame、CodeObject、bytecode是啥, 你如何回答?
当我们在python中所谓定义一个函数的时候,我们只是新建了一个变量,然后这个变量里面保存了一个函数对象,也就是 `function object`!
每一个function object也都会有它对应的一个CodeObject..
所有的python代码在编译器都会被编译成CodeObject.
code object里有啥? 有该段程序的bytecode(字节码)、有位置参数关键字参数的数量、自由变量、局部变量等信息.
- 当你 [每一次调用函数] 或者 [刚开始运行python] 的时候,都会建立一个新的frame
- 在这个frame的环境下,你会一条条的运行bytecode,每一条bytecode在c语言里都有相应的代码去执行它!
- 在每一个frame里,python会维护一个stack(栈)
bytecode跟这个栈进行交互,当然也会跟codeobject里保存的那些乱七八糟的东西进行交互.
接着就是进行计算,拿到结果,返回,继续.
这一套类似于汇编,只不过汇编可以直接运行在硬件上,而python的bytecode需要运行在c语言上!
2
3
4
5
6
7
8
9
10
11
12
13